 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Explanations Over Time: Articulated Reasoning for Interactive Environments
Jun 04, 2025Structural Causal Explanations (SCEs) can be used to automatically generate explanations in natural language to questions about given data that are grounded in a (possibly learned) causal model. Unfortunately they work for small data only. In turn they are not attractive to offer reasons for events, e.g., tracking causal changes over multiple time steps, or a behavioral component that involves feedback loops through actions of an agent. To this end, we generalize SCEs to a (recursive) formulation of explanation trees to capture the temporal interactions between reasons. We show the benefits of this more general SCE algorithm on synthetic time-series data and a 2D grid game, and further compare it to the base SCE and other existing methods for causal explanations.
Diagnostic Reasoning in Natural Language: Computational Model and Application
Sep 09, 2024



Diagnostic reasoning is a key component of expert work in many domains. It is a hard, time-consuming activity that requires expertise, and AI research has investigated the ways automated systems can support this process. Yet, due to the complexity of natural language, the applications of AI for diagnostic reasoning to language-related tasks are lacking. To close this gap, we investigate diagnostic abductive reasoning (DAR) in the context of language-grounded tasks (NL-DAR). We propose a novel modeling framework for NL-DAR based on Pearl's structural causal models and instantiate it in a comprehensive study of scientific paper assessment in the biomedical domain. We use the resulting dataset to investigate the human decision-making process in NL-DAR and determine the potential of LLMs to support structured decision-making over text. Our framework, open resources and tools lay the groundwork for the empirical study of collaborative diagnostic reasoning in the age of LLMs, in the scholarly domain and beyond.
$χ$SPN: Characteristic Interventional Sum-Product Networks for Causal Inference in Hybrid Domains
Aug 14, 2024



Causal inference in hybrid domains, characterized by a mixture of discrete and continuous variables, presents a formidable challenge. We take a step towards this direction and propose Characteristic Interventional Sum-Product Network ($\chi$SPN) that is capable of estimating interventional distributions in presence of random variables drawn from mixed distributions. $\chi$SPN uses characteristic functions in the leaves of an interventional SPN (iSPN) thereby providing a unified view for discrete and continuous random variables through the Fourier-Stieltjes transform of the probability measures. A neural network is used to estimate the parameters of the learned iSPN using the intervened data. Our experiments on 3 synthetic heterogeneous datasets suggest that $\chi$SPN can effectively capture the interventional distributions for both discrete and continuous variables while being expressive and causally adequate. We also show that $\chi$SPN generalize to multiple interventions while being trained only on a single intervention data.
Do Not Marginalize Mechanisms, Rather Consolidate!
Oct 12, 2023



Structural causal models (SCMs) are a powerful tool for understanding the complex causal relationships that underlie many real-world systems. As these systems grow in size, the number of variables and complexity of interactions between them does, too. Thus, becoming convoluted and difficult to analyze. This is particularly true in the context of machine learning and artificial intelligence, where an ever increasing amount of data demands for new methods to simplify and compress large scale SCM. While methods for marginalizing and abstracting SCM already exist today, they may destroy the causality of the marginalized model. To alleviate this, we introduce the concept of consolidating causal mechanisms to transform large-scale SCM while preserving consistent interventional behaviour. We show consolidation is a powerful method for simplifying SCM, discuss reduction of computational complexity and give a perspective on generalizing abilities of consolidated SCM.
Causal Parrots: Large Language Models May Talk Causality But Are Not Causal
Aug 24, 2023



Some argue scale is all what is needed to achieve AI, covering even causal models. We make it clear that large language models (LLMs) cannot be causal and give reason onto why sometimes we might feel otherwise. To this end, we define and exemplify a new subgroup of Structural Causal Model (SCM) that we call meta SCM which encode causal facts about other SCM within their variables. We conjecture that in the cases where LLM succeed in doing causal inference, underlying was a respective meta SCM that exposed correlations between causal facts in natural language on whose data the LLM was ultimately trained. If our hypothesis holds true, then this would imply that LLMs are like parrots in that they simply recite the causal knowledge embedded in the data. Our empirical analysis provides favoring evidence that current LLMs are even weak `causal parrots.'
* Published in Transactions in Machine Learning Research (TMLR) (08/2023). Main paper: 17 pages, References: 3 pages, Appendix: 7 pages. Figures: 5 main, 3 appendix. Tables: 3 main
Continual Causal Abstractions
Jan 06, 2023
This short paper discusses continually updated causal abstractions as a potential direction of future research. The key idea is to revise the existing level of causal abstraction to a different level of detail that is both consistent with the history of observed data and more effective in solving a given task.
On How AI Needs to Change to Advance the Science of Drug Discovery
Dec 23, 2022


Research around AI for Science has seen significant success since the rise of deep learning models over the past decade, even with longstanding challenges such as protein structure prediction. However, this fast development inevitably made their flaws apparent -- especially in domains of reasoning where understanding the cause-effect relationship is important. One such domain is drug discovery, in which such understanding is required to make sense of data otherwise plagued by spurious correlations. Said spuriousness only becomes worse with the ongoing trend of ever-increasing amounts of data in the life sciences and thereby restricts researchers in their ability to understand disease biology and create better therapeutics. Therefore, to advance the science of drug discovery with AI it is becoming necessary to formulate the key problems in the language of causality, which allows the explication of modelling assumptions needed for identifying true cause-effect relationships. In this attention paper, we present causal drug discovery as the craft of creating models that ground the process of drug discovery in causal reasoning.
Pearl Causal Hierarchy on Image Data: Intricacies & Challenges
Dec 23, 2022Many researchers have voiced their support towards Pearl's counterfactual theory of causation as a stepping stone for AI/ML research's ultimate goal of intelligent systems. As in any other growing subfield, patience seems to be a virtue since significant progress on integrating notions from both fields takes time, yet, major challenges such as the lack of ground truth benchmarks or a unified perspective on classical problems such as computer vision seem to hinder the momentum of the research movement. This present work exemplifies how the Pearl Causal Hierarchy (PCH) can be understood on image data by providing insights on several intricacies but also challenges that naturally arise when applying key concepts from Pearlian causality to the study of image data.
Attributions Beyond Neural Networks: The Linear Program Case
Jun 14, 2022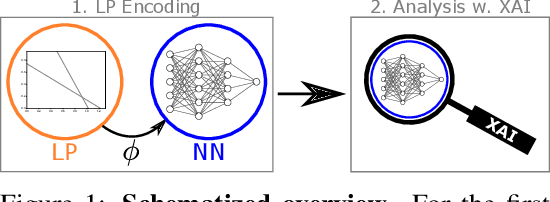

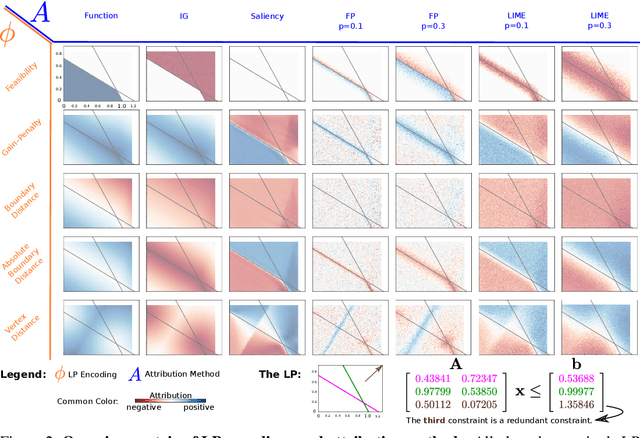
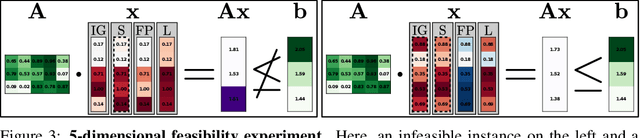
Linear Programs (LPs) have been one of the building blocks in machine learning and have championed recent strides in differentiable optimizers for learning systems. While there exist solvers for even high-dimensional LPs, understanding said high-dimensional solutions poses an orthogonal and unresolved problem. We introduce an approach where we consider neural encodings for LPs that justify the application of attribution methods from explainable artificial intelligence (XAI) designed for neural learning systems. The several encoding functions we propose take into account aspects such as feasibility of the decision space, the cost attached to each input, or the distance to special points of interest. We investigate the mathematical consequences of several XAI methods on said neural LP encodings. We empirically show that the attribution methods Saliency and LIME reveal indistinguishable results up to perturbation levels, and we propose the property of Directedness as the main discriminative criterion between Saliency and LIME on one hand, and a perturbation-based Feature Permutation approach on the other hand. Directedness indicates whether an attribution method gives feature attributions with respect to an increase of that feature. We further notice the baseline selection problem beyond the classical computer vision setting for Integrated Gradients.
Can Foundation Models Talk Causality?
Jun 14, 2022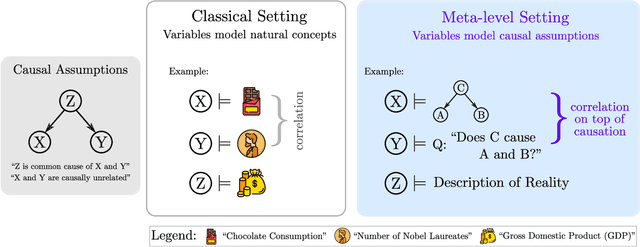
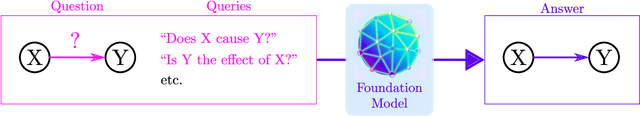
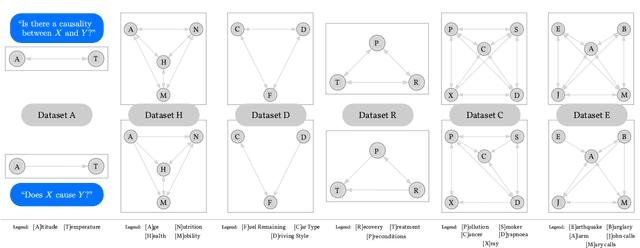
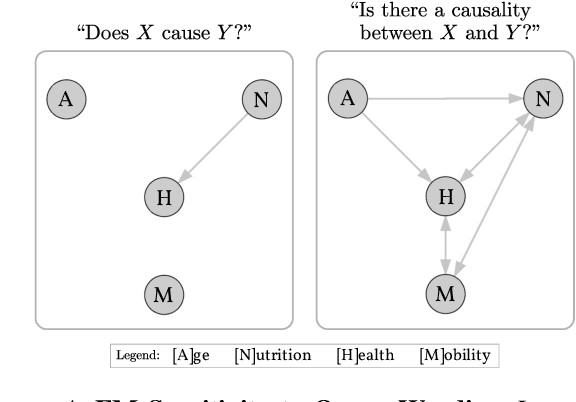
Foundation models are subject to an ongoing heated debate, leaving open the question of progress towards AGI and dividing the community into two camps: the ones who see the arguably impressive results as evidence to the scaling hypothesis, and the others who are worried about the lack of interpretability and reasoning capabilities. By investigating to which extent causal representations might be captured by these large scale language models, we make a humble efforts towards resolving the ongoing philosophical conflicts.