 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Context-Aware Online Client Selection for Hierarchical Federated Learning
Dec 02, 2021
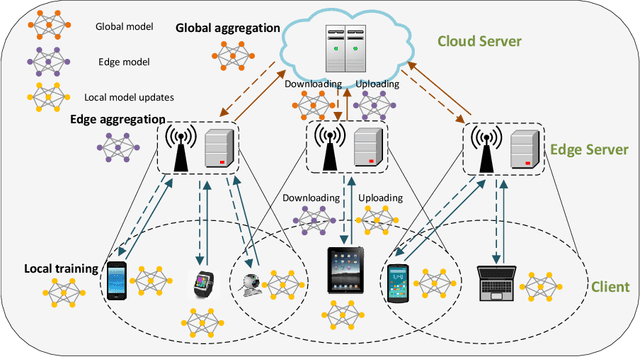
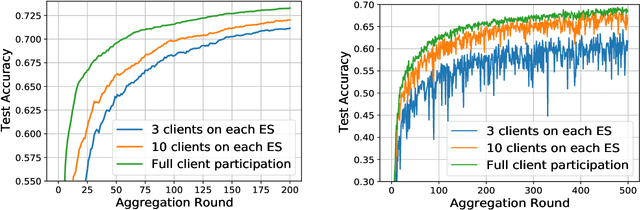
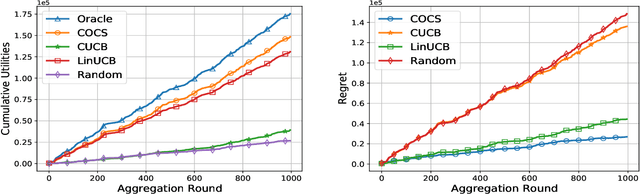
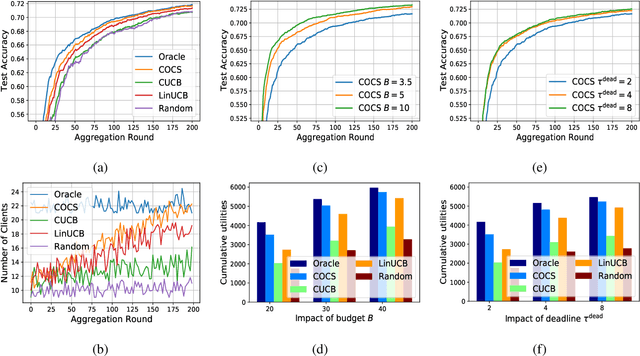
Federated Learning (FL) has been considered as an appealing framework to tackle data privacy issues of mobile devices compared to conventional Machine Learning (ML). Using Edge Servers (ESs) as intermediaries to perform model aggregation in proximity can reduce the transmission overhead, and it enables great potentials in low-latency FL, where the hierarchical architecture of FL (HFL) has been attracted more attention. Designing a proper client selection policy can significantly improve training performance, and it has been extensively used in FL studies. However, to the best of our knowledge, there are no studies focusing on HFL. In addition, client selection for HFL faces more challenges than conventional FL, e.g., the time-varying connection of client-ES pairs and the limited budget of the Network Operator (NO). In this paper, we investigate a client selection problem for HFL, where the NO learns the number of successful participating clients to improve the training performance (i.e., select as many clients in each round) as well as under the limited budget on each ES. An online policy, called Context-aware Online Client Selection (COCS), is developed based on Contextual Combinatorial Multi-Armed Bandit (CC-MAB). COCS observes the side-information (context) of local computing and transmission of client-ES pairs and makes client selection decisions to maximize NO's utility given a limited budget. Theoretically, COCS achieves a sublinear regret compared to an Oracle policy on both strongly convex and non-convex HFL. Simulation results also support the efficiency of the proposed COCS policy on real-world datasets.
Learning Disentangled Representations of Satellite Image Time Series
Mar 21, 2019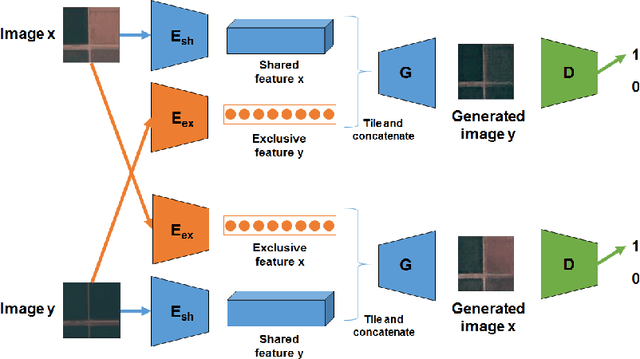
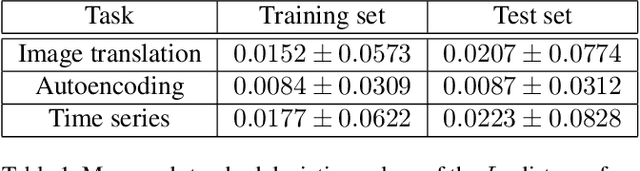
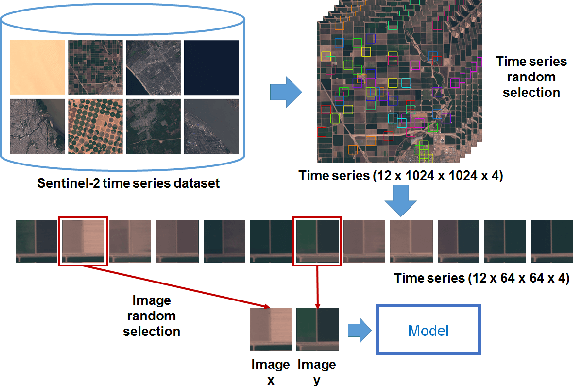
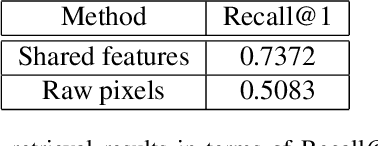
In this paper, we investigate how to learn a suitable representation of satellite image time series in an unsupervised manner by leveraging large amounts of unlabeled data. Additionally , we aim to disentangle the representation of time series into two representations: a shared representation that captures the common information between the images of a time series and an exclusive representation that contains the specific information of each image of the time series. To address these issues, we propose a model that combines a novel component called cross-domain autoencoders with the variational autoencoder (VAE) and generative ad-versarial network (GAN) methods. In order to learn disentangled representations of time series, our model learns the multimodal image-to-image translation task. We train our model using satellite image time series from the Sentinel-2 mission. Several experiments are carried out to evaluate the obtained representations. We show that these disentangled representations can be very useful to perform multiple tasks such as image classification, image retrieval, image segmentation and change detection.
Evaluating the application of NLP tools in mainstream participatory budgeting processes in Scotland
Nov 23, 2021In recent years participatory budgeting (PB) in Scotland has grown from a handful of community-led processes to a movement supported by local and national government. This is epitomized by an agreement between the Scottish Government and the Convention of Scottish Local Authorities (COSLA) that at least 1% of local authority budgets will be subject to PB. This ongoing research paper explores the challenges that emerge from this 'scaling up' or 'mainstreaming' across the 32 local authorities that make up Scotland. The main objective is to evaluate local authority use of the digital platform Consul, which applies Natural Language Processing (NLP) to address these challenges. This project adopts a qualitative longitudinal design with interviews, observations of PB processes, and analysis of the digital platform data. Thematic analysis is employed to capture the major issues and themes which emerge. Longitudinal analysis then explores how these evolve over time. The potential for 32 live study sites provides a unique opportunity to explore discrete political and social contexts which materialize and allow for a deeper dive into the challenges and issues that may exist, something a wider cross-sectional study would miss. Initial results show that issues and challenges which come from scaling up may be tackled using NLP technology which, in a previous controlled use case-based evaluation, has shown to improve the effectiveness of citizen participation.
Learning Correspondence from the Cycle-Consistency of Time
Apr 02, 2019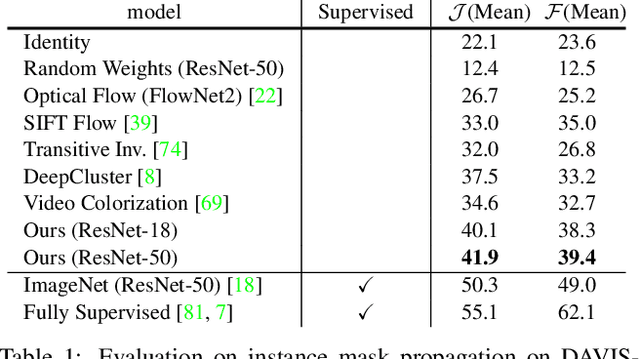
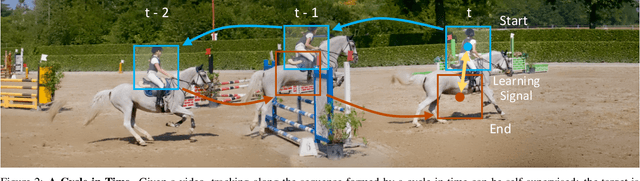
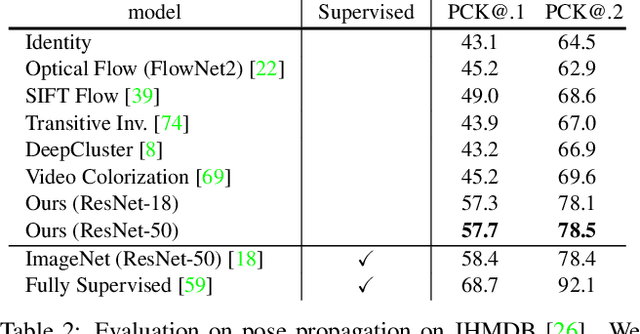
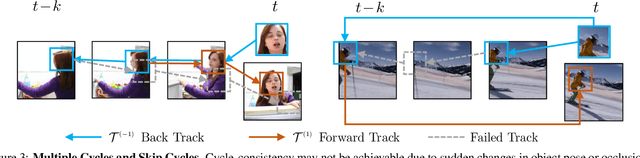
We introduce a self-supervised method for learning visual correspondence from unlabeled video. The main idea is to use cycle-consistency in time as free supervisory signal for learning visual representations from scratch. At training time, our model learns a feature map representation to be useful for performing cycle-consistent tracking. At test time, we use the acquired representation to find nearest neighbors across space and time. We demonstrate the generalizability of the representation -- without finetuning -- across a range of visual correspondence tasks, including video object segmentation, keypoint tracking, and optical flow. Our approach outperforms previous self-supervised methods and performs competitively with strongly supervised methods.
Radar Aided 6G Beam Prediction: Deep Learning Algorithms and Real-World Demonstration
Nov 18, 2021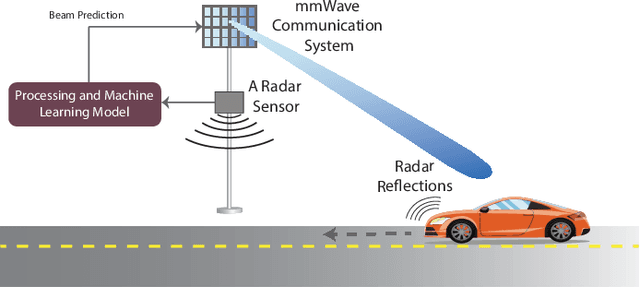
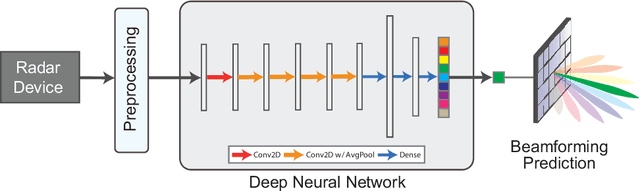
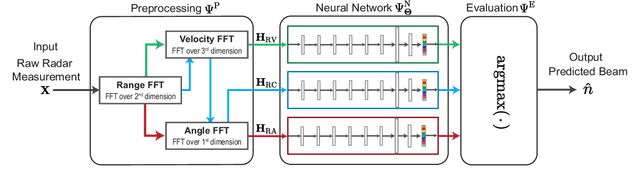

This paper presents the first machine learning based real-world demonstration for radar-aided beam prediction in a practical vehicular communication scenario. Leveraging radar sensory data at the communication terminals provides important awareness about the transmitter/receiver locations and the surrounding environment. This awareness could be utilized to reduce or even eliminate the beam training overhead in millimeter wave (mmWave) and sub-terahertz (THz) MIMO communication systems, which enables a wide range of highly-mobile low-latency applications. In this paper, we develop deep learning based radar-aided beam prediction approaches for mmWave/sub-THz systems. The developed solutions leverage domain knowledge for radar signal processing to extract the relevant features fed to the learning models. This optimizes their performance, complexity, and inference time. The proposed radar-aided beam prediction solutions are evaluated using the large-scale real-world dataset DeepSense 6G, which comprises co-existing mmWave beam training and radar measurements. In addition to completely eliminating the radar/communication calibration overhead, the experimental results showed that the proposed algorithms are able to achieve around $90\%$ top-5 beam prediction accuracy while saving $93\%$ of the beam training overhead. This highlights a promising direction for addressing the beam management overhead challenges in mmWave/THz communication systems.
Swift sky localization of gravitational waves using deep learning seeded importance sampling
Nov 01, 2021
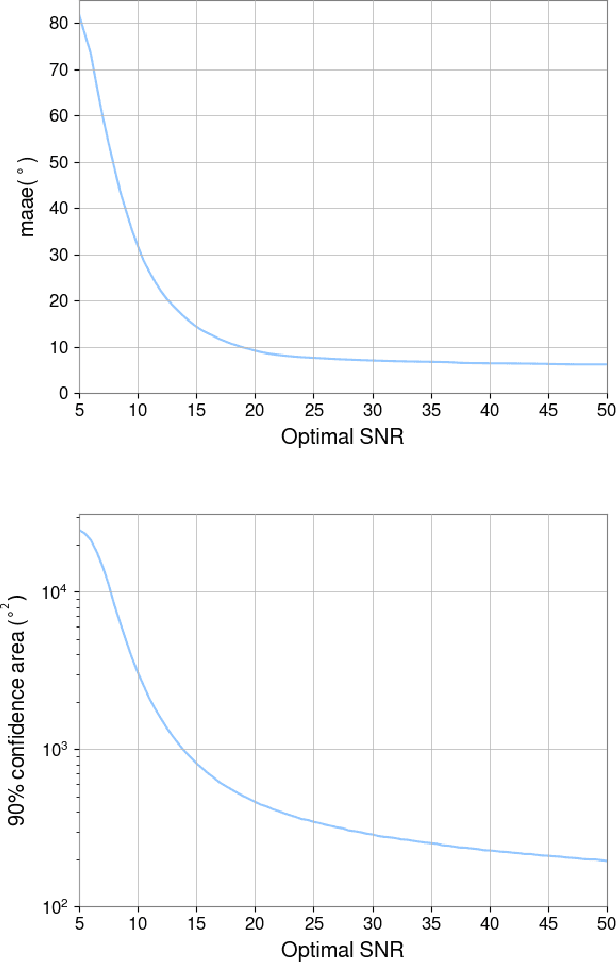
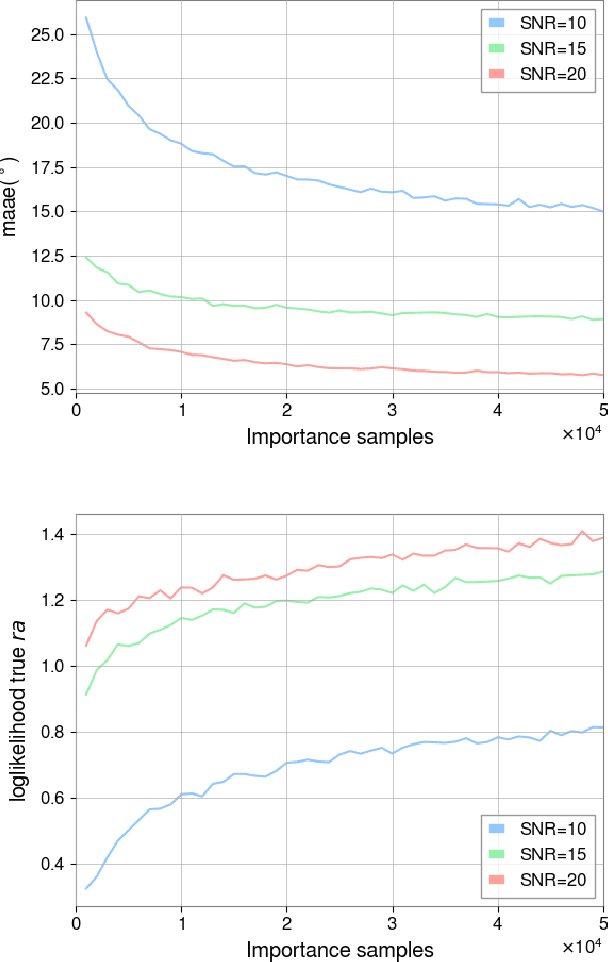
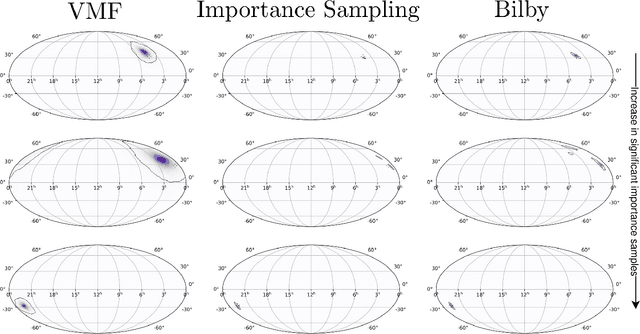
Fast, highly accurate, and reliable inference of the sky origin of gravitational waves would enable real-time multi-messenger astronomy. Current Bayesian inference methodologies, although highly accurate and reliable, are slow. Deep learning models have shown themselves to be accurate and extremely fast for inference tasks on gravitational waves, but their output is inherently questionable due to the blackbox nature of neural networks. In this work, we join Bayesian inference and deep learning by applying importance sampling on an approximate posterior generated by a multi-headed convolutional neural network. The neural network parametrizes Von Mises-Fisher and Gaussian distributions for the sky coordinates and two masses for given simulated gravitational wave injections in the LIGO and Virgo detectors. We generate skymaps for unseen gravitational-wave events that highly resemble predictions generated using Bayesian inference in a few minutes. Furthermore, we can detect poor predictions from the neural network, and quickly flag them.
Cross-modal Zero-shot Hashing by Label Attributes Embedding
Nov 07, 2021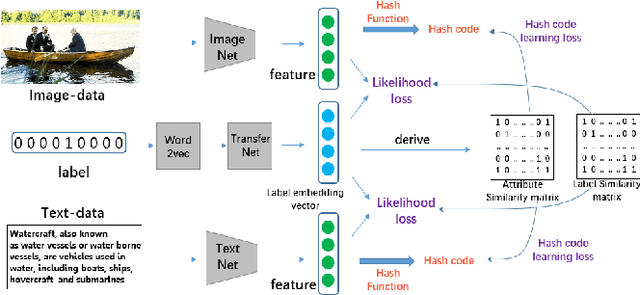
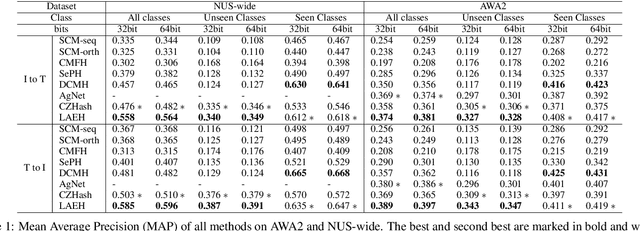
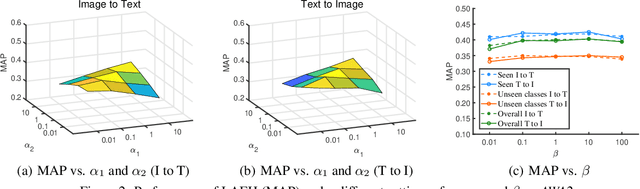
Cross-modal hashing (CMH) is one of the most promising methods in cross-modal approximate nearest neighbor search. Most CMH solutions ideally assume the labels of training and testing set are identical. However, the assumption is often violated, causing a zero-shot CMH problem. Recent efforts to address this issue focus on transferring knowledge from the seen classes to the unseen ones using label attributes. However, the attributes are isolated from the features of multi-modal data. To reduce the information gap, we introduce an approach called LAEH (Label Attributes Embedding for zero-shot cross-modal Hashing). LAEH first gets the initial semantic attribute vectors of labels by word2vec model and then uses a transformation network to transform them into a common subspace. Next, it leverages the hash vectors and the feature similarity matrix to guide the feature extraction network of different modalities. At the same time, LAEH uses the attribute similarity as the supplement of label similarity to rectify the label embedding and common subspace. Experiments show that LAEH outperforms related representative zero-shot and cross-modal hashing methods.
SAR Image Classification Based on Spiking Neural Network through Spike-Time Dependent Plasticity and Gradient Descent
Jun 15, 2021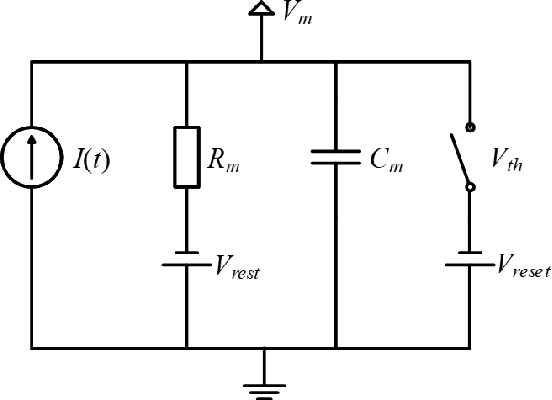
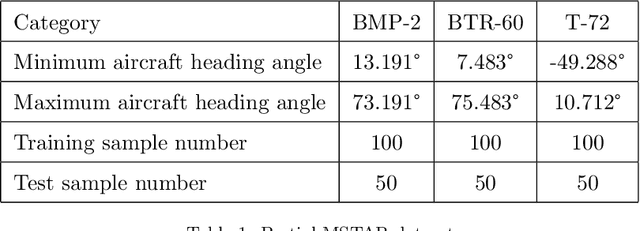
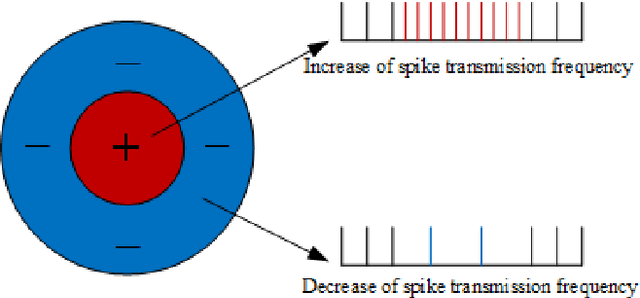
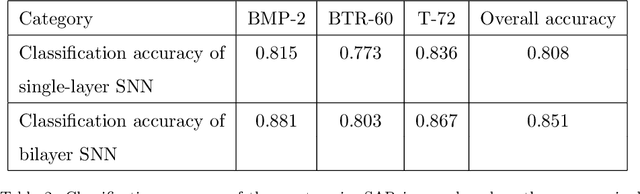
At present, the Synthetic Aperture Radar (SAR) image classification method based on convolution neural network (CNN) has faced some problems such as poor noise resistance and generalization ability. Spiking neural network (SNN) is one of the core components of brain-like intelligence and has good application prospects. This article constructs a complete SAR image classifier based on unsupervised and supervised learning of SNN by using spike sequences with complex spatio-temporal information. We firstly expound the spiking neuron model, the receptive field of SNN, and the construction of spike sequence. Then we put forward an unsupervised learning algorithm based on STDP and a supervised learning algorithm based on gradient descent. The average classification accuracy of single layer and bilayer unsupervised learning SNN in three categories images on MSTAR dataset is 80.8\% and 85.1\%, respectively. Furthermore, the convergent output spike sequences of unsupervised learning can be used as teaching signals. Based on the TensorFlow framework, a single layer supervised learning SNN is built from the bottom, and the classification accuracy reaches 90.05\%. By comparing noise resistance and model parameters between SNNs and CNNs, the effectiveness and outstanding advantages of SNN are verified. Code to reproduce our experiments is available at \url{https://github.com/Jiankun-chen/Supervised-SNN-with-GD}.
Traffic-Net: 3D Traffic Monitoring Using a Single Camera
Sep 19, 2021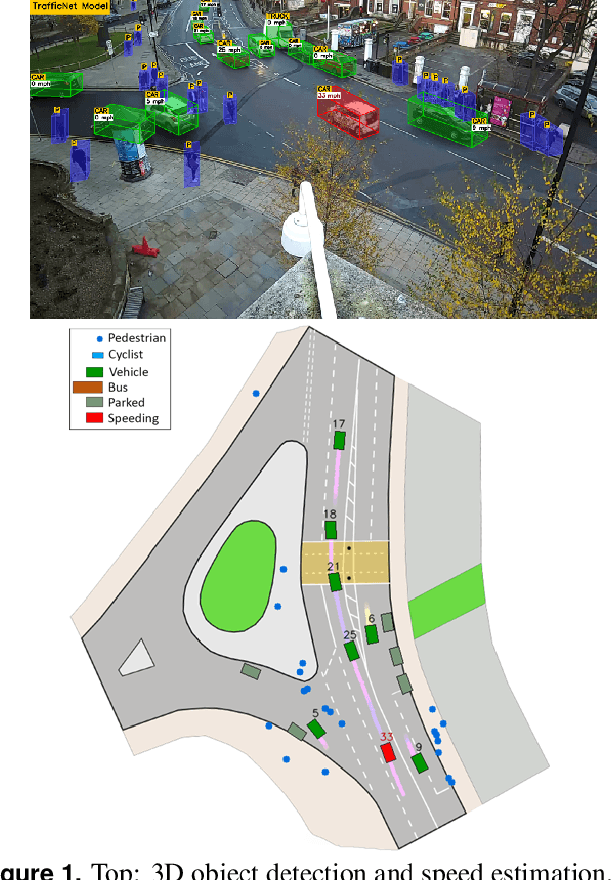
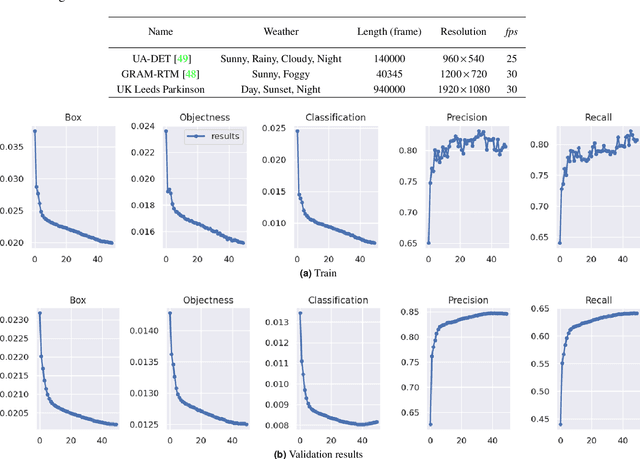
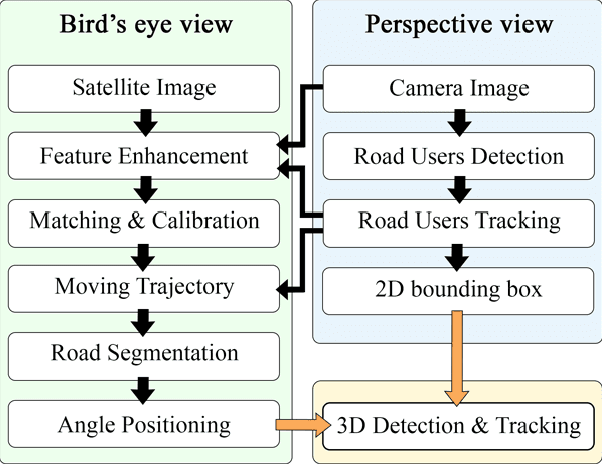
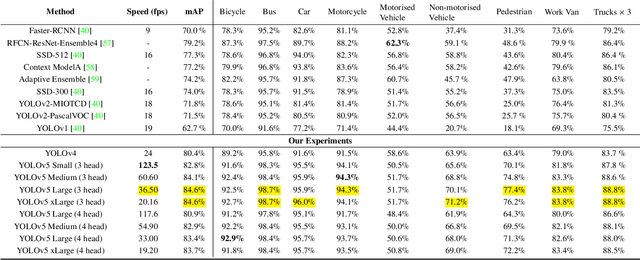
Computer Vision has played a major role in Intelligent Transportation Systems (ITS) and traffic surveillance. Along with the rapidly growing automated vehicles and crowded cities, the automated and advanced traffic management systems (ATMS) using video surveillance infrastructures have been evolved by the implementation of Deep Neural Networks. In this research, we provide a practical platform for real-time traffic monitoring, including 3D vehicle/pedestrian detection, speed detection, trajectory estimation, congestion detection, as well as monitoring the interaction of vehicles and pedestrians, all using a single CCTV traffic camera. We adapt a custom YOLOv5 deep neural network model for vehicle/pedestrian detection and an enhanced SORT tracking algorithm. For the first time, a hybrid satellite-ground based inverse perspective mapping (SG-IPM) method for camera auto-calibration is also developed which leads to an accurate 3D object detection and visualisation. We also develop a hierarchical traffic modelling solution based on short- and long-term temporal video data stream to understand the traffic flow, bottlenecks, and risky spots for vulnerable road users. Several experiments on real-world scenarios and comparisons with state-of-the-art are conducted using various traffic monitoring datasets, including MIO-TCD, UA-DETRAC and GRAM-RTM collected from highways, intersections, and urban areas under different lighting and weather conditions.
Predicting Rebar Endpoints using Sin Exponential Regression Model
Oct 18, 2021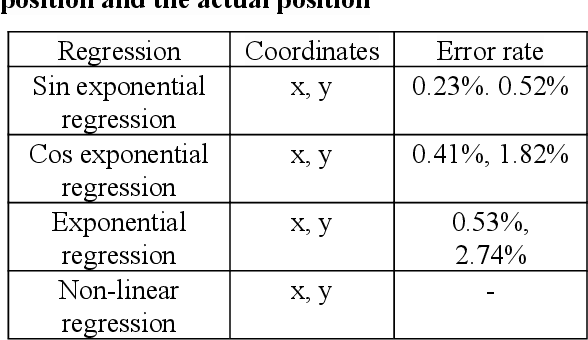
Currently, unmanned automation studies are underway to minimize the loss rate of rebar production and the time and accuracy of calibration when producing defective products in the cutting process of processing rebar factories. In this paper, we propose a method to detect and track rebar endpoint images entering the machine vision camera based on YOLO (You Only Look Once)v3, and to predict rebar endpoint in advance with sin exponential regression of acquired coordinates. The proposed method solves the problem of large prediction error rates for frame locations where rebar endpoints are far away in OPPDet (Object Position Prediction Detect) models, which prepredict rebar endpoints with improved results showing 0.23 to 0.52% less error rates at sin exponential regression prediction points.