 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal-Audit: A Framework for Risk Assessment of Assumption Violations in Time-Series Causal Discovery
Apr 02, 2026Time-series causal discovery methods rely on assumptions such as stationarity, regular sampling, and bounded temporal dependence. When these assumptions are violated, structure learning can produce confident but misleading causal graphs without warning. We introduce Causal-Audit, a framework that formalizes assumption validation as calibrated risk assessment. The framework computes effect-size diagnostics across five assumption families (stationarity, irregularity, persistence, nonlinearity, and confounding proxies), aggregates them into four calibrated risk scores with uncertainty intervals, and applies an abstention-aware decision policy that recommends methods (e.g., PCMCI+, VAR-based Granger causality) only when evidence supports reliable inference. The semi-automatic diagnostic stage can also be used independently for structured assumption auditing in individual studies. Evaluation on a synthetic atlas of 500 data-generating processes (DGPs) spanning 10 violation families demonstrates well-calibrated risk scores (AUROC > 0.95), a 62% false positive reduction among recommended datasets, and 78% abstention on severe-violation cases. On 21 external evaluations from TimeGraph (18 categories) and CausalTime (3 domains), recommend-or-abstain decisions are consistent with benchmark specifications in all cases. An open-source implementation of our framework is available.
AI-assisted Advanced Propellant Development for Electric Propulsion
Sep 30, 2025Artificial Intelligence algorithms are introduced in this work as a tool to predict the performance of new chemical compounds as alternative propellants for electric propulsion, focusing on predicting their ionisation characteristics and fragmentation patterns. The chemical properties and structure of the compounds are encoded using a chemical fingerprint, and the training datasets are extracted from the NIST WebBook. The AI-predicted ionisation energy and minimum appearance energy have a mean relative error of 6.87% and 7.99%, respectively, and a predicted ion mass with a 23.89% relative error. In the cases of full mass spectra due to electron ionisation, the predictions have a cosine similarity of 0.6395 and align with the top 10 most similar mass spectra in 78% of instances within a 30 Da range.
Convolutional Neural Networks for Accurate Measurement of Train Speed
Aug 23, 2025


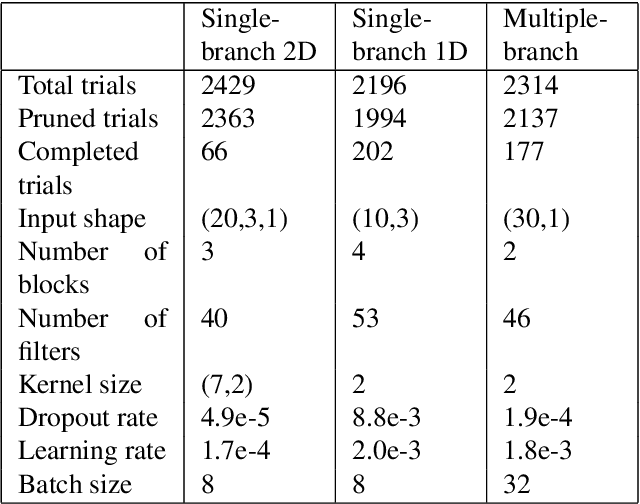
In this study, we explore the use of Convolutional Neural Networks for improving train speed estimation accuracy, addressing the complex challenges of modern railway systems. We investigate three CNN architectures - single-branch 2D, single-branch 1D, and multiple-branch models - and compare them with the Adaptive Kalman Filter. We analyse their performance using simulated train operation datasets with and without Wheel Slide Protection activation. Our results reveal that CNN-based approaches, especially the multiple-branch model, demonstrate superior accuracy and robustness compared to traditional methods, particularly under challenging operational conditions. These findings highlight the potential of deep learning techniques to enhance railway safety and operational efficiency by more effectively capturing intricate patterns in complex transportation datasets.
Parameter Estimation using Reinforcement Learning Causal Curiosity: Limits and Challenges
May 13, 2025



Causal understanding is important in many disciplines of science and engineering, where we seek to understand how different factors in the system causally affect an experiment or situation and pave a pathway towards creating effective or optimising existing models. Examples of use cases are autonomous exploration and modelling of unknown environments or assessing key variables in optimising large complex systems. In this paper, we analyse a Reinforcement Learning approach called Causal Curiosity, which aims to estimate as accurately and efficiently as possible, without directly measuring them, the value of factors that causally determine the dynamics of a system. Whilst the idea presents a pathway forward, measurement accuracy is the foundation of methodology effectiveness. Focusing on the current causal curiosity's robotic manipulator, we present for the first time a measurement accuracy analysis of the future potentials and current limitations of this technique and an analysis of its sensitivity and confounding factor disentanglement capability - crucial for causal analysis. As a result of our work, we promote proposals for an improved and efficient design of Causal Curiosity methods to be applied to real-world complex scenarios.
Machine Learning Information Retrieval and Summarisation to Support Systematic Review on Outcomes Based Contracting
Dec 11, 2024As academic literature proliferates, traditional review methods are increasingly challenged by the sheer volume and diversity of available research. This article presents a study that aims to address these challenges by enhancing the efficiency and scope of systematic reviews in the social sciences through advanced machine learning (ML) and natural language processing (NLP) tools. In particular, we focus on automating stages within the systematic reviewing process that are time-intensive and repetitive for human annotators and which lend themselves to immediate scalability through tools such as information retrieval and summarisation guided by expert advice. The article concludes with a summary of lessons learnt regarding the integrated approach towards systematic reviews and future directions for improvement, including explainability.
Deep Autoencoders for Unsupervised Anomaly Detection in Wildfire Prediction
Nov 14, 2024



Wildfires pose a significantly increasing hazard to global ecosystems due to the climate crisis. Due to its complex nature, there is an urgent need for innovative approaches to wildfire prediction, such as machine learning. This research took a unique approach, differentiating from classical supervised learning, and addressed the gap in unsupervised wildfire prediction using autoencoders and clustering techniques for anomaly detection. Historical weather and normalised difference vegetation index datasets of Australia for 2005 - 2021 were utilised. Two main unsupervised approaches were analysed. The first used a deep autoencoder to obtain latent features, which were then fed into clustering models, isolation forest, local outlier factor and one-class SVM for anomaly detection. The second approach used a deep autoencoder to reconstruct the input data and use reconstruction errors to identify anomalies. Long Short-Term Memory (LSTM) autoencoders and fully connected (FC) autoencoders were employed in this part, both in an unsupervised way learning only from nominal data. The FC autoencoder outperformed its counterparts, achieving an accuracy of 0.71, an F1-score of 0.74, and an MCC of 0.42. These findings highlight the practicality of this method, as it effectively predicts wildfires in the absence of ground truth, utilising an unsupervised learning technique.
Spacecraft inertial parameters estimation using time series clustering and reinforcement learning
Aug 06, 2024This paper presents a machine learning approach to estimate the inertial parameters of a spacecraft in cases when those change during operations, e.g. multiple deployments of payloads, unfolding of appendages and booms, propellant consumption as well as during in-orbit servicing and active debris removal operations. The machine learning approach uses time series clustering together with an optimised actuation sequence generated by reinforcement learning to facilitate distinguishing among different inertial parameter sets. The performance of the proposed strategy is assessed against the case of a multi-satellite deployment system showing that the algorithm is resilient towards common disturbances in such kinds of operations.
Wind Estimation in Unmanned Aerial Vehicles with Causal Machine Learning
Jul 01, 2024



In this work we demonstrate the possibility of estimating the wind environment of a UAV without specialised sensors, using only the UAV's trajectory, applying a causal machine learning approach. We implement the causal curiosity method which combines machine learning times series classification and clustering with a causal framework. We analyse three distinct wind environments: constant wind, shear wind, and turbulence, and explore different optimisation strategies for optimal UAV manoeuvres to estimate the wind conditions. The proposed approach can be used to design optimal trajectories in challenging weather conditions, and to avoid specialised sensors that add to the UAV's weight and compromise its functionality.
SyROCCo: Enhancing Systematic Reviews using Machine Learning
Jun 24, 2024



The sheer number of research outputs published every year makes systematic reviewing increasingly time- and resource-intensive. This paper explores the use of machine learning techniques to help navigate the systematic review process. ML has previously been used to reliably 'screen' articles for review - that is, identify relevant articles based on reviewers' inclusion criteria. The application of ML techniques to subsequent stages of a review, however, such as data extraction and evidence mapping, is in its infancy. We therefore set out to develop a series of tools that would assist in the profiling and analysis of 1,952 publications on the theme of 'outcomes-based contracting'. Tools were developed for the following tasks: assign publications into 'policy area' categories; identify and extract key information for evidence mapping, such as organisations, laws, and geographical information; connect the evidence base to an existing dataset on the same topic; and identify subgroups of articles that may share thematic content. An interactive tool using these techniques and a public dataset with their outputs have been released. Our results demonstrate the utility of ML techniques to enhance evidence accessibility and analysis within the systematic review processes. These efforts show promise in potentially yielding substantial efficiencies for future systematic reviewing and for broadening their analytical scope. Our work suggests that there may be implications for the ease with which policymakers and practitioners can access evidence. While ML techniques seem poised to play a significant role in bridging the gap between research and policy by offering innovative ways of gathering, accessing, and analysing data from systematic reviews, we also highlight their current limitations and the need to exercise caution in their application, particularly given the potential for errors and biases.
PANACEA: An Automated Misinformation Detection System on COVID-19
Feb 28, 2023In this demo, we introduce a web-based misinformation detection system PANACEA on COVID-19 related claims, which has two modules, fact-checking and rumour detection. Our fact-checking module, which is supported by novel natural language inference methods with a self-attention network, outperforms state-of-the-art approaches. It is also able to give automated veracity assessment and ranked supporting evidence with the stance towards the claim to be checked. In addition, PANACEA adapts the bi-directional graph convolutional networks model, which is able to detect rumours based on comment networks of related tweets, instead of relying on the knowledge base. This rumour detection module assists by warning the users in the early stages when a knowledge base may not be available.