 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GraDIRN: Learning Iterative Gradient Descent-based Energy Minimization for Deformable Image Registration
Dec 07, 2021
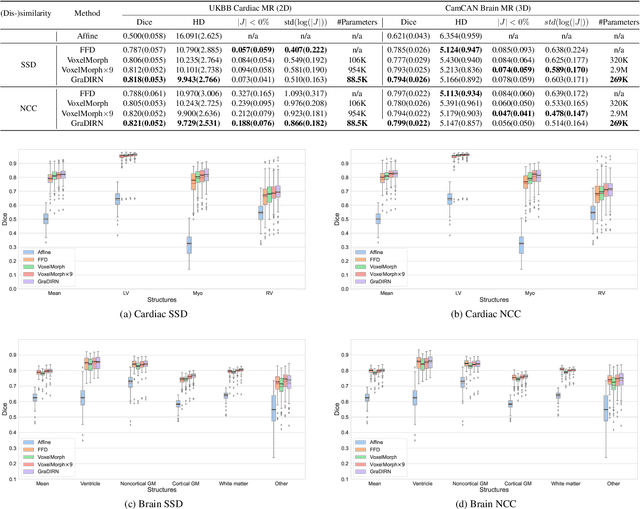
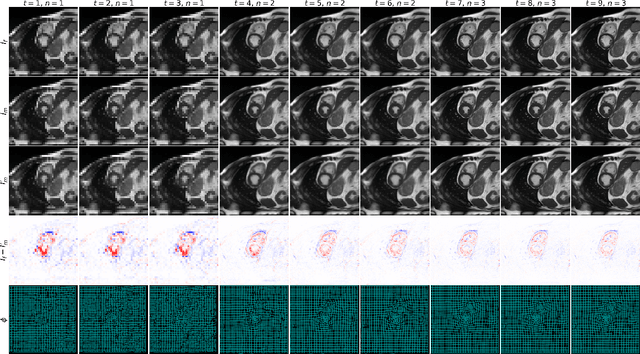
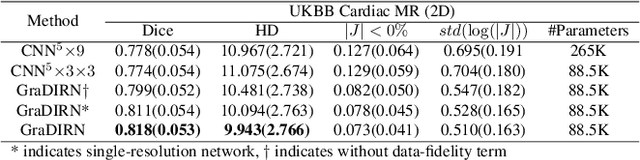
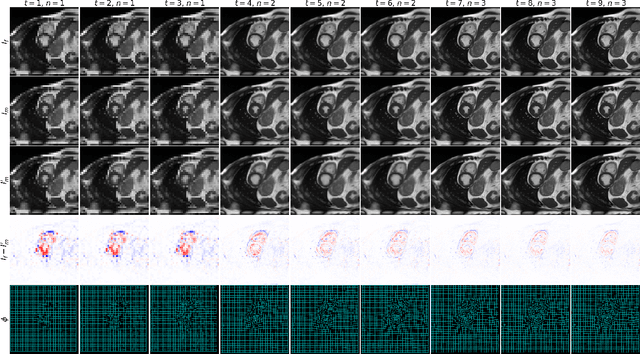
We present a Gradient Descent-based Image Registration Network (GraDIRN) for learning deformable image registration by embedding gradient-based iterative energy minimization in a deep learning framework. Traditional image registration algorithms typically use iterative energy-minimization optimization to find the optimal transformation between a pair of images, which is time-consuming when many iterations are needed. In contrast, recent learning-based methods amortize this costly iterative optimization by training deep neural networks so that registration of one pair of images can be achieved by fast network forward pass after training. Motivated by successes in image reconstruction techniques that combine deep learning with the mathematical structure of iterative variational energy optimization, we formulate a novel registration network based on multi-resolution gradient descent energy minimization. The forward pass of the network takes explicit image dissimilarity gradient steps and generalized regularization steps parameterized by Convolutional Neural Networks (CNN) for a fixed number of iterations. We use auto-differentiation to derive the forward computational graph for the explicit image dissimilarity gradient w.r.t. the transformation, so arbitrary image dissimilarity metrics and transformation models can be used without complex and error-prone gradient derivations. We demonstrate that this approach achieves state-of-the-art registration performance while using fewer learnable parameters through extensive evaluations on registration tasks using 2D cardiac MR images and 3D brain MR images.
Smart Fashion: A Review of AI Applications in the Fashion & Apparel Industry
Nov 02, 2021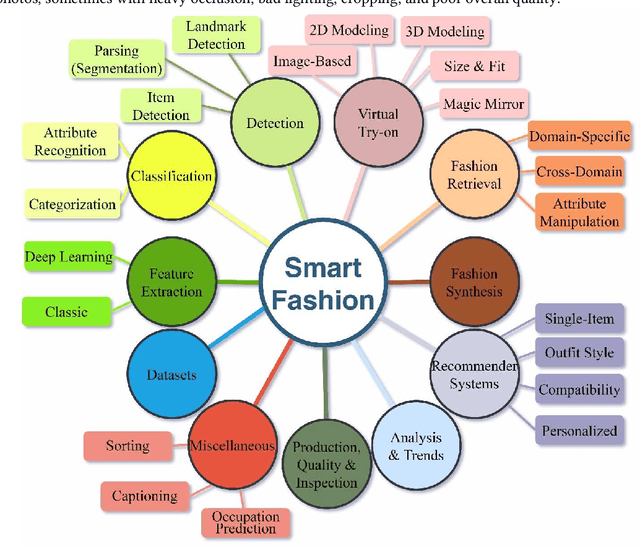
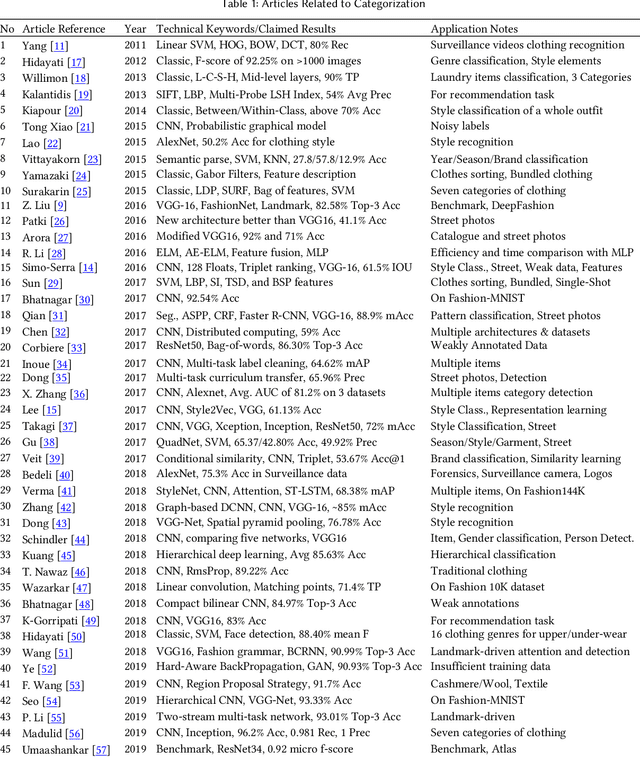

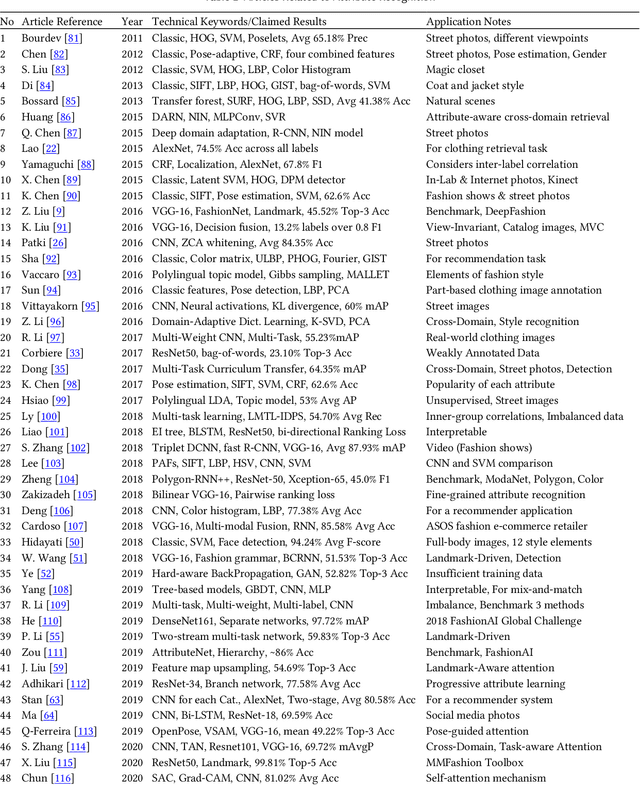
The fashion industry is on the verge of an unprecedented change. The implementation of machine learning, computer vision, and artificial intelligence (AI) in fashion applications is opening lots of new opportunities for this industry. This paper provides a comprehensive survey on this matter, categorizing more than 580 related articles into 22 well-defined fashion-related tasks. Such structured task-based multi-label classification of fashion research articles provides researchers with explicit research directions and facilitates their access to the related studies, improving the visibility of studies simultaneously. For each task, a time chart is provided to analyze the progress through the years. Furthermore, we provide a list of 86 public fashion datasets accompanied by a list of suggested applications and additional information for each.
Self-encoding Barnacle Mating Optimizer Algorithm for Manpower Scheduling in Flow Shop
Nov 16, 2021
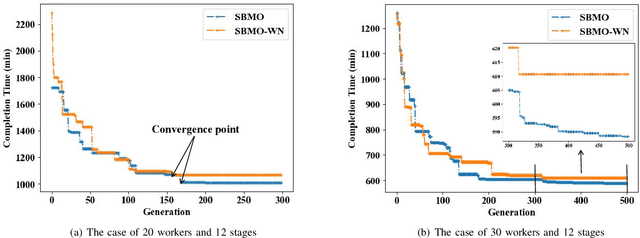
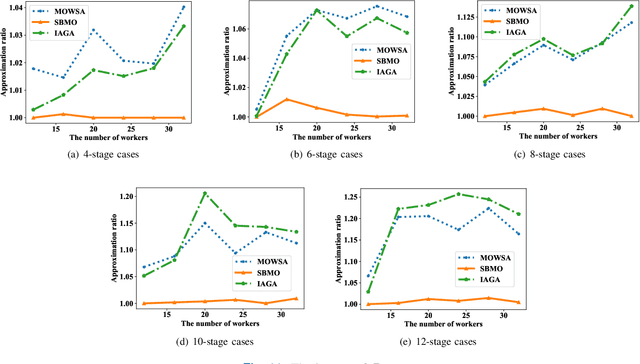
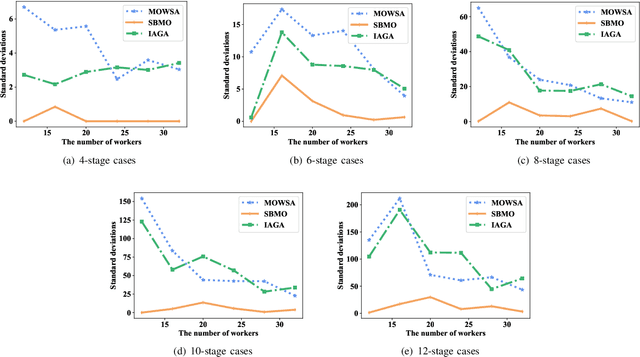
Flow Shop Scheduling (FSS) has been widely researched due to its application in many types of fields, while the human participant brings great challenges to this problem. Manpower scheduling captures attention for assigning workers with diverse proficiency to the appropriate stages, which is of great significance to production efficiency. In this paper, we present a novel algorithm called Self-encoding Barnacle Mating Optimizer (SBMO), which solves the FSS problem considering worker proficiency, defined as a new problem, Flow Shop Manpower Scheduling Problem (FSMSP). The highlight of the SBMO algorithm is the combination with the encoding method, crossover and mutation operators. Moreover, in order to solve the local optimum problem, we design a neighborhood search scheme. Finally, the extensive comparison simulations are conducted to demonstrate the superiority of the proposed SBMO. The results indicate the effectiveness of SBMO in approximate ratio, powerful stability, and execution time, compared with the classic and popular counterparts.
Reconfigurable Low-latency Memory System for Sparse Matricized Tensor Times Khatri-Rao Product on FPGA
Sep 18, 2021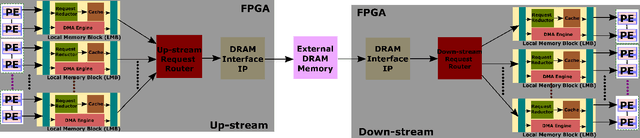
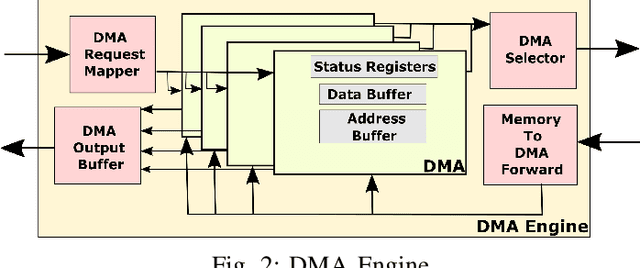
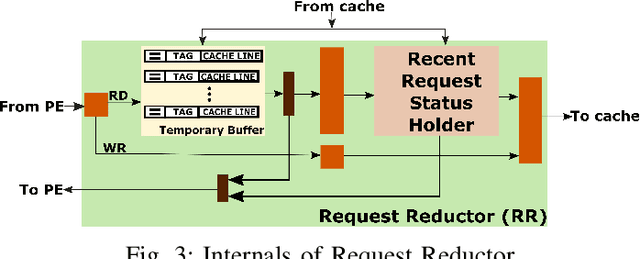
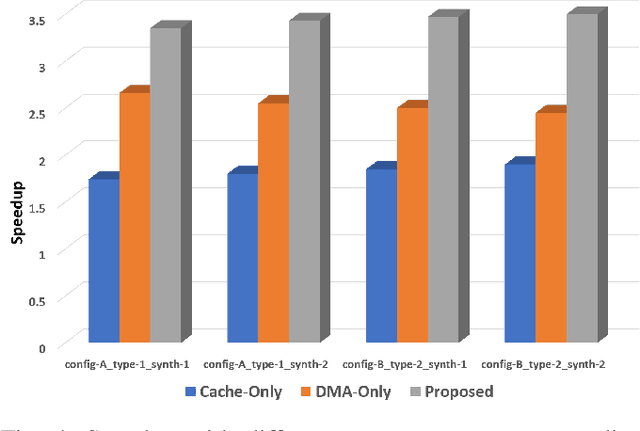
Tensor decomposition has become an essential tool in many applications in various domains, including machine learning. Sparse Matricized Tensor Times Khatri-Rao Product (MTTKRP) is one of the most computationally expensive kernels in tensor computations. Despite having significant computational parallelism, MTTKRP is a challenging kernel to optimize due to its irregular memory access characteristics. This paper focuses on a multi-faceted memory system, which explores the spatial and temporal locality of the data structures of MTTKRP. Further, users can reconfigure our design depending on the behavior of the compute units used in the FPGA accelerator. Our system efficiently accesses all the MTTKRP data structures while reducing the total memory access time, using a distributed cache and Direct Memory Access (DMA) subsystem. Moreover, our work improves the memory access time by 3.5x compared with commercial memory controller IPs. Also, our system shows 2x and 1.26x speedups compared with cache-only and DMA-only memory systems, respectively.
How to Query An Oracle? Efficient Strategies to Label Data
Oct 05, 2021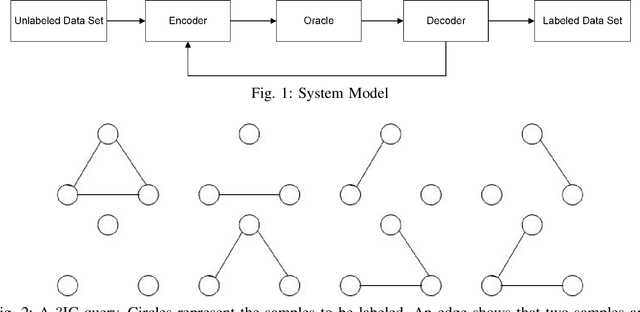
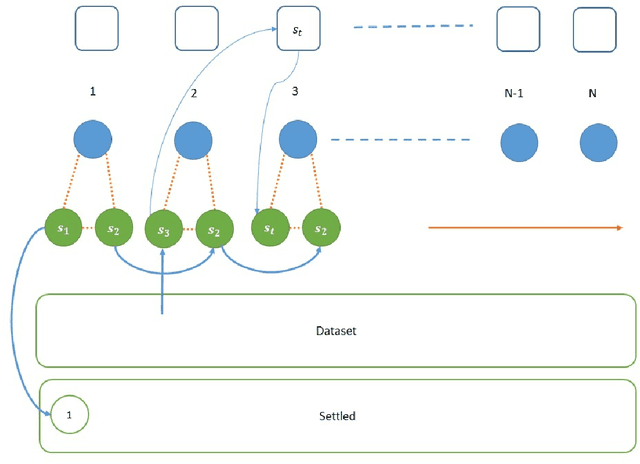
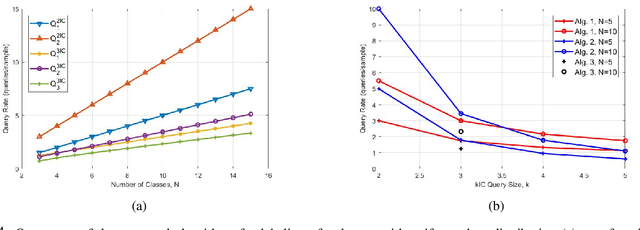
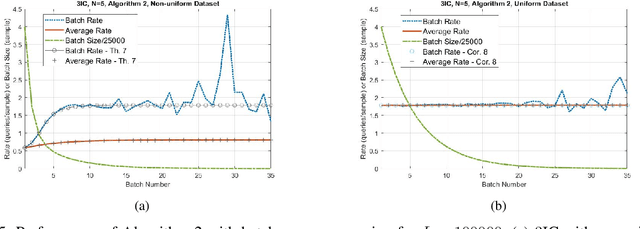
We consider the basic problem of querying an expert oracle for labeling a dataset in machine learning. This is typically an expensive and time consuming process and therefore, we seek ways to do so efficiently. The conventional approach involves comparing each sample with (the representative of) each class to find a match. In a setting with $N$ equally likely classes, this involves $N/2$ pairwise comparisons (queries per sample) on average. We consider a $k$-ary query scheme with $k\ge 2$ samples in a query that identifies (dis)similar items in the set while effectively exploiting the associated transitive relations. We present a randomized batch algorithm that operates on a round-by-round basis to label the samples and achieves a query rate of $O(\frac{N}{k^2})$. In addition, we present an adaptive greedy query scheme, which achieves an average rate of $\approx 0.2N$ queries per sample with triplet queries. For the proposed algorithms, we investigate the query rate performance analytically and with simulations. Empirical studies suggest that each triplet query takes an expert at most 50\% more time compared with a pairwise query, indicating the effectiveness of the proposed $k$-ary query schemes. We generalize the analyses to nonuniform class distributions when possible.
Fast query-by-example speech search using separable model
Sep 18, 2021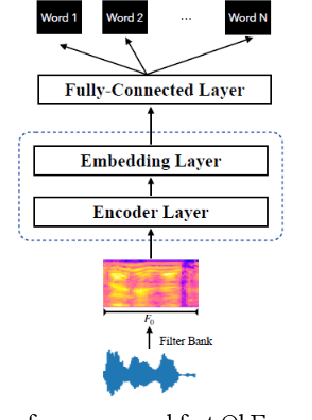
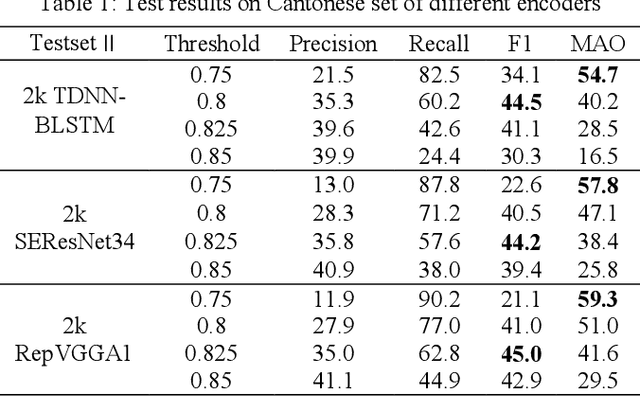
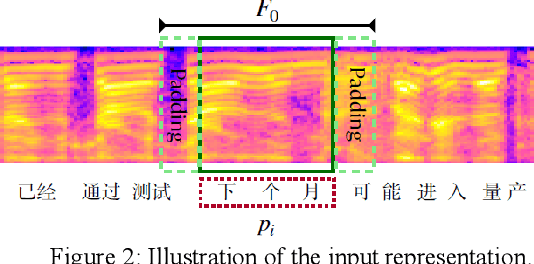
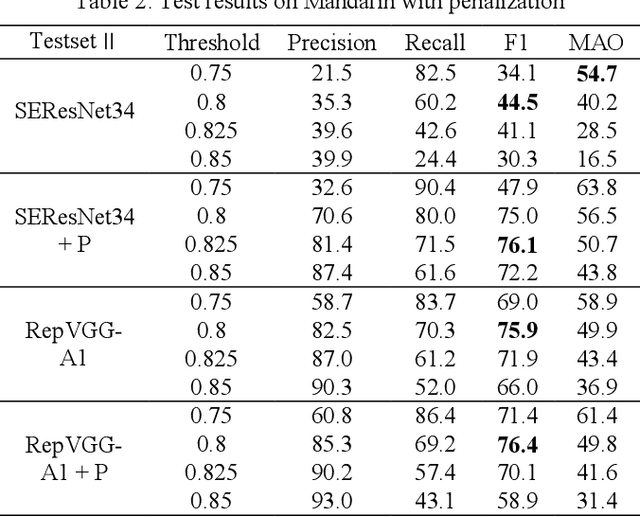
Traditional Query-by-Example (QbE) speech search approaches usually use methods based on frame-level features, while state-of-the-art approaches tend to use models based on acoustic word embeddings (AWEs) to transform variable length audio signals into fixed length feature vector representations. However, these approaches cannot meet the requirements of the search quality as well as speed at the same time. In this paper, we propose a novel fast QbE speech search method based on separable models to fix this problem. First, a QbE speech search training framework is introduced. Second, we design a novel model inference scheme based on RepVGG which can efficiently improve the QbE search quality. Third, we modify and improve our QbE speech search model according to the proposed model inference scheme. Experiments on keywords dataset shows that our proposed method can improve the GPU Real-time Factor (RTF) from 1/150 to 1/2300 by just applying separable model scheme and outperforms other state-of-the-art methods.
Optimal No-Regret Learning in General Games: Bounded Regret with Unbounded Step-Sizes via Clairvoyant MWU
Dec 19, 2021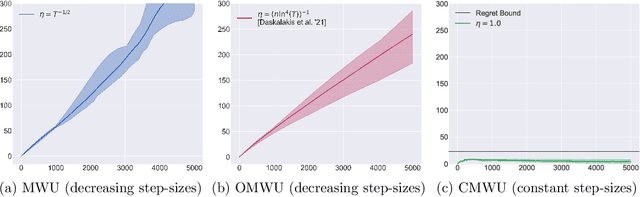
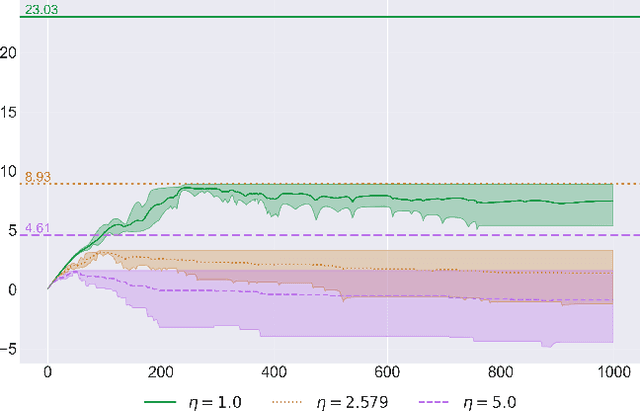
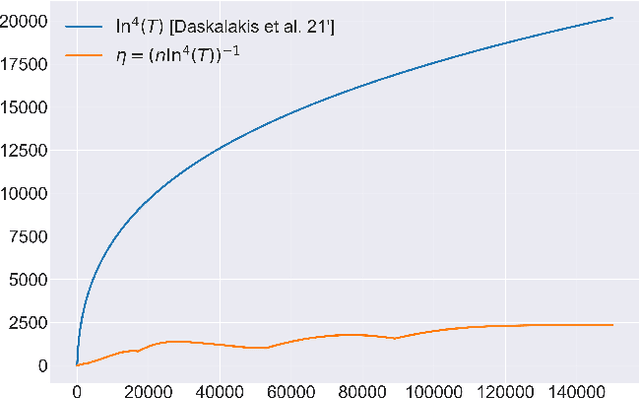
In this paper we solve the problem of no-regret learning in general games. Specifically, we provide a simple and practical algorithm that achieves constant regret with fixed step-sizes. The cumulative regret of our algorithm provably decreases linearly as the step-size increases. Our findings depart from the prevailing paradigm that vanishing step-sizes are a prerequisite for low regret as championed by all state-of-the-art methods to date. We shift away from this paradigm by defining a novel algorithm that we call Clairvoyant Multiplicative Weights Updates (CMWU). CMWU is Multiplicative Weights Updates (MWU) equipped with a mental model (jointly shared across all agents) about the state of the system in its next period. Each agent records its mixed strategy, i.e., its belief about what it expects to play in the next period, in this shared mental model which is internally updated using MWU without any changes to the real-world behavior up until it equilibrates, thus marking its consistency with the next day's real-world outcome. It is then and only then that agents take action in the real-world, effectively doing so with the "full knowledge" of the state of the system on the next day, i.e., they are clairvoyant. CMWU effectively acts as MWU with one day look-ahead, achieving bounded regret. At a technical level, we establish that self-consistent mental models exist for any choice of step-sizes and provide bounds on the step-size under which their uniqueness and linear-time computation are guaranteed via contraction mapping arguments. Our arguments extend well beyond normal-form games with little effort.
Enabling Automated FPGA Accelerator Optimization Using Graph Neural Networks
Nov 22, 2021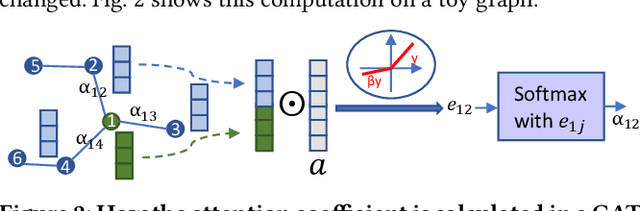

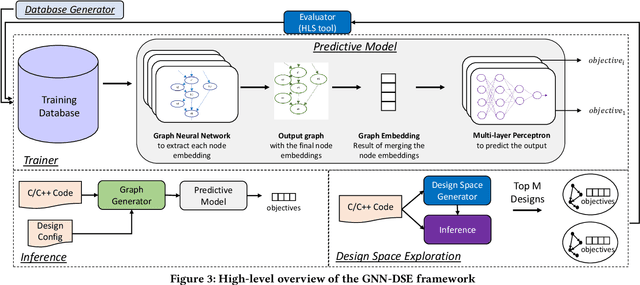

High-level synthesis (HLS) has freed the computer architects from developing their designs in a very low-level language and needing to exactly specify how the data should be transferred in register-level. With the help of HLS, the hardware designers must describe only a high-level behavioral flow of the design. Despite this, it still can take weeks to develop a high-performance architecture mainly because there are many design choices at a higher level that requires more time to explore. It also takes several minutes to hours to get feedback from the HLS tool on the quality of each design candidate. In this paper, we propose to solve this problem by modeling the HLS tool with a graph neural network (GNN) that is trained to be used for a wide range of applications. The experimental results demonstrate that by employing the GNN-based model, we are able to estimate the quality of design in milliseconds with high accuracy which can help us search through the solution space very quickly.
Hidden Markov Nonlinear ICA: Unsupervised Learning from Nonstationary Time Series
Jun 22, 2020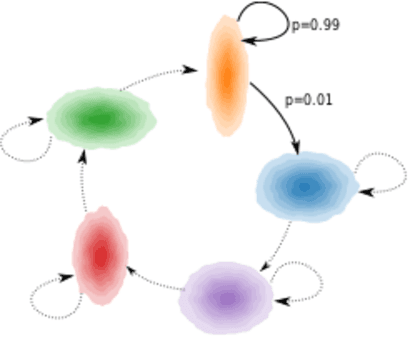
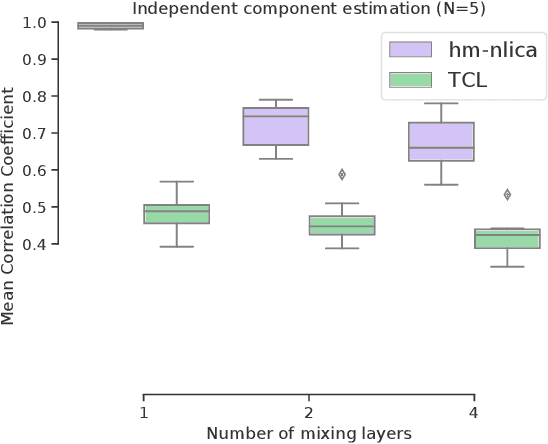
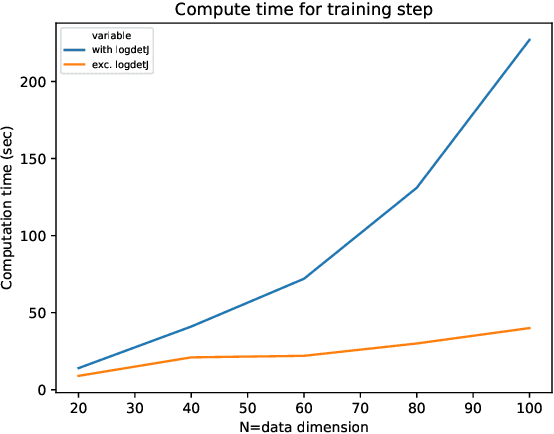
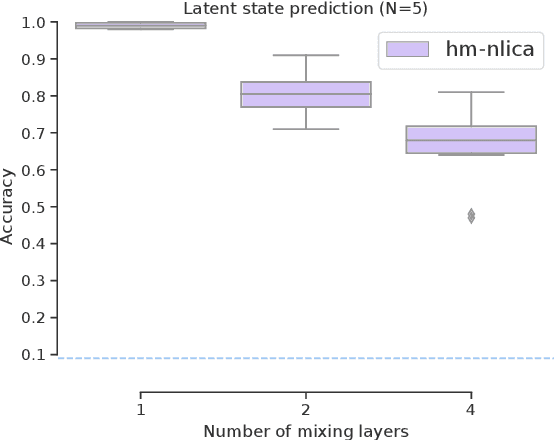
Recent advances in nonlinear Independent Component Analysis (ICA) provide a principled framework for unsupervised feature learning and disentanglement. The central idea in such works is that the latent components are assumed to be independent conditional on some observed auxiliary variables, such as the time-segment index. This requires manual segmentation of data into non-stationary segments which is computationally expensive, inaccurate and often impossible. These models are thus not fully unsupervised. We remedy these limitations by combining nonlinear ICA with a Hidden Markov Model, resulting in a model where a latent state acts in place of the observed segment-index. We prove identifiability of the proposed model for a general mixing nonlinearity, such as a neural network. We also show how maximum likelihood estimation of the model can be done using the expectation-maximization algorithm. Thus, we achieve a new nonlinear ICA framework which is unsupervised, more efficient, as well as able to model underlying temporal dynamics.
Beyond Pointwise Submodularity: Non-Monotone Adaptive Submodular Maximization in Linear Time
Aug 14, 2020In this paper, we study the non-monotone adaptive submodular maximization problem subject to a cardinality constraint. We first revisit the adaptive random greedy algorithm proposed in \citep{gotovos2015non}, where they show that this algorithm achieves a $1/e$ approximation ratio if the objective function is adaptive submodular and pointwise submodular. It is not clear whether the same guarantee holds under adaptive submodularity (without resorting to pointwise submodularity) or not. Our first contribution is to show that the adaptive random greedy algorithm achieves a $1/e$ approximation ratio under adaptive submodularity. One limitation of the adaptive random greedy algorithm is that it requires $O(n\times k)$ value oracle queries, where $n$ is the size of the ground set and $k$ is the cardinality constraint. Our second contribution is to develop the first linear-time algorithm for the non-monotone adaptive submodular maximization problem. Our algorithm achieves a $1/e-\epsilon$ approximation ratio (this bound is improved to $1-1/e-\epsilon$ for monotone case), using only $O(n\epsilon^{-2}\log \epsilon^{-1})$ value oracle queries. Notably, $O(n\epsilon^{-2}\log \epsilon^{-1})$ is independent of the cardinality constraint.