 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Vision Transformer based COVID-19 Detection using Chest X-rays
Oct 09, 2021
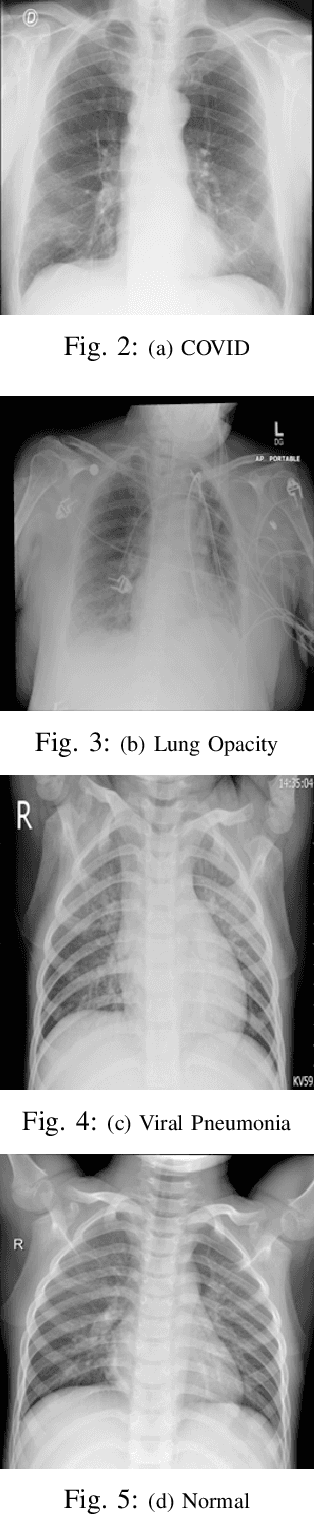
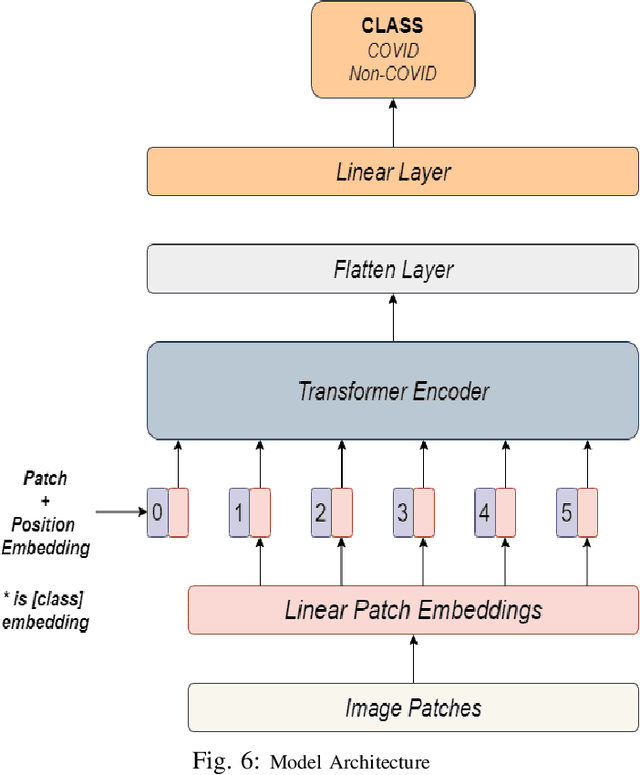
COVID-19 is a global pandemic, and detecting them is a momentous task for medical professionals today due to its rapid mutations. Current methods of examining chest X-rays and CT scan requires profound knowledge and are time consuming, which suggests that it shrinks the precious time of medical practitioners when people's lives are at stake. This study tries to assist this process by achieving state-of-the-art performance in classifying chest X-rays by fine-tuning Vision Transformer(ViT). The proposed approach uses pretrained models, fine-tuned for detecting the presence of COVID-19 disease on chest X-rays. This approach achieves an accuracy score of 97.61%, precision score of 95.34%, recall score of 93.84% and, f1-score of 94.58%. This result signifies the performance of transformer-based models on chest X-ray.
Generating Fluent Fact Checking Explanations with Unsupervised Post-Editing
Dec 13, 2021
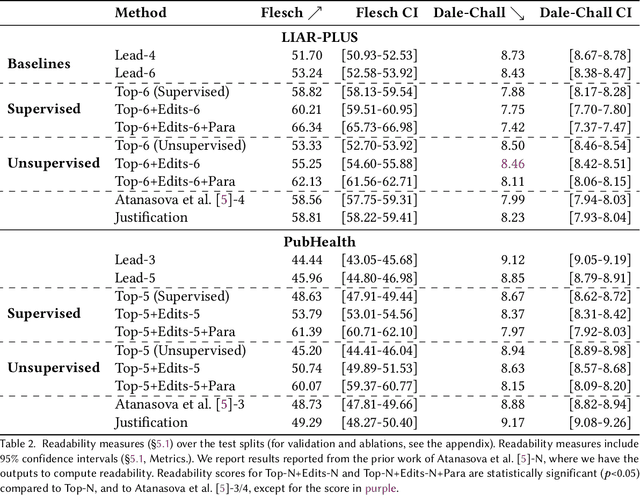
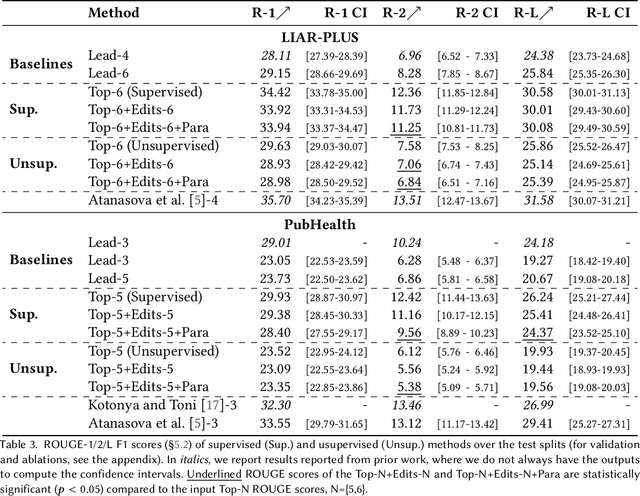
Fact-checking systems have become important tools to verify fake and misguiding news. These systems become more trustworthy when human-readable explanations accompany the veracity labels. However, manual collection of such explanations is expensive and time-consuming. Recent works frame explanation generation as extractive summarization, and propose to automatically select a sufficient subset of the most important facts from the ruling comments (RCs) of a professional journalist to obtain fact-checking explanations. However, these explanations lack fluency and sentence coherence. In this work, we present an iterative edit-based algorithm that uses only phrase-level edits to perform unsupervised post-editing of disconnected RCs. To regulate our editing algorithm, we use a scoring function with components including fluency and semantic preservation. In addition, we show the applicability of our approach in a completely unsupervised setting. We experiment with two benchmark datasets, LIAR-PLUS and PubHealth. We show that our model generates explanations that are fluent, readable, non-redundant, and cover important information for the fact check.
Optimal Rate Adaption in Federated Learning with Compressed Communications
Dec 13, 2021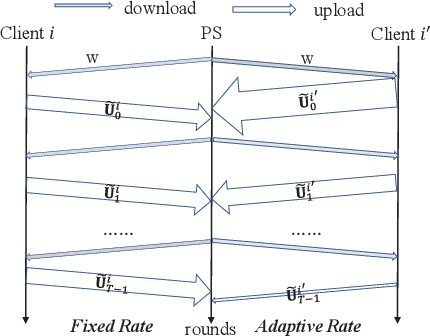
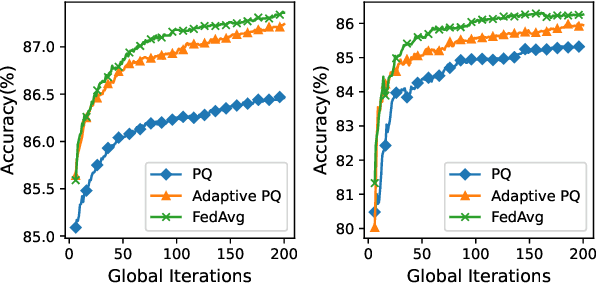
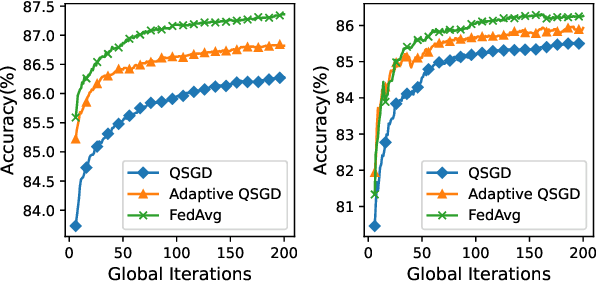
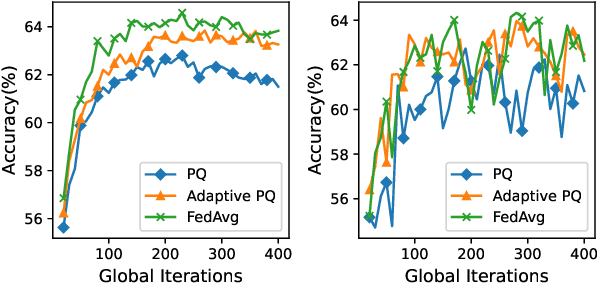
Federated Learning (FL) incurs high communication overhead, which can be greatly alleviated by compression for model updates. Yet the tradeoff between compression and model accuracy in the networked environment remains unclear and, for simplicity, most implementations adopt a fixed compression rate only. In this paper, we for the first time systematically examine this tradeoff, identifying the influence of the compression error on the final model accuracy with respect to the learning rate. Specifically, we factor the compression error of each global iteration into the convergence rate analysis under both strongly convex and non-convex loss functions. We then present an adaptation framework to maximize the final model accuracy by strategically adjusting the compression rate in each iteration. We have discussed the key implementation issues of our framework in practical networks with representative compression algorithms. Experiments over the popular MNIST and CIFAR-10 datasets confirm that our solution effectively reduces network traffic yet maintains high model accuracy in FL.
SP-SEDT: Self-supervised Pre-training for Sound Event Detection Transformer
Nov 30, 2021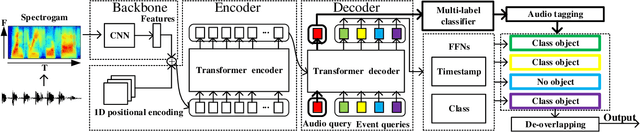
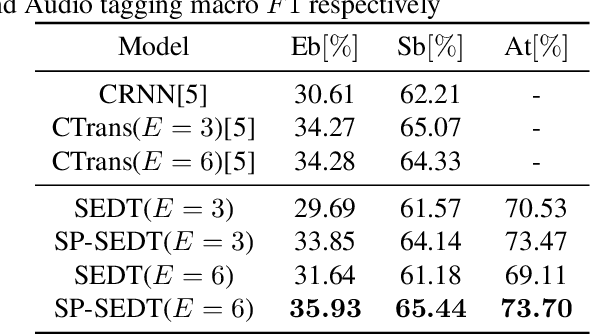
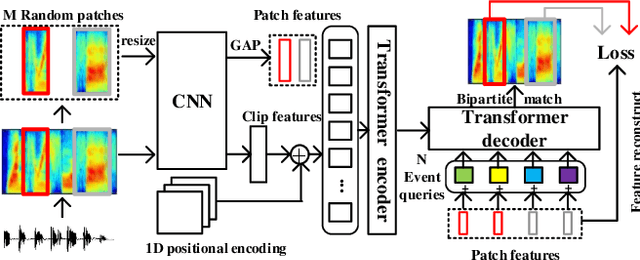
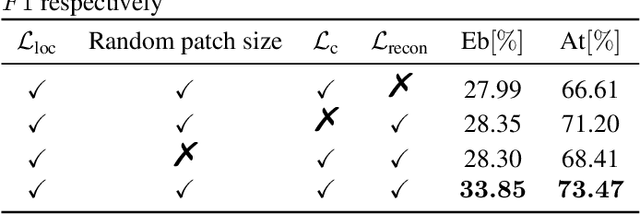
Recently, an event-based end-to-end model (SEDT) has been proposed for sound event detection (SED) and achieves competitive performance. However, compared with the frame-based model, it requires more training data with temporal annotations to improve the localization ability. Synthetic data is an alternative, but it suffers from a great domain gap with real recordings. Inspired by the great success of UP-DETR in object detection, we propose to self-supervisedly pre-train SEDT (SP-SEDT) by detecting random patches (only cropped along the time axis). Experiments on the DCASE2019 task4 dataset show the proposed SP-SEDT can outperform fine-tuned frame-based model. The ablation study is also conducted to investigate the impact of different loss functions and patch size.
Predictive Analysis of COVID-19 Time-series Data from Johns Hopkins University
May 22, 2020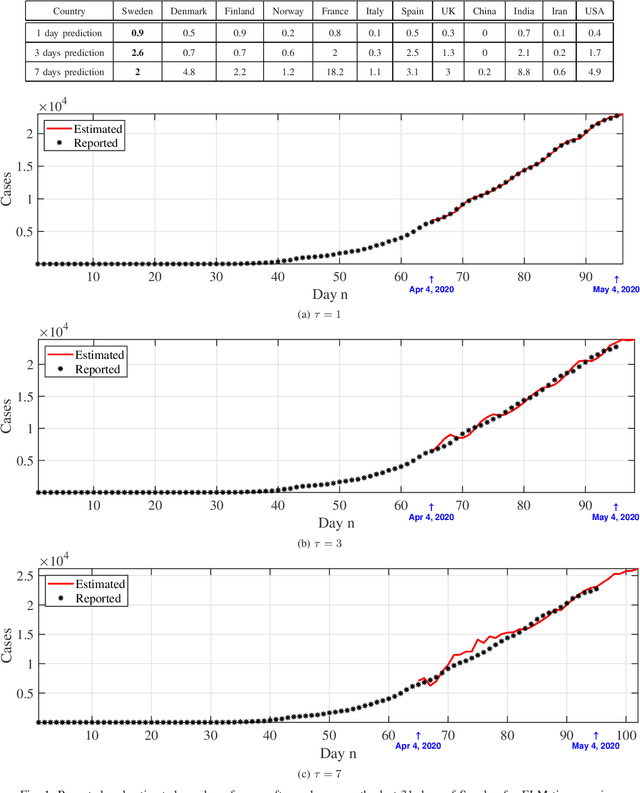
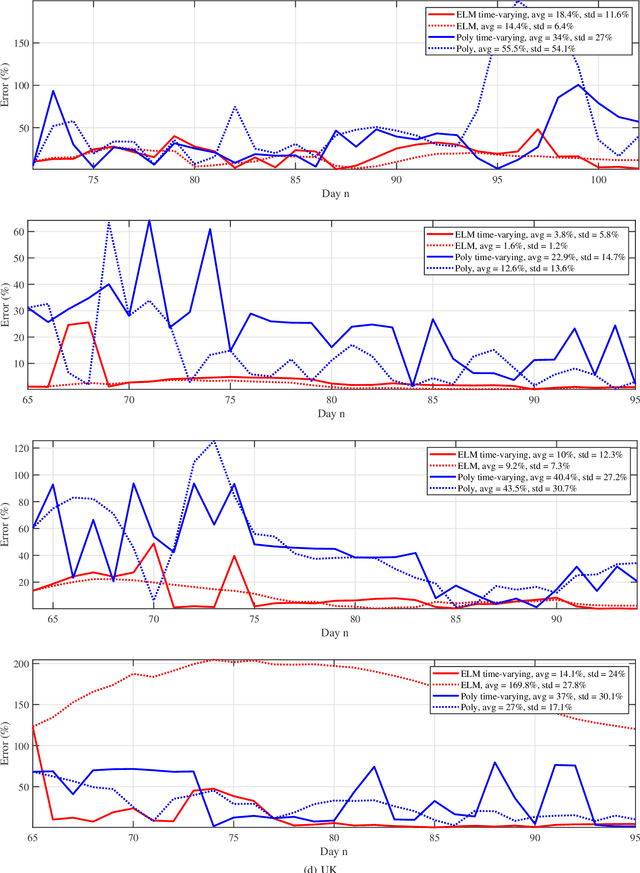
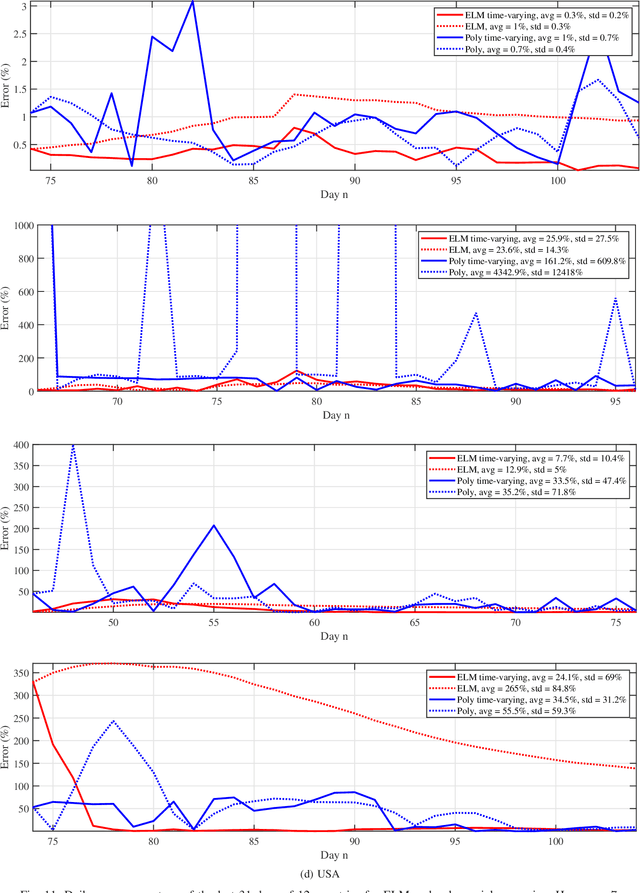
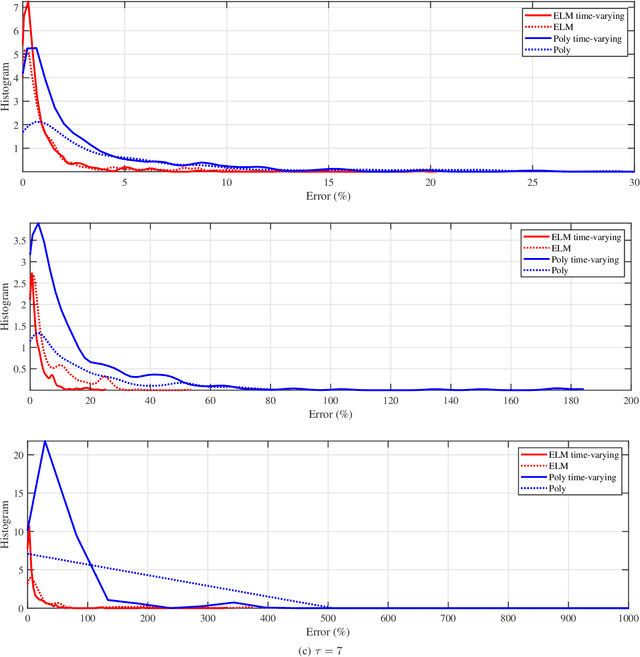
We provide a predictive analysis of the spread of COVID-19, also known as SARS-CoV-2, using the dataset made publicly available online by the Johns Hopkins University. Our main objective is to provide predictions of the number of infected people for different countries in the next 14 days. The predictive analysis is done using time-series data transformed on a logarithmic scale. We use two well-known methods for prediction: polynomial regression and neural network. As the number of training data for each country is limited, we use a single-layer neural network called the extreme learning machine (ELM) to avoid over-fitting. Due to the non-stationary nature of the time-series, a sliding window approach is used to provide a more accurate prediction.
Smart obervation method with wide field small aperture telescopes for real time transient detection
Nov 20, 2020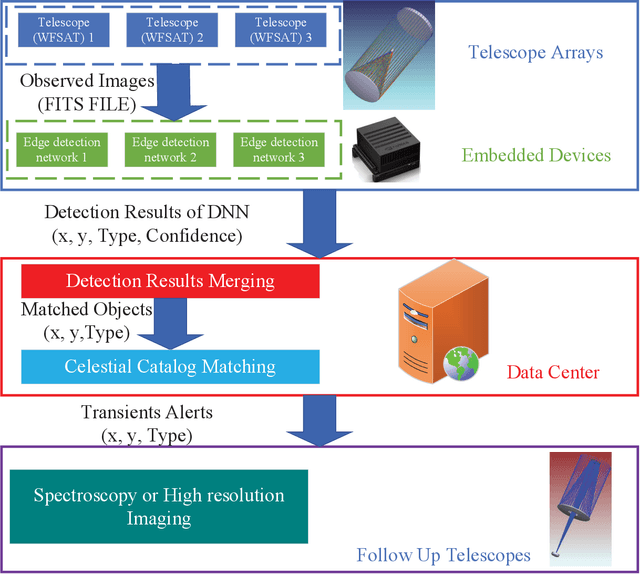
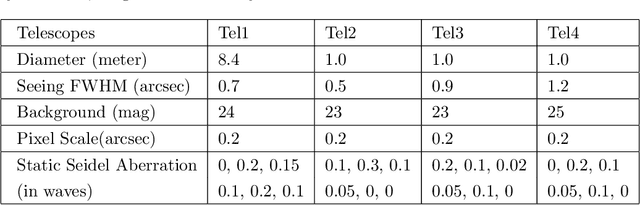


Wide field small aperture telescopes (WFSATs) are commonly used for fast sky survey. Telescope arrays composed by several WFSATs are capable to scan sky several times per night. Huge amount of data would be obtained by them and these data need to be processed immediately. In this paper, we propose ARGUS (Astronomical taRGets detection framework for Unified telescopes) for real-time transit detection. The ARGUS uses a deep learning based astronomical detection algorithm implemented in embedded devices in each WFSATs to detect astronomical targets. The position and probability of a detection being an astronomical targets will be sent to a trained ensemble learning algorithm to output information of celestial sources. After matching these sources with star catalog, ARGUS will directly output type and positions of transient candidates. We use simulated data to test the performance of ARGUS and find that ARGUS can increase the performance of WFSATs in transient detection tasks robustly.
Convolutional Deep Exponential Families
Oct 27, 2021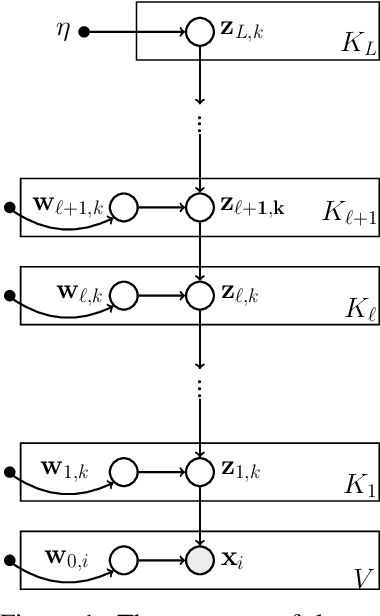
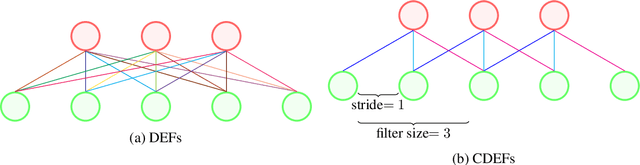

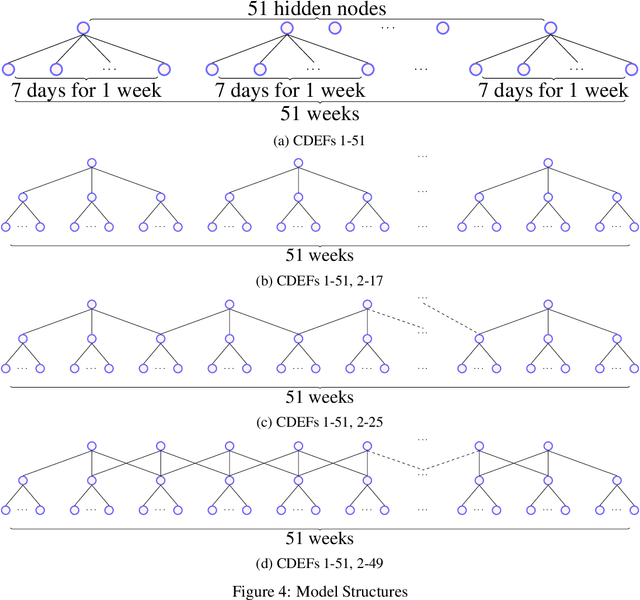
We describe convolutional deep exponential families (CDEFs) in this paper. CDEFs are built based on deep exponential families, deep probabilistic models that capture the hierarchical dependence between latent variables. CDEFs greatly reduce the number of free parameters by tying the weights of DEFs. Our experiments show that CDEFs are able to uncover time correlations with a small amount of data.
Quantifying Cognitive Factors in Lexical Decline
Oct 12, 2021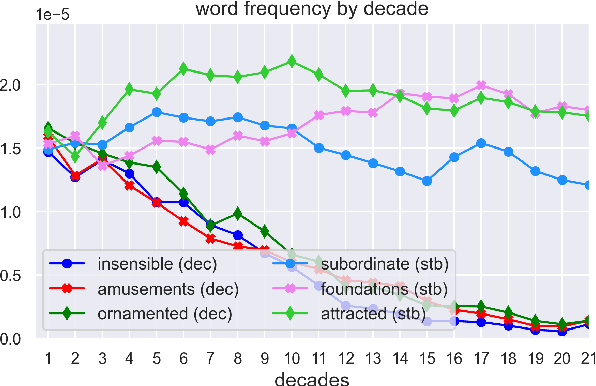
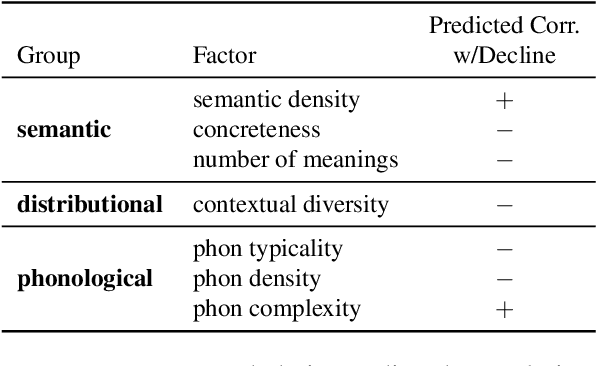
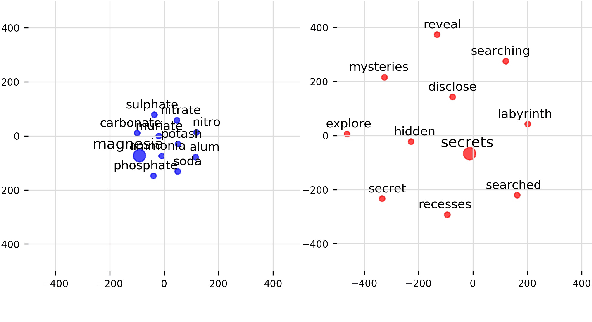
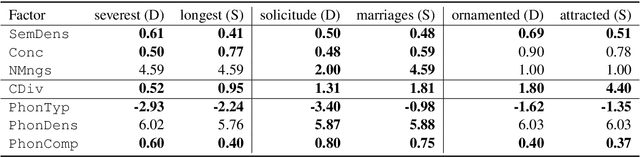
We adopt an evolutionary view on language change in which cognitive factors (in addition to social ones) affect the fitness of words and their success in the linguistic ecosystem. Specifically, we propose a variety of psycholinguistic factors -- semantic, distributional, and phonological -- that we hypothesize are predictive of lexical decline, in which words greatly decrease in frequency over time. Using historical data across three languages (English, French, and German), we find that most of our proposed factors show a significant difference in the expected direction between each curated set of declining words and their matched stable words. Moreover, logistic regression analyses show that semantic and distributional factors are significant in predicting declining words. Further diachronic analysis reveals that declining words tend to decrease in the diversity of their lexical contexts over time, gradually narrowing their 'ecological niches'.
A Study on Token Pruning for ColBERT
Dec 13, 2021
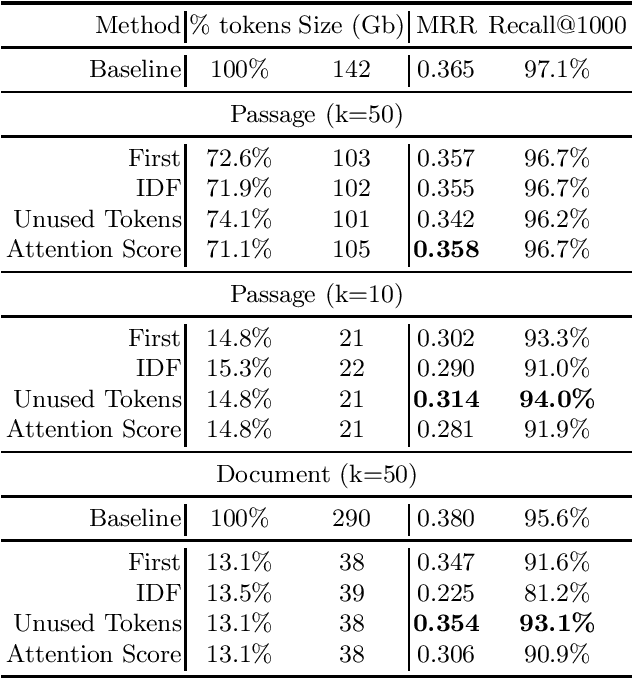
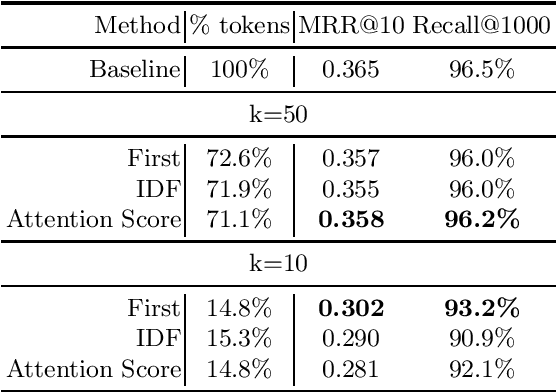
The ColBERT model has recently been proposed as an effective BERT based ranker. By adopting a late interaction mechanism, a major advantage of ColBERT is that document representations can be precomputed in advance. However, the big downside of the model is the index size, which scales linearly with the number of tokens in the collection. In this paper, we study various designs for ColBERT models in order to attack this problem. While compression techniques have been explored to reduce the index size, in this paper we study token pruning techniques for ColBERT. We compare simple heuristics, as well as a single layer of attention mechanism to select the tokens to keep at indexing time. Our experiments show that ColBERT indexes can be pruned up to 30\% on the MS MARCO passage collection without a significant drop in performance. Finally, we experiment on MS MARCO documents, which reveal several challenges for such mechanism.
VirtualCube: An Immersive 3D Video Communication System
Dec 29, 2021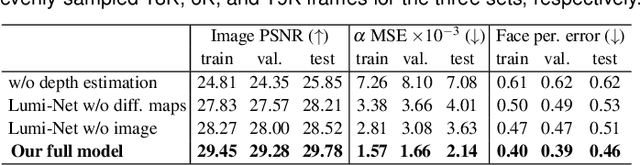
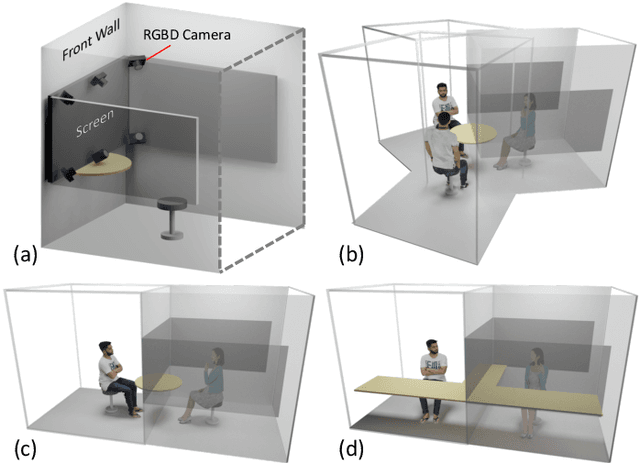

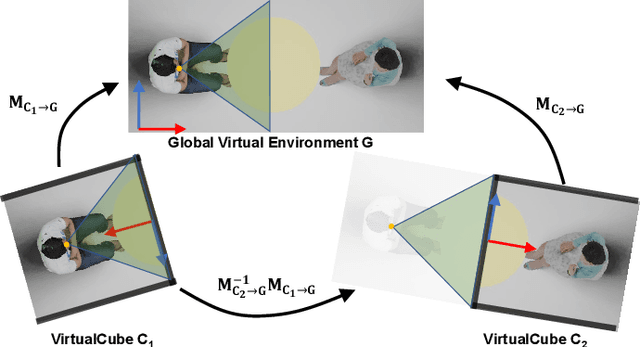
The VirtualCube system is a 3D video conference system that attempts to overcome some limitations of conventional technologies. The key ingredient is VirtualCube, an abstract representation of a real-world cubicle instrumented with RGBD cameras for capturing the 3D geometry and texture of a user. We design VirtualCube so that the task of data capturing is standardized and significantly simplified, and everything can be built using off-the-shelf hardware. We use VirtualCubes as the basic building blocks of a virtual conferencing environment, and we provide each VirtualCube user with a surrounding display showing life-size videos of remote participants. To achieve real-time rendering of remote participants, we develop the V-Cube View algorithm, which uses multi-view stereo for more accurate depth estimation and Lumi-Net rendering for better rendering quality. The VirtualCube system correctly preserves the mutual eye gaze between participants, allowing them to establish eye contact and be aware of who is visually paying attention to them. The system also allows a participant to have side discussions with remote participants as if they were in the same room. Finally, the system sheds lights on how to support the shared space of work items (e.g., documents and applications) and track the visual attention of participants to work items.