 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMFAAN: Unveiling Audio Deepfakes with a Multi-Feature Authenticity Network
Nov 06, 2023

In the contemporary digital age, the proliferation of deepfakes presents a formidable challenge to the sanctity of information dissemination. Audio deepfakes, in particular, can be deceptively realistic, posing significant risks in misinformation campaigns. To address this threat, we introduce the Multi-Feature Audio Authenticity Network (MFAAN), an advanced architecture tailored for the detection of fabricated audio content. MFAAN incorporates multiple parallel paths designed to harness the strengths of different audio representations, including Mel-frequency cepstral coefficients (MFCC), linear-frequency cepstral coefficients (LFCC), and Chroma Short Time Fourier Transform (Chroma-STFT). By synergistically fusing these features, MFAAN achieves a nuanced understanding of audio content, facilitating robust differentiation between genuine and manipulated recordings. Preliminary evaluations of MFAAN on two benchmark datasets, 'In-the-Wild' Audio Deepfake Data and The Fake-or-Real Dataset, demonstrate its superior performance, achieving accuracies of 98.93% and 94.47% respectively. Such results not only underscore the efficacy of MFAAN but also highlight its potential as a pivotal tool in the ongoing battle against deepfake audio content.
Automated Classification of Stroke Blood Clot Origin using Whole-Slide Digital Pathology Images
Apr 26, 2023The classification of the origin of blood clots is a crucial step in diagnosing and treating ischemic stroke. Various imaging techniques such as computed tomography (CT), magnetic resonance imaging (MRI), and ultrasound have been employed to detect and locate blood clots within the body. However, identifying the origin of a blood clot remains challenging due to the complexity of the blood flow dynamics and the limitations of the imaging techniques. The study suggests a novel methodology for classifying the source of a blood clot through the integration of data from whole-slide digital pathology images, which are utilized to fine-tune several cutting-edge computer vision models. Upon comparison, the SwinTransformerV2 model outperforms all the other models and achieves an accuracy score of 94.24%, precision score of 94.41%, recall score of 94.09%, and, f1-score of 94.06%. Our approach shows promising results in detecting the origin of blood clots in different vascular regions and can potentially improve the diagnosis and management of ischemic stroke.
Benchmarking Conventional Vision Models on Neuromorphic Fall Detection and Action Recognition Dataset
Jan 28, 2022
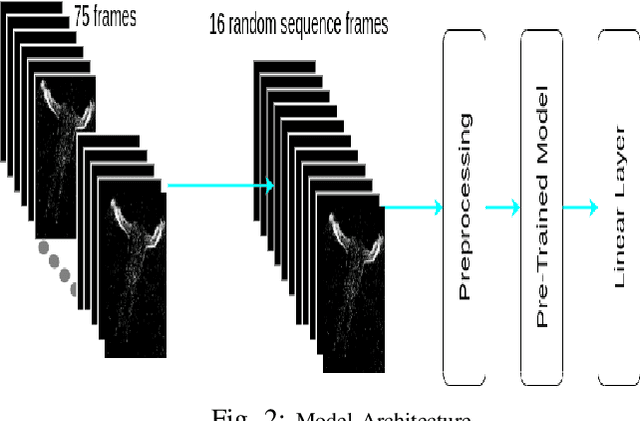
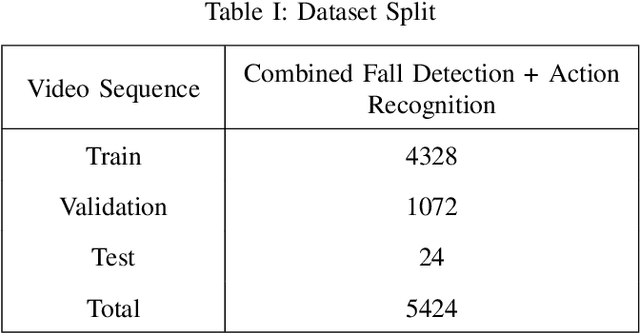
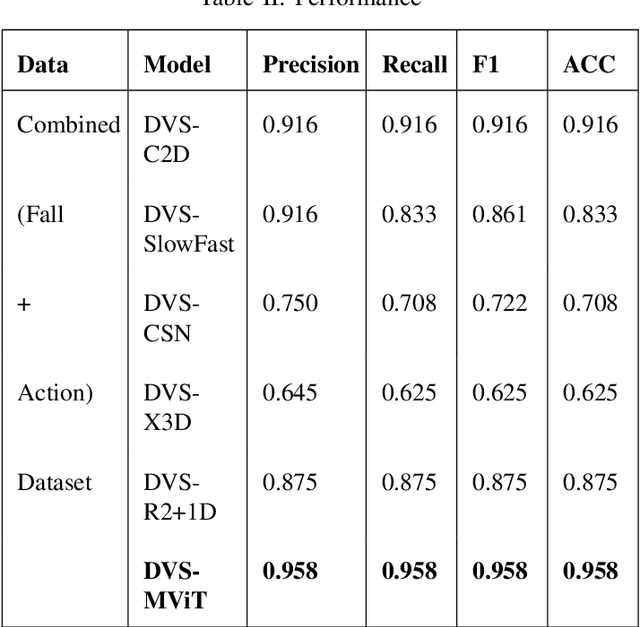
Neuromorphic vision-based sensors are gaining popularity in recent years with their ability to capture Spatio-temporal events with low power sensing. These sensors record events or spikes over traditional cameras which helps in preserving the privacy of the subject being recorded. These events are captured as per-pixel brightness changes and the output data stream is encoded with time, location, and pixel intensity change information. This paper proposes and benchmarks the performance of fine-tuned conventional vision models on neuromorphic human action recognition and fall detection datasets. The Spatio-temporal event streams from the Dynamic Vision Sensing cameras are encoded into a standard sequence image frames. These video frames are used for benchmarking conventional deep learning-based architectures. In this proposed approach, we fine-tuned the state-of-the-art vision models for this Dynamic Vision Sensing (DVS) application and named these models as DVS-R2+1D, DVS-CSN, DVS-C2D, DVS-SlowFast, DVS-X3D, and DVS-MViT. Upon comparing the performance of these models, we see the current state-of-the-art MViT based architecture DVS-MViT outperforms all the other models with an accuracy of 0.958 and an F-1 score of 0.958. The second best is the DVS-C2D with an accuracy of 0.916 and an F-1 score of 0.916. Third and Fourth are DVS-R2+1D and DVS-SlowFast with an accuracy of 0.875 and 0.833 and F-1 score of 0.875 and 0.861 respectively. DVS-CSN and DVS-X3D were the least performing models with an accuracy of 0.708 and 0.625 and an F1 score of 0.722 and 0.625 respectively.
SwiftSRGAN -- Rethinking Super-Resolution for Efficient and Real-time Inference
Nov 29, 2021
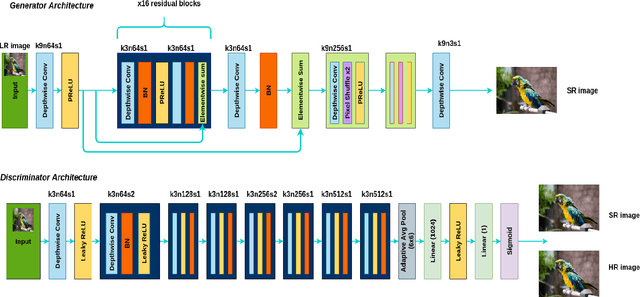


In recent years, there have been several advancements in the task of image super-resolution using the state of the art Deep Learning-based architectures. Many super-resolution-based techniques previously published, require high-end and top-of-the-line Graphics Processing Unit (GPUs) to perform image super-resolution. With the increasing advancements in Deep Learning approaches, neural networks have become more and more compute hungry. We took a step back and, focused on creating a real-time efficient solution. We present an architecture that is faster and smaller in terms of its memory footprint. The proposed architecture uses Depth-wise Separable Convolutions to extract features and, it performs on-par with other super-resolution GANs (Generative Adversarial Networks) while maintaining real-time inference and a low memory footprint. A real-time super-resolution enables streaming high resolution media content even under poor bandwidth conditions. While maintaining an efficient trade-off between the accuracy and latency, we are able to produce a comparable performance model which is one-eighth (1/8) the size of super-resolution GANs and computes 74 times faster than super-resolution GANs.
Vision Transformer based COVID-19 Detection using Chest X-rays
Oct 09, 2021
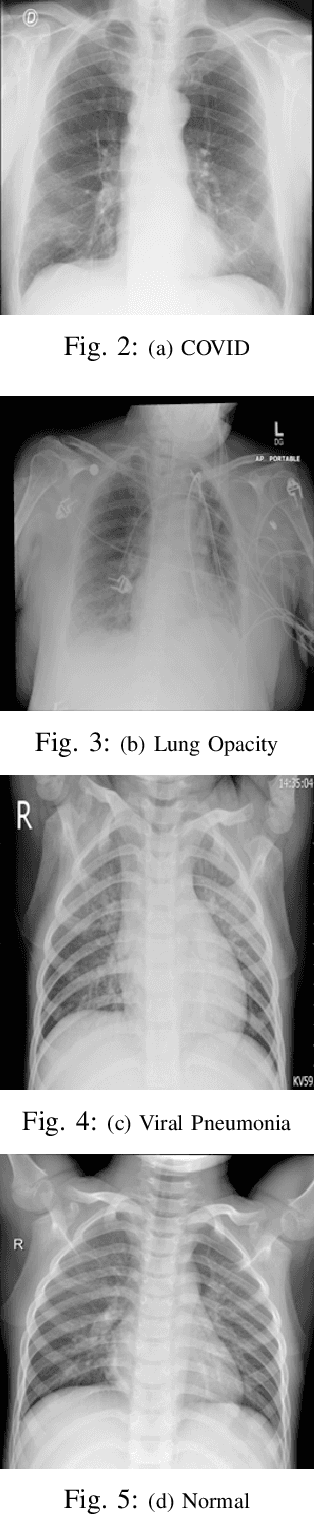
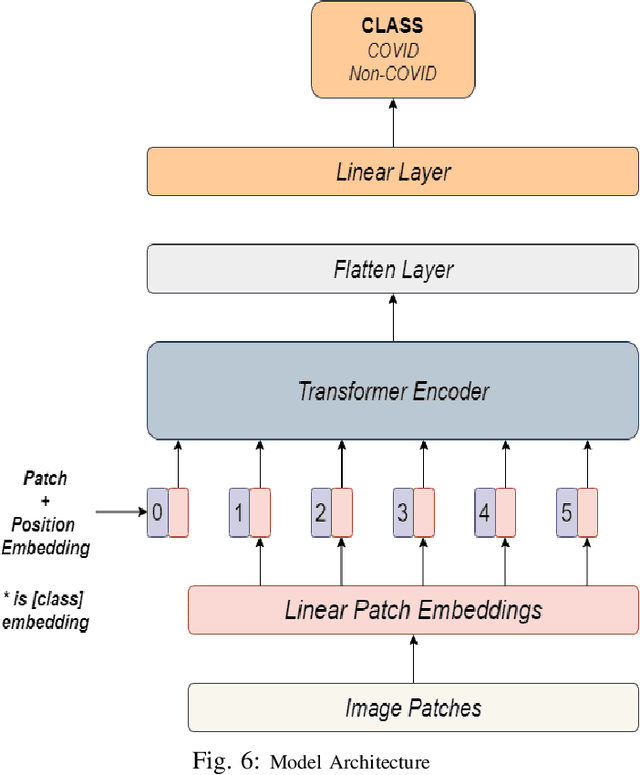
COVID-19 is a global pandemic, and detecting them is a momentous task for medical professionals today due to its rapid mutations. Current methods of examining chest X-rays and CT scan requires profound knowledge and are time consuming, which suggests that it shrinks the precious time of medical practitioners when people's lives are at stake. This study tries to assist this process by achieving state-of-the-art performance in classifying chest X-rays by fine-tuning Vision Transformer(ViT). The proposed approach uses pretrained models, fine-tuned for detecting the presence of COVID-19 disease on chest X-rays. This approach achieves an accuracy score of 97.61%, precision score of 95.34%, recall score of 93.84% and, f1-score of 94.58%. This result signifies the performance of transformer-based models on chest X-ray.