 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MoViDNN: A Mobile Platform for Evaluating Video Quality Enhancement with Deep Neural Networks
Jan 12, 2022
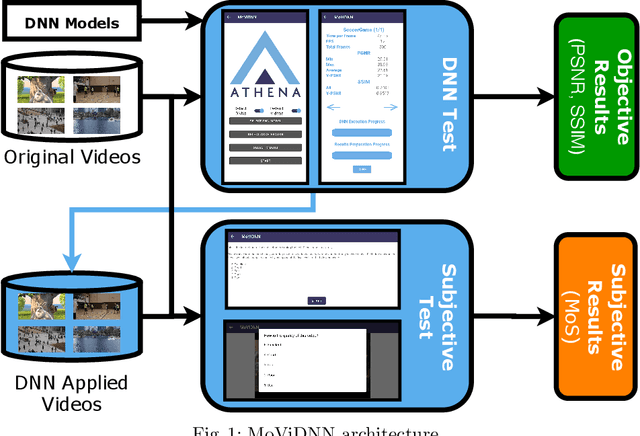


Deep neural network (DNN) based approaches have been intensively studied to improve video quality thanks to their fast advancement in recent years. These approaches are designed mainly for desktop devices due to their high computational cost. However, with the increasing performance of mobile devices in recent years, it became possible to execute DNN based approaches in mobile devices. Despite having the required computational power, utilizing DNNs to improve the video quality for mobile devices is still an active research area. In this paper, we propose an open-source mobile platform, namely MoViDNN, to evaluate DNN based video quality enhancement methods, such as super-resolution, denoising, and deblocking. Our proposed platform can be used to evaluate the DNN based approaches both objectively and subjectively. For objective evaluation, we report common metrics such as execution time, PSNR, and SSIM. For subjective evaluation, Mean Score Opinion (MOS) is reported. The proposed platform is available publicly at https://github.com/cd-athena/MoViDNN
Real Time Video based Heart and Respiration Rate Monitoring
Jun 04, 2021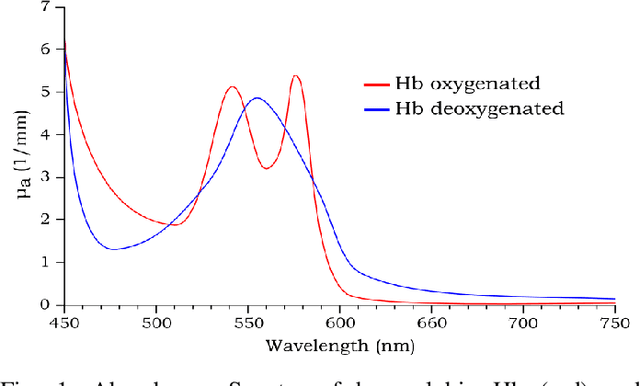


In recent years, research about monitoring vital signs by smartphones grows significantly. There are some special sensors like Electrocardiogram (ECG) and Photoplethysmographic (PPG) to detect heart rate (HR) and respiration rate (RR). Smartphone cameras also can measure HR by detecting and processing imaging Photoplethysmographic (iPPG) signals from the video of a user's face. Indeed, the variation in the intensity of the green channel can be measured by the iPPG signals of the video. This study aimed to provide a method to extract heart rate and respiration rate using the video of individuals' faces. The proposed method is based on measuring fluctuations in the Hue, and can therefore extract both HR and RR from the video of a user's face. The proposed method is evaluated by performing on 25 healthy individuals. For each subject, 20 seconds video of his/her face is recorded. Results show that the proposed approach of measuring iPPG using Hue gives more accurate rates than the Green channel.
A Brief Survey of Machine Learning Methods for Emotion Prediction using Physiological Data
Jan 17, 2022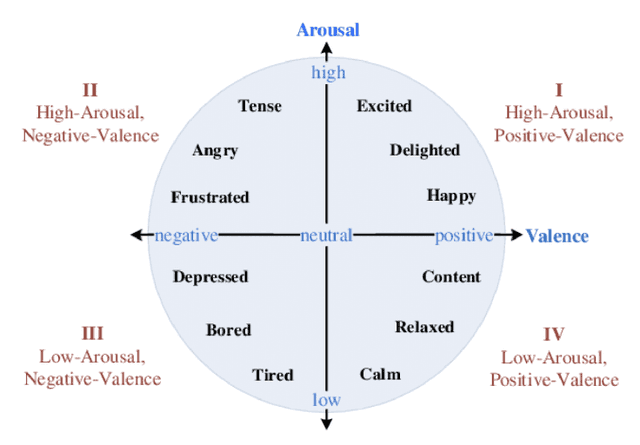
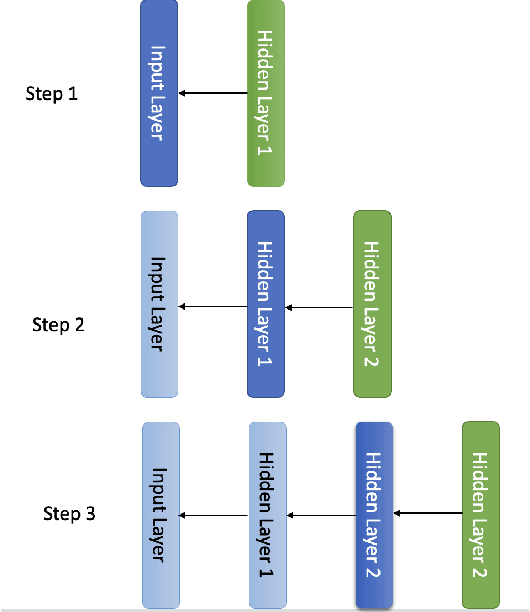
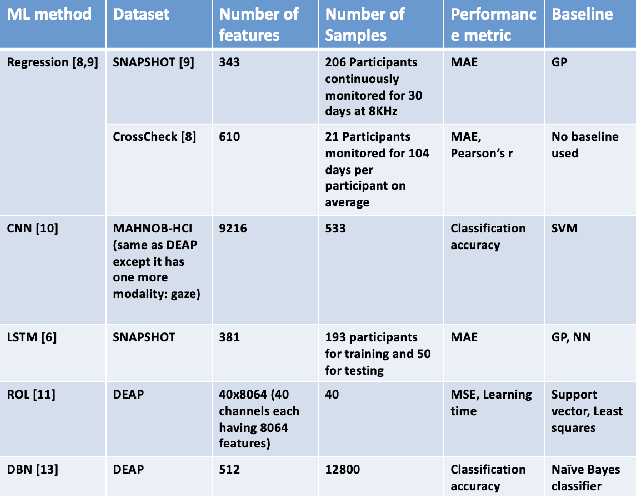
Emotion prediction is a key emerging research area that focuses on identifying and forecasting the emotional state of a human from multiple modalities. Among other data sources, physiological data can serve as an indicator for emotions with an added advantage that it cannot be masked/tampered by the individual and can be easily collected. This paper surveys multiple machine learning methods that deploy smartphone and physiological data to predict emotions in real-time, using self-reported ecological momentary assessments (EMA) scores as ground-truth. Comparing regression, long short-term memory (LSTM) networks, convolutional neural networks (CNN), reinforcement online learning (ROL), and deep belief networks (DBN), we showcase the variability of machine learning methods employed to achieve accurate emotion prediction. We compare the state-of-the-art methods and highlight that experimental performance is still not very good. The performance can be improved in future works by considering the following issues: improving scalability and generalizability, synchronizing multimodal data, optimizing EMA sampling, integrating adaptability with sequence prediction, collecting unbiased data, and leveraging sophisticated feature engineering techniques.
An Interpretable Baseline for Time Series Classification Without Intensive Learning
Jul 13, 2020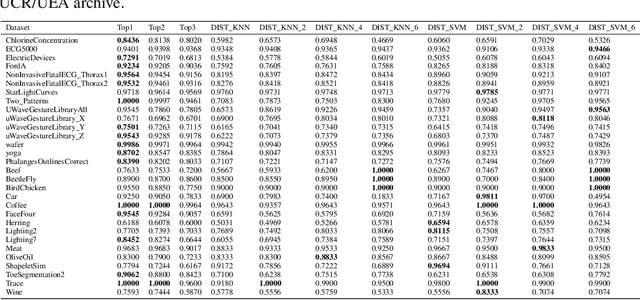
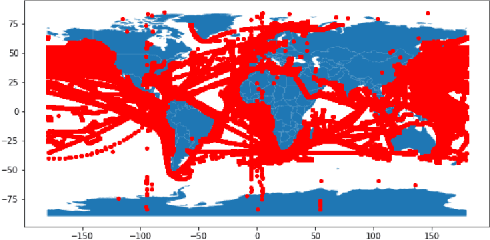
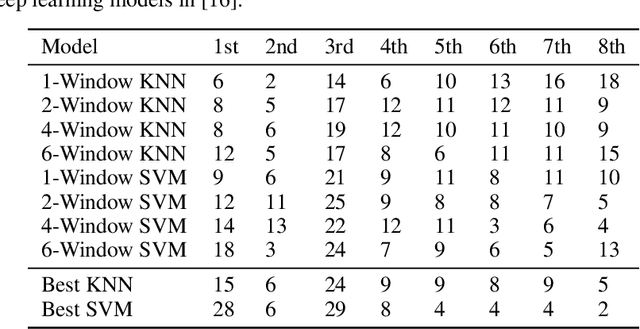
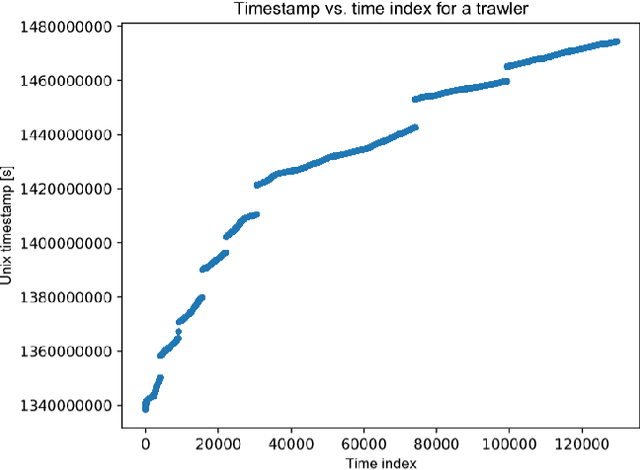
Recent advances in time series classification have largely focused on methods that either employ deep learning or utilize other machine learning models for feature extraction. Though such methods have proven powerful, they can also require computationally expensive models that may lack interpretability of results, or may require larger datasets than are freely available. In this paper, we propose an interpretable baseline based on representing each time series as a collection of probability distributions of extracted geometric features. The features used are intuitive and require minimal parameter tuning. We perform an exhaustive evaluation of our baseline on a large number of real datasets, showing that simple classifiers trained on these features exhibit surprising performance relative to state of the art methods requiring much more computational power. In particular, we show that our methodology achieves good performance on a challenging dataset involving the classification of fishing vessels, where our methods achieve good performance relative to the state of the art despite only having access to approximately two percent of the dataset used in training and evaluating this state of the art.
AI-Based Radio Resource Management and Trajectory Design in CoMP UAV VLC Networks
Nov 22, 2021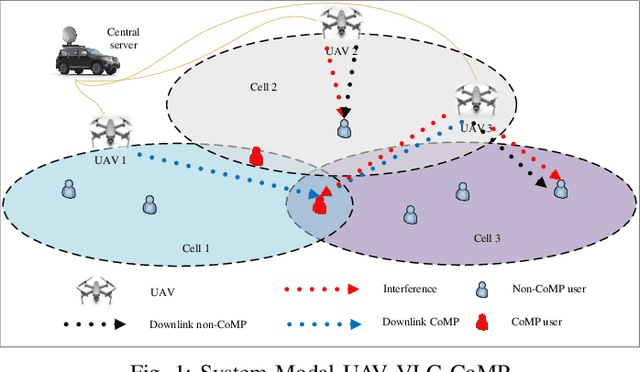
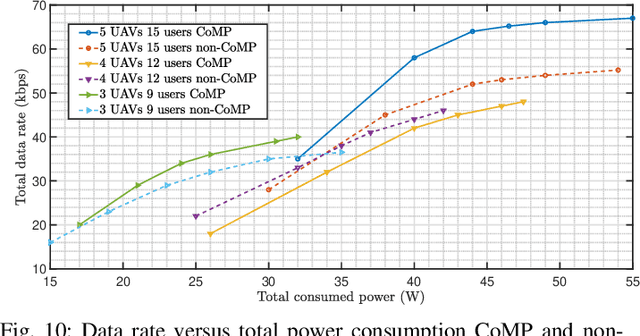
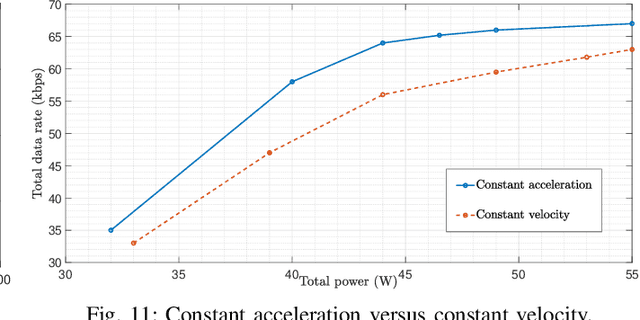
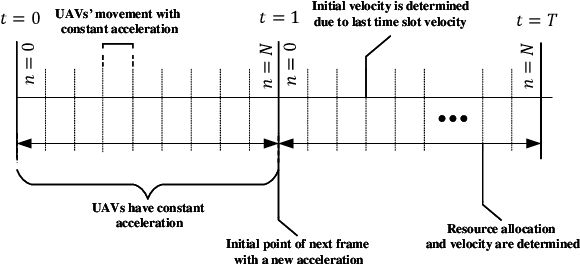
In this paper, we consider unmanned aerial vehicles (UAVs) equipped with a visible light communication (VLC) access point and coordinated multipoint (CoMP) capability that allows users to connect to more than one UAV. UAVs can move in 3-dimensional (3D) at a constant acceleration in each time scale, where a central server is responsible for synchronization and cooperation among UAVs. The effect of accelerated motion in UAV is necessary to be considered. We define the data rate for each user type, CoMP and non-CoMP. Unlike most existing works, we see the effect of variable speed on kinetic and allocation formulas. For the proposed system model, we define two different timescales. In the master timescale, the acceleration of each UAV is specified, and in each short timescale, radio resources are allocated. The initial velocity in each small time slot is obtained from the previous time slot's velocity. Our goal is to formulate a multiobjective optimization problem where the total data rate is maximized and the total communication power consumption is minimized simultaneously. To handle this multiobjective optimization, we first apply the scalarization method and then apply multi-agent deep deterministic policy gradient (MADDPG) which is a multi-agent method based on deep deterministic policy gradient (DDPG) that ensures stable and fast convergence. We improve this solution method by adding two critic networks together with allocating the two step acceleration. Simulation results indicate that the constant acceleration motion of UAVs shows about 8% better results than conventional motion systems in terms of performance. Furthermore, CoMP supports the system to achieve an average 12% average higher rates compared to a non-CoMP system.
Learning-based Measurement Scheduling for Loosely-Coupled Cooperative Localization
Dec 06, 2021
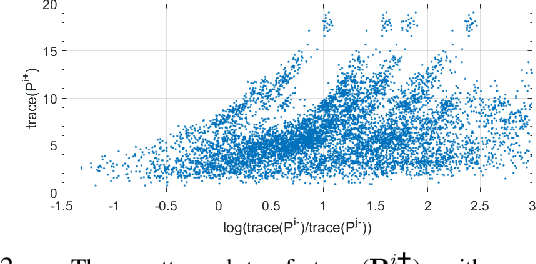
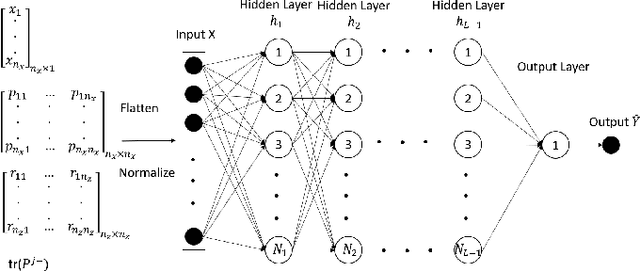
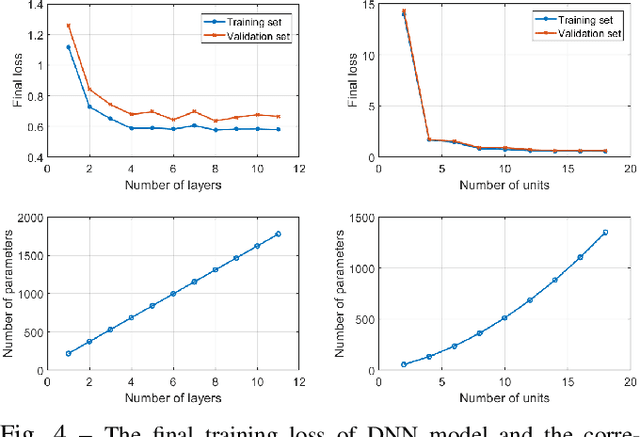
In cooperative localization, communicating mobile agents use inter-agent relative measurements to improve their dead-reckoning-based global localization. Measurement scheduling enables an agent to decide which subset of available inter-agent relative measurements it should process when its computational resources are limited. Optimal measurement scheduling is an NP-hard combinatorial optimization problem. The so-called sequential greedy (SG) algorithm is a popular suboptimal polynomial-time solution for this problem. However, the merit function evaluation for the SG algorithms requires access to the state estimate vector and error covariance matrix of all the landmark agents (teammates that an agent can take measurements from). This paper proposes a measurement scheduling for CL that follows the SG approach but reduces the communication and computation cost by using a neural network-based surrogate model as a proxy for the SG algorithm's merit function. The significance of this model is that it is driven by local information and only a scalar metadata from the landmark agents. This solution addresses the time and memory complexity issues of running the SG algorithm in three ways: (a) reducing the inter-agent communication message size, (b) decreasing the complexity of function evaluations by using a simpler surrogate (proxy) function, (c) reducing the required memory size.Simulations demonstrate our results.
Bag of Tricks for Natural Policy Gradient Reinforcement Learning
Jan 22, 2022
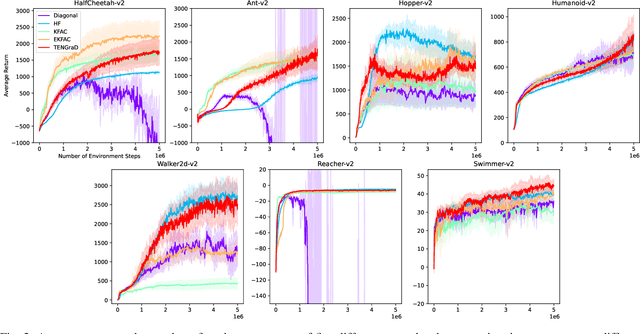

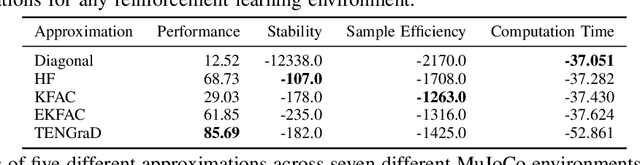
Natural policy gradient methods are popular reinforcement learning methods that improve the stability of policy gradient methods by preconditioning the gradient with the inverse of the Fisher-information matrix. However, leveraging natural policy gradient methods in an optimal manner can be very challenging as many implementation details must be set to achieve optimal performance. To the best of the authors' knowledge, there has not been a study that has investigated strategies for setting these details for natural policy gradient methods to achieve high performance in a comprehensive and systematic manner. To address this, we have implemented and compared strategies that impact performance in natural policy gradient reinforcement learning across five different second-order approximations. These include varying batch sizes and optimizing the critic network using the natural gradient. Furthermore, insights about the fundamental trade-offs when optimizing for performance (stability, sample efficiency, and computation time) were generated. Experimental results indicate that the proposed collection of strategies for performance optimization can improve results by 86% to 181% across the MuJuCo control benchmark, with TENGraD exhibiting the best approximation performance amongst the tested approximations. Code in this study is available at https://github.com/gebob19/natural-policy-gradient-reinforcement-learning.
D-HAN: Dynamic News Recommendation with Hierarchical Attention Network
Dec 19, 2021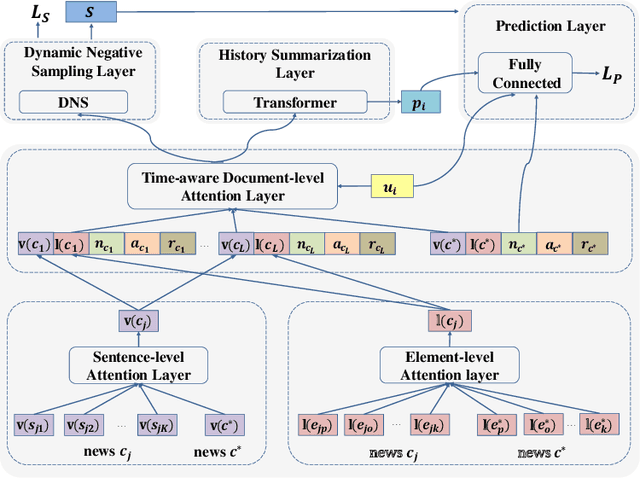
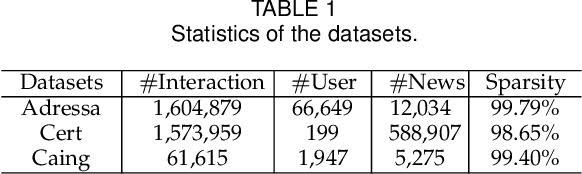
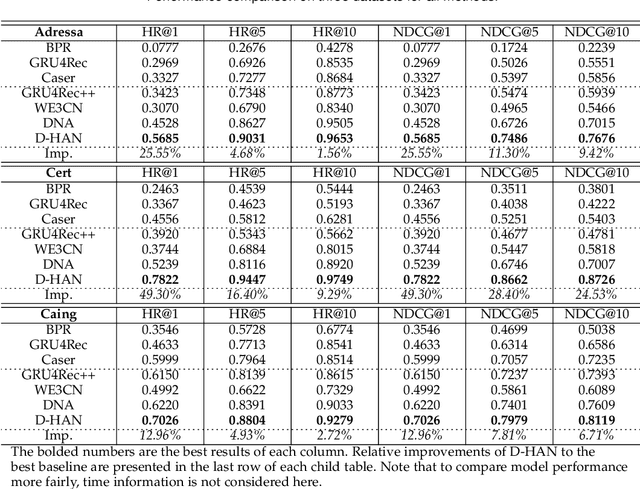
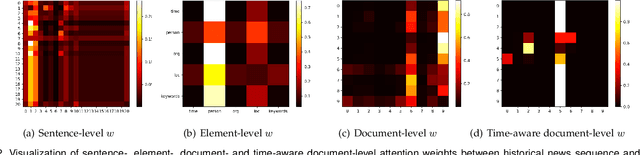
News recommendation is an effective information dissemination solution in modern society. While recent years have witnessed many promising news recommendation models, they mostly capture the user-news interactions on the document-level in a static manner. However, in real-world scenarios, the news can be quite complex and diverse, blindly squeezing all the contents into an embedding vector can be less effective in extracting information compatible with the personalized preference of the users. In addition, user preferences in the news recommendation scenario can be highly dynamic, and a tailored dynamic mechanism should be designed for better recommendation performance. In this paper, we propose a novel dynamic news recommender model. For better understanding the news content, we leverage the attention mechanism to represent the news from the sentence-, element- and document-levels, respectively. For capturing users' dynamic preferences, the continuous time information is seamlessly incorporated into the computing of the attention weights. More specifically, we design a hierarchical attention network, where the lower layer learns the importance of different sentences and elements, and the upper layer captures the correlations between the previously interacted and the target news. To comprehensively model the dynamic characters, we firstly enhance the traditional attention mechanism by incorporating both absolute and relative time information, and then we propose a dynamic negative sampling method to optimize the users' implicit feedback. We conduct extensive experiments based on three real-world datasets to demonstrate our model's effectiveness. Our source code and pre-trained representations are available at https://github.com/lshowway/D-HAN.
Deep Neural Networks for automatic extraction of features in time series satellite images
Aug 17, 2020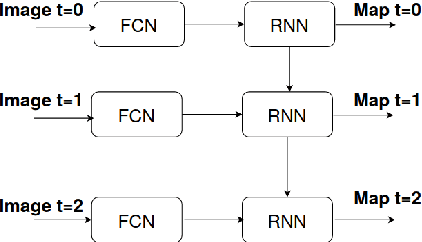


Many earth observation programs such as Landsat, Sentinel, SPOT, and Pleiades produce huge volume of medium to high resolution multi-spectral images every day that can be organized in time series. In this work, we exploit both temporal and spatial information provided by these images to generate land cover maps. For this purpose, we combine a fully convolutional neural network with a convolutional long short-term memory. Implementation details of the proposed spatio-temporal neural network architecture are provided. Experimental results show that the temporal information provided by time series images allows increasing the accuracy of land cover classification, thus producing up-to-date maps that can help in identifying changes on earth.
MDS-Net: A Multi-scale Depth Stratification Based Monocular 3D Object Detection Algorithm
Jan 12, 2022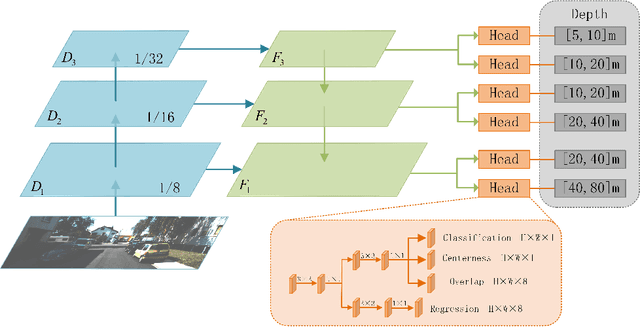
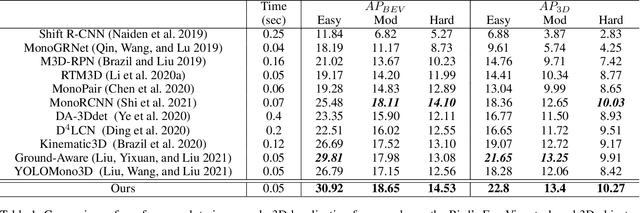
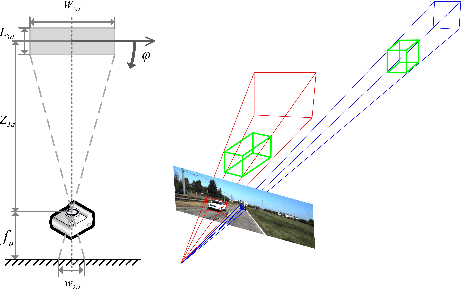

Monocular 3D object detection is very challenging in autonomous driving due to the lack of depth information. This paper proposes a one-stage monocular 3D object detection algorithm based on multi-scale depth stratification, which uses the anchor-free method to detect 3D objects in a per-pixel prediction. In the proposed MDS-Net, a novel depth-based stratification structure is developed to improve the network's ability of depth prediction by establishing mathematical models between depth and image size of objects. A new angle loss function is then developed to further improve the accuracy of the angle prediction and increase the convergence speed of training. An optimized soft-NMS is finally applied in the post-processing stage to adjust the confidence of candidate boxes. Experiments on the KITTI benchmark show that the MDS-Net outperforms the existing monocular 3D detection methods in 3D detection and BEV detection tasks while fulfilling real-time requirements.