 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoving past point-contacts: Extending the ALIP model to humanoids with non-trivial feet using hierarchical, full-body momentum control
Aug 09, 2024



The Angular-Momentum Linear Inverted Pendulum (ALIP) model is a promising motion planner for bipedal robots. However, it relies on two assumptions: (1) the robot has point-contact feet or passive ankles, and (2) the angular momentum around the center of mass, known as centroidal angular momentum, is negligible. This paper addresses the question of whether the ALIP paradigm can be applied to more general bipedal systems with complex foot geometry (e.g., flat feet) and nontrivial torso/limb inertia and mass distribution (e.g., non-centralized arms). In such systems, the dynamics introduce non-negligible centroidal momentum and contact wrenches at the feet, rendering the assumptions of the ALIP model invalid. This paper presents the ALIP planner for general bipedal robots with non-point-contact feet through the use of a task-space whole-body controller that regulates centroidal momentum, thereby ensuring that the robot's behavior aligns with the desired template dynamics. To demonstrate the effectiveness of our proposed approach, we conduct simulations using the Sarcos Guardian XO robot, which is a hybrid humanoid/exoskeleton with large, offset feet. The results demonstrate the practicality and effectiveness of our approach in achieving stable and versatile bipedal locomotion.
An Interpretable Baseline for Time Series Classification Without Intensive Learning
Jul 13, 2020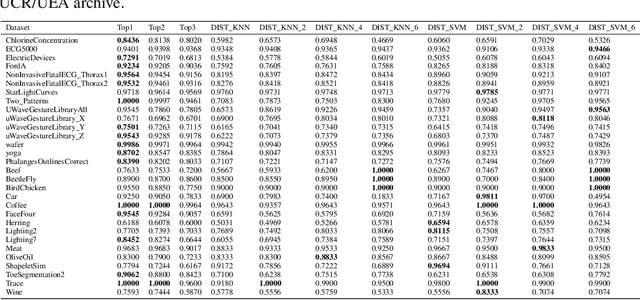
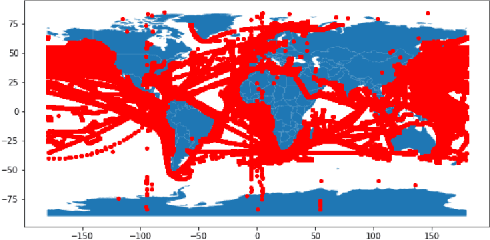
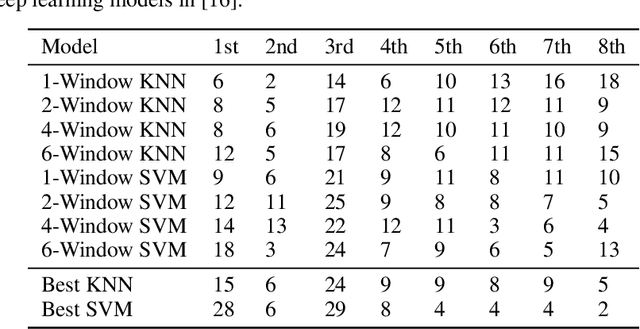
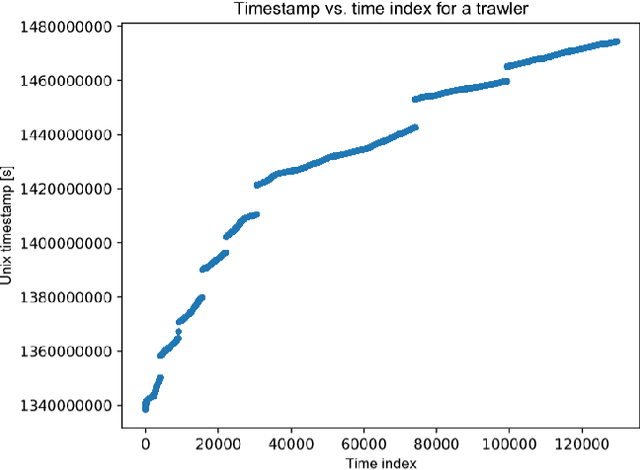
Recent advances in time series classification have largely focused on methods that either employ deep learning or utilize other machine learning models for feature extraction. Though such methods have proven powerful, they can also require computationally expensive models that may lack interpretability of results, or may require larger datasets than are freely available. In this paper, we propose an interpretable baseline based on representing each time series as a collection of probability distributions of extracted geometric features. The features used are intuitive and require minimal parameter tuning. We perform an exhaustive evaluation of our baseline on a large number of real datasets, showing that simple classifiers trained on these features exhibit surprising performance relative to state of the art methods requiring much more computational power. In particular, we show that our methodology achieves good performance on a challenging dataset involving the classification of fishing vessels, where our methods achieve good performance relative to the state of the art despite only having access to approximately two percent of the dataset used in training and evaluating this state of the art.
Robust Marine Buoy Placement for Ship Detection Using Dropout K-Means
Feb 20, 2020
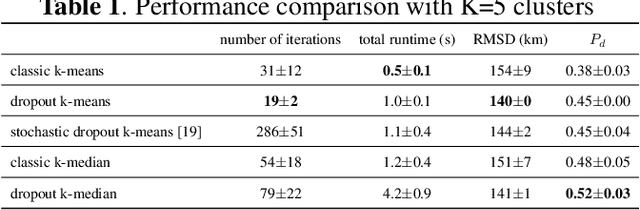
Marine buoys aid in the battle against Illegal, Unreported and Unregulated (IUU) fishing by detecting fishing vessels in their vicinity. Marine buoys, however, may be disrupted by natural causes and buoy vandalism. In this paper, we formulate marine buoy placement as a clustering problem, and propose dropout k-means and dropout k-median to improve placement robustness to buoy disruption. We simulated the passage of ships in the Gabonese waters near West Africa using historical Automatic Identification System (AIS) data, then compared the ship detection probability of dropout k-means to classic k-means and dropout k-median to classic k-median. With 5 buoys, the buoy arrangement computed by classic k-means, dropout k-means, classic k-median and dropout k-median have ship detection probabilities of 38%, 45%, 48% and 52%.