 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedMPDD: Communication-Efficient Federated Learning with Privacy Preservation Attributes via Projected Directional Derivative
Dec 23, 2025This paper introduces \texttt{FedMPDD} (\textbf{Fed}erated Learning via \textbf{M}ulti-\textbf{P}rojected \textbf{D}irectional \textbf{D}erivatives), a novel algorithm that simultaneously optimizes bandwidth utilization and enhances privacy in Federated Learning. The core idea of \texttt{FedMPDD} is to encode each client's high-dimensional gradient by computing its directional derivatives along multiple random vectors. This compresses the gradient into a much smaller message, significantly reducing uplink communication costs from $\mathcal{O}(d)$ to $\mathcal{O}(m)$, where $m \ll d$. The server then decodes the aggregated information by projecting it back onto the same random vectors. Our key insight is that averaging multiple projections overcomes the dimension-dependent convergence limitations of a single projection. We provide a rigorous theoretical analysis, establishing that \texttt{FedMPDD} converges at a rate of $\mathcal{O}(1/\sqrt{K})$, matching the performance of FedSGD. Furthermore, we demonstrate that our method provides some inherent privacy against gradient inversion attacks due to the geometric properties of low-rank projections, offering a tunable privacy-utility trade-off controlled by the number of projections. Extensive experiments on benchmark datasets validate our theory and demonstrates our results.
B-ActiveSEAL: Scalable Uncertainty-Aware Active Exploration with Tightly Coupled Localization-Mapping
Dec 13, 2025Active robot exploration requires decision-making processes that integrate localization and mapping under tightly coupled uncertainty. However, managing these interdependent uncertainties over long-term operations in large-scale environments rapidly becomes computationally intractable. To address this challenge, we propose B-ActiveSEAL, a scalable information-theoretic active exploration framework that explicitly accounts for coupled uncertainties-from perception through mapping-into the decision-making process. Our framework (i) adaptively balances map uncertainty (exploration) and localization uncertainty (exploitation), (ii) accommodates a broad class of generalized entropy measures, enabling flexible and uncertainty-aware active exploration, and (iii) establishes Behavioral entropy (BE) as an effective information measure for active exploration by enabling intuitive and adaptive decision-making under coupled uncertainties. We establish a theoretical foundation for propagating coupled uncertainties and integrating them into general entropy formulations, enabling uncertainty-aware active exploration under tightly coupled localization-mapping. The effectiveness of the proposed approach is validated through rigorous theoretical analysis and extensive experiments on open-source maps and ROS-Unity simulations across diverse and complex environments. The results demonstrate that B-ActiveSEAL achieves a well-balanced exploration-exploitation trade-off and produces diverse, adaptive exploration behaviors across environments, highlighting clear advantages over representative baselines.
BEASST: Behavioral Entropic Gradient based Adaptive Source Seeking for Mobile Robots
Aug 14, 2025This paper presents BEASST (Behavioral Entropic Gradient-based Adaptive Source Seeking for Mobile Robots), a novel framework for robotic source seeking in complex, unknown environments. Our approach enables mobile robots to efficiently balance exploration and exploitation by modeling normalized signal strength as a surrogate probability of source location. Building on Behavioral Entropy(BE) with Prelec's probability weighting function, we define an objective function that adapts robot behavior from risk-averse to risk-seeking based on signal reliability and mission urgency. The framework provides theoretical convergence guarantees under unimodal signal assumptions and practical stability under bounded disturbances. Experimental validation across DARPA SubT and multi-room scenarios demonstrates that BEASST consistently outperforms state-of-the-art methods, achieving 15% reduction in path length and 20% faster source localization through intelligent uncertainty-driven navigation that dynamically transitions between aggressive pursuit and cautious exploration.
NavEX: A Multi-Agent Coverage in Non-Convex and Uneven Environments via Exemplar-Clustering
Apr 29, 2025This paper addresses multi-agent deployment in non-convex and uneven environments. To overcome the limitations of traditional approaches, we introduce Navigable Exemplar-Based Dispatch Coverage (NavEX), a novel dispatch coverage framework that combines exemplar-clustering with obstacle-aware and traversability-aware shortest distances, offering a deployment framework based on submodular optimization. NavEX provides a unified approach to solve two critical coverage tasks: (a) fair-access deployment, aiming to provide equitable service by minimizing agent-target distances, and (b) hotspot deployment, prioritizing high-density target regions. A key feature of NavEX is the use of exemplar-clustering for the coverage utility measure, which provides the flexibility to employ non-Euclidean distance metrics that do not necessarily conform to the triangle inequality. This allows NavEX to incorporate visibility graphs for shortest-path computation in environments with planar obstacles, and traversability-aware RRT* for complex, rugged terrains. By leveraging submodular optimization, the NavEX framework enables efficient, near-optimal solutions with provable performance guarantees for multi-agent deployment in realistic and complex settings, as demonstrated by our simulations.
Sequential Gaussian Variational Inference for Nonlinear State Estimation applied to Robotic Applications
Jul 07, 2024



Probabilistic state estimation is essential for robots navigating uncertain environments. Accurately and efficiently managing uncertainty in estimated states is key to robust robotic operation. However, nonlinearities in robotic platforms pose significant challenges that require advanced estimation techniques. Gaussian variational inference (GVI) offers an optimization perspective on the estimation problem, providing analytically tractable solutions and efficiencies derived from the geometry of Gaussian space. We propose a Sequential Gaussian Variational Inference (S-GVI) method to address nonlinearity and provide efficient sequential inference processes. Our approach integrates sequential Bayesian principles into the GVI framework, which are addressed using statistical approximations and gradient updates on the information geometry. Validations through simulations and real-world experiments demonstrate significant improvements in state estimation over the Maximum A Posteriori (MAP) estimation method.
Stein-MAP: A Sequential Variational Inference Framework for Maximum A Posteriori Estimation
Dec 16, 2023



State estimation poses substantial challenges in robotics, often involving encounters with multimodality in real-world scenarios. To address these challenges, it is essential to calculate Maximum a posteriori (MAP) sequences from joint probability distributions of latent states and observations over time. However, it generally involves a trade-off between approximation errors and computational complexity. In this article, we propose a new method for MAP sequence estimation called Stein-MAP, which effectively manages multimodality with fewer approximation errors while significantly reducing computational and memory burdens. Our key contribution lies in the introduction of a sequential variational inference framework designed to handle temporal dependencies among transition states within dynamical system models. The framework integrates Stein's identity from probability theory and reproducing kernel Hilbert space (RKHS) theory, enabling computationally efficient MAP sequence estimation. As a MAP sequence estimator, Stein-MAP boasts a computational complexity of O(N), where N is the number of particles, in contrast to the O(N^2) complexity of the Viterbi algorithm. The proposed method is empirically validated through real-world experiments focused on range-only (wireless) localization. The results demonstrate a substantial enhancement in state estimation compared to existing methods. A remarkable feature of Stein-MAP is that it can attain improved state estimation with only 40 to 50 particles, as opposed to the 1000 particles that the particle filter or its variants require.
Bayesian Learning for Dynamic Target Localization with Human-provided Spatial Information
Aug 24, 2023



This paper considers a human-autonomy collaborative sensor data fusion for dynamic target localization in a Bayesian framework. To compensate for the shortcomings of an autonomous tracking system, we propose to collect spatial sensing information from human operators who visually monitor the target and can provide target localization information in the form of free sketches encircling the area where the target is located. Our focus in this paper is to construct an adaptive probabilistic model for human-provided inputs where the adaption terms capture the level of reliability of the human inputs. The next contribution of this paper is a novel joint Bayesian learning method to fuse human and autonomous sensor inputs in a manner that the dynamic changes in human detection reliability are also captured and accounted for. A unique aspect of this Bayesian modeling framework is its analytical closed-form update equations, endowing our method with significant computational efficiency. Simulations demonstrate our results.
Distributed Unconstrained Optimization with Time-varying Cost Functions
Dec 12, 2022


In this paper, we propose a novel solution for the distributed unconstrained optimization problem where the total cost is the summation of time-varying local cost functions of a group networked agents. The objective is to track the optimal trajectory that minimizes the total cost at each time instant. Our approach consists of a two-stage dynamics, where the first one samples the first and second derivatives of the local costs periodically to construct an estimate of the descent direction towards the optimal trajectory, and the second one uses this estimate and a consensus term to drive local states towards the time-varying solution while reaching consensus. The first part is carried out by the implementation of a weighted average consensus algorithm in the discrete-time framework and the second part is performed with a continuous-time dynamics. Using the Lyapunov stability analysis, an upper bound on the gradient of the total cost is obtained which is asymptotically reached. This bound is characterized by the properties of the local costs. To demonstrate the performance of the proposed method, a numerical example is conducted that studies tuning the algorithm's parameters and their effects on the convergence of local states to the optimal trajectory.
Online Target Localization using Adaptive Belief Propagation in the HMM Framework
Mar 18, 2022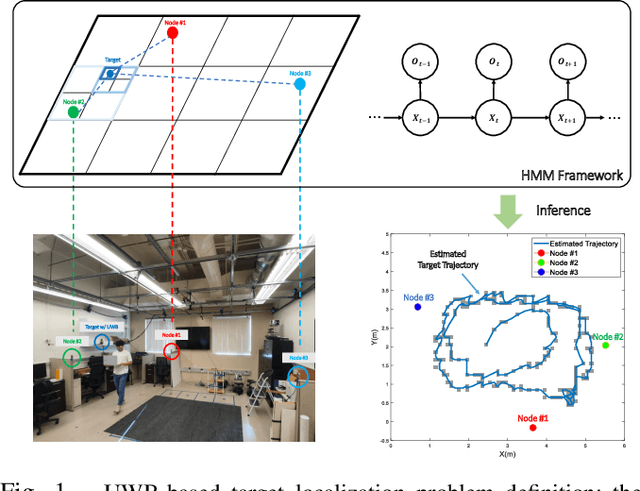
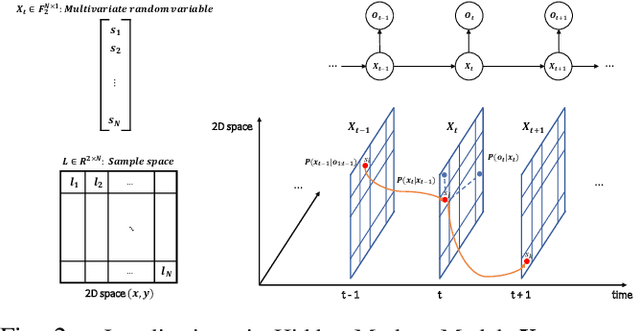
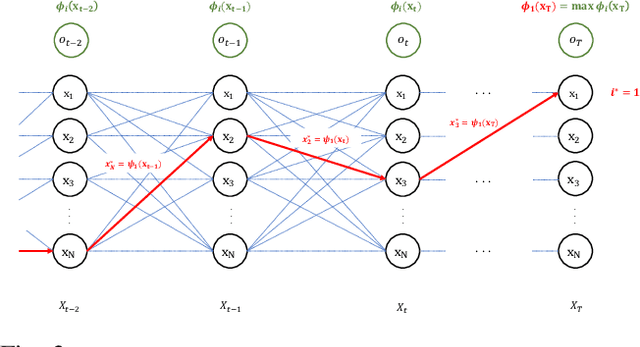
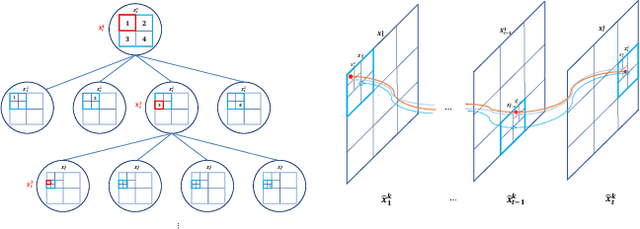
This paper proposes a novel adaptive sample space-based Viterbi algorithm for ultra-wideband (UWB) based target localization in an online manner. As the discretized area of interest is defined as a finite number of hidden states, the most probable trajectory of the unspecified agent is computed efficiently via dynamic programming in a Hidden Markov Model (HMM) framework. Furthermore, the approach has no requirements about Gaussian assumption and linearization for Bayesian calculation. However, the issue of computational complexity becomes very critical as the number of hidden states increases for estimation accuracy and large space. Previous localization works, based on discrete-state HMM, handle a small number of hidden variables, which represent specific paths or places. Inspired by the k-d Tree algorithm (e.g., quadtree) that is commonly used in the computer vision field, we propose a belief propagation in the most probable belief space with a low to high-resolution sequentially, thus reducing the required resources significantly. Our method has three advantages for localization: (a) no Gaussian assumptions and linearization, (b) handling the whole area of interest, not specific or small map representations, (c) reducing computation time and required memory size. Experimental tests demonstrate our results.
Learning Contraction Policies from Offline Data
Dec 11, 2021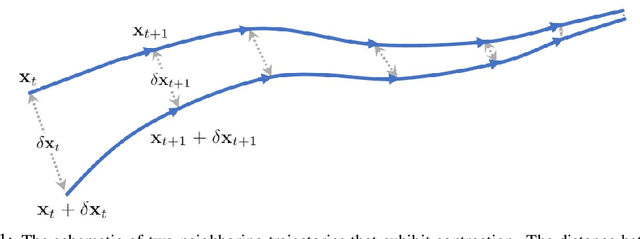

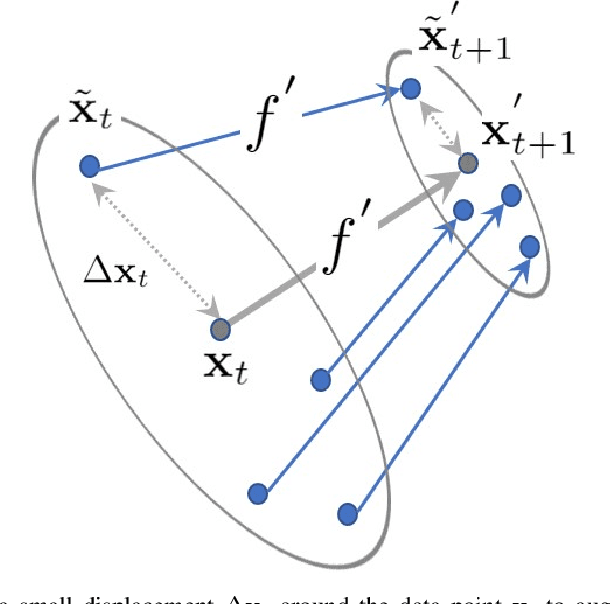
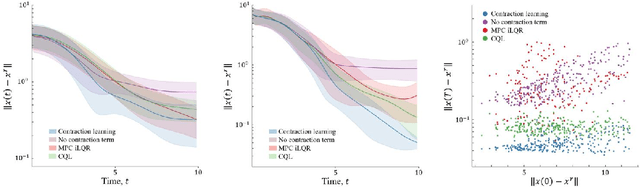
This paper proposes a data-driven method for learning convergent control policies from offline data using Contraction theory. Contraction theory enables constructing a policy that makes the closed-loop system trajectories inherently convergent towards a unique trajectory. At the technical level, identifying the contraction metric, which is the distance metric with respect to which a robot's trajectories exhibit contraction is often non-trivial. We propose to jointly learn the control policy and its corresponding contraction metric while enforcing contraction. To achieve this, we learn an implicit dynamics model of the robotic system from an offline data set consisting of the robot's state and input trajectories. Using this learned dynamics model, we propose a data augmentation algorithm for learning contraction policies. We randomly generate samples in the state-space and propagate them forward in time through the learned dynamics model to generate auxiliary sample trajectories. We then learn both the control policy and the contraction metric such that the distance between the trajectories from the offline data set and our generated auxiliary sample trajectories decreases over time. We evaluate the performance of our proposed framework on simulated robotic goal-reaching tasks and demonstrate that enforcing contraction results in faster convergence and greater robustness of the learned policy.