 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Shaping Advice in Deep Reinforcement Learning
Feb 19, 2022
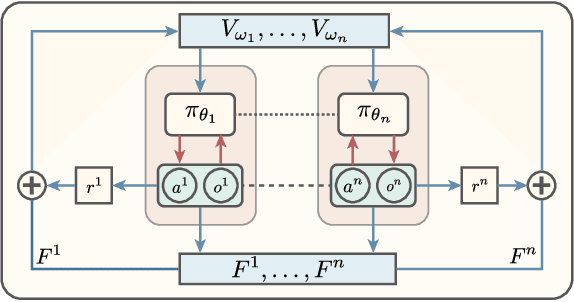
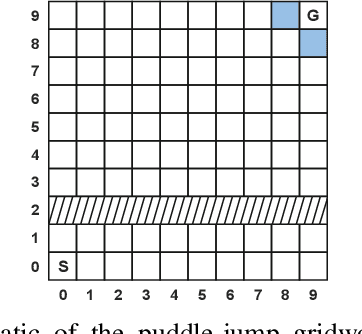
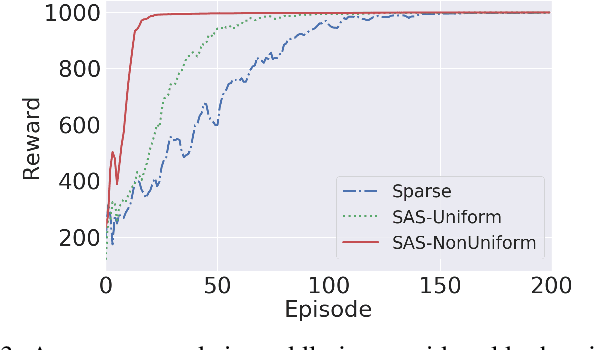
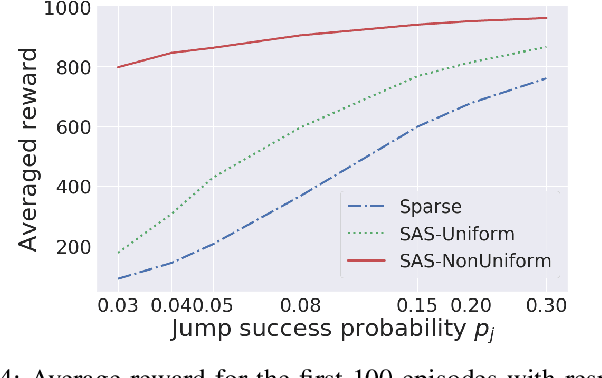
Reinforcement learning involves agents interacting with an environment to complete tasks. When rewards provided by the environment are sparse, agents may not receive immediate feedback on the quality of actions that they take, thereby affecting learning of policies. In this paper, we propose to methods to augment the reward signal from the environment with an additional reward termed shaping advice in both single and multi-agent reinforcement learning. The shaping advice is specified as a difference of potential functions at consecutive time-steps. Each potential function is a function of observations and actions of the agents. The use of potential functions is underpinned by an insight that the total potential when starting from any state and returning to the same state is always equal to zero. We show through theoretical analyses and experimental validation that the shaping advice does not distract agents from completing tasks specified by the environment reward. Theoretically, we prove that the convergence of policy gradients and value functions when using shaping advice implies the convergence of these quantities in the absence of shaping advice. We design two algorithms- Shaping Advice in Single-agent reinforcement learning (SAS) and Shaping Advice in Multi-agent reinforcement learning (SAM). Shaping advice in SAS and SAM needs to be specified only once at the start of training, and can easily be provided by non-experts. Experimentally, we evaluate SAS and SAM on two tasks in single-agent environments and three tasks in multi-agent environments that have sparse rewards. We observe that using shaping advice results in agents learning policies to complete tasks faster, and obtain higher rewards than algorithms that do not use shaping advice.
A Novel 1D State Space for Efficient Music Rhythmic Analysis
Nov 01, 2021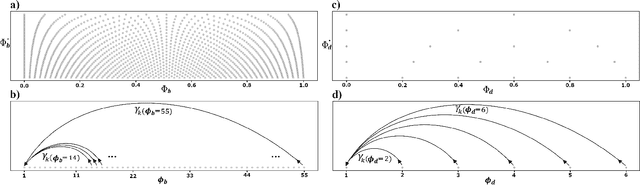
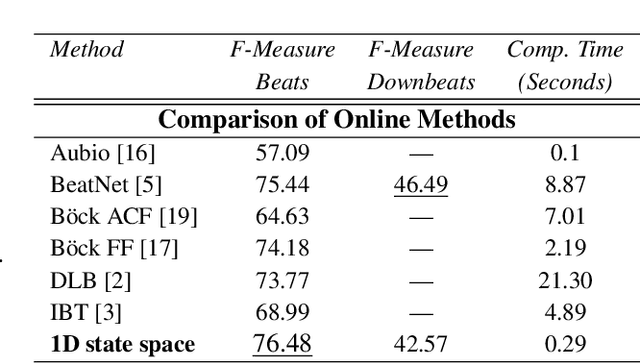
Inferring music time structures has a broad range of applications in music production, processing and analysis. Scholars have proposed various methods to analyze different aspects of time structures, including beat, downbeat, tempo and meter. Many of the state-of-the-art methods, however, are computationally expensive. This makes them inapplicable in real-world industrial settings where the scale of the music collections can be millions. This paper proposes a new state space approach for music time structure analysis. The proposed approach collapses the commonly used 2D state spaces into 1D through a jump-back reward strategy. This reduces the state space size drastically. We then utilize the proposed method for casual, joint beat, downbeat, tempo, and meter tracking, and compare it against several previous beat and downbeat tracking methods. The proposed method delivers comparable performance with the state-of-the-art joint casual models with a much smaller state space and a more than 30 times speedup.
Generation of Synthetic Rat Brain MRI scans with a 3D Enhanced Alpha-GAN
Jan 04, 2022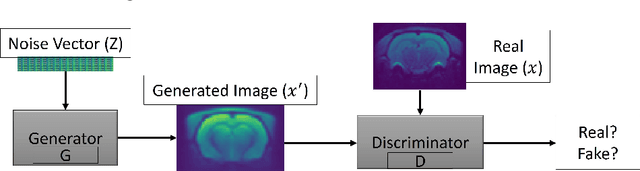
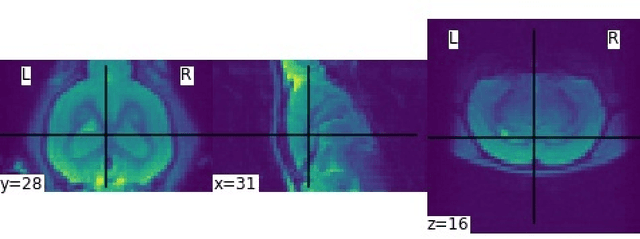
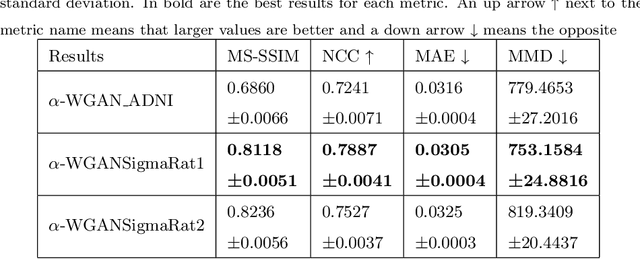
Translational brain research using Magnetic Resonance Imaging (MRI) is becoming increasingly popular as animal models are an essential part of scientific studies and more ultra-high-field scanners are becoming available. Some disadvantages of MRI are the availability of MRI scanners and the time required for a full scanning session (it usually takes over 30 minutes). Privacy laws and the 3Rs ethics rule also make it difficult to create large datasets for training deep learning models. Generative Adversarial Networks (GANs) can perform data augmentation with higher quality than other techniques. In this work, the alpha-GAN architecture is used to test its ability to produce realistic 3D MRI scans of the rat brain. As far as the authors are aware, this is the first time that a GAN-based approach has been used for data augmentation in preclinical data. The generated scans are evaluated using various qualitative and quantitative metrics. A Turing test conducted by 4 experts has shown that the generated scans can trick almost any expert. The generated scans were also used to evaluate their impact on the performance of an existing deep learning model developed for segmenting the rat brain into white matter, grey matter and cerebrospinal fluid. The models were compared using the Dice score. The best results for whole brain and white matter segmentation were obtained when 174 real scans and 348 synthetic scans were used, with improvements of 0.0172 and 0.0129, respectively. Using 174 real scans and 87 synthetic scans resulted in improvements of 0.0038 and 0.0764 for grey matter and CSF segmentation, respectively. Thus, by using the proposed new normalisation layer and loss functions, it was possible to improve the realism of the generated rat MRI scans and it was shown that using the generated data improved the segmentation model more than using the conventional data augmentation.
Improving the repeatability of deep learning models with Monte Carlo dropout
Feb 15, 2022
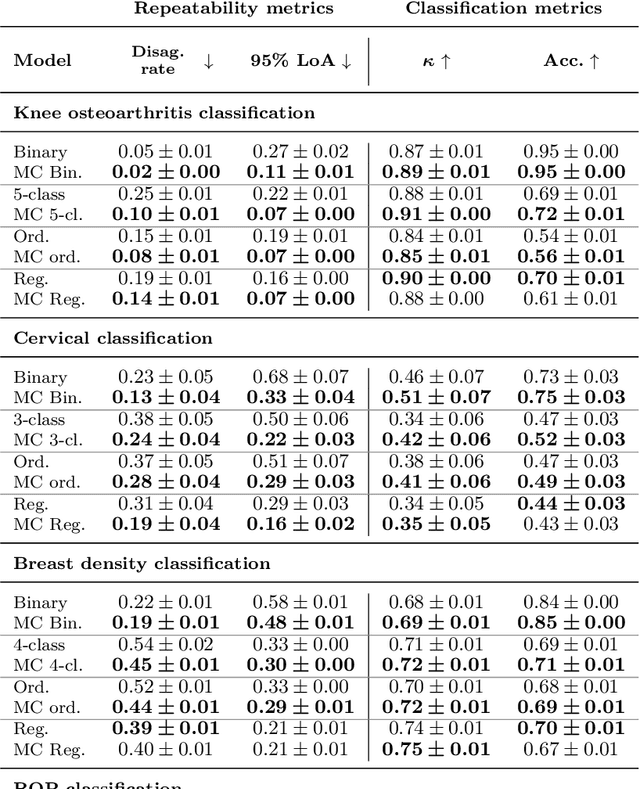
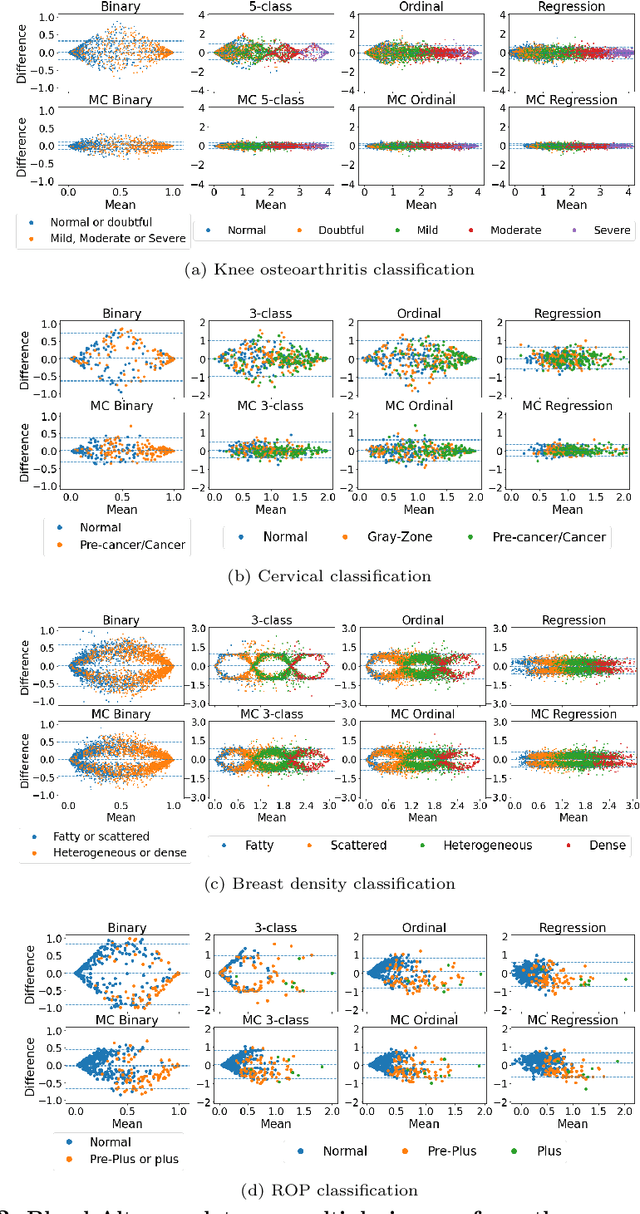
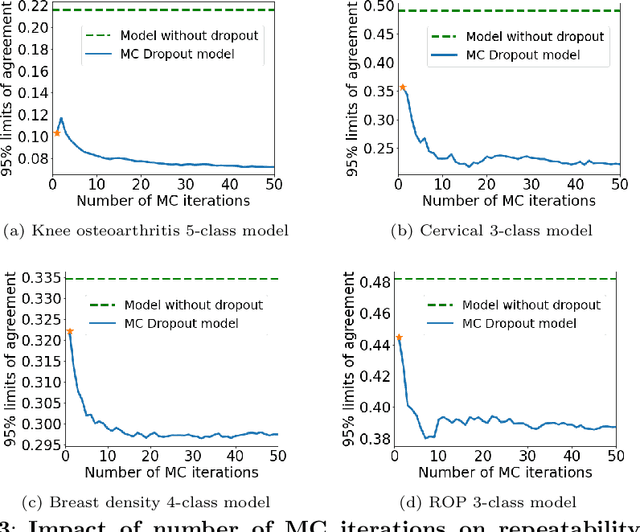
The integration of artificial intelligence into clinical workflows requires reliable and robust models. Repeatability is a key attribute of model robustness. Repeatable models output predictions with low variation during independent tests carried out under similar conditions. During model development and evaluation, much attention is given to classification performance while model repeatability is rarely assessed, leading to the development of models that are unusable in clinical practice. In this work, we evaluate the repeatability of four model types (binary classification, multi-class classification, ordinal classification, and regression) on images that were acquired from the same patient during the same visit. We study the performance of binary, multi-class, ordinal, and regression models on four medical image classification tasks from public and private datasets: knee osteoarthritis, cervical cancer screening, breast density estimation, and retinopathy of prematurity. Repeatability is measured and compared on ResNet and DenseNet architectures. Moreover, we assess the impact of sampling Monte Carlo dropout predictions at test time on classification performance and repeatability. Leveraging Monte Carlo predictions significantly increased repeatability for all tasks on the binary, multi-class, and ordinal models leading to an average reduction of the 95\% limits of agreement by 16% points and of the disagreement rate by 7% points. The classification accuracy improved in most settings along with the repeatability. Our results suggest that beyond about 20 Monte Carlo iterations, there is no further gain in repeatability. In addition to the higher test-retest agreement, Monte Carlo predictions were better calibrated which leads to output probabilities reflecting more accurately the true likelihood of being correctly classified.
Assessing the State of Self-Supervised Human Activity Recognition using Wearables
Feb 22, 2022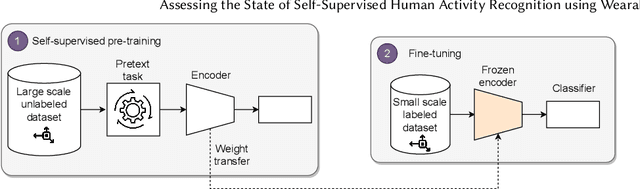

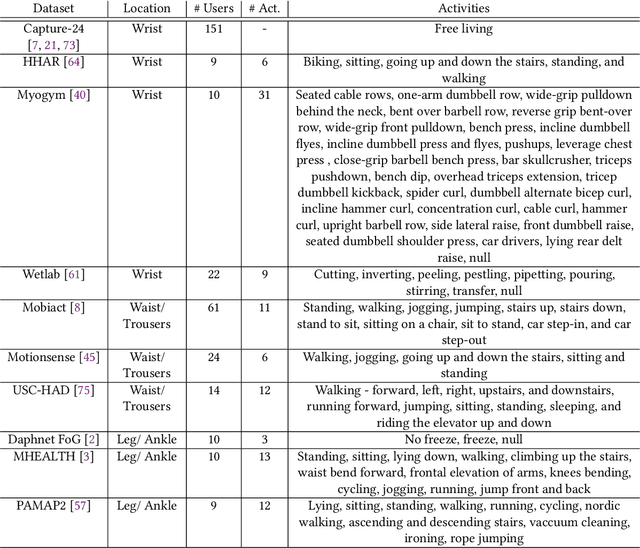
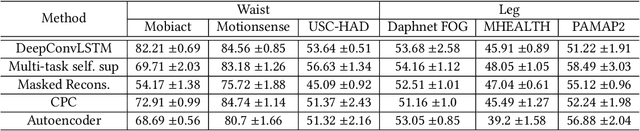
The emergence of self-supervised learning in the field of wearables-based human activity recognition (HAR) has opened up opportunities to tackle the most pressing challenges in the field, namely to exploit unlabeled data to derive reliable recognition systems from only small amounts of labeled training samples. Furthermore, self-supervised methods enable a host of new application domains such as, for example, domain adaptation and transfer across sensor positions, activities etc. As such, self-supervision, i.e., the paradigm of 'pretrain-then-finetune' has the potential to become a strong alternative to the predominant end-to-end training approaches, let alone the classic activity recognition chain with hand-crafted features of sensor data. Recently a number of contributions have been made that introduced self-supervised learning into the field of HAR, including, Multi-task self-supervision, Masked Reconstruction, CPC to name but a few. With the initial success of these methods, the time has come for a systematic inventory and analysis of the potential self-supervised learning has for the field. This paper provides exactly that. We assess the progress of self-supervised HAR research by introducing a framework that performs a multi-faceted exploration of model performance. We organize the framework into three dimensions, each containing three constituent criteria, and utilize it to assess state-of-the-art self-supervised learning methods in a large empirical study on a curated set of nine diverse benchmarks. This exploration leads us to the formulation of insights into the properties of these techniques and to establish their value towards learning representations for diverse scenarios. Based on our findings we call upon the community to join our efforts and to contribute towards shaping the evaluation of the ongoing paradigm change in modeling human activities from body-worn sensor data.
Automated Attack Synthesis by Extracting Finite State Machines from Protocol Specification Documents
Feb 18, 2022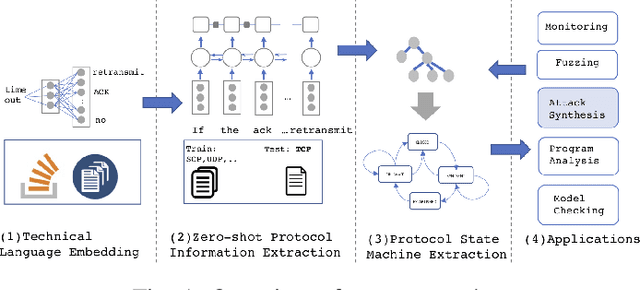
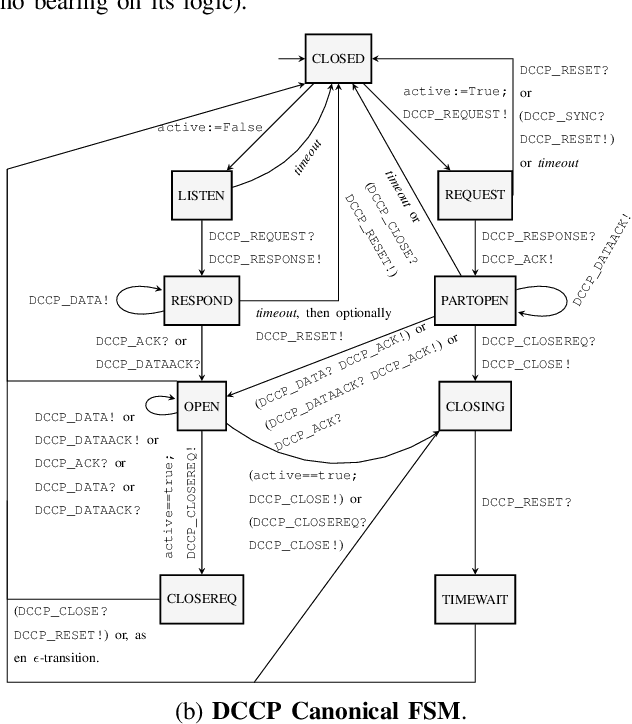

Automated attack discovery techniques, such as attacker synthesis or model-based fuzzing, provide powerful ways to ensure network protocols operate correctly and securely. Such techniques, in general, require a formal representation of the protocol, often in the form of a finite state machine (FSM). Unfortunately, many protocols are only described in English prose, and implementing even a simple network protocol as an FSM is time-consuming and prone to subtle logical errors. Automatically extracting protocol FSMs from documentation can significantly contribute to increased use of these techniques and result in more robust and secure protocol implementations. In this work we focus on attacker synthesis as a representative technique for protocol security, and on RFCs as a representative format for protocol prose description. Unlike other works that rely on rule-based approaches or use off-the-shelf NLP tools directly, we suggest a data-driven approach for extracting FSMs from RFC documents. Specifically, we use a hybrid approach consisting of three key steps: (1) large-scale word-representation learning for technical language, (2) focused zero-shot learning for mapping protocol text to a protocol-independent information language, and (3) rule-based mapping from protocol-independent information to a specific protocol FSM. We show the generalizability of our FSM extraction by using the RFCs for six different protocols: BGPv4, DCCP, LTP, PPTP, SCTP and TCP. We demonstrate how automated extraction of an FSM from an RFC can be applied to the synthesis of attacks, with TCP and DCCP as case-studies. Our approach shows that it is possible to automate attacker synthesis against protocols by using textual specifications such as RFCs.
Physical Activity Recognition by Utilising Smartphone Sensor Signals
Jan 20, 2022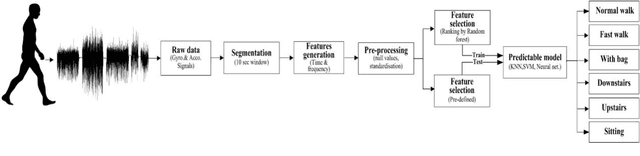
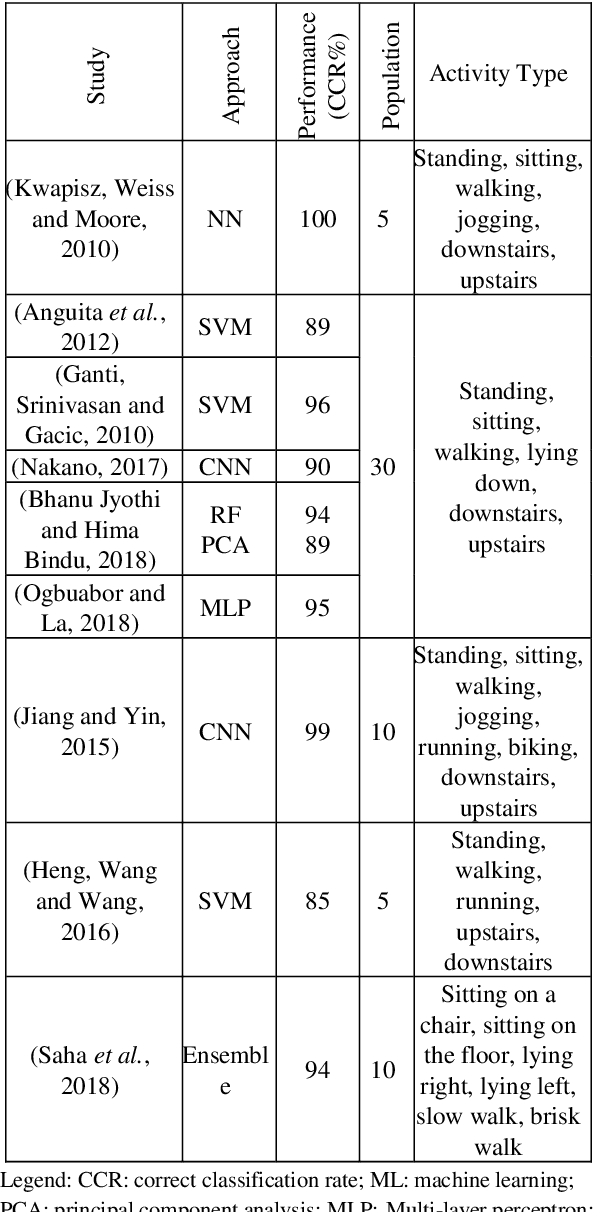
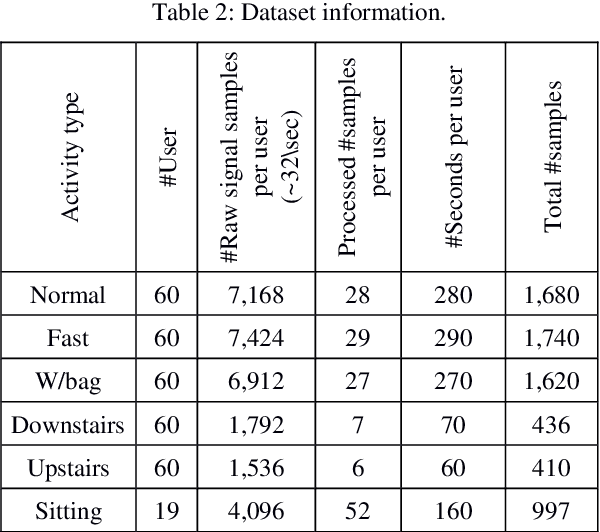
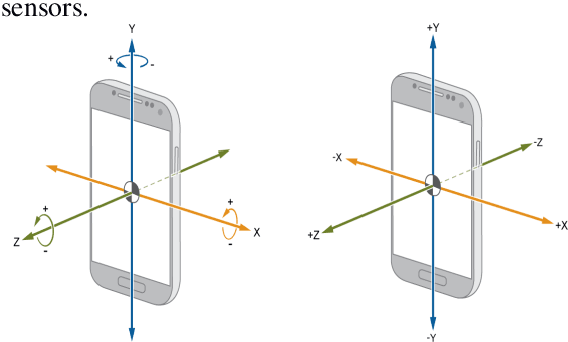
Human physical motion activity identification has many potential applications in various fields, such as medical diagnosis, military sensing, sports analysis, and human-computer security interaction. With the recent advances in smartphones and wearable technologies, it has become common for such devices to have embedded motion sensors that are able to sense even small body movements. This study collected human activity data from 60 participants across two different days for a total of six activities recorded by gyroscope and accelerometer sensors in a modern smartphone. The paper investigates to what extent different activities can be identified by utilising machine learning algorithms using approaches such as majority algorithmic voting. More analyses are also provided that reveal which time and frequency domain based features were best able to identify individuals motion activity types. Overall, the proposed approach achieved a classification accuracy of 98 percent in identifying four different activities: walking, walking upstairs, walking downstairs, and sitting while the subject is calm and doing a typical desk-based activity.
Inference Time Style Control for Summarization
Apr 05, 2021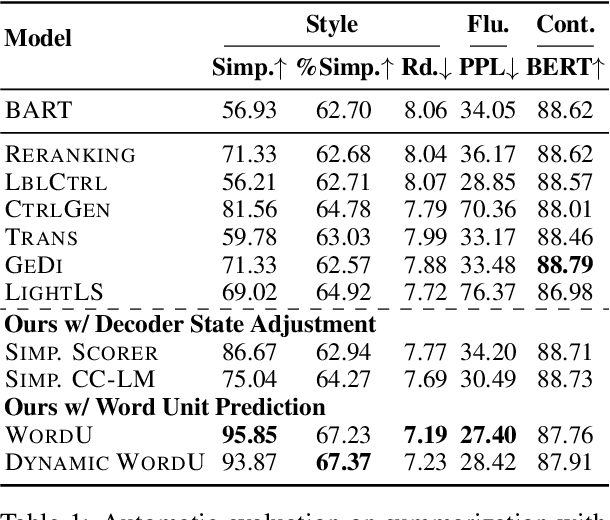
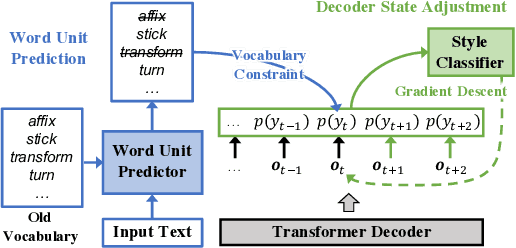
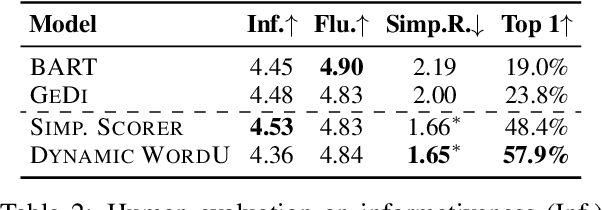
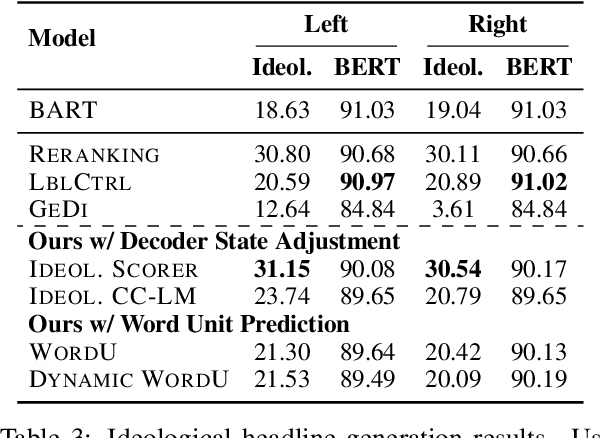
How to generate summaries of different styles without requiring corpora in the target styles, or training separate models? We present two novel methods that can be deployed during summary decoding on any pre-trained Transformer-based summarization model. (1) Decoder state adjustment instantly modifies decoder final states with externally trained style scorers, to iteratively refine the output against a target style. (2) Word unit prediction constrains the word usage to impose strong lexical control during generation. In experiments of summarizing with simplicity control, automatic evaluation and human judges both find our models producing outputs in simpler languages while still informative. We also generate news headlines with various ideological leanings, which can be distinguished by humans with a reasonable probability.
SEFR: A Fast Linear-Time Classifier for Ultra-Low Power Devices
Jun 08, 2020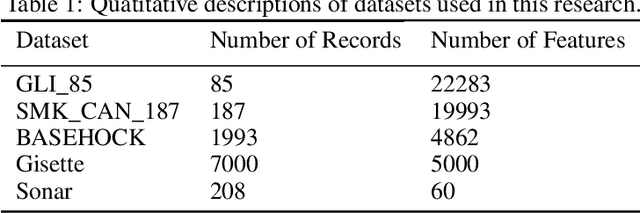
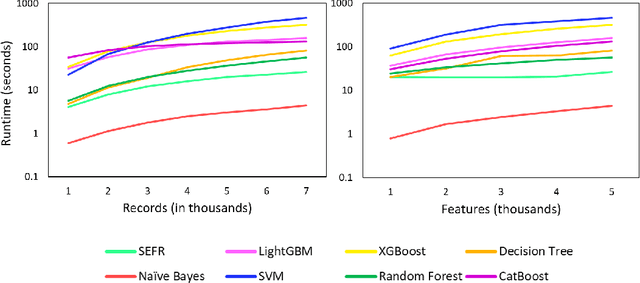
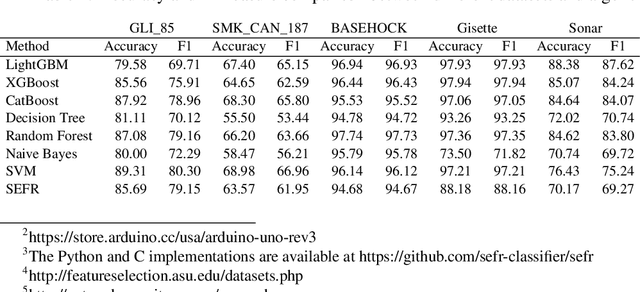
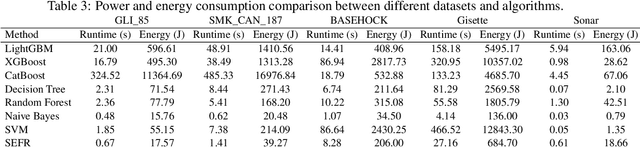
One of the fundamental challenges for running machine learning algorithms on battery-powered devices is the time and energy needed for computation, as these devices have constraints on resources. There are energy-efficient classifier algorithms, but their accuracy is often sacrificed for resource efficiency. Here, we propose an ultra-low power binary classifier, SEFR, with linear time complexity, both in the training and the testing phases. The SEFR method runs by creating a hyperplane to separate two classes. The weights of this hyperplane are calculated using normalization, and then the bias is computed based on the weights. SEFR is comparable to state-of-the-art classifiers in terms of classification accuracy, but its execution time and energy consumption are 11.02% and 8.67% of the average of state-of-the-art and baseline classifiers. The energy and memory consumption of SEFR is very insignificant, and it even can perform both train and test phases on microcontrollers. We have implemented SEFR on Arduino Uno, and on a dataset with 100 records and 100 features, the training time is 195 milliseconds, and testing for 100 records with 100 features takes 0.73 milliseconds. To the best of our knowledge, this is the first multipurpose algorithm specifically devised for learning on ultra-low power devices.
Smart Data Representations: Impact on the Accuracy of Deep Neural Networks
Nov 17, 2021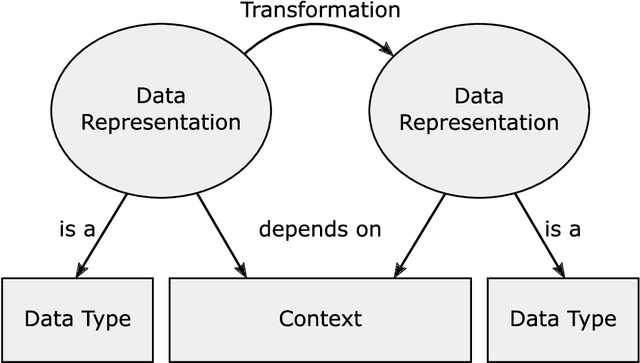


Deep Neural Networks are able to solve many complex tasks with less engineering effort and better performance. However, these networks often use data for training and evaluation without investigating its representation, i.e.~the form of the used data. In the present paper, we analyze the impact of data representations on the performance of Deep Neural Networks using energy time series forecasting. Based on an overview of exemplary data representations, we select four exemplary data representations and evaluate them using two different Deep Neural Network architectures and three forecasting horizons on real-world energy time series. The results show that, depending on the forecast horizon, the same data representations can have a positive or negative impact on the accuracy of Deep Neural Networks.