 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModels Got Talent: Identifying High Performing Wearable Human Activity Recognition Models Without Training
Nov 19, 2025A promising alternative to the computationally expensive Neural Architecture Search (NAS) involves the development of Zero Cost Proxies (ZCPs), which correlate well with trained performance, but can be computed through a single forward/backward pass on a randomly sampled batch of data. In this paper, we investigate the effectiveness of ZCPs for HAR on six benchmark datasets, and demonstrate that they discover network architectures that obtain within 5% of performance attained by full-scale training involving 1500 randomly sampled architectures. This results in substantial computational savings as high-performing architectures can be discovered with minimal training. Our experiments not only introduce ZCPs to sensor-based HAR, but also demonstrate that they are robust to data noise, further showcasing their suitability for practical scenarios.
Past, Present, and Future of Sensor-based Human Activity Recognition using Wearables: A Surveying Tutorial on a Still Challenging Task
Nov 11, 2024In the many years since the inception of wearable sensor-based Human Activity Recognition (HAR), a wide variety of methods have been introduced and evaluated for their ability to recognize activities. Substantial gains have been made since the days of hand-crafting heuristics as features, yet, progress has seemingly stalled on many popular benchmarks, with performance falling short of what may be considered 'sufficient'-- despite the increase in computational power and scale of sensor data, as well as rising complexity in techniques being employed. The HAR community approaches a new paradigm shift, this time incorporating world knowledge from foundational models. In this paper, we take stock of sensor-based HAR -- surveying it from its beginnings to the current state of the field, and charting its future. This is accompanied by a hands-on tutorial, through which we guide practitioners in developing HAR systems for real-world application scenarios. We provide a compendium for novices and experts alike, of methods that aim at finally solving the activity recognition problem.
Limitations in Employing Natural Language Supervision for Sensor-Based Human Activity Recognition -- And Ways to Overcome Them
Aug 21, 2024Cross-modal contrastive pre-training between natural language and other modalities, e.g., vision and audio, has demonstrated astonishing performance and effectiveness across a diverse variety of tasks and domains. In this paper, we investigate whether such natural language supervision can be used for wearable sensor based Human Activity Recognition (HAR), and discover that-surprisingly-it performs substantially worse than standard end-to-end training and self-supervision. We identify the primary causes for this as: sensor heterogeneity and the lack of rich, diverse text descriptions of activities. To mitigate their impact, we also develop strategies and assess their effectiveness through an extensive experimental evaluation. These strategies lead to significant increases in activity recognition, bringing performance closer to supervised and self-supervised training, while also enabling the recognition of unseen activities and cross modal retrieval of videos. Overall, our work paves the way for better sensor-language learning, ultimately leading to the development of foundational models for HAR using wearables.
Large Language Models Memorize Sensor Datasets! Implications on Human Activity Recognition Research
Jun 09, 2024



The astonishing success of Large Language Models (LLMs) in Natural Language Processing (NLP) has spurred their use in many application domains beyond text analysis, including wearable sensor-based Human Activity Recognition (HAR). In such scenarios, often sensor data are directly fed into an LLM along with text instructions for the model to perform activity classification. Seemingly remarkable results have been reported for such LLM-based HAR systems when they are evaluated on standard benchmarks from the field. Yet, we argue, care has to be taken when evaluating LLM-based HAR systems in such a traditional way. Most contemporary LLMs are trained on virtually the entire (accessible) internet -- potentially including standard HAR datasets. With that, it is not unlikely that LLMs actually had access to the test data used in such benchmark experiments.The resulting contamination of training data would render these experimental evaluations meaningless. In this paper we investigate whether LLMs indeed have had access to standard HAR datasets during training. We apply memorization tests to LLMs, which involves instructing the models to extend given snippets of data. When comparing the LLM-generated output to the original data we found a non-negligible amount of matches which suggests that the LLM under investigation seems to indeed have seen wearable sensor data from the benchmark datasets during training. For the Daphnet dataset in particular, GPT-4 is able to reproduce blocks of sensor readings. We report on our investigations and discuss potential implications on HAR research, especially with regards to reporting results on experimental evaluation
Layout Agnostic Human Activity Recognition in Smart Homes through Textual Descriptions Of Sensor Triggers (TDOST)
May 20, 2024



Human activity recognition (HAR) using ambient sensors in smart homes has numerous applications for human healthcare and wellness. However, building general-purpose HAR models that can be deployed to new smart home environments requires a significant amount of annotated sensor data and training overhead. Most smart homes vary significantly in their layouts, i.e., floor plans and the specifics of sensors embedded, resulting in low generalizability of HAR models trained for specific homes. We address this limitation by introducing a novel, layout-agnostic modeling approach for HAR systems in smart homes that utilizes the transferrable representational capacity of natural language descriptions of raw sensor data. To this end, we generate Textual Descriptions Of Sensor Triggers (TDOST) that encapsulate the surrounding trigger conditions and provide cues for underlying activities to the activity recognition models. Leveraging textual embeddings, rather than raw sensor data, we create activity recognition systems that predict standard activities across homes without either (re-)training or adaptation on target homes. Through an extensive evaluation, we demonstrate the effectiveness of TDOST-based models in unseen smart homes through experiments on benchmarked CASAS datasets. Furthermore, we conduct a detailed analysis of how the individual components of our approach affect downstream activity recognition performance.
Cross-Domain HAR: Few Shot Transfer Learning for Human Activity Recognition
Oct 22, 2023



The ubiquitous availability of smartphones and smartwatches with integrated inertial measurement units (IMUs) enables straightforward capturing of human activities. For specific applications of sensor based human activity recognition (HAR), however, logistical challenges and burgeoning costs render especially the ground truth annotation of such data a difficult endeavor, resulting in limited scale and diversity of datasets. Transfer learning, i.e., leveraging publicly available labeled datasets to first learn useful representations that can then be fine-tuned using limited amounts of labeled data from a target domain, can alleviate some of the performance issues of contemporary HAR systems. Yet they can fail when the differences between source and target conditions are too large and/ or only few samples from a target application domain are available, each of which are typical challenges in real-world human activity recognition scenarios. In this paper, we present an approach for economic use of publicly available labeled HAR datasets for effective transfer learning. We introduce a novel transfer learning framework, Cross-Domain HAR, which follows the teacher-student self-training paradigm to more effectively recognize activities with very limited label information. It bridges conceptual gaps between source and target domains, including sensor locations and type of activities. Through our extensive experimental evaluation on a range of benchmark datasets, we demonstrate the effectiveness of our approach for practically relevant few shot activity recognition scenarios. We also present a detailed analysis into how the individual components of our framework affect downstream performance.
Towards Learning Discrete Representations via Self-Supervision for Wearables-Based Human Activity Recognition
Jun 01, 2023



Human activity recognition (HAR) in wearable computing is typically based on direct processing of sensor data. Sensor readings are translated into representations, either derived through dedicated preprocessing, or integrated into end-to-end learning. Independent of their origin, for the vast majority of contemporary HAR, those representations are typically continuous in nature. That has not always been the case. In the early days of HAR, discretization approaches have been explored - primarily motivated by the desire to minimize computational requirements, but also with a view on applications beyond mere recognition, such as, activity discovery, fingerprinting, or large-scale search. Those traditional discretization approaches, however, suffer from substantial loss in precision and resolution in the resulting representations with detrimental effects on downstream tasks. Times have changed and in this paper we propose a return to discretized representations. We adopt and apply recent advancements in Vector Quantization (VQ) to wearables applications, which enables us to directly learn a mapping between short spans of sensor data and a codebook of vectors, resulting in recognition performance that is generally on par with their contemporary, continuous counterparts - sometimes surpassing them. Therefore, this work presents a proof-of-concept for demonstrating how effective discrete representations can be derived, enabling applications beyond mere activity classification but also opening up the field to advanced tools for the analysis of symbolic sequences, as they are known, for example, from domains such as natural language processing. Based on an extensive experimental evaluation on a suite of wearables-based benchmark HAR tasks, we demonstrate the potential of our learned discretization scheme and discuss how discretized sensor data analysis can lead to substantial changes in HAR.
Investigating Enhancements to Contrastive Predictive Coding for Human Activity Recognition
Nov 11, 2022The dichotomy between the challenging nature of obtaining annotations for activities, and the more straightforward nature of data collection from wearables, has resulted in significant interest in the development of techniques that utilize large quantities of unlabeled data for learning representations. Contrastive Predictive Coding (CPC) is one such method, learning effective representations by leveraging properties of time-series data to setup a contrastive future timestep prediction task. In this work, we propose enhancements to CPC, by systematically investigating the encoder architecture, the aggregator network, and the future timestep prediction, resulting in a fully convolutional architecture, thereby improving parallelizability. Across sensor positions and activities, our method shows substantial improvements on four of six target datasets, demonstrating its ability to empower a wide range of application scenarios. Further, in the presence of very limited labeled data, our technique significantly outperforms both supervised and self-supervised baselines, positively impacting situations where collecting only a few seconds of labeled data may be possible. This is promising, as CPC does not require specialized data transformations or reconstructions for learning effective representations.
Multi-Stage Based Feature Fusion of Multi-Modal Data for Human Activity Recognition
Nov 08, 2022To properly assist humans in their needs, human activity recognition (HAR) systems need the ability to fuse information from multiple modalities. Our hypothesis is that multimodal sensors, visual and non-visual tend to provide complementary information, addressing the limitations of other modalities. In this work, we propose a multi-modal framework that learns to effectively combine features from RGB Video and IMU sensors, and show its robustness for MMAct and UTD-MHAD datasets. Our model is trained in two-stage, where in the first stage, each input encoder learns to effectively extract features, and in the second stage, learns to combine these individual features. We show significant improvements of 22% and 11% compared to video only and IMU only setup on UTD-MHAD dataset, and 20% and 12% on MMAct datasets. Through extensive experimentation, we show the robustness of our model on zero shot setting, and limited annotated data setting. We further compare with state-of-the-art methods that use more input modalities and show that our method outperforms significantly on the more difficult MMact dataset, and performs comparably in UTD-MHAD dataset.
Assessing the State of Self-Supervised Human Activity Recognition using Wearables
Feb 22, 2022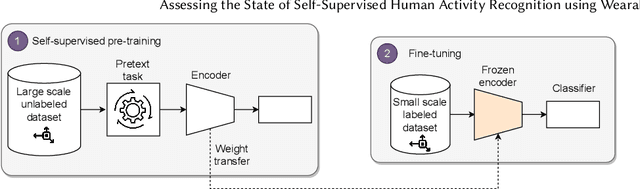

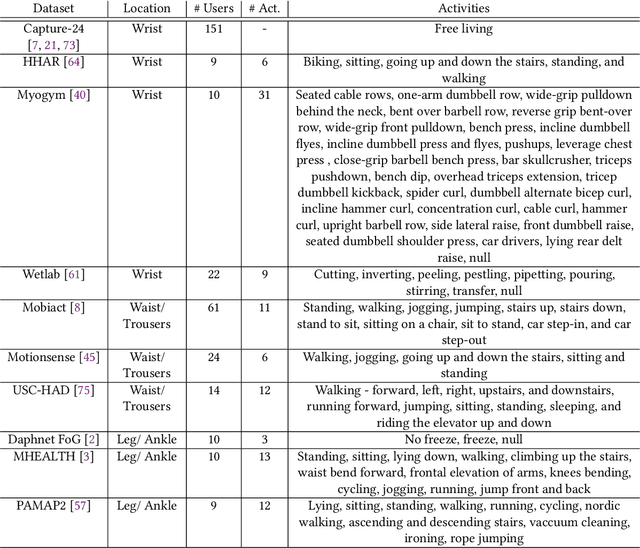
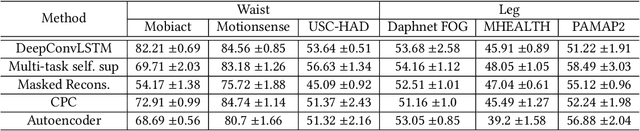
The emergence of self-supervised learning in the field of wearables-based human activity recognition (HAR) has opened up opportunities to tackle the most pressing challenges in the field, namely to exploit unlabeled data to derive reliable recognition systems from only small amounts of labeled training samples. Furthermore, self-supervised methods enable a host of new application domains such as, for example, domain adaptation and transfer across sensor positions, activities etc. As such, self-supervision, i.e., the paradigm of 'pretrain-then-finetune' has the potential to become a strong alternative to the predominant end-to-end training approaches, let alone the classic activity recognition chain with hand-crafted features of sensor data. Recently a number of contributions have been made that introduced self-supervised learning into the field of HAR, including, Multi-task self-supervision, Masked Reconstruction, CPC to name but a few. With the initial success of these methods, the time has come for a systematic inventory and analysis of the potential self-supervised learning has for the field. This paper provides exactly that. We assess the progress of self-supervised HAR research by introducing a framework that performs a multi-faceted exploration of model performance. We organize the framework into three dimensions, each containing three constituent criteria, and utilize it to assess state-of-the-art self-supervised learning methods in a large empirical study on a curated set of nine diverse benchmarks. This exploration leads us to the formulation of insights into the properties of these techniques and to establish their value towards learning representations for diverse scenarios. Based on our findings we call upon the community to join our efforts and to contribute towards shaping the evaluation of the ongoing paradigm change in modeling human activities from body-worn sensor data.