 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Zero-Reference Image Restoration for Under-Display Camera of UAV
Feb 13, 2022
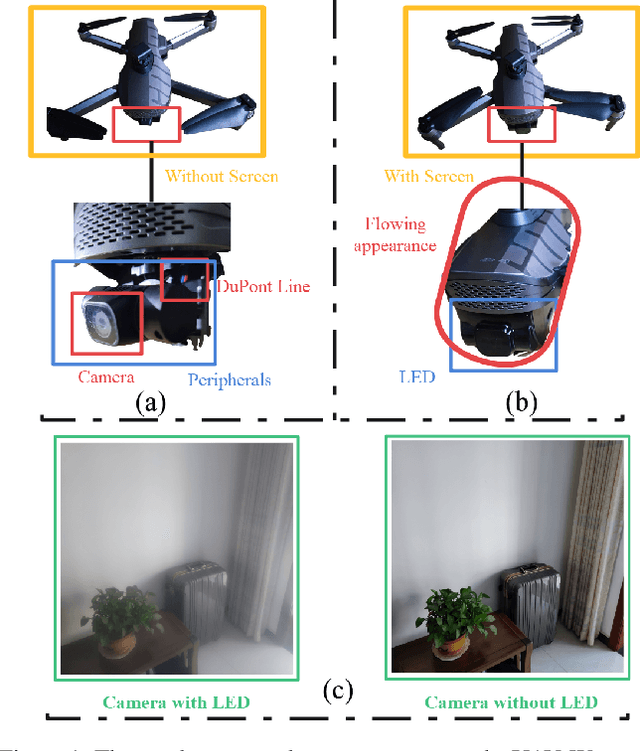
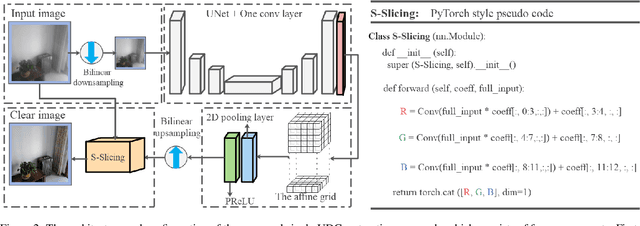


The exposed cameras of UAV can shake, shift, or even malfunction under the influence of harsh weather, while the add-on devices (Dupont lines) are very vulnerable to damage. We can place a low-cost T-OLED overlay around the camera to protect it, but this would also introduce image degradation issues. In particular, the temperature variations in the atmosphere can create mist that adsorbs to the T-OLED, which can cause secondary disasters (i.e., more severe image degradation) during the UAV's filming process. To solve the image degradation problem caused by overlaying T-OLEDs, in this paper we propose a new method to enhance the visual experience by enhancing the texture and color of images. Specifically, our method trains a lightweight network to estimate a low-rank affine grid on the input image, and then utilizes the grid to enhance the input image at block granularity. The advantages of our method are that no reference image is required and the loss function is developed from visual experience. In addition, our model can perform high-quality recovery of images of arbitrary resolution in real time. In the end, the limitations of our model and the collected datasets (including the daytime and nighttime scenes) are discussed.
Super-resolution in Molecular Dynamics Trajectory Reconstruction with Bi-Directional Neural Networks
Jan 02, 2022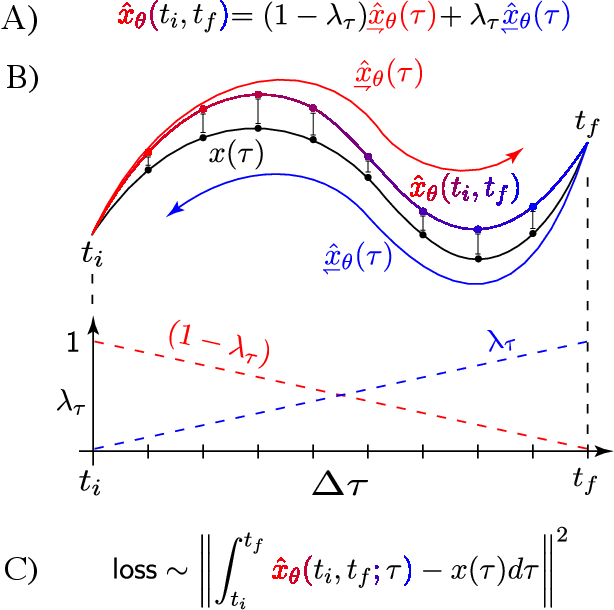
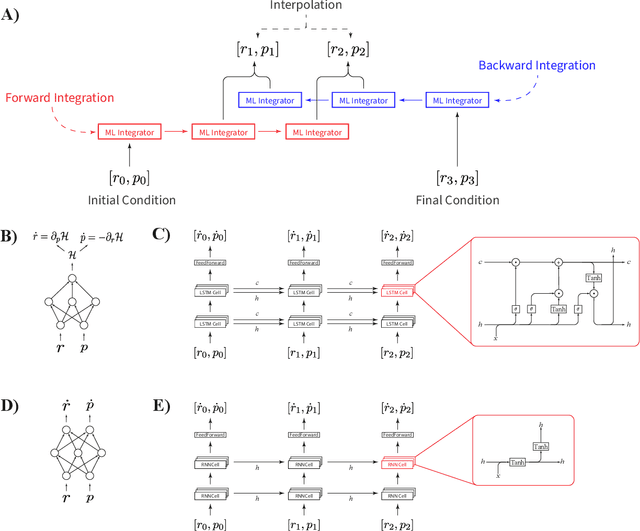
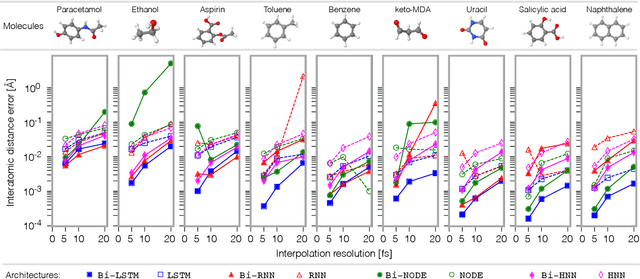
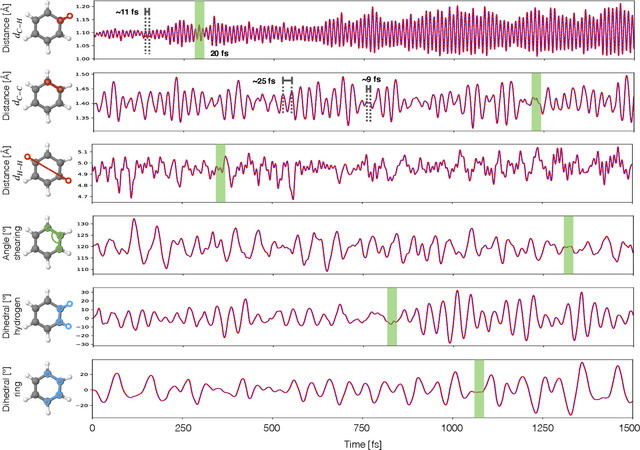
Molecular dynamics simulations are a cornerstone in science, allowing to investigate from the system's thermodynamics to analyse intricate molecular interactions. In general, to create extended molecular trajectories can be a computationally expensive process, for example, when running $ab-initio$ simulations. Hence, repeating such calculations to either obtain more accurate thermodynamics or to get a higher resolution in the dynamics generated by a fine-grained quantum interaction can be time- and computationally-consuming. In this work, we explore different machine learning (ML) methodologies to increase the resolution of molecular dynamics trajectories on-demand within a post-processing step. As a proof of concept, we analyse the performance of bi-directional neural networks such as neural ODEs, Hamiltonian networks, recurrent neural networks and LSTMs, as well as the uni-directional variants as a reference, for molecular dynamics simulations (here: the MD17 dataset). We have found that Bi-LSTMs are the best performing models; by utilizing the local time-symmetry of thermostated trajectories they can even learn long-range correlations and display high robustness to noisy dynamics across molecular complexity. Our models can reach accuracies of up to 10$^{-4}$ angstroms in trajectory interpolation, while faithfully reconstructing several full cycles of unseen intricate high-frequency molecular vibrations, rendering the comparison between the learned and reference trajectories indistinguishable. The results reported in this work can serve (1) as a baseline for larger systems, as well as (2) for the construction of better MD integrators.
Effective Training Strategies for Deep-learning-based Precipitation Nowcasting and Estimation
Feb 17, 2022
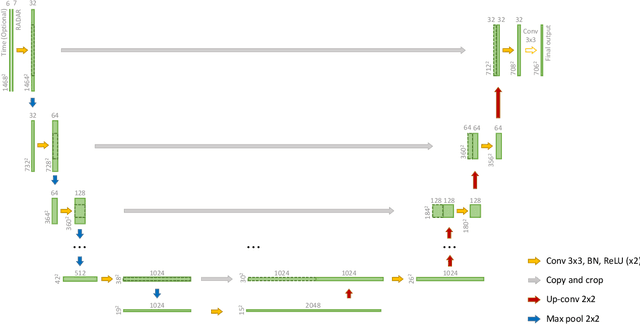
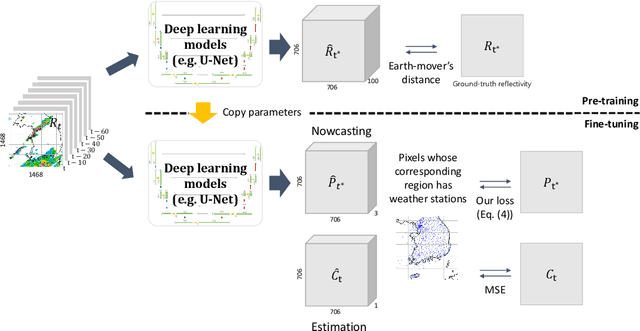
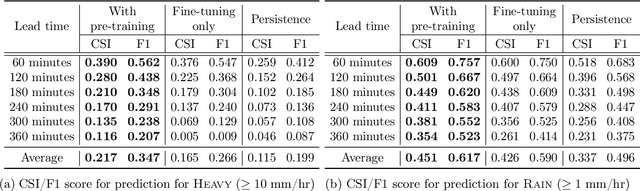
Deep learning has been successfully applied to precipitation nowcasting. In this work, we propose a pre-training scheme and a new loss function for improving deep-learning-based nowcasting. First, we adapt U-Net, a widely-used deep-learning model, for the two problems of interest here: precipitation nowcasting and precipitation estimation from radar images. We formulate the former as a classification problem with three precipitation intervals and the latter as a regression problem. For these tasks, we propose to pre-train the model to predict radar images in the near future without requiring ground-truth precipitation, and we also propose the use of a new loss function for fine-tuning to mitigate the class imbalance problem. We demonstrate the effectiveness of our approach using radar images and precipitation datasets collected from South Korea over seven years. It is highlighted that our pre-training scheme and new loss function improve the critical success index (CSI) of nowcasting of heavy rainfall (at least 10 mm/hr) by up to 95.7% and 43.6%, respectively, at a 5-hr lead time. We also demonstrate that our approach reduces the precipitation estimation error by up to 10.7%, compared to the conventional approach, for light rainfall (between 1 and 10 mm/hr). Lastly, we report the sensitivity of our approach to different resolutions and a detailed analysis of four cases of heavy rainfall.
Oracle-Efficient Online Learning for Beyond Worst-Case Adversaries
Feb 17, 2022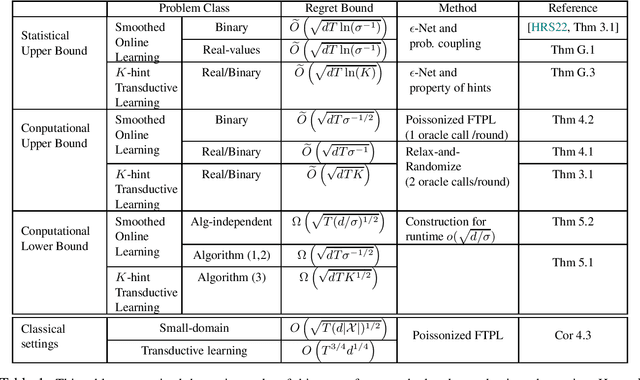
In this paper, we study oracle-efficient algorithms for beyond worst-case analysis of online learning. We focus on two settings. First, the smoothed analysis setting of [RST11, HRS12] where an adversary is constrained to generating samples from distributions whose density is upper bounded by $1/\sigma$ times the uniform density. Second, the setting of $K$-hint transductive learning, where the learner is given access to $K$ hints per time step that are guaranteed to include the true instance. We give the first known oracle-efficient algorithms for both settings that depend only on the VC dimension of the class and parameters $\sigma$ and $K$ that capture the power of the adversary. In particular, we achieve oracle-efficient regret bounds of $ O ( \sqrt{T (d / \sigma )^{1/2} } ) $ and $ O ( \sqrt{T d K } )$ respectively for these setting. For the smoothed analysis setting, our results give the first oracle-efficient algorithm for online learning with smoothed adversaries [HRS21]. This contrasts the computational separation between online learning with worst-case adversaries and offline learning established by [HK16]. Our algorithms also imply improved bounds for worst-case setting with small domains. In particular, we give an oracle-efficient algorithm with regret of $O ( \sqrt{T(d \vert{\mathcal{X}}\vert ) ^{1/2} })$, which is a refinement of the earlier $O ( \sqrt{T\vert{\mathcal{X} } \vert })$ bound by [DS16].
Recursive Two-Step Lookahead Expected Payoff for Time-Dependent Bayesian Optimization
Jun 14, 2020

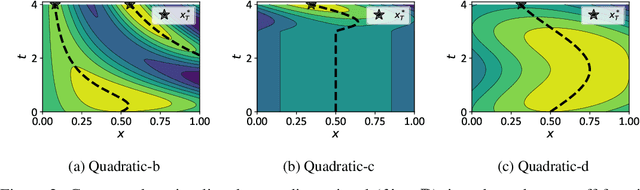

We propose a novel Bayesian method to solve the maximization of a time-dependent expensive-to-evaluate oracle. We are interested in the decision that maximizes the oracle at a finite time horizon, when relatively few noisy evaluations can be performed before the horizon. Our recursive, two-step lookahead expected payoff ($\texttt{r2LEY}$) acquisition function makes nonmyopic decisions at every stage by maximizing the estimated expected value of the oracle at the horizon. $\texttt{r2LEY}$ circumvents the evaluation of the expensive multistep (more than two steps) lookahead acquisition function by recursively optimizing a two-step lookahead acquisition function at every stage; unbiased estimators of this latter function and its gradient are utilized for efficient optimization. $\texttt{r2LEY}$ is shown to exhibit natural exploration properties far from the time horizon, enabling accurate emulation of the oracle, which is exploited in the final decision made at the horizon. To demonstrate the utility of $\texttt{r2LEY}$, we compare it with time-dependent extensions of popular myopic acquisition functions via both synthetic and real-world datasets.
A Speech Intelligibility Enhancement Model based on Canonical Correlation and Deep Learning for Hearing-Assistive Technologies
Feb 08, 2022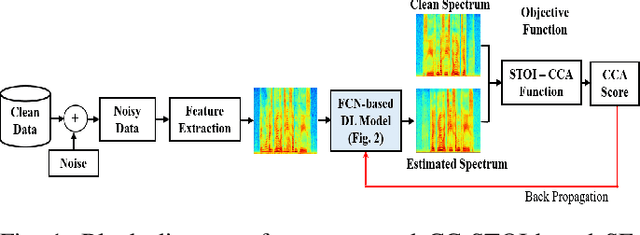
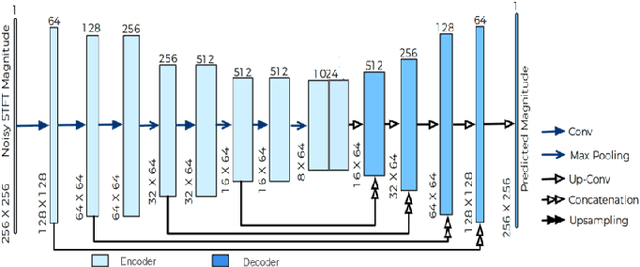
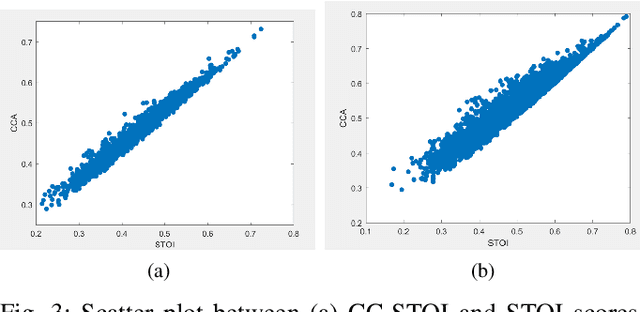
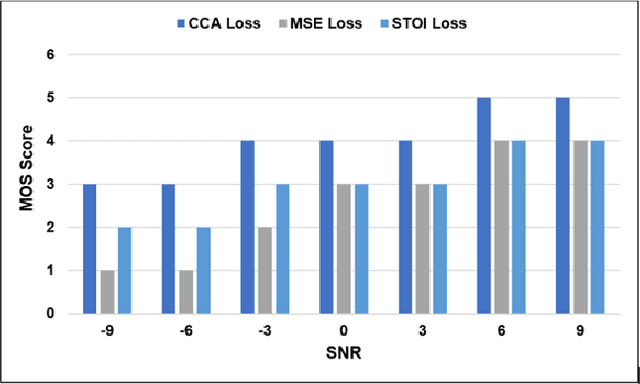
Current deep learning (DL) based approaches to speech intelligibility enhancement in noisy environments are generally trained to minimise the distance between clean and enhanced speech features. These often result in improved speech quality however they suffer from a lack of generalisation and may not deliver the required speech intelligibility in everyday noisy situations. In an attempt to address these challenges, researchers have explored intelligibility-oriented (I-O) loss functions to train DL approaches for robust speech enhancement (SE). In this paper, we formulate a novel canonical correlation-based I-O loss function to more effectively train DL algorithms. Specifically, we present a fully convolutional SE model that uses a modified canonical-correlation based short-time objective intelligibility (CC-STOI) metric as a training cost function. To the best of our knowledge, this is the first work that exploits the integration of canonical correlation in an I-O based loss function for SE. Comparative experimental results demonstrate that our proposed CC-STOI based SE framework outperforms DL models trained with conventional STOI and distance-based loss functions, in terms of both standard objective and subjective evaluation measures when dealing with unseen speakers and noises.
The Lifecycle of a Statistical Model: Model Failure Detection, Identification, and Refitting
Feb 08, 2022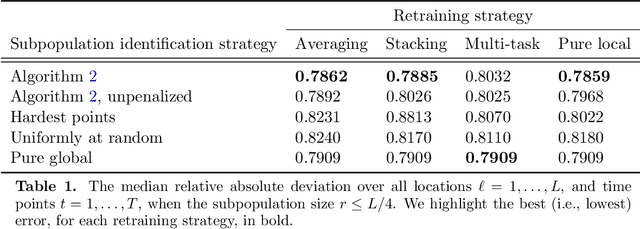
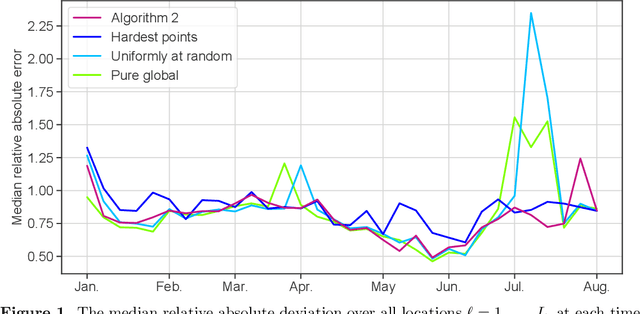
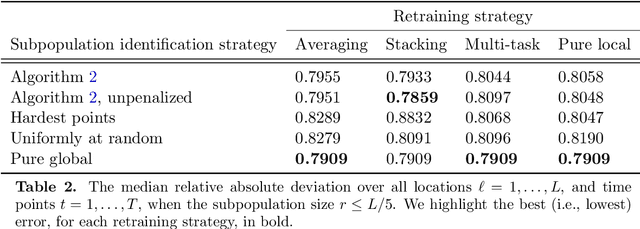
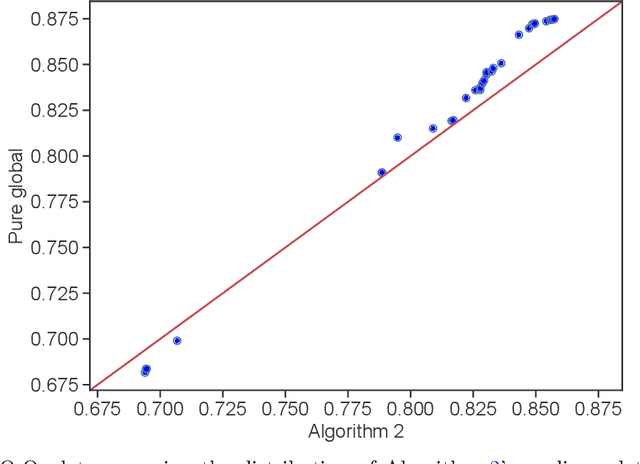
The statistical machine learning community has demonstrated considerable resourcefulness over the years in developing highly expressive tools for estimation, prediction, and inference. The bedrock assumptions underlying these developments are that the data comes from a fixed population and displays little heterogeneity. But reality is significantly more complex: statistical models now routinely fail when released into real-world systems and scientific applications, where such assumptions rarely hold. Consequently, we pursue a different path in this paper vis-a-vis the well-worn trail of developing new methodology for estimation and prediction. In this paper, we develop tools and theory for detecting and identifying regions of the covariate space (subpopulations) where model performance has begun to degrade, and study intervening to fix these failures through refitting. We present empirical results with three real-world data sets -- including a time series involving forecasting the incidence of COVID-19 -- showing that our methodology generates interpretable results, is useful for tracking model performance, and can boost model performance through refitting. We complement these empirical results with theory proving that our methodology is minimax optimal for recovering anomalous subpopulations as well as refitting to improve accuracy in a structured normal means setting.
Unified Characterization and Precoding for Non-Stationary Channels
Feb 08, 2022
Modern wireless channels are increasingly dense and mobile making the channel highly non-stationary. The time-varying distribution and the existence of joint interference across multiple degrees of freedom (e.g., users, antennas, frequency and symbols) in such channels render conventional precoding sub-optimal in practice, and have led to historically poor characterization of their statistics. The core of our work is the derivation of a high-order generalization of Mercer's Theorem to decompose the non-stationary channel into constituent fading sub-channels (2-D eigenfunctions) that are jointly orthogonal across its degrees of freedom. Consequently, transmitting these eigenfunctions with optimally derived coefficients eventually mitigates any interference across these dimensions and forms the foundation of the proposed joint spatio-temporal precoding. The precoded symbols directly reconstruct the data symbols at the receiver upon demodulation, thereby significantly reducing its computational burden, by alleviating the need for any complementary decoding. These eigenfunctions are paramount to extracting the second-order channel statistics, and therefore completely characterize the underlying channel. Theory and simulations show that such precoding leads to ${>}10^4{\times}$ BER improvement (at 20dB) over existing methods for non-stationary channels.
CLS: Cross Labeling Supervision for Semi-Supervised Learning
Feb 17, 2022
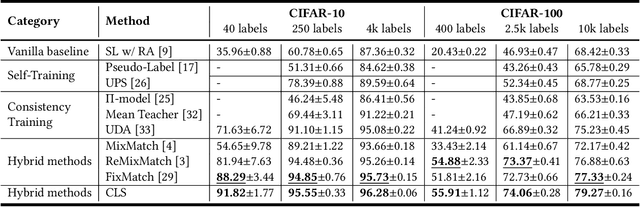
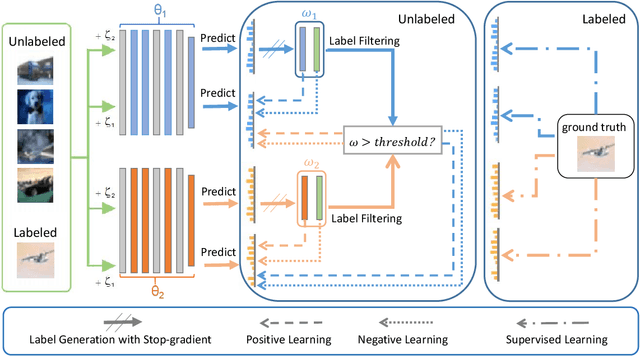
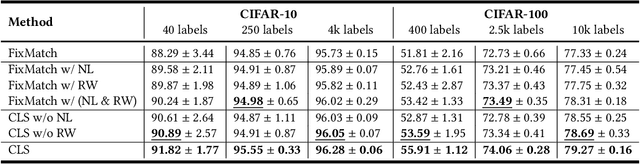
It is well known that the success of deep neural networks is greatly attributed to large-scale labeled datasets. However, it can be extremely time-consuming and laborious to collect sufficient high-quality labeled data in most practical applications. Semi-supervised learning (SSL) provides an effective solution to reduce the cost of labeling by simultaneously leveraging both labeled and unlabeled data. In this work, we present Cross Labeling Supervision (CLS), a framework that generalizes the typical pseudo-labeling process. Based on FixMatch, where a pseudo label is generated from a weakly-augmented sample to teach the prediction on a strong augmentation of the same input sample, CLS allows the creation of both pseudo and complementary labels to support both positive and negative learning. To mitigate the confirmation bias of self-labeling and boost the tolerance to false labels, two different initialized networks with the same structure are trained simultaneously. Each network utilizes high-confidence labels from the other network as additional supervision signals. During the label generation phase, adaptive sample weights are assigned to artificial labels according to their prediction confidence. The sample weight plays two roles: quantify the generated labels' quality and reduce the disruption of inaccurate labels on network training. Experimental results on the semi-supervised classification task show that our framework outperforms existing approaches by large margins on the CIFAR-10 and CIFAR-100 datasets.
Feels Bad Man: Dissecting Automated Hateful Meme Detection Through the Lens of Facebook's Challenge
Feb 17, 2022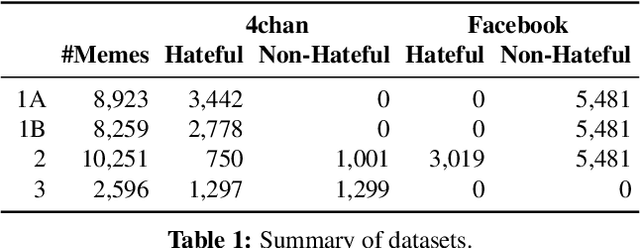
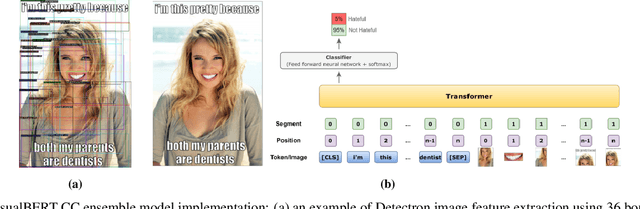

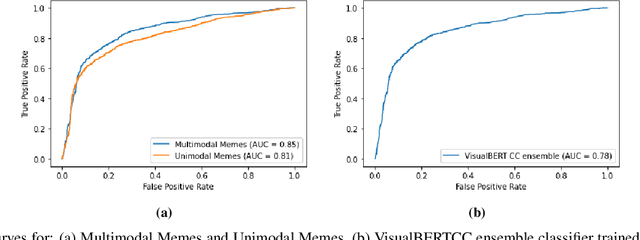
Internet memes have become a dominant method of communication; at the same time, however, they are also increasingly being used to advocate extremism and foster derogatory beliefs. Nonetheless, we do not have a firm understanding as to which perceptual aspects of memes cause this phenomenon. In this work, we assess the efficacy of current state-of-the-art multimodal machine learning models toward hateful meme detection, and in particular with respect to their generalizability across platforms. We use two benchmark datasets comprising 12,140 and 10,567 images from 4chan's "Politically Incorrect" board (/pol/) and Facebook's Hateful Memes Challenge dataset to train the competition's top-ranking machine learning models for the discovery of the most prominent features that distinguish viral hateful memes from benign ones. We conduct three experiments to determine the importance of multimodality on classification performance, the influential capacity of fringe Web communities on mainstream social platforms and vice versa, and the models' learning transferability on 4chan memes. Our experiments show that memes' image characteristics provide a greater wealth of information than its textual content. We also find that current systems developed for online detection of hate speech in memes necessitate further concentration on its visual elements to improve their interpretation of underlying cultural connotations, implying that multimodal models fail to adequately grasp the intricacies of hate speech in memes and generalize across social media platforms.