 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bandit Change-Point Detection for Real-Time Monitoring High-Dimensional Data Under Sampling Control
Sep 24, 2020
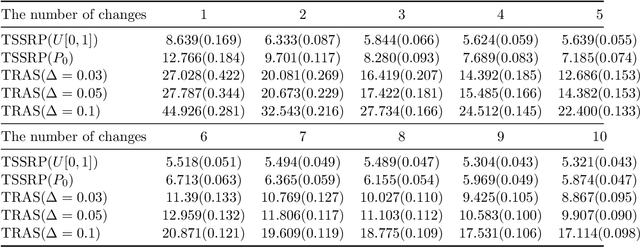
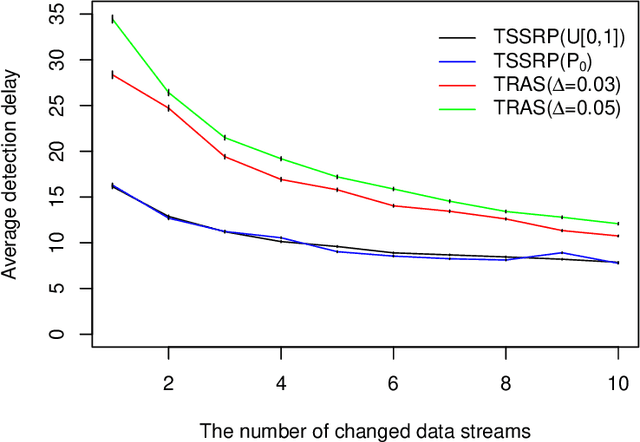

In many real-world problems of real-time monitoring high-dimensional streaming data, one wants to detect an undesired event or change quickly once it occurs, but under the sampling control constraint in the sense that one might be able to only observe or use selected components data for decision-making per time step in the resource-constrained environments. In this paper, we propose to incorporate multi-armed bandit approaches into sequential change-point detection to develop an efficient bandit change-point detection algorithm. Our proposed algorithm, termed Thompson-Sampling-Shiryaev-Roberts-Pollak (TSSRP), consists of two policies per time step: the adaptive sampling policy applies the Thompson Sampling algorithm to balance between exploration for acquiring long-term knowledge and exploitation for immediate reward gain, and the statistical decision policy fuses the local Shiryaev-Roberts-Pollak statistics to determine whether to raise a global alarm by sum shrinkage techniques. Extensive numerical simulations and case studies demonstrate the statistical and computational efficiency of our proposed TSSRP algorithm.
Provable and Efficient Continual Representation Learning
Mar 03, 2022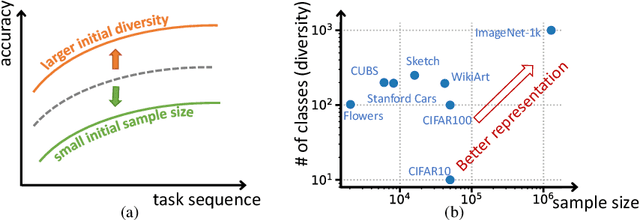
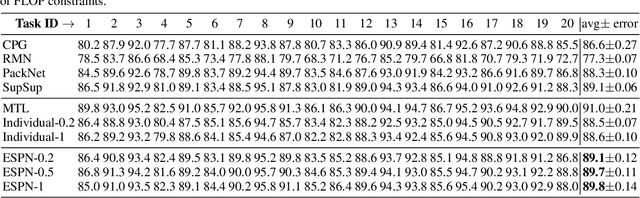
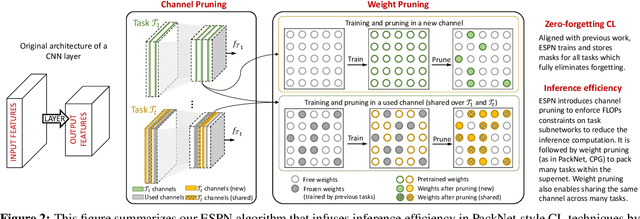
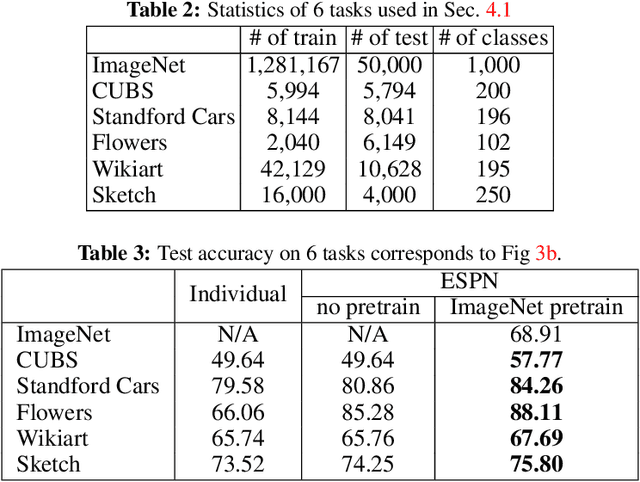
In continual learning (CL), the goal is to design models that can learn a sequence of tasks without catastrophic forgetting. While there is a rich set of techniques for CL, relatively little understanding exists on how representations built by previous tasks benefit new tasks that are added to the network. To address this, we study the problem of continual representation learning (CRL) where we learn an evolving representation as new tasks arrive. Focusing on zero-forgetting methods where tasks are embedded in subnetworks (e.g., PackNet), we first provide experiments demonstrating CRL can significantly boost sample efficiency when learning new tasks. To explain this, we establish theoretical guarantees for CRL by providing sample complexity and generalization error bounds for new tasks by formalizing the statistical benefits of previously-learned representations. Our analysis and experiments also highlight the importance of the order in which we learn the tasks. Specifically, we show that CL benefits if the initial tasks have large sample size and high "representation diversity". Diversity ensures that adding new tasks incurs small representation mismatch and can be learned with few samples while training only few additional nonzero weights. Finally, we ask whether one can ensure each task subnetwork to be efficient during inference time while retaining the benefits of representation learning. To this end, we propose an inference-efficient variation of PackNet called Efficient Sparse PackNet (ESPN) which employs joint channel & weight pruning. ESPN embeds tasks in channel-sparse subnets requiring up to 80% less FLOPs to compute while approximately retaining accuracy and is very competitive with a variety of baselines. In summary, this work takes a step towards data and compute-efficient CL with a representation learning perspective. GitHub page: https://github.com/ucr-optml/CtRL
TASO: Time and Space Optimization for Memory-Constrained DNN Inference
May 21, 2020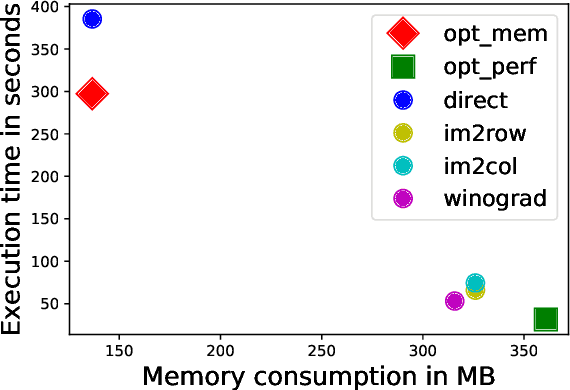
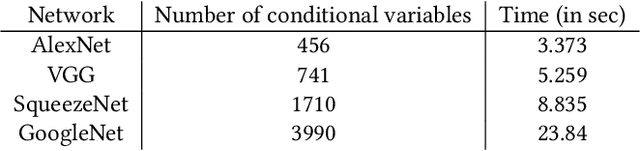

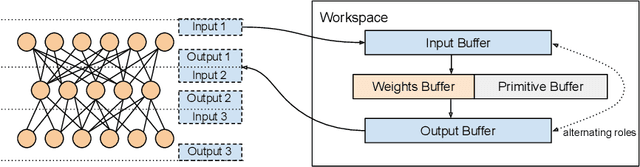
Convolutional neural networks (CNNs) are used in many embedded applications, from industrial robotics and automation systems to biometric identification on mobile devices. State-of-the-art classification is typically achieved by large networks, which are prohibitively expensive to run on mobile and embedded devices with tightly constrained memory and energy budgets. We propose an approach for ahead-of-time domain specific optimization of CNN models, based on an integer linear programming (ILP) for selecting primitive operations to implement convolutional layers. We optimize the trade-off between execution time and memory consumption by: 1) attempting to minimize execution time across the whole network by selecting data layouts and primitive operations to implement each layer; and 2) allocating an appropriate workspace that reflects the upper bound of memory footprint per layer. These two optimization strategies can be used to run any CNN on any platform with a C compiler. Our evaluation with a range of popular ImageNet neural architectures (GoogleNet, AlexNet, VGG, ResNet and SqueezeNet) on the ARM Cortex-A15 yields speedups of 8x compared to a greedy algorithm based primitive selection, reduces memory requirement by 2.2x while sacrificing only 15% of inference time compared to a solver that considers inference time only. In addition, our optimization approach exposes a range of optimal points for different configurations across the Pareto frontier of memory and latency trade-off, which can be used under arbitrary system constraints.
PL-VINS: Real-Time Monocular Visual-Inertial SLAM with Point and Line
Sep 16, 2020
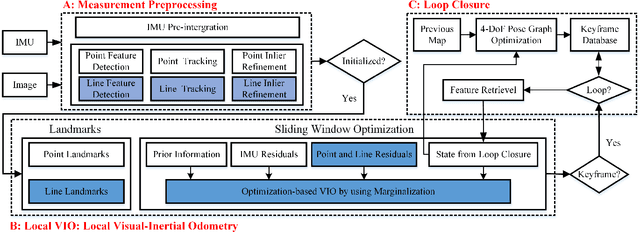

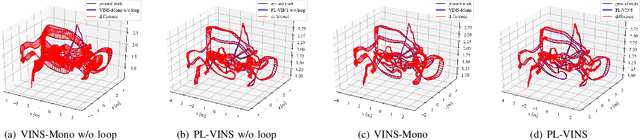
Leveraging line features to improve location accuracy of point-based visual-inertial SLAM (VINS) is gaining importance as they provide additional constraint of scene structure regularity, however, real-time performance has not been focused. This paper presents PL-VINS, a real-time optimization-based monocular VINS method with point and line, developed based on state-of-the-art point-based VINS-Mono \cite{vins}. Observe that current works use LSD \cite{lsd} algorithm to extract lines, however, the LSD is designed for scene shape representation instead of specific pose estimation problem, which becomes the bottleneck for the real-time performance due to its expensive cost. In this work, a modified LSD algorithm is presented by studying hidden parameter tuning and length rejection strategy. The modified LSD can run three times at least as fast as the LSD. Further, by representing a line landmark with Pl\"{u}cker coordinate, the line reprojection residual is modeled as midpoint-to-line distance then minimized by iteratively updating the minimum four-parameter orthonormal representation of the Pl\"{u}cker coordinate. Experiments in public EuRoc benchmark dataset show the location error of our method is down 12-16\% compared to VINS-Mono at the same work frequency on a low-power CPU @1.1 GHz without GPU parallelization. For the benefit of the community, we make public the source code: \textit{https://github.com/cnqiangfu/PL-VINS
Learning to Evolve on Dynamic Graphs
Nov 13, 2021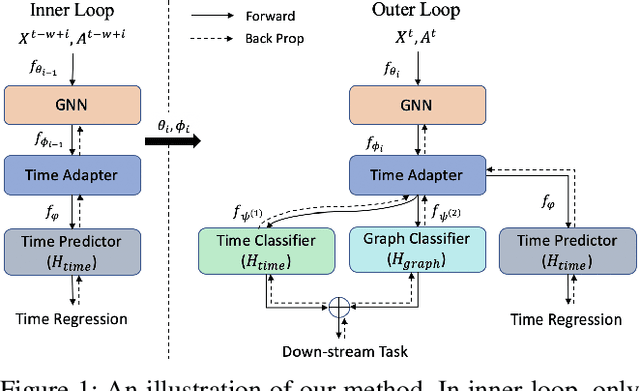

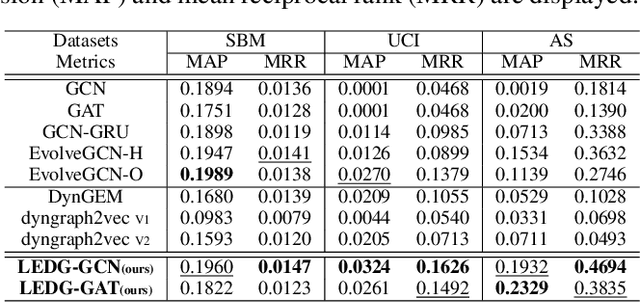
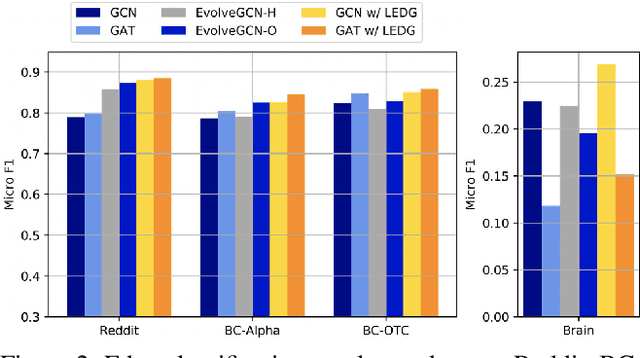
Representation learning in dynamic graphs is a challenging problem because the topology of graph and node features vary at different time. This requires the model to be able to effectively capture both graph topology information and temporal information. Most existing works are built on recurrent neural networks (RNNs), which are used to exact temporal information of dynamic graphs, and thus they inherit the same drawbacks of RNNs. In this paper, we propose Learning to Evolve on Dynamic Graphs (LEDG) - a novel algorithm that jointly learns graph information and time information. Specifically, our approach utilizes gradient-based meta-learning to learn updating strategies that have better generalization ability than RNN on snapshots. It is model-agnostic and thus can train any message passing based graph neural network (GNN) on dynamic graphs. To enhance the representation power, we disentangle the embeddings into time embeddings and graph intrinsic embeddings. We conduct experiments on various datasets and down-stream tasks, and the experimental results validate the effectiveness of our method.
Fair Latency-Aware Metric for real-time video segmentation networks
Apr 06, 2020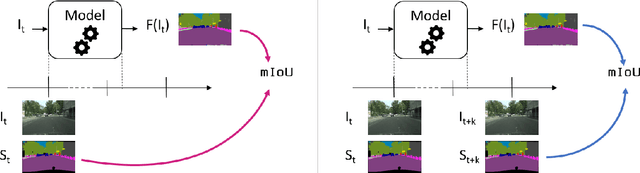
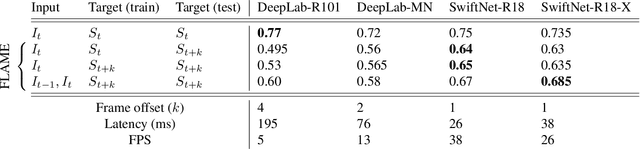
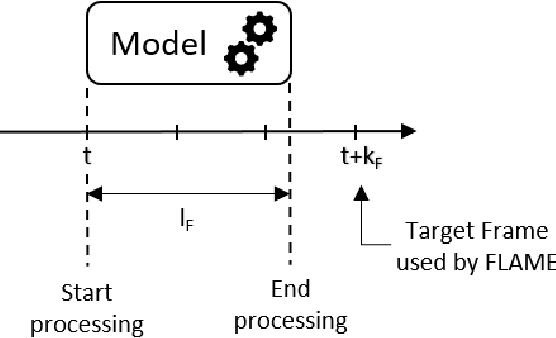
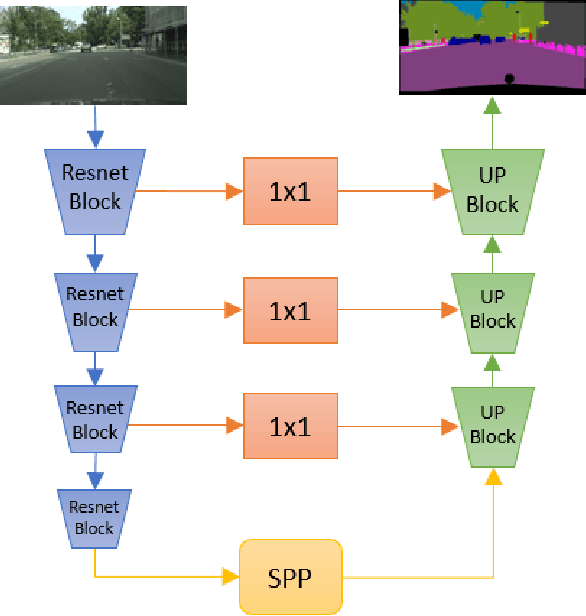
As supervised semantic segmentation is reaching satisfying results, many recent papers focused on making segmentation network architectures faster, smaller and more efficient. In particular, studies often aim to reach the stage to which they can claim to be "real-time". Achieving this goal is especially relevant in the context of real-time video operations for autonomous vehicles and robots, or medical imaging during surgery. The common metric used for assessing these methods is so far the same as the ones used for image segmentation without time constraint: mean Intersection over Union (mIoU). In this paper, we argue that this metric is not relevant enough for real-time video as it does not take into account the processing time (latency) of the network. We propose a similar but more relevant metric called FLAME for video-segmentation networks, that compares the output segmentation of the network with the ground truth segmentation of the current video frame at the time when the network finishes the processing. We perform experiments to compare a few networks using this metric and propose a simple addition to network training to enhance results according to that metric.
Adjoint-aided inference of Gaussian process driven differential equations
Feb 09, 2022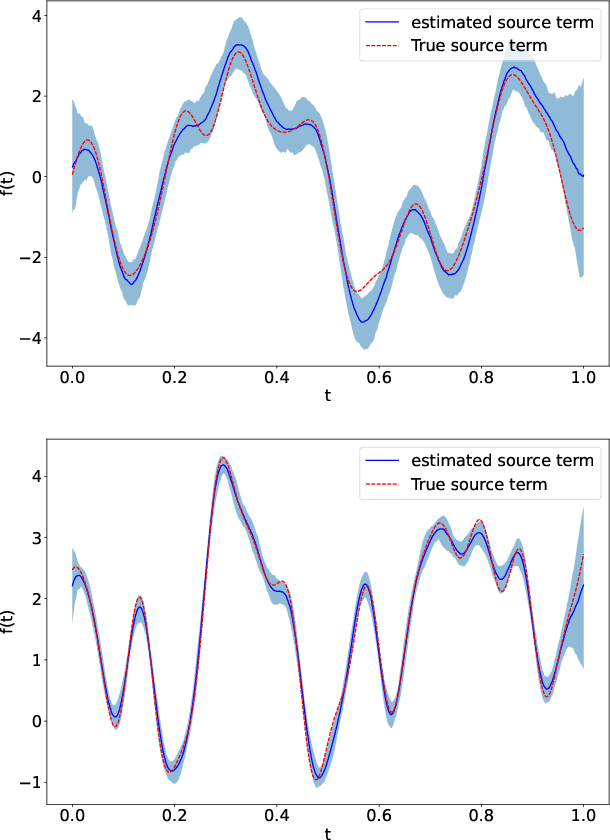
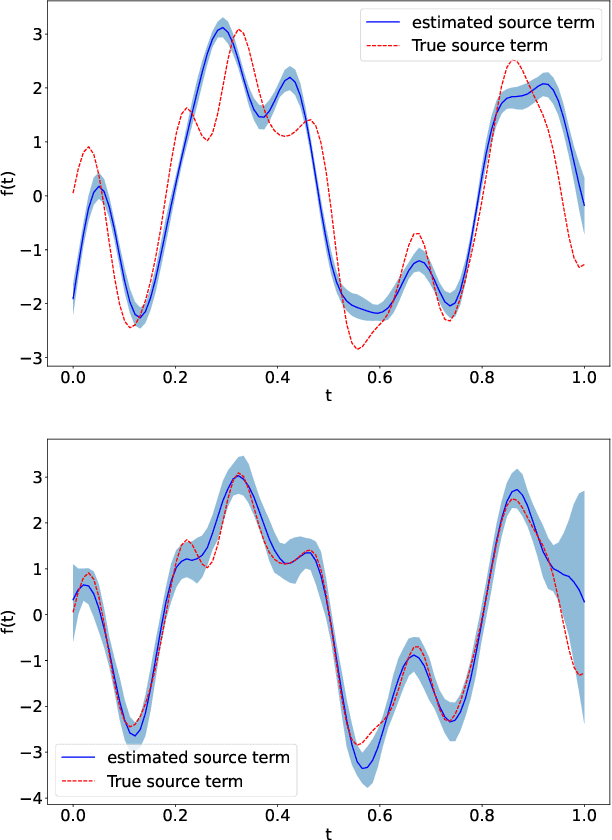
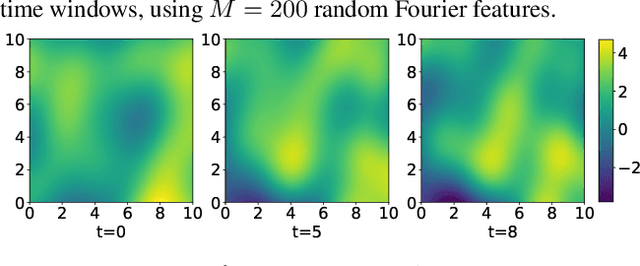
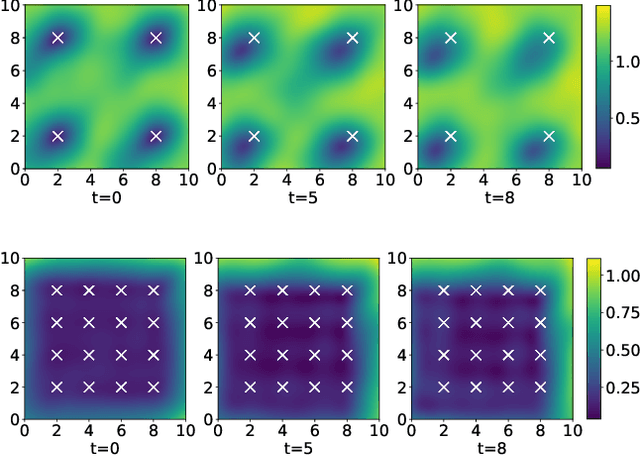
Linear systems occur throughout engineering and the sciences, most notably as differential equations. In many cases the forcing function for the system is unknown, and interest lies in using noisy observations of the system to infer the forcing, as well as other unknown parameters. In differential equations, the forcing function is an unknown function of the independent variables (typically time and space), and can be modelled as a Gaussian process (GP). In this paper we show how the adjoint of a linear system can be used to efficiently infer forcing functions modelled as GPs, after using a truncated basis expansion of the GP kernel. We show how exact conjugate Bayesian inference for the truncated GP can be achieved, in many cases with substantially lower computation than would be required using MCMC methods. We demonstrate the approach on systems of both ordinary and partial differential equations, and by testing on synthetic data, show that the basis expansion approach approximates well the true forcing with a modest number of basis vectors. Finally, we show how to infer point estimates for the non-linear model parameters, such as the kernel length-scales, using Bayesian optimisation.
StandardSim: A Synthetic Dataset For Retail Environments
Feb 04, 2022
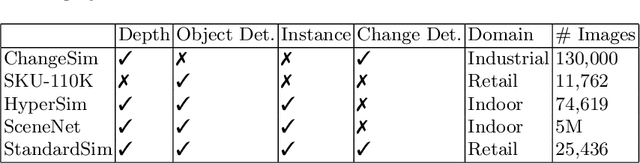

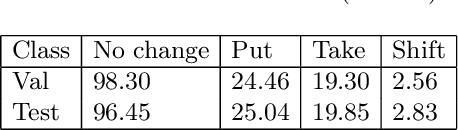
Autonomous checkout systems rely on visual and sensory inputs to carry out fine-grained scene understanding in retail environments. Retail environments present unique challenges compared to typical indoor scenes owing to the vast number of densely packed, unique yet similar objects. The problem becomes even more difficult when only RGB input is available, especially for data-hungry tasks such as instance segmentation. To address the lack of datasets for retail, we present StandardSim, a large-scale photorealistic synthetic dataset featuring annotations for semantic segmentation, instance segmentation, depth estimation, and object detection. Our dataset provides multiple views per scene, enabling multi-view representation learning. Further, we introduce a novel task central to autonomous checkout called change detection, requiring pixel-level classification of takes, puts and shifts in objects over time. We benchmark widely-used models for segmentation and depth estimation on our dataset, show that our test set constitutes a difficult benchmark compared to current smaller-scale datasets and that our training set provides models with crucial information for autonomous checkout tasks.
Fourier ptychography multi-parameter neural network with composite physical priori optimization
Feb 18, 2022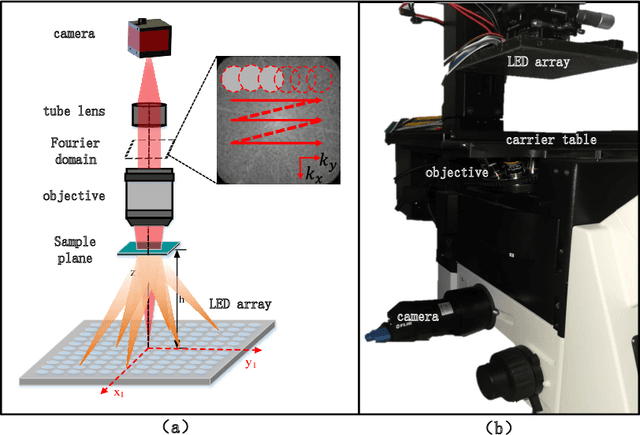
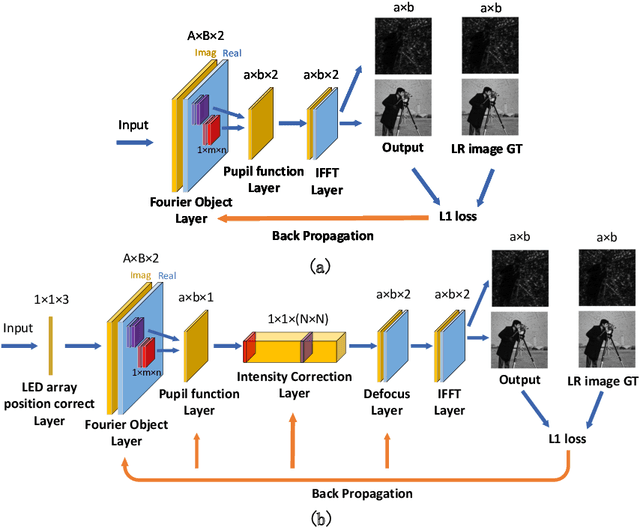
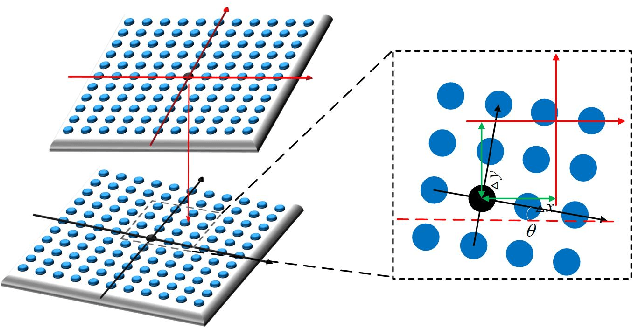
Fourier ptychography microscopy(FP) is a recently developed computational imaging approach for microscopic super-resolution imaging. By turning on each light-emitting-diode (LED) located on different position on the LED array sequentially and acquiring the corresponding images that contain different spatial frequency components, high spatial resolution and quantitative phase imaging can be achieved in the case of large field-of-view. Nevertheless, FPM has high requirements for the system construction and data acquisition processes, such as precise LEDs position, accurate focusing and appropriate exposure time, which brings many limitations to its practical applications. In this paper, inspired by artificial neural network, we propose a Fourier ptychography multi-parameter neural network (FPMN) with composite physical prior optimization. A hybrid parameter determination strategy combining physical imaging model and data-driven network training is proposed to recover the multi layers of the network corresponding to different physical parameters, including sample complex function, system pupil function, defocus distance, LED array position deviation and illumination intensity fluctuation, etc. Among these parameters, LED array position deviation is recovered based on the features of brightfield to darkfield transition low-resolution images while the others are recovered in the process of training of the neural network. The feasibility and effectiveness of FPMN are verified through simulations and actual experiments. Therefore FPMN can evidently reduce the requirement for practical applications of FPM.
PGCN: Progressive Graph Convolutional Networks for Spatial-Temporal Traffic Forecasting
Feb 18, 2022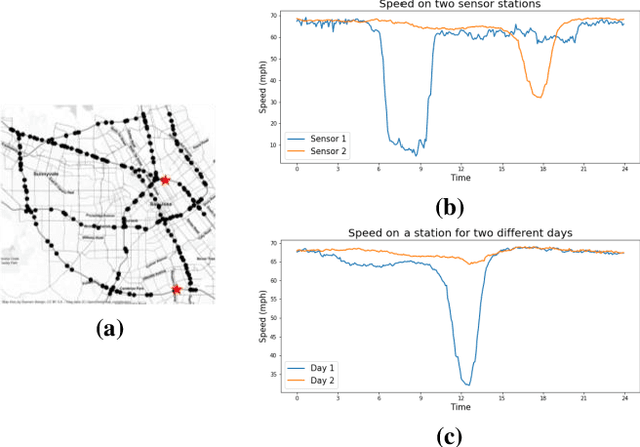
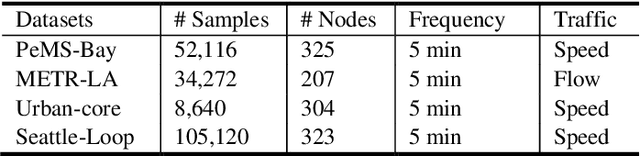
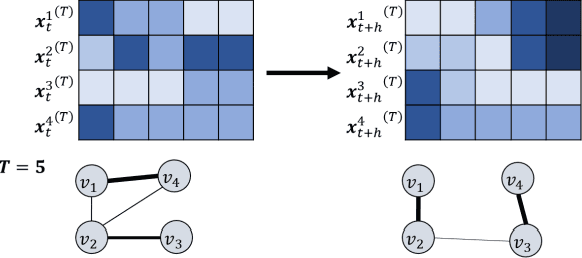
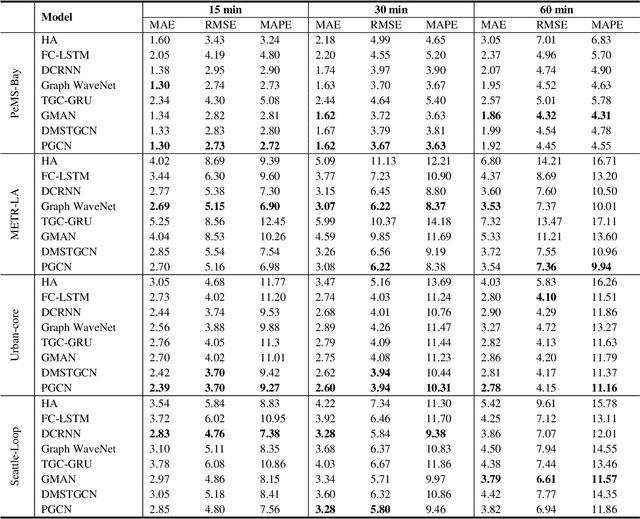
The complex spatial-temporal correlations in transportation networks make the traffic forecasting problem challenging. Since transportation system inherently possesses graph structures, much research efforts have been put with graph neural networks. Recently, constructing adaptive graphs to the data has shown promising results over the models relying on a single static graph structure. However, the graph adaptations are applied during the training phases, and do not reflect the data used during the testing phases. Such shortcomings can be problematic especially in traffic forecasting since the traffic data often suffers from the unexpected changes and irregularities in the time series. In this study, we propose a novel traffic forecasting framework called Progressive Graph Convolutional Network (PGCN). PGCN constructs a set of graphs by progressively adapting to input data during the training and the testing phases. Specifically, we implemented the model to construct progressive adjacency matrices by learning trend similarities among graph nodes. Then, the model is combined with the dilated causal convolution and gated activation unit to extract temporal features. With residual and skip connections, PGCN performs the traffic prediction. When applied to four real-world traffic datasets of diverse geometric nature, the proposed model achieves state-of-the-art performance with consistency in all datasets. We conclude that the ability of PGCN to progressively adapt to input data enables the model to generalize in different study sites with robustness.