 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Tracking and Planning with Spatial World Models
Jan 25, 2022

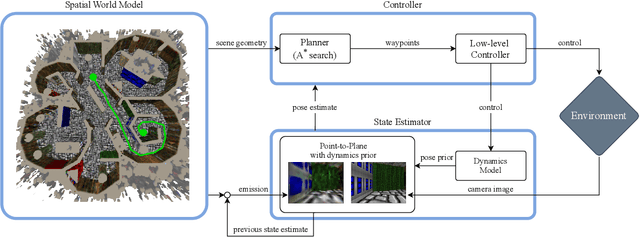
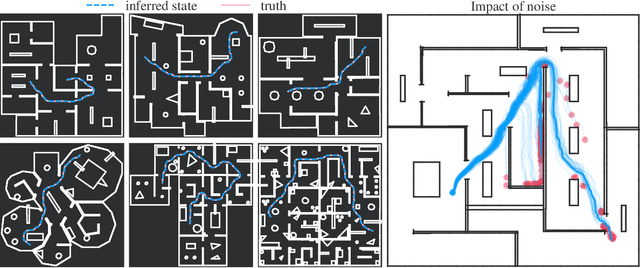
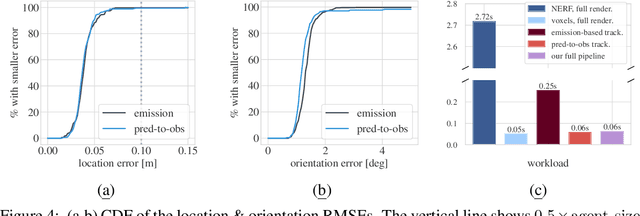
We introduce a method for real-time navigation and tracking with differentiably rendered world models. Learning models for control has led to impressive results in robotics and computer games, but this success has yet to be extended to vision-based navigation. To address this, we transfer advances in the emergent field of differentiable rendering to model-based control. We do this by planning in a learned 3D spatial world model, combined with a pose estimation algorithm previously used in the context of TSDF fusion, but now tailored to our setting and improved to incorporate agent dynamics. We evaluate over six simulated environments based on complex human-designed floor plans and provide quantitative results. We achieve up to 92% navigation success rate at a frequency of 15 Hz using only image and depth observations under stochastic, continuous dynamics.
CondenseNeXt: An Ultra-Efficient Deep Neural Network for Embedded Systems
Dec 01, 2021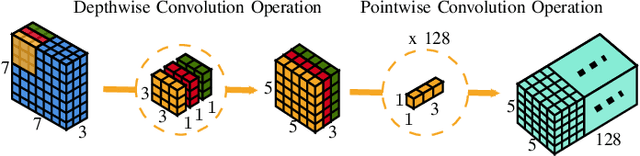
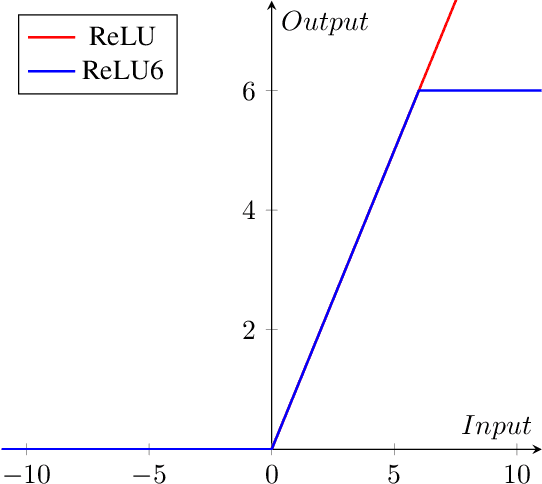
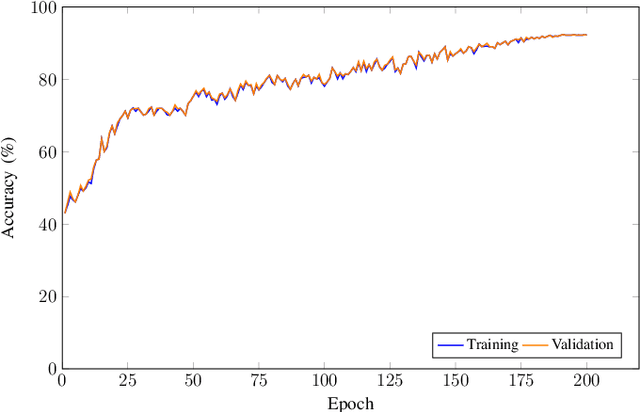

Due to the advent of modern embedded systems and mobile devices with constrained resources, there is a great demand for incredibly efficient deep neural networks for machine learning purposes. There is also a growing concern of privacy and confidentiality of user data within the general public when their data is processed and stored in an external server which has further fueled the need for developing such efficient neural networks for real-time inference on local embedded systems. The scope of our work presented in this paper is limited to image classification using a convolutional neural network. A Convolutional Neural Network (CNN) is a class of Deep Neural Network (DNN) widely used in the analysis of visual images captured by an image sensor, designed to extract information and convert it into meaningful representations for real-time inference of the input data. In this paper, we propose a neoteric variant of deep convolutional neural network architecture to ameliorate the performance of existing CNN architectures for real-time inference on embedded systems. We show that this architecture, dubbed CondenseNeXt, is remarkably efficient in comparison to the baseline neural network architecture, CondenseNet, by reducing trainable parameters and FLOPs required to train the network whilst maintaining a balance between the trained model size of less than 3.0 MB and accuracy trade-off resulting in an unprecedented computational efficiency.
Integrated multimodal artificial intelligence framework for healthcare applications
Feb 25, 2022
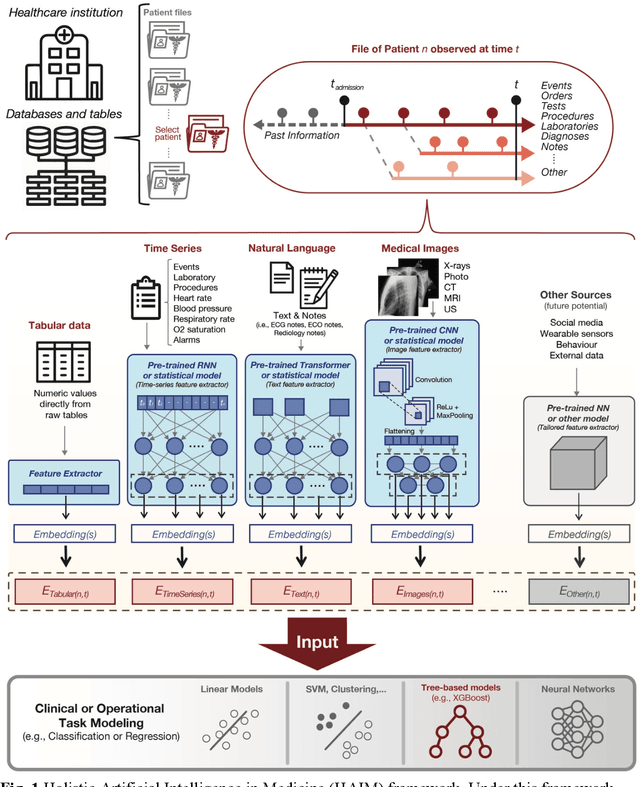
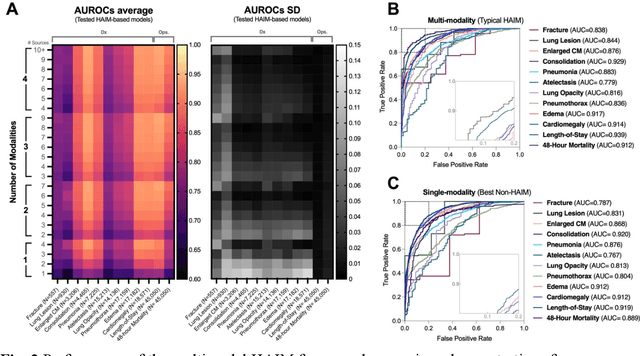
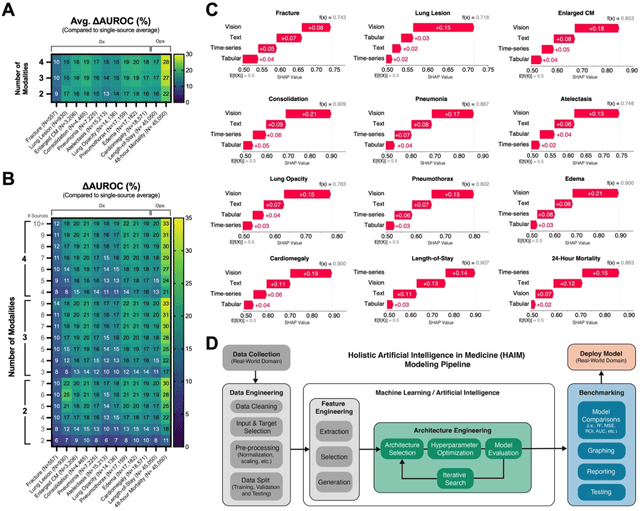
Artificial intelligence (AI) systems hold great promise to improve healthcare over the next decades. Specifically, AI systems leveraging multiple data sources and input modalities are poised to become a viable method to deliver more accurate results and deployable pipelines across a wide range of applications. In this work, we propose and evaluate a unified Holistic AI in Medicine (HAIM) framework to facilitate the generation and testing of AI systems that leverage multimodal inputs. Our approach uses generalizable data pre-processing and machine learning modeling stages that can be readily adapted for research and deployment in healthcare environments. We evaluate our HAIM framework by training and characterizing 14,324 independent models based on MIMIC-IV-MM, a multimodal clinical database (N=34,537 samples) containing 7,279 unique hospitalizations and 6,485 patients, spanning all possible input combinations of 4 data modalities (i.e., tabular, time-series, text and images), 11 unique data sources and 12 predictive tasks. We show that this framework can consistently and robustly produce models that outperform similar single-source approaches across various healthcare demonstrations (by 6-33%), including 10 distinct chest pathology diagnoses, along with length-of-stay and 48-hour mortality predictions. We also quantify the contribution of each modality and data source using Shapley values, which demonstrates the heterogeneity in data type importance and the necessity of multimodal inputs across different healthcare-relevant tasks. The generalizable properties and flexibility of our Holistic AI in Medicine (HAIM) framework could offer a promising pathway for future multimodal predictive systems in clinical and operational healthcare settings.
Artificial Neural Network for Resource Allocation in Laser-based Optical wireless Networks
Nov 27, 2021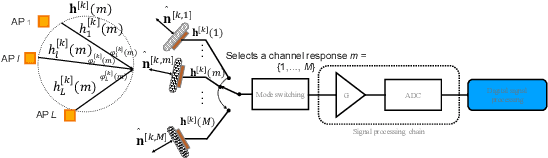
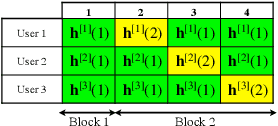
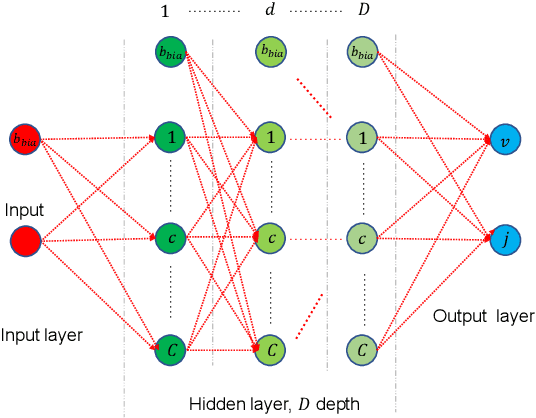
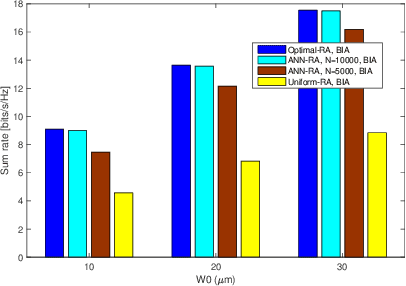
Optical wireless communication offers unprecedented communication speeds that can support the massive use of the Internet on a daily basis. In indoor environments, optical wireless networks are usually multi-user multiple-input multiple-output (MU-MIMO) systems, where a high number of optical access points (APs) is required to ensure coverage. In this work, a laser-based optical wireless network is considered for serving multiple users. Moreover, blind inference alignment (BIA) is implemented to achieve a high degree of freedom (DoF) without the need for channel state information (CSI) at transmitters, which is difficult to provide in such wireless networks. Then, an objective function is defined to allocate the resources of the network taking into consideration the requirements of users and the available resources. This optimization problem can be solved through exhaustive search or distributed algorithms. However, a practical algorithm that provides immediate solutions in real time scenarios is required. In this context, an artificial neural network (ANN) model is derived in order to obtain a sub-optimal solution with low computational time. The implementation of the ANN model involves three important steps, dataset generation, offline training, and real time application. The results show that the trained ANN model provides a significant solution close to the optimal one.
Attention-based Deep Neural Networks for Battery Discharge Capacity Forecasting
Feb 14, 2022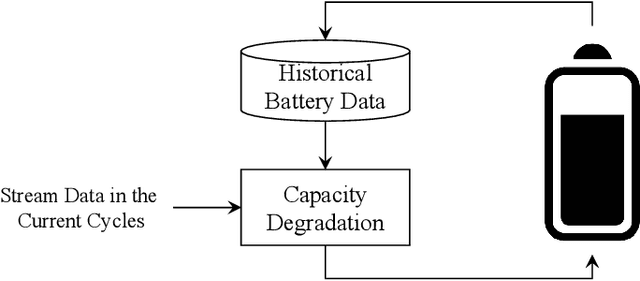
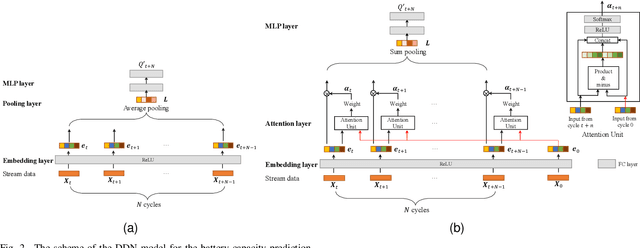
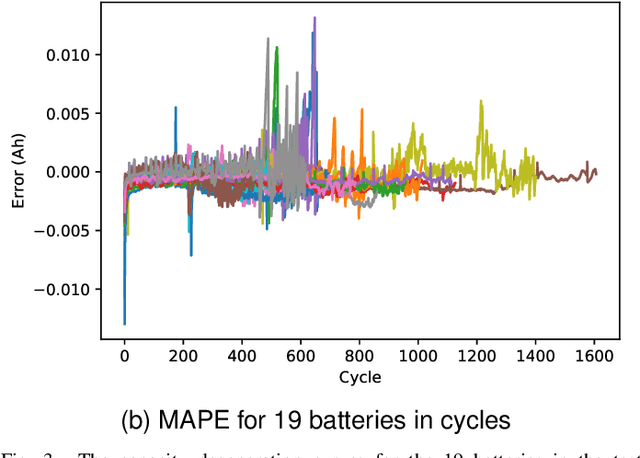
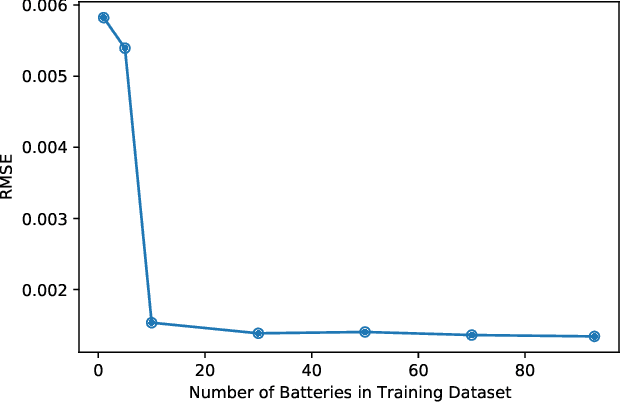
Battery discharge capacity forecasting is critically essential for the applications of lithium-ion batteries. The capacity degeneration can be treated as the memory of the initial battery state of charge from the data point of view. The streaming sensor data collected by battery management systems (BMS) reflect the usable battery capacity degradation rates under various operational working conditions. The battery capacity in different cycles can be measured with the temporal patterns extracted from the streaming sensor data based on the attention mechanism. The attention-based similarity regarding the first cycle can describe the battery capacity degradation in the following cycles. The deep degradation network (DDN) is developed with the attention mechanism to measure similarity and predict battery capacity. The DDN model can extract the degeneration-related temporal patterns from the streaming sensor data and perform the battery capacity prediction efficiently online in real-time. Based on the MIT-Stanford open-access battery aging dataset, the root-mean-square error of the capacity estimation is 1.3 mAh. The mean absolute percentage error of the proposed DDN model is 0.06{\%}. The DDN model also performance well in the Oxford Battery Degradation Dataset with dynamic load profiles. Therefore, the high accuracy and strong robustness of the proposed algorithm are verified.
RIFE: Real-Time Intermediate Flow Estimation for Video Frame Interpolation
Nov 12, 2020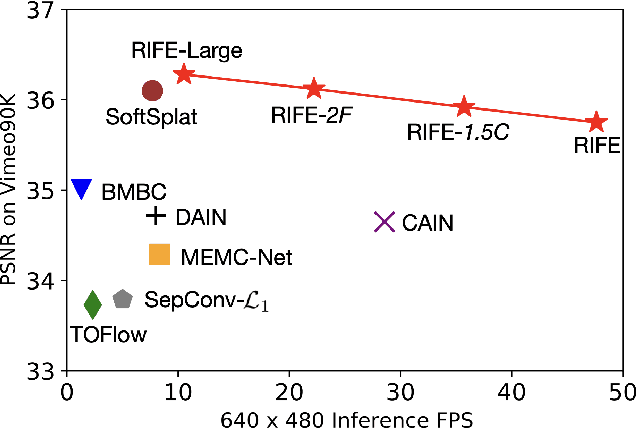

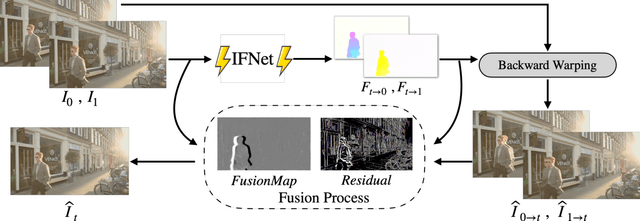
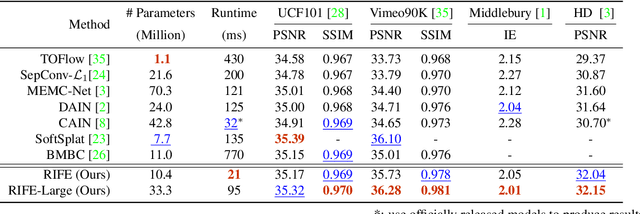
We propose a real-time intermediate flow estimation algorithm (RIFE) for video frame interpolation (VFI). Most existing methods first estimate the bi-directional optical flows, and then linearly combine them to approximate intermediate flows, leading to artifacts around motion boundaries. We design an intermediate flow model named IFNet that can directly estimate the intermediate flows from coarse to fine. We then warp the input frames according to the estimated intermediate flows and employ a fusion process to compute final results. Based on our proposed leakage distillation, RIFE can be trained end-to-end and achieve excellent performance. Experiments demonstrate that RIFE is significantly faster than existing flow-based VFI methods and achieves state-of-the-art index on several benchmarks. The code is available at https://github.com/hzwer/RIFE.
Every time I fire a conversational designer, the performance of the dialog system goes down
Sep 27, 2021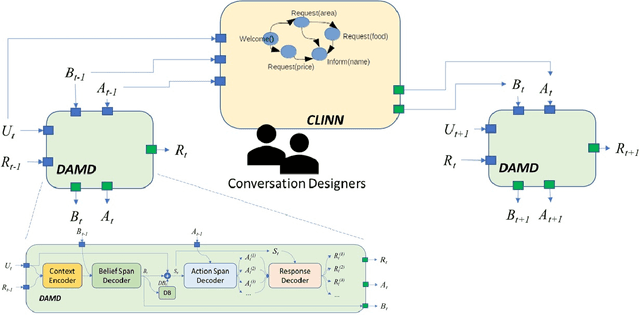
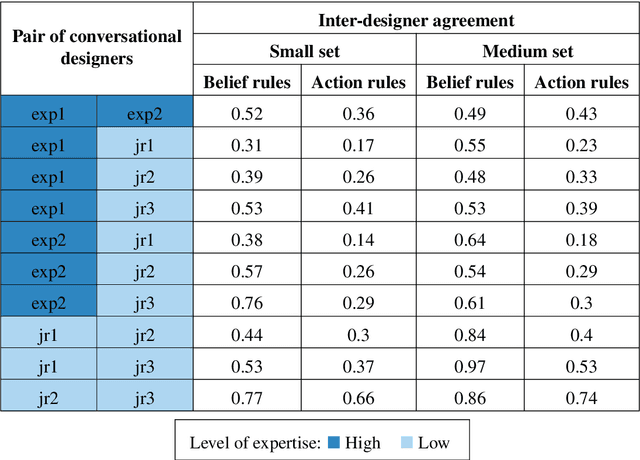
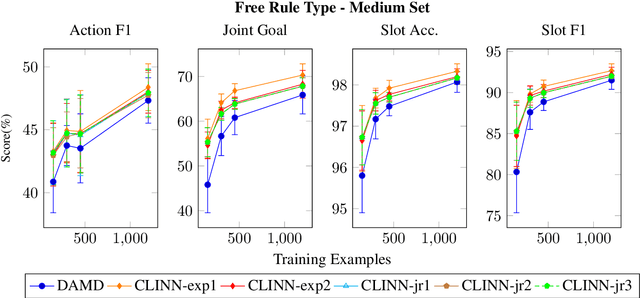
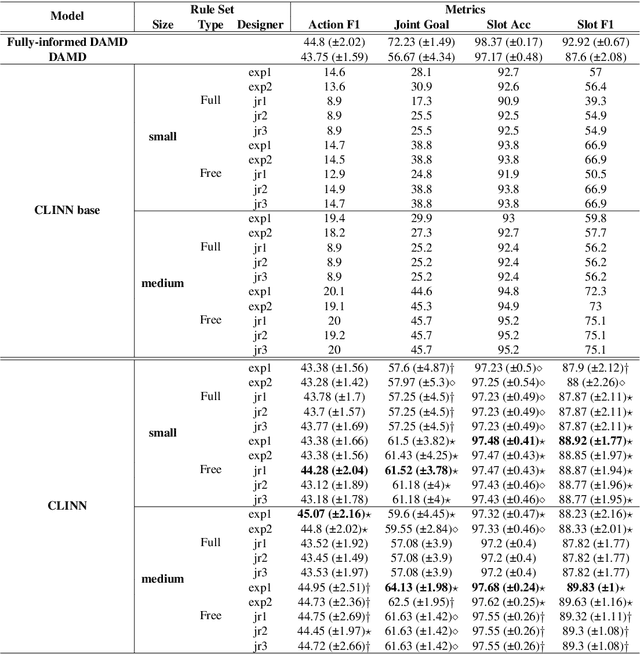
Incorporating explicit domain knowledge into neural-based task-oriented dialogue systems is an effective way to reduce the need of large sets of annotated dialogues. In this paper, we investigate how the use of explicit domain knowledge of conversational designers affects the performance of neural-based dialogue systems. To support this investigation, we propose the Conversational-Logic-Injection-in-Neural-Network system (CLINN) where explicit knowledge is coded in semi-logical rules. By using CLINN, we evaluated semi-logical rules produced by a team of differently skilled conversational designers. We experimented with the Restaurant topic of the MultiWOZ dataset. Results show that external knowledge is extremely important for reducing the need of annotated examples for conversational systems. In fact, rules from conversational designers used in CLINN significantly outperform a state-of-the-art neural-based dialogue system.
A Hardware-Aware System for Accelerating Deep Neural Network Optimization
Feb 25, 2022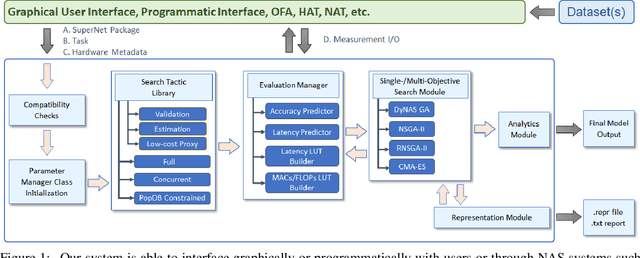
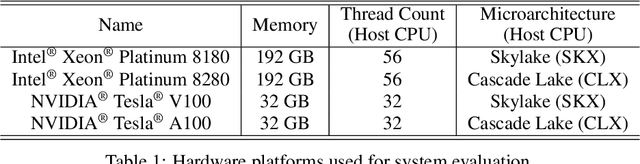
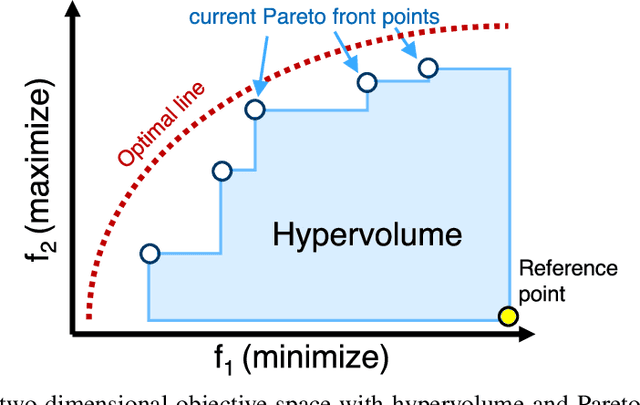
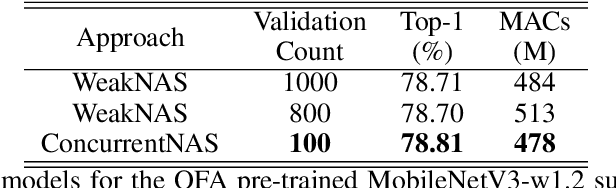
Recent advances in Neural Architecture Search (NAS) which extract specialized hardware-aware configurations (a.k.a. "sub-networks") from a hardware-agnostic "super-network" have become increasingly popular. While considerable effort has been employed towards improving the first stage, namely, the training of the super-network, the search for derivative high-performing sub-networks is still largely under-explored. For example, some recent network morphism techniques allow a super-network to be trained once and then have hardware-specific networks extracted from it as needed. These methods decouple the super-network training from the sub-network search and thus decrease the computational burden of specializing to different hardware platforms. We propose a comprehensive system that automatically and efficiently finds sub-networks from a pre-trained super-network that are optimized to different performance metrics and hardware configurations. By combining novel search tactics and algorithms with intelligent use of predictors, we significantly decrease the time needed to find optimal sub-networks from a given super-network. Further, our approach does not require the super-network to be refined for the target task a priori, thus allowing it to interface with any super-network. We demonstrate through extensive experiments that our system works seamlessly with existing state-of-the-art super-network training methods in multiple domains. Moreover, we show how novel search tactics paired with evolutionary algorithms can accelerate the search process for ResNet50, MobileNetV3 and Transformer while maintaining objective space Pareto front diversity and demonstrate an 8x faster search result than the state-of-the-art Bayesian optimization WeakNAS approach.
Boundary Conditions for Linear Exit Time Gradient Trajectories Around Saddle Points: Analysis and Algorithm
Jan 07, 2021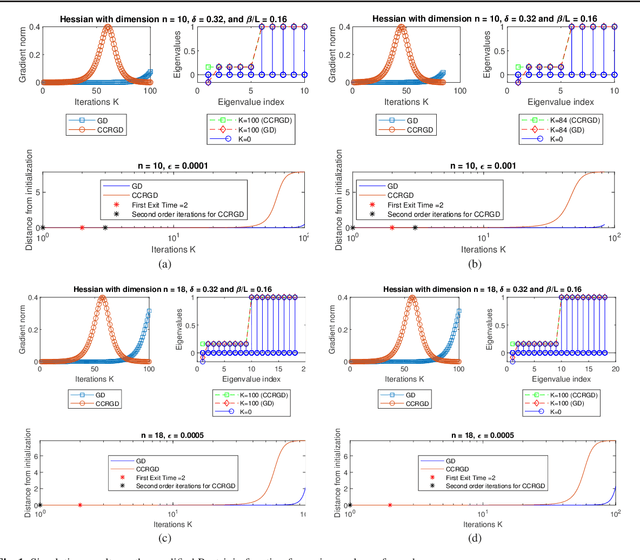
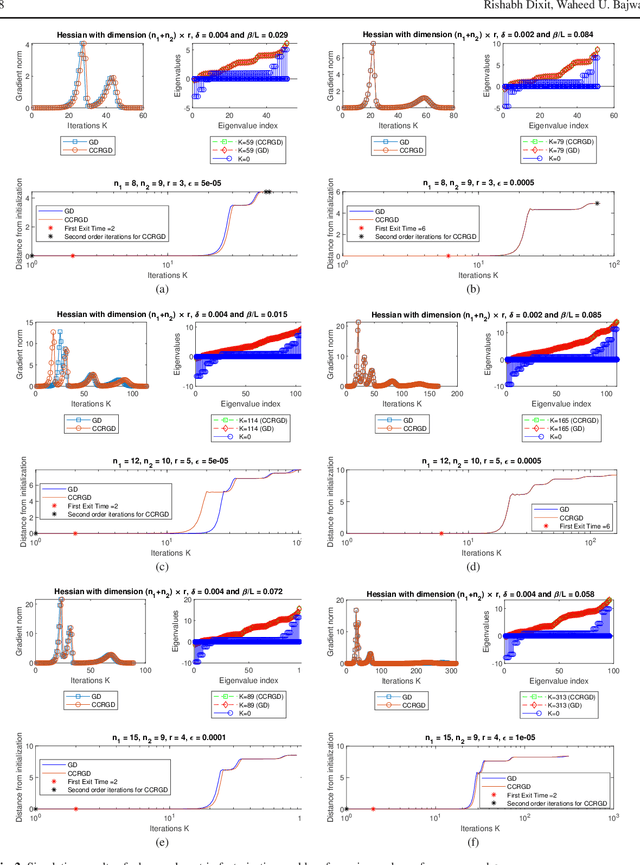
Gradient-related first-order methods have become the workhorse of large-scale numerical optimization problems. Many of these problems involve nonconvex objective functions with multiple saddle points, which necessitates an understanding of the behavior of discrete trajectories of first-order methods within the geometrical landscape of these functions. This paper concerns convergence of first-order discrete methods to a local minimum of nonconvex optimization problems that comprise strict saddle points within the geometrical landscape. To this end, it focuses on analysis of discrete gradient trajectories around saddle neighborhoods, derives sufficient conditions under which these trajectories can escape strict-saddle neighborhoods in linear time, explores the contractive and expansive dynamics of these trajectories in neighborhoods of strict-saddle points that are characterized by gradients of moderate magnitude, characterizes the non-curving nature of these trajectories, and highlights the inability of these trajectories to re-enter the neighborhoods around strict-saddle points after exiting them. Based on these insights and analyses, the paper then proposes a simple variant of the vanilla gradient descent algorithm, termed Curvature Conditioned Regularized Gradient Descent (CCRGD) algorithm, which utilizes a check for an initial boundary condition to ensure its trajectories can escape strict-saddle neighborhoods in linear time. Convergence analysis of the CCRGD algorithm, which includes its rate of convergence to a local minimum within a geometrical landscape that has a maximum number of strict-saddle points, is also presented in the paper. Numerical experiments are then provided on a test function as well as a low-rank matrix factorization problem to evaluate the efficacy of the proposed algorithm.
Flexible fast-convolution processing for cellular radio evolution
Feb 05, 2022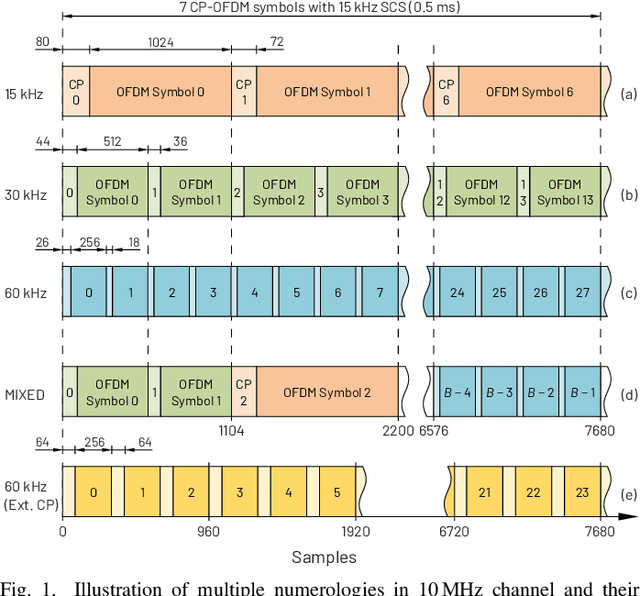
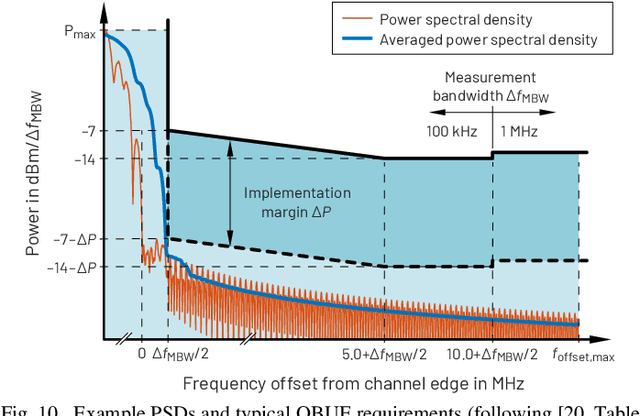
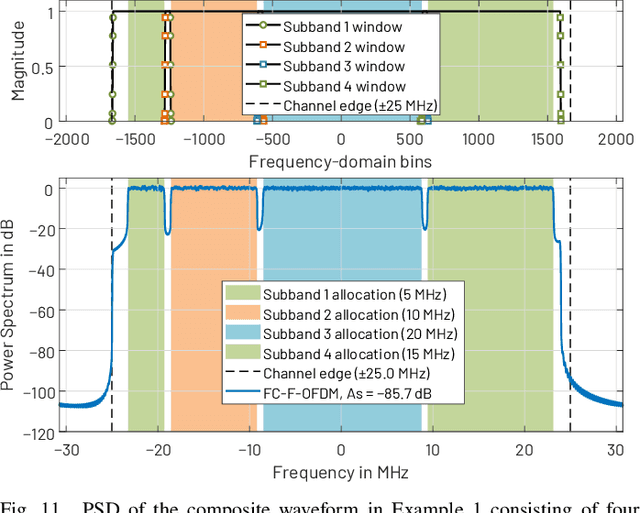
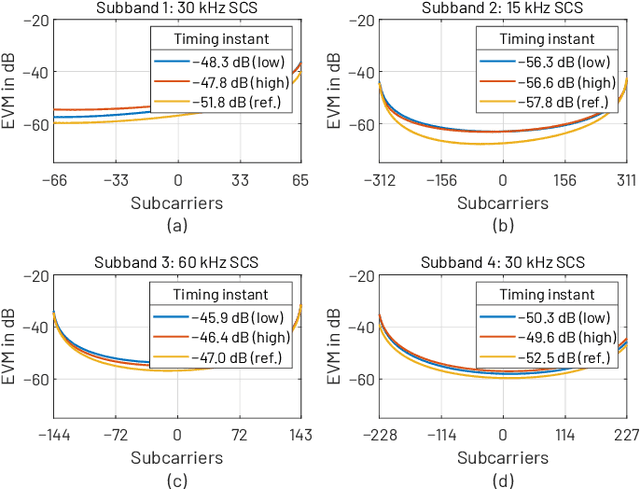
Orthogonal frequency-division multiplexing (OFDM) has been selected as a baseline waveform for long-term evolution (LTE) and fifth-generation new radio (5G NR). Fast-convolution (FC)-based frequency-domain signal processing has been considered recently as an effective tool for spectrum enhancement of OFDM-based waveforms. FC-based filtering approximates linear convolution by effective fast Fourier transform (FFT)-based circular convolutions using partly overlapping processing blocks. In earlier work, we have shown that FC-based filtering is a very flexible and efficient tool for filtered-OFDM signal generation and receiver side subband filtering. In this paper, we present a symbol-synchronous FC-processing scheme flexibly allowing filter re-configuration time resolution equal to one OFDM symbol while supporting tight carrier-wise filtering for 5G NR in mixed-numerology scenarios with adjustable subcarrier spacings, center frequencies, and subband bandwidths as well as providing co-exitence with LTE. The proposed scheme is demonstrated to support envisioned use cases of 5G NR and provide flexible starting point for sixth generation development.