 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DAE : Discriminatory Auto-Encoder for multivariate time-series anomaly detection in air transportation
Sep 08, 2021
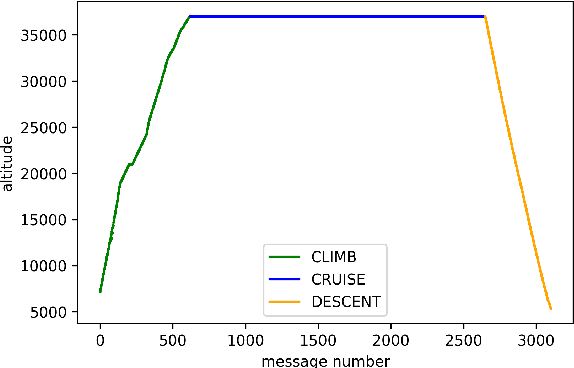
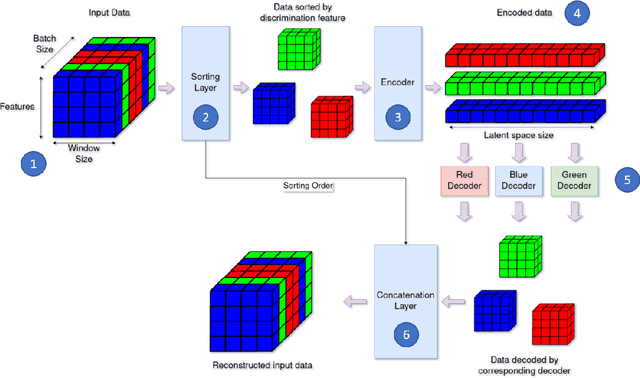
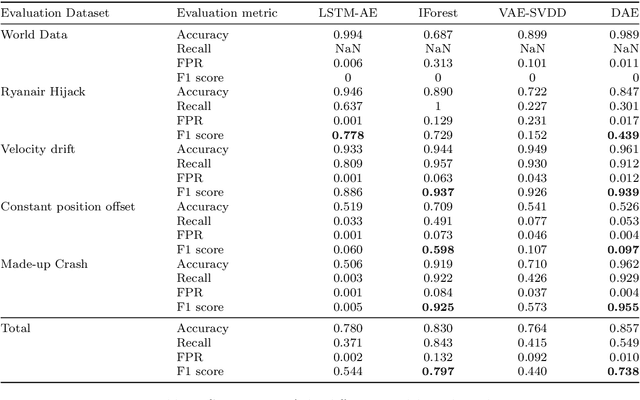
The Automatic Dependent Surveillance Broadcast protocol is one of the latest compulsory advances in air surveillance. While it supports the tracking of the ever-growing number of aircraft in the air, it also introduces cybersecurity issues that must be mitigated e.g., false data injection attacks where an attacker emits fake surveillance information. The recent data sources and tools available to obtain flight tracking records allow the researchers to create datasets and develop Machine Learning models capable of detecting such anomalies in En-Route trajectories. In this context, we propose a novel multivariate anomaly detection model called Discriminatory Auto-Encoder (DAE). It uses the baseline of a regular LSTM-based auto-encoder but with several decoders, each getting data of a specific flight phase (e.g. climbing, cruising or descending) during its training.To illustrate the DAE's efficiency, an evaluation dataset was created using real-life anomalies as well as realistically crafted ones, with which the DAE as well as three anomaly detection models from the literature were evaluated. Results show that the DAE achieves better results in both accuracy and speed of detection. The dataset, the models implementations and the evaluation results are available in an online repository, thereby enabling replicability and facilitating future experiments.
FedREP: Towards Horizontal Federated Load Forecasting for Retail Energy Providers
Mar 01, 2022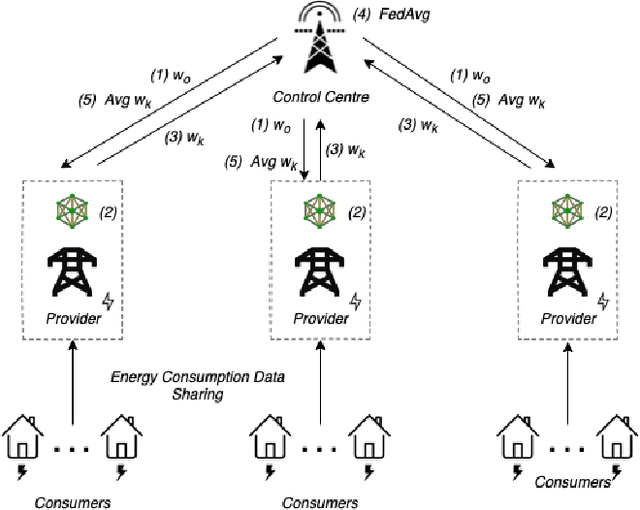
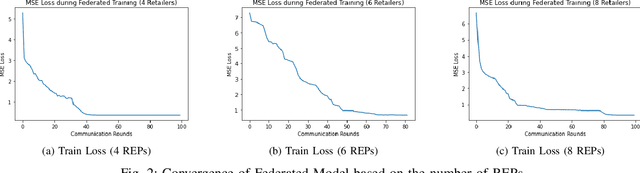
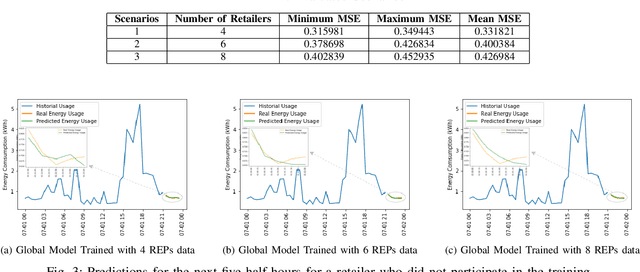
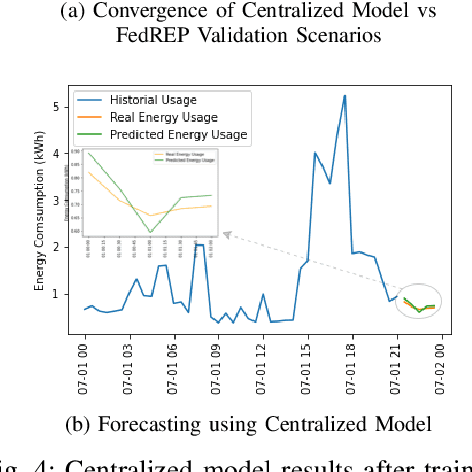
As Smart Meters are collecting and transmitting household energy consumption data to Retail Energy Providers (REP), the main challenge is to ensure the effective use of fine-grained consumer data while ensuring data privacy. In this manuscript, we tackle this challenge for energy load consumption forecasting in regards to REPs which is essential to energy demand management, load switching and infrastructure development. Specifically, we note that existing energy load forecasting is centralized, which are not scalable and most importantly, vulnerable to data privacy threats. Besides, REPs are individual market participants and liable to ensure the privacy of their own customers. To address this issue, we propose a novel horizontal privacy-preserving federated learning framework for REPs energy load forecasting, namely FedREP. We consider a federated learning system consisting of a control centre and multiple retailers by enabling multiple REPs to build a common, robust machine learning model without sharing data, thus addressing critical issues such as data privacy, data security and scalability. For forecasting, we use a state-of-the-art Long Short-Term Memory (LSTM) neural network due to its ability to learn long term sequences of observations and promises of higher accuracy with time-series data while solving the vanishing gradient problem. Finally, we conduct extensive data-driven experiments using a real energy consumption dataset. Experimental results demonstrate that our proposed federated learning framework can achieve sufficient performance in terms of MSE ranging between 0.3 to 0.4 and is relatively similar to that of a centralized approach while preserving privacy and improving scalability.
Per-Link Parallel and Distributed Hybrid Beamforming for Multi-Cell Massive MIMO Millimeter Wave Full Duplex
Jan 03, 2022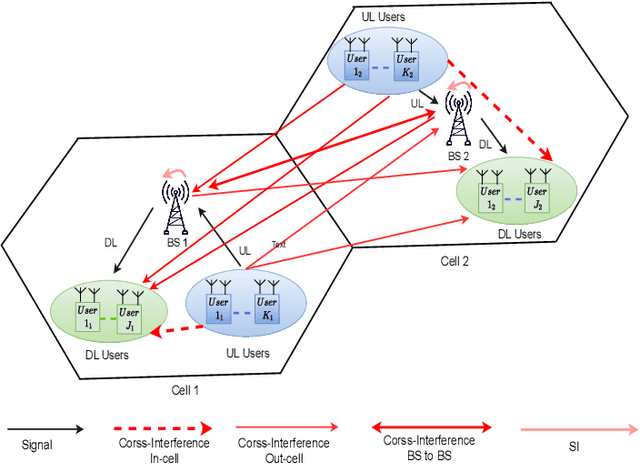
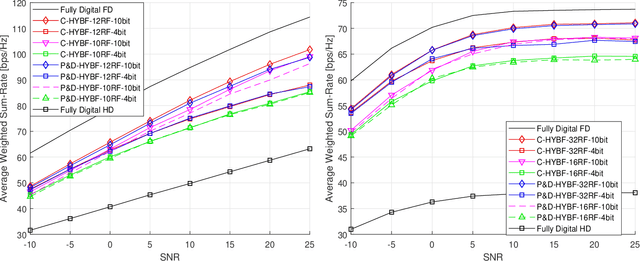
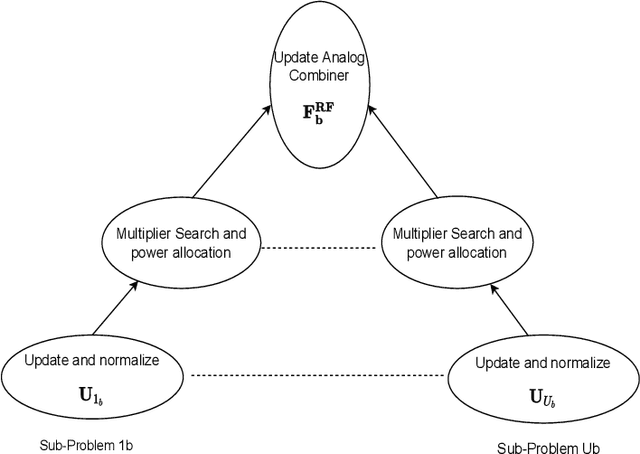
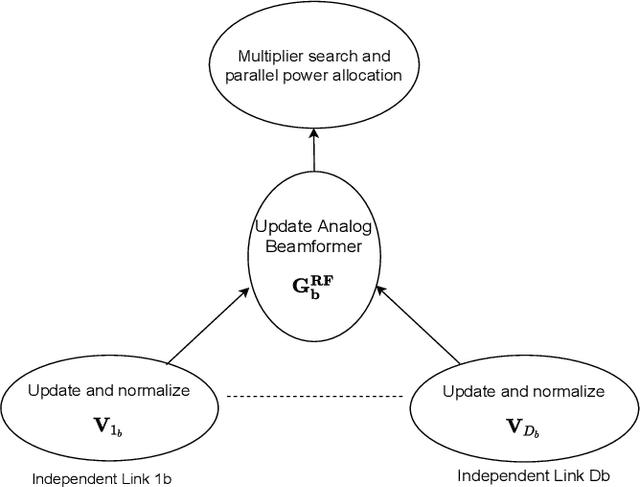
This paper presents two novel hybrid beamforming (HYBF) designs for a multi-cell massive multiple-input-multiple-output (mMIMO) millimeter wave (mmWave) full duplex (FD) system under limited dynamic range (LDR). Firstly, we present a novel centralized HYBF (C-HYBF) scheme based on alternating optimization. In general, the complexity of C-HYBF schemes scales quadratically as a function of the number of users and cells, which may limit their scalability. Moreover, they require significant communication overhead to transfer complete channel state information (CSI) to the central node every channel coherence time for optimization. The central node also requires very high computational power to jointly optimize many variables for the uplink (UL) and downlink (DL) users for FD. To overcome these drawbacks, we propose a very low-complexity and scalable cooperative per-link parallel and distributed (P$\&$D)-HYBF scheme. It allows each mmWave FD base station (BS) to update the beamformers for its users in a distributed fashion and independently in parallel on different computational processors. The complexity of P$\&$D-HYBF scales only linearly as the network size grows, making it desirable for the next generation of large and dense mmWave FD networks. Simulation results show that both designs significantly outperform the fully digital half duplex (HD) system with only a few radio-frequency (RF) chains, achieve similar performance, and the P$\&$D-HYBF design requires considerably less execution time.
RawNeXt: Speaker verification system for variable-duration utterances with deep layer aggregation and extended dynamic scaling policies
Dec 15, 2021



Despite achieving satisfactory performance in speaker verification using deep neural networks, variable-duration utterances remain a challenge that threatens the robustness of systems. To deal with this issue, we propose a speaker verification system called RawNeXt that can handle input raw waveforms of arbitrary length by employing the following two components: (1) A deep layer aggregation strategy enhances speaker information by iteratively and hierarchically aggregating features of various time scales and spectral channels output from blocks. (2) An extended dynamic scaling policy flexibly processes features according to the length of the utterance by selectively merging the activations of different resolution branches in each block. Owing to these two components, our proposed model can extract speaker embeddings rich in time-spectral information and operate dynamically on length variations. Experimental results on the VoxCeleb1 test set consisting of various duration utterances demonstrate that RawNeXt achieves state-of-the-art performance compared to the recently proposed systems. Our code and trained model weights are available at https://github.com/wngh1187/RawNeXt.
Teaching Networks to Solve Optimization Problems
Feb 08, 2022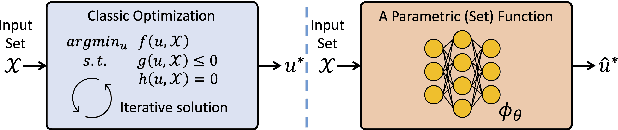
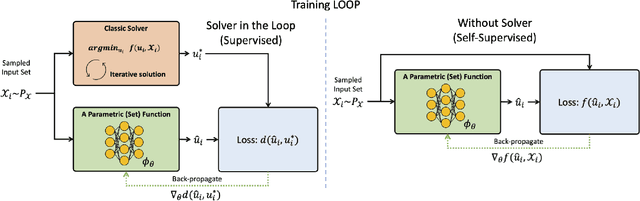
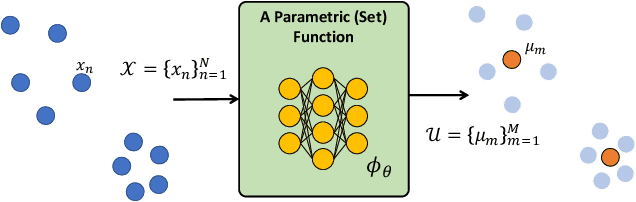
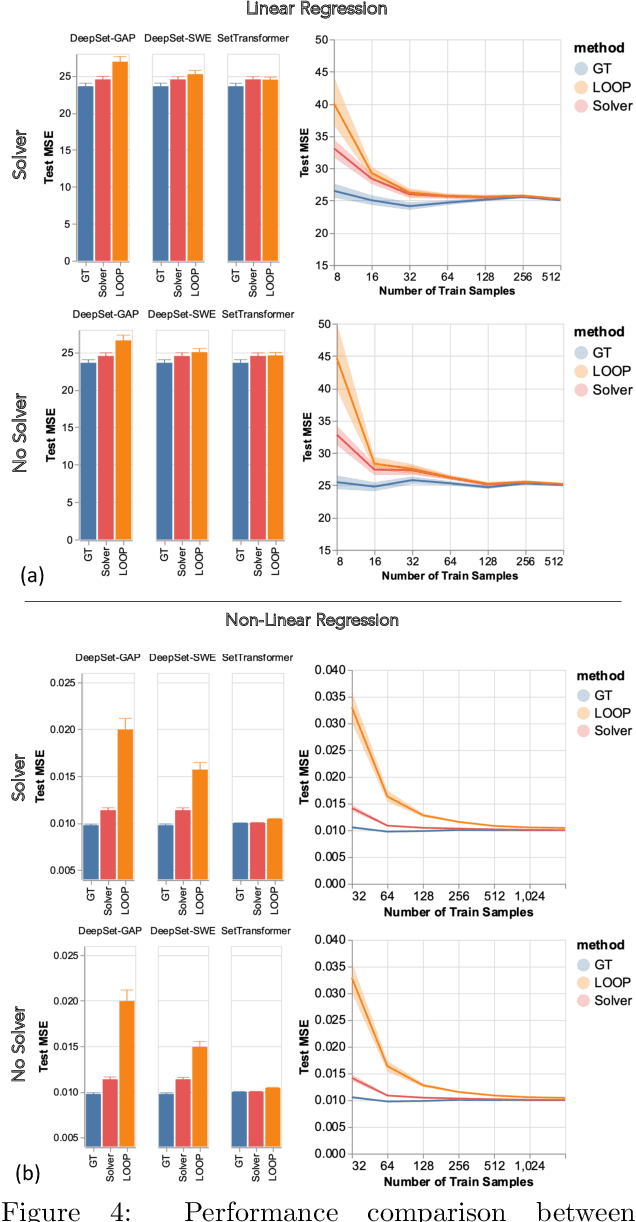
Leveraging machine learning to optimize the optimization process is an emerging field which holds the promise to bypass the fundamental computational bottleneck caused by traditional iterative solvers in critical applications requiring near-real-time optimization. The majority of existing approaches focus on learning data-driven optimizers that lead to fewer iterations in solving an optimization. In this paper, we take a different approach and propose to replace the iterative solvers altogether with a trainable parametric set function that outputs the optimal arguments/parameters of an optimization problem in a single feed-forward. We denote our method as, Learning to Optimize the Optimization Process (LOOP). We show the feasibility of learning such parametric (set) functions to solve various classic optimization problems, including linear/nonlinear regression, principal component analysis, transport-based core-set, and quadratic programming in supply management applications. In addition, we propose two alternative approaches for learning such parametric functions, with and without a solver in the-LOOP. Finally, we demonstrate the effectiveness of our proposed approach through various numerical experiments.
Learning to Coordinate in Multi-Agent Systems: A Coordinated Actor-Critic Algorithm and Finite-Time Guarantees
Oct 11, 2021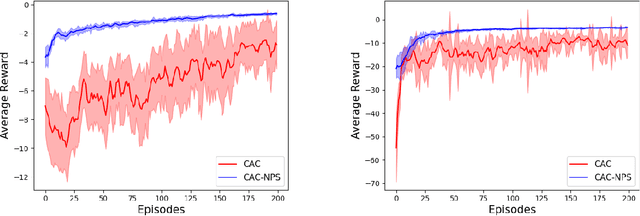
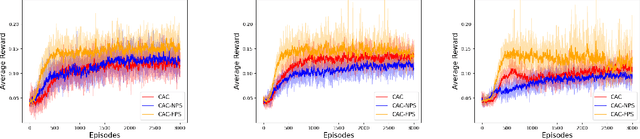
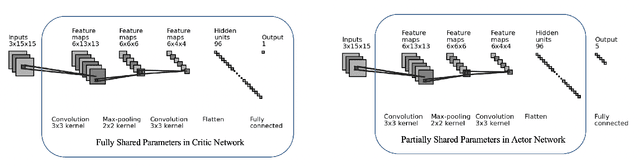
Multi-agent reinforcement learning (MARL) has attracted much research attention recently. However, unlike its single-agent counterpart, many theoretical and algorithmic aspects of MARL have not been well-understood. In this paper, we study the emergence of coordinated behavior by autonomous agents using an actor-critic (AC) algorithm. Specifically, we propose and analyze a class of coordinated actor-critic algorithms (CAC) in which individually parametrized policies have a {\it shared} part (which is jointly optimized among all agents) and a {\it personalized} part (which is only locally optimized). Such kind of {\it partially personalized} policy allows agents to learn to coordinate by leveraging peers' past experience and adapt to individual tasks. The flexibility in our design allows the proposed MARL-CAC algorithm to be used in a {\it fully decentralized} setting, where the agents can only communicate with their neighbors, as well as a {\it federated} setting, where the agents occasionally communicate with a server while optimizing their (partially personalized) local models. Theoretically, we show that under some standard regularity assumptions, the proposed MARL-CAC algorithm requires $\mathcal{O}(\epsilon^{-\frac{5}{2}})$ samples to achieve an $\epsilon$-stationary solution (defined as the solution whose squared norm of the gradient of the objective function is less than $\epsilon$). To the best of our knowledge, this work provides the first finite-sample guarantee for decentralized AC algorithm with partially personalized policies.
Adaptive Sampling to Estimate Quantiles for Guiding Physical Sampling
Jan 25, 2022
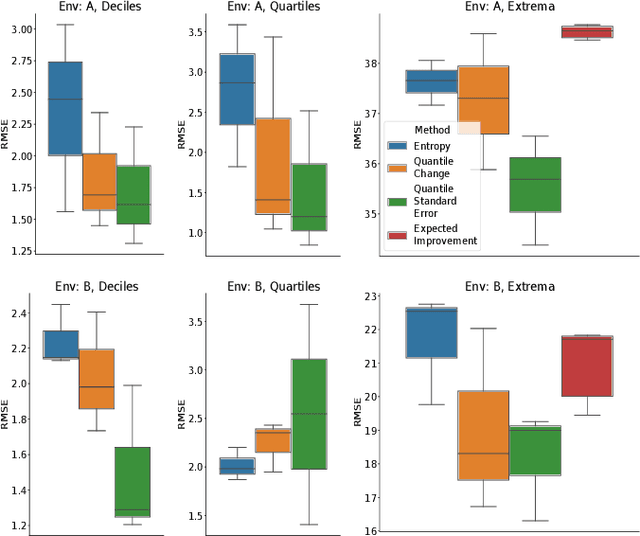
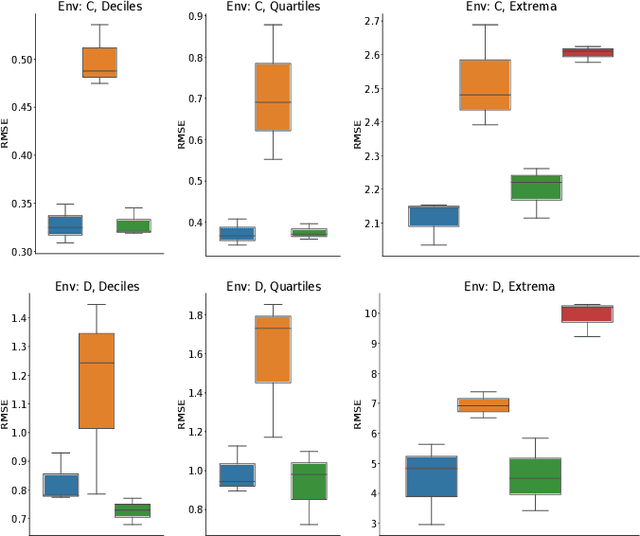
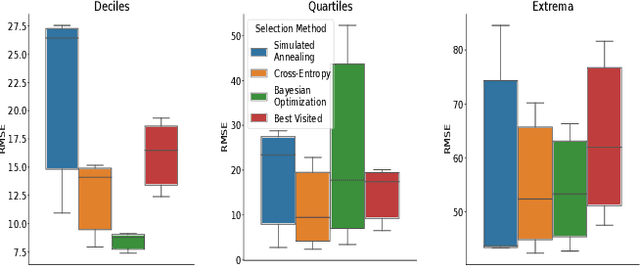
Scientists interested in studying natural phenomena often take physical samples for later analysis at locations specified by expert heuristics. Instead, we propose to guide scientists' physical sampling by using a robot to perform an adaptive sampling survey to find locations to suggest that correspond to the quantile values of pre-specified quantiles of interest. We develop a robot planner using novel objective functions to improve the estimates of the quantile values over time and an approach to find locations which correspond to the quantile values. We demonstrate our approach on two different sampling tasks in simulation using previously collected aquatic data and validate it in a field trial. Our approach outperforms objectives that maximize spatial coverage or find extrema in planning and is able to localize the quantile spatial locations.
OpenREALM: Real-time Mapping for Unmanned Aerial Vehicles
Sep 22, 2020
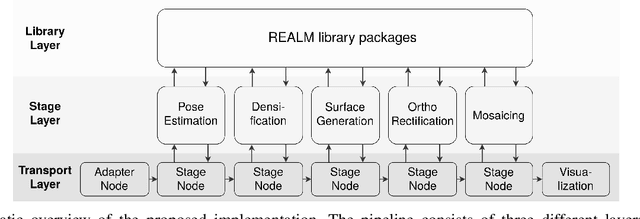
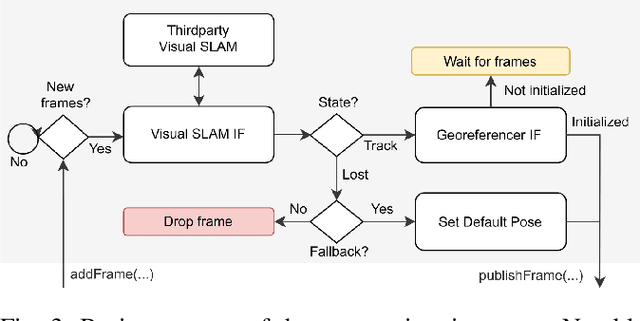
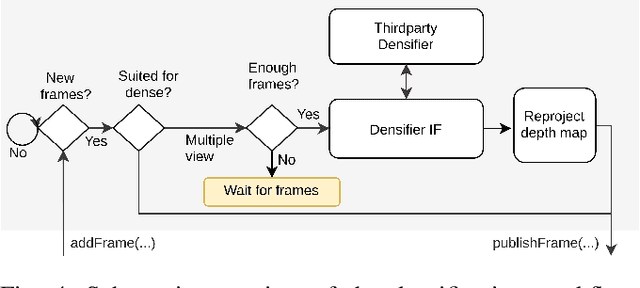
This paper presents OpenREALM, a real-time mapping framework for Unmanned Aerial Vehicles (UAVs). A camera attached to the onboard computer of a moving UAV is utilized to acquire high resolution image mosaics of a targeted area of interest. Different modes of operation allow OpenREALM to perform simple stitching assuming an approximate plane ground, or to fully recover complex 3D surface information to extract both elevation maps and geometrically corrected orthophotos. Additionally, the global position of the UAV is used to georeference the data. In all modes incremental progress of the resulting map can be viewed live by an operator on the ground. Obtained, up-to-date surface information will be a push forward to a variety of UAV applications. For the benefit of the community, source code is public at https://github.com/laxnpander/OpenREALM.
Grammar-Based Grounded Lexicon Learning
Feb 17, 2022
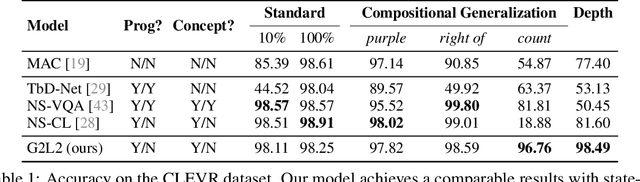
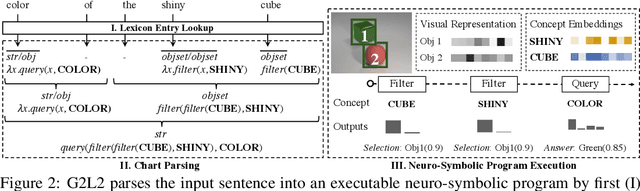
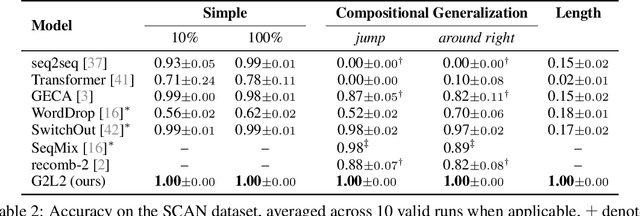
We present Grammar-Based Grounded Lexicon Learning (G2L2), a lexicalist approach toward learning a compositional and grounded meaning representation of language from grounded data, such as paired images and texts. At the core of G2L2 is a collection of lexicon entries, which map each word to a tuple of a syntactic type and a neuro-symbolic semantic program. For example, the word shiny has a syntactic type of adjective; its neuro-symbolic semantic program has the symbolic form {\lambda}x. filter(x, SHINY), where the concept SHINY is associated with a neural network embedding, which will be used to classify shiny objects. Given an input sentence, G2L2 first looks up the lexicon entries associated with each token. It then derives the meaning of the sentence as an executable neuro-symbolic program by composing lexical meanings based on syntax. The recovered meaning programs can be executed on grounded inputs. To facilitate learning in an exponentially-growing compositional space, we introduce a joint parsing and expected execution algorithm, which does local marginalization over derivations to reduce the training time. We evaluate G2L2 on two domains: visual reasoning and language-driven navigation. Results show that G2L2 can generalize from small amounts of data to novel compositions of words.
cosFormer: Rethinking Softmax in Attention
Feb 17, 2022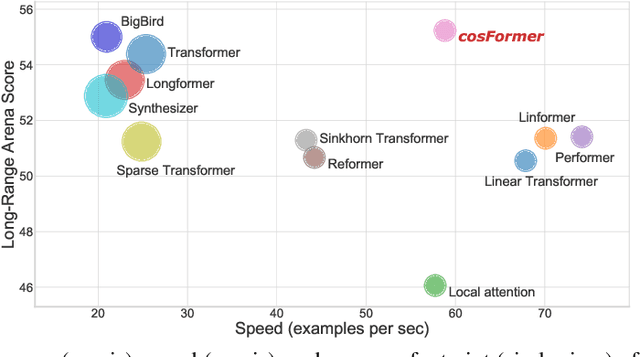
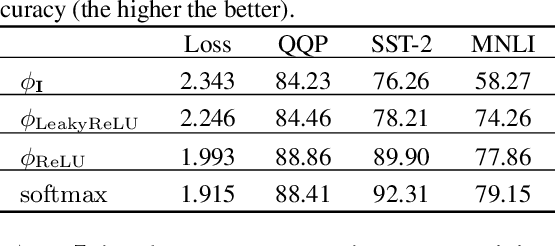
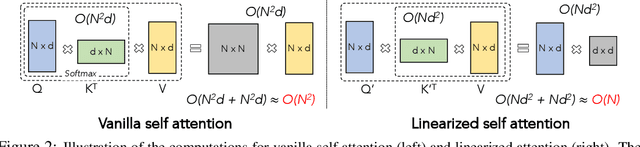
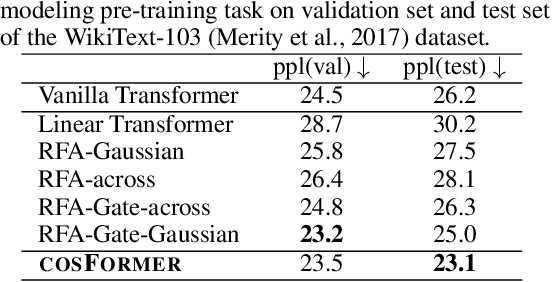
Transformer has shown great successes in natural language processing, computer vision, and audio processing. As one of its core components, the softmax attention helps to capture long-range dependencies yet prohibits its scale-up due to the quadratic space and time complexity to the sequence length. Kernel methods are often adopted to reduce the complexity by approximating the softmax operator. Nevertheless, due to the approximation errors, their performances vary in different tasks/corpus and suffer crucial performance drops when compared with the vanilla softmax attention. In this paper, we propose a linear transformer called cosFormer that can achieve comparable or better accuracy to the vanilla transformer in both casual and cross attentions. cosFormer is based on two key properties of softmax attention: i). non-negativeness of the attention matrix; ii). a non-linear re-weighting scheme that can concentrate the distribution of the attention matrix. As its linear substitute, cosFormer fulfills these properties with a linear operator and a cosine-based distance re-weighting mechanism. Extensive experiments on language modeling and text understanding tasks demonstrate the effectiveness of our method. We further examine our method on long sequences and achieve state-of-the-art performance on the Long-Range Arena benchmark. The source code is available at https://github.com/OpenNLPLab/cosFormer.