 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automation of Citation Screening for Systematic Literature Reviews using Neural Networks: A Replicability Study
Jan 19, 2022
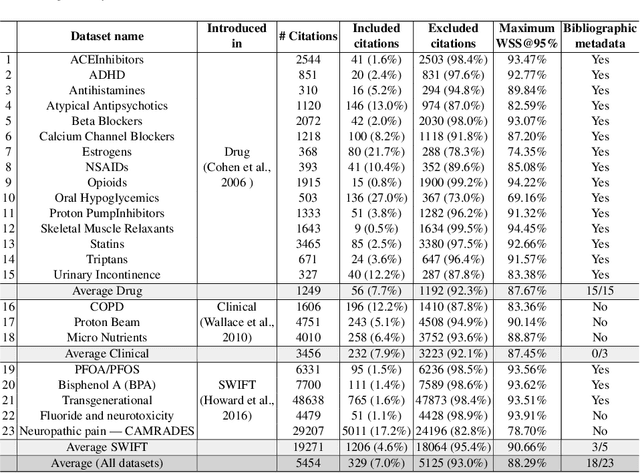
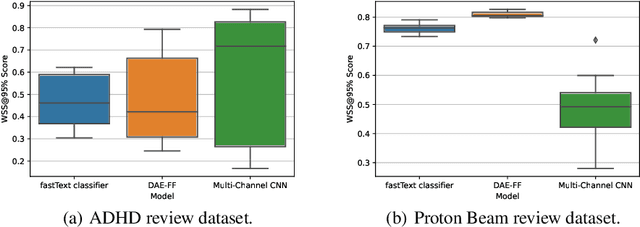
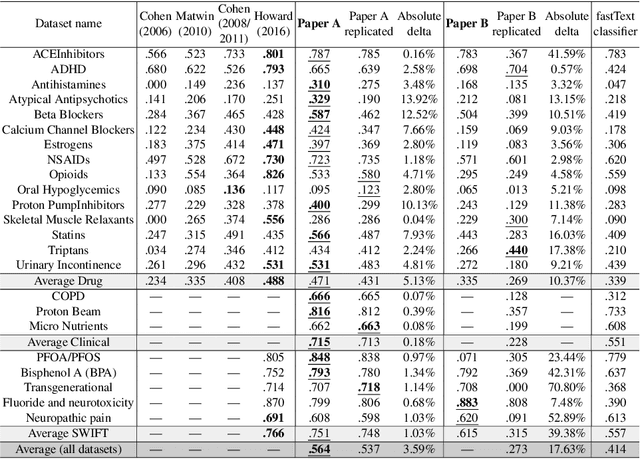
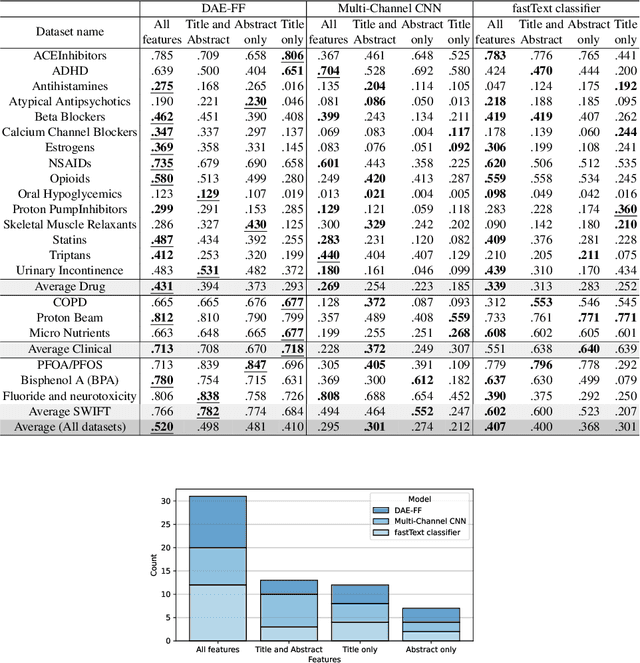
In the process of Systematic Literature Review, citation screening is estimated to be one of the most time-consuming steps. Multiple approaches to automate it using various machine learning techniques have been proposed. The first research papers that apply deep neural networks to this problem were published in the last two years. In this work, we conduct a replicability study of the first two deep learning papers for citation screening and evaluate their performance on 23 publicly available datasets. While we succeeded in replicating the results of one of the papers, we were unable to replicate the results of the other. We summarise the challenges involved in the replication, including difficulties in obtaining the datasets to match the experimental setup of the original papers and problems with executing the original source code. Motivated by this experience, we subsequently present a simpler model based on averaging word embeddings that outperforms one of the models on 18 out of 23 datasets and is, on average, 72 times faster than the second replicated approach. Finally, we measure the training time and the invariance of the models when exposed to a variety of input features and random initialisations, demonstrating differences in the robustness of these approaches.
A Lightweight and Accurate Spatial-Temporal Transformer for Traffic Forecasting
Dec 30, 2021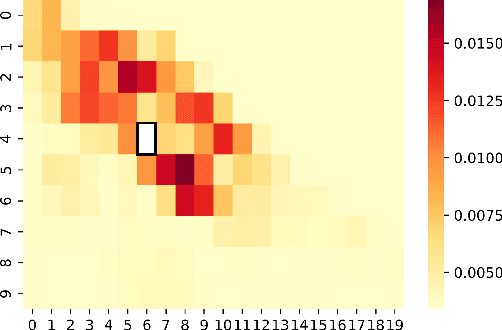
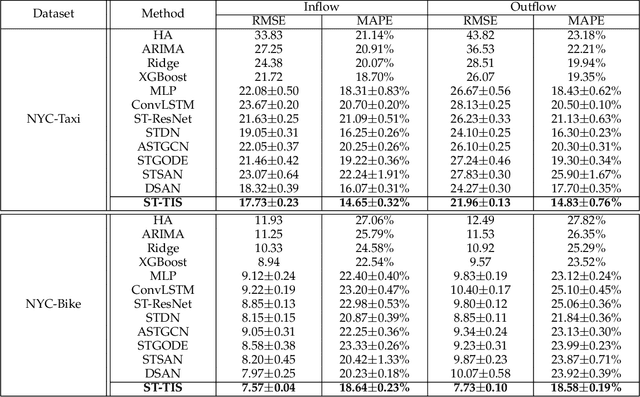
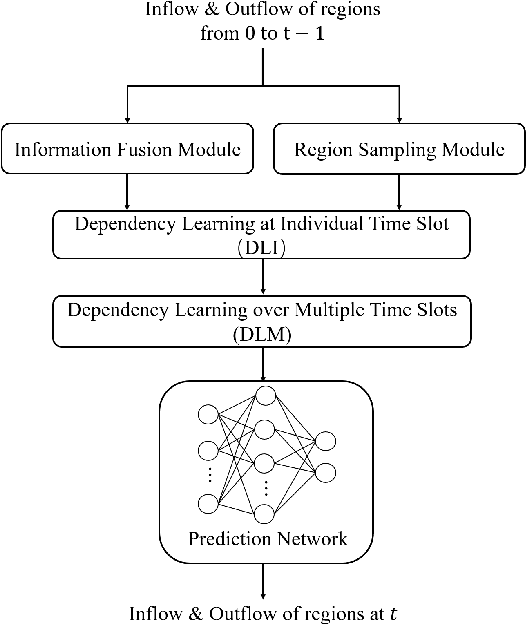
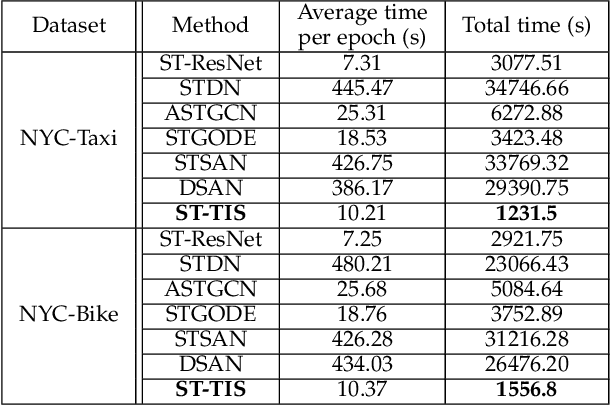
We study the forecasting problem for traffic with dynamic, possibly periodical, and joint spatial-temporal dependency between regions. Given the aggregated inflow and outflow traffic of regions in a city from time slots 0 to t-1, we predict the traffic at time t at any region. Prior arts in the area often consider the spatial and temporal dependencies in a decoupled manner or are rather computationally intensive in training with a large number of hyper-parameters to tune. We propose ST-TIS, a novel, lightweight, and accurate Spatial-Temporal Transformer with information fusion and region sampling for traffic forecasting. ST-TIS extends the canonical Transformer with information fusion and region sampling. The information fusion module captures the complex spatial-temporal dependency between regions. The region sampling module is to improve the efficiency and prediction accuracy, cutting the computation complexity for dependency learning from $O(n^2)$ to $O(n\sqrt{n})$, where n is the number of regions. With far fewer parameters than state-of-the-art models, the offline training of our model is significantly faster in terms of tuning and computation (with a reduction of up to $90\%$ on training time and network parameters). Notwithstanding such training efficiency, extensive experiments show that ST-TIS is substantially more accurate in online prediction than state-of-the-art approaches (with an average improvement of up to $11\%$ on RMSE, $14\%$ on MAPE).
System Identification via Meta-Learning in Linear Time-Varying Environments
Oct 27, 2020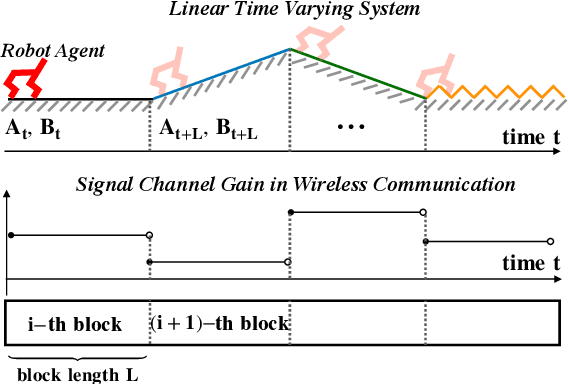
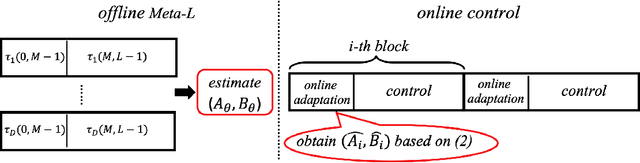
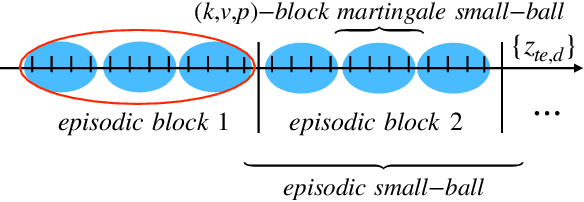
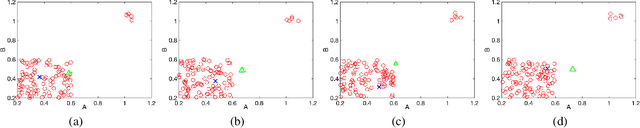
System identification is a fundamental problem in reinforcement learning, control theory and signal processing, and the non-asymptotic analysis of the corresponding sample complexity is challenging and elusive, even for linear time-varying (LTV) systems. To tackle this challenge, we develop an episodic block model for the LTV system where the model parameters remain constant within each block but change from block to block. Based on the observation that the model parameters across different blocks are related, we treat each episodic block as a learning task and then run meta-learning over many blocks for system identification, using two steps, namely offline meta-learning and online adaptation. We carry out a comprehensive non-asymptotic analysis of the performance of meta-learning based system identification. To deal with the technical challenges rooted in the sample correlation and small sample sizes in each block, we devise a new two-scale martingale small-ball approach for offline meta-learning, for arbitrary model correlation structure across blocks. We then quantify the finite time error of online adaptation by leveraging recent advances in linear stochastic approximation with correlated samples.
Evaluation of April Tag and WhyCode Fiducial Systems for Autonomous Precision Drone Landing with a Gimbal-Mounted Camera
Mar 18, 2022

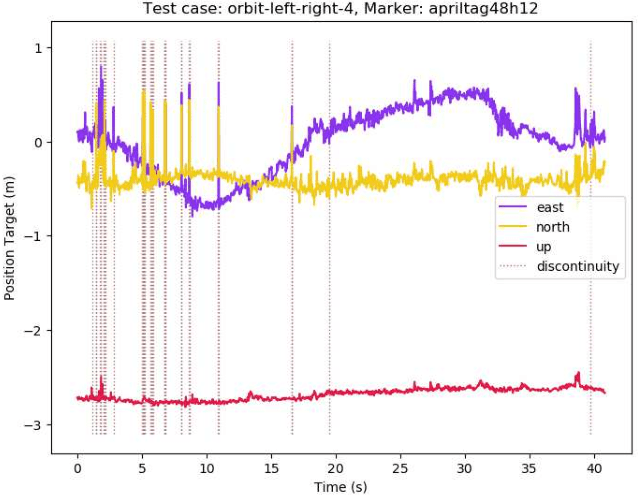
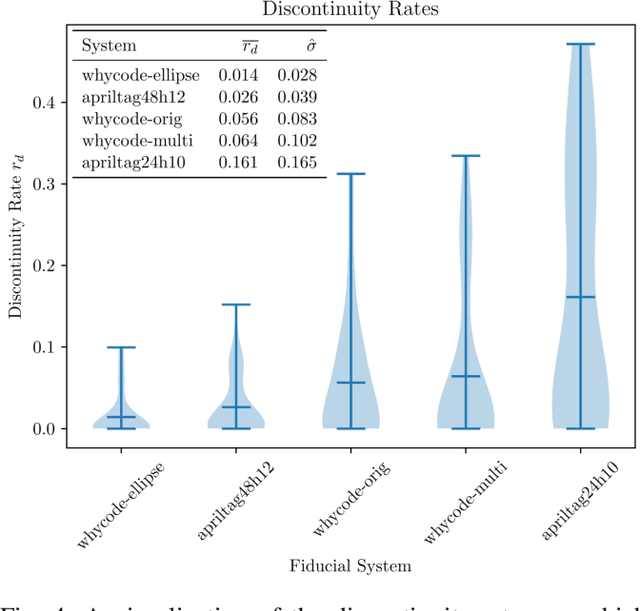
Fiducial markers provide a computationally cheap way for drones to determine their location with respect to a landing pad and execute precision landings. However, most existing work in this field uses a fixed, downward facing camera that does not leverage the common gimbal-mounted camera setup found on many drones. Such rigid systems cannot easily track detected markers, and may lose sight of the markers in non-ideal conditions (e.g. wind gusts). This paper evaluates April Tag and WhyCode fiducial systems for drone landing with a gimbal-mounted, monocular camera, with the advantage that the drone system can track the marker over time. However, since the orientation of the camera changes, we must know the orientation of the marker, which is unreliable in monocular fiducial systems. Additionally, the system must be fast. We propose 2 methods for mitigating the orientation ambiguity of WhyCode, and 1 method for increasing the runtime detection rate of April Tag. We evaluate our 3 systems against 2 default systems in terms of marker orientation ambiguity, and detection rate. We test rates of marker detection in a ROS framework on a Raspberry Pi 4, and we rank the systems in terms of their performance. Our first WhyCode variant significantly reduces orientation ambiguity with an insignificant reduction in detection rate. Our second WhyCode variant does not show significantly different orientation ambiguity from the default WhyCode system, but does provide additional functionality in terms of multi-marker WhyCode bundle arrangements. Our April Tag variant does not show performance improvements on a Raspberry Pi 4.
Sampling in Dirichlet Process Mixture Models for Clustering Streaming Data
Feb 27, 2022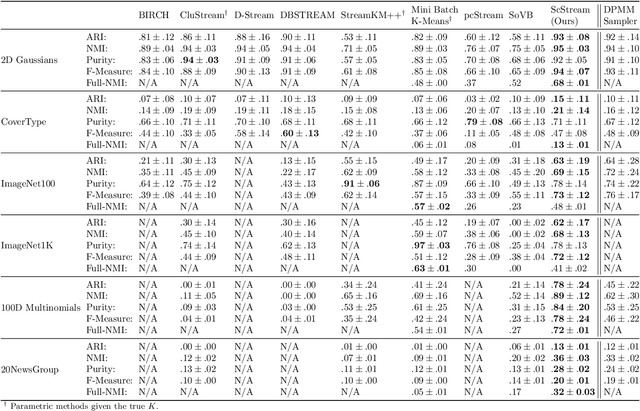



Practical tools for clustering streaming data must be fast enough to handle the arrival rate of the observations. Typically, they also must adapt on the fly to possible lack of stationarity; i.e., the data statistics may be time-dependent due to various forms of drifts, changes in the number of clusters, etc. The Dirichlet Process Mixture Model (DPMM), whose Bayesian nonparametric nature allows it to adapt its complexity to the data, seems a natural choice for the streaming-data case. In its classical formulation, however, the DPMM cannot capture common types of drifts in the data statistics. Moreover, and regardless of that limitation, existing methods for online DPMM inference are too slow to handle rapid data streams. In this work we propose adapting both the DPMM and a known DPMM sampling-based non-streaming inference method for streaming-data clustering. We demonstrate the utility of the proposed method on several challenging settings, where it obtains state-of-the-art results while being on par with other methods in terms of speed.
Earthquake Nowcasting with Deep Learning
Dec 18, 2021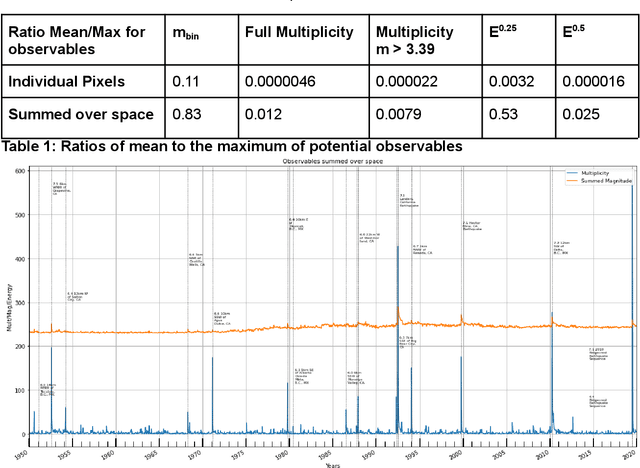
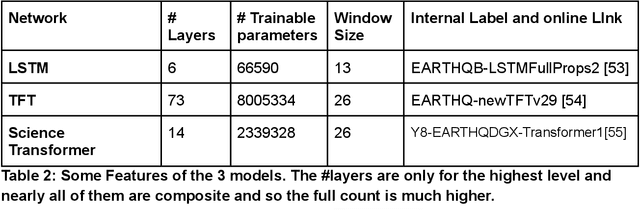
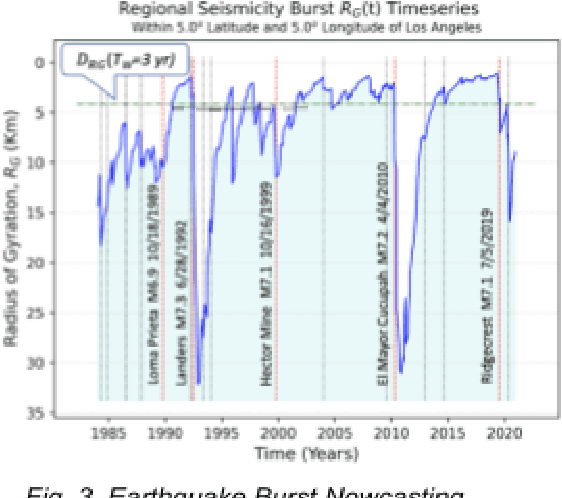

We review previous approaches to nowcasting earthquakes and introduce new approaches based on deep learning using three distinct models based on recurrent neural networks and transformers. We discuss different choices for observables and measures presenting promising initial results for a region of Southern California from 1950-2020. Earthquake activity is predicted as a function of 0.1-degree spatial bins for time periods varying from two weeks to four years. The overall quality is measured by the Nash Sutcliffe Efficiency comparing the deviation of nowcast and observation with the variance over time in each spatial region. The software is available as open-source together with the preprocessed data from the USGS.
Dense Urban Outdoor-Indoor Coverage from 3.5 to 28 GHz
Mar 08, 2022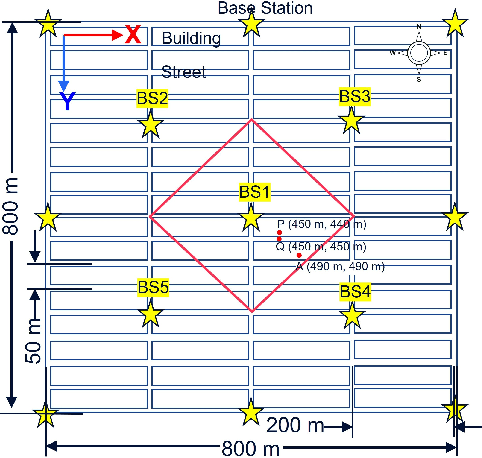
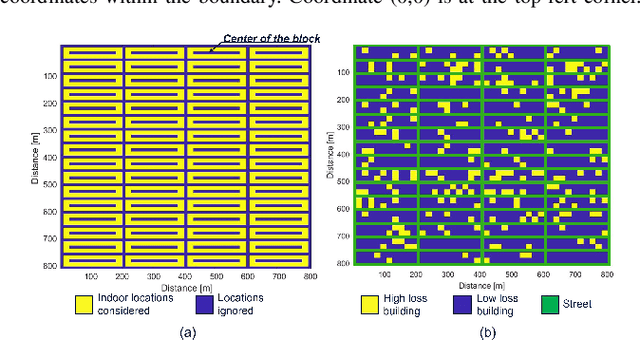
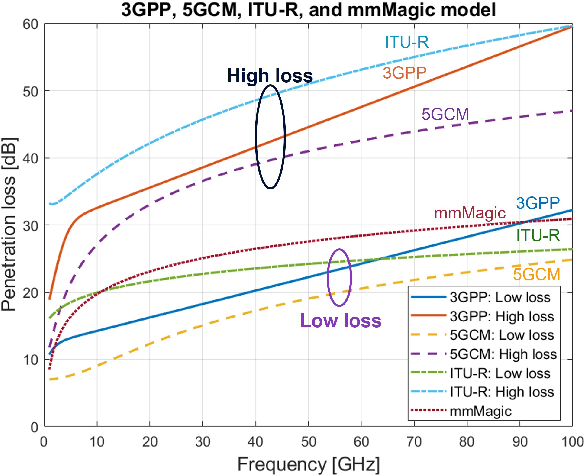
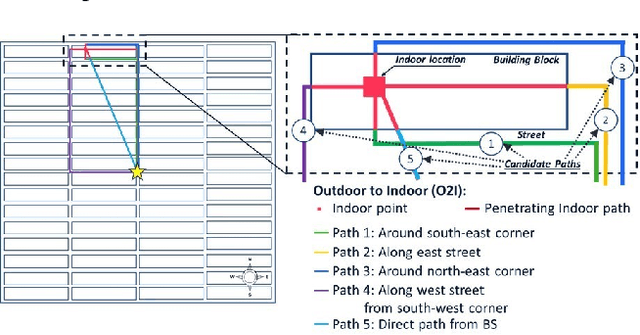
In the US, people spend 87% of their time indoors and have an average of four connected devices per person (in 2020). As such, providing indoor coverage has always been a challenge but becomes even more difficult as carrier frequencies increase to mmWave and beyond. This paper investigates the outdoor and outdoor-indoor coverage of an urban network comparing globally standardized building penetration models and implementing models to corresponding scenarios. The glass used in windows of buildings in the grid plays a pivotal role in determining the outdoor-to-indoor propagation loss. For 28 GHz with 1 W/polarization transmit power in the urban street grid, the downlink data rates for 90% of outdoor users are estimated at over 250 Mbps. In contrast, 15% of indoor users are estimated to be in outage, with SNR $<-$3 dB when base stations are 400 m apart with one-fifth of the buildings imposing high penetration loss ($\sim$ 35 dB). At 3.5 GHz, base stations may achieve over 250 Mbps for 90% indoor users if 400 MHz bandwidth with 100 W/polarization transmit power is available. The methods and models presented can be used to facilitate decisions regarding the density and transmit power required to provide high data rates to majority users in urban centers.
Tactile SLAM: Real-time inference of shape and pose from planar pushing
Nov 13, 2020

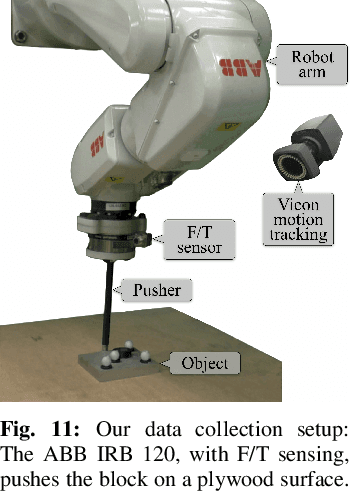
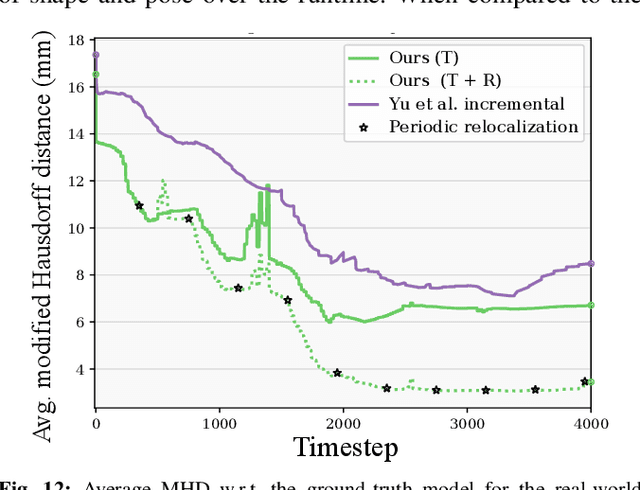
Tactile perception is central to robot manipulation in unstructured environments. However, it requires contact, and a mature implementation must infer object models while also accounting for the motion induced by the interaction. In this work, we present a method to estimate both object shape and pose in real-time from a stream of tactile measurements. This is applied towards tactile exploration of an unknown object by planar pushing. We consider this as an online SLAM problem with a nonparametric shape representation. Our formulation of tactile inference alternates between Gaussian process implicit surface regression and pose estimation on a factor graph. Through a combination of local Gaussian processes and fixed-lag smoothing, we infer object shape and pose in real-time. We evaluate our system across different objects in both simulated and real-world planar pushing tasks.
Anomalib: A Deep Learning Library for Anomaly Detection
Feb 16, 2022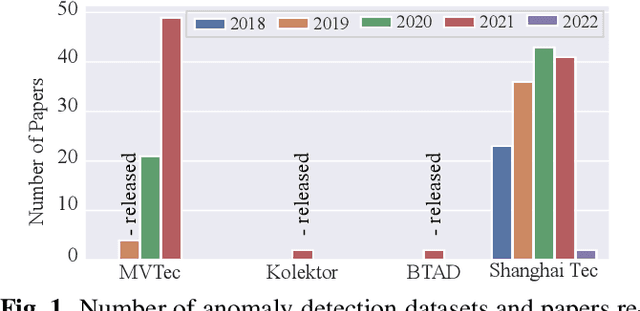

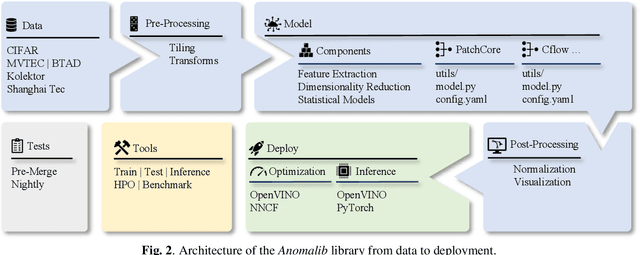

This paper introduces anomalib, a novel library for unsupervised anomaly detection and localization. With reproducibility and modularity in mind, this open-source library provides algorithms from the literature and a set of tools to design custom anomaly detection algorithms via a plug-and-play approach. Anomalib comprises state-of-the-art anomaly detection algorithms that achieve top performance on the benchmarks and that can be used off-the-shelf. In addition, the library provides components to design custom algorithms that could be tailored towards specific needs. Additional tools, including experiment trackers, visualizers, and hyper-parameter optimizers, make it simple to design and implement anomaly detection models. The library also supports OpenVINO model optimization and quantization for real-time deployment. Overall, anomalib is an extensive library for the design, implementation, and deployment of unsupervised anomaly detection models from data to the edge.
An Empirical Survey of Data Augmentation for Time Series Classification with Neural Networks
Jul 31, 2020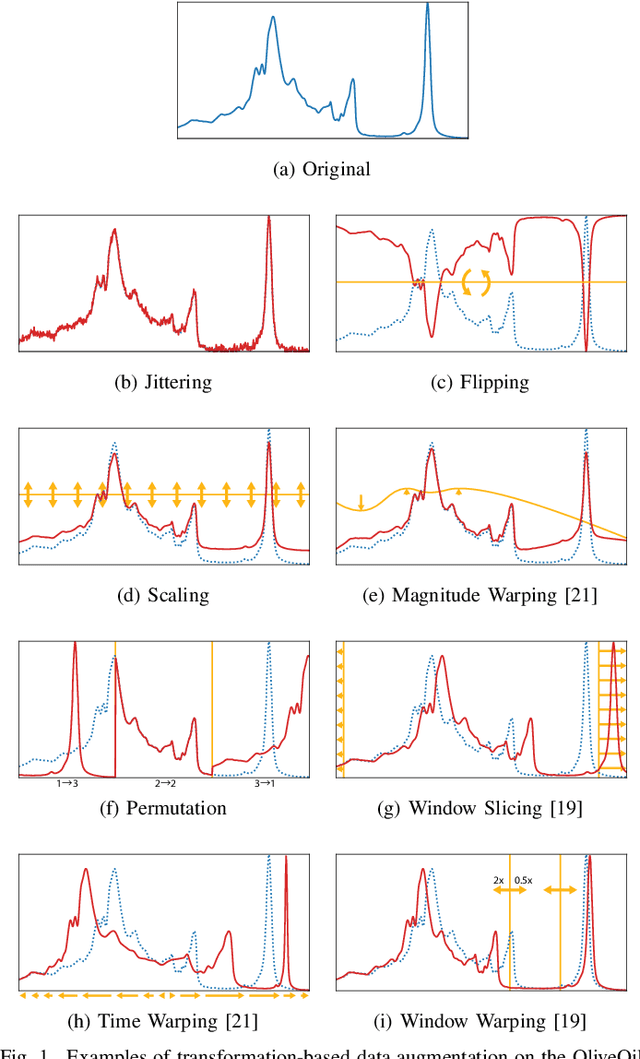
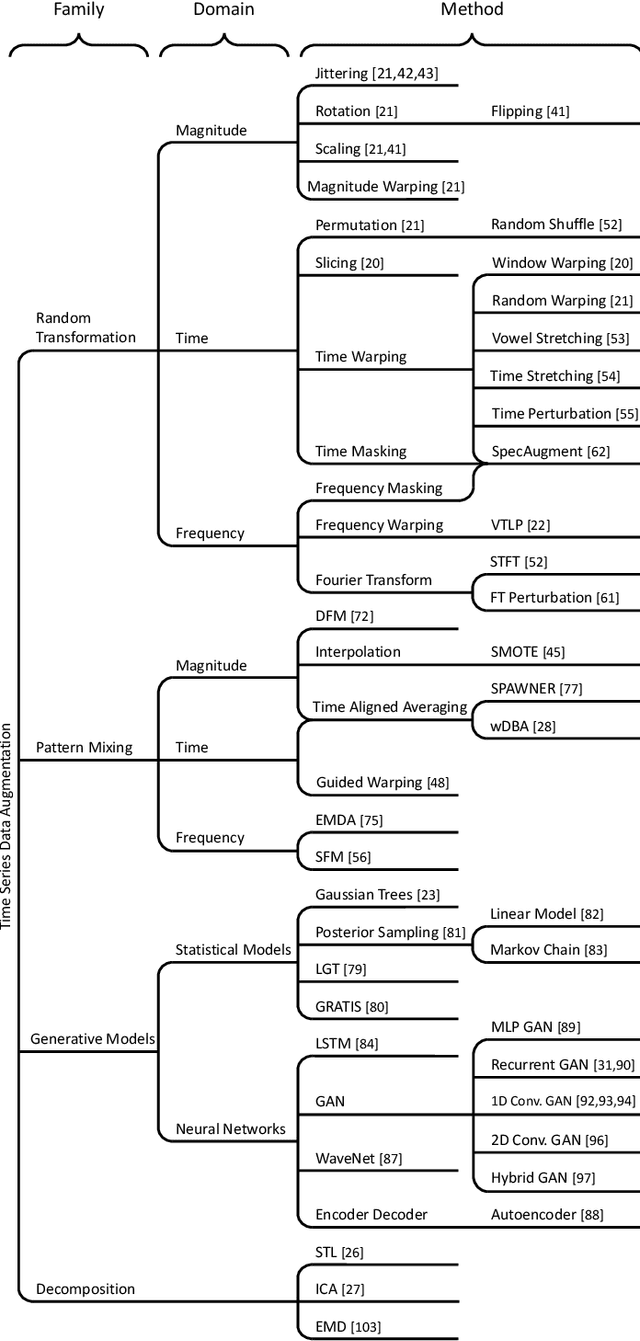
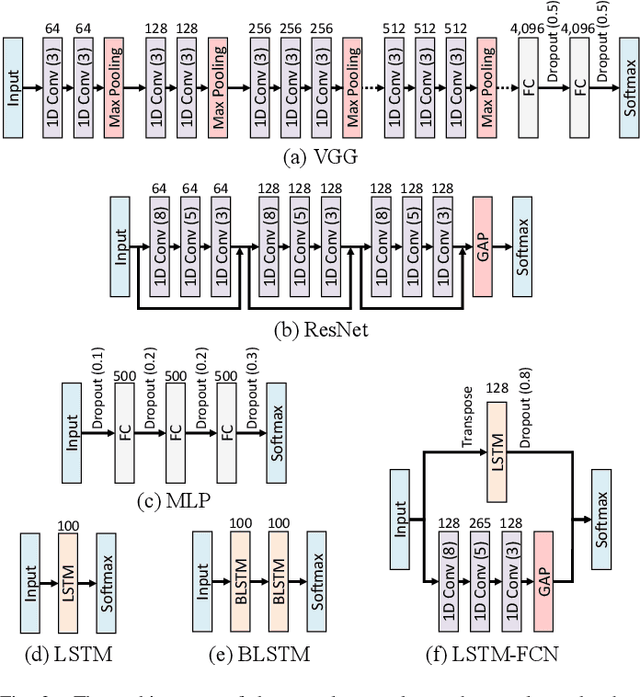
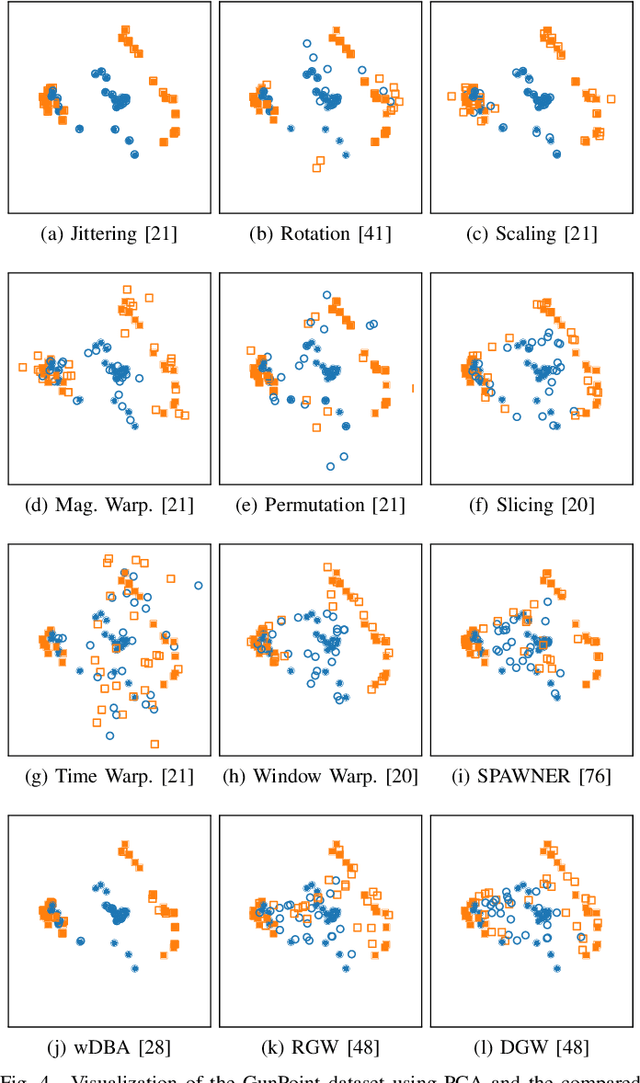
In recent times, deep artificial neural networks have achieved many successes in pattern recognition. Part of this success is the reliance on big data to increase generalization. However, in the field of time series recognition, many datasets are often very small. One method of addressing this problem is through the use of data augmentation. In this paper, we survey data augmentation techniques for time series and their application to time series classification with neural networks. We outline four families of time series data augmentation, including transformation-based methods, pattern mixing, generative models, and decomposition methods, and detail their taxonomy. Furthermore, we empirically evaluate 12 time series data augmentation methods on 128 time series classification datasets with 6 different types of neural networks. Through the results, we are able to analyze the characteristics, advantages and disadvantages, and recommendations of each data augmentation method. This survey aims to help in the selection of time series data augmentation for neural network applications.