 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automatic Recognition and Digital Documentation of Cultural Heritage Hemispherical Domes using Images
Jan 25, 2022



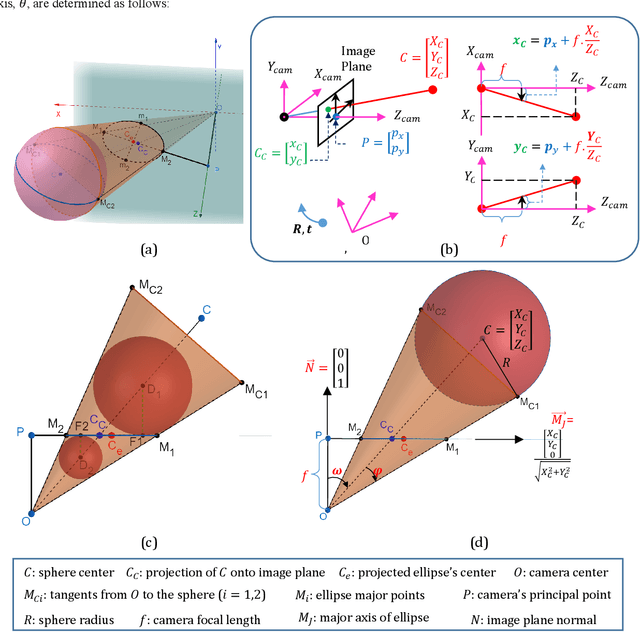
Advancements in optical metrology has enabled documentation of dense 3D point clouds of cultural heritage sites. For large scale and continuous digital documentation, processing of dense 3D point clouds becomes computationally cumbersome, and often requires additional hardware for data management, increasing the time cost, and complexity of projects. To this end, this manuscript presents an original approach to generate fast and reliable semantic digital models of heritage hemispherical domes using only two images. New closed formulations were derived to establish the relationships between spheres and their projected ellipses onto images, which fostered the development of a new automatic framework for as-built generation of spheres. The effectiveness of the proposed method was evaluated under both laboratory and real-world datasets. The results revealed that the proposed method achieved as-built modeling accuracy of around 6mm, while improving the computation time by a factor of 7, when compared to established point cloud processing methods.
A Survey on Scalable LoRaWAN for Massive IoT: Recent Advances, Potentials, and Challenges
Feb 22, 2022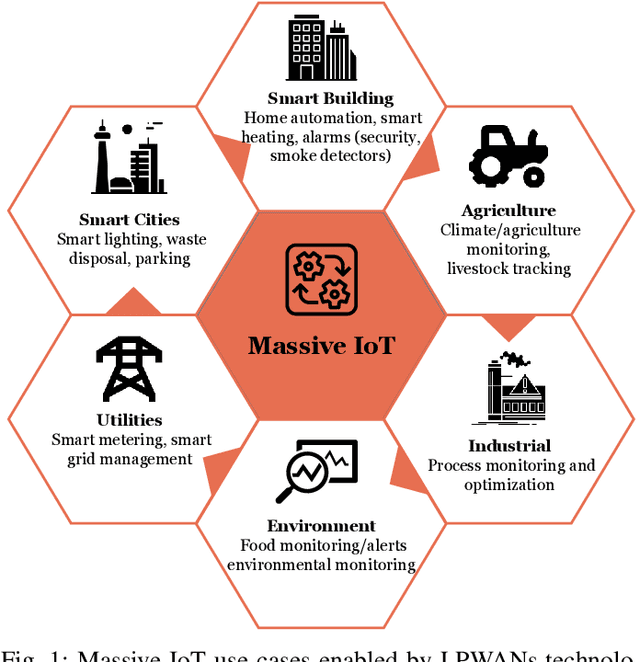
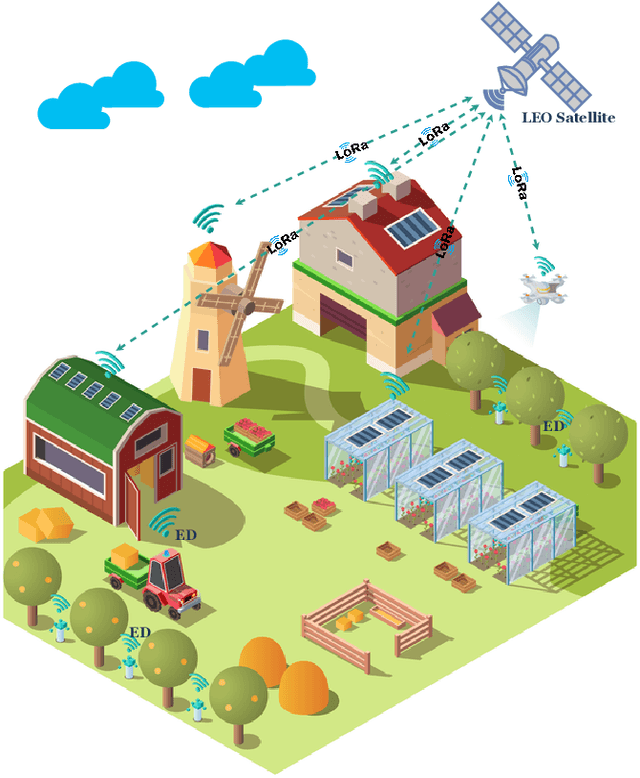
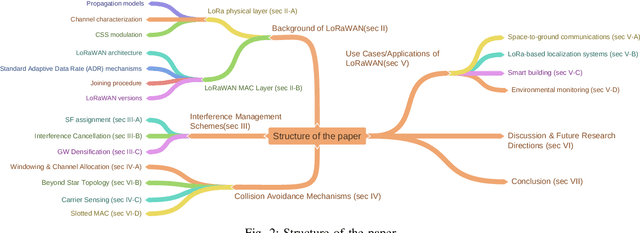
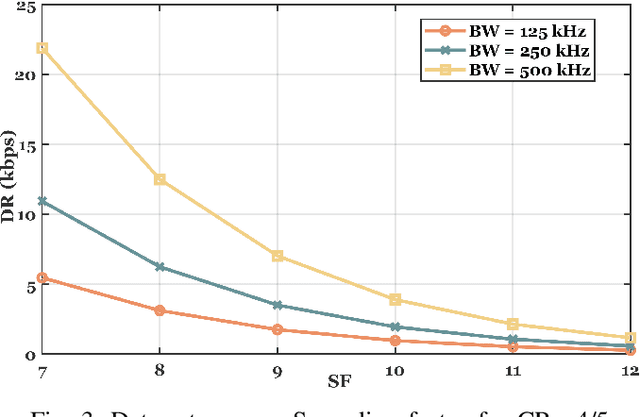
Long Range (LoRa) is the most widely used technology for enabling Low Power Wide Area Networks (LPWANs) on unlicensed frequency bands. Despite its modest Data Rates (DRs), it provides extensive coverage for low-power devices, making it an ideal communication system for many Internet of Things (IoT) applications. In general, LoRa radio is considered as the physical layer, whereas Long Range Wide Area Networks (LoRaWAN) is the MAC layer of the LoRa stack that adopts star topology to enable communication between multiple End Devices (EDs) and the network Gateway (GW). The Chirp Spread Spectrum (CSS) modulation deals with LoRa signals interference and ensures long-range communication. At the same time, the Adaptive Data Rate (ADR) mechanism allows EDs to dynamically alter some LoRa features such as the Spreading Factor (SF), Code Rate (CR), and carrier frequency to address the time variance of communication conditions in dense networks. Despite the high LoRa connectivity demand, LoRa signals interference and concurrent transmission collisions are major limitations. Therefore, to enhance LoRaWAN capacity, the LoRa alliance released many LoRaWAN versions, and the research community provided numerous solutions to develop scalable LoRaWAN technology. Hence, we thoroughly examined LoRaWAN scalability challenges and the state-of-the-art solutions in both the PHY and MAC layers. Most of these solutions rely on SF, logical, and frequency channel assignment, while others propose new network topologies or implement signal processing schemes to cancel the interference and allow LoRaWAN to connect more EDs efficiently. A summary of the existing solutions in the literature is provided at the end of the paper by describing the advantages and drawbacks of each solution and suggesting possible enhancements as future research directions.
Decontextualized I3D ConvNet for ultra-distance runners performance analysis at a glance
Mar 25, 2022
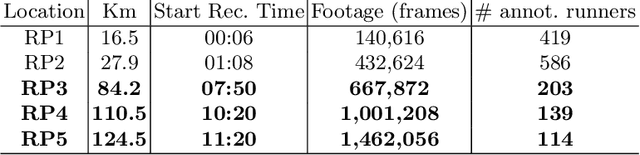
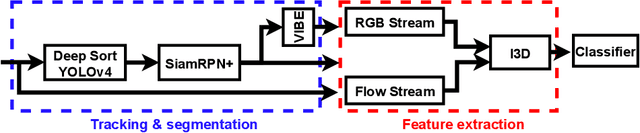

In May 2021, the site runnersworld.com published that participation in ultra-distance races has increased by 1,676% in the last 23 years. Moreover, nearly 41% of those runners participate in more than one race per year. The development of wearable devices has undoubtedly contributed to motivating participants by providing performance measures in real-time. However, we believe there is room for improvement, particularly from the organizers point of view. This work aims to determine how the runners performance can be quantified and predicted by considering a non-invasive technique focusing on the ultra-running scenario. In this sense, participants are captured when they pass through a set of locations placed along the race track. Each footage is considered an input to an I3D ConvNet to extract the participant's running gait in our work. Furthermore, weather and illumination capture conditions or occlusions may affect these footages due to the race staff and other runners. To address this challenging task, we have tracked and codified the participant's running gait at some RPs and removed the context intending to ensure a runner-of-interest proper evaluation. The evaluation suggests that the features extracted by an I3D ConvNet provide enough information to estimate the participant's performance along the different race tracks.
Speech watermarking: an approach for the forensic analysis of digital telephonic recordings
Mar 12, 2022
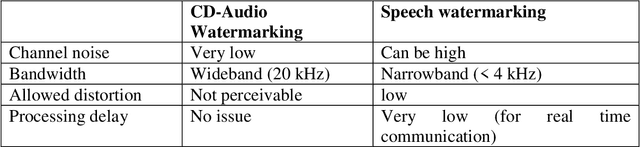
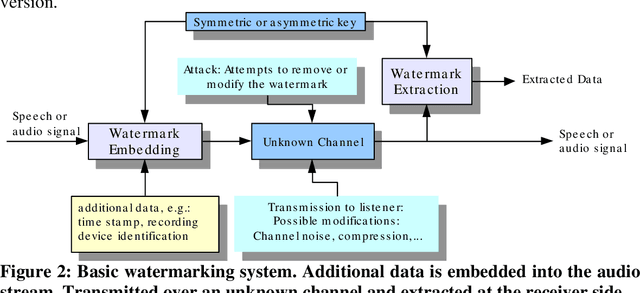
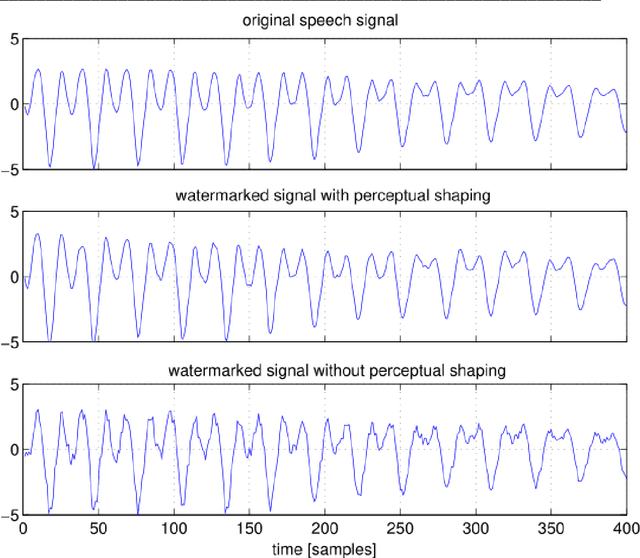
In this article, the authors discuss the problem of forensic authentication of digital audio recordings. Although forensic audio has been addressed in several articles, the existing approaches are focused on analog magnetic recordings, which are less prevalent because of the large amount of digital recorders available on the market (optical, solid state, hard disks, etc.). An approach based on digital signal processing that consists of spread spectrum techniques for speech watermarking is presented. This approach presents the advantage that the authentication is based on the signal itself rather than the recording format. Thus, it is valid for usual recording devices in police-controlled telephone intercepts. In addition, our proposal allows for the introduction of relevant information such as the recording date and time and all the relevant data (this is not always possible with classical systems). Our experimental results reveal that the speech watermarking procedure does not interfere in a significant way with the posterior forensic speaker identification.
* 15 pages
Speech-enhanced and Noise-aware Networks for Robust Speech Recognition
Mar 25, 2022
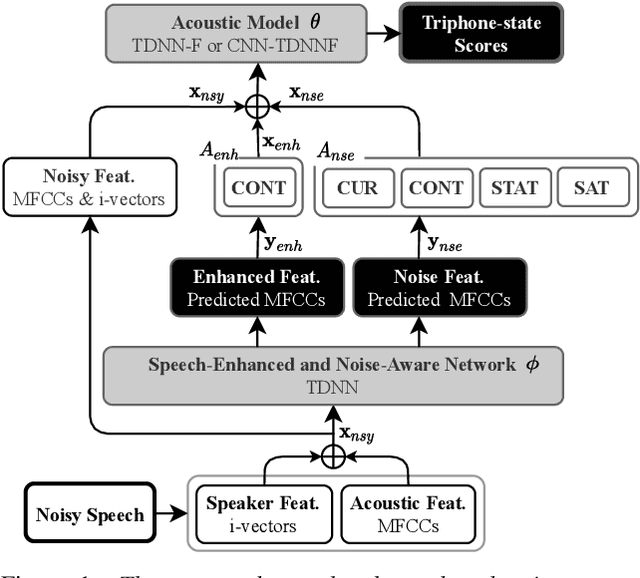
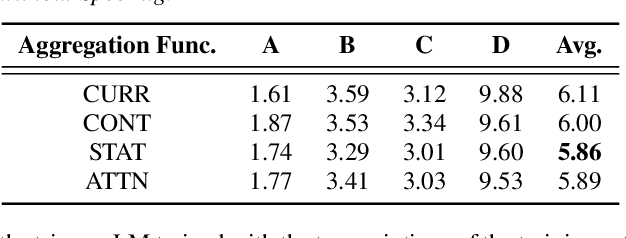
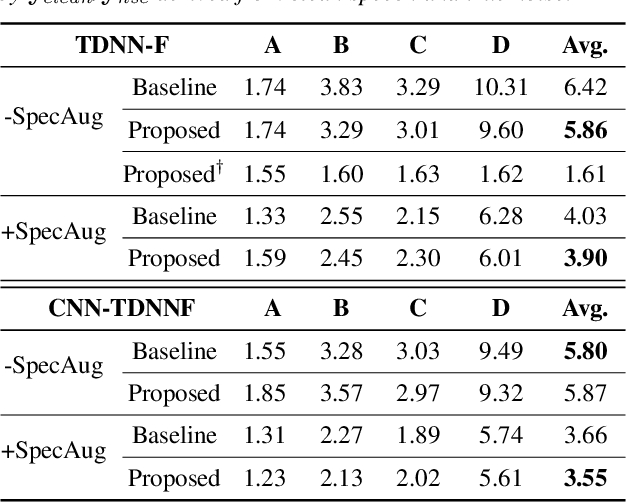
Compensation for channel mismatch and noise interference is essential for robust automatic speech recognition. Enhanced speech has been introduced into the multi-condition training of acoustic models to improve their generalization ability. In this paper, a noise-aware training framework based on two cascaded neural structures is proposed to jointly optimize speech enhancement and speech recognition. The feature enhancement module is composed of a multi-task autoencoder, where noisy speech is decomposed into clean speech and noise. By concatenating its enhanced, noise-aware, and noisy features for each frame, the acoustic-modeling module maps each feature-augmented frame into a triphone state by optimizing the lattice-free maximum mutual information and cross entropy between the predicted and actual state sequences. On top of the factorized time delay neural network (TDNN-F) and its convolutional variant (CNN-TDNNF), both with SpecAug, the two proposed systems achieve word error rate (WER) of 3.90% and 3.55%, respectively, on the Aurora-4 task. Compared with the best existing systems that use bigram and trigram language models for decoding, the proposed CNN-TDNNF-based system achieves a relative WER reduction of 15.20% and 33.53%, respectively. In addition, the proposed CNN-TDNNF-based system also outperforms the baseline CNN-TDNNF system on the AMI task.
Asynchronous Parallel Incremental Block-Coordinate Descent for Decentralized Machine Learning
Feb 07, 2022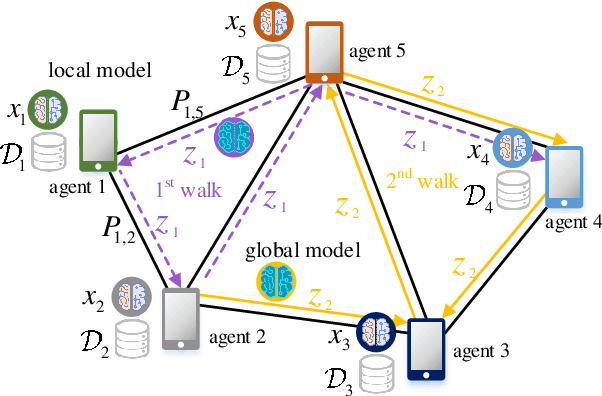
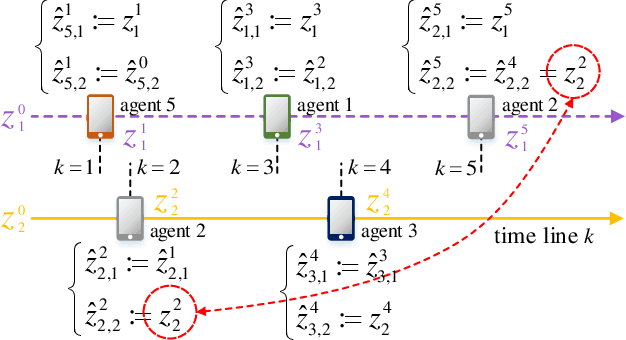
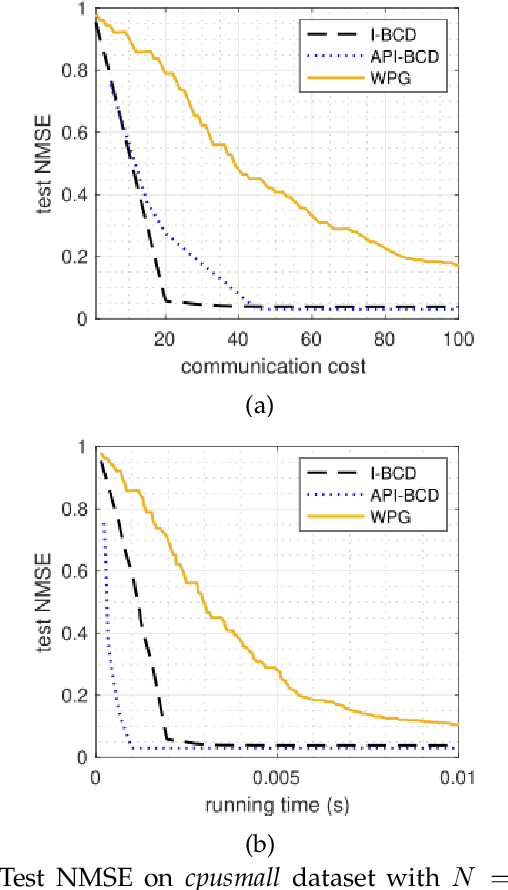
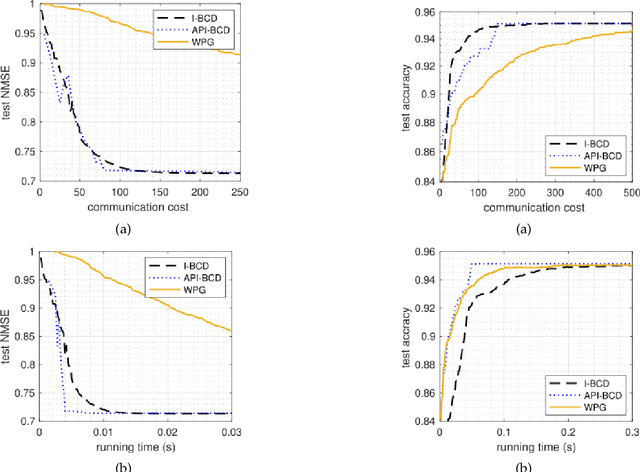
Machine learning (ML) is a key technique for big-data-driven modelling and analysis of massive Internet of Things (IoT) based intelligent and ubiquitous computing. For fast-increasing applications and data amounts, distributed learning is a promising emerging paradigm since it is often impractical or inefficient to share/aggregate data to a centralized location from distinct ones. This paper studies the problem of training an ML model over decentralized systems, where data are distributed over many user devices and the learning algorithm run on-device, with the aim of relaxing the burden at a central entity/server. Although gossip-based approaches have been used for this purpose in different use cases, they suffer from high communication costs, especially when the number of devices is large. To mitigate this, incremental-based methods are proposed. We first introduce incremental block-coordinate descent (I-BCD) for the decentralized ML, which can reduce communication costs at the expense of running time. To accelerate the convergence speed, an asynchronous parallel incremental BCD (API-BCD) method is proposed, where multiple devices/agents are active in an asynchronous fashion. We derive convergence properties for the proposed methods. Simulation results also show that our API-BCD method outperforms state of the art in terms of running time and communication costs.
GCF: Generalized Causal Forest for Heterogeneous Treatment Effect Estimation in Online Marketplace
Mar 21, 2022

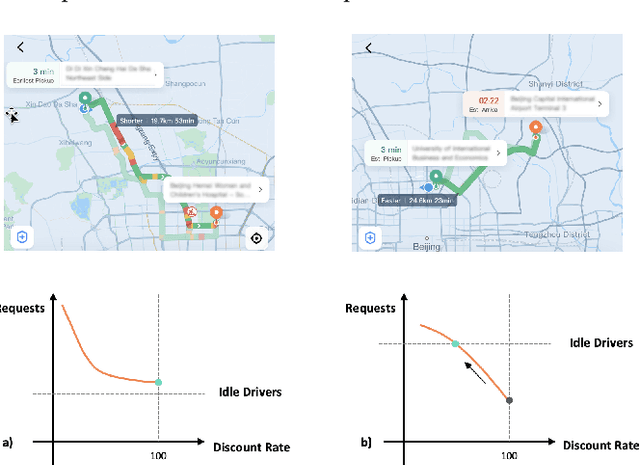
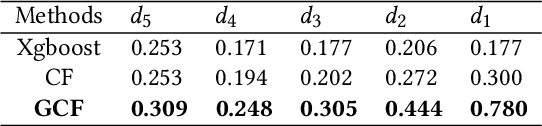
Uplift modeling is a rapidly growing approach that utilizes machine learning and causal inference methods to estimate the heterogeneous treatment effects. It has been widely adopted and applied to online marketplaces to assist large-scale decision-making in recent years. The existing popular methods, like forest-based modeling, either work only for discrete treatments or make partially linear or parametric assumptions that may suffer from model misspecification. To alleviate these problems, we extend causal forest (CF) with non-parametric dose-response functions (DRFs) that can be estimated locally using a kernel-based doubly robust estimator. Moreover, we propose a distance-based splitting criterion in the functional space of conditional DRFs to capture the heterogeneity for the continuous treatments. We call the proposed algorithm generalized causal forest (GCF) as it generalizes the use case of CF to a much broader setup. We show the effectiveness of GCF by comparing it to popular uplift modeling models on both synthetic and real-world datasets. We implement GCF in Spark and successfully deploy it into DiDi's real-time pricing system. Online A/B testing results further validate the superiority of GCF.
Learning from Irregularly-Sampled Time Series: A Missing Data Perspective
Aug 17, 2020
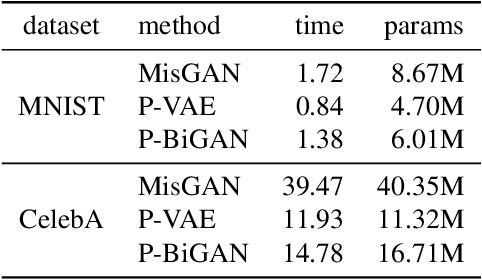
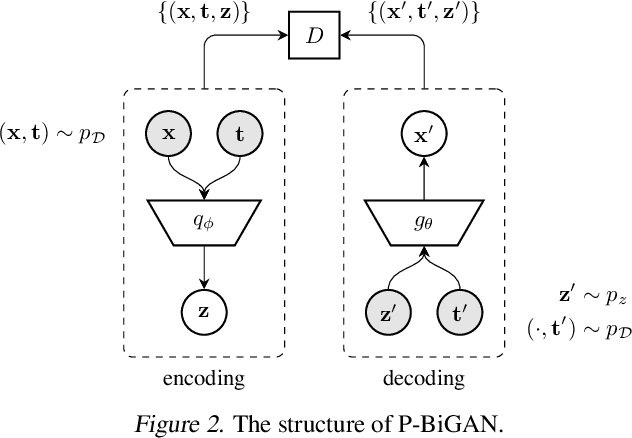
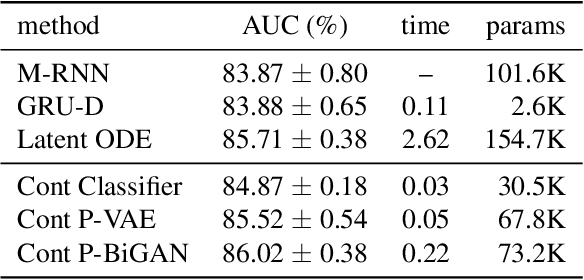
Irregularly-sampled time series occur in many domains including healthcare. They can be challenging to model because they do not naturally yield a fixed-dimensional representation as required by many standard machine learning models. In this paper, we consider irregular sampling from the perspective of missing data. We model observed irregularly-sampled time series data as a sequence of index-value pairs sampled from a continuous but unobserved function. We introduce an encoder-decoder framework for learning from such generic indexed sequences. We propose learning methods for this framework based on variational autoencoders and generative adversarial networks. For continuous irregularly-sampled time series, we introduce continuous convolutional layers that can efficiently interface with existing neural network architectures. Experiments show that our models are able to achieve competitive or better classification results on irregularly-sampled multivariate time series compared to recent RNN models while offering significantly faster training times.
Learning to Act with Affordance-Aware Multimodal Neural SLAM
Jan 24, 2022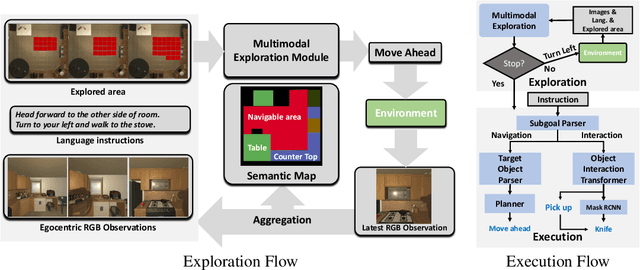

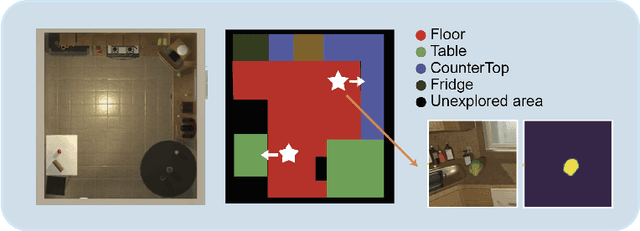
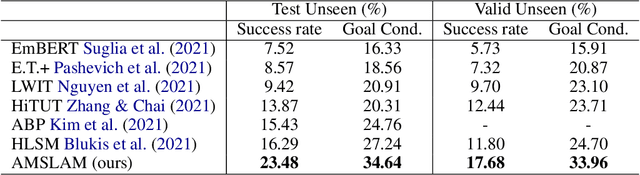
Recent years have witnessed an emerging paradigm shift toward embodied artificial intelligence, in which an agent must learn to solve challenging tasks by interacting with its environment. There are several challenges in solving embodied multimodal tasks, including long-horizon planning, vision-and-language grounding, and efficient exploration. We focus on a critical bottleneck, namely the performance of planning and navigation. To tackle this challenge, we propose a Neural SLAM approach that, for the first time, utilizes several modalities for exploration, predicts an affordance-aware semantic map, and plans over it at the same time. This significantly improves exploration efficiency, leads to robust long-horizon planning, and enables effective vision-and-language grounding. With the proposed Affordance-aware Multimodal Neural SLAM (AMSLAM) approach, we obtain more than $40\%$ improvement over prior published work on the ALFRED benchmark and set a new state-of-the-art generalization performance at a success rate of $23.48\%$ on the test unseen scenes.
A Novel Chaos-based Light-weight Image Encryption Scheme for Multi-modal Hearing Aids
Feb 11, 2022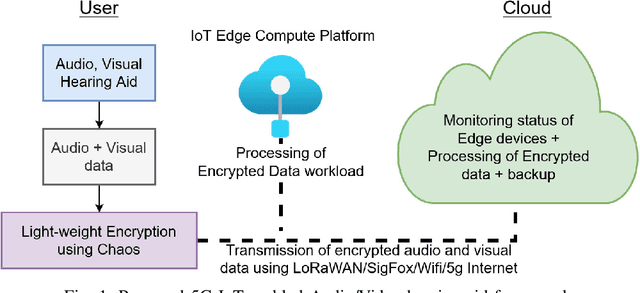

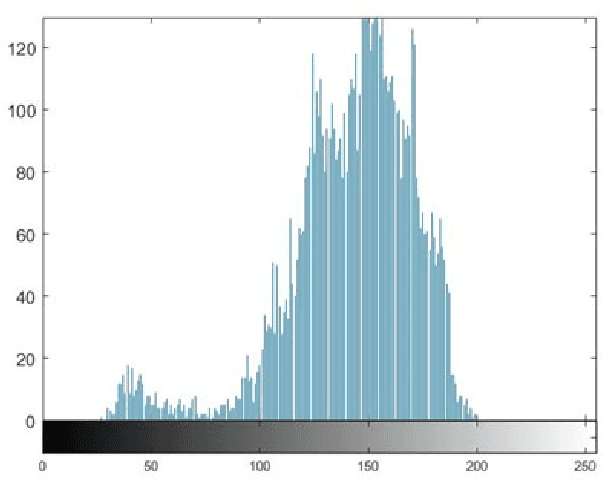
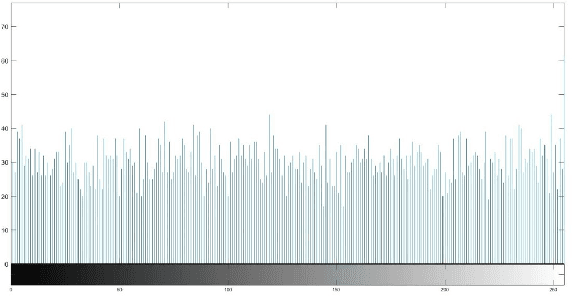
Multimodal hearing aids (HAs) aim to deliver more intelligible audio in noisy environments by contextually sensing and processing data in the form of not only audio but also visual information (e.g. lip reading). Machine learning techniques can play a pivotal role for the contextually processing of multimodal data. However, since the computational power of HA devices is low, therefore this data must be processed either on the edge or cloud which, in turn, poses privacy concerns for sensitive user data. Existing literature proposes several techniques for data encryption but their computational complexity is a major bottleneck to meet strict latency requirements for development of future multi-modal hearing aids. To overcome this problem, this paper proposes a novel real-time audio/visual data encryption scheme based on chaos-based encryption using the Tangent-Delay Ellipse Reflecting Cavity-Map System (TD-ERCS) map and Non-linear Chaotic (NCA) Algorithm. The results achieved against different security parameters, including Correlation Coefficient, Unified Averaged Changed Intensity (UACI), Key Sensitivity Analysis, Number of Changing Pixel Rate (NPCR), Mean-Square Error (MSE), Peak Signal to Noise Ratio (PSNR), Entropy test, and Chi-test, indicate that the newly proposed scheme is more lightweight due to its lower execution time as compared to existing schemes and more secure due to increased key-space against modern brute-force attacks.