 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An untrained deep learning method for reconstructing dynamic magnetic resonance images from accelerated model-based data
May 04, 2022
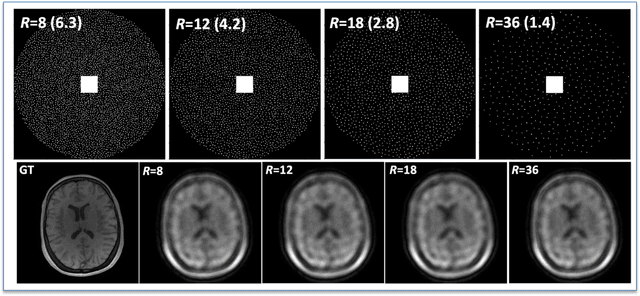
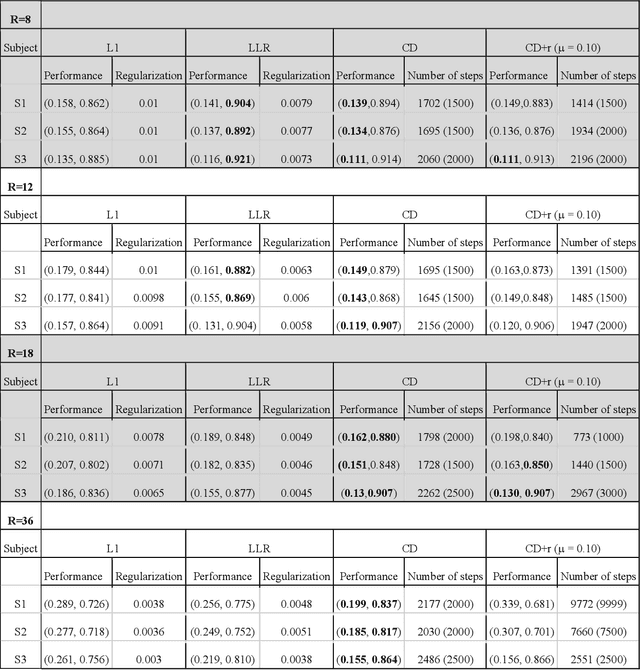
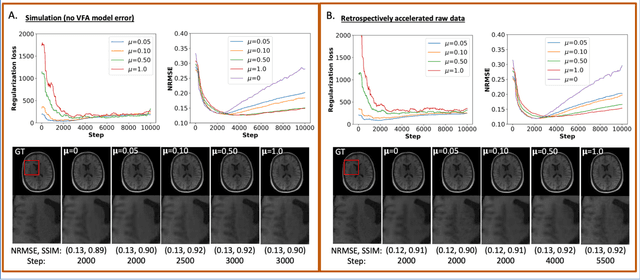
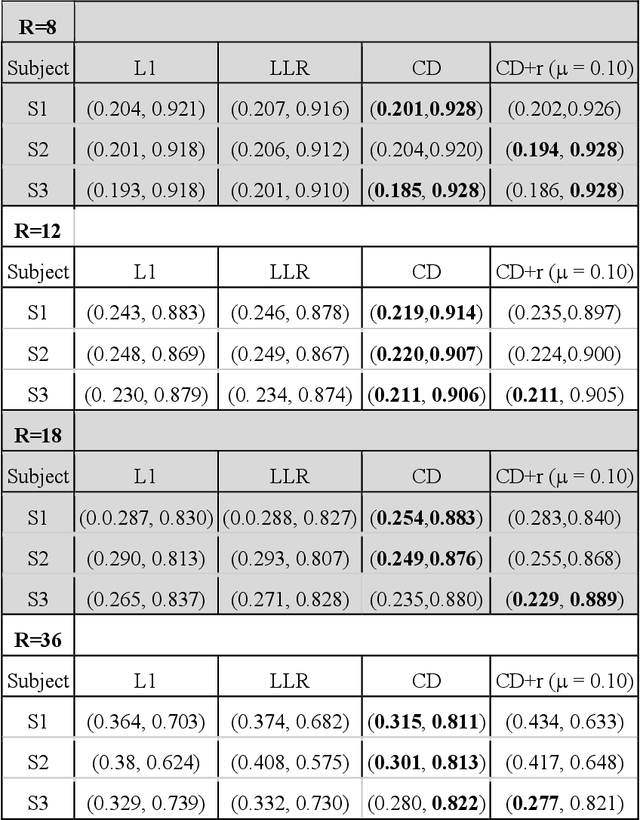
The purpose of this work is to implement physics-based regularization as a stopping condition in tuning an untrained deep neural network for reconstructing MR images from accelerated data. The ConvDecoder neural network was trained with a physics-based regularization term incorporating the spoiled gradient echo equation that describes variable-flip angle (VFA) data. Fully-sampled VFA k-space data were retrospectively accelerated by factors of R={8,12,18,36} and reconstructed with ConvDecoder (CD), ConvDecoder with the proposed regularization (CD+r), locally low-rank (LR) reconstruction, and compressed sensing with L1-wavelet regularization (L1). Final images from CD+r training were evaluated at the \emph{argmin} of the regularization loss; whereas the CD, LR, and L1 reconstructions were chosen optimally based on ground truth data. The performance measures used were the normalized root-mean square error, the concordance correlation coefficient (CCC), and the structural similarity index (SSIM). The CD+r reconstructions, chosen using the stopping condition, yielded SSIMs that were similar to the CD (p=0.47) and LR SSIMs (p=0.95) across R and that were significantly higher than the L1 SSIMs (p=0.04). The CCC values for the CD+r T1 maps across all R and subjects were greater than those corresponding to the L1 (p=0.15) and LR (p=0.13) T1 maps, respectively. For R > 12 (<4.2 minutes scan time), L1 and LR T1 maps exhibit a loss of spatially refined details compared to CD+r. We conclude that the use of an untrained neural network together with a physics-based regularization loss shows promise as a measure for determining the optimal stopping point in training without relying on fully-sampled ground truth data.
Graph Normalized-LMP Algorithm for Signal Estimation Under Impulsive Noise
Mar 01, 2022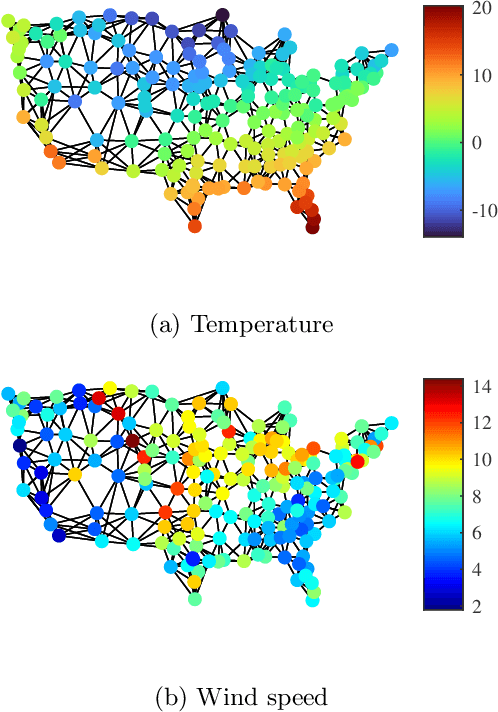
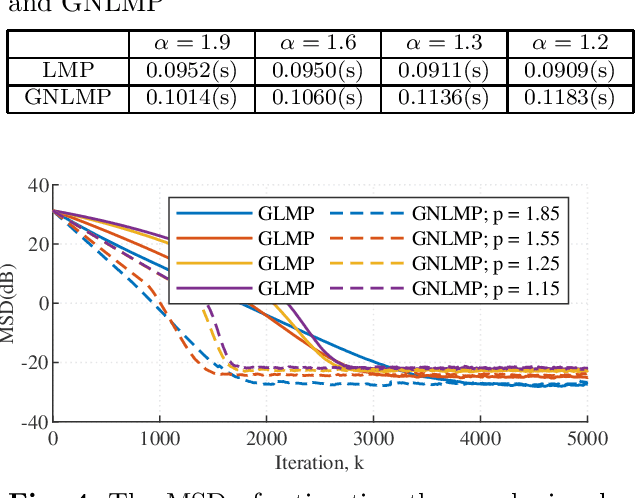
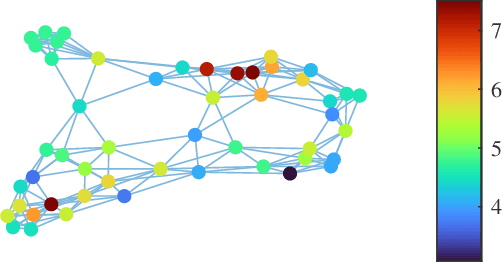
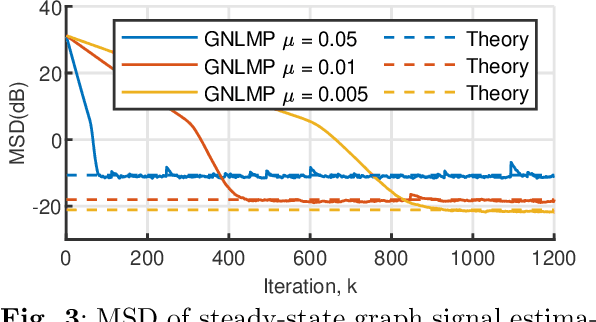
In this paper, we introduce an adaptive graph normalized least mean pth power (GNLMP) algorithm for graph signal processing (GSP) that utilizes GSP techniques, including bandlimited filtering and node sampling, to estimate sampled graph signals under impulsive noise. Different from least-squares-based algorithms, such as the adaptive GSP Least Mean Squares (GLMS) algorithm and the normalized GLMS (GNLMS) algorithm, the GNLMP algorithm has the ability to reconstruct a graph signal that is corrupted by non-Gaussian noise with heavy-tailed characteristics. Compared to the recently introduced adaptive GSP least mean pth power (GLMP) algorithm, the GNLMP algorithm reduces the number of iterations to converge to a steady graph signal. The convergence condition of the GNLMP algorithm is derived, and the ability of the GNLMP algorithm to process multidimensional time-varying graph signals with multiple features is demonstrated as well. Simulations show the performance of the GNLMP algorithm in estimating steady-state and time-varying graph signals is faster than GLMP and more robust in comparison to GLMS and GNLMS.
Algorithms and Theory for Supervised Gradual Domain Adaptation
Apr 25, 2022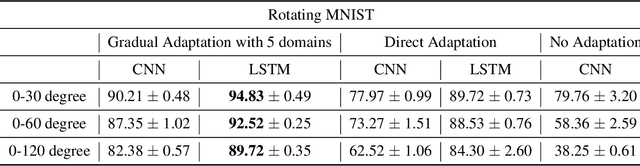
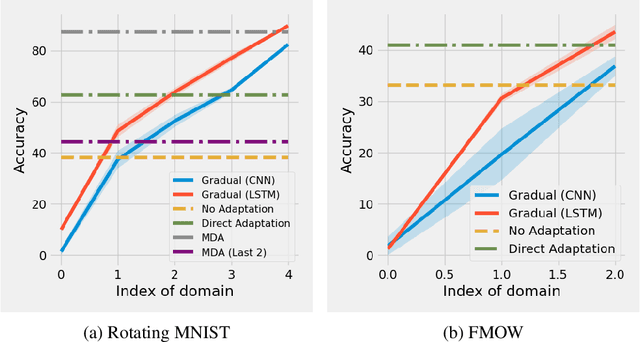
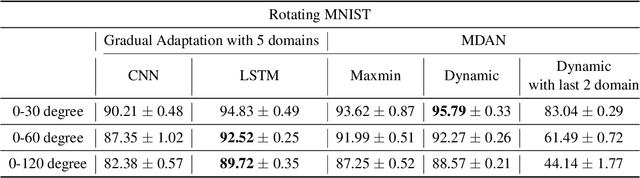
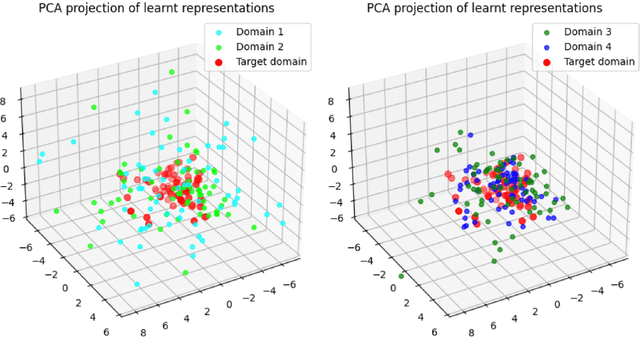
The phenomenon of data distribution evolving over time has been observed in a range of applications, calling the needs of adaptive learning algorithms. We thus study the problem of supervised gradual domain adaptation, where labeled data from shifting distributions are available to the learner along the trajectory, and we aim to learn a classifier on a target data distribution of interest. Under this setting, we provide the first generalization upper bound on the learning error under mild assumptions. Our results are algorithm agnostic, general for a range of loss functions, and only depend linearly on the averaged learning error across the trajectory. This shows significant improvement compared to the previous upper bound for unsupervised gradual domain adaptation, where the learning error on the target domain depends exponentially on the initial error on the source domain. Compared with the offline setting of learning from multiple domains, our results also suggest the potential benefits of the temporal structure among different domains in adapting to the target one. Empirically, our theoretical results imply that learning proper representations across the domains will effectively mitigate the learning errors. Motivated by these theoretical insights, we propose a min-max learning objective to learn the representation and classifier simultaneously. Experimental results on both semi-synthetic and large-scale real datasets corroborate our findings and demonstrate the effectiveness of our objectives.
Online Planning in POMDPs with Self-Improving Simulators
Jan 27, 2022

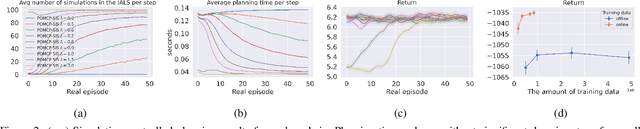

How can we plan efficiently in a large and complex environment when the time budget is limited? Given the original simulator of the environment, which may be computationally very demanding, we propose to learn online an approximate but much faster simulator that improves over time. To plan reliably and efficiently while the approximate simulator is learning, we develop a method that adaptively decides which simulator to use for every simulation, based on a statistic that measures the accuracy of the approximate simulator. This allows us to use the approximate simulator to replace the original simulator for faster simulations when it is accurate enough under the current context, thus trading off simulation speed and accuracy. Experimental results in two large domains show that when integrated with POMCP, our approach allows to plan with improving efficiency over time.
Untrimmed Action Anticipation
Feb 08, 2022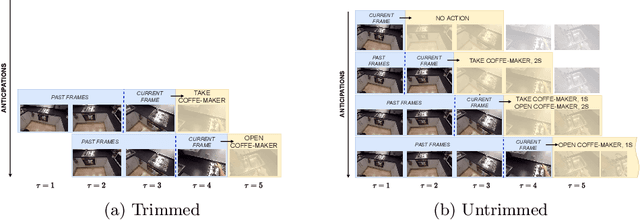
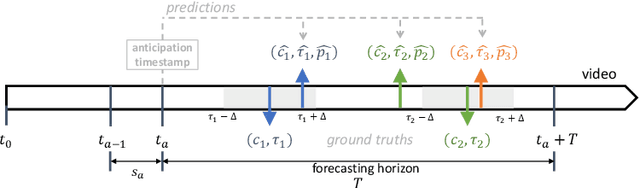
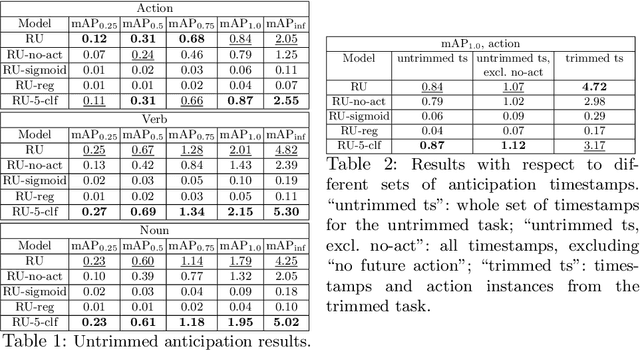
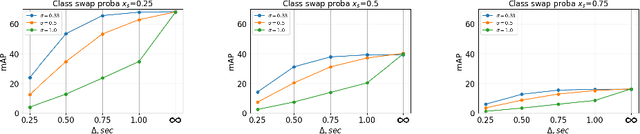
Egocentric action anticipation consists in predicting a future action the camera wearer will perform from egocentric video. While the task has recently attracted the attention of the research community, current approaches assume that the input videos are "trimmed", meaning that a short video sequence is sampled a fixed time before the beginning of the action. We argue that, despite the recent advances in the field, trimmed action anticipation has a limited applicability in real-world scenarios where it is important to deal with "untrimmed" video inputs and it cannot be assumed that the exact moment in which the action will begin is known at test time. To overcome such limitations, we propose an untrimmed action anticipation task, which, similarly to temporal action detection, assumes that the input video is untrimmed at test time, while still requiring predictions to be made before the actions actually take place. We design an evaluation procedure for methods designed to address this novel task, and compare several baselines on the EPIC-KITCHENS-100 dataset. Experiments show that the performance of current models designed for trimmed action anticipation is very limited and more research on this task is required.
Accelerating Real-Time Question Answering via Question Generation
Sep 10, 2020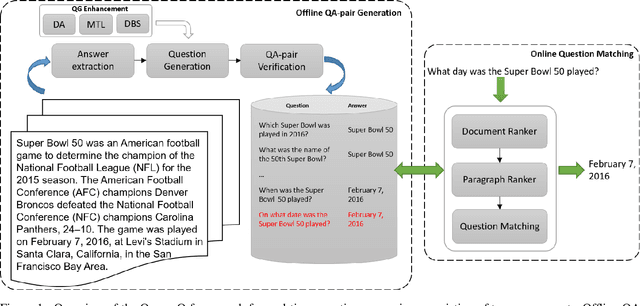
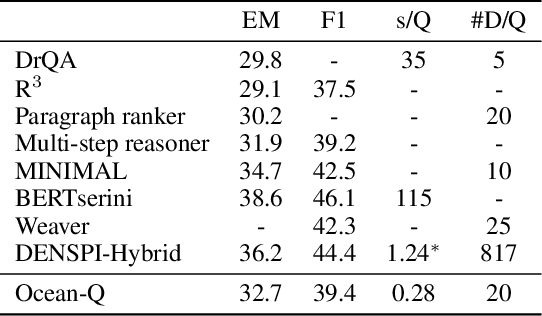
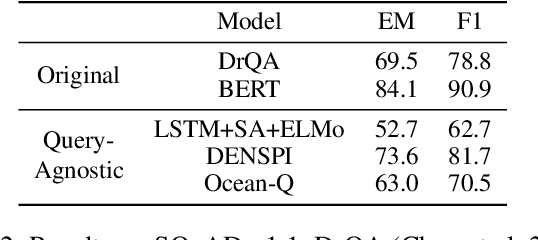
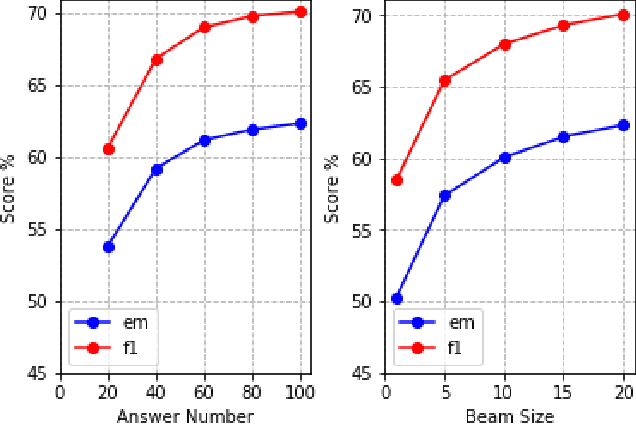
Existing approaches to real-time question answering (RTQA) rely on learning the representations of only key phrases in the documents, then matching them with the question representation to derive answer. However, such approach is bottlenecked by the encoding time of real-time questions, thus suffering from detectable latency in deployment for large-volume traffic. To accelerate RTQA for practical use, we present Ocean-Q (an Ocean of Questions), a novel approach that leverages question generation (QG) for RTQA. Ocean-Q introduces a QG model to generate a large pool of question-answer (QA) pairs offline, then in real time matches an input question with the candidate QA pool to predict the answer without question encoding. To further improve QG quality, we propose a new data augmentation method and leverage multi-task learning and diverse beam search to boost RTQA performance. Experiments on SQuAD(-open) and HotpotQA benchmarks demonstrate that Ocean-Q is able to accelerate the fastest state-of-the-art RTQA system by 4X times, with only a 3+% accuracy drop.
Multiple Narrow-band signals Direction Finding with TMLA by Nonuniform Period Modulation
Mar 30, 2022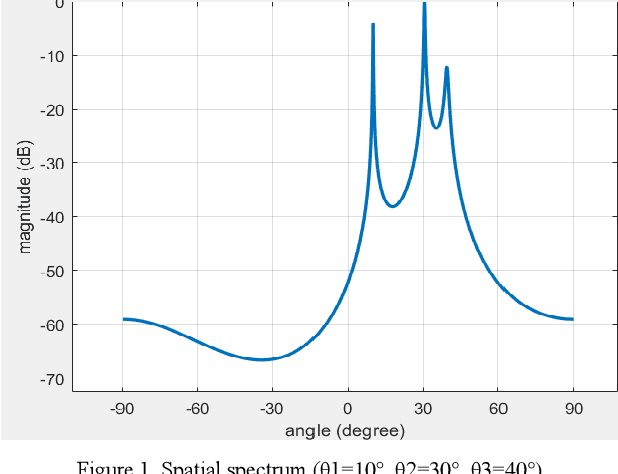

A new array signal reconstruction and signal-channel DOA estimation method based on TMLA by nonuniform period modulation are proposed. By using non-uniform period modulation, the harmonic component produced by different elements could be separated. Therefore, the conventional snapshot could be reconstructed by analyzing the spectrum of the combined signal. Then spatial spectrum estimation method is used to implement DOA estimation. Numerical simulations are provided to verify the feasibility and accuracy of the proposed method. Since the duration of the signal in the frequency domain analysis processed in a single time is very short, this method is also applicable to narrowband signals. Another highlight is that this method can simultaneously measure the number of the elements-1 angle of incident signals.
SemAttNet: Towards Attention-based Semantic Aware Guided Depth Completion
Apr 28, 2022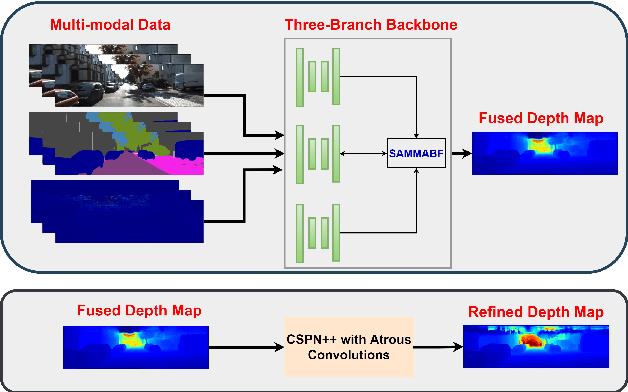
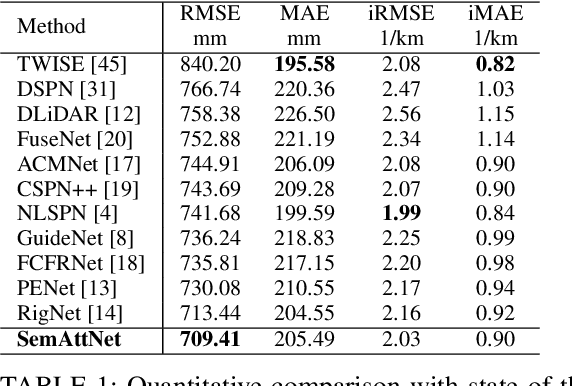
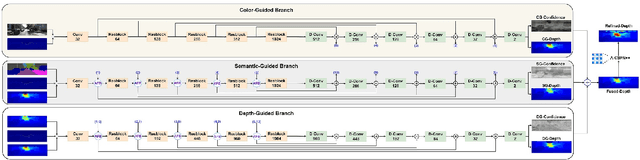

Depth completion involves recovering a dense depth map from a sparse map and an RGB image. Recent approaches focus on utilizing color images as guidance images to recover depth at invalid pixels. However, color images alone are not enough to provide the necessary semantic understanding of the scene. Consequently, the depth completion task suffers from sudden illumination changes in RGB images (e.g., shadows). In this paper, we propose a novel three-branch backbone comprising color-guided, semantic-guided, and depth-guided branches. Specifically, the color-guided branch takes a sparse depth map and RGB image as an input and generates color depth which includes color cues (e.g., object boundaries) of the scene. The predicted dense depth map of color-guided branch along-with semantic image and sparse depth map is passed as input to semantic-guided branch for estimating semantic depth. The depth-guided branch takes sparse, color, and semantic depths to generate the dense depth map. The color depth, semantic depth, and guided depth are adaptively fused to produce the output of our proposed three-branch backbone. In addition, we also propose to apply semantic-aware multi-modal attention-based fusion block (SAMMAFB) to fuse features between all three branches. We further use CSPN++ with Atrous convolutions to refine the dense depth map produced by our three-branch backbone. Extensive experiments show that our model achieves state-of-the-art performance in the KITTI depth completion benchmark at the time of submission.
How certain are your uncertainties?
Mar 01, 2022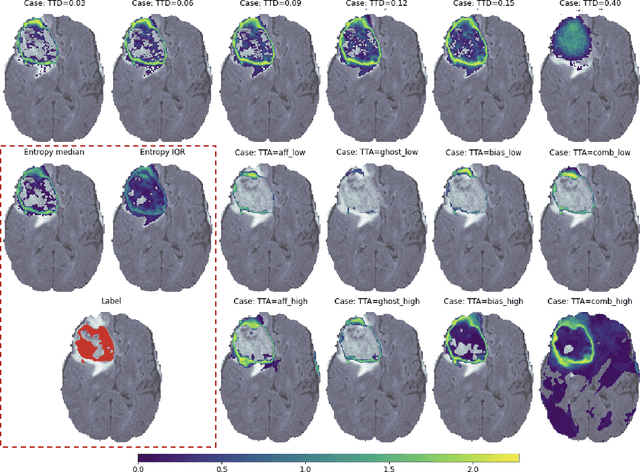
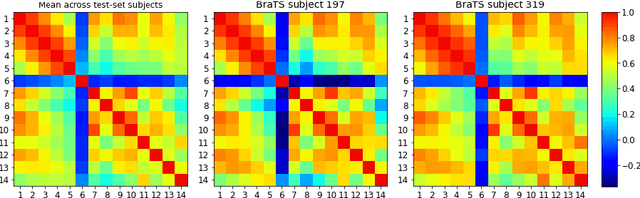
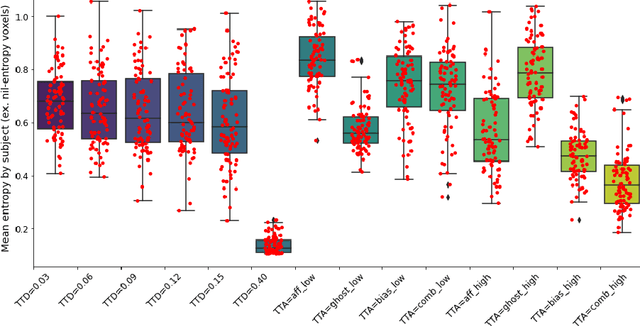
Having a measure of uncertainty in the output of a deep learning method is useful in several ways, such as in assisting with interpretation of the outputs, helping build confidence with end users, and for improving the training and performance of the networks. Therefore, several different methods have been proposed to capture various types of uncertainty, including epistemic (relating to the model used) and aleatoric (relating to the data) sources, with the most commonly used methods for estimating these being test-time dropout for epistemic uncertainty and test-time augmentation for aleatoric uncertainty. However, these methods are parameterised (e.g. amount of dropout or type and level of augmentation) and so there is a whole range of possible uncertainties that could be calculated, even with a fixed network and dataset. This work investigates the stability of these uncertainty measurements, in terms of both magnitude and spatial pattern. In experiments using the well characterised BraTS challenge, we demonstrate substantial variability in the magnitude and spatial pattern of these uncertainties, and discuss the implications for interpretability, repeatability and confidence in results.
Near-Field Rainbow: Wideband Beam Training for XL-MIMO
May 07, 2022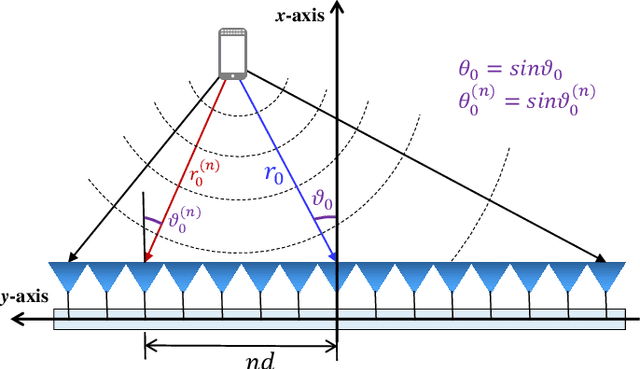
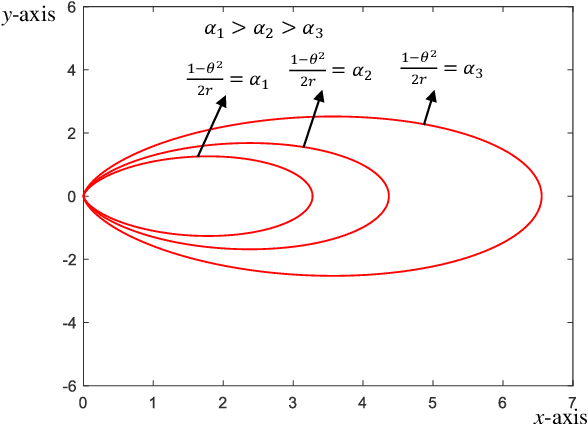
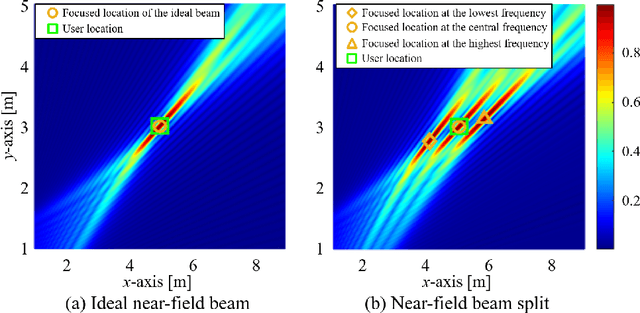
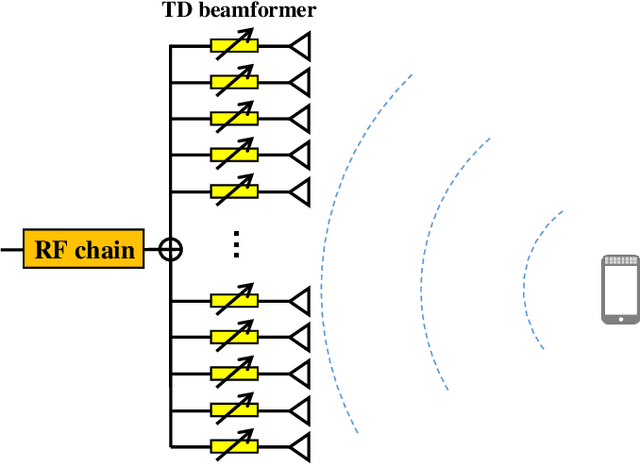
Wideband extremely large-scale multiple-input-multiple-output (XL-MIMO) is a promising technique to achieve Tbps data rates in future 6G systems through beamforming and spatial multiplexing. Due to the extensive bandwidth and the huge number of antennas for wideband XL-MIMO, a significant near-field beam split effect will be induced, where beams at different frequencies are focused on different locations. The near-field beam split effect results in a severe array gain loss, so existing works mainly focus on compensating for this loss by utilizing the time delay (TD) beamformer. By contrast, this paper demonstrates that although the near-field beam split effect degrades the array gain, it also provides a new possibility to realize fast near-field beam training. Specifically, we first reveal the mechanism of the near-field controllable beam split effect. This effect indicates that, by dedicatedly designing the delay parameters, a TD beamformer is able to control the degree of the near-field beam split effect, i.e., beams at different frequencies can flexibly occupy the desired location range. Due to the similarity with the dispersion of natural light caused by a prism, this effect is also termed as the near-field rainbow in this paper. Then, taking advantage of the near-field rainbow effect, a fast wideband beam training scheme is proposed. In our scheme, the close form of the beamforming vector is elaborately derived to enable beams at different frequencies to be focused on different desired locations. By this means, the optimal beamforming vector with the largest array gain can be rapidly searched out by generating multiple beams focused on multiple locations simultaneously through only one radio-frequency (RF) chain. Finally, simulation results demonstrate the proposed scheme is able to realize near-optimal nearfield beam training with a very low training overhead.