 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Surface Fitting to RGBD Sensor Data
Mar 11, 2021
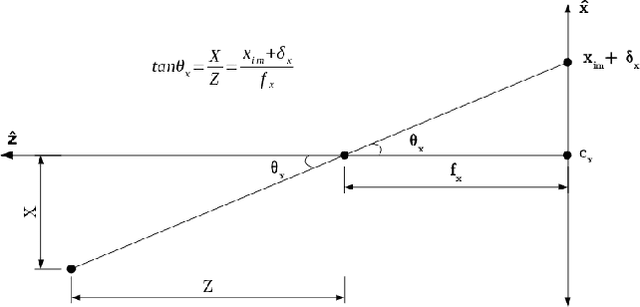
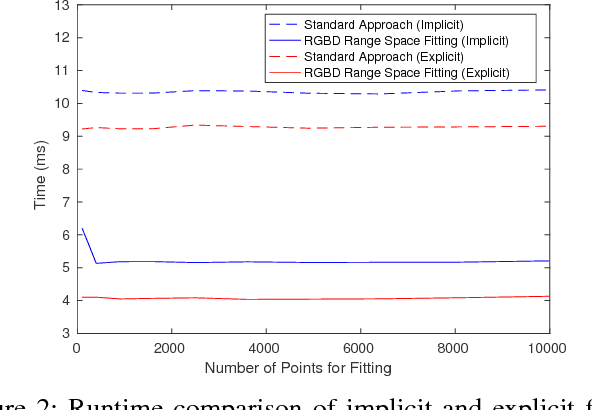
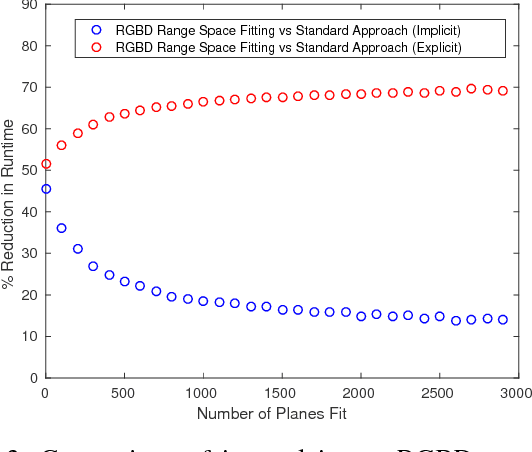

This article describes novel approaches to quickly estimate planar surfaces from RGBD sensor data. The approach manipulates the standard algebraic fitting equations into a form that allows many of the needed regression variables to be computed directly from the camera calibration information. As such, much of the computational burden required by a standard algebraic surface fit can be pre-computed. This provides a significant time and resource savings, especially when many surface fits are being performed which is often the case when RGBD point-cloud data is being analyzed for normal estimation, curvature estimation, polygonization or 3D segmentation applications. Using an integral image implementation, the proposed approaches show a significant increase in performance compared to the standard algebraic fitting approaches.
Analytically Integratable Zero-restlength Springs for Capturing Dynamic Modes unrepresented by Quasistatic Neural Networks
Jan 25, 2022
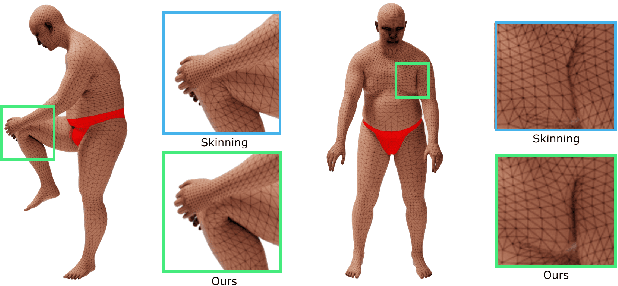
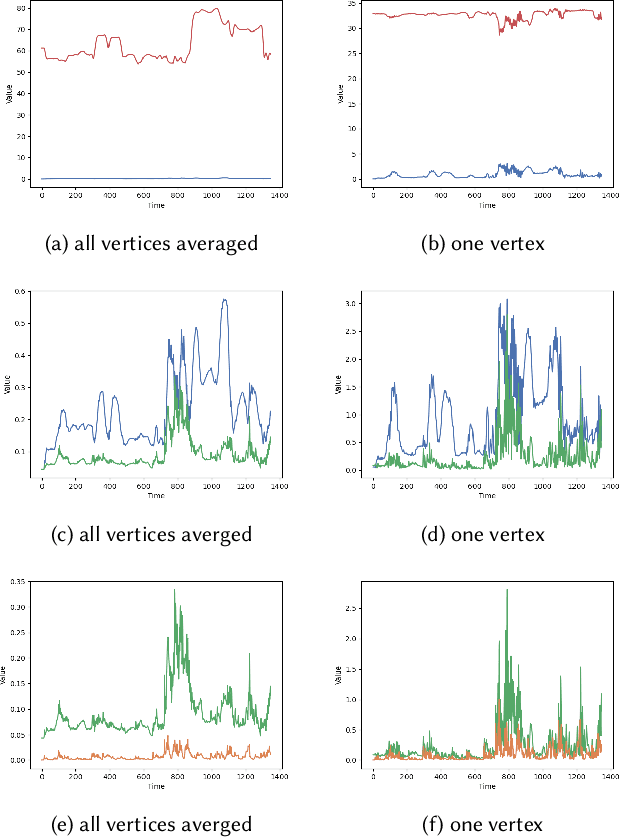
We present a novel paradigm for modeling certain types of dynamic simulation in real-time with the aid of neural networks. In order to significantly reduce the requirements on data (especially time-dependent data), as well as decrease generalization error, our approach utilizes a data-driven neural network only to capture quasistatic information (instead of dynamic or time-dependent information). Subsequently, we augment our quasistatic neural network (QNN) inference with a (real-time) dynamic simulation layer. Our key insight is that the dynamic modes lost when using a QNN approximation can be captured with a quite simple (and decoupled) zero-restlength spring model, which can be integrated analytically (as opposed to numerically) and thus has no time-step stability restrictions. Additionally, we demonstrate that the spring constitutive parameters can be robustly learned from a surprisingly small amount of dynamic simulation data. Although we illustrate the efficacy of our approach by considering soft-tissue dynamics on animated human bodies, the paradigm is extensible to many different simulation frameworks.
TemporalWiki: A Lifelong Benchmark for Training and Evaluating Ever-Evolving Language Models
Apr 29, 2022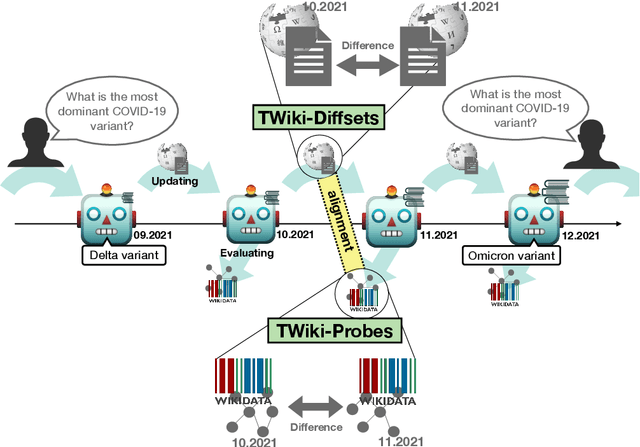
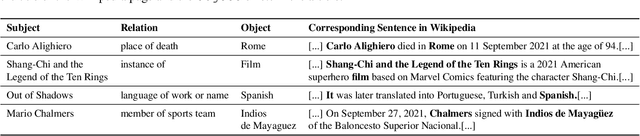

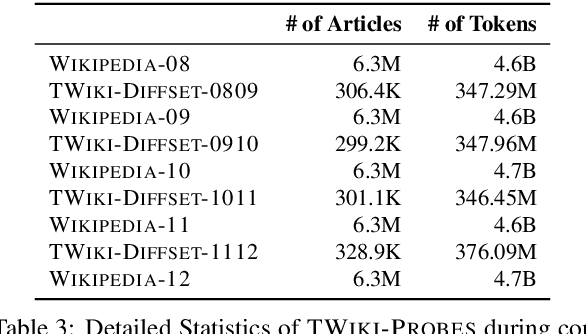
Language Models (LMs) become outdated as the world changes; they often fail to perform tasks requiring recent factual information which was absent or different during training, a phenomenon called temporal misalignment. This is especially a challenging problem because the research community still lacks a coherent dataset for assessing the adaptability of LMs to frequently-updated knowledge corpus such as Wikipedia. To this end, we introduce TemporalWiki, a lifelong benchmark for ever-evolving LMs that utilizes the difference between consecutive snapshots of English Wikipedia and English Wikidata for training and evaluation, respectively. The benchmark hence allows researchers to periodically track an LM's ability to retain previous knowledge and acquire updated/new knowledge at each point in time. We also find that training an LM on the diff data through continual learning methods achieves similar or better perplexity than on the entire snapshot in our benchmark with 12 times less computational cost, which verifies that factual knowledge in LMs can be safely updated with minimal training data via continual learning. The dataset and the code are available at https://github.com/joeljang/temporalwiki .
DUAL: Discrete Spoken Unit Adaptive Learning for Textless Spoken Question Answering
Mar 26, 2022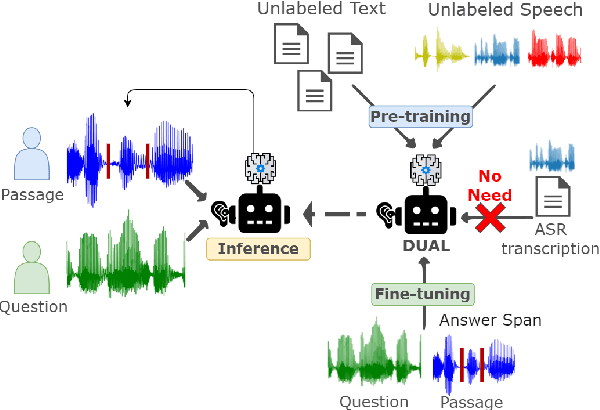
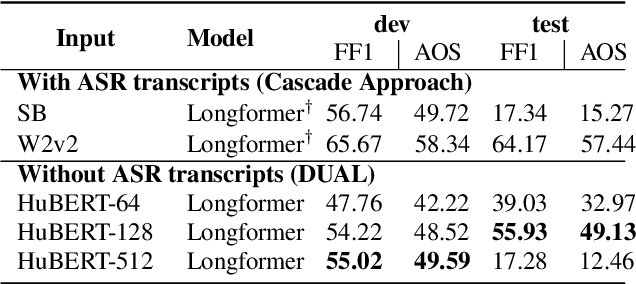
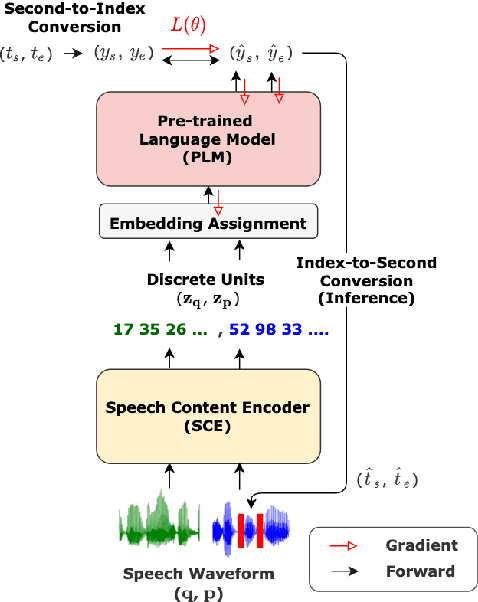
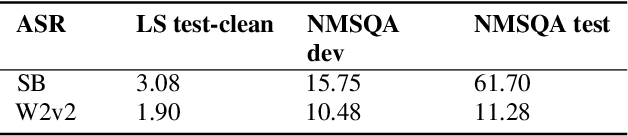
Spoken Question Answering (SQA) is to find the answer from a spoken document given a question, which is crucial for personal assistants when replying to the queries from the users. Existing SQA methods all rely on Automatic Speech Recognition (ASR) transcripts. Not only does ASR need to be trained with massive annotated data that are time and cost-prohibitive to collect for low-resourced languages, but more importantly, very often the answers to the questions include name entities or out-of-vocabulary words that cannot be recognized correctly. Also, ASR aims to minimize recognition errors equally over all words, including many function words irrelevant to the SQA task. Therefore, SQA without ASR transcripts (textless) is always highly desired, although known to be very difficult. This work proposes Discrete Spoken Unit Adaptive Learning (DUAL), leveraging unlabeled data for pre-training and fine-tuned by the SQA downstream task. The time intervals of spoken answers can be directly predicted from spoken documents. We also release a new SQA benchmark corpus, NMSQA, for data with more realistic scenarios. We empirically showed that DUAL yields results comparable to those obtained by cascading ASR and text QA model and robust to real-world data. Our code and model will be open-sourced.
CORPS: Cost-free Rigorous Pseudo-labeling based on Similarity-ranking for Brain MRI Segmentation
May 19, 2022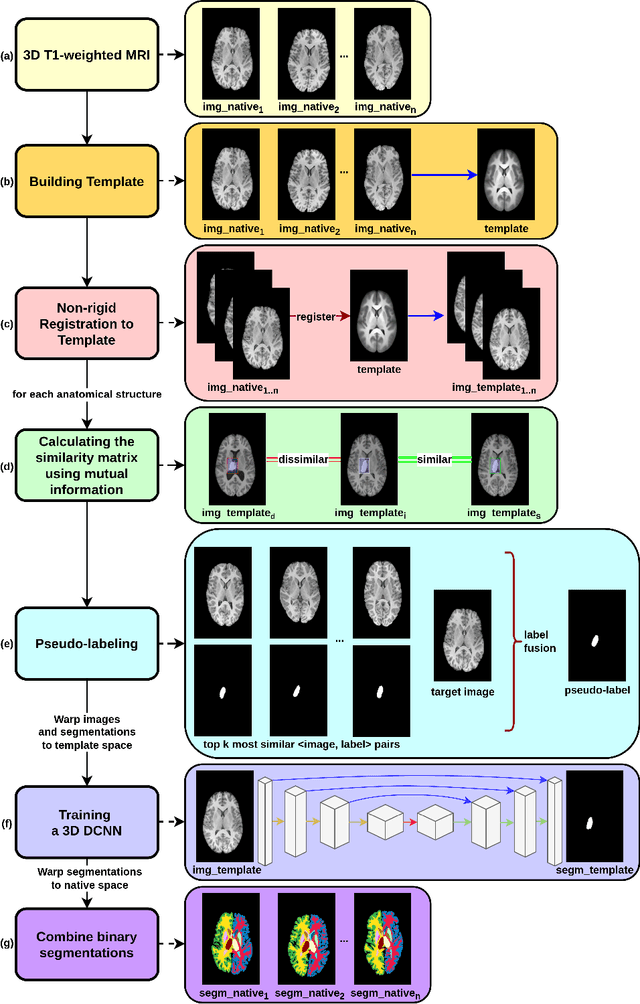

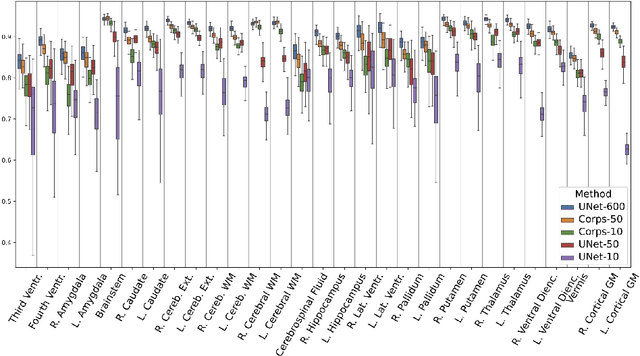
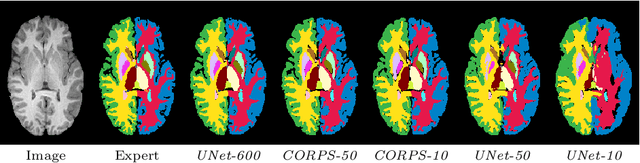
Segmentation of brain magnetic resonance images (MRI) is crucial for the analysis of the human brain and diagnosis of various brain disorders. The drawbacks of time-consuming and error-prone manual delineation procedures are aimed to be alleviated by atlas-based and supervised machine learning methods where the former methods are computationally intense and the latter methods lack a sufficiently large number of labeled data. With this motivation, we propose CORPS, a semi-supervised segmentation framework built upon a novel atlas-based pseudo-labeling method and a 3D deep convolutional neural network (DCNN) for 3D brain MRI segmentation. In this work, we propose to generate expert-level pseudo-labels for unlabeled set of images in an order based on a local intensity-based similarity score to existing labeled set of images and using a novel atlas-based label fusion method. Then, we propose to train a 3D DCNN on the combination of expert and pseudo labeled images for binary segmentation of each anatomical structure. The binary segmentation approach is proposed to avoid the poor performance of multi-class segmentation methods on limited and imbalanced data. This also allows to employ a lightweight and efficient 3D DCNN in terms of the number of filters and reserve memory resources for training the binary networks on full-scale and full-resolution 3D MRI volumes instead of 2D/3D patches or 2D slices. Thus, the proposed framework can encapsulate the spatial contiguity in each dimension and enhance context-awareness. The experimental results demonstrate the superiority of the proposed framework over the baseline method both qualitatively and quantitatively without additional labeling cost for manual labeling.
Industry-academia research collaboration and knowledge co-creation: Patterns and anti-patterns
Apr 29, 2022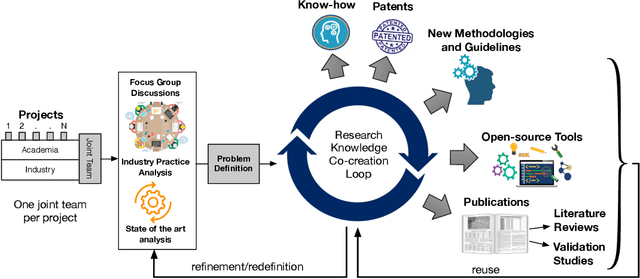

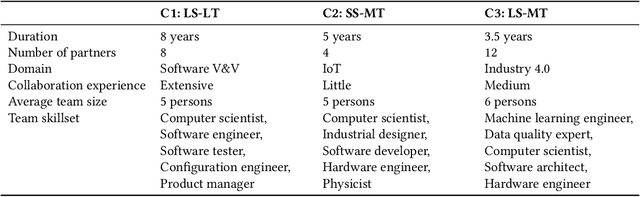
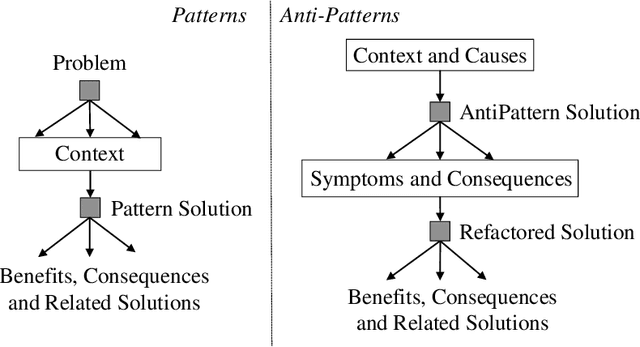
Increasing the impact of software engineering research in the software industry and the society at large has long been a concern of high priority for the software engineering community. The problem of two cultures, research conducted in a vacuum (disconnected from the real world), or misaligned time horizons are just some of the many complex challenges standing in the way of successful industry-academia collaborations. This paper reports on the experience of research collaboration and knowledge co-creation between industry and academia in software engineering as a way to bridge the research-practice collaboration gap. Our experience spans 14 years of collaboration between researchers in software engineering and the European and Norwegian software and IT industry. Using the participant observation and interview methods we have collected and afterwards analyzed an extensive record of qualitative data. Drawing upon the findings made and the experience gained, we provide a set of 14 patterns and 14 anti-patterns for industry-academia collaborations, aimed to support other researchers and practitioners in establishing and running research collaboration projects in software engineering.
Monitoring and mapping of crop fields with UAV swarms based on information gain
Mar 22, 2022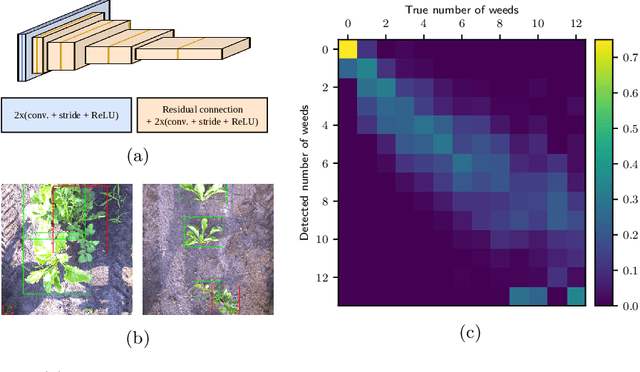
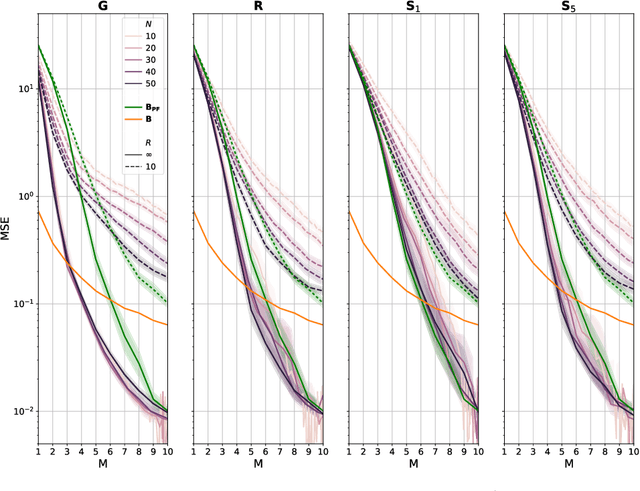
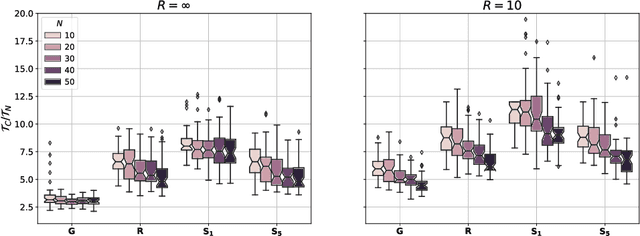
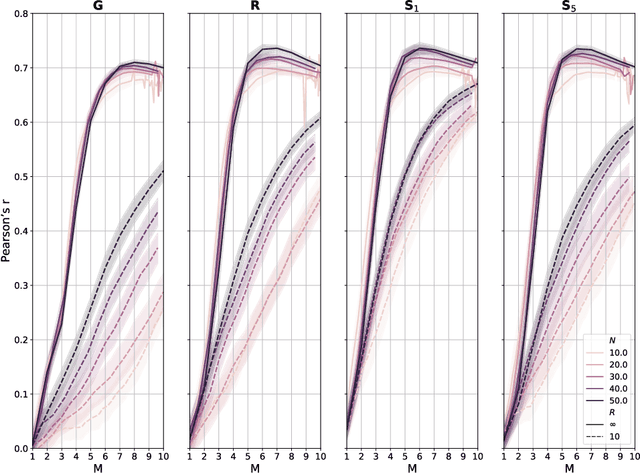
Monitoring crop fields to map features like weeds can be efficiently performed with unmanned aerial vehicles (UAVs) that can cover large areas in a short time due to their privileged perspective and motion speed. However, the need for high-resolution images for precise classification of features (e.g., detecting even the smallest weeds in the field) contrasts with the limited payload and ight time of current UAVs. Thus, it requires several flights to cover a large field uniformly. However, the assumption that the whole field must be observed with the same precision is unnecessary when features are heterogeneously distributed, like weeds appearing in patches over the field. In this case, an adaptive approach that focuses only on relevant areas can perform better, especially when multiple UAVs are employed simultaneously. Leveraging on a swarm-robotics approach, we propose a monitoring and mapping strategy that adaptively chooses the target areas based on the expected information gain, which measures the potential for uncertainty reduction due to further observations. The proposed strategy scales well with group size and leads to smaller mapping errors than optimal pre-planned monitoring approaches.
A Prospective Approach for Human-to-Human Interaction Recognition from Wi-Fi Channel Data using Attention Bidirectional Gated Recurrent Neural Network with GUI Application Implementation
Mar 12, 2022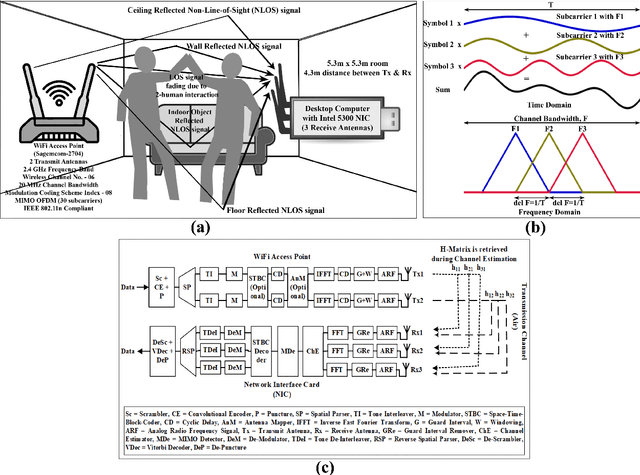
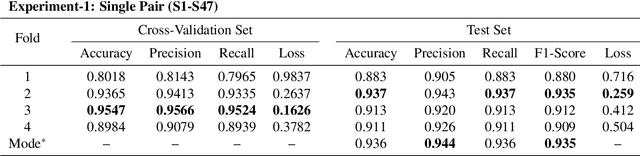
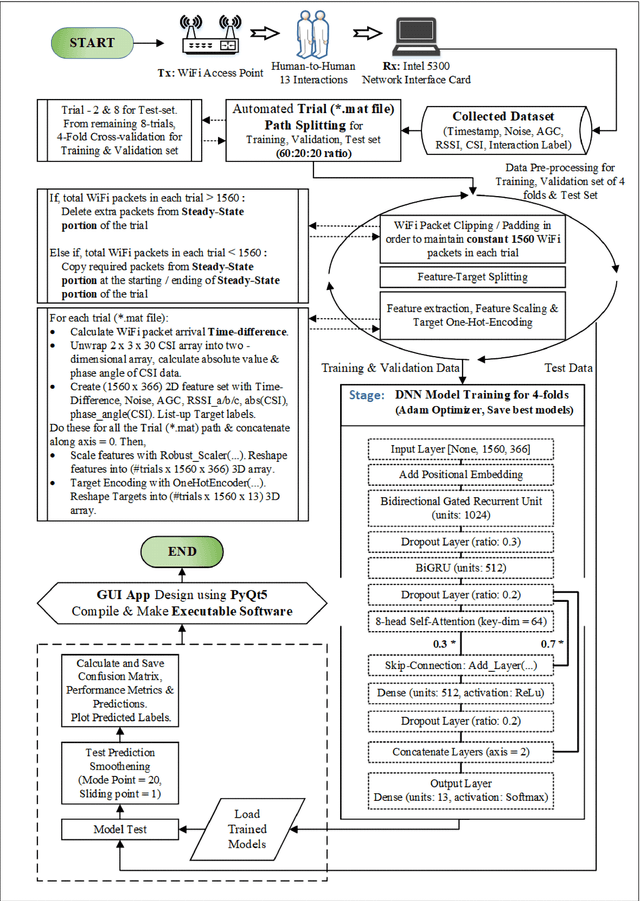
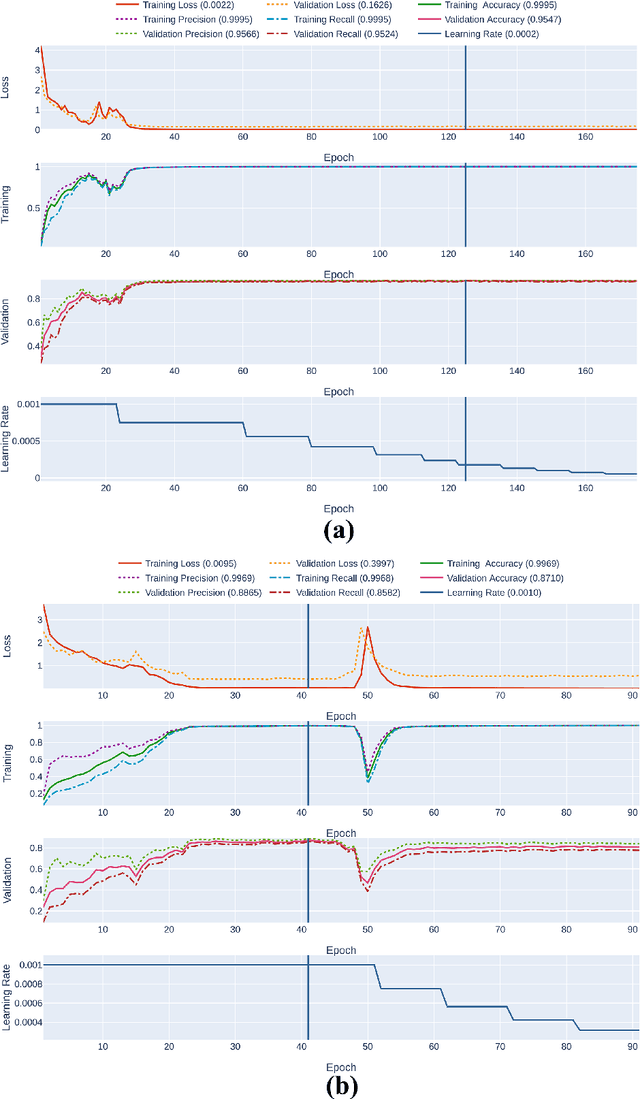
Recent advances in 5G wireless technology and socioeconomic transformation have brought a paradigm shift in sensor applications. Wi-Fi signal demonstrates a strong correlation between its temporal variation and body movements, which can be leveraged to recognize human activity. In this article, we demonstrate the cognitive ability of device free mutual human-to-human interaction recognition method based on the time scale Wi-Fi channel state information. The mutual activities examined are steady-state, approaching, departing, handshaking, high-five, hugging, kicking (left-leg), kicking (right-leg), pointing (left-hand), pointing (right-hand), punching(left-hand), punching (right-hand), and pushing. We explore and propose a Self-Attention furnished Bidirectional Gated Recurrent Neural Network model to classify the 13 interaction types from the time-series data through automated temporal feature extraction. Our proposed model can recognize a two subject pair mutual interaction with a maximum benchmark accuracy of 94%. This has been expanded for ten subject pairs, which secured a benchmark accuracy of 88% with improved classification around the interaction-transition region. Also, an executable graphical user interface (GUI) is developed, using the PyQt5 python module, to subsequently display the overall mutual human-interaction recognition procedure in real-time. Finally, we conclude with a brief discourse regarding the possible solutions to the handicaps that resulted in curtailments observed during the study. Such, Wi-Fi channel perturbation pattern analysis is believed to be an efficient, economical & privacy-friendly approach to be potentially utilized in mutual human-interaction recognition for indoor activity monitoring, surveillance system, smart health monitoring systems & independent assisted living.
Simpler is Better: off-the-shelf Continual Learning Through Pretrained Backbones
May 03, 2022

In this short paper, we propose a baseline (off-the-shelf) for Continual Learning of Computer Vision problems, by leveraging the power of pretrained models. By doing so, we devise a simple approach achieving strong performance for most of the common benchmarks. Our approach is fast since requires no parameters updates and has minimal memory requirements (order of KBytes). In particular, the "training" phase reorders data and exploit the power of pretrained models to compute a class prototype and fill a memory bank. At inference time we match the closest prototype through a knn-like approach, providing us the prediction. We will see how this naive solution can act as an off-the-shelf continual learning system. In order to better consolidate our results, we compare the devised pipeline with common CNN models and show the superiority of Vision Transformers, suggesting that such architectures have the ability to produce features of higher quality. Moreover, this simple pipeline, raises the same questions raised by previous works \cite{gdumb} on the effective progresses made by the CL community especially in the dataset considered and the usage of pretrained models. Code is live at https://github.com/francesco-p/off-the-shelf-cl
Energy-Efficient Classification at the Wireless Edge with Reliability Guarantees
Apr 25, 2022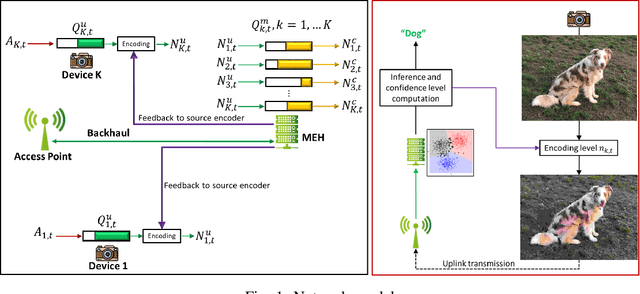
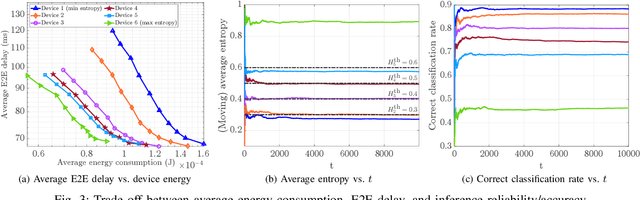
Learning at the edge is a challenging task from several perspectives, since data must be collected by end devices (e.g. sensors), possibly pre-processed (e.g. data compression), and finally processed remotely to output the result of training and/or inference phases. This involves heterogeneous resources, such as radio, computing and learning related parameters. In this context, we propose an algorithm that dynamically selects data encoding scheme, local computing resources, uplink radio parameters, and remote computing resources, to perform a classification task with the minimum average end devices' energy consumption, under E2E delay and inference reliability constraints. Our method does not assume any prior knowledge of the statistics of time varying context parameters, while it only requires the solution of low complexity per-slot deterministic optimization problems, based on instantaneous observations of these parameters and that of properly defined state variables. Numerical results on convolutional neural network based image classification illustrate the effectiveness of our method in striking the best trade-off between energy, delay and inference reliability.