 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TLSAN: Time-aware Long- and Short-term Attention Network for Next-item Recommendation
Mar 16, 2021
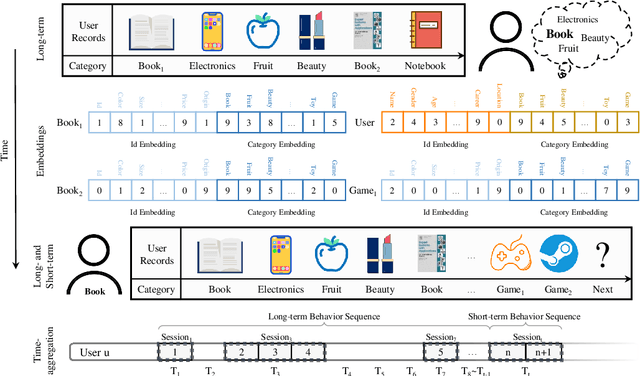

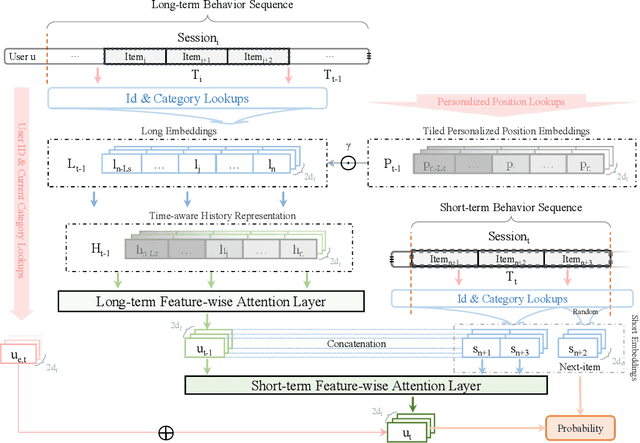
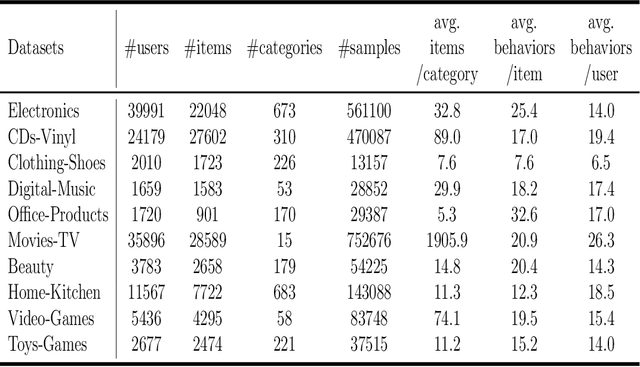
Recently, deep neural networks are widely applied in recommender systems for their effectiveness in capturing/modeling users' preferences. Especially, the attention mechanism in deep learning enables recommender systems to incorporate various features in an adaptive way. Specifically, as for the next item recommendation task, we have the following three observations: 1) users' sequential behavior records aggregate at time positions ("time-aggregation"), 2) users have personalized taste that is related to the "time-aggregation" phenomenon ("personalized time-aggregation"), and 3) users' short-term interests play an important role in the next item prediction/recommendation. In this paper, we propose a new Time-aware Long- and Short-term Attention Network (TLSAN) to address those observations mentioned above. Specifically, TLSAN consists of two main components. Firstly, TLSAN models "personalized time-aggregation" and learn user-specific temporal taste via trainable personalized time position embeddings with category-aware correlations in long-term behaviors. Secondly, long- and short-term feature-wise attention layers are proposed to effectively capture users' long- and short-term preferences for accurate recommendation. Especially, the attention mechanism enables TLSAN to utilize users' preferences in an adaptive way, and its usage in long- and short-term layers enhances TLSAN's ability of dealing with sparse interaction data. Extensive experiments are conducted on Amazon datasets from different fields (also with different size), and the results show that TLSAN outperforms state-of-the-art baselines in both capturing users' preferences and performing time-sensitive next-item recommendation.
i-GSI: A Fast and Reliable Grasp-type Switching Interface based on Augmented Reality and Eye-tracking
Apr 22, 2022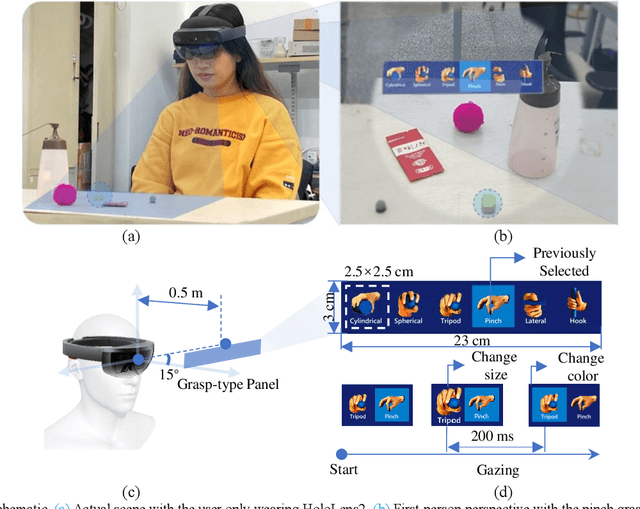
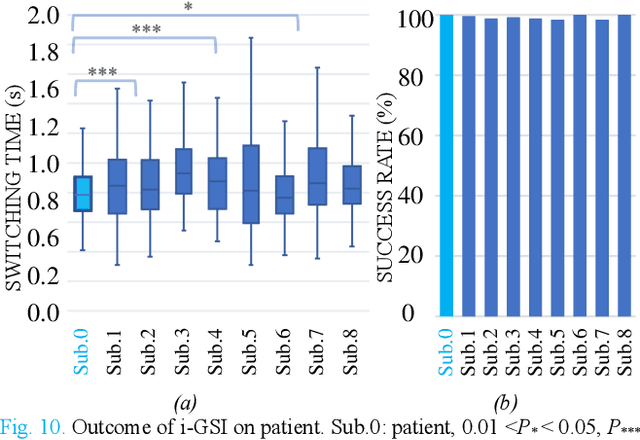
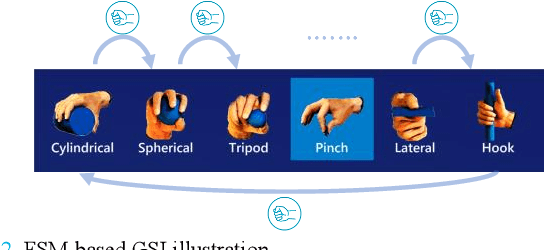
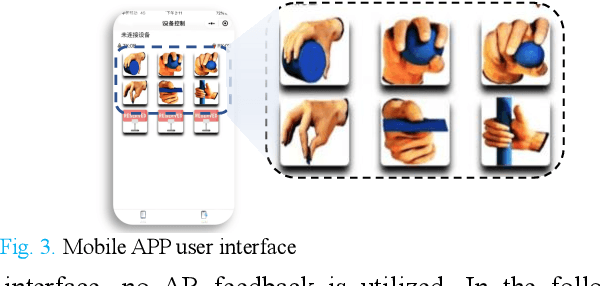
The control of multi-fingered dexterous prosthetics hand remains challenging due to the lack of an intuitive and efficient Grasp-type Switching Interface (GSI). We propose a new GSI (i-GSI) t hat integrates the manifold power of eye-tracking and augmentced reality technologies to solve this problem. It runs entirely in a HoloLens2 helmet, where users can glance at icons on the holographic interface to switch between six daily grasp types quickly. Compared to traditional GSIs (FSM-based, PR-based, and mobile APP-based), i-GSI achieved the best results in the experiment with eight healthy subjects, achieving a switching time of 0.84 s, a switching success rate of 99.0%, and learning efficiency of 93.50%. By verifying on one patient with a congenital upper limb deficiency, i-GSI achieved an equivalent great outcome as on healthy people, with a switching time of 0.78 s and switching success rate of 100%. The new i-GSI, as a standalone module, can be combined with traditional proportional myoelectric control to form a hybrid-controlled prosthetic system that can help patients accomplish dexterous operations in various daily-life activities.
Sub-Word Alignment Is Still Useful: A Vest-Pocket Method for Enhancing Low-Resource Machine Translation
May 09, 2022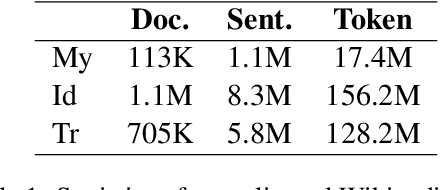
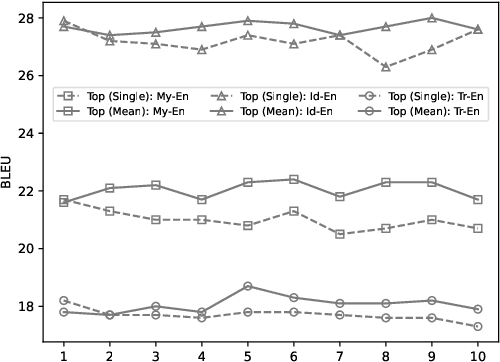
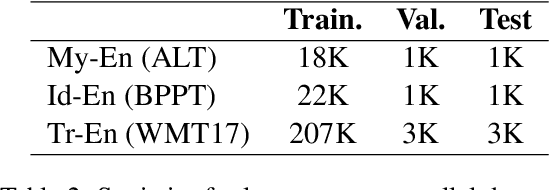
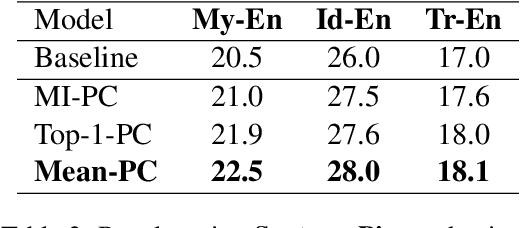
We leverage embedding duplication between aligned sub-words to extend the Parent-Child transfer learning method, so as to improve low-resource machine translation. We conduct experiments on benchmark datasets of My-En, Id-En and Tr-En translation scenarios. The test results show that our method produces substantial improvements, achieving the BLEU scores of 22.5, 28.0 and 18.1 respectively. In addition, the method is computationally efficient which reduces the consumption of training time by 63.8%, reaching the duration of 1.6 hours when training on a Tesla 16GB P100 GPU. All the models and source codes in the experiments will be made publicly available to support reproducible research.
NanoNet: Real-Time Polyp Segmentation in Video Capsule Endoscopy and Colonoscopy
Apr 22, 2021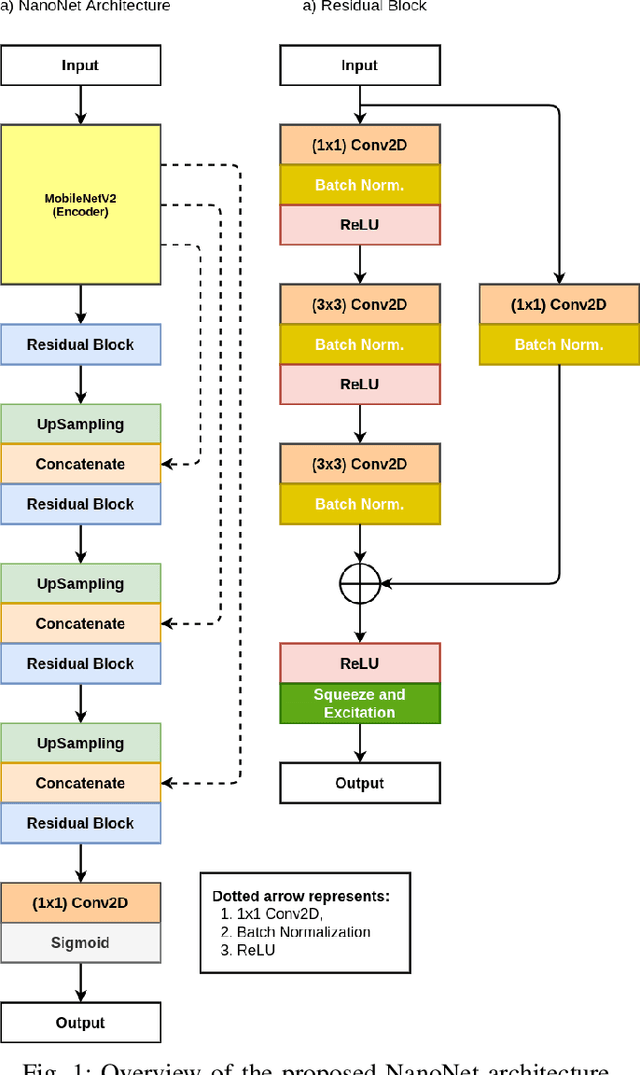
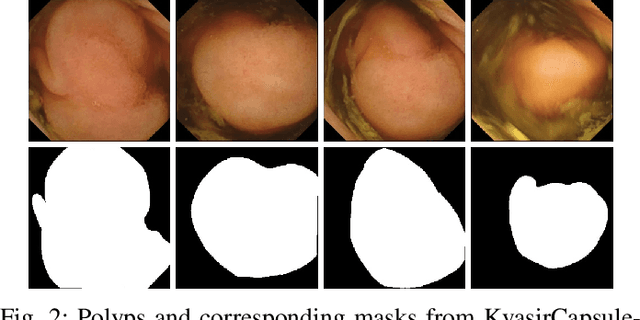
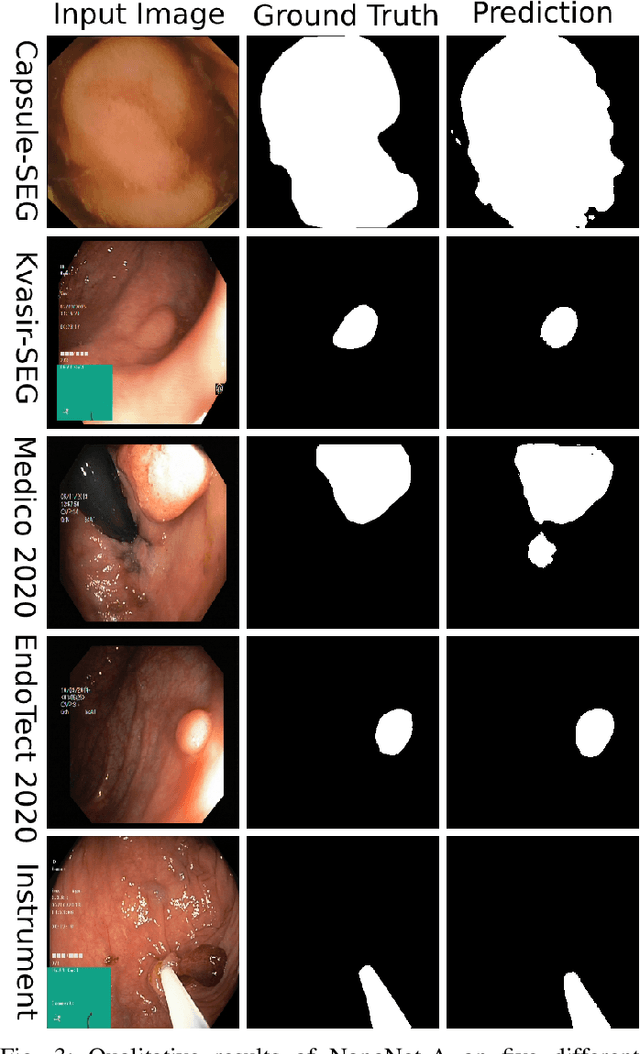

Deep learning in gastrointestinal endoscopy can assist to improve clinical performance and be helpful to assess lesions more accurately. To this extent, semantic segmentation methods that can perform automated real-time delineation of a region-of-interest, e.g., boundary identification of cancer or precancerous lesions, can benefit both diagnosis and interventions. However, accurate and real-time segmentation of endoscopic images is extremely challenging due to its high operator dependence and high-definition image quality. To utilize automated methods in clinical settings, it is crucial to design lightweight models with low latency such that they can be integrated with low-end endoscope hardware devices. In this work, we propose NanoNet, a novel architecture for the segmentation of video capsule endoscopy and colonoscopy images. Our proposed architecture allows real-time performance and has higher segmentation accuracy compared to other more complex ones. We use video capsule endoscopy and standard colonoscopy datasets with polyps, and a dataset consisting of endoscopy biopsies and surgical instruments, to evaluate the effectiveness of our approach. Our experiments demonstrate the increased performance of our architecture in terms of a trade-off between model complexity, speed, model parameters, and metric performances. Moreover, the resulting model size is relatively tiny, with only nearly 36,000 parameters compared to traditional deep learning approaches having millions of parameters.
Physics-Inspired Temporal Learning of Quadrotor Dynamics for Accurate Model Predictive Trajectory Tracking
Jun 07, 2022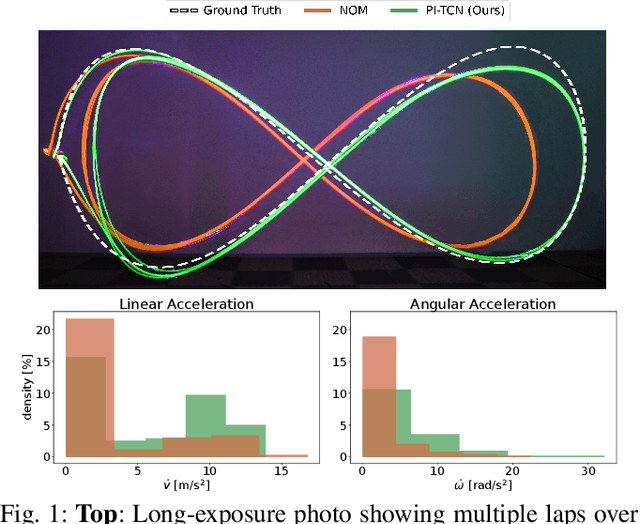
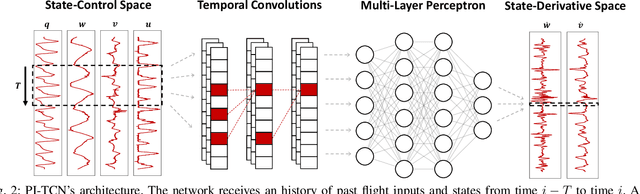
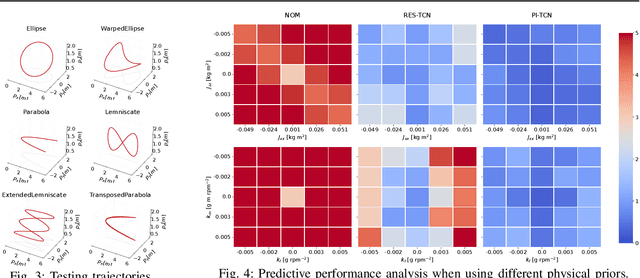
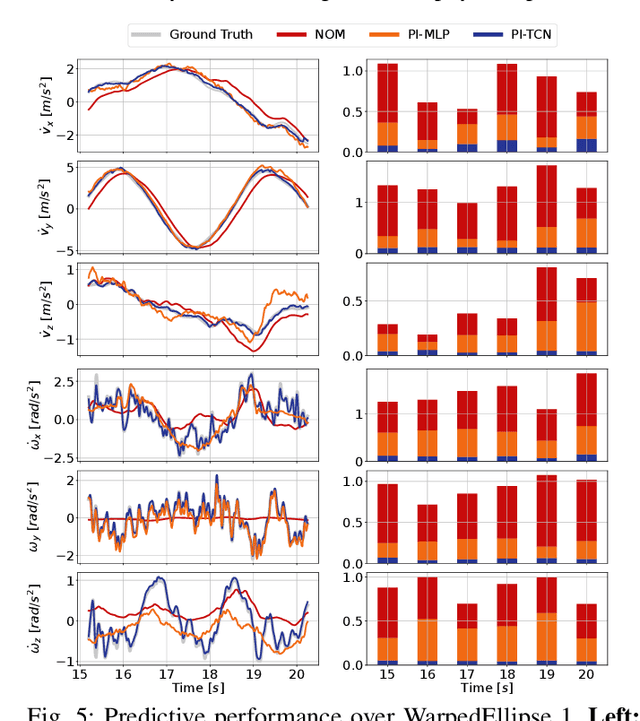
Accurately modeling quadrotor's system dynamics is critical for guaranteeing agile, safe, and stable navigation. The model needs to capture the system behavior in multiple flight regimes and operating conditions, including those producing highly nonlinear effects such as aerodynamic forces and torques, rotor interactions, or possible system configuration modifications. Classical approaches rely on handcrafted models and struggle to generalize and scale to capture these effects. In this paper, we present a novel Physics-Inspired Temporal Convolutional Network (PI-TCN) approach to learning quadrotor's system dynamics purely from robot experience. Our approach combines the expressive power of sparse temporal convolutions and dense feed-forward connections to make accurate system predictions. In addition, physics constraints are embedded in the training process to facilitate the network's generalization capabilities to data outside the training distribution. Finally, we design a model predictive control approach that incorporates the learned dynamics for accurate closed-loop trajectory tracking fully exploiting the learned model predictions in a receding horizon fashion. Experimental results demonstrate that our approach accurately extracts the structure of the quadrotor's dynamics from data, capturing effects that would remain hidden to classical approaches. To the best of our knowledge, this is the first time physics-inspired deep learning is successfully applied to temporal convolutional networks and to the system identification task, while concurrently enabling predictive control.
On the Effectiveness of Fine-tuning Versus Meta-reinforcement Learning
Jun 07, 2022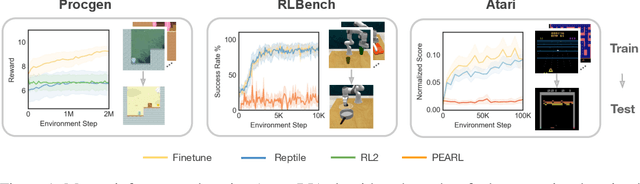
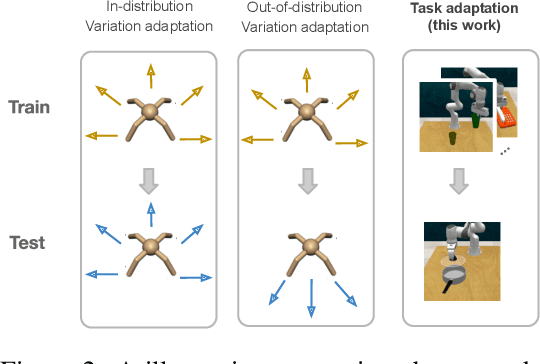
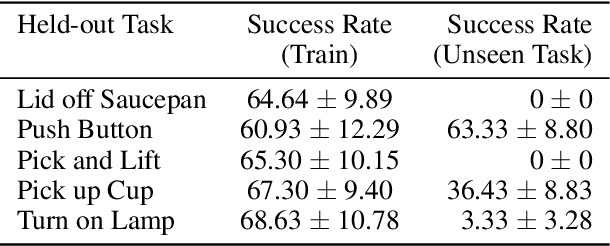
Intelligent agents should have the ability to leverage knowledge from previously learned tasks in order to learn new ones quickly and efficiently. Meta-learning approaches have emerged as a popular solution to achieve this. However, meta-reinforcement learning (meta-RL) algorithms have thus far been restricted to simple environments with narrow task distributions. Moreover, the paradigm of pretraining followed by fine-tuning to adapt to new tasks has emerged as a simple yet effective solution in supervised and self-supervised learning. This calls into question the benefits of meta-learning approaches also in reinforcement learning, which typically come at the cost of high complexity. We hence investigate meta-RL approaches in a variety of vision-based benchmarks, including Procgen, RLBench, and Atari, where evaluations are made on completely novel tasks. Our findings show that when meta-learning approaches are evaluated on different tasks (rather than different variations of the same task), multi-task pretraining with fine-tuning on new tasks performs equally as well, or better, than meta-pretraining with meta test-time adaptation. This is encouraging for future research, as multi-task pretraining tends to be simpler and computationally cheaper than meta-RL. From these findings, we advocate for evaluating future meta-RL methods on more challenging tasks and including multi-task pretraining with fine-tuning as a simple, yet strong baseline.
On the Relevance of Bandwidth Extension for Speaker Verification
Apr 05, 2022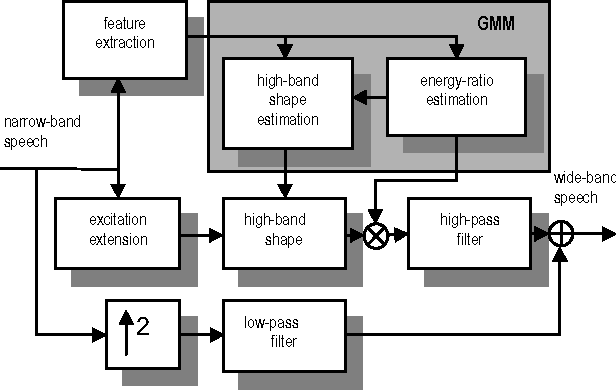

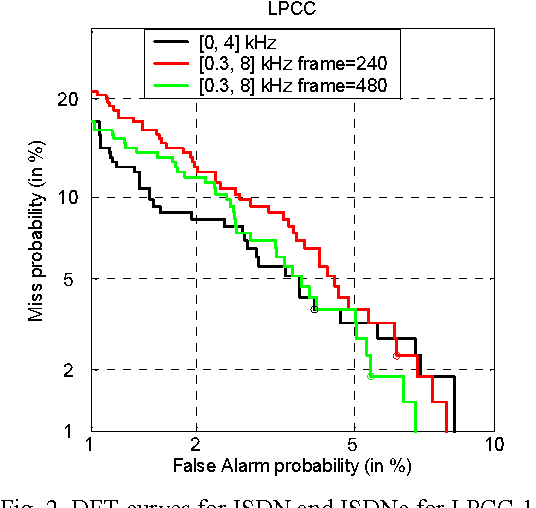
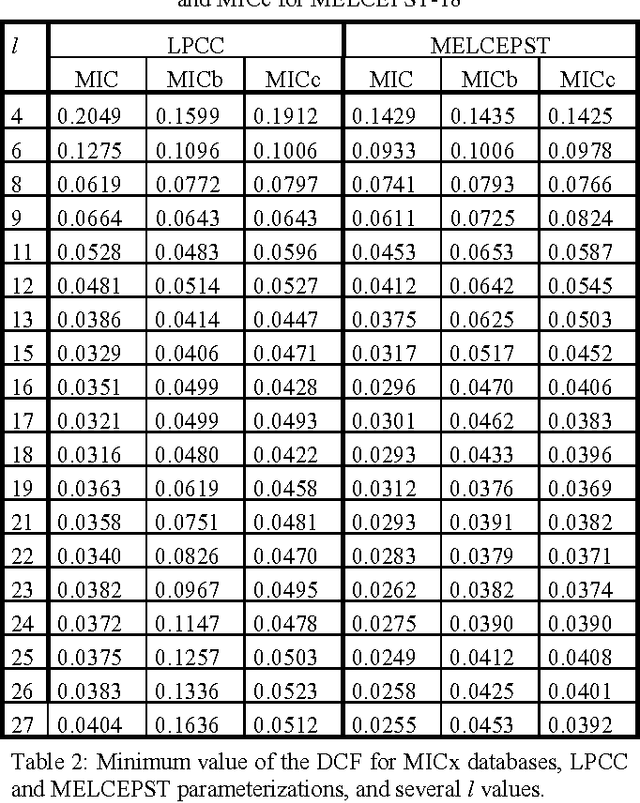
In this paper, we consider the effect of a bandwidth extension of narrow-band speech signals (0.3-3.4 kHz) to 0.3-8 kHz on speaker verification. Using covariance matrix based verification systems together with detection error trade-off curves, we compare the performance between systems operating on narrow-band, wide-band (0-8 kHz), and bandwidth-extended speech. The experiments were conducted using different short-time spectral parameterizations derived from microphone and ISDN speech databases. The studied bandwidth-extension algorithm did not introduce artifacts that affected the speaker verification task, and we achieved improvements between 1 and 10 percent (depending on the model order) over the verification system designed for narrow-band speech when mel-frequency cepstral coefficients for the short-time spectral parameterization were used.
* 4 pages published in 7th International Conference on Spoken Language Processing, September 16-20, 2002, Denver, Colorado, USA. arXiv admin note: text overlap with arXiv:2202.13865
A Class of Low-complexity DCT-like Transforms for Image and Video Coding
May 31, 2022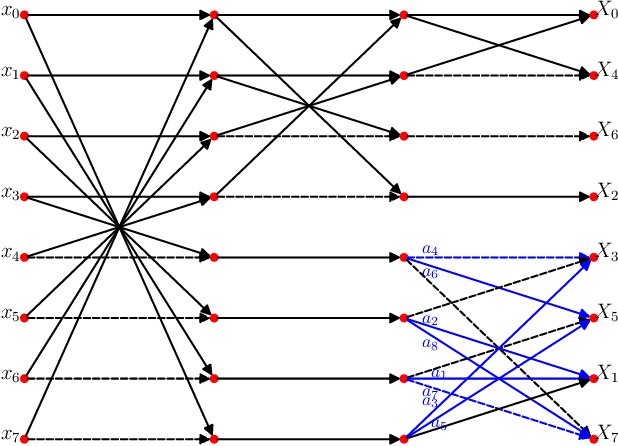
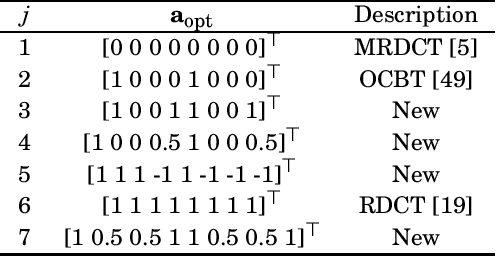
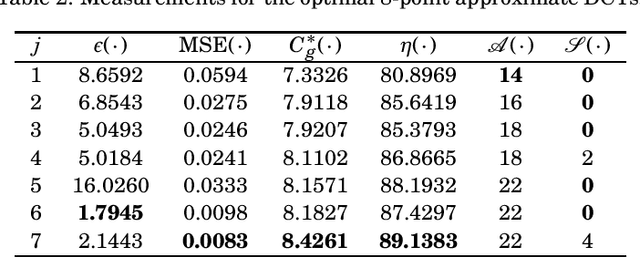
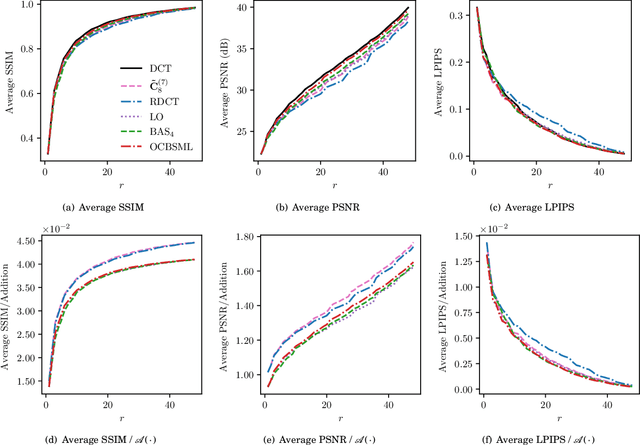
The discrete cosine transform (DCT) is a relevant tool in signal processing applications, mainly known for its good decorrelation properties. Current image and video coding standards -- such as JPEG and HEVC -- adopt the DCT as a fundamental building block for compression. Recent works have introduced low-complexity approximations for the DCT, which become paramount in applications demanding real-time computation and low-power consumption. The design of DCT approximations involves a trade-off between computational complexity and performance. This paper introduces a new multiparametric transform class encompassing the round-off DCT (RDCT) and the modified RDCT (MRDCT), two relevant multiplierless 8-point approximate DCTs. The associated fast algorithm is provided. Four novel orthogonal low-complexity 8-point DCT approximations are obtained by solving a multicriteria optimization problem. The optimal 8-point transforms are scaled to lengths 16 and 32 while keeping the arithmetic complexity low. The proposed methods are assessed by proximity and coding measures with respect to the exact DCT. Image and video coding experiments hardware realization are performed. The novel transforms perform close to or outperform the current state-of-the-art DCT approximations.
Robust Molecular Image Recognition: A Graph Generation Approach
May 28, 2022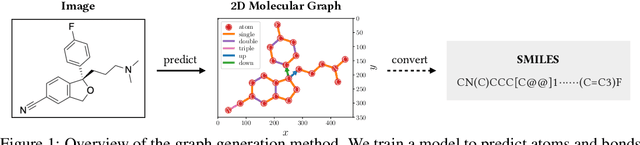
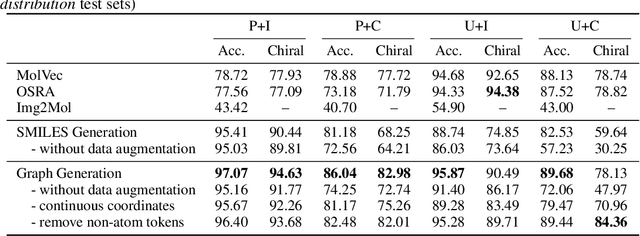
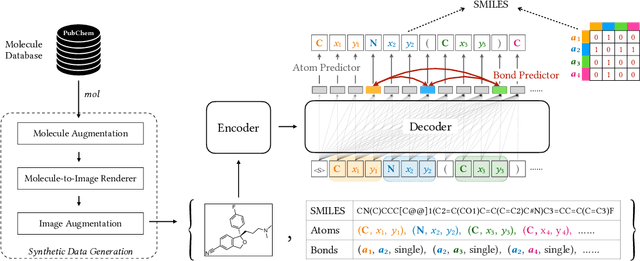
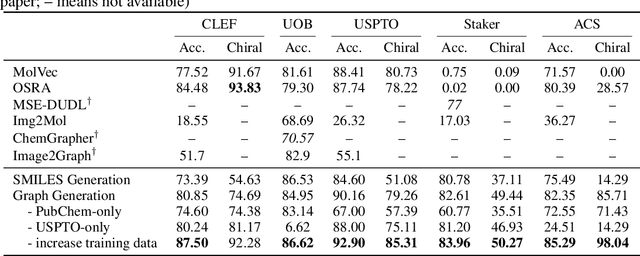
Molecular image recognition is a fundamental task in information extraction from chemistry literature. Previous data-driven models formulate it as an image-to-sequence task, to generate a sequential representation of the molecule (e.g. SMILES string) from its graphical representation. Although they perform adequately on certain benchmarks, these models are not robust in real-world situations, where molecular images differ in style, quality, and chemical patterns. In this paper, we propose a novel graph generation approach that explicitly predicts atoms and bonds, along with their geometric layouts, to construct the molecular graph. We develop data augmentation strategies for molecules and images to increase the robustness of our model against domain shifts. Our model is flexible to incorporate chemistry constraints, and produces more interpretable predictions than SMILES. In experiments on both synthetic and realistic molecular images, our model significantly outperforms previous models, achieving 84-93% accuracy on five benchmarks. We also conduct human evaluation and show that our model reduces the time for a chemist to extract molecular structures from images by roughly 50%.
Numerical and geometrical aspects of flow-based variational quantum Monte Carlo
Mar 28, 2022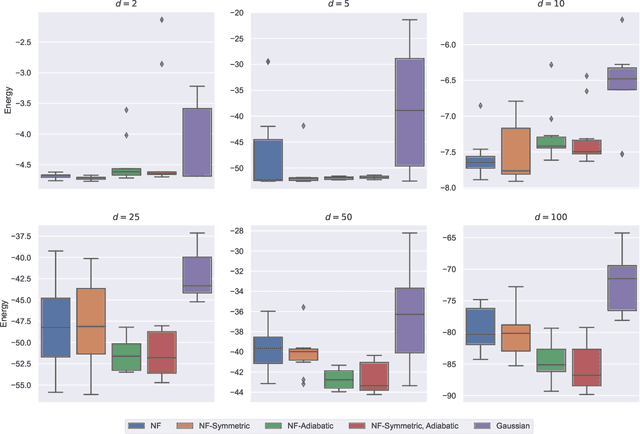
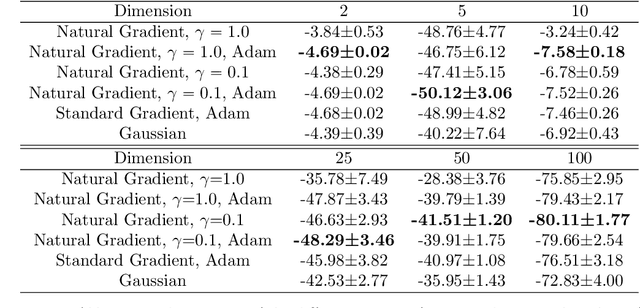
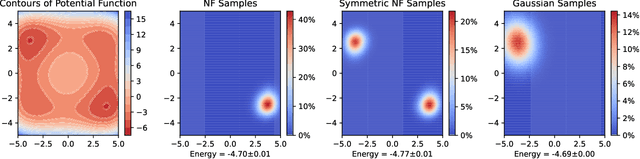
This article aims to summarize recent and ongoing efforts to simulate continuous-variable quantum systems using flow-based variational quantum Monte Carlo techniques, focusing for pedagogical purposes on the example of bosons in the field amplitude (quadrature) basis. Particular emphasis is placed on the variational real- and imaginary-time evolution problems, carefully reviewing the stochastic estimation of the time-dependent variational principles and their relationship with information geometry. Some practical instructions are provided to guide the implementation of a PyTorch code. The review is intended to be accessible to researchers interested in machine learning and quantum information science.