 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Three Applications of Conformal Prediction for Rating Breast Density in Mammography
Jun 23, 2022
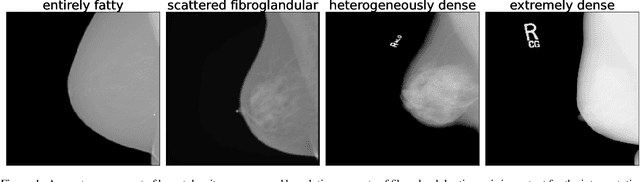

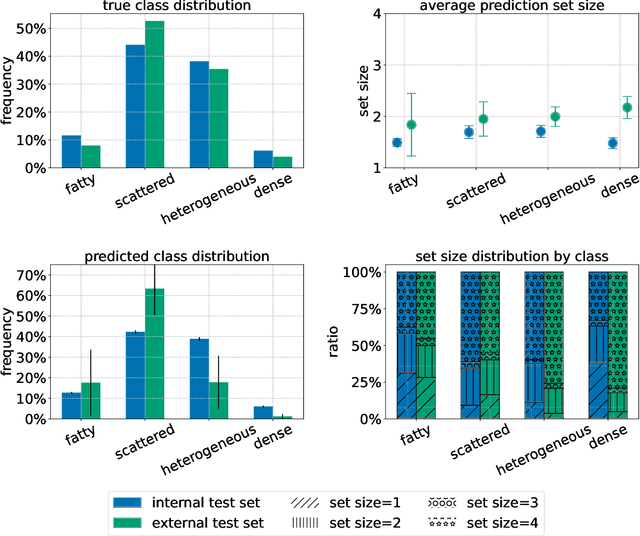
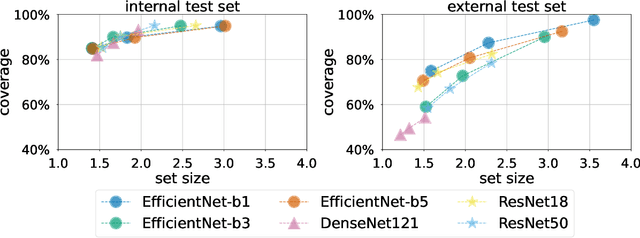
Breast cancer is the most common cancers and early detection from mammography screening is crucial in improving patient outcomes. Assessing mammographic breast density is clinically important as the denser breasts have higher risk and are more likely to occlude tumors. Manual assessment by experts is both time-consuming and subject to inter-rater variability. As such, there has been increased interest in the development of deep learning methods for mammographic breast density assessment. Despite deep learning having demonstrated impressive performance in several prediction tasks for applications in mammography, clinical deployment of deep learning systems in still relatively rare; historically, mammography Computer-Aided Diagnoses (CAD) have over-promised and failed to deliver. This is in part due to the inability to intuitively quantify uncertainty of the algorithm for the clinician, which would greatly enhance usability. Conformal prediction is well suited to increase reliably and trust in deep learning tools but they lack realistic evaluations on medical datasets. In this paper, we present a detailed analysis of three possible applications of conformal prediction applied to medical imaging tasks: distribution shift characterization, prediction quality improvement, and subgroup fairness analysis. Our results show the potential of distribution-free uncertainty quantification techniques to enhance trust on AI algorithms and expedite their translation to usage.
Computation Offloading and Resource Allocation in F-RANs: A Federated Deep Reinforcement Learning Approach
Jun 13, 2022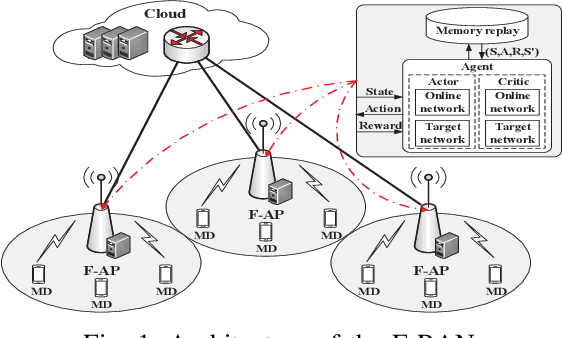
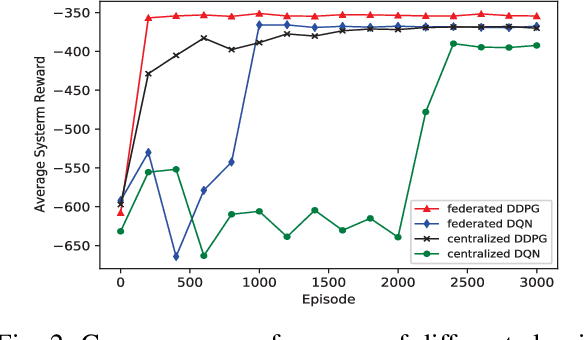
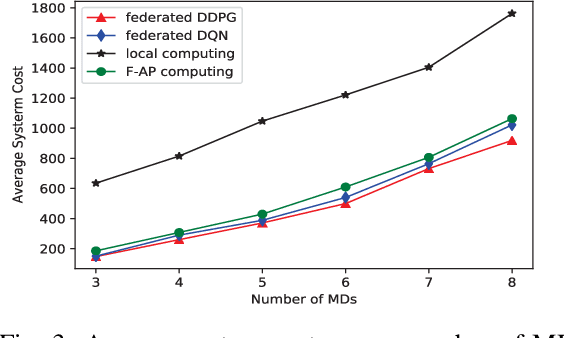
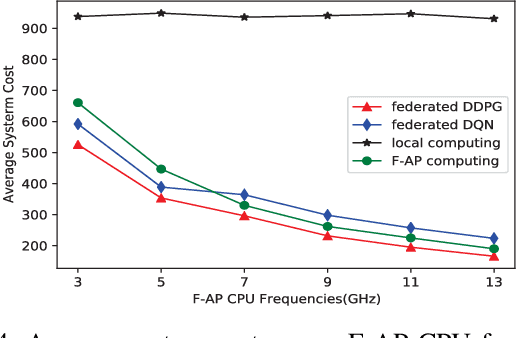
The fog radio access network (F-RAN) is a promising technology in which the user mobile devices (MDs) can offload computation tasks to the nearby fog access points (F-APs). Due to the limited resource of F-APs, it is important to design an efficient task offloading scheme. In this paper, by considering time-varying network environment, a dynamic computation offloading and resource allocation problem in F-RANs is formulated to minimize the task execution delay and energy consumption of MDs. To solve the problem, a federated deep reinforcement learning (DRL) based algorithm is proposed, where the deep deterministic policy gradient (DDPG) algorithm performs computation offloading and resource allocation in each F-AP. Federated learning is exploited to train the DDPG agents in order to decrease the computing complexity of training process and protect the user privacy. Simulation results show that the proposed federated DDPG algorithm can achieve lower task execution delay and energy consumption of MDs more quickly compared with the other existing strategies.
Formulating Robustness Against Unforeseen Attacks
Apr 28, 2022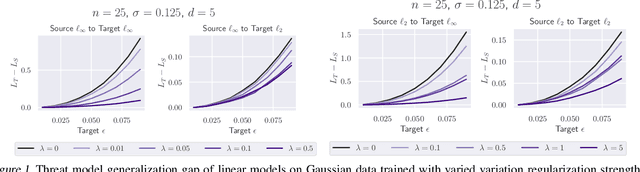
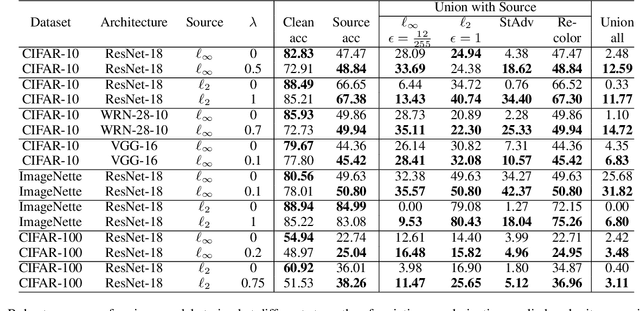
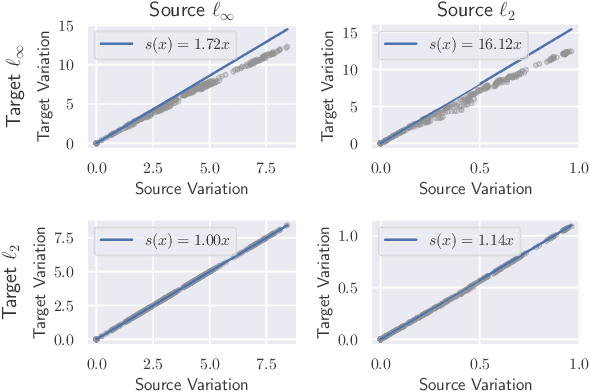
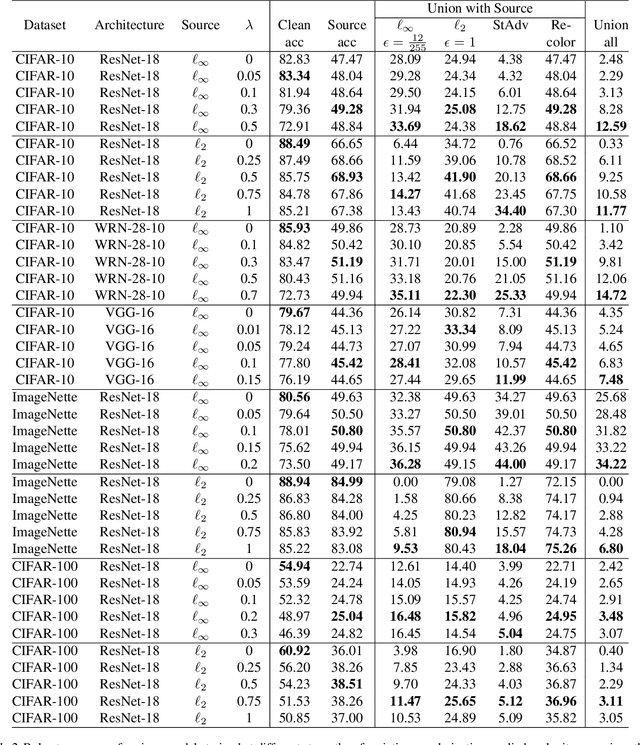
Existing defenses against adversarial examples such as adversarial training typically assume that the adversary will conform to a specific or known threat model, such as $\ell_p$ perturbations within a fixed budget. In this paper, we focus on the scenario where there is a mismatch in the threat model assumed by the defense during training, and the actual capabilities of the adversary at test time. We ask the question: if the learner trains against a specific "source" threat model, when can we expect robustness to generalize to a stronger unknown "target" threat model during test-time? Our key contribution is to formally define the problem of learning and generalization with an unforeseen adversary, which helps us reason about the increase in adversarial risk from the conventional perspective of a known adversary. Applying our framework, we derive a generalization bound which relates the generalization gap between source and target threat models to variation of the feature extractor, which measures the expected maximum difference between extracted features across a given threat model. Based on our generalization bound, we propose adversarial training with variation regularization (AT-VR) which reduces variation of the feature extractor across the source threat model during training. We empirically demonstrate that AT-VR can lead to improved generalization to unforeseen attacks during test-time compared to standard adversarial training on Gaussian and image datasets.
Controllable Image Enhancement
Jun 16, 2022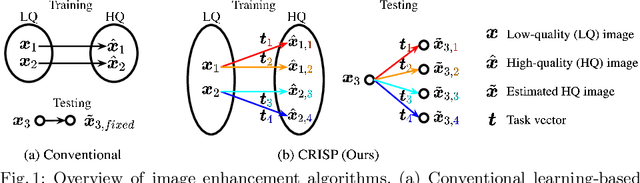
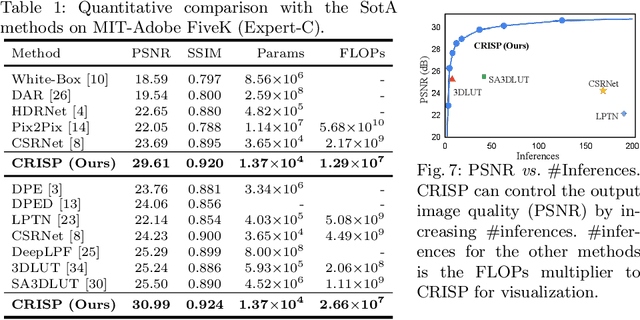
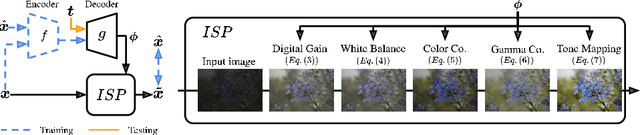

Editing flat-looking images into stunning photographs requires skill and time. Automated image enhancement algorithms have attracted increased interest by generating high-quality images without user interaction. However, the quality assessment of a photograph is subjective. Even in tone and color adjustments, a single photograph of auto-enhancement is challenging to fit user preferences which are subtle and even changeable. To address this problem, we present a semiautomatic image enhancement algorithm that can generate high-quality images with multiple styles by controlling a few parameters. We first disentangle photo retouching skills from high-quality images and build an efficient enhancement system for each skill. Specifically, an encoder-decoder framework encodes the retouching skills into latent codes and decodes them into the parameters of image signal processing (ISP) functions. The ISP functions are computationally efficient and consist of only 19 parameters. Despite our approach requiring multiple inferences to obtain the desired result, experimental results present that the proposed method achieves state-of-the-art performances on the benchmark dataset for image quality and model efficiency.
IRS Aided MEC Systems with Binary Offloading: A Unified Framework for Dynamic IRS Beamforming
May 29, 2022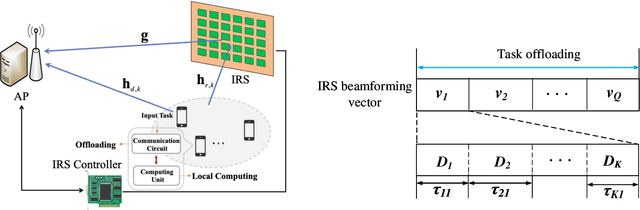
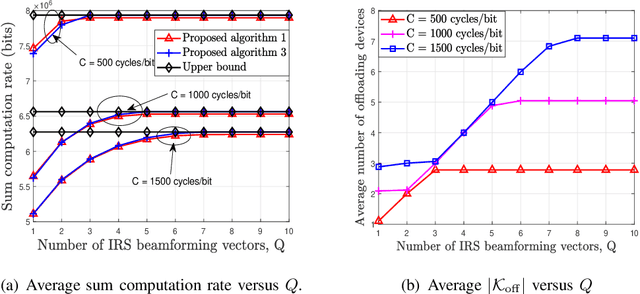
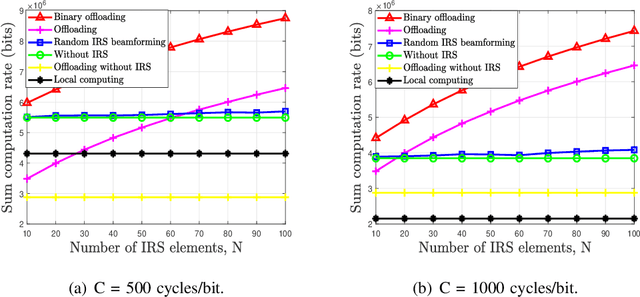
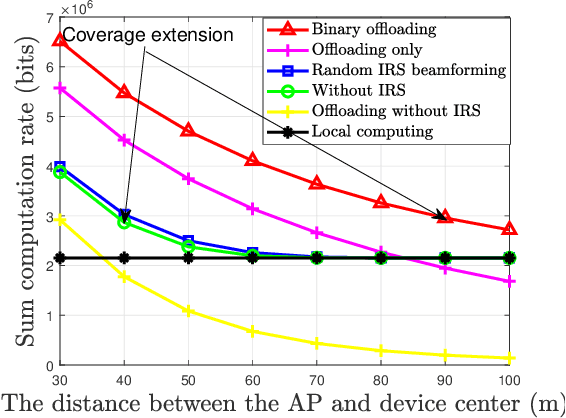
In this paper, we develop a unified dynamic intelligent reflecting surface (IRS) beamforming framework to boost the sum computation rate of an IRS-aided mobile edge computing (MEC) system, where each device follows a binary offloading policy. Specifically, the task of each device has to be either executed locally or offloaded to MEC servers as a whole with the aid of given number of IRS beamforming vectors available. By flexibly controlling the number of IRS reconfiguration times, the system can achieve a balance between the performance and associated signalling overhead. We aim to maximize the sum computation rate by jointly optimizing the computational mode selection for each device, offloading time allocation, and IRS beamforming vectors across time. Since the resulting optimization problem is non-convex and NP-hard, there are generally no standard methods to solve it optimally. To tackle this problem, we first propose a penalty-based successive convex approximation algorithm, where all the associated variables in the inner-layer iterations are optimized simultaneously and the obtained solution is guaranteed to be locally optimal. Then, we further derive the offloading activation condition for each device by deeply exploiting the intrinsic structure of the original optimization problem. According to the offloading activation condition, a low-complexity algorithm based on the successive refinement method is proposed to obtain high-quality solutions, which is more appealing for practical systems with a large number of devices and IRS elements. Moreover, the optimal condition for the proposed low-complexity algorithm is revealed. Numerical results demonstrate the effectiveness of our proposed algorithms and also unveil the fundamental performance-cost tradeoff of the proposed dynamic IRS beamforming framework.
Discriminating modelling approaches for Point in Time Economic Scenario Generation
Aug 19, 2021

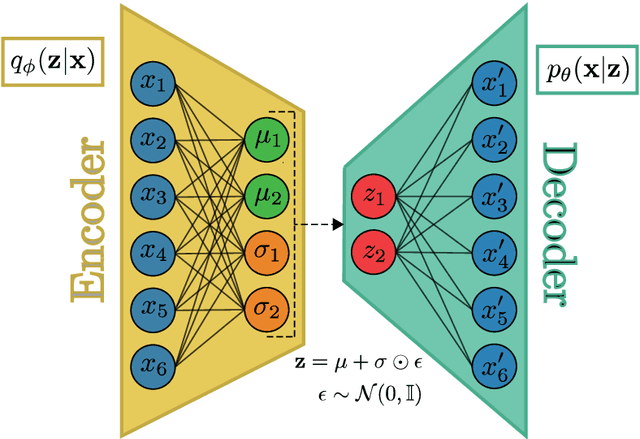
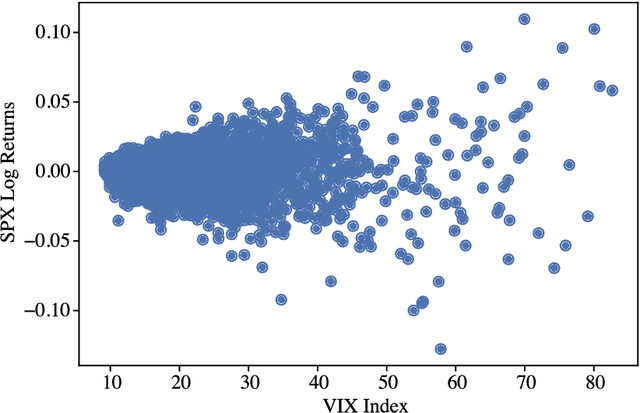
We introduce the notion of Point in Time Economic Scenario Generation (PiT ESG) with a clear mathematical problem formulation to unify and compare economic scenario generation approaches conditional on forward looking market data. Such PiT ESGs should provide quicker and more flexible reactions to sudden economic changes than traditional ESGs calibrated solely to long periods of historical data. We specifically take as economic variable the S&P500 Index with the VIX Index as forward looking market data to compare the nonparametric filtered historical simulation, GARCH model with joint likelihood estimation (parametric), Restricted Boltzmann Machine and the conditional Variational Autoencoder (Generative Networks) for their suitability as PiT ESG. Our evaluation consists of statistical tests for model fit and benchmarking the out of sample forecasting quality with a strategy backtest using model output as stop loss criterion. We find that both Generative Networks outperform the nonparametric and classic parametric model in our tests, but that the CVAE seems to be particularly well suited for our purposes: yielding more robust performance and being computationally lighter.
Dimensionality Reduced Training by Pruning and Freezing Parts of a Deep Neural Network, a Survey
May 17, 2022
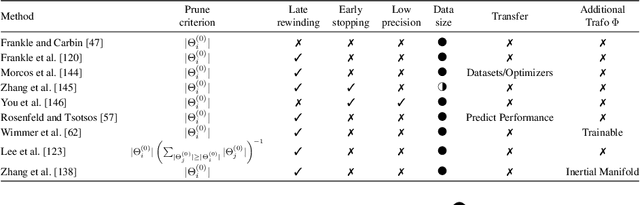
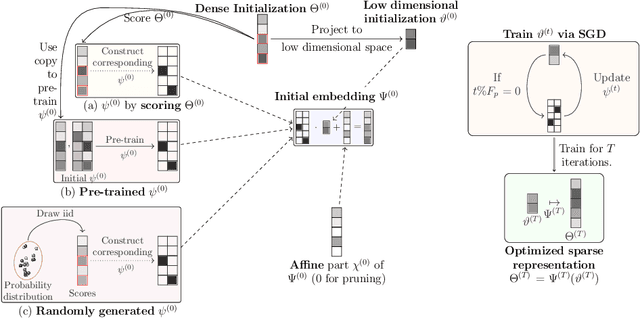
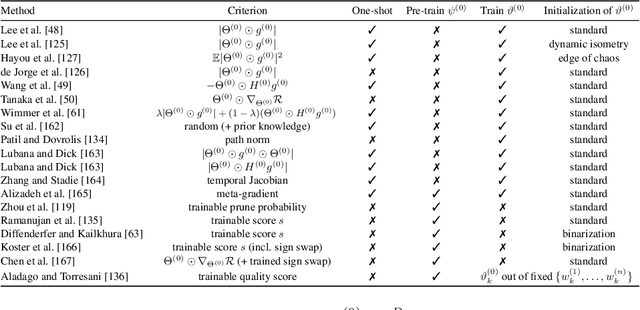
State-of-the-art deep learning models have a parameter count that reaches into the billions. Training, storing and transferring such models is energy and time consuming, thus costly. A big part of these costs is caused by training the network. Model compression lowers storage and transfer costs, and can further make training more efficient by decreasing the number of computations in the forward and/or backward pass. Thus, compressing networks also at training time while maintaining a high performance is an important research topic. This work is a survey on methods which reduce the number of trained weights in deep learning models throughout the training. Most of the introduced methods set network parameters to zero which is called pruning. The presented pruning approaches are categorized into pruning at initialization, lottery tickets and dynamic sparse training. Moreover, we discuss methods that freeze parts of a network at its random initialization. By freezing weights, the number of trainable parameters is shrunken which reduces gradient computations and the dimensionality of the model's optimization space. In this survey we first propose dimensionality reduced training as an underlying mathematical model that covers pruning and freezing during training. Afterwards, we present and discuss different dimensionality reduced training methods.
A New Weakly Supervised Learning Approach for Real-time Iron Ore Feed Load Estimation
Oct 06, 2021

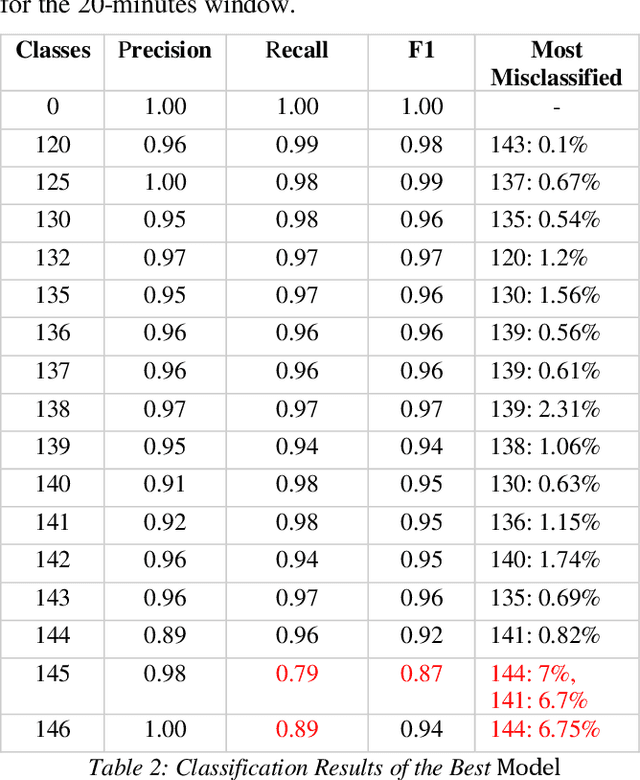
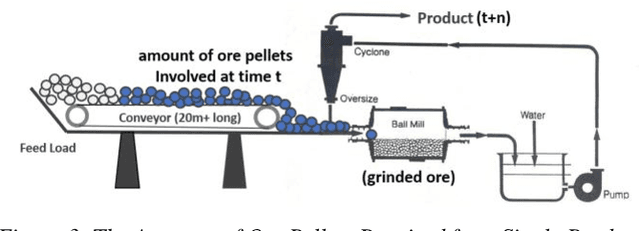
Iron ore feed load control is one of the most critical settings in a mineral grinding process, directly impacting the quality of final products. The setting of the feed load is mainly determined by the characteristics of the ore pellets. However, the characterisation of ore is challenging to acquire in many production environments, leading to poor feed load settings and inefficient production processes. This paper presents our work using deep learning models for direct ore feed load estimation from ore pellet images. To address the challenges caused by the large size of a full ore pellets image and the shortage of accurately annotated data, we treat the whole modelling process as a weakly supervised learning problem. A two-stage model training algorithm and two neural network architectures are proposed. The experiment results show competitive model performance, and the trained models can be used for real-time feed load estimation for grind process optimisation.
EventNeRF: Neural Radiance Fields from a Single Colour Event Camera
Jun 23, 2022
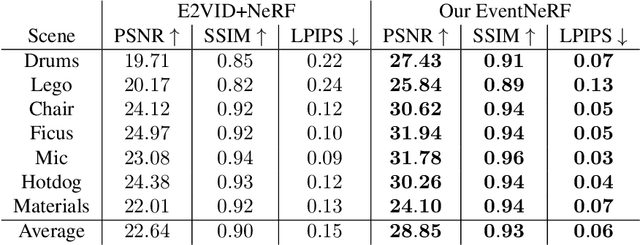

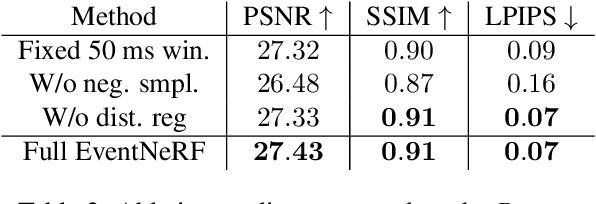
Learning coordinate-based volumetric 3D scene representations such as neural radiance fields (NeRF) has been so far studied assuming RGB or RGB-D images as inputs. At the same time, it is known from the neuroscience literature that human visual system (HVS) is tailored to process asynchronous brightness changes rather than synchronous RGB images, in order to build and continuously update mental 3D representations of the surroundings for navigation and survival. Visual sensors that were inspired by HVS principles are event cameras. Thus, events are sparse and asynchronous per-pixel brightness (or colour channel) change signals. In contrast to existing works on neural 3D scene representation learning, this paper approaches the problem from a new perspective. We demonstrate that it is possible to learn NeRF suitable for novel-view synthesis in the RGB space from asynchronous event streams. Our models achieve high visual accuracy of the rendered novel views of challenging scenes in the RGB space, even though they are trained with substantially fewer data (i.e., event streams from a single event camera moving around the object) and more efficiently (due to the inherent sparsity of event streams) than the existing NeRF models trained with RGB images. We will release our datasets and the source code, see https://4dqv.mpi-inf.mpg.de/EventNeRF/.
Enhancing a Student Productivity Model for Adaptive Problem-Solving Assistance
Jul 07, 2022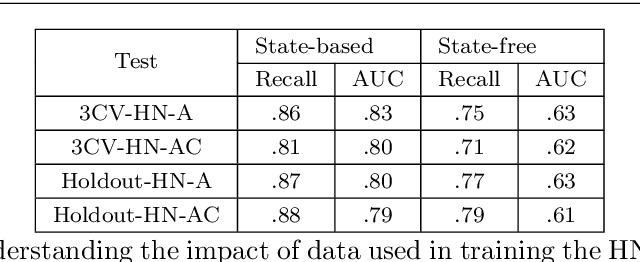
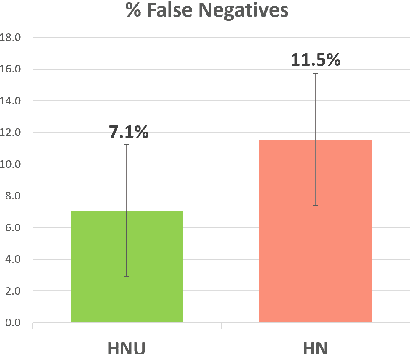
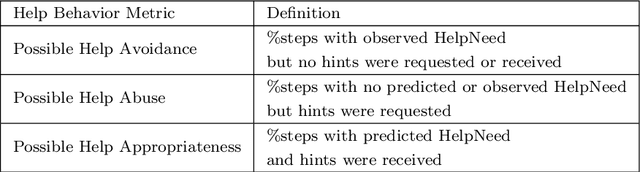
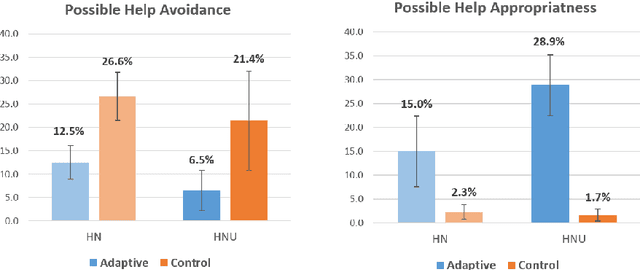
Research on intelligent tutoring systems has been exploring data-driven methods to deliver effective adaptive assistance. While much work has been done to provide adaptive assistance when students seek help, they may not seek help optimally. This had led to the growing interest in proactive adaptive assistance, where the tutor provides unsolicited assistance upon predictions of struggle or unproductivity. Determining when and whether to provide personalized support is a well-known challenge called the assistance dilemma. Addressing this dilemma is particularly challenging in open-ended domains, where there can be several ways to solve problems. Researchers have explored methods to determine when to proactively help students, but few of these methods have taken prior hint usage into account. In this paper, we present a novel data-driven approach to incorporate students' hint usage in predicting their need for help. We explore its impact in an intelligent tutor that deals with the open-ended and well-structured domain of logic proofs. We present a controlled study to investigate the impact of an adaptive hint policy based on predictions of HelpNeed that incorporate students' hint usage. We show empirical evidence to support that such a policy can save students a significant amount of time in training, and lead to improved posttest results, when compared to a control without proactive interventions. We also show that incorporating students' hint usage significantly improves the adaptive hint policy's efficacy in predicting students' HelpNeed, thereby reducing training unproductivity, reducing possible help avoidance, and increasing possible help appropriateness (a higher chance of receiving help when it was likely to be needed). We conclude with suggestions on the domains that can benefit from this approach as well as the requirements for adoption.