 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Recent Trends and Future Prospects of Neural Recording Circuits and Systems: A Tutorial Brief
May 27, 2022
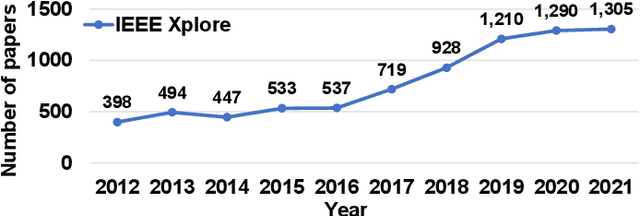
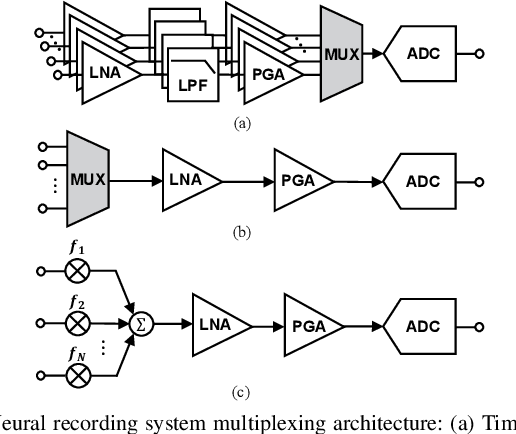
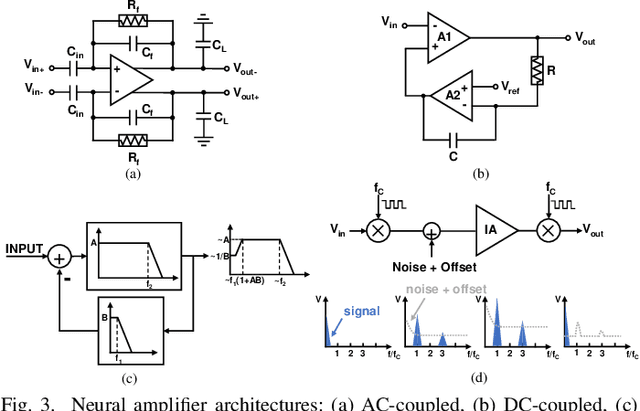
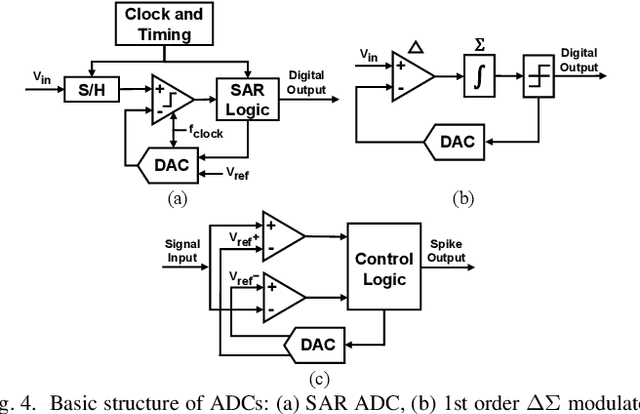
Recent years have seen fast advances in neural recording circuits and systems as they offer a promising way to investigate real-time brain monitoring and the closed-loop modulation of psychological disorders and neurodegenerative diseases. In this context, this tutorial brief presents a concise overview of concepts and design methodologies of neural recording, highlighting neural signal characteristics, system-level specifications and architectures, circuit-level implementation, and noise reduction techniques. Future trends and challenges of neural recording are finally discussed.
Automatic Prosody Annotation with Pre-Trained Text-Speech Model
Jun 16, 2022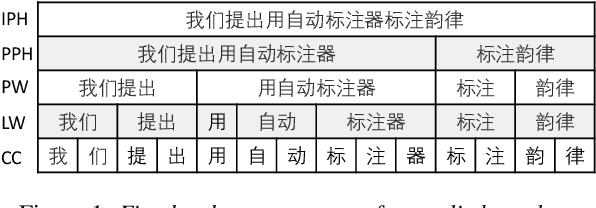
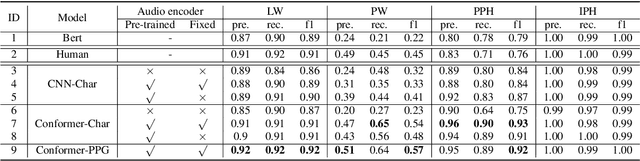
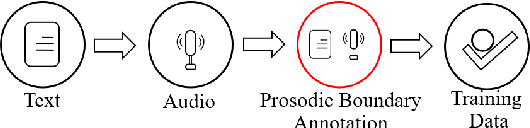

Prosodic boundary plays an important role in text-to-speech synthesis (TTS) in terms of naturalness and readability. However, the acquisition of prosodic boundary labels relies on manual annotation, which is costly and time-consuming. In this paper, we propose to automatically extract prosodic boundary labels from text-audio data via a neural text-speech model with pre-trained audio encoders. This model is pre-trained on text and speech data separately and jointly fine-tuned on TTS data in a triplet format: {speech, text, prosody}. The experimental results on both automatic evaluation and human evaluation demonstrate that: 1) the proposed text-speech prosody annotation framework significantly outperforms text-only baselines; 2) the quality of automatic prosodic boundary annotations is comparable to human annotations; 3) TTS systems trained with model-annotated boundaries are slightly better than systems that use manual ones.
Aug-NeRF: Training Stronger Neural Radiance Fields with Triple-Level Physically-Grounded Augmentations
Jul 04, 2022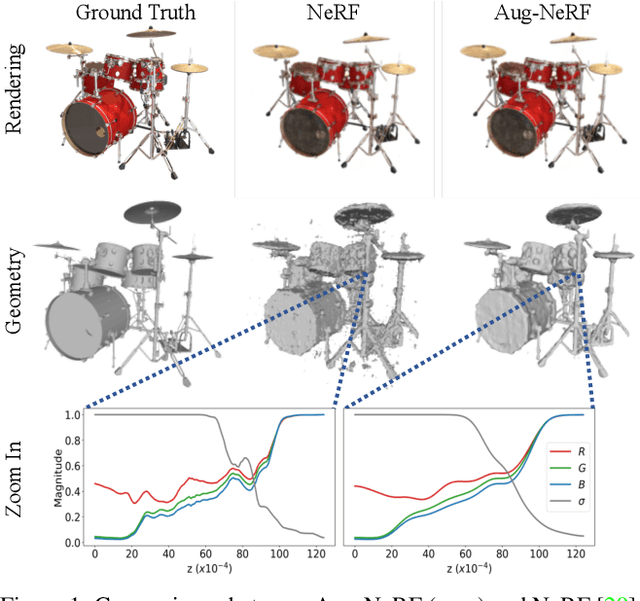
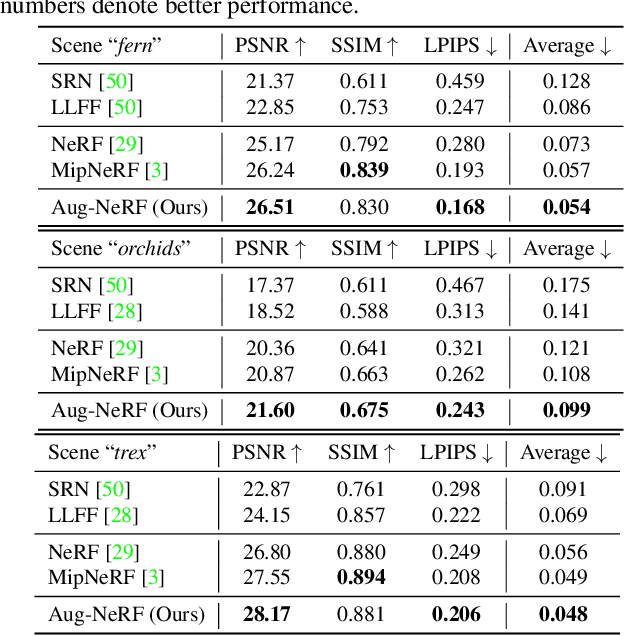
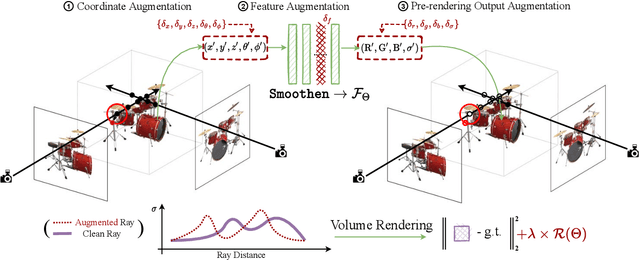
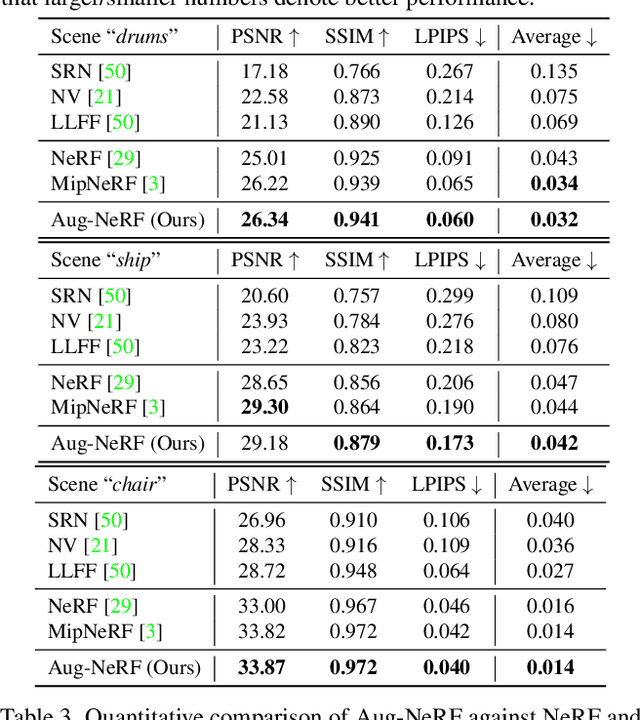
Neural Radiance Field (NeRF) regresses a neural parameterized scene by differentially rendering multi-view images with ground-truth supervision. However, when interpolating novel views, NeRF often yields inconsistent and visually non-smooth geometric results, which we consider as a generalization gap between seen and unseen views. Recent advances in convolutional neural networks have demonstrated the promise of advanced robust data augmentations, either random or learned, in enhancing both in-distribution and out-of-distribution generalization. Inspired by that, we propose Augmented NeRF (Aug-NeRF), which for the first time brings the power of robust data augmentations into regularizing the NeRF training. Particularly, our proposal learns to seamlessly blend worst-case perturbations into three distinct levels of the NeRF pipeline with physical grounds, including (1) the input coordinates, to simulate imprecise camera parameters at image capture; (2) intermediate features, to smoothen the intrinsic feature manifold; and (3) pre-rendering output, to account for the potential degradation factors in the multi-view image supervision. Extensive results demonstrate that Aug-NeRF effectively boosts NeRF performance in both novel view synthesis (up to 1.5dB PSNR gain) and underlying geometry reconstruction. Furthermore, thanks to the implicit smooth prior injected by the triple-level augmentations, Aug-NeRF can even recover scenes from heavily corrupted images, a highly challenging setting untackled before. Our codes are available in https://github.com/VITA-Group/Aug-NeRF.
Reactive Locomotion Decision-Making and Robust Motion Planning for Real-Time Perturbation Recovery
Oct 13, 2021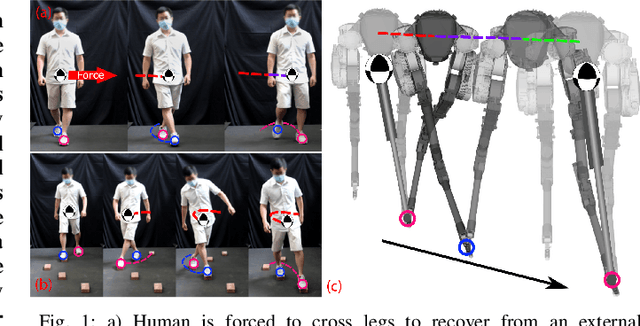
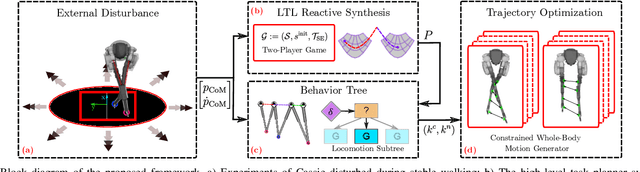
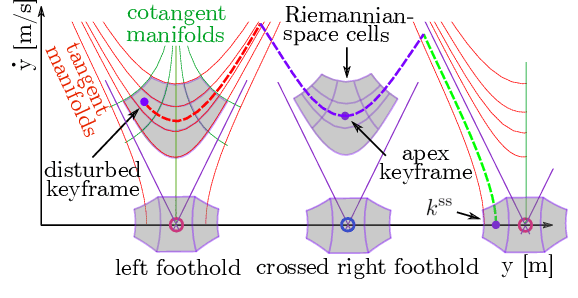
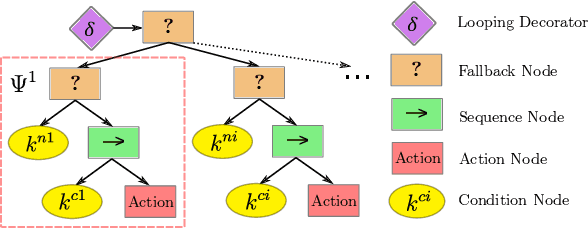
In this paper, we examine the problem of push recovery for bipedal robot locomotion and present a reactive decision-making and robust planning framework for locomotion resilient to external perturbations. Rejecting perturbations is an essential capability of bipedal robots and has been widely studied in the locomotion literature. However, adversarial disturbances and aggressive turning can lead to negative lateral step width (i.e., crossed-leg scenarios) with unstable motions and self-collision risks. These motion planning problems are computationally difficult and have not been explored under a hierarchically integrated task and motion planning method. We explore a planning and decision-making framework that closely ties linear-temporal-logic-based reactive synthesis with trajectory optimization incorporating the robot's full-body dynamics, kinematics, and leg collision avoidance constraints. Between the high-level discrete symbolic decision-making and the low-level continuous motion planning, behavior trees serve as a reactive interface to handle perturbations occurring at any time of the locomotion process. Our experimental results show the efficacy of our method in generating resilient recovery behaviors in response to diverse perturbations from any direction with bounded magnitudes.
Squeeze All: Novel Estimator and Self-Normalized Bound for Linear Contextual Bandits
Jun 16, 2022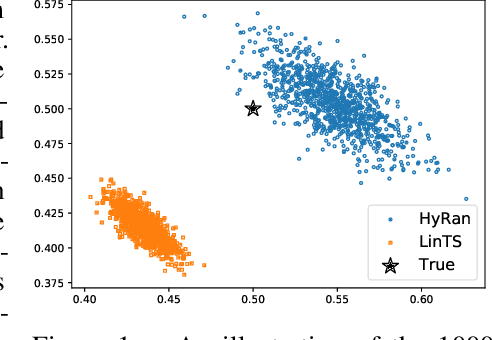
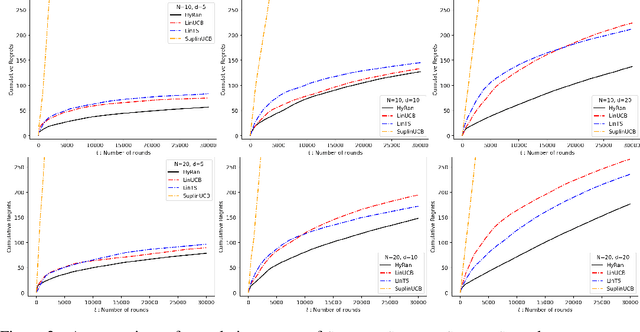
We propose a novel algorithm for linear contextual bandits with $O(\sqrt{dT \log T})$ regret bound, where $d$ is the dimension of contexts and $T$ is the time horizon. Our proposed algorithm is equipped with a novel estimator in which exploration is embedded through explicit randomization. Depending on the randomization, our proposed estimator takes contribution either from contexts of all arms or from selected contexts. We establish a self-normalized bound for our estimator, which allows a novel decomposition of the cumulative regret into additive dimension-dependent terms instead of multiplicative terms. We also prove a novel lower bound of $\Omega(\sqrt{dT})$ under our problem setting. Hence, the regret of our proposed algorithm matches the lower bound up to logarithmic factors. The numerical experiments support the theoretical guarantees and show that our proposed method outperforms the existing linear bandit algorithms.
Improving saliency models' predictions of the next fixation with humans' intrinsic cost of gaze shifts
Jul 09, 2022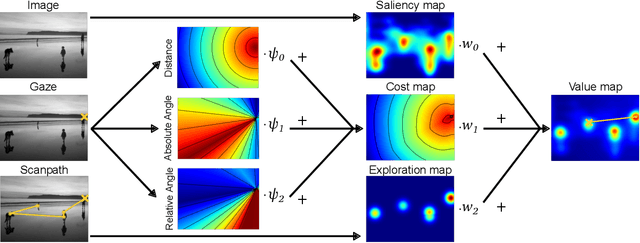
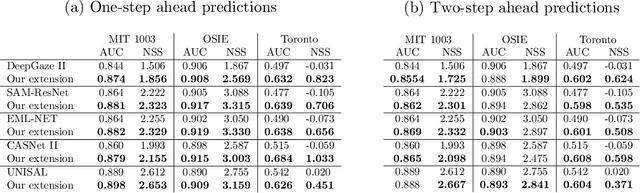
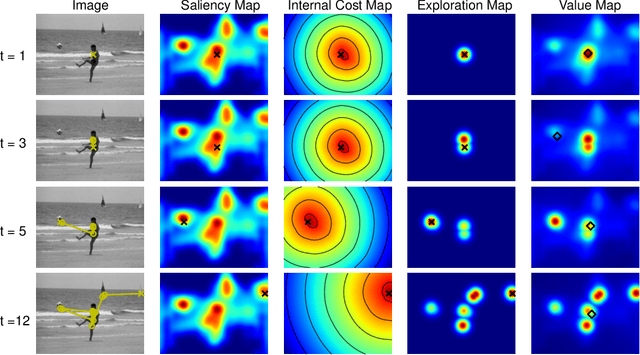
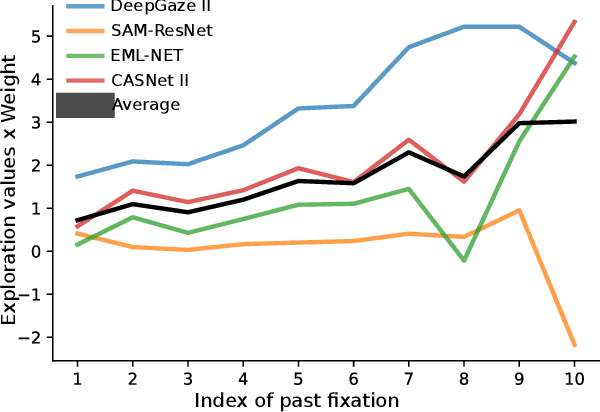
The human prioritization of image regions can be modeled in a time invariant fashion with saliency maps or sequentially with scanpath models. However, while both types of models have steadily improved on several benchmarks and datasets, there is still a considerable gap in predicting human gaze. Here, we leverage two recent developments to reduce this gap: theoretical analyses establishing a principled framework for predicting the next gaze target and the empirical measurement of the human cost for gaze switches independently of image content. We introduce an algorithm in the framework of sequential decision making, which converts any static saliency map into a sequence of dynamic history-dependent value maps, which are recomputed after each gaze shift. These maps are based on 1) a saliency map provided by an arbitrary saliency model, 2) the recently measured human cost function quantifying preferences in magnitude and direction of eye movements, and 3) a sequential exploration bonus, which changes with each subsequent gaze shift. The parameters of the spatial extent and temporal decay of this exploration bonus are estimated from human gaze data. The relative contributions of these three components were optimized on the MIT1003 dataset for the NSS score and are sufficient to significantly outperform predictions of the next gaze target on NSS and AUC scores for five state of the art saliency models on three image data sets. Thus, we provide an implementation of human gaze preferences, which can be used to improve arbitrary saliency models' predictions of humans' next gaze targets.
Feedback Gradient Descent: Efficient and Stable Optimization with Orthogonality for DNNs
May 12, 2022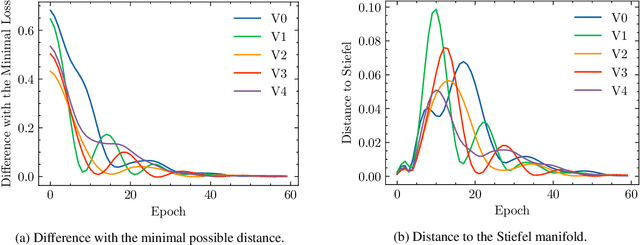
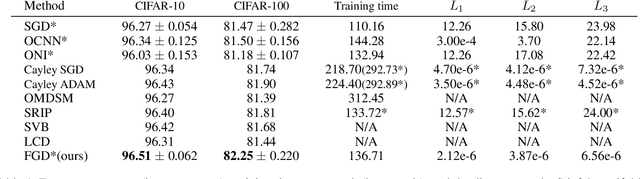
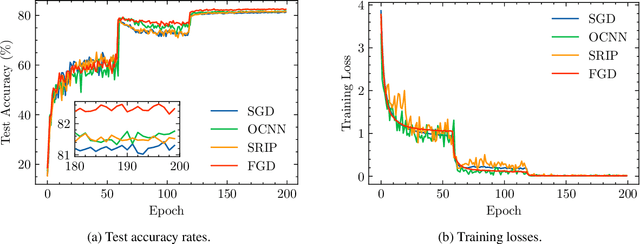

The optimization with orthogonality has been shown useful in training deep neural networks (DNNs). To impose orthogonality on DNNs, both computational efficiency and stability are important. However, existing methods utilizing Riemannian optimization or hard constraints can only ensure stability while those using soft constraints can only improve efficiency. In this paper, we propose a novel method, named Feedback Gradient Descent (FGD), to our knowledge, the first work showing high efficiency and stability simultaneously. FGD induces orthogonality based on the simple yet indispensable Euler discretization of a continuous-time dynamical system on the tangent bundle of the Stiefel manifold. In particular, inspired by a numerical integration method on manifolds called Feedback Integrators, we propose to instantiate it on the tangent bundle of the Stiefel manifold for the first time. In the extensive image classification experiments, FGD comprehensively outperforms the existing state-of-the-art methods in terms of accuracy, efficiency, and stability.
Robust Task Planning for Assembly Lines with Human-Robot Collaboration
Apr 17, 2022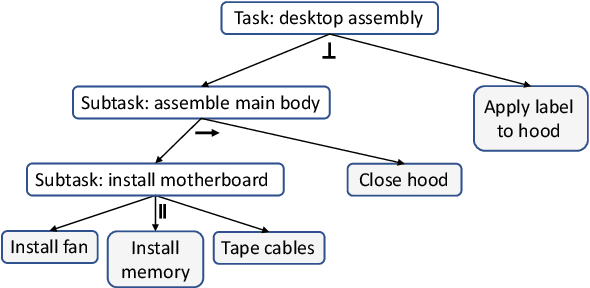
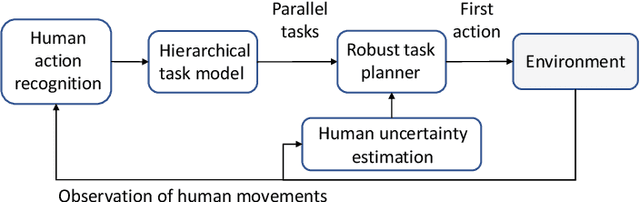
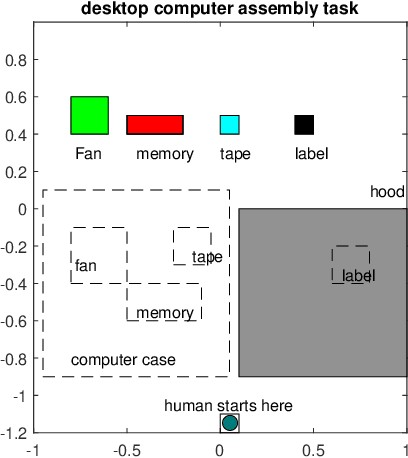

Efficient and robust task planning for a human-robot collaboration (HRC) system remains challenging. The human-aware task planner needs to assign jobs to both robots and human workers so that they can work collaboratively to achieve better time efficiency. However, the complexity of the tasks and the stochastic nature of the human collaborators bring challenges to such task planning. To reduce the complexity of the planning problem, we utilize the hierarchical task model, which explicitly captures the sequential and parallel relationships of the task. We model human movements with the sigma-lognormal functions to account for human-induced uncertainties. A human action model adaptation scheme is applied during run-time, and it provides a measure for modeling the human-induced uncertainties. We propose a sampling-based method to estimate human job completion time uncertainties. Next, we propose a robust task planner, which formulates the planning problem as a robust optimization problem by considering the task structure and the uncertainties. We conduct simulations of a robot arm collaborating with a human worker in an electronics assembly setting. The results show that our proposed planner can reduce task completion time when human-induced uncertainties occur compared to the baseline planner.
U-Former: Improving Monaural Speech Enhancement with Multi-head Self and Cross Attention
May 18, 2022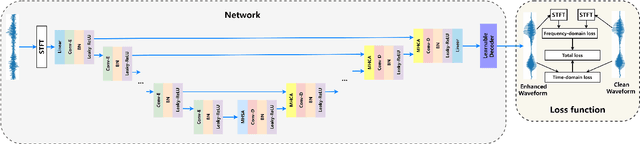
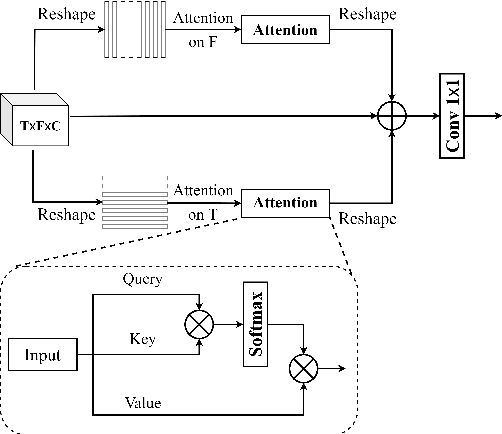
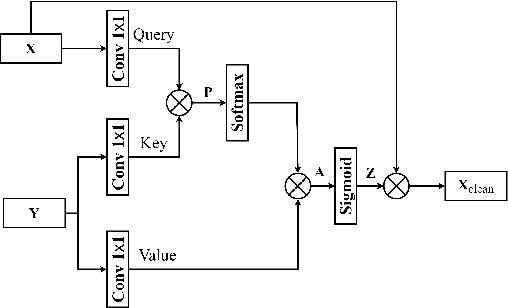
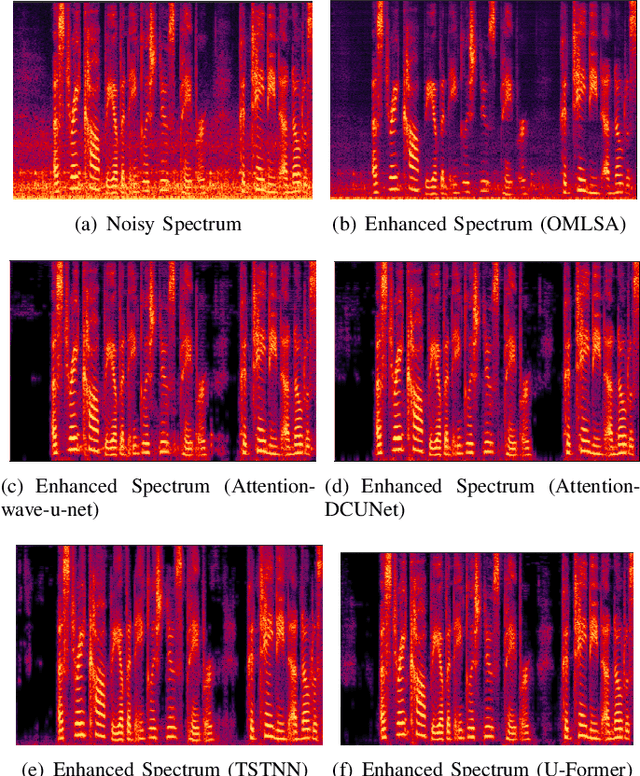
For supervised speech enhancement, contextual information is important for accurate spectral mapping. However, commonly used deep neural networks (DNNs) are limited in capturing temporal contexts. To leverage long-term contexts for tracking a target speaker, this paper treats the speech enhancement as sequence-to-sequence mapping, and propose a novel monaural speech enhancement U-net structure based on Transformer, dubbed U-Former. The key idea is to model long-term correlations and dependencies, which are crucial for accurate noisy speech modeling, through the multi-head attention mechanisms. For this purpose, U-Former incorporates multi-head attention mechanisms at two levels: 1) a multi-head self-attention module which calculate the attention map along both time- and frequency-axis to generate time and frequency sub-attention maps for leveraging global interactions between encoder features, while 2) multi-head cross-attention module which are inserted in the skip connections allows a fine recovery in the decoder by filtering out uncorrelated features. Experimental results illustrate that the U-Former obtains consistently better performance than recent models of PESQ, STOI, and SSNR scores.
Rethinking Deconvolution for 2D Human Pose Estimation Light yet Accurate Model for Real-time Edge Computing
Nov 08, 2021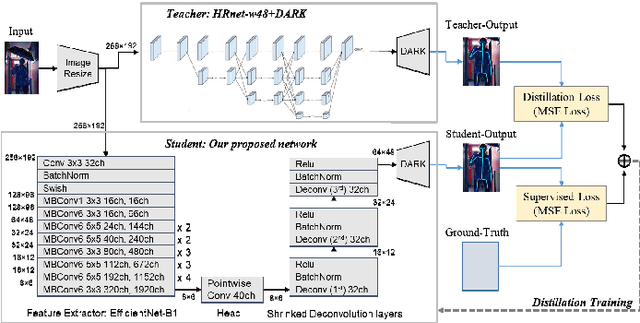
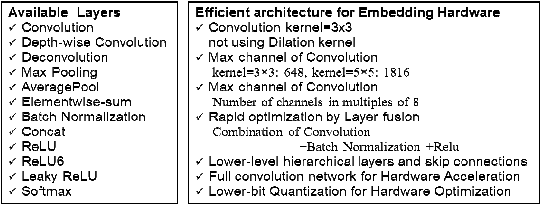
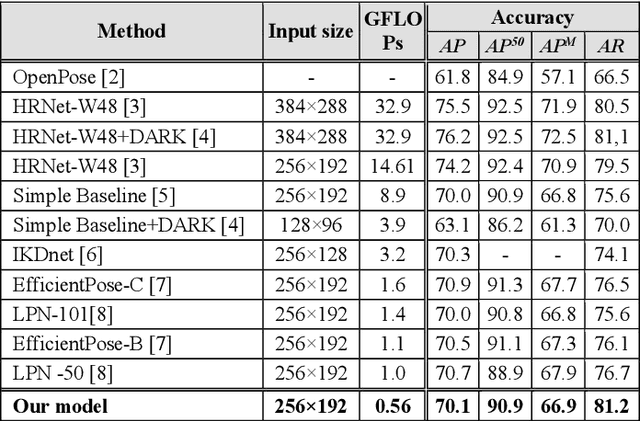
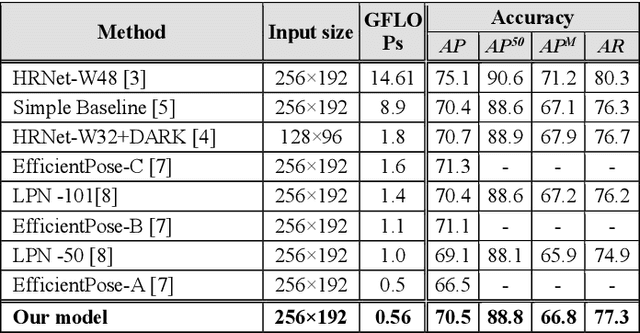
In this study, we present a pragmatic lightweight pose estimation model. Our model can achieve real-time predictions using low-power embedded devices. This system was found to be very accurate and achieved a 94.5% accuracy of SOTA HRNet 256x192 using a computational cost of only 3.8% on COCO test dataset. Our model adopts an encoder-decoder architecture and is carefully downsized to improve its efficiency. We especially focused on optimizing the deconvolution layers and observed that the channel reduction of the deconvolution layers contributes significantly to reducing computational resource consumption without degrading the accuracy of this system. We also incorporated recent model agnostic techniques such as DarkPose and distillation training to maximize the efficiency of our model. Furthermore, we applied model quantization to exploit multi/mixed precision features. Our FP16'ed model (COCO AP 70.0) operates at ~60-fps on NVIDIA Jetson AGX Xavier and ~200 fps on NVIDIA Quadro RTX6000.