 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Analog Compressed Sensing for Sparse Frequency Shift Keying Modulation Schemes
May 31, 2022
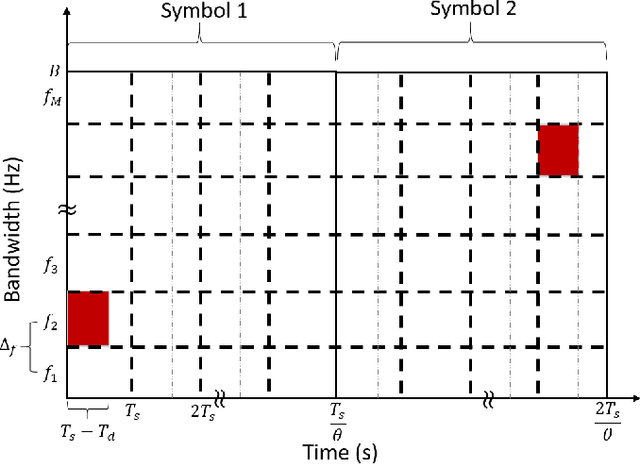
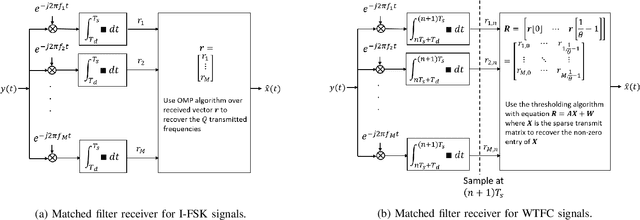
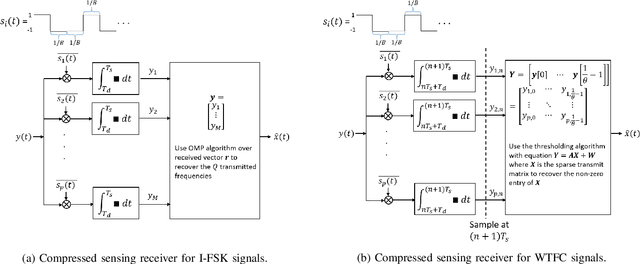
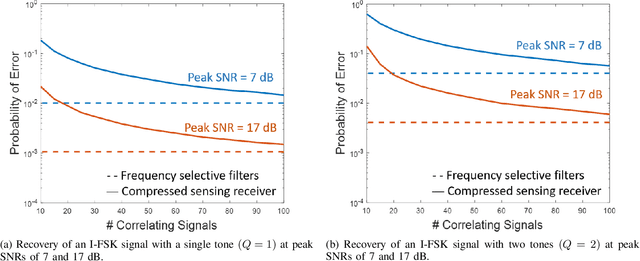
There is a growing interest in signaling schemes that operate in the wideband regime due to the crowded frequency spectrum. However, a downside of the wideband regime is that obtaining channel state information is costly, and the capacity of previously used modulation schemes such as code division multiple access and orthogonal frequency division multiplexing begins to diverge from the capacity bound without channel state information. Impulsive frequency shift keying and wideband time frequency coding have been shown to perform well in the wideband regime without channel state information, thus avoiding the costs and challenges associated with obtaining channel state information. However, the maximum likelihood receiver is a bank of frequency-selective filters, which is very costly to implement due to the large number of filters. In this work, we aim to simplify the receiver by using an analog compressed sensing receiver with chipping sequences as correlating signals to detect the sparse signals. Our results show that using a compressed sensing receiver allows for the simplification of the analog receiver with the trade off of a slight degradation in recovery performance. For a fixed frequency separation, symbol time, and peak SNR, the performance loss remains the same for a fixed ratio of number of correlating signals to the number of frequencies.
Prosody Cloning in Zero-Shot Multispeaker Text-to-Speech
Jun 24, 2022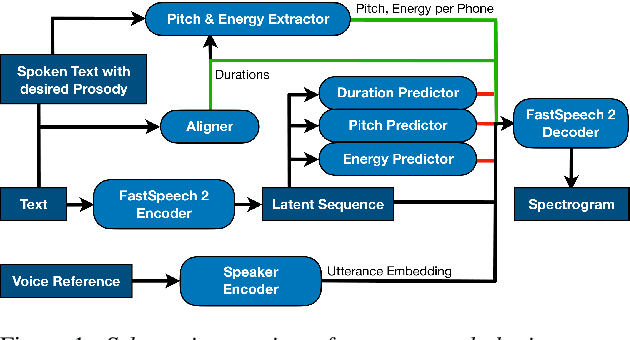
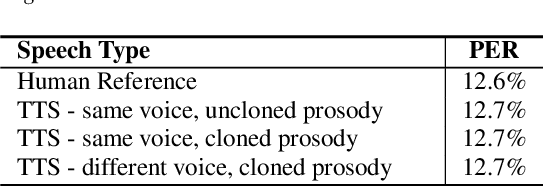

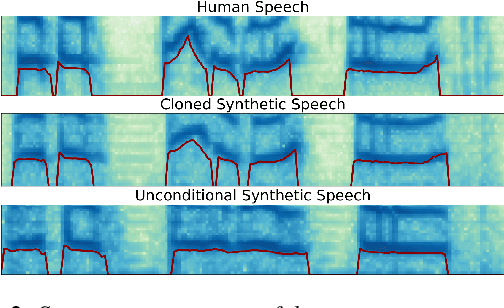
The cloning of a speaker's voice using an untranscribed reference sample is one of the great advances of modern neural text-to-speech (TTS) methods. Approaches for mimicking the prosody of a transcribed reference audio have also been proposed recently. In this work, we bring these two tasks together for the first time through utterance level normalization in conjunction with an utterance level speaker embedding. We further introduce a lightweight aligner for extracting fine-grained prosodic features, that can be finetuned on individual samples within seconds. We show that it is possible to clone the voice of a speaker as well as the prosody of a spoken reference independently without any degradation in quality and high similarity to both original voice and prosody, as our objective evaluation and human study show. All of our code and trained models are available, alongside static and interactive demos.
Mean Embeddings with Test-Time Data Augmentation for Ensembling of Representations
Jul 14, 2021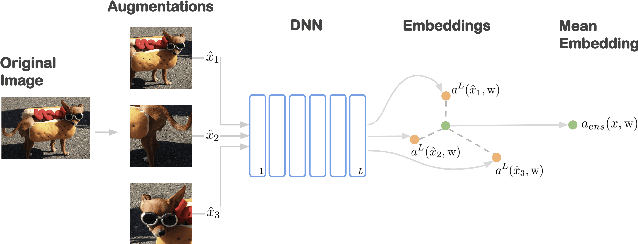
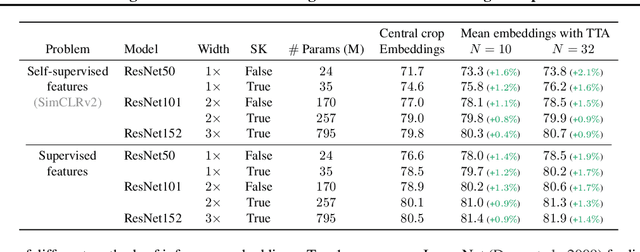
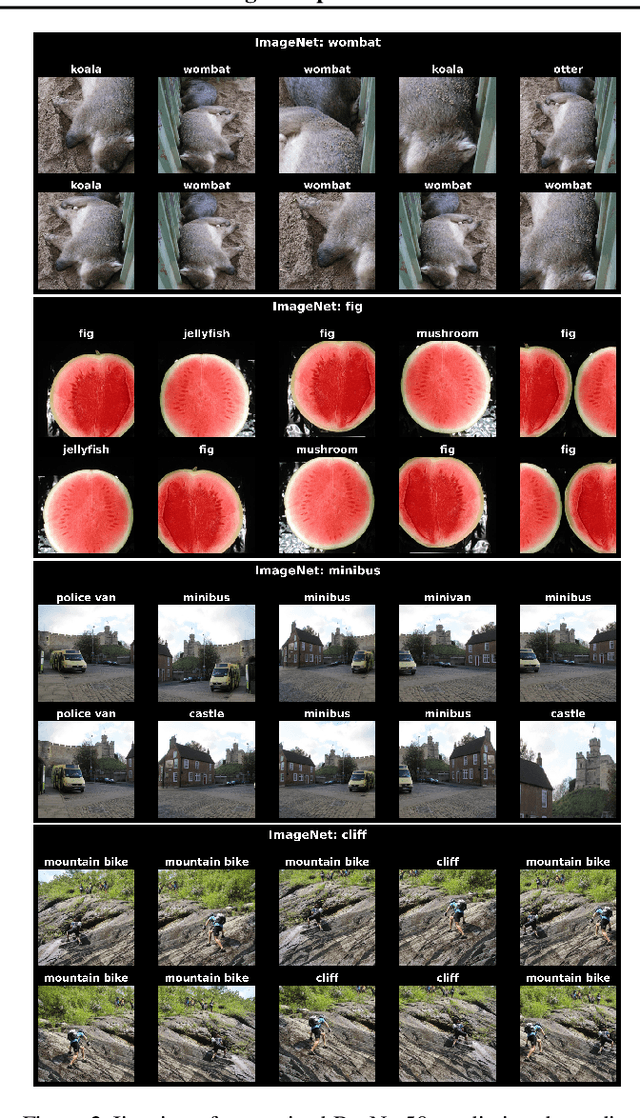
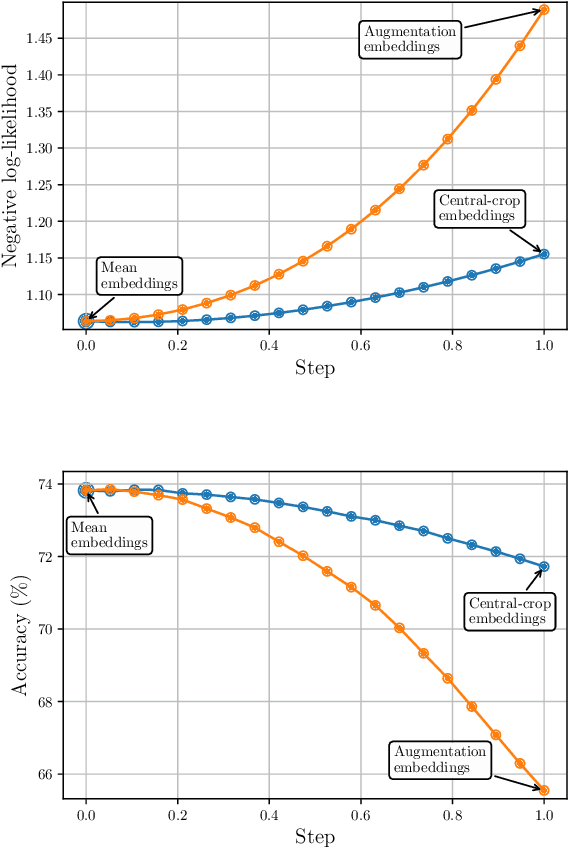
Averaging predictions over a set of models -- an ensemble -- is widely used to improve predictive performance and uncertainty estimation of deep learning models. At the same time, many machine learning systems, such as search, matching, and recommendation systems, heavily rely on embeddings. Unfortunately, due to misalignment of features of independently trained models, embeddings, cannot be improved with a naive deep ensemble like approach. In this work, we look at the ensembling of representations and propose mean embeddings with test-time augmentation (MeTTA) simple yet well-performing recipe for ensembling representations. Empirically we demonstrate that MeTTA significantly boosts the quality of linear evaluation on ImageNet for both supervised and self-supervised models. Even more exciting, we draw connections between MeTTA, image retrieval, and transformation invariant models. We believe that spreading the success of ensembles to inference higher-quality representations is the important step that will open many new applications of ensembling.
A Spatio-Temporal Multilayer Perceptron for Gesture Recognition
Apr 25, 2022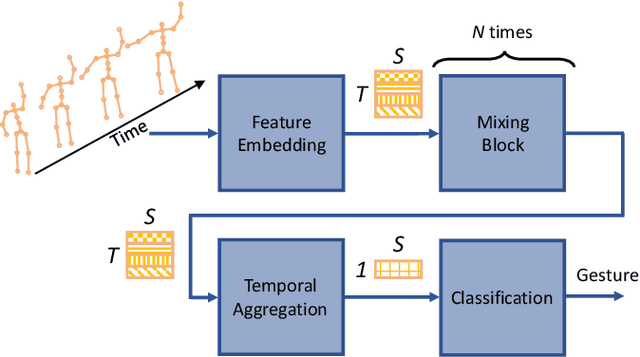
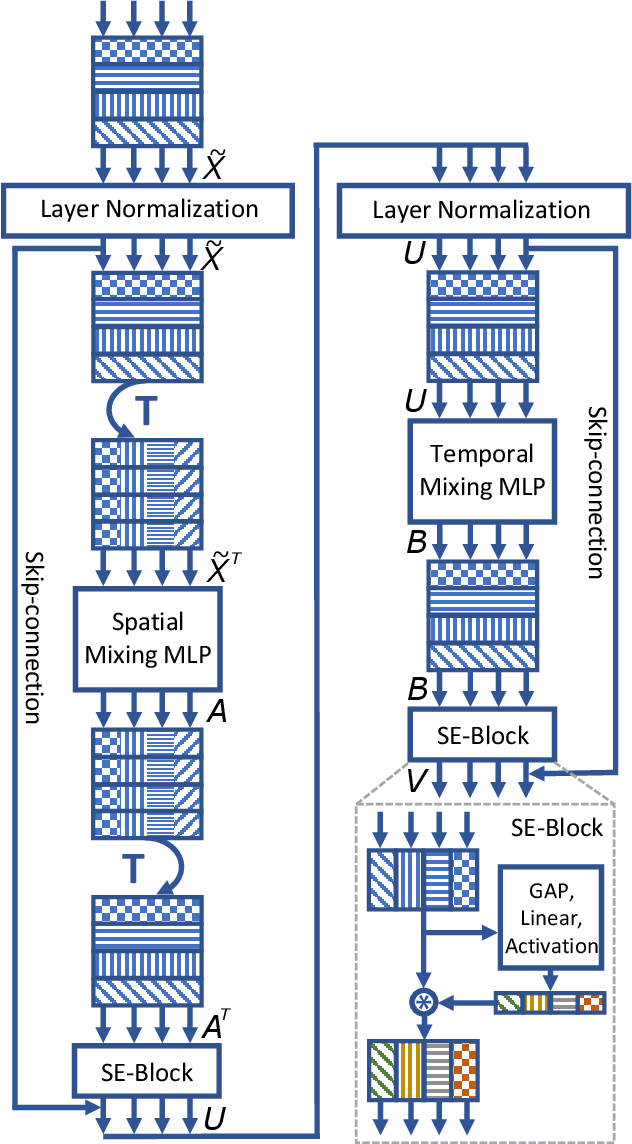

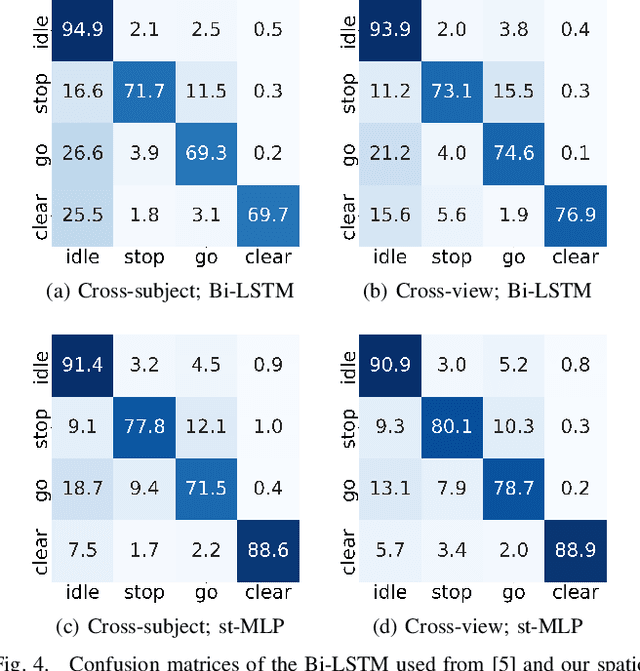
Gesture recognition is essential for the interaction of autonomous vehicles with humans. While the current approaches focus on combining several modalities like image features, keypoints and bone vectors, we present neural network architecture that delivers state-of-the-art results only with body skeleton input data. We propose the spatio-temporal multilayer perceptron for gesture recognition in the context of autonomous vehicles. Given 3D body poses over time, we define temporal and spatial mixing operations to extract features in both domains. Additionally, the importance of each time step is re-weighted with Squeeze-and-Excitation layers. An extensive evaluation of the TCG and Drive&Act datasets is provided to showcase the promising performance of our approach. Furthermore, we deploy our model to our autonomous vehicle to show its real-time capability and stable execution.
Channel Estimation and Signal Detection for MIMO-AFDM under Doubly Selective Channels
Jun 26, 2022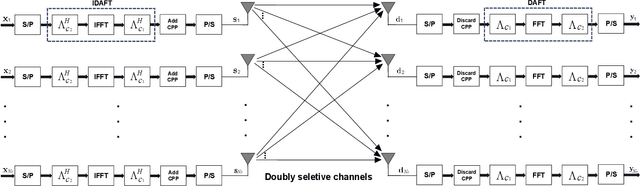
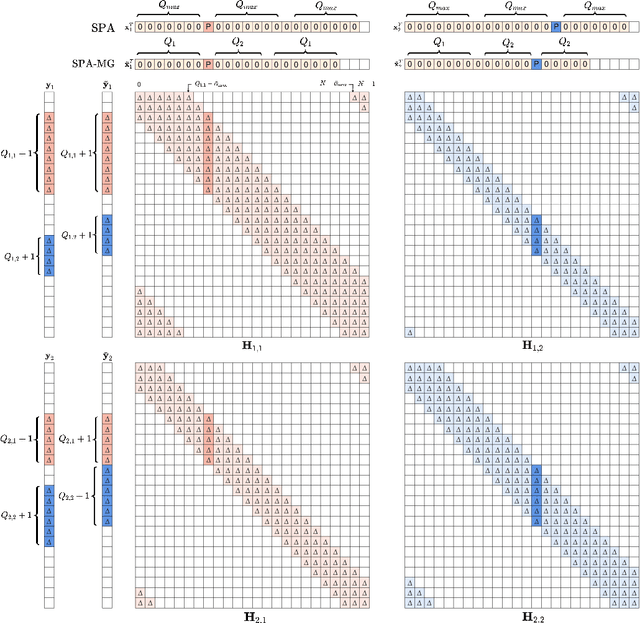
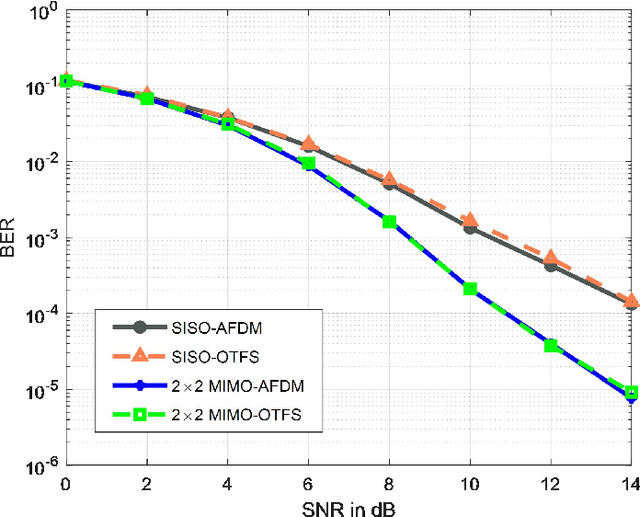
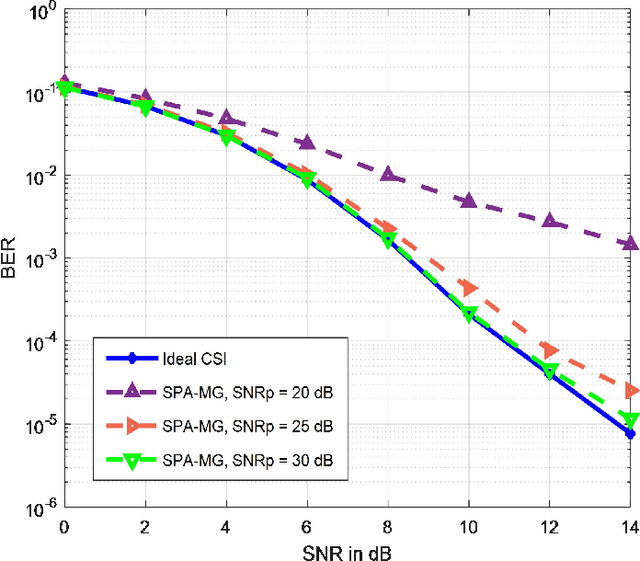
On the heels of orthogonal time frequency space (OTFS) modulation, the recently discovered affine frequency division multiplexing (AFDM) is a promising waveform for the sixth-generation wireless network due to its strong delay-doppler resilience against the double dispersive channels. With the superiorities of high multiplexing and diversity gain of multiple-input multiple-output (MIMO), we derive a vectorized input-output formulation of the MIMO-AFDM system. Correspondingly, we also propose an efficient single pilot aided with minimum guard (SPA-MG) scheme to perform channel estimation in the discrete affine Fourier transform (DAFT) domain. Furthermore, the message passing based iterative detector is explored for signal detection. Finally, the bit error ratio (BER) performances are simulated under doubly selective channels. It is worth emphasizing that the MIMO-AFDM system can achieve outstanding performance similar to MIMO-OTFS. Additionally, compared to ideal channel state information, our proposed SPA-MG scheme is verified to provide marginal difference with the least overhead.
SphereVLAD++: Attention-based and Signal-enhanced Viewpoint Invariant Descriptor
Jul 06, 2022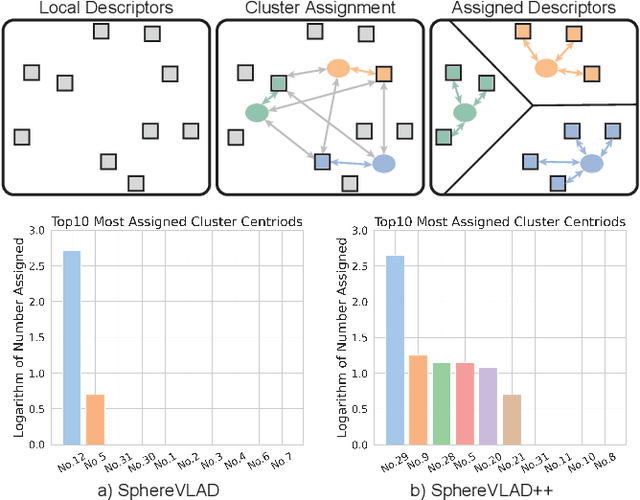
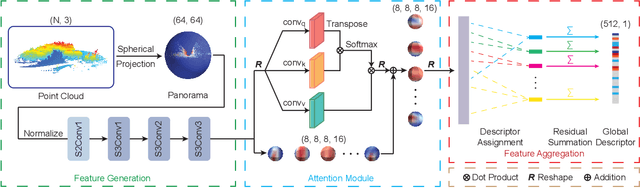
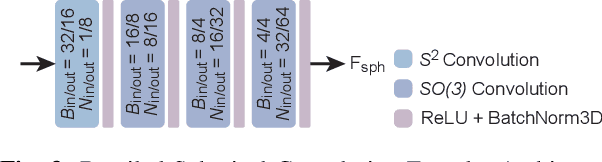
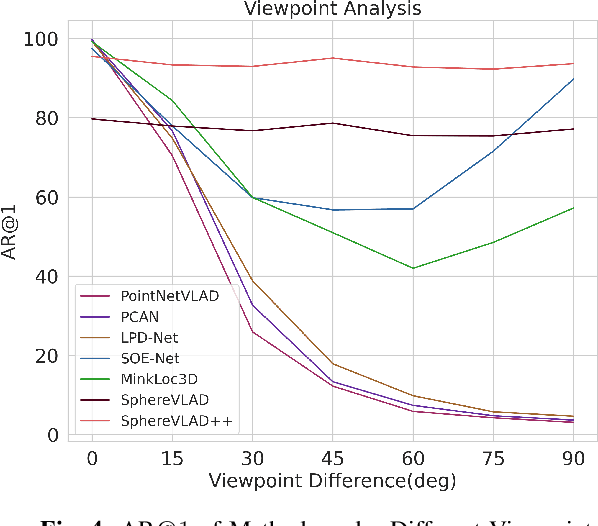
LiDAR-based localization approach is a fundamental module for large-scale navigation tasks, such as last-mile delivery and autonomous driving, and localization robustness highly relies on viewpoints and 3D feature extraction. Our previous work provides a viewpoint-invariant descriptor to deal with viewpoint differences; however, the global descriptor suffers from a low signal-noise ratio in unsupervised clustering, reducing the distinguishable feature extraction ability. We develop SphereVLAD++, an attention-enhanced viewpoint invariant place recognition method in this work. SphereVLAD++ projects the point cloud on the spherical perspective for each unique area and captures the contextual connections between local features and their dependencies with global 3D geometry distribution. In return, clustered elements within the global descriptor are conditioned on local and global geometries and support the original viewpoint-invariant property of SphereVLAD. In the experiments, we evaluated the localization performance of SphereVLAD++ on both public KITTI360 datasets and self-generated datasets from the city of Pittsburgh. The experiment results show that SphereVLAD++ outperforms all relative state-of-the-art 3D place recognition methods under small or even totally reversed viewpoint differences and shows 0.69% and 15.81% successful retrieval rates with better than the second best. Low computation requirements and high time efficiency also help its application for low-cost robots.
NP-Match: When Neural Processes meet Semi-Supervised Learning
Jul 03, 2022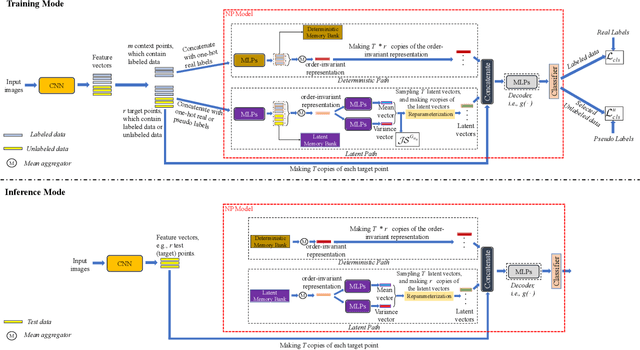
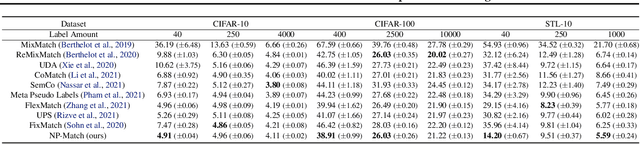
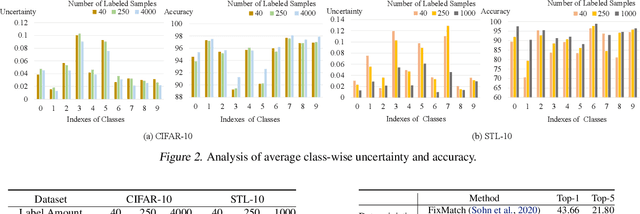
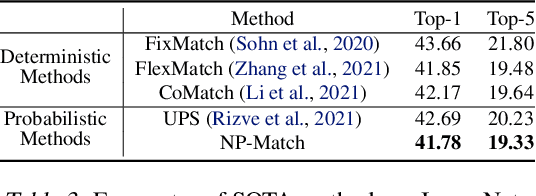
Semi-supervised learning (SSL) has been widely explored in recent years, and it is an effective way of leveraging unlabeled data to reduce the reliance on labeled data. In this work, we adjust neural processes (NPs) to the semi-supervised image classification task, resulting in a new method named NP-Match. NP-Match is suited to this task for two reasons. Firstly, NP-Match implicitly compares data points when making predictions, and as a result, the prediction of each unlabeled data point is affected by the labeled data points that are similar to it, which improves the quality of pseudo-labels. Secondly, NP-Match is able to estimate uncertainty that can be used as a tool for selecting unlabeled samples with reliable pseudo-labels. Compared with uncertainty-based SSL methods implemented with Monte Carlo (MC) dropout, NP-Match estimates uncertainty with much less computational overhead, which can save time at both the training and the testing phases. We conducted extensive experiments on four public datasets, and NP-Match outperforms state-of-the-art (SOTA) results or achieves competitive results on them, which shows the effectiveness of NP-Match and its potential for SSL.
Resource-Efficient Separation Transformer
Jun 19, 2022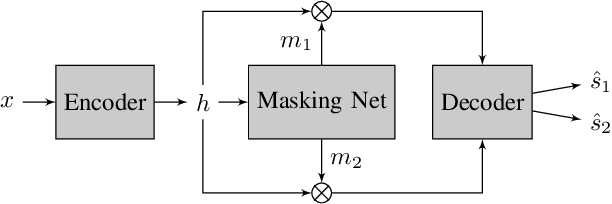
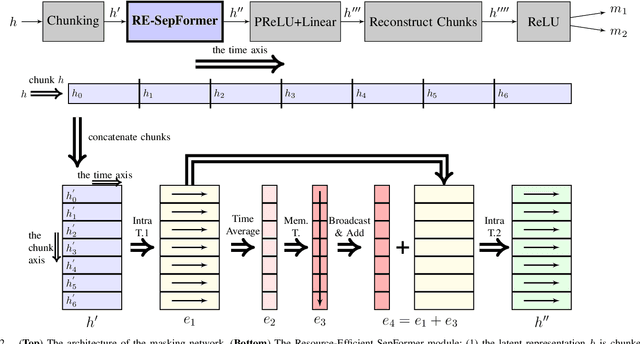
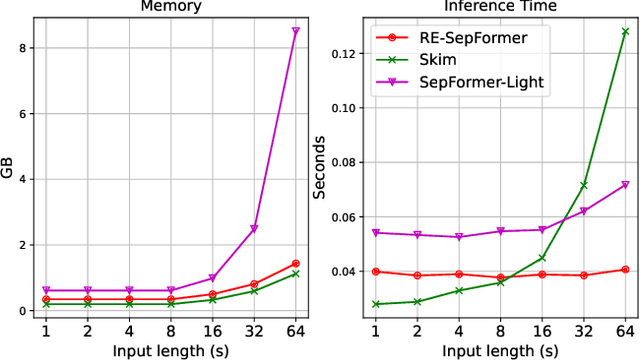
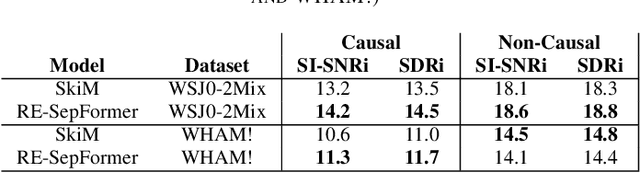
Transformers have recently achieved state-of-the-art performance in speech separation. These models, however, are computationally-demanding and require a lot of learnable parameters. This paper explores Transformer-based speech separation with a reduced computational cost. Our main contribution is the development of the Resource-Efficient Separation Transformer (RE-SepFormer), a self-attention-based architecture that reduces the computational burden in two ways. First, it uses non-overlapping blocks in the latent space. Second, it operates on compact latent summaries calculated from each chunk. The RE-SepFormer reaches a competitive performance on the popular WSJ0-2Mix and WHAM! datasets in both causal and non-causal settings. Remarkably, it scales significantly better than the previous Transformer and RNN-based architectures in terms of memory and inference-time, making it more suitable for processing long mixtures.
TE2Rules: Extracting Rule Lists from Tree Ensembles
Jun 30, 2022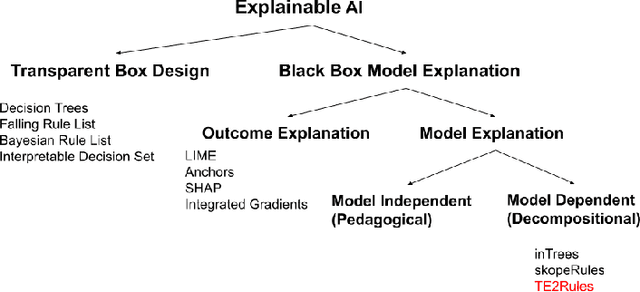
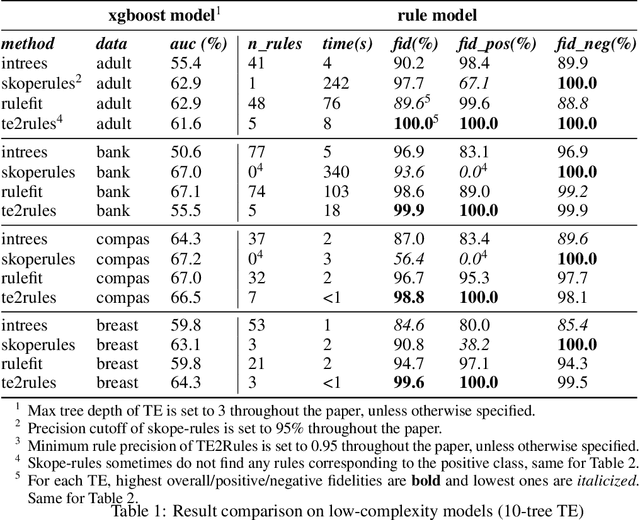
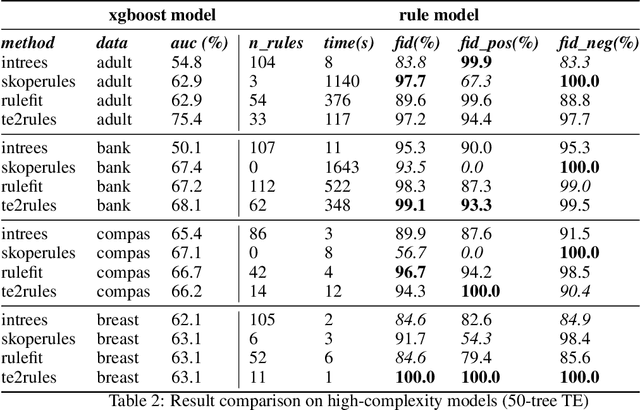
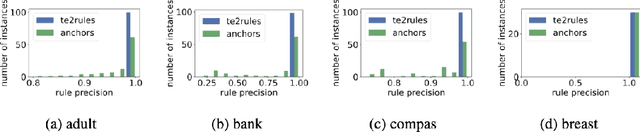
Tree Ensemble (TE) models (e.g. Gradient Boosted Trees and Random Forests) often provide higher prediction performance compared to single decision trees. However, TE models generally lack transparency and interpretability, as humans have difficulty understanding their decision logic. This paper presents a novel approach to convert a TE trained for a binary classification task, to a rule list (RL) that is a global equivalent to the TE and is comprehensible for a human. This RL captures all necessary and sufficient conditions for decision making by the TE. Experiments on benchmark datasets demonstrate that, compared to state-of-the-art methods, (i) predictions from the RL generated by TE2Rules have high fidelity with respect to the original TE, (ii) the RL from TE2Rules has high interpretability measured by the number and the length of the decision rules, (iii) the run-time of TE2Rules algorithm can be reduced significantly at the cost of a slightly lower fidelity, and (iv) the RL is a fast alternative to the state-of-the-art rule-based instance-level outcome explanation techniques.
Automated Mobility Context Detection with Inertial Signals
May 16, 2022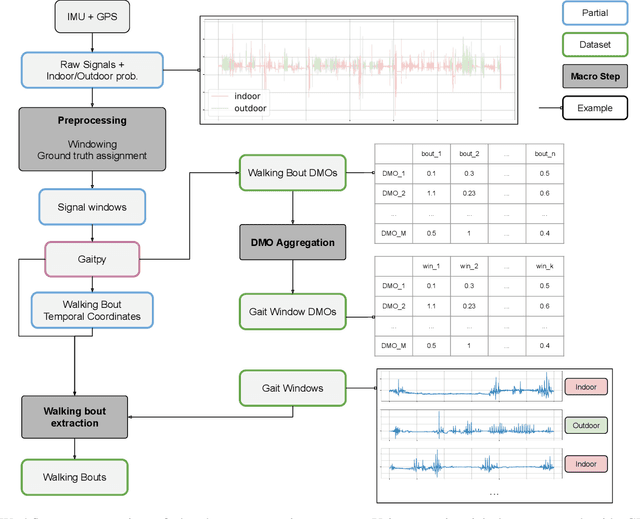
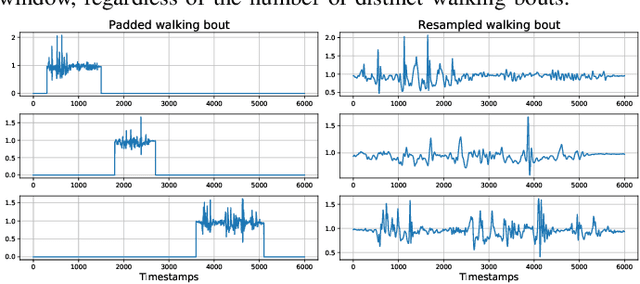
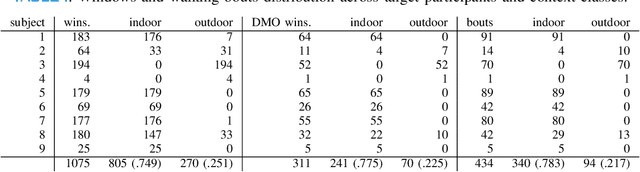
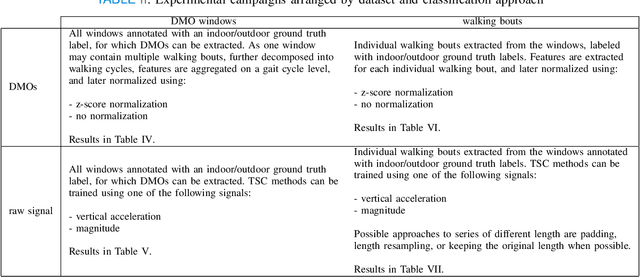
Remote monitoring of motor functions is a powerful approach for health assessment, especially among the elderly population or among subjects affected by pathologies that negatively impact their walking capabilities. This is further supported by the continuous development of wearable sensor devices, which are getting progressively smaller, cheaper, and more energy efficient. The external environment and mobility context have an impact on walking performance, hence one of the biggest challenges when remotely analysing gait episodes is the ability to detect the context within which those episodes occurred. The primary goal of this paper is the investigation of context detection for remote monitoring of daily motor functions. We aim to understand whether inertial signals sampled with wearable accelerometers, provide reliable information to classify gait-related activities as either indoor or outdoor. We explore two different approaches to this task: (1) using gait descriptors and features extracted from the input inertial signals sampled during walking episodes, together with classic machine learning algorithms, and (2) treating the input inertial signals as time series data and leveraging end-to-end state-of-the-art time series classifiers. We directly compare the two approaches through a set of experiments based on data collected from 9 healthy individuals. Our results indicate that the indoor/outdoor context can be successfully derived from inertial data streams. We also observe that time series classification models achieve better accuracy than any other feature-based models, while preserving efficiency and ease of use.