 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SPR:Supervised Personalized Ranking Based on Prior Knowledge for Recommendation
Jul 07, 2022
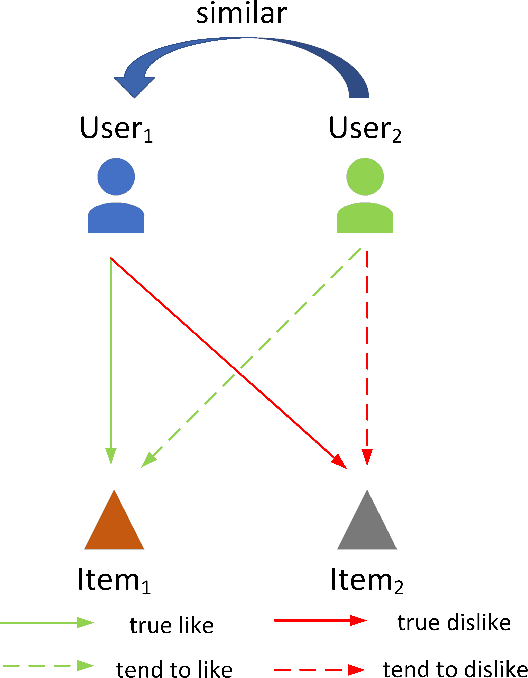
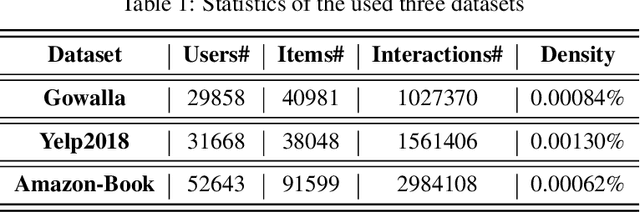

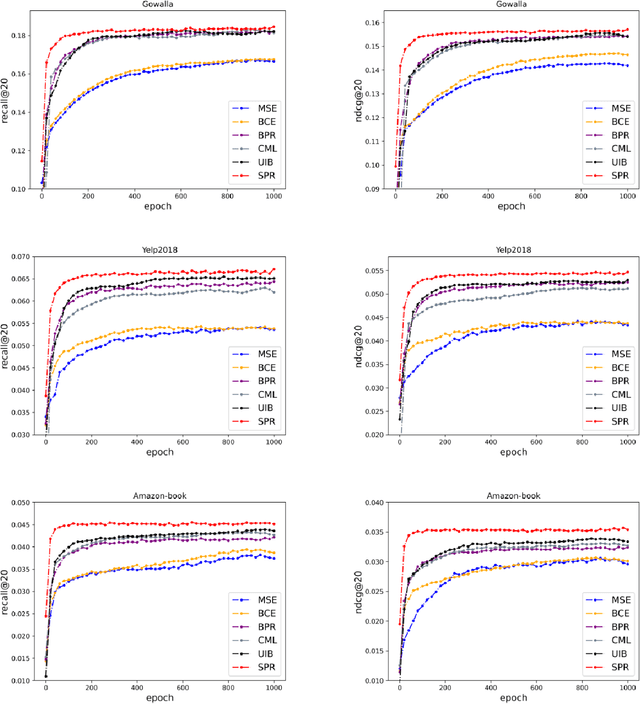
The goal of a recommendation system is to model the relevance between each user and each item through the user-item interaction history, so that maximize the positive samples score and minimize negative samples. Currently, two popular loss functions are widely used to optimize recommender systems: the pointwise and the pairwise. Although these loss functions are widely used, however, there are two problems. (1) These traditional loss functions do not fit the goals of recommendation systems adequately and utilize prior knowledge information sufficiently. (2) The slow convergence speed of these traditional loss functions makes the practical application of various recommendation models difficult. To address these issues, we propose a novel loss function named Supervised Personalized Ranking (SPR) Based on Prior Knowledge. The proposed method improves the BPR loss by exploiting the prior knowledge on the interaction history of each user or item in the raw data. Unlike BPR, instead of constructing <user, positive item, negative item> triples, the proposed SPR constructs <user, similar user, positive item, negative item> quadruples. Although SPR is very simple, it is very effective. Extensive experiments show that our proposed SPR not only achieves better recommendation performance, but also significantly accelerates the convergence speed, resulting in a significant reduction in the required training time.
Beyond the Gates of Euclidean Space: Temporal-Discrimination-Fusions and Attention-based Graph Neural Network for Human Activity Recognition
Jun 10, 2022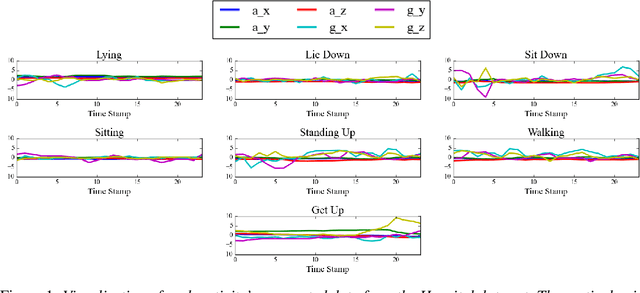
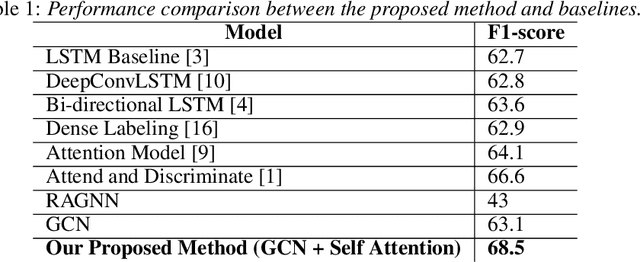
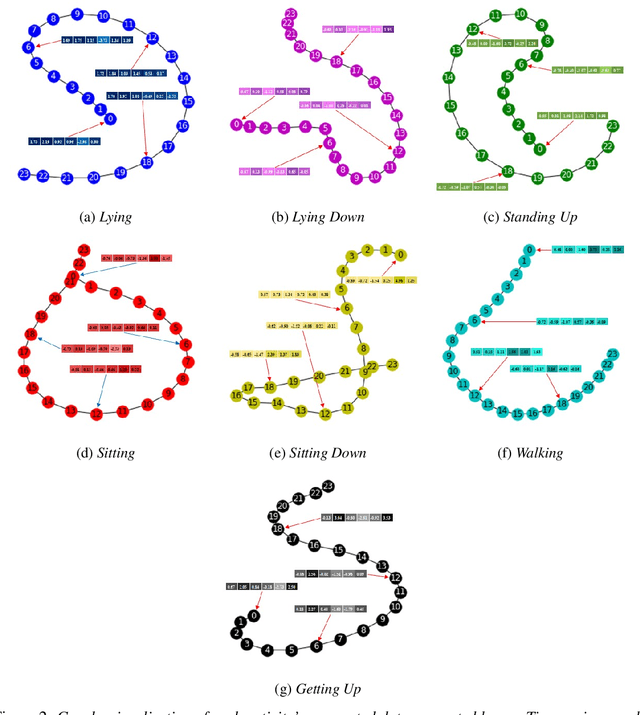
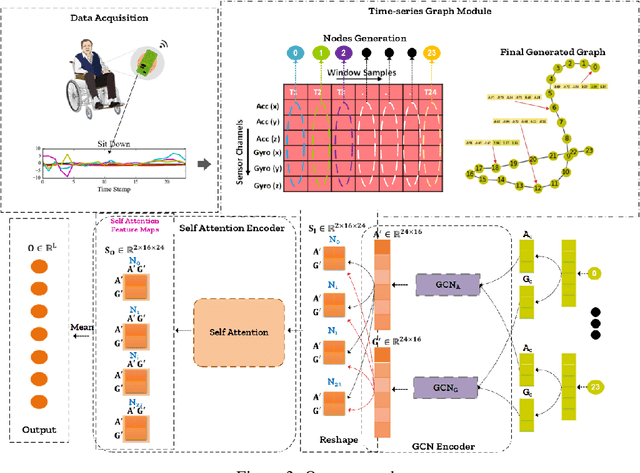
Human activity recognition (HAR) through wearable devices has received much interest due to its numerous applications in fitness tracking, wellness screening, and supported living. As a result, we have seen a great deal of work in this field. Traditional deep learning (DL) has set a state of the art performance for HAR domain. However, it ignores the data's structure and the association between consecutive time stamps. To address this constraint, we offer an approach based on Graph Neural Networks (GNNs) for structuring the input representation and exploiting the relations among the samples. However, even when using a simple graph convolution network to eliminate this shortage, there are still several limiting factors, such as inter-class activities issues, skewed class distribution, and a lack of consideration for sensor data priority, all of which harm the HAR model's performance. To improve the current HAR model's performance, we investigate novel possibilities within the framework of graph structure to achieve highly discriminated and rich activity features. We propose a model for (1) time-series-graph module that converts raw data from HAR dataset into graphs; (2) Graph Convolutional Neural Networks (GCNs) to discover local dependencies and correlations between neighboring nodes; and (3) self-attention GNN encoder to identify sensors interactions and data priorities. To the best of our knowledge, this is the first work for HAR, which introduces a GNN-based approach that incorporates both the GCN and the attention mechanism. By employing a uniform evaluation method, our framework significantly improves the performance on hospital patient's activities dataset comparatively considered other state of the art baseline methods.
Enveloped Sinusoid Parseval Frames
Apr 18, 2022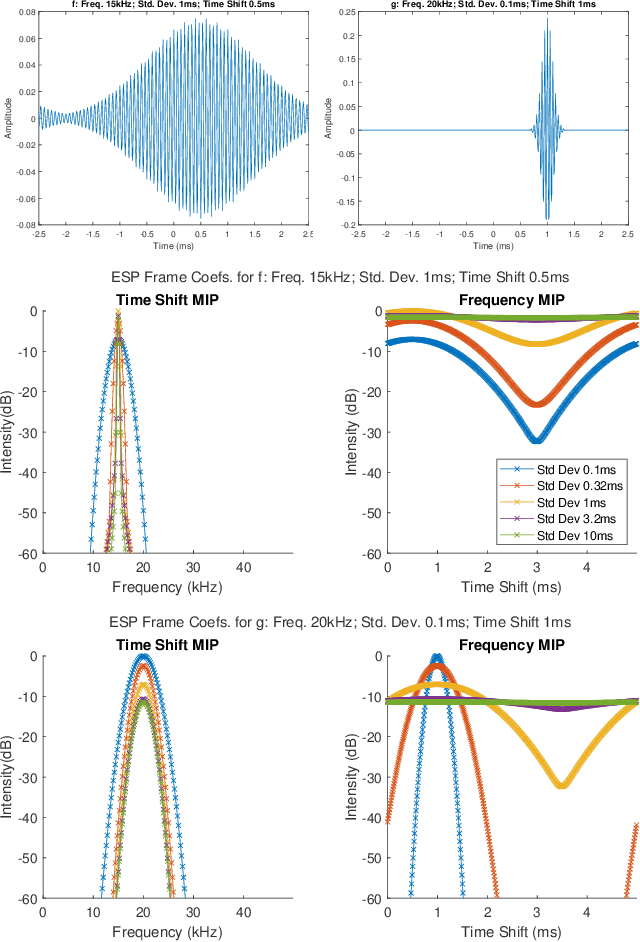
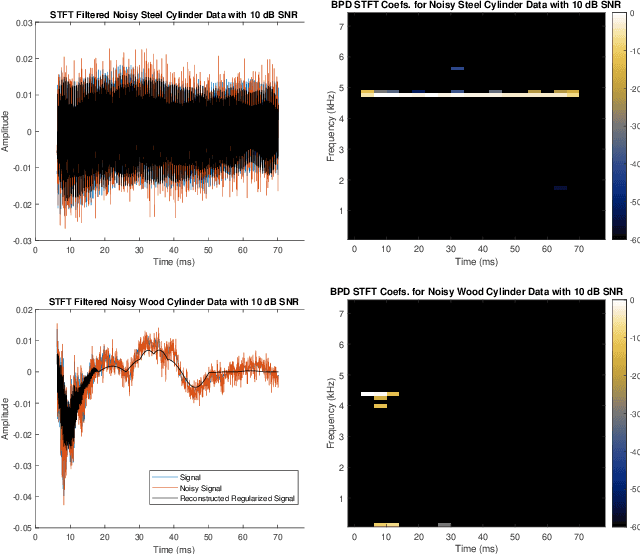
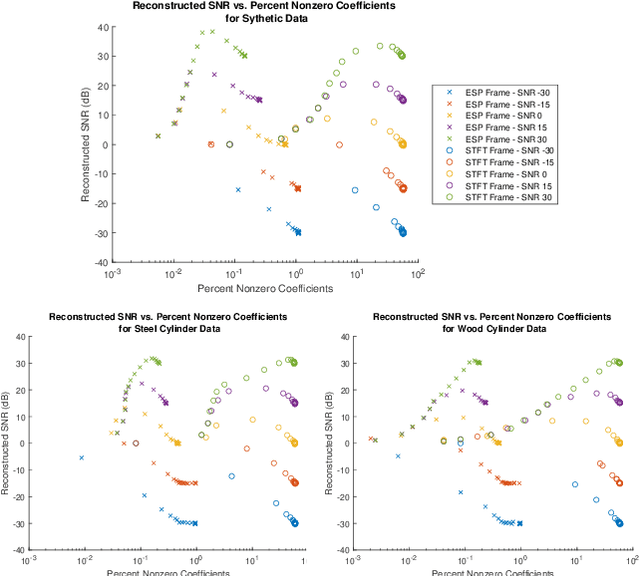
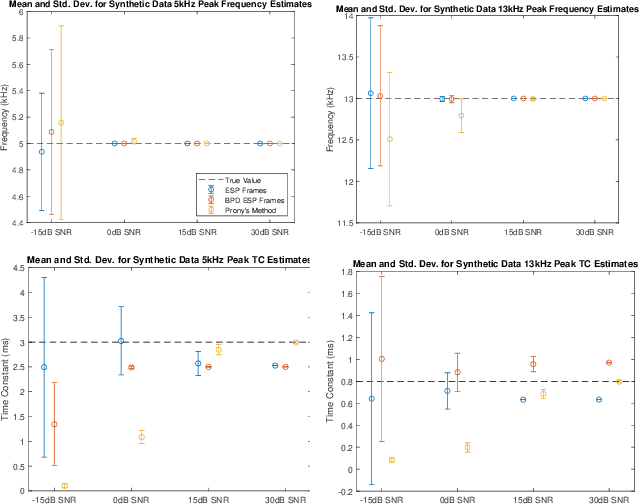
This paper presents a method of constructing Parseval frames from any collection of complex envelopes. The resulting Enveloped Sinusoid Parseval (ESP) frames can represent a wide variety of signal types as specified by their physical morphology. Since the ESP frame retains its Parseval property even when generated from a variety of envelopes, it is compatible with large scale and iterative optimization algorithms. ESP frames are constructed by applying time-shifted enveloping functions to the discrete Fourier Transform basis, and in this way are similar to the short-time Fourier Transform. This work provides examples of ESP frame generation for both synthetic and experimentally measured signals. Furthermore, the frame's compatibility with distributed sparse optimization frameworks is demonstrated, and efficient implementation details are provided. Numerical experiments on acoustics data reveal that the flexibility of this method allows it to be simultaneously competitive with the STFT in time-frequency processing and also with Prony's Method for time-constant parameter estimation, surpassing the shortcomings of each individual technique.
Active Learning with Safety Constraints
Jun 22, 2022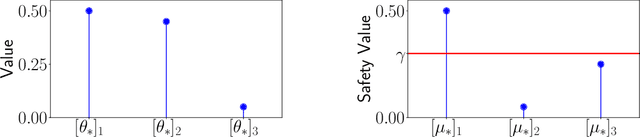
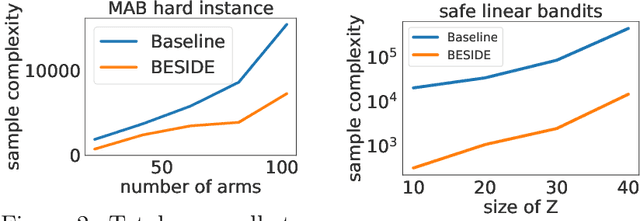
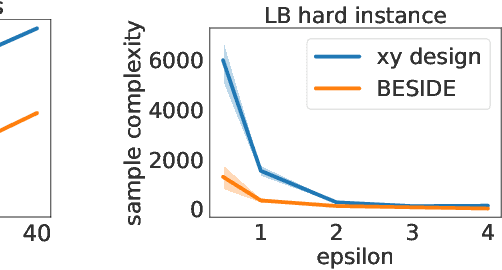
Active learning methods have shown great promise in reducing the number of samples necessary for learning. As automated learning systems are adopted into real-time, real-world decision-making pipelines, it is increasingly important that such algorithms are designed with safety in mind. In this work we investigate the complexity of learning the best safe decision in interactive environments. We reduce this problem to a constrained linear bandits problem, where our goal is to find the best arm satisfying certain (unknown) safety constraints. We propose an adaptive experimental design-based algorithm, which we show efficiently trades off between the difficulty of showing an arm is unsafe vs suboptimal. To our knowledge, our results are the first on best-arm identification in linear bandits with safety constraints. In practice, we demonstrate that this approach performs well on synthetic and real world datasets.
TINC: Temporally Informed Non-Contrastive Learning for Disease Progression Modeling in Retinal OCT Volumes
Jun 30, 2022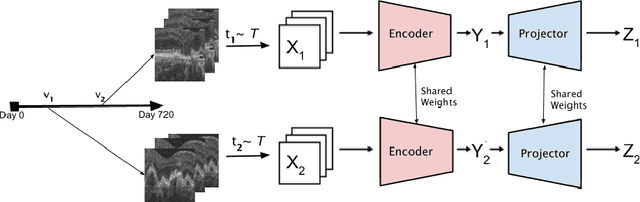

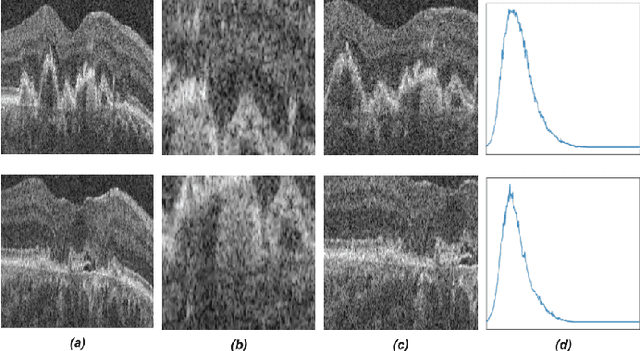

Recent contrastive learning methods achieved state-of-the-art in low label regimes. However, the training requires large batch sizes and heavy augmentations to create multiple views of an image. With non-contrastive methods, the negatives are implicitly incorporated in the loss, allowing different images and modalities as pairs. Although the meta-information (i.e., age, sex) in medical imaging is abundant, the annotations are noisy and prone to class imbalance. In this work, we exploited already existing temporal information (different visits from a patient) in a longitudinal optical coherence tomography (OCT) dataset using temporally informed non-contrastive loss (TINC) without increasing complexity and need for negative pairs. Moreover, our novel pair-forming scheme can avoid heavy augmentations and implicitly incorporates the temporal information in the pairs. Finally, these representations learned from the pretraining are more successful in predicting disease progression where the temporal information is crucial for the downstream task. More specifically, our model outperforms existing models in predicting the risk of conversion within a time frame from intermediate age-related macular degeneration (AMD) to the late wet-AMD stage.
Localizing the Recurrent Laryngeal Nerve via Ultrasound with a Bayesian Shape Framework
Jun 30, 2022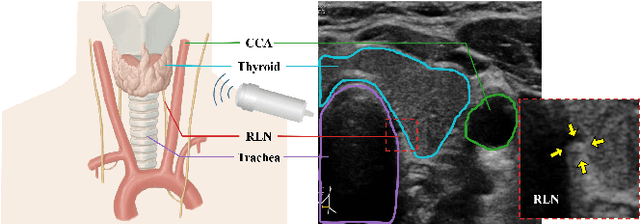
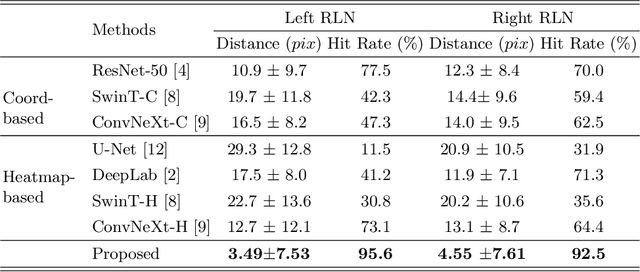
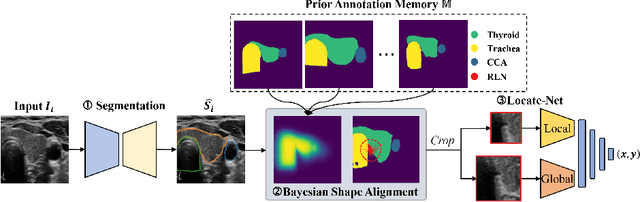
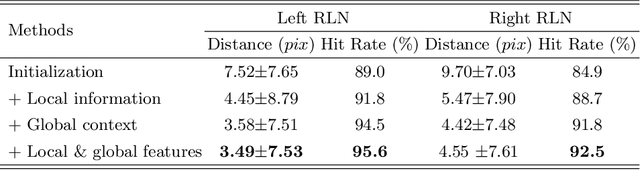
Tumor infiltration of the recurrent laryngeal nerve (RLN) is a contraindication for robotic thyroidectomy and can be difficult to detect via standard laryngoscopy. Ultrasound (US) is a viable alternative for RLN detection due to its safety and ability to provide real-time feedback. However, the tininess of the RLN, with a diameter typically less than 3mm, poses significant challenges to the accurate localization of the RLN. In this work, we propose a knowledge-driven framework for RLN localization, mimicking the standard approach surgeons take to identify the RLN according to its surrounding organs. We construct a prior anatomical model based on the inherent relative spatial relationships between organs. Through Bayesian shape alignment (BSA), we obtain the candidate coordinates of the center of a region of interest (ROI) that encloses the RLN. The ROI allows a decreased field of view for determining the refined centroid of the RLN using a dual-path identification network, based on multi-scale semantic information. Experimental results indicate that the proposed method achieves superior hit rates and substantially smaller distance errors compared with state-of-the-art methods.
CTrGAN: Cycle Transformers GAN for Gait Transfer
Jun 30, 2022
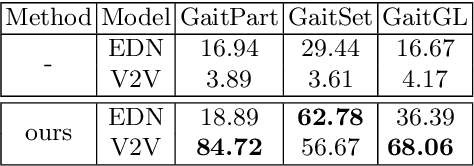
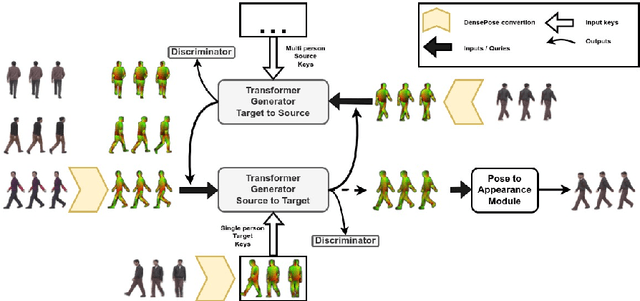
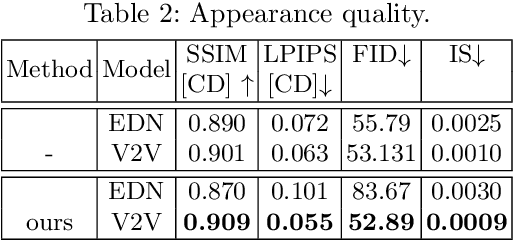
We attempt for the first time to address the problem of gait transfer. In contrast to motion transfer, the objective here is not to imitate the source's normal motions, but rather to transform the source's motion into a typical gait pattern for the target. Using gait recognition models, we demonstrate that existing techniques yield a discrepancy that can be easily detected. We introduce a novel model, Cycle Transformers GAN (CTrGAN), that can successfully generate the target's natural gait. CTrGAN's generators consist of a decoder and encoder, both Transformers, where the attention is on the temporal domain between complete images rather than the spatial domain between patches. While recent Transformer studies in computer vision mainly focused on discriminative tasks, we introduce an architecture that can be applied to synthesis tasks. Using a widely-used gait recognition dataset, we demonstrate that our approach is capable of producing over an order of magnitude more realistic personalized gaits than existing methods, even when used with sources that were not available during training.
Deep Transformer Model with Pre-Layer Normalization for COVID-19 Growth Prediction
Jul 10, 2022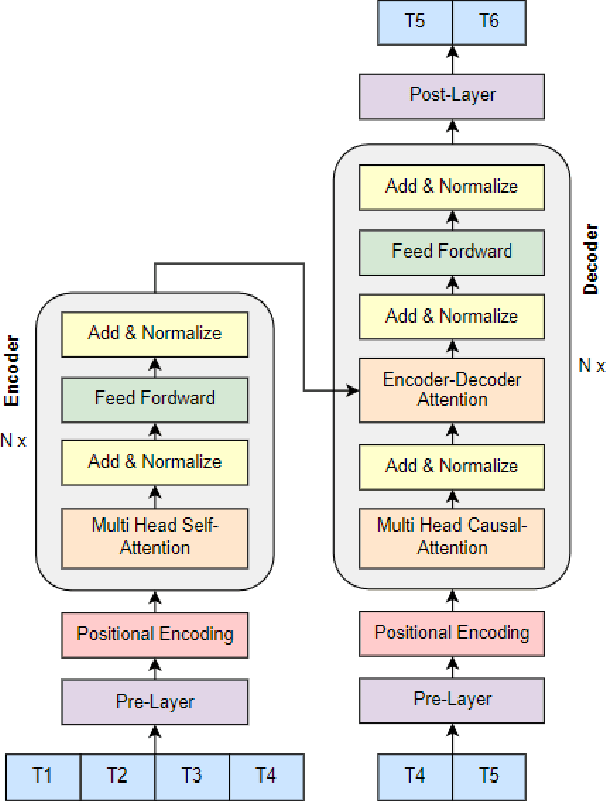
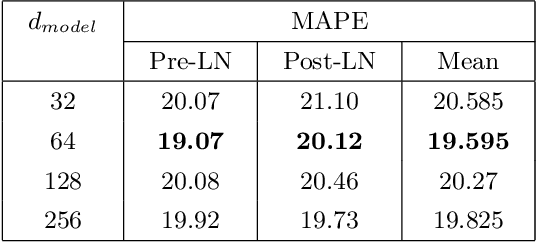
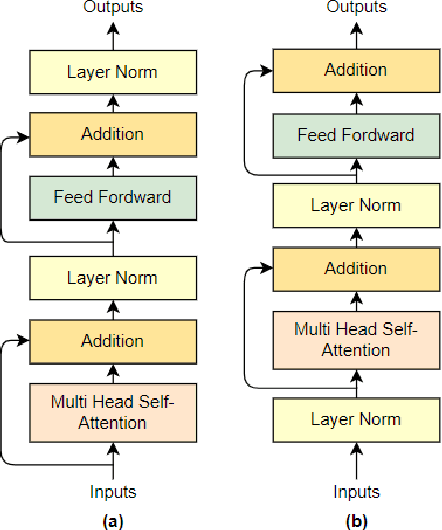
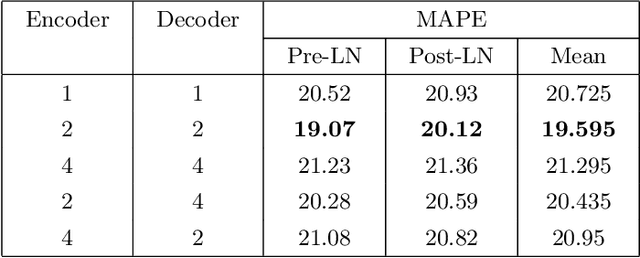
Coronavirus disease or COVID-19 is an infectious disease caused by the SARS-CoV-2 virus. The first confirmed case caused by this virus was found at the end of December 2019 in Wuhan City, China. This case then spread throughout the world, including Indonesia. Therefore, the COVID-19 case was designated as a global pandemic by WHO. The growth of COVID-19 cases, especially in Indonesia, can be predicted using several approaches, such as the Deep Neural Network (DNN). One of the DNN models that can be used is Deep Transformer which can predict time series. The model is trained with several test scenarios to get the best model. The evaluation is finding the best hyperparameters. Then, further evaluation was carried out using the best hyperparameters setting of the number of prediction days, the optimizer, the number of features, and comparison with the former models of the Long Short-Term Memory (LSTM) and Recurrent Neural Network (RNN). All evaluations used metric of the Mean Absolute Percentage Error (MAPE). Based on the results of the evaluations, Deep Transformer produces the best results when using the Pre-Layer Normalization and predicting one day ahead with a MAPE value of 18.83. Furthermore, the model trained with the Adamax optimizer obtains the best performance among other tested optimizers. The performance of the Deep Transformer also exceeds other test models, which are LSTM and RNN.
Deep learning pipeline for image classification on mobile phones
May 31, 2022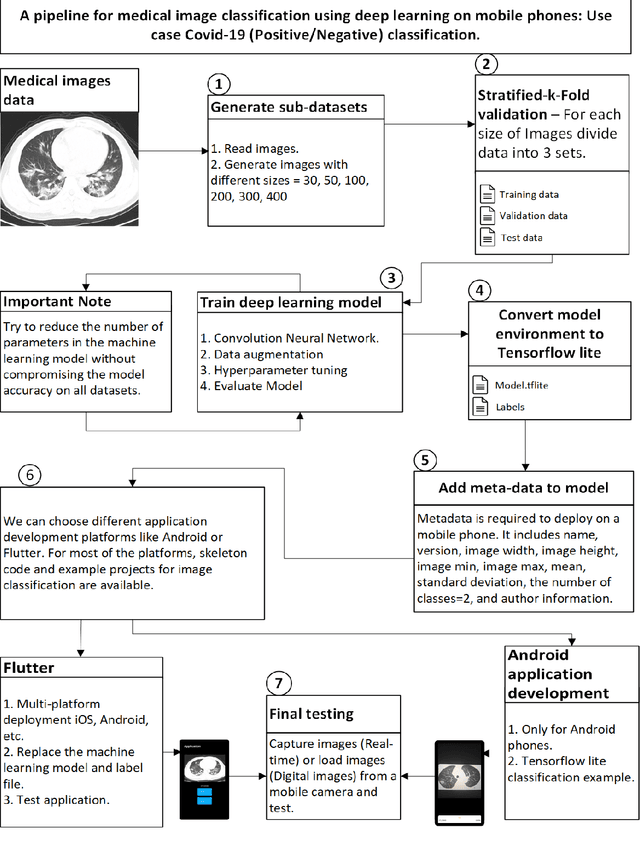
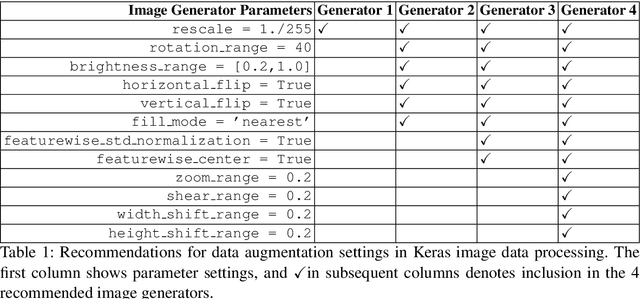
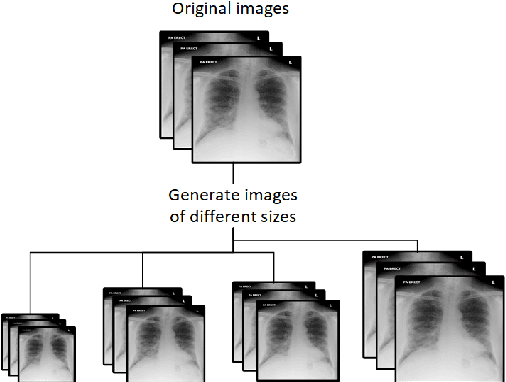
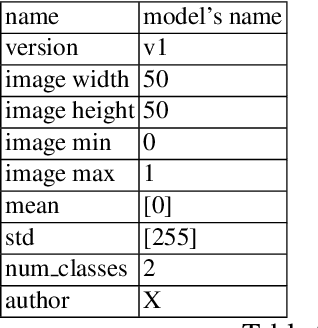
This article proposes and documents a machine-learning framework and tutorial for classifying images using mobile phones. Compared to computers, the performance of deep learning model performance degrades when deployed on a mobile phone and requires a systematic approach to find a model that performs optimally on both computers and mobile phones. By following the proposed pipeline, which consists of various computational tools, simple procedural recipes, and technical considerations, one can bring the power of deep learning medical image classification to mobile devices, potentially unlocking new domains of applications. The pipeline is demonstrated on four different publicly available datasets: COVID X-rays, COVID CT scans, leaves, and colorectal cancer. We used two application development frameworks: TensorFlow Lite (real-time testing) and Flutter (digital image testing) to test the proposed pipeline. We found that transferring deep learning models to a mobile phone is limited by hardware and classification accuracy drops. To address this issue, we proposed this pipeline to find an optimized model for mobile phones. Finally, we discuss additional applications and computational concerns related to deploying deep-learning models on phones, including real-time analysis and image preprocessing. We believe the associated documentation and code can help physicians and medical experts develop medical image classification applications for distribution.
* 20 pages
An Innovative Attack Modelling and Attack Detection Approach for a Waiting Time-based Adaptive Traffic Signal Controller
Aug 19, 2021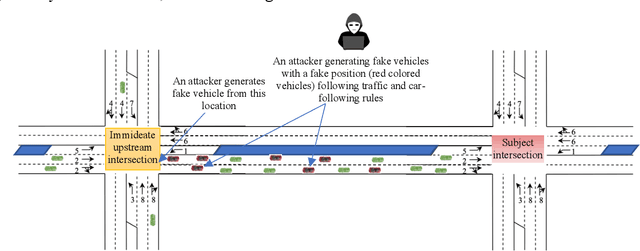

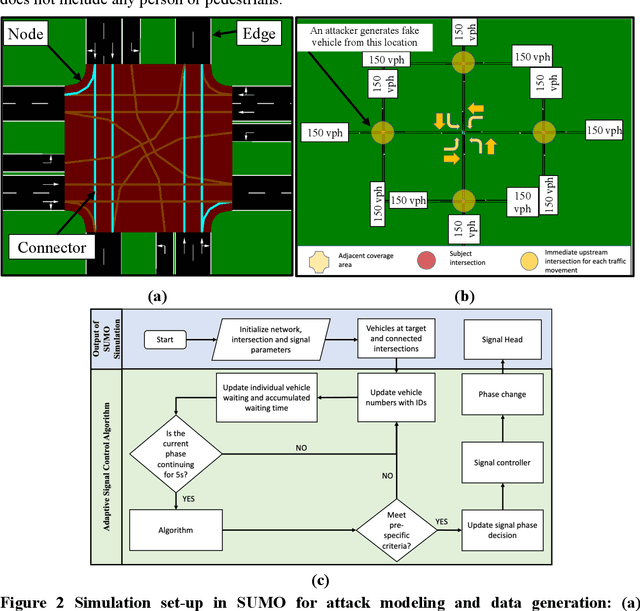
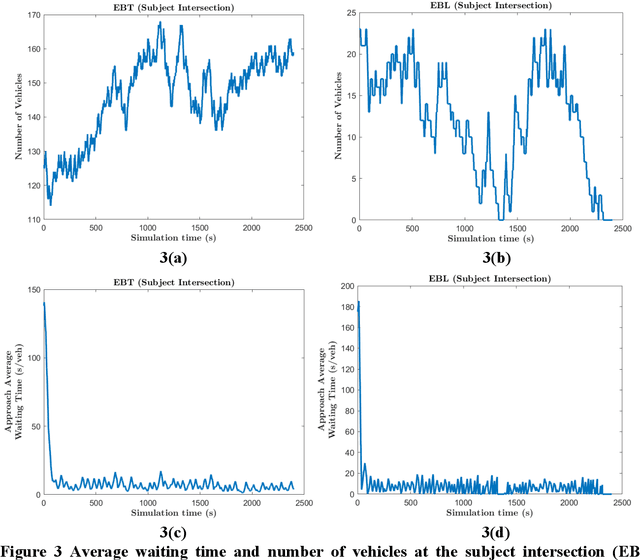
An adaptive traffic signal controller (ATSC) combined with a connected vehicle (CV) concept uses real-time vehicle trajectory data to regulate green time and has the ability to reduce intersection waiting time significantly and thereby improve travel time in a signalized corridor. However, the CV-based ATSC increases the size of the surface vulnerable to potential cyber-attack, allowing an attacker to generate disastrous traffic congestion in a roadway network. An attacker can congest a route by generating fake vehicles by maintaining traffic and car-following rules at a slow rate so that the signal timing and phase change without having any abrupt changes in number of vehicles. Because of the adaptive nature of ATSC, it is a challenge to model this kind of attack and also to develop a strategy for detection. This paper introduces an innovative "slow poisoning" cyberattack for a waiting time based ATSC algorithm and a corresponding detection strategy. Thus, the objectives of this paper are to: (i) develop a "slow poisoning" attack generation strategy for an ATSC, and (ii) develop a prediction-based "slow poisoning" attack detection strategy using a recurrent neural network -- i.e., long short-term memory model. We have generated a "slow poisoning" attack modeling strategy using a microscopic traffic simulator -- Simulation of Urban Mobility (SUMO) -- and used generated data from the simulation to develop both the attack model and detection model. Our analyses revealed that the attack strategy is effective in creating a congestion in an approach and detection strategy is able to flag the attack.