 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DDKtor: Automatic Diadochokinetic Speech Analysis
Jun 29, 2022
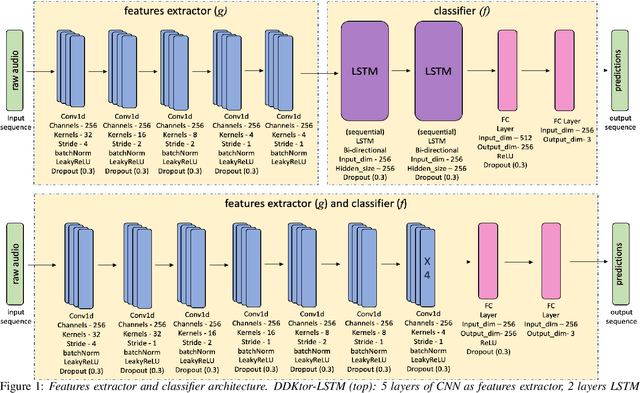
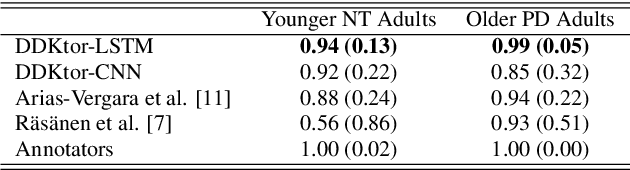
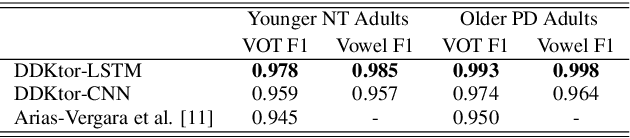
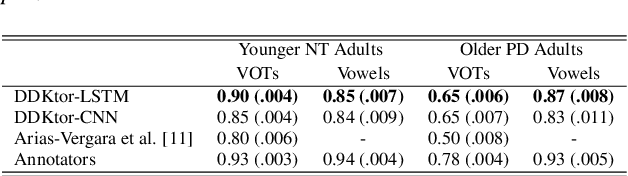
Diadochokinetic speech tasks (DDK), in which participants repeatedly produce syllables, are commonly used as part of the assessment of speech motor impairments. These studies rely on manual analyses that are time-intensive, subjective, and provide only a coarse-grained picture of speech. This paper presents two deep neural network models that automatically segment consonants and vowels from unannotated, untranscribed speech. Both models work on the raw waveform and use convolutional layers for feature extraction. The first model is based on an LSTM classifier followed by fully connected layers, while the second model adds more convolutional layers followed by fully connected layers. These segmentations predicted by the models are used to obtain measures of speech rate and sound duration. Results on a young healthy individuals dataset show that our LSTM model outperforms the current state-of-the-art systems and performs comparably to trained human annotators. Moreover, the LSTM model also presents comparable results to trained human annotators when evaluated on unseen older individuals with Parkinson's Disease dataset.
Human-Robot Handovers using Task-Space Quadratic Programming
Jun 18, 2022
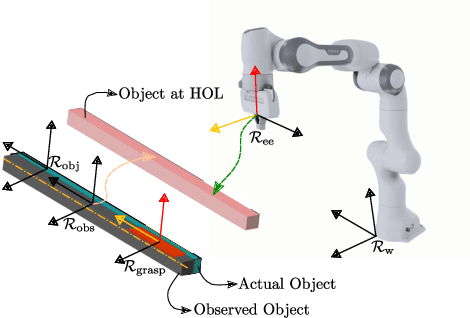

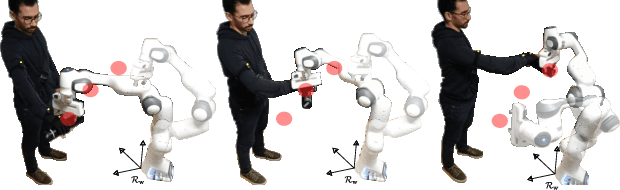
Bidirectional object handover between a human and a robot enables an important functionality skill in robotic human-centered manufacturing or services. The problem in achieving this skill lies in the capacity of any solution to deal with three important aspects: (i) synchronized timing for the handing over phases; (ii) the handling of object pose constraints; and (iii) understanding the haptic exchanging to seamlessly achieve some steps of the (i). We propose a new approach for (i) and (ii) consisting in explicitly formulating the handover process as constraints in a task-space quadratic programming control framework to achieve implicit time and trajectory encounters. Our method is implemented on Panda robotic arm taking objects from a human operator.
PD/EUP Workshop Proceedings
Jul 15, 2022People who need robots are often not the same as people who can program them. This key observation in human-robot interaction (HRI) has lead to a number of challenges when developing robotic applications, since developers must understand the exact needs of end-users. Participatory Design (PD), the process of including stakeholders such as end users early in the robot design process, has been used with noteworthy success in HRI, but typically remains limited to the early phases of development. Resulting robot behaviors are often then hardcoded by engineers or utilized in Wizard-of-Oz (WoZ) systems that rarely achieve autonomy. End-User Programming (EUP), i.e., the research of tools allowing end users with limited computer knowledge to program systems, has been widely applied to the design of robot behaviors for interaction with humans, but these tools risk being used solely as research demonstrations only existing for the amount of time required for them to be evaluated and published. In the PD/EUP Workshop, we aim to facilitate mutual learning between these communities and to create communication opportunities that could help the larger HRI community work towards end-user personalized and adaptable interactions. Both PD and EUP will be key requirements if we want robots to be useful for wider society. From this workshop, we expect new collaboration opportunities to emerge and we aim to formalize new methodologies that integrate PD and EUP approaches.
3DVerifier: Efficient Robustness Verification for 3D Point Cloud Models
Jul 15, 2022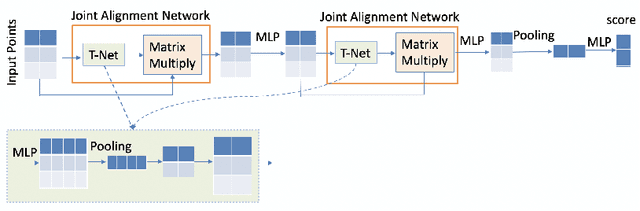
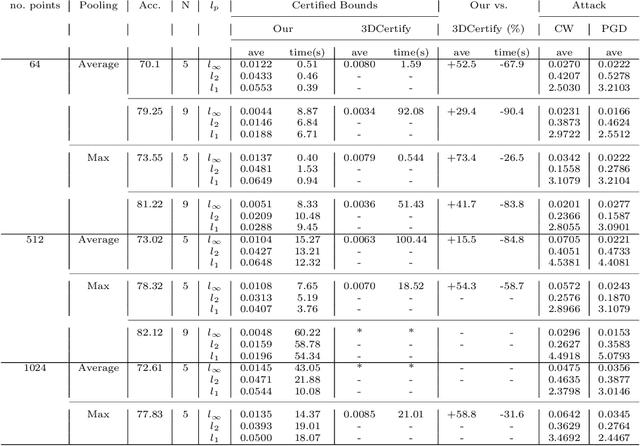

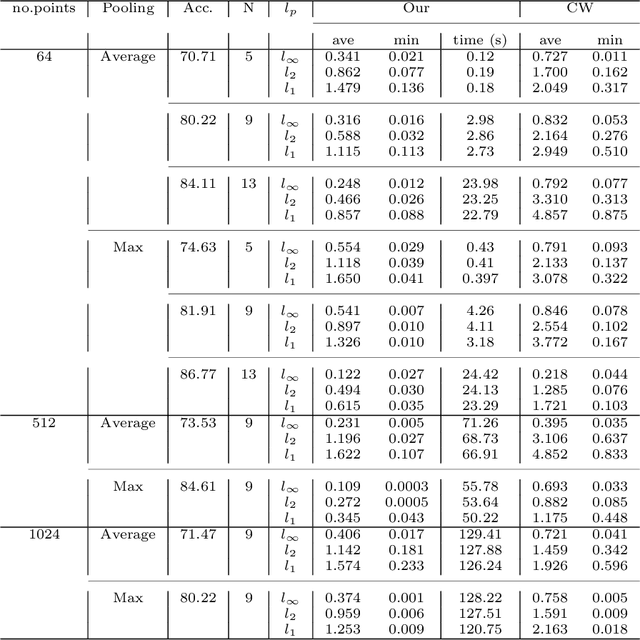
3D point cloud models are widely applied in safety-critical scenes, which delivers an urgent need to obtain more solid proofs to verify the robustness of models. Existing verification method for point cloud model is time-expensive and computationally unattainable on large networks. Additionally, they cannot handle the complete PointNet model with joint alignment network (JANet) that contains multiplication layers, which effectively boosts the performance of 3D models. This motivates us to design a more efficient and general framework to verify various architectures of point cloud models. The key challenges in verifying the large-scale complete PointNet models are addressed as dealing with the cross-non-linearity operations in the multiplication layers and the high computational complexity of high-dimensional point cloud inputs and added layers. Thus, we propose an efficient verification framework, 3DVerifier, to tackle both challenges by adopting a linear relaxation function to bound the multiplication layer and combining forward and backward propagation to compute the certified bounds of the outputs of the point cloud models. Our comprehensive experiments demonstrate that 3DVerifier outperforms existing verification algorithms for 3D models in terms of both efficiency and accuracy. Notably, our approach achieves an orders-of-magnitude improvement in verification efficiency for the large network, and the obtained certified bounds are also significantly tighter than the state-of-the-art verifiers. We release our tool 3DVerifier via https://github.com/TrustAI/3DVerifier for use by the community.
Wayformer: Motion Forecasting via Simple & Efficient Attention Networks
Jul 12, 2022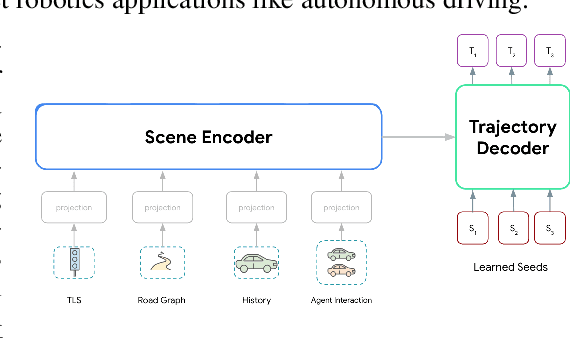
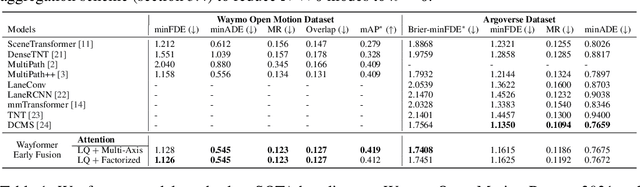
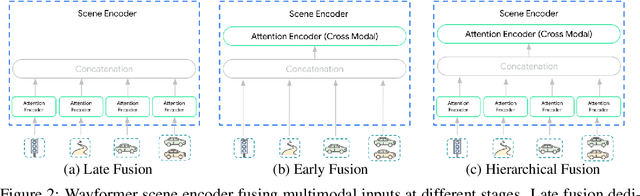
Motion forecasting for autonomous driving is a challenging task because complex driving scenarios result in a heterogeneous mix of static and dynamic inputs. It is an open problem how best to represent and fuse information about road geometry, lane connectivity, time-varying traffic light state, and history of a dynamic set of agents and their interactions into an effective encoding. To model this diverse set of input features, many approaches proposed to design an equally complex system with a diverse set of modality specific modules. This results in systems that are difficult to scale, extend, or tune in rigorous ways to trade off quality and efficiency. In this paper, we present Wayformer, a family of attention based architectures for motion forecasting that are simple and homogeneous. Wayformer offers a compact model description consisting of an attention based scene encoder and a decoder. In the scene encoder we study the choice of early, late and hierarchical fusion of the input modalities. For each fusion type we explore strategies to tradeoff efficiency and quality via factorized attention or latent query attention. We show that early fusion, despite its simplicity of construction, is not only modality agnostic but also achieves state-of-the-art results on both Waymo Open MotionDataset (WOMD) and Argoverse leaderboards, demonstrating the effectiveness of our design philosophy
Group-Theoretic Wideband Radar Waveform Design
Jul 03, 2022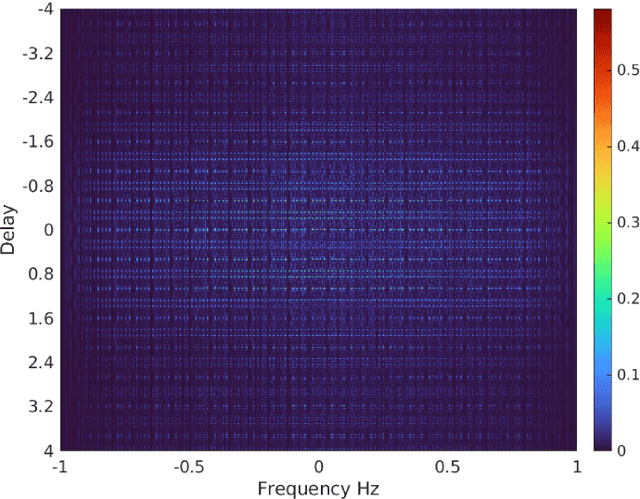
We investigate the theory of affine groups in the context of designing radar waveforms that obey the desired wideband ambiguity function (WAF). The WAF is obtained by correlating the signal with its time-dilated, Doppler-shifted, and delayed replicas. We consider the WAF definition as a coefficient function of the unitary representation of the group $a\cdot x + b$. This is essentially an algebraic problem applied to the radar waveform design. Prior works on this subject largely analyzed narrow-band ambiguity functions. Here, we show that when the underlying wideband signal of interest is a pulse or pulse train, a tight frame can be built to design that waveform. Specifically, we design the radar signals by minimizing the ratio of bounding constants of the frame in order to obtain lower sidelobes in the WAF. This minimization is performed by building a codebook based on difference sets in order to achieve the Welch bound. We show that the tight frame so obtained is connected with the wavelet transform that defines the WAF.
An adaptive admittance controller for collaborative drilling with a robot based on subtask classification via deep learning
May 31, 2022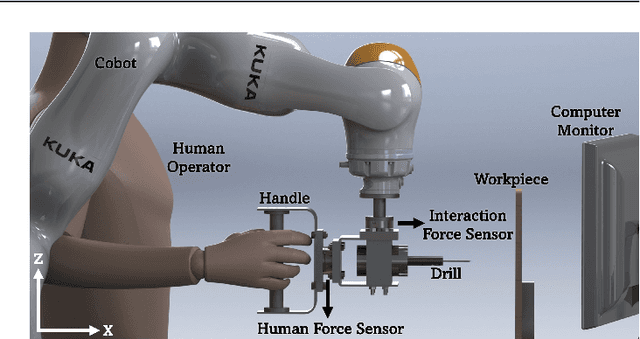
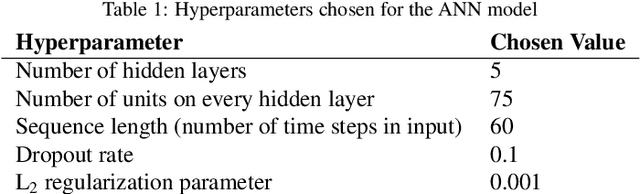
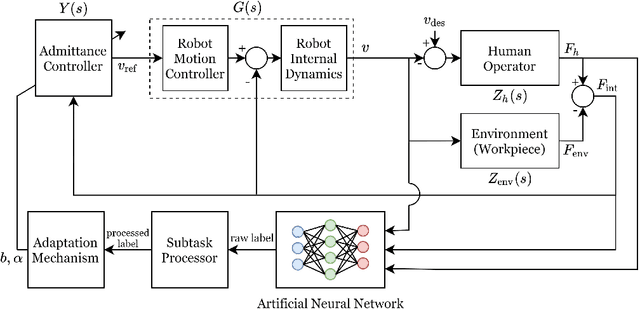
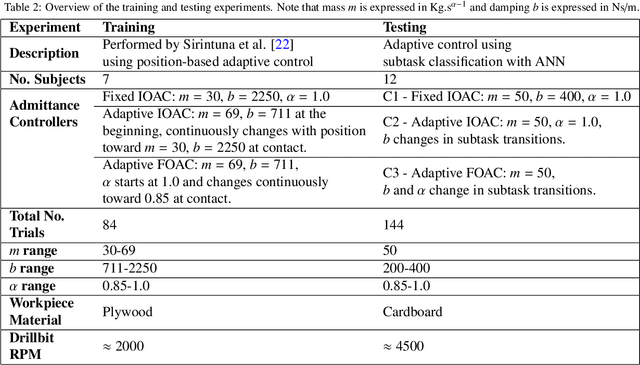
In this paper, we propose a supervised learning approach based on an Artificial Neural Network (ANN) model for real-time classification of subtasks in a physical human-robot interaction (pHRI) task involving contact with a stiff environment. In this regard, we consider three subtasks for a given pHRI task: Idle, Driving, and Contact. Based on this classification, the parameters of an admittance controller that regulates the interaction between human and robot are adjusted adaptively in real time to make the robot more transparent to the operator (i.e. less resistant) during the Driving phase and more stable during the Contact phase. The Idle phase is primarily used to detect the initiation of task. Experimental results have shown that the ANN model can learn to detect the subtasks under different admittance controller conditions with an accuracy of 98% for 12 participants. Finally, we show that the admittance adaptation based on the proposed subtask classifier leads to 20% lower human effort (i.e. higher transparency) in the Driving phase and 25% lower oscillation amplitude (i.e. higher stability) during drilling in the Contact phase compared to an admittance controller with fixed parameters.
Real-time Semantic 3D Dense Occupancy Mapping with Efficient Free Space Representations
Jul 07, 2021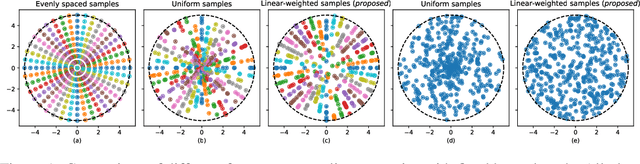

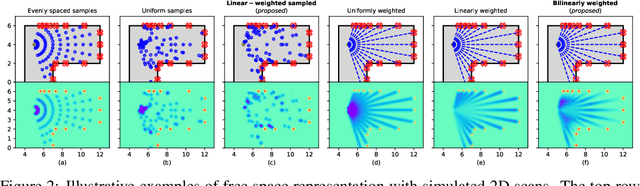
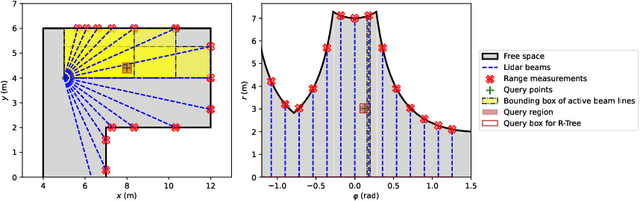
A real-time semantic 3D occupancy mapping framework is proposed in this paper. The mapping framework is based on the Bayesian kernel inference strategy from the literature. Two novel free space representations are proposed to efficiently construct training data and improve the mapping speed, which is a major bottleneck for real-world deployments. Our method achieves real-time mapping even on a consumer-grade CPU. Another important benefit is that our method can handle dynamic scenarios, thanks to the coverage completeness of the proposed algorithm. Experiments on real-world point cloud scan datasets are presented.
Augmented Imagefication: A Data-driven Fault Detection Method for Aircraft Air Data Sensors
Jun 18, 2022
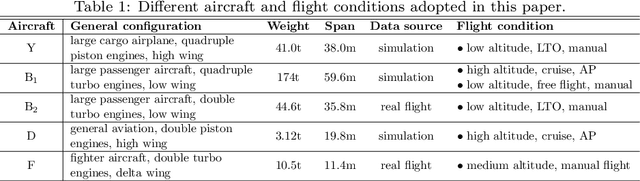
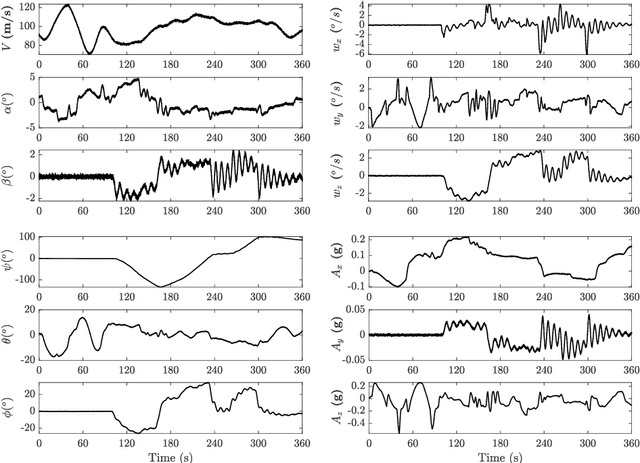

In this paper, a novel data-driven approach named Augmented Imagefication for Fault detection (FD) of aircraft air data sensors (ADS) is proposed. Exemplifying the FD problem of aircraft air data sensors, an online FD scheme on edge device based on deep neural network (DNN) is developed. First, the aircraft inertial reference unit measurements is adopted as equivalent inputs, which is scalable to different aircraft/flight cases. Data associated with 6 different aircraft/flight conditions are collected to provide diversity (scalability) in the training/testing database. Then Augmented Imagefication is proposed for the DNN-based prediction of flying conditions. The raw data are reshaped as a grayscale image for convolutional operation, and the necessity of augmentation is analyzed and pointed out. Different kinds of augmented method, i.e. Flip, Repeat, Tile and their combinations are discussed, the result shows that the All Repeat operation in both axes of image matrix leads to the best performance of DNN. The interpretability of DNN is studied based on Grad-CAM, which provide a better understanding and further solidifies the robustness of DNN. Next the DNN model, VGG-16 with augmented imagefication data is optimized for mobile hardware deployment. After pruning of DNN, a lightweight model (98.79% smaller than original VGG-16) with high accuracy (slightly up by 0.27%) and fast speed (time delay is reduced by 87.54%) is obtained. And the hyperparameters optimization of DNN based on TPE is implemented and the best combination of hyperparameters is determined (learning rate 0.001, iterative epochs 600, and batch size 100 yields the highest accuracy at 0.987). Finally, a online FD deployment based on edge device, Jetson Nano, is developed and the real time monitoring of aircraft is achieved. We believe that this method is instructive for addressing the FD problems in other similar fields.
A Temporally and Spatially Local Spike-based Backpropagation Algorithm to Enable Training in Hardware
Jul 20, 2022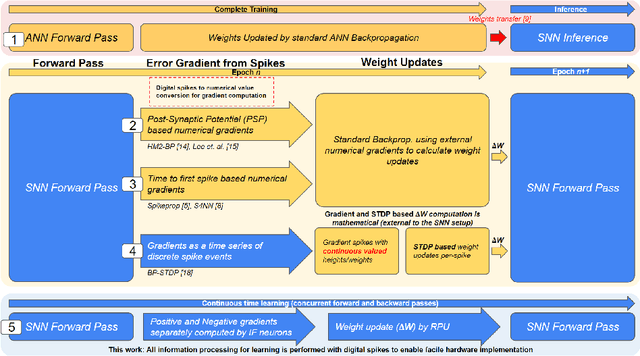
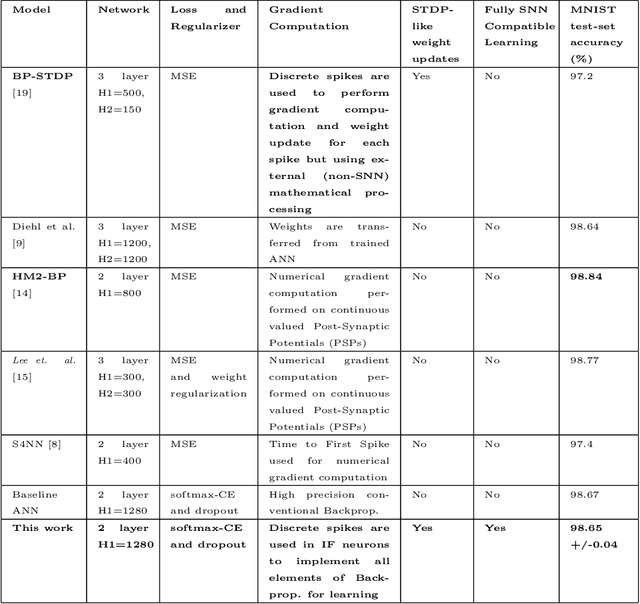
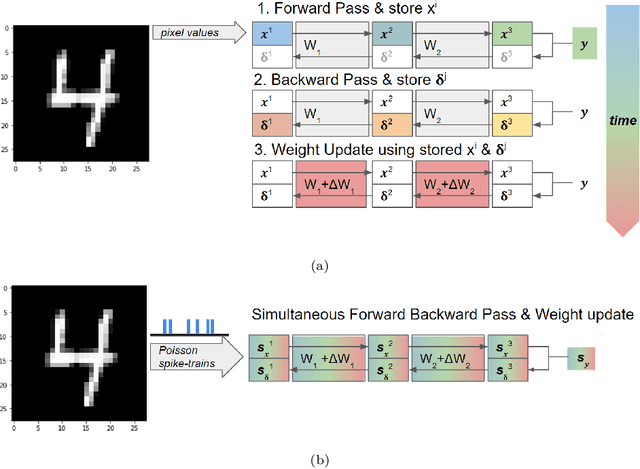
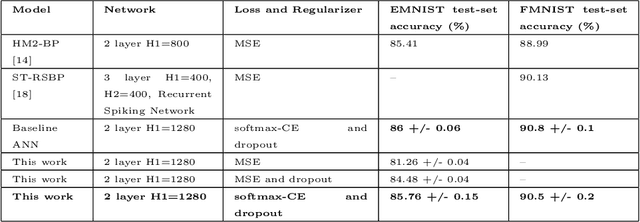
Spiking Neural Networks (SNNs) have emerged as a hardware efficient architecture for classification tasks. The penalty of spikes-based encoding has been the lack of a universal training mechanism performed entirely using spikes. There have been several attempts to adopt the powerful backpropagation (BP) technique used in non-spiking artificial neural networks (ANN): (1) SNNs can be trained by externally computed numerical gradients. (2) A major advancement toward native spike-based learning has been the use of approximate Backpropagation using spike-time-dependent plasticity (STDP) with phased forward/backward passes. However, the transfer of information between such phases necessitates external memory and computational access. This is a challenge for neuromorphic hardware implementations. In this paper, we propose a stochastic SNN-based Back-Prop (SSNN-BP) algorithm that utilizes a composite neuron to simultaneously compute the forward pass activations and backward pass gradients explicitly with spikes. Although signed gradient values are a challenge for spike-based representation, we tackle this by splitting the gradient signal into positive and negative streams. The composite neuron encodes information in the form of stochastic spike-trains and converts Backpropagation weight updates into temporally and spatially local discrete STDP-like spike coincidence updates compatible with hardware-friendly Resistive Processing Units (RPUs). Furthermore, our method approaches BP ANN baseline with sufficiently long spike-trains. Finally, we show that softmax cross-entropy loss function can be implemented through inhibitory lateral connections enforcing a Winner Take All (WTA) rule. Our SNN shows excellent generalization through comparable performance to ANNs on the MNIST, Fashion-MNIST and Extended MNIST datasets. Thus, SSNN-BP enables BP compatible with purely spike-based neuromorphic hardware.