 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmploying self-supervised learning models for cross-linguistic child speech maturity classification
Jun 10, 2025



Speech technology systems struggle with many downstream tasks for child speech due to small training corpora and the difficulties that child speech pose. We apply a novel dataset, SpeechMaturity, to state-of-the-art transformer models to address a fundamental classification task: identifying child vocalizations. Unlike previous corpora, our dataset captures maximally ecologically-valid child vocalizations across an unprecedented sample, comprising children acquiring 25+ languages in the U.S., Bolivia, Vanuatu, Papua New Guinea, Solomon Islands, and France. The dataset contains 242,004 labeled vocalizations, magnitudes larger than previous work. Models were trained to distinguish between cry, laughter, mature (consonant+vowel), and immature speech (just consonant or vowel). Models trained on the dataset outperform state-of-the-art models trained on previous datasets, achieved classification accuracy comparable to humans, and were robust across rural and urban settings.
DDKtor: Automatic Diadochokinetic Speech Analysis
Jun 29, 2022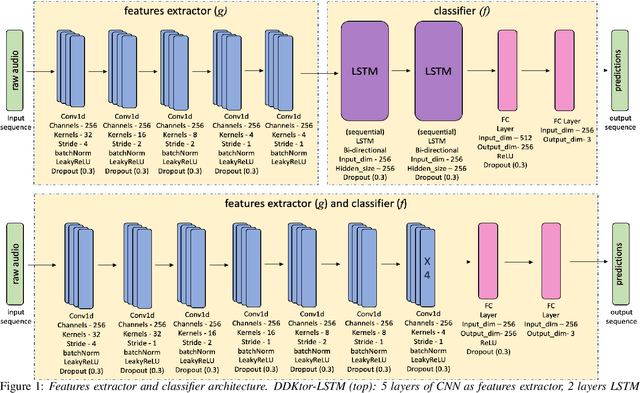
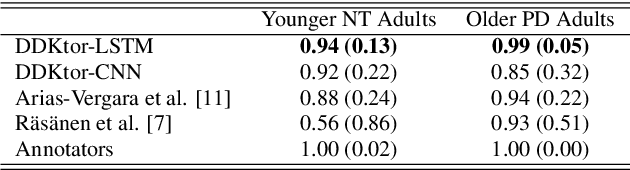
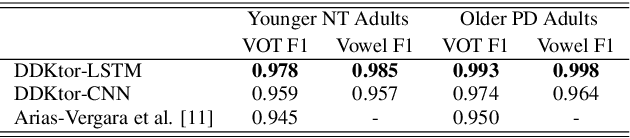
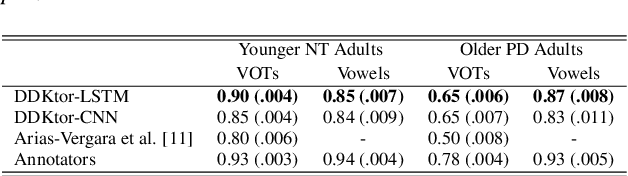
Diadochokinetic speech tasks (DDK), in which participants repeatedly produce syllables, are commonly used as part of the assessment of speech motor impairments. These studies rely on manual analyses that are time-intensive, subjective, and provide only a coarse-grained picture of speech. This paper presents two deep neural network models that automatically segment consonants and vowels from unannotated, untranscribed speech. Both models work on the raw waveform and use convolutional layers for feature extraction. The first model is based on an LSTM classifier followed by fully connected layers, while the second model adds more convolutional layers followed by fully connected layers. These segmentations predicted by the models are used to obtain measures of speech rate and sound duration. Results on a young healthy individuals dataset show that our LSTM model outperforms the current state-of-the-art systems and performs comparably to trained human annotators. Moreover, the LSTM model also presents comparable results to trained human annotators when evaluated on unseen older individuals with Parkinson's Disease dataset.