 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-Aware Q-Networks: Resolving Temporal Irregularity for Deep Reinforcement Learning
May 06, 2021
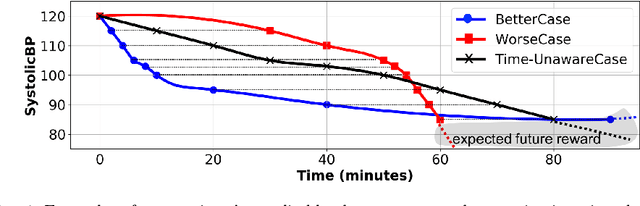
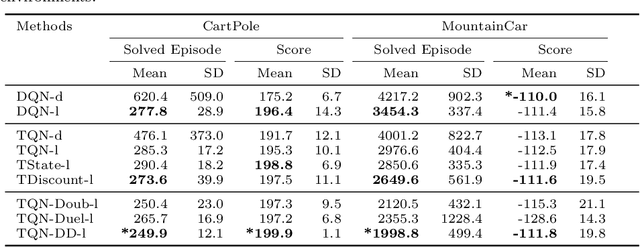
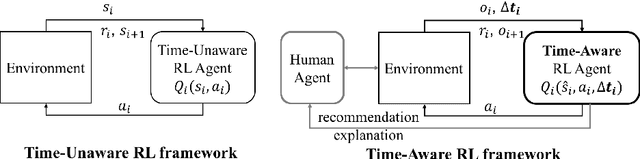
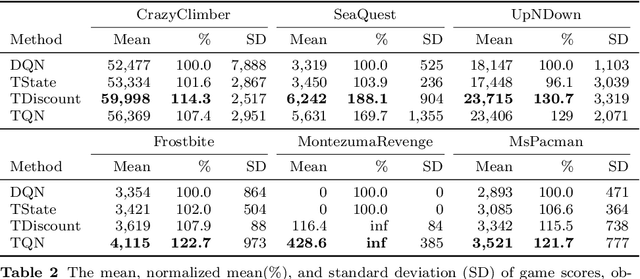
Deep Reinforcement Learning (DRL) has shown outstanding performance on inducing effective action policies that maximize expected long-term return on many complex tasks. Much of DRL work has been focused on sequences of events with discrete time steps and ignores the irregular time intervals between consecutive events. Given that in many real-world domains, data often consists of temporal sequences with irregular time intervals, and it is important to consider the time intervals between temporal events to capture latent progressive patterns of states. In this work, we present a general Time-Aware RL framework: Time-aware Q-Networks (TQN), which takes into account physical time intervals within a deep RL framework. TQN deals with time irregularity from two aspects: 1) elapsed time in the past and an expected next observation time for time-aware state approximation, and 2) action time window for the future for time-aware discounting of rewards. Experimental results show that by capturing the underlying structures in the sequences with time irregularities from both aspects, TQNs significantly outperform DQN in four types of contexts with irregular time intervals. More specifically, our results show that in classic RL tasks such as CartPole and MountainCar and Atari benchmark with randomly segmented time intervals, time-aware discounting alone is more important while in the real-world tasks such as nuclear reactor operation and septic patient treatment with intrinsic time intervals, both time-aware state and time-aware discounting are crucial. Moreover, to improve the agent's learning capacity, we explored three boosting methods: Double networks, Dueling networks, and Prioritized Experience Replay, and our results show that for the two real-world tasks, combining all three boosting methods with TQN is especially effective.
Implementing a Real-Time, YOLOv5 based Social Distancing Measuring System for Covid-19
Apr 07, 2022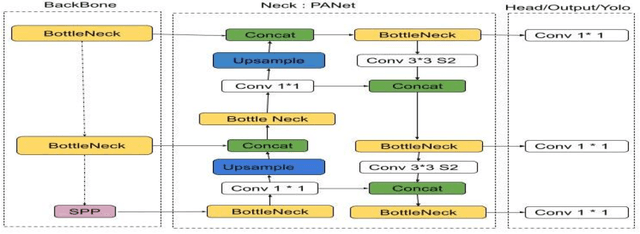

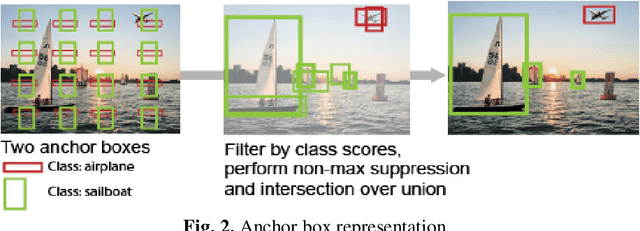
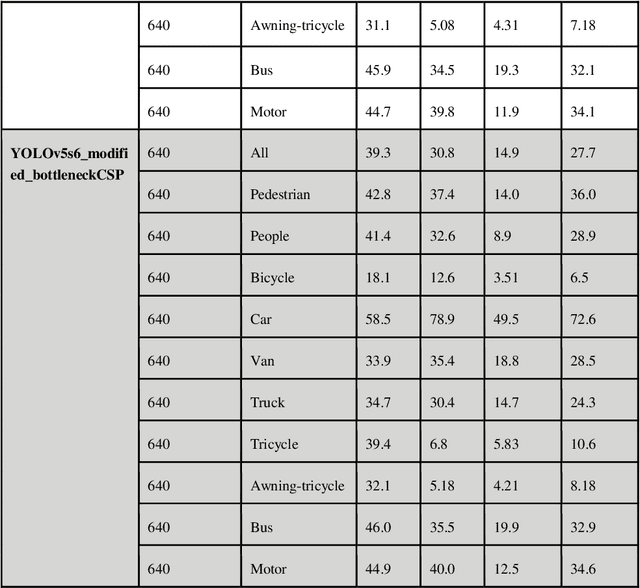
The purpose of this work is, to provide a YOLOv5 deep learning-based social distance monitoring framework using an overhead view perspective. In addition, we have developed a custom defined model YOLOv5 modified CSP (Cross Stage Partial Network) and assessed the performance on COCO and Visdrone dataset with and without transfer learning. Our findings show that the developed model successfully identifies the individual who violates the social distances. The accuracy of 81.7% for the modified bottleneck CSP without transfer learning is observed on COCO dataset after training the model for 300 epochs whereas for the same epochs, the default YOLOv5 model is attaining 80.1% accuracy with transfer learning. This shows an improvement in accuracy by our modified bottleneck CSP model. For the Visdrone dataset, we are able to achieve an accuracy of upto 56.5% for certain classes and especially an accuracy of 40% for people and pedestrians with transfer learning using the default YOLOv5s model for 30 epochs. While the modified bottleneck CSP is able to perform slightly better than the default model with an accuracy score of upto 58.1% for certain classes and an accuracy of ~40.4% for people and pedestrians.
Probabilistic forecasts of extreme heatwaves using convolutional neural networks in a regime of lack of data
Aug 01, 2022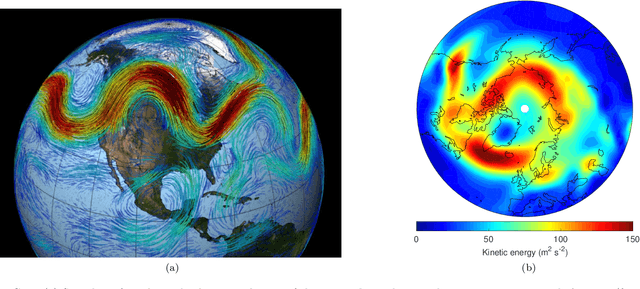
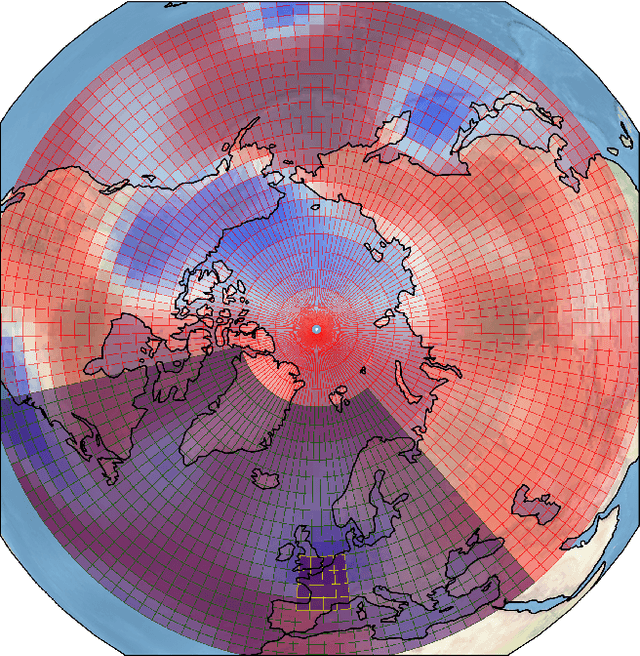
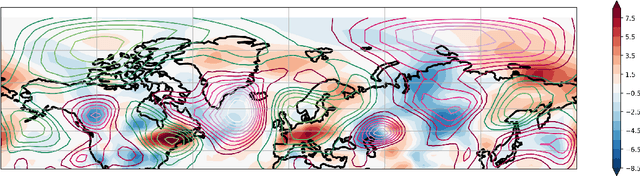
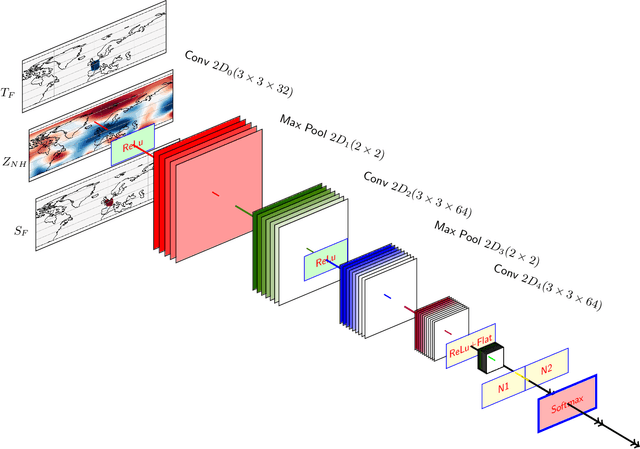
Understanding extreme events and their probability is key for the study of climate change impacts, risk assessment, adaptation, and the protection of living beings. In this work we develop a methodology to build forecasting models for extreme heatwaves. These models are based on convolutional neural networks, trained on extremely long 8,000-year climate model outputs. Because the relation between extreme events is intrinsically probabilistic, we emphasise probabilistic forecast and validation. We demonstrate that deep neural networks are suitable for this purpose for long lasting 14-day heatwaves over France, up to 15 days ahead of time for fast dynamical drivers (500 hPa geopotential height fields), and also at much longer lead times for slow physical drivers (soil moisture). The method is easily implemented and versatile. We find that the deep neural network selects extreme heatwaves associated with a North-Hemisphere wavenumber-3 pattern. We find that the 2 meter temperature field does not contain any new useful statistical information for heatwave forecast, when added to the 500 hPa geopotential height and soil moisture fields. The main scientific message is that training deep neural networks for predicting extreme heatwaves occurs in a regime of drastic lack of data. We suggest that this is likely the case for most other applications to large scale atmosphere and climate phenomena. We discuss perspectives for dealing with the lack of data regime, for instance rare event simulations, and how transfer learning may play a role in this latter task.
Learning to Order for Inventory Systems with Lost Sales and Uncertain Supplies
Jul 10, 2022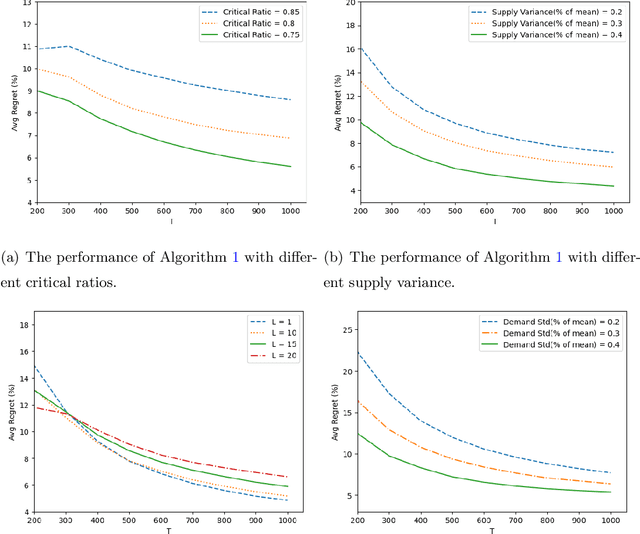
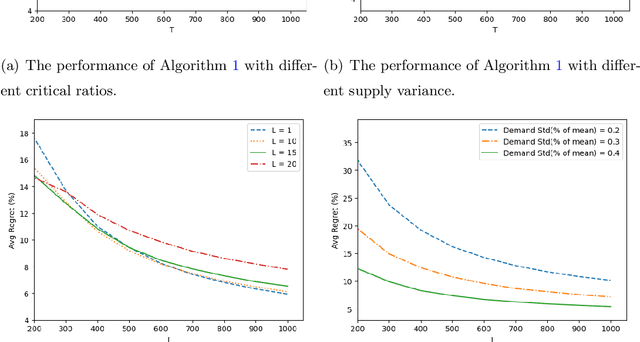
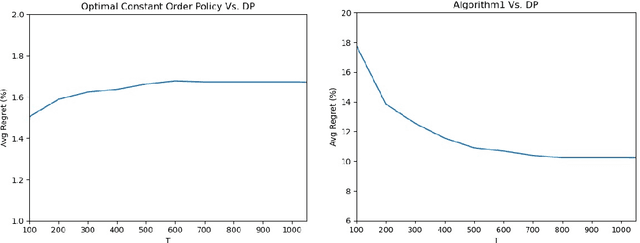
We consider a stochastic lost-sales inventory control system with a lead time $L$ over a planning horizon $T$. Supply is uncertain, and is a function of the order quantity (due to random yield/capacity, etc). We aim to minimize the $T$-period cost, a problem that is known to be computationally intractable even under known distributions of demand and supply. In this paper, we assume that both the demand and supply distributions are unknown and develop a computationally efficient online learning algorithm. We show that our algorithm achieves a regret (i.e. the performance gap between the cost of our algorithm and that of an optimal policy over $T$ periods) of $O(L+\sqrt{T})$ when $L\geq\log(T)$. We do so by 1) showing our algorithm cost is higher by at most $O(L+\sqrt{T})$ for any $L\geq 0$ compared to an optimal constant-order policy under complete information (a well-known and widely-used algorithm) and 2) leveraging its known performance guarantee from the existing literature. To the best of our knowledge, a finite-sample $O(\sqrt{T})$ (and polynomial in $L$) regret bound when benchmarked against an optimal policy is not known before in the online inventory control literature. A key challenge in this learning problem is that both demand and supply data can be censored; hence only truncated values are observable. We circumvent this challenge by showing that the data generated under an order quantity $q^2$ allows us to simulate the performance of not only $q^2$ but also $q^1$ for all $q^1<q^2$, a key observation to obtain sufficient information even under data censoring. By establishing a high probability coupling argument, we are able to evaluate and compare the performance of different order policies at their steady state within a finite time horizon. Since the problem lacks convexity, we develop an active elimination method that adaptively rules out suboptimal solutions.
Analysis of Kinetic Models for Label Switching and Stochastic Gradient Descent
Jul 01, 2022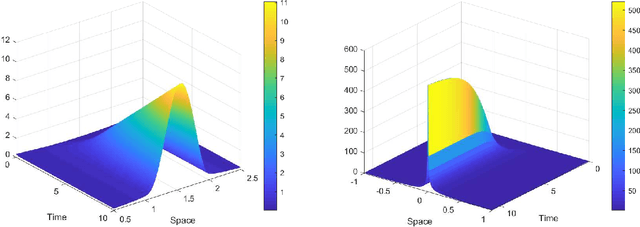
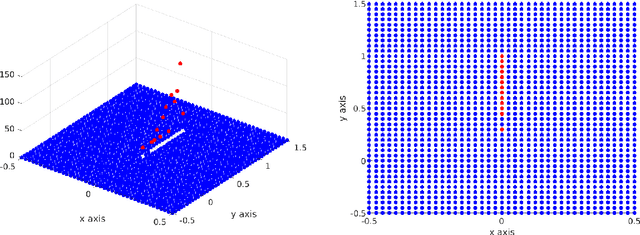
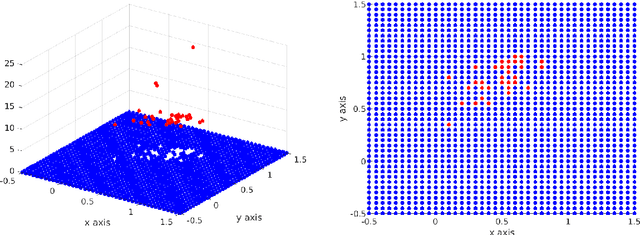
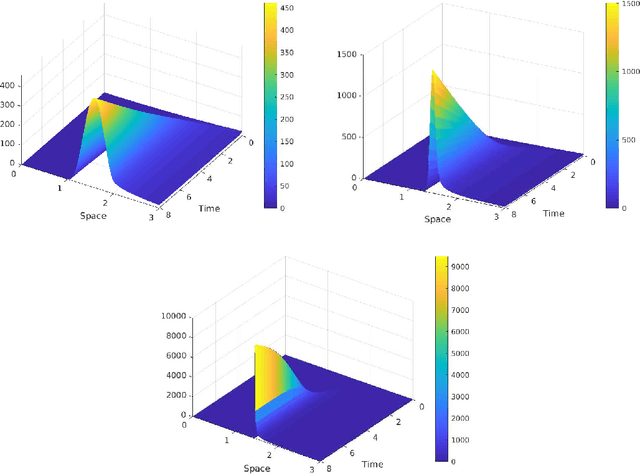
In this paper we provide a novel approach to the analysis of kinetic models for label switching, which are used for particle systems that can randomly switch between gradient flows in different energy landscapes. Besides problems in biology and physics, we also demonstrate that stochastic gradient descent, the most popular technique in machine learning, can be understood in this setting, when considering a time-continuous variant. Our analysis is focusing on the case of evolution in a collection of external potentials, for which we provide analytical and numerical results about the evolution as well as the stationary problem.
Efficient Distance-Optimal Tethered Path Planning in Planar Environments: The Workspace Convexity
Aug 08, 2022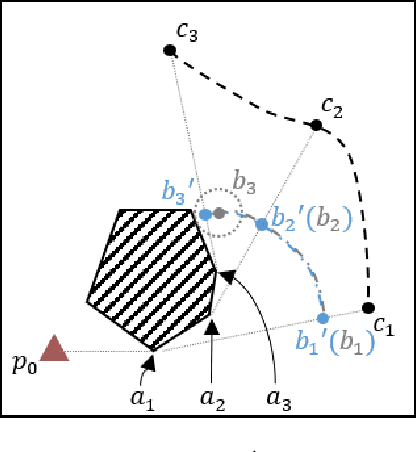
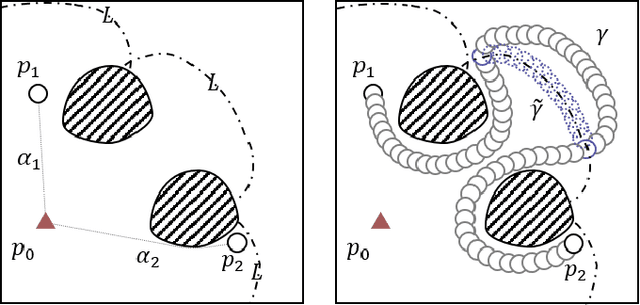
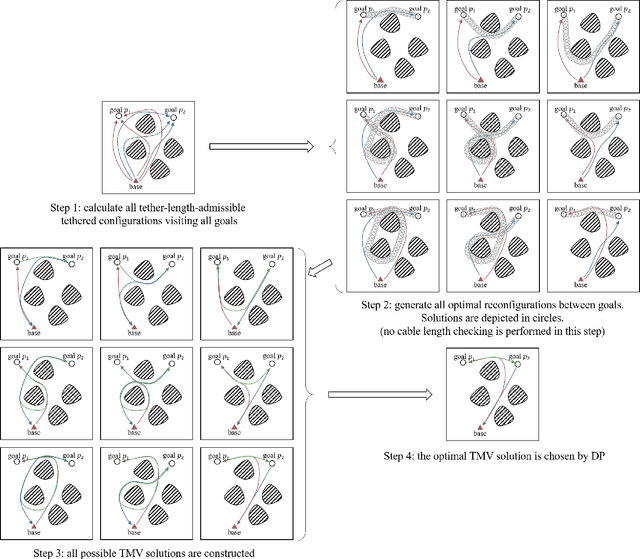
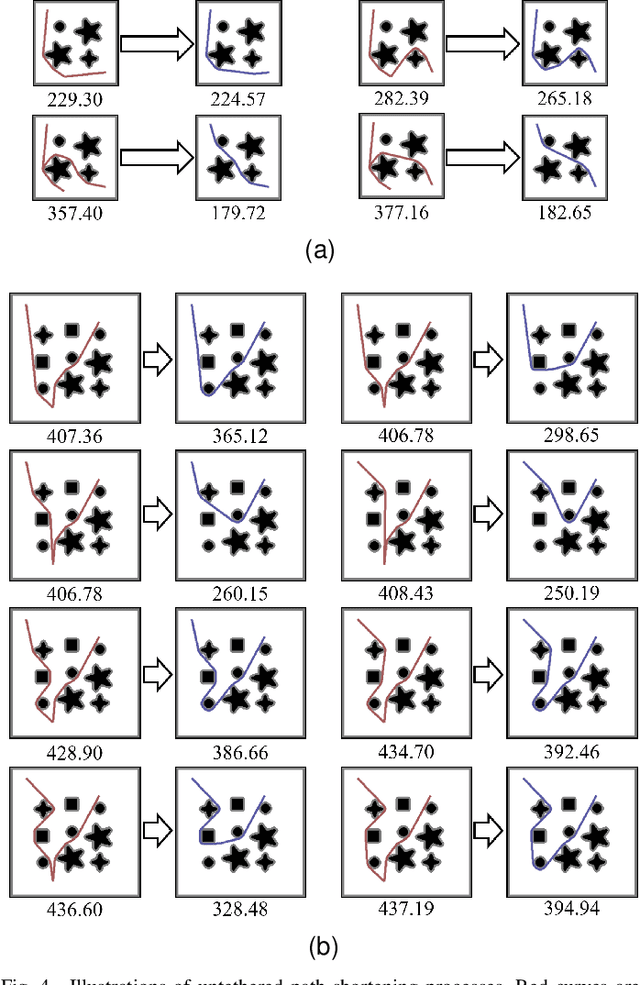
The main contribution of this paper is the proof of the convexity of the omni-directional tethered robot workspace (namely, the set of all tether-length-admissible robot configurations), as well as a set of distance-optimal tethered path planning algorithms that leverage the workspace convexity. The workspace is proven to be topologically a simply-connected subset and geometrically a convex subset of the set of all configurations. As a direct result, the tether-length-admissible optimal path between two configurations is proven exactly the untethered collision-free locally shortest path in the homotopy specified by the concatenation of the tether curve of the given configurations, which can be simply constructed by performing an untethered path shortening process in the 2D environment instead of a path searching process in the pre-calculated workspace. The convexity is an intrinsic property to the tethered robot kinematics, thus has universal impacts on all high-level distance-optimal tethered path planning tasks: The most time-consuming workspace pre-calculation (WP) process is replaced with a goal configuration pre-calculation (GCP) process, and the homotopy-aware path searching process is replaced with untethered path shortening processes. Motivated by the workspace convexity, efficient algorithms to solve the following problems are naturally proposed: (a) The optimal tethered reconfiguration (TR) planning problem is solved by a locally untethered path shortening (UPS) process, (b) The classic optimal tethered path (TP) planning problem (from a starting configuration to a goal location whereby the target tether state is not assigned) is solved by a GCP process and $n$ UPS processes, where $n$ is the number of tether-length-admissible configurations that visit the goal location, (c) The optimal tethered motion to visit a sequence of multiple goal locations, referred to as
Vers la compréhension automatique de la parole bout-en-bout à moindre effort
Jul 01, 2022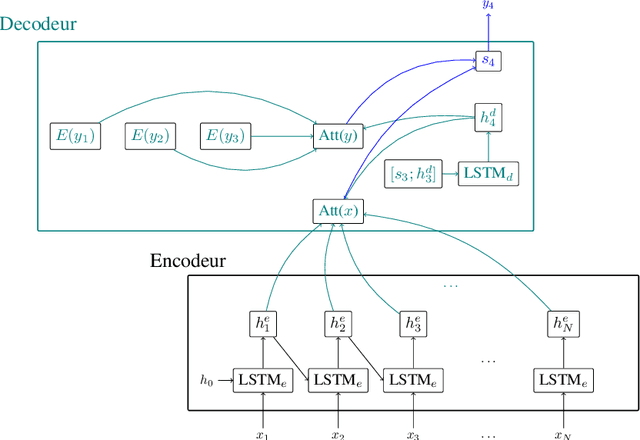
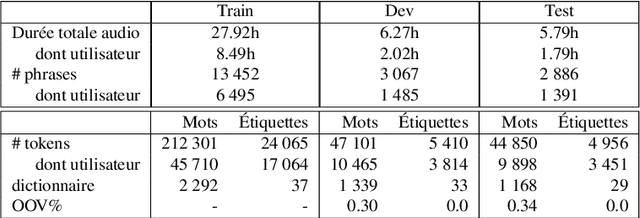
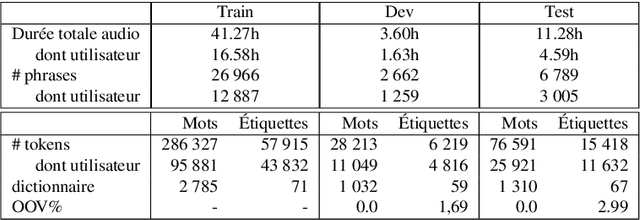
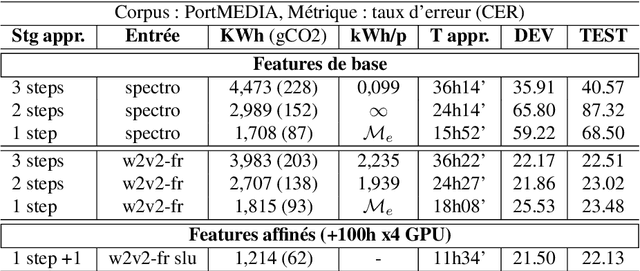
Recent advances in spoken language understanding benefited from Self-Supervised models trained on large speech corpora. For French, the LeBenchmark project has made such models available and has led to impressive progress on several tasks including spoken language understanding. These advances have a non-negligible cost in terms of computation time and energy consumption. In this paper, we compare several learning strategies aiming at reducing such cost while keeping competitive performances. The experiments are performed on the MEDIA corpus, and show that it is possible to reduce the learning cost while maintaining state-of-the-art performances.
SatMAE: Pre-training Transformers for Temporal and Multi-Spectral Satellite Imagery
Jul 17, 2022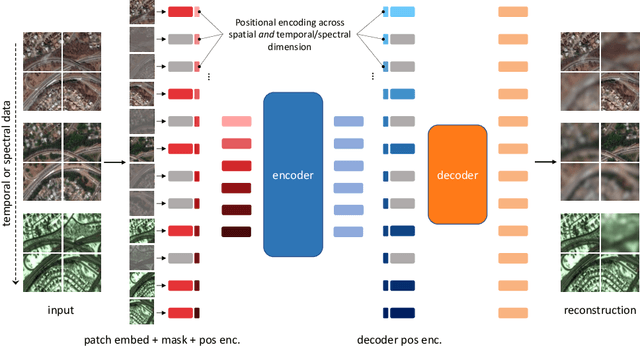

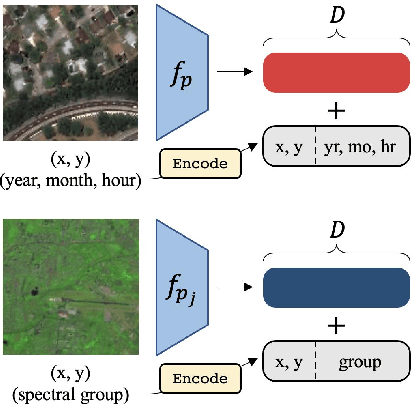
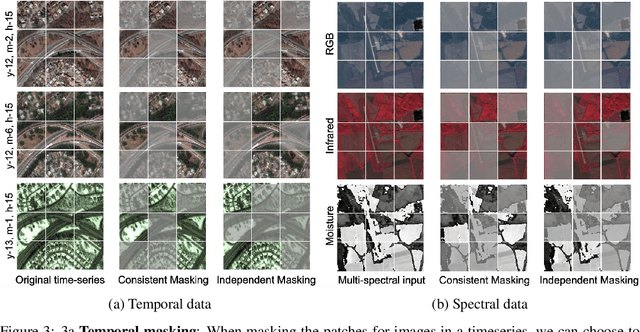
Unsupervised pre-training methods for large vision models have shown to enhance performance on downstream supervised tasks. Developing similar techniques for satellite imagery presents significant opportunities as unlabelled data is plentiful and the inherent temporal and multi-spectral structure provides avenues to further improve existing pre-training strategies. In this paper, we present SatMAE, a pre-training framework for temporal or multi-spectral satellite imagery based on Masked Autoencoder (MAE). To leverage temporal information, we include a temporal embedding along with independently masking image patches across time. In addition, we demonstrate that encoding multi-spectral data as groups of bands with distinct spectral positional encodings is beneficial. Our approach yields strong improvements over previous state-of-the-art techniques, both in terms of supervised learning performance on benchmark datasets (up to $\uparrow$ 7\%), and transfer learning performance on downstream remote sensing tasks, including land cover classification (up to $\uparrow$ 14\%) and semantic segmentation.
Real-time Attacks Against Deep Reinforcement Learning Policies
Jun 16, 2021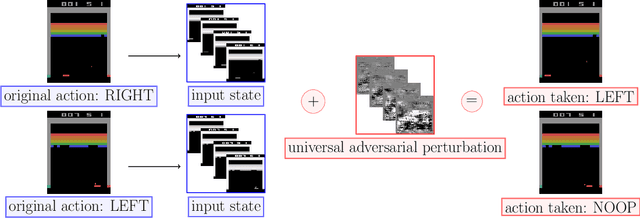
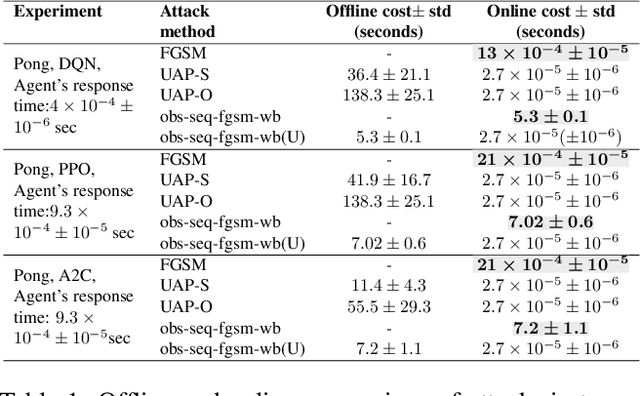
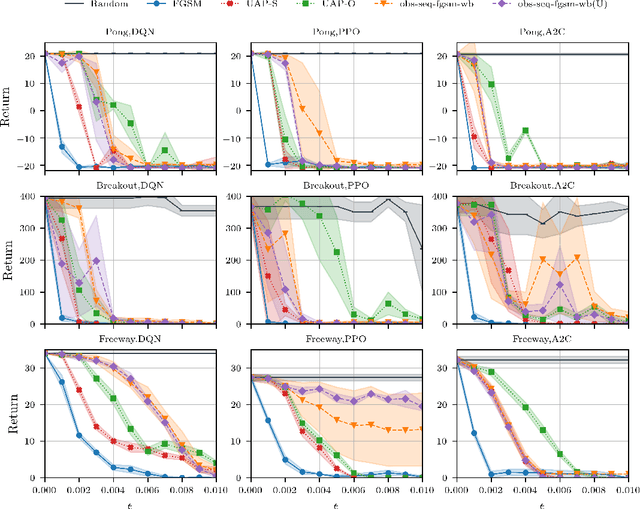

Recent work has discovered that deep reinforcement learning (DRL) policies are vulnerable to adversarial examples. These attacks mislead the policy of DRL agents by perturbing the state of the environment observed by agents. They are feasible in principle but too slow to fool DRL policies in real time. We propose a new attack to fool DRL policies that is both effective and efficient enough to be mounted in real time. We utilize the Universal Adversarial Perturbation (UAP) method to compute effective perturbations independent of the individual inputs to which they are applied. Via an extensive evaluation using Atari 2600 games, we show that our technique is effective, as it fully degrades the performance of both deterministic and stochastic policies (up to 100%, even when the $l_\infty$ bound on the perturbation is as small as 0.005). We also show that our attack is efficient, incurring an online computational cost of 0.027ms on average. It is faster compared to the response time (0.6ms on average) of agents with different DRL policies, and considerably faster than prior attacks (2.7ms on average). Furthermore, we demonstrate that known defenses are ineffective against universal perturbations. We propose an effective detection technique which can form the basis for robust defenses against attacks based on universal perturbations.
PI-ARS: Accelerating Evolution-Learned Visual-Locomotion with Predictive Information Representations
Jul 27, 2022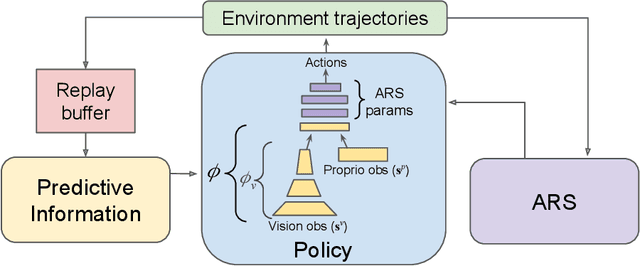

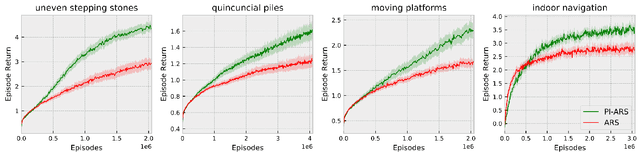

Evolution Strategy (ES) algorithms have shown promising results in training complex robotic control policies due to their massive parallelism capability, simple implementation, effective parameter-space exploration, and fast training time. However, a key limitation of ES is its scalability to large capacity models, including modern neural network architectures. In this work, we develop Predictive Information Augmented Random Search (PI-ARS) to mitigate this limitation by leveraging recent advancements in representation learning to reduce the parameter search space for ES. Namely, PI-ARS combines a gradient-based representation learning technique, Predictive Information (PI), with a gradient-free ES algorithm, Augmented Random Search (ARS), to train policies that can process complex robot sensory inputs and handle highly nonlinear robot dynamics. We evaluate PI-ARS on a set of challenging visual-locomotion tasks where a quadruped robot needs to walk on uneven stepping stones, quincuncial piles, and moving platforms, as well as to complete an indoor navigation task. Across all tasks, PI-ARS demonstrates significantly better learning efficiency and performance compared to the ARS baseline. We further validate our algorithm by demonstrating that the learned policies can successfully transfer to a real quadruped robot, for example, achieving a 100% success rate on the real-world stepping stone environment, dramatically improving prior results achieving 40% success.