 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PSA-GAN: Progressive Self Attention GANs for Synthetic Time Series
Aug 02, 2021
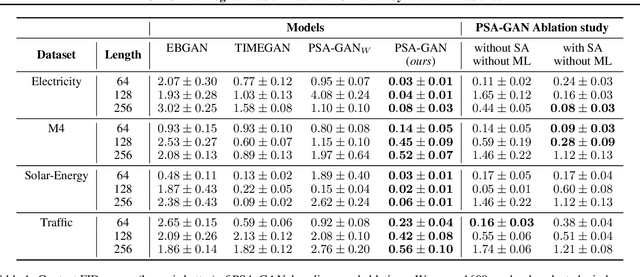

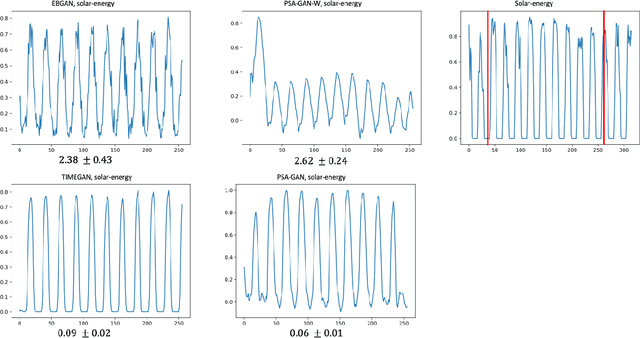
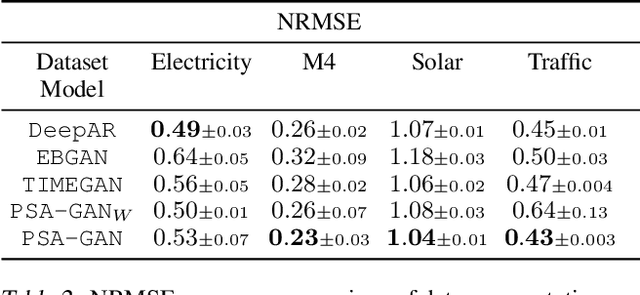
Realistic synthetic time series data of sufficient length enables practical applications in time series modeling tasks, such as forecasting, but remains a challenge. In this paper we present PSA-GAN, a generative adversarial network (GAN) that generates long time series samples of high quality using progressive growing of GANs and self-attention. We show that PSA-GAN can be used to reduce the error in two downstream forecasting tasks over baselines that only use real data. We also introduce a Frechet-Inception Distance-like score, Context-FID, assessing the quality of synthetic time series samples. In our downstream tasks, we find that the lowest scoring models correspond to the best-performing ones. Therefore, Context-FID could be a useful tool to develop time series GAN models.
Scalable Nanophotonic-Electronic Spiking Neural Networks
Aug 28, 2022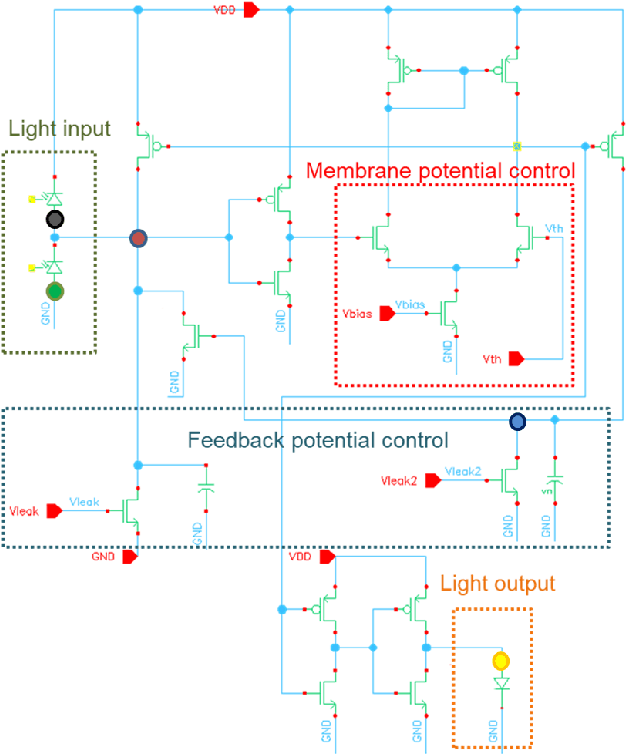
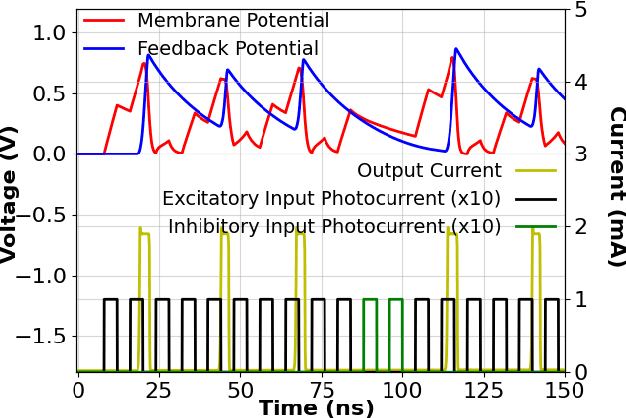
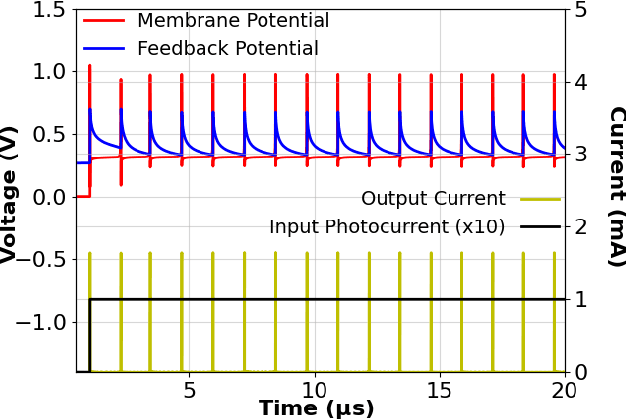
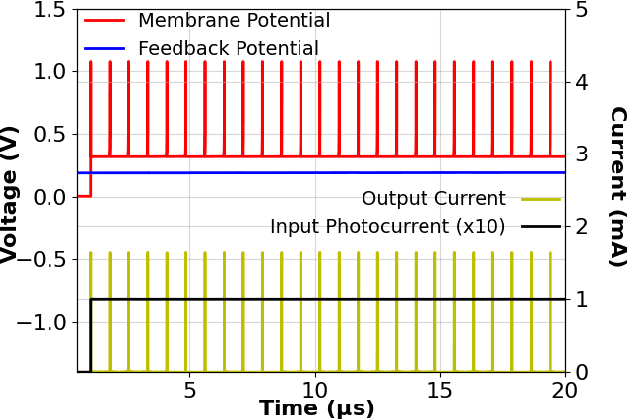
Spiking neural networks (SNN) provide a new computational paradigm capable of highly parallelized, real-time processing. Photonic devices are ideal for the design of high-bandwidth, parallel architectures matching the SNN computational paradigm. Co-integration of CMOS and photonic elements allow low-loss photonic devices to be combined with analog electronics for greater flexibility of nonlinear computational elements. As such, we designed and simulated an optoelectronic spiking neuron circuit on a monolithic silicon photonics (SiPh) process that replicates useful spiking behaviors beyond the leaky integrate-and-fire (LIF). Additionally, we explored two learning algorithms with the potential for on-chip learning using Mach-Zehnder Interferometric (MZI) meshes as synaptic interconnects. A variation of Random Backpropagation (RPB) was experimentally demonstrated on-chip and matched the performance of a standard linear regression on a simple classification task. Meanwhile, the Contrastive Hebbian Learning (CHL) rule was applied to a simulated neural network composed of MZI meshes for a random input-output mapping task. The CHL-trained MZI network performed better than random guessing but does not match the performance of the ideal neural network (without the constraints imposed by the MZI meshes). Through these efforts, we demonstrate that co-integrated CMOS and SiPh technologies are well-suited to the design of scalable SNN computing architectures.
STS: Surround-view Temporal Stereo for Multi-view 3D Detection
Aug 22, 2022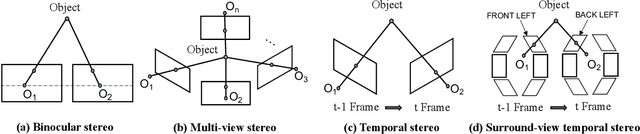
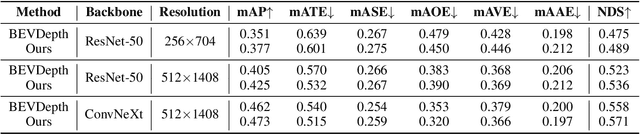
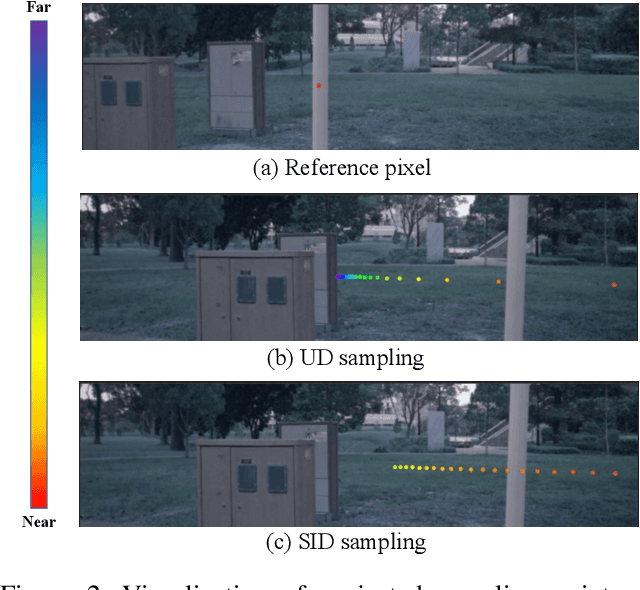
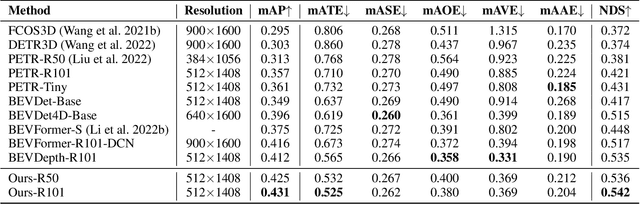
Learning accurate depth is essential to multi-view 3D object detection. Recent approaches mainly learn depth from monocular images, which confront inherent difficulties due to the ill-posed nature of monocular depth learning. Instead of using a sole monocular depth method, in this work, we propose a novel Surround-view Temporal Stereo (STS) technique that leverages the geometry correspondence between frames across time to facilitate accurate depth learning. Specifically, we regard the field of views from all cameras around the ego vehicle as a unified view, namely surroundview, and conduct temporal stereo matching on it. The resulting geometrical correspondence between different frames from STS is utilized and combined with the monocular depth to yield final depth prediction. Comprehensive experiments on nuScenes show that STS greatly boosts 3D detection ability, notably for medium and long distance objects. On BEVDepth with ResNet-50 backbone, STS improves mAP and NDS by 2.6% and 1.4%, respectively. Consistent improvements are observed when using a larger backbone and a larger image resolution, demonstrating its effectiveness
Improving spatial cues for hearables using a parameterized binaural CDR estimator
Jul 17, 2022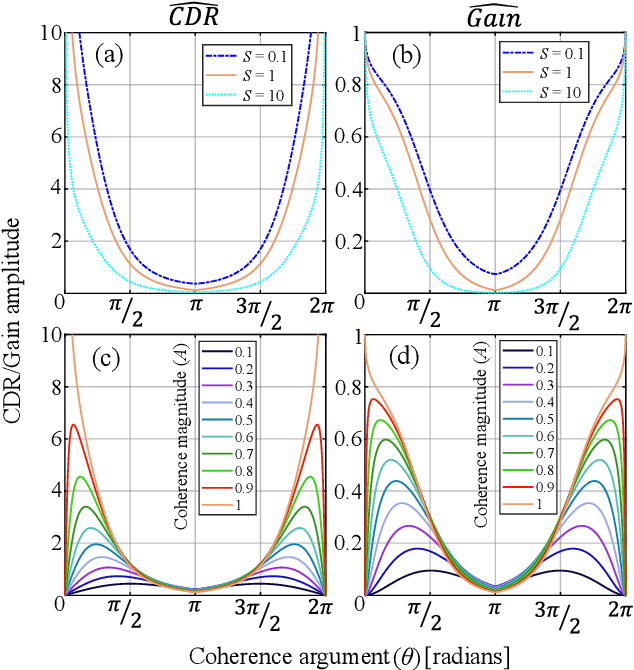
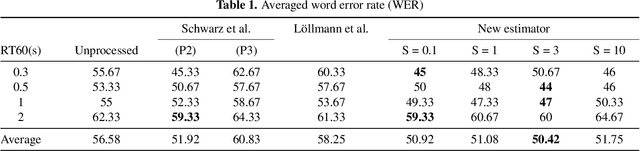
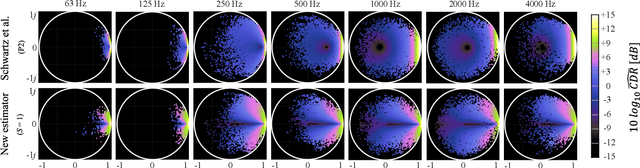
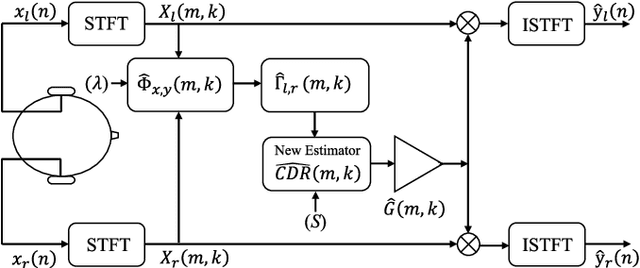
We investigate a speech enhancement method based on the binaural coherence-to-diffuse power ratio (CDR), which preserves auditory spatial cues for maskers and a broadside target. Conventional CDR estimators typically rely on a mathematical coherence model of the desired signal and/or diffuse noise field in their formulation, which may influence their accuracy in natural environments. This work proposes a new robust and parameterized directional binaural CDR estimator. The estimator is calculated in the time-frequency domain and is based on a geometrical interpretation of the spatial coherence function between the binaural microphone signals. The binaural performance of the new CDR estimator is compared with three state-of-the-art CDR estimators in cocktail-party-like environments and has shown improvements in terms of several objective speech quality metrics such as PESQ and SRMR. We also discuss the benefits of the parameterizable CDR estimator for varying sound environments and briefly reflect on several informal subjective evaluations using a low-latency real-time framework.
High-Quality Real Time Facial Capture Based on Single Camera
Nov 15, 2021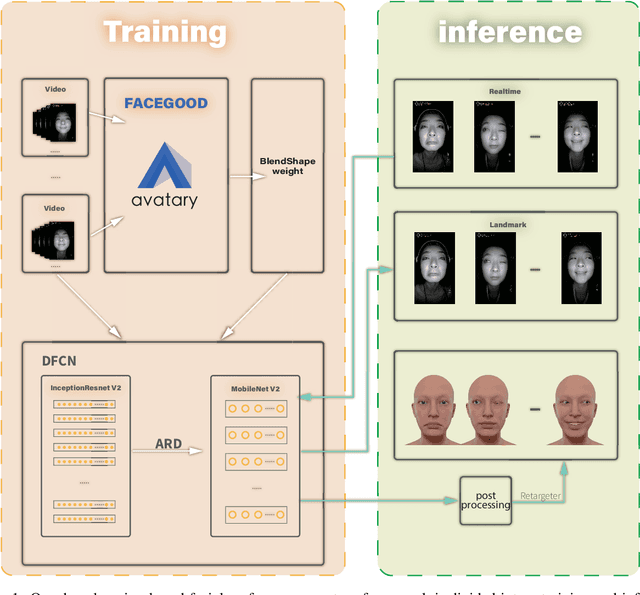


We propose a real time deep learning framework for video-based facial expression capture. Our process uses a high-end facial capture pipeline based on FACEGOOD to capture facial expression. We train a convolutional neural network to produce high-quality continuous blendshape weight output from video training. Since this facial capture is fully automated, our system can drastically reduce the amount of labor involved in the development of modern narrative-driven video games or films involving realistic digital doubles of actors and potentially hours of animated dialogue per character. We demonstrate compelling animation inference in challenging areas such as eyes and lips.
Real-time Recognition of Yoga Poses using computer Vision for Smart Health Care
Jan 19, 2022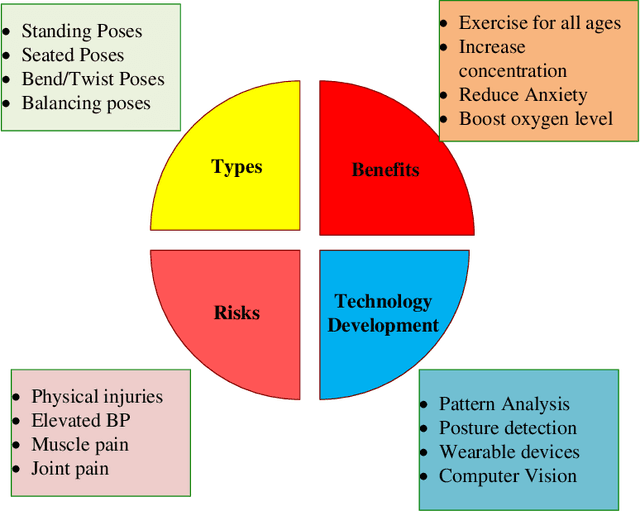
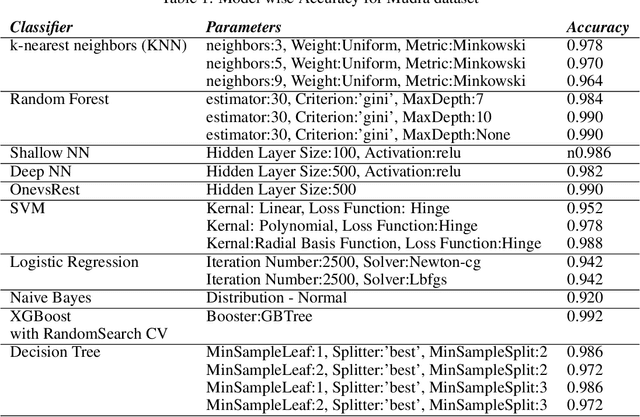
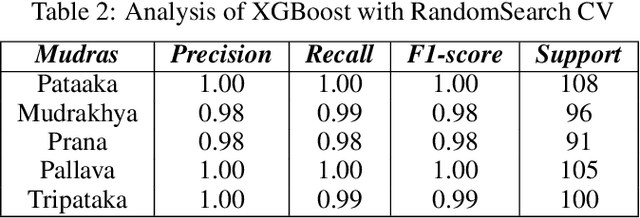
Nowadays, yoga has become a part of life for many people. Exercises and sports technological assistance is implemented in yoga pose identification. In this work, a self-assistance based yoga posture identification technique is developed, which helps users to perform Yoga with the correction feature in Real-time. The work also presents Yoga-hand mudra (hand gestures) identification. The YOGI dataset has been developed which include 10 Yoga postures with around 400-900 images of each pose and also contain 5 mudras for identification of mudras postures. It contains around 500 images of each mudra. The feature has been extracted by making a skeleton on the body for yoga poses and hand for mudra poses. Two different algorithms have been used for creating a skeleton one for yoga poses and the second for hand mudras. Angles of the joints have been extracted as a features for different machine learning and deep learning models. among all the models XGBoost with RandomSearch CV is most accurate and gives 99.2\% accuracy. The complete design framework is described in the present paper.
Explaining Time Series Predictions with Dynamic Masks
Jun 09, 2021

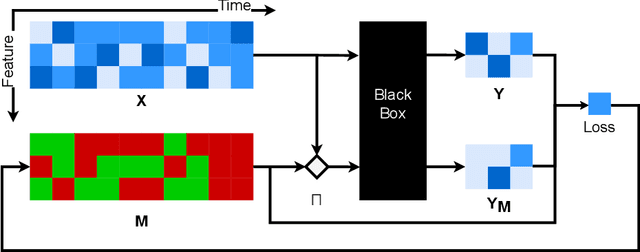
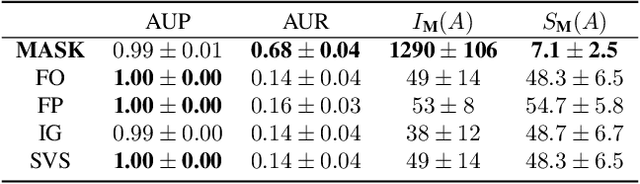
How can we explain the predictions of a machine learning model? When the data is structured as a multivariate time series, this question induces additional difficulties such as the necessity for the explanation to embody the time dependency and the large number of inputs. To address these challenges, we propose dynamic masks (Dynamask). This method produces instance-wise importance scores for each feature at each time step by fitting a perturbation mask to the input sequence. In order to incorporate the time dependency of the data, Dynamask studies the effects of dynamic perturbation operators. In order to tackle the large number of inputs, we propose a scheme to make the feature selection parsimonious (to select no more feature than necessary) and legible (a notion that we detail by making a parallel with information theory). With synthetic and real-world data, we demonstrate that the dynamic underpinning of Dynamask, together with its parsimony, offer a neat improvement in the identification of feature importance over time. The modularity of Dynamask makes it ideal as a plug-in to increase the transparency of a wide range of machine learning models in areas such as medicine and finance, where time series are abundant.
DBE-KT22: A Knowledge Tracing Dataset Based on Online Student Evaluation
Aug 19, 2022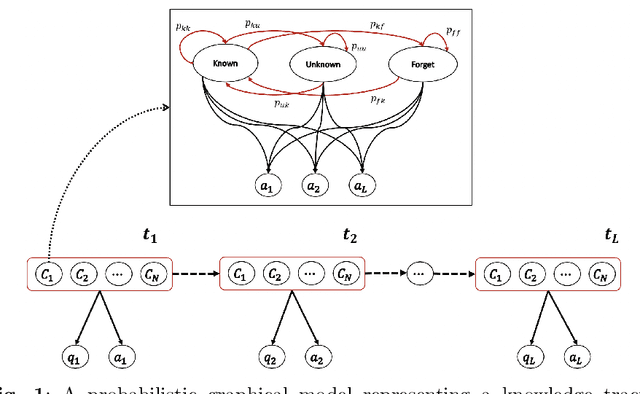
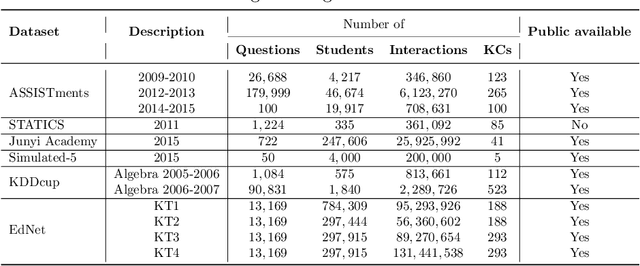
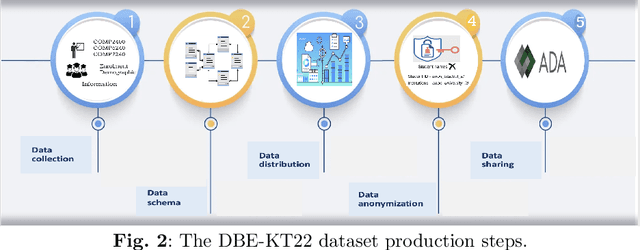
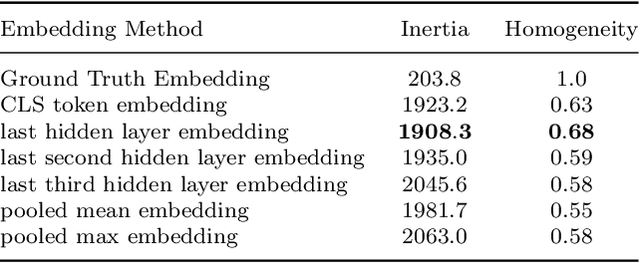
Online education has gained an increasing importance over the last decade for providing affordable high-quality education to students worldwide. This has been further magnified during the global pandemic as more students switched to study online. The majority of online education tasks, e.g., course recommendation, exercise recommendation, or automated evaluation, depends on tracking students' knowledge progress. This is known as the \emph{Knowledge Tracing} problem in the literature. Addressing this problem requires collecting student evaluation data that can reflect their knowledge evolution over time. In this paper, we propose a new knowledge tracing dataset named Database Exercises for Knowledge Tracing (DBE-KT22) that is collected from an online student exercise system in a course taught at the Australian National University in Australia. We discuss the characteristics of the DBE-KT22 dataset and contrast it with the existing datasets in the knowledge tracing literature. Our dataset is available for public access through the Australian Data Archive platform.
Model-Based Reinforcement Learning with SINDy
Aug 30, 2022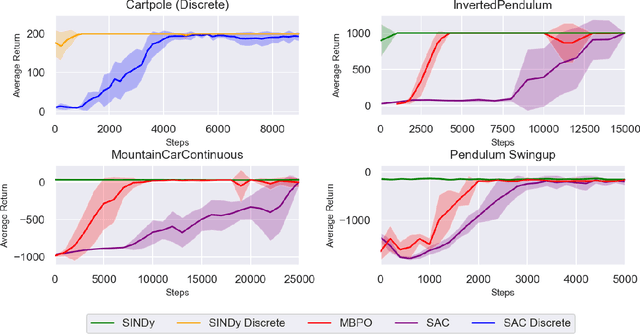
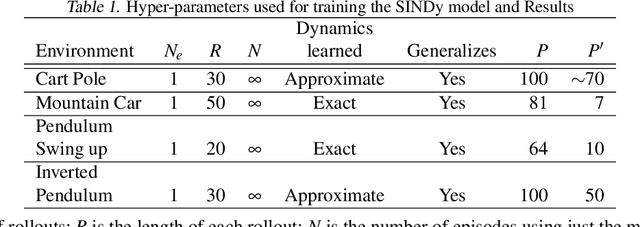
We draw on the latest advancements in the physics community to propose a novel method for discovering the governing non-linear dynamics of physical systems in reinforcement learning (RL). We establish that this method is capable of discovering the underlying dynamics using significantly fewer trajectories (as little as one rollout with $\leq 30$ time steps) than state of the art model learning algorithms. Further, the technique learns a model that is accurate enough to induce near-optimal policies given significantly fewer trajectories than those required by model-free algorithms. It brings the benefits of model-based RL without requiring a model to be developed in advance, for systems that have physics-based dynamics. To establish the validity and applicability of this algorithm, we conduct experiments on four classic control tasks. We found that an optimal policy trained on the discovered dynamics of the underlying system can generalize well. Further, the learned policy performs well when deployed on the actual physical system, thus bridging the model to real system gap. We further compare our method to state-of-the-art model-based and model-free approaches, and show that our method requires fewer trajectories sampled on the true physical system compared other methods. Additionally, we explored approximate dynamics models and found that they also can perform well.
Development of Sleep State Trend (SST), a bedside measure of neonatal sleep state fluctuations based on single EEG channels
Aug 25, 2022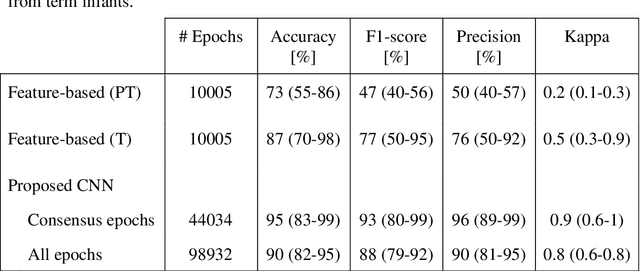
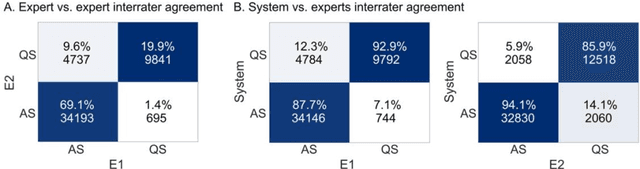
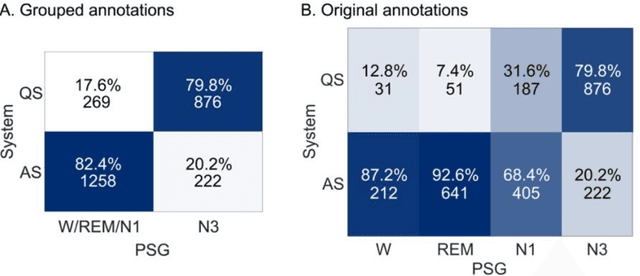
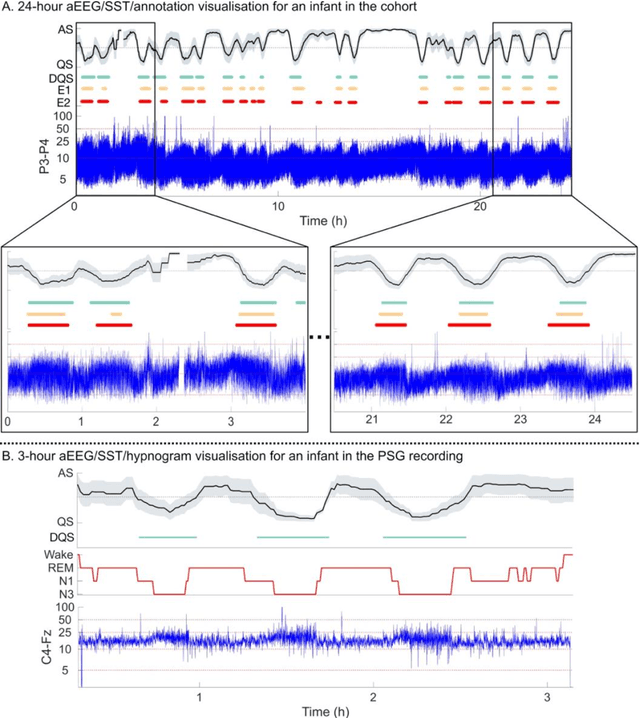
Objective: To develop and validate an automated method for bedside monitoring of sleep state fluctuations in neonatal intensive care units. Methods: A deep learning -based algorithm was designed and trained using 53 EEG recordings from a long-term (a)EEG monitoring in 30 near-term neonates. The results were validated using an external dataset from 30 polysomnography recordings. In addition to training and validating a single EEG channel quiet sleep detector, we constructed Sleep State Trend (SST), a bedside-ready means for visualizing classifier outputs. Results: The accuracy of quiet sleep detection in the training data was 90%, and the accuracy was comparable (85-86%) in all bipolar derivations available from the 4-electrode recordings. The algorithm generalized well to an external dataset, showing 81% overall accuracy despite different signal derivations. SST allowed an intuitive, clear visualization of the classifier output. Conclusions: Fluctuations in sleep states can be detected at high fidelity from a single EEG channel, and the results can be visualized as a transparent and intuitive trend in the bedside monitors. Significance: The Sleep State Trend (SST) may provide caregivers a real-time view of sleep state fluctuations and its cyclicity.