 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PlaneSLAM: Plane-based LiDAR SLAM for Motion Planning in Structured 3D Environments
Sep 17, 2022
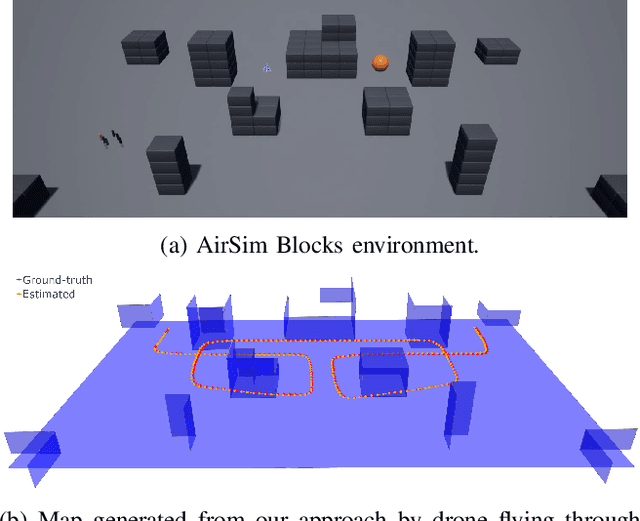
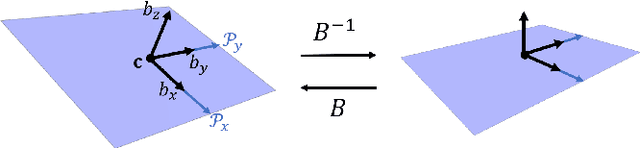
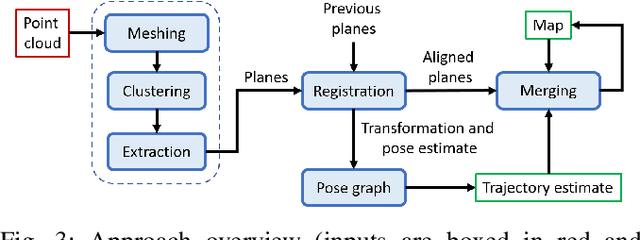
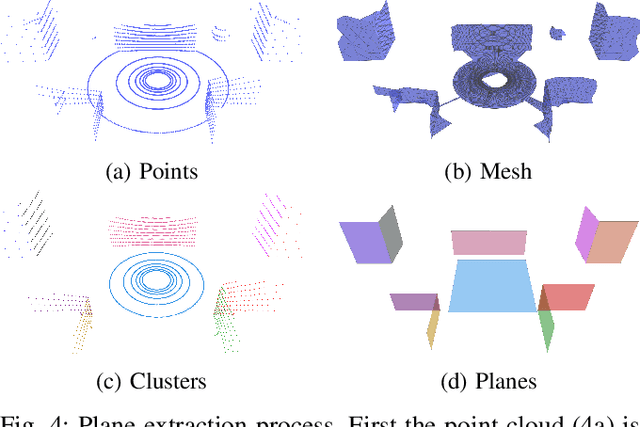
LiDAR sensors are a powerful tool for robot simultaneous localization and mapping (SLAM) in unknown environments, but the raw point clouds they produce are dense, computationally expensive to store, and unsuited for direct use by downstream autonomy tasks, such as motion planning. For integration with motion planning, it is desirable for SLAM pipelines to generate lightweight geometric map representations. Such representations are also particularly well-suited for man-made environments, which can often be viewed as a so-called "Manhattan world" built on a Cartesian grid. In this work we present a 3D LiDAR SLAM algorithm for Manhattan world environments which extracts planar features from point clouds to achieve lightweight, real-time localization and mapping. Our approach generates plane-based maps which occupy significantly less memory than their point cloud equivalents, and are suited towards fast collision checking for motion planning. By leveraging the Manhattan world assumption, we target extraction of orthogonal planes to generate maps which are more structured and organized than those of existing plane-based LiDAR SLAM approaches. We demonstrate our approach in the high-fidelity AirSim simulator and in real-world experiments with a ground rover equipped with a Velodyne LiDAR. For both cases, we are able to generate high quality maps and trajectory estimates at a rate matching the sensor rate of 10 Hz.
Temporal and cross-modal attention for audio-visual zero-shot learning
Jul 20, 2022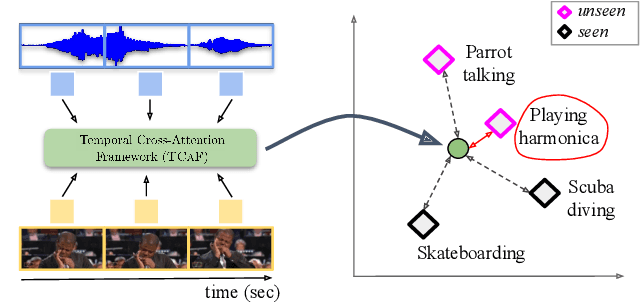
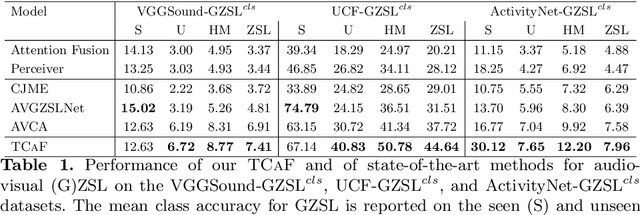


Audio-visual generalised zero-shot learning for video classification requires understanding the relations between the audio and visual information in order to be able to recognise samples from novel, previously unseen classes at test time. The natural semantic and temporal alignment between audio and visual data in video data can be exploited to learn powerful representations that generalise to unseen classes at test time. We propose a multi-modal and Temporal Cross-attention Framework (\modelName) for audio-visual generalised zero-shot learning. Its inputs are temporally aligned audio and visual features that are obtained from pre-trained networks. Encouraging the framework to focus on cross-modal correspondence across time instead of self-attention within the modalities boosts the performance significantly. We show that our proposed framework that ingests temporal features yields state-of-the-art performance on the \ucf, \vgg, and \activity benchmarks for (generalised) zero-shot learning. Code for reproducing all results is available at \url{https://github.com/ExplainableML/TCAF-GZSL}.
Partial annotations for the segmentation of large structures with low annotation cost
Sep 25, 2022Deep learning methods have been shown to be effective for the automatic segmentation of structures and pathologies in medical imaging. However, they require large annotated datasets, whose manual segmentation is a tedious and time-consuming task, especially for large structures. We present a new method of partial annotations that uses a small set of consecutive annotated slices from each scan with an annotation effort that is equal to that of only few annotated cases. The training with partial annotations is performed by using only annotated blocks, incorporating information about slices outside the structure of interest and modifying a batch loss function to consider only the annotated slices. To facilitate training in a low data regime, we use a two-step optimization process. We tested the method with the popular soft Dice loss for the fetal body segmentation task in two MRI sequences, TRUFI and FIESTA, and compared full annotation regime to partial annotations with a similar annotation effort. For TRUFI data, the use of partial annotations yielded slightly better performance on average compared to full annotations with an increase in Dice score from 0.936 to 0.942, and a substantial decrease in Standard Deviations (STD) of Dice score by 22% and Average Symmetric Surface Distance (ASSD) by 15%. For the FIESTA sequence, partial annotations also yielded a decrease in STD of the Dice score and ASSD metrics by 27.5% and 33% respectively for in-distribution data, and a substantial improvement also in average performance on out-of-distribution data, increasing Dice score from 0.84 to 0.9 and decreasing ASSD from 7.46 to 4.01 mm. The two-step optimization process was helpful for partial annotations for both in-distribution and out-of-distribution data. The partial annotations method with the two-step optimizer is therefore recommended to improve segmentation performance under low data regime.
* 10 pages, 4 figures
Toward Improving Health Literacy in Patient Education Materials with Neural Machine Translation Models
Sep 14, 2022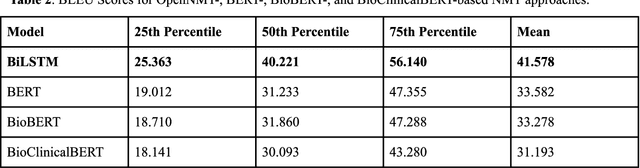
Health literacy is the central focus of Healthy People 2030, the fifth iteration of the U.S. national goals and objectives. People with low health literacy usually have trouble understanding health information, following post-visit instructions, and using prescriptions, which results in worse health outcomes and serious health disparities. In this study, we propose to leverage natural language processing techniques to improve health literacy in patient education materials by automatically translating illiterate languages in a given sentence. We scraped patient education materials from four online health information websites: MedlinePlus.gov, Drugs.com, Mayoclinic.org and Reddit.com. We trained and tested the state-of-the-art neural machine translation (NMT) models on a silver standard training dataset and a gold standard testing dataset, respectively. The experimental results showed that the Bidirectional Long Short-Term Memory (BiLSTM) NMT model outperformed Bidirectional Encoder Representations from Transformers (BERT)-based NMT models. We also verified the effectiveness of NMT models in translating health illiterate languages by comparing the ratio of health illiterate language in the sentence. The proposed NMT models were able to identify the correct complicated words and simplify into layman language while at the same time the models suffer from sentence completeness, fluency, readability, and have difficulty in translating certain medical terms.
The SpeakIn Speaker Verification System for Far-Field Speaker Verification Challenge 2022
Sep 23, 2022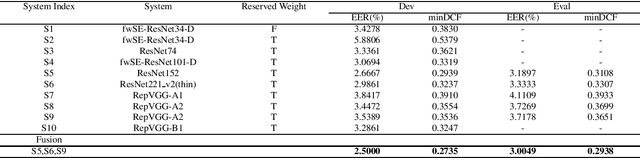
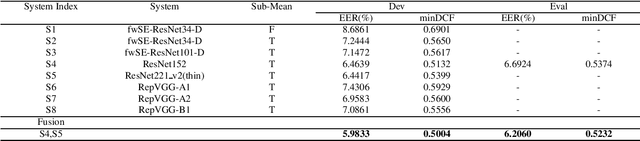
This paper describes speaker verification (SV) systems submitted by the SpeakIn team to the Task 1 and Task 2 of the Far-Field Speaker Verification Challenge 2022 (FFSVC2022). SV tasks of the challenge focus on the problem of fully supervised far-field speaker verification (Task 1) and semi-supervised far-field speaker verification (Task 2). In Task 1, we used the VoxCeleb and FFSVC2020 datasets as train datasets. And for Task 2, we only used the VoxCeleb dataset as train set. The ResNet-based and RepVGG-based architectures were developed for this challenge. Global statistic pooling structure and MQMHA pooling structure were used to aggregate the frame-level features across time to obtain utterance-level representation. We adopted AM-Softmax and AAM-Softmax to classify the resulting embeddings. We innovatively propose a staged transfer learning method. In the pre-training stage we reserve the speaker weights, and there are no positive samples to train them in this stage. Then we fine-tune these weights with both positive and negative samples in the second stage. Compared with the traditional transfer learning strategy, this strategy can better improve the model performance. The Sub-Mean and AS-Norm backend methods were used to solve the problem of domain mismatch. In the fusion stage, three models were fused in Task1 and two models were fused in Task2. On the FFSVC2022 leaderboard, the EER of our submission is 3.0049% and the corresponding minDCF is 0.2938 in Task1. In Task2, EER and minDCF are 6.2060% and 0.5232 respectively. Our approach leads to excellent performance and ranks 1st in both challenge tasks.
Feature-Rich Long-term Bitcoin Trading Assistant
Sep 14, 2022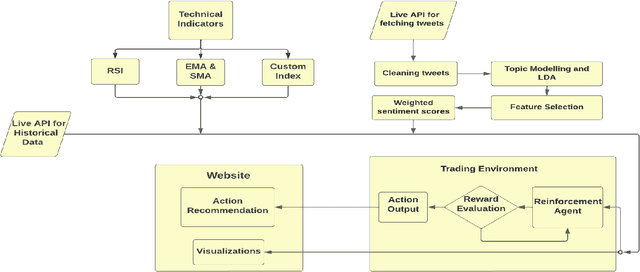
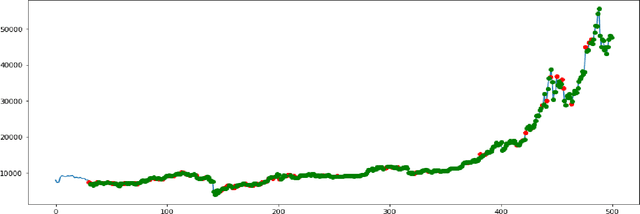
For a long time predicting, studying and analyzing financial indices has been of major interest for the financial community. Recently, there has been a growing interest in the Deep-Learning community to make use of reinforcement learning which has surpassed many of the previous benchmarks in a lot of fields. Our method provides a feature rich environment for the reinforcement learning agent to work on. The aim is to provide long term profits to the user so, we took into consideration the most reliable technical indicators. We have also developed a custom indicator which would provide better insights of the Bitcoin market to the user. The Bitcoin market follows the emotions and sentiments of the traders, so another element of our trading environment is the overall daily Sentiment Score of the market on Twitter. The agent is tested for a period of 685 days which also included the volatile period of Covid-19. It has been capable of providing reliable recommendations which give an average profit of about 69%. Finally, the agent is also capable of suggesting the optimal actions to the user through a website. Users on the website can also access the visualizations of the indicators to help fortify their decisions.
Large-displacement 3D Object Tracking with Hybrid Non-local Optimization
Jul 26, 2022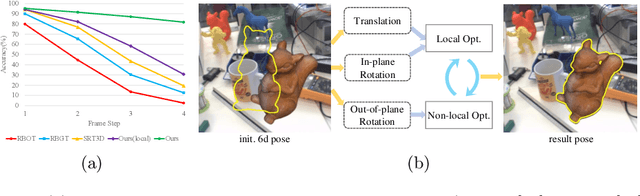


Optimization-based 3D object tracking is known to be precise and fast, but sensitive to large inter-frame displacements. In this paper we propose a fast and effective non-local 3D tracking method. Based on the observation that erroneous local minimum are mostly due to the out-of-plane rotation, we propose a hybrid approach combining non-local and local optimizations for different parameters, resulting in efficient non-local search in the 6D pose space. In addition, a precomputed robust contour-based tracking method is proposed for the pose optimization. By using long search lines with multiple candidate correspondences, it can adapt to different frame displacements without the need of coarse-to-fine search. After the pre-computation, pose updates can be conducted very fast, enabling the non-local optimization to run in real time. Our method outperforms all previous methods for both small and large displacements. For large displacements, the accuracy is greatly improved ($81.7\% \;\text{v.s.}\; 19.4\%$). At the same time, real-time speed ($>$50fps) can be achieved with only CPU. The source code is available at \url{https://github.com/cvbubbles/nonlocal-3dtracking}.
I-SPLIT: Deep Network Interpretability for Split Computing
Sep 23, 2022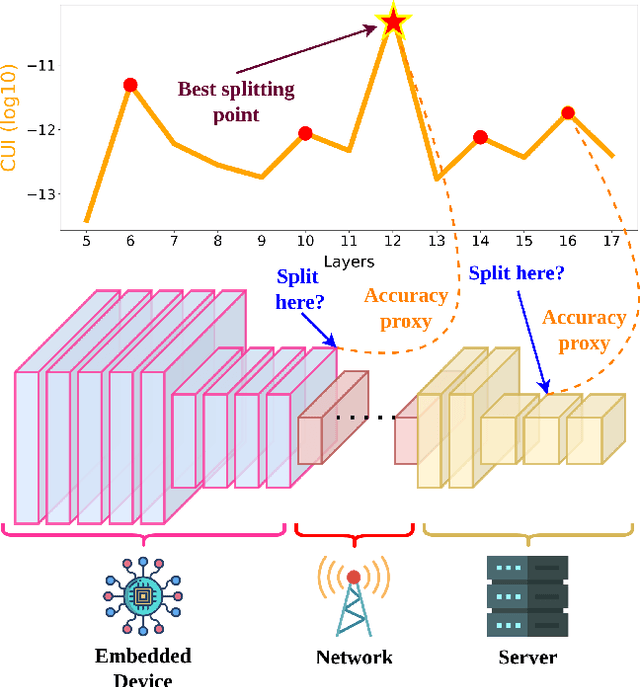
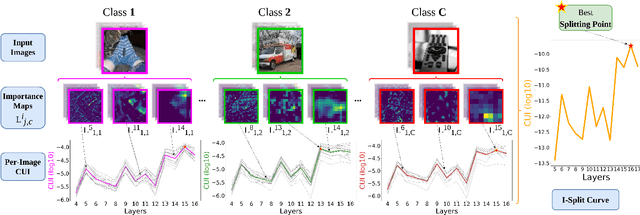
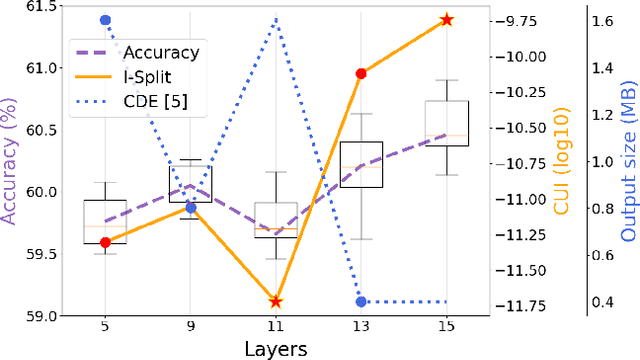
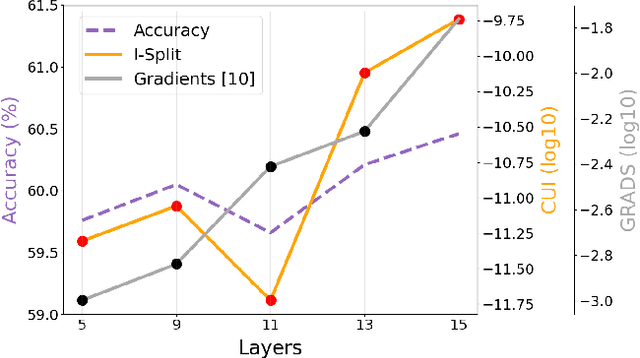
This work makes a substantial step in the field of split computing, i.e., how to split a deep neural network to host its early part on an embedded device and the rest on a server. So far, potential split locations have been identified exploiting uniquely architectural aspects, i.e., based on the layer sizes. Under this paradigm, the efficacy of the split in terms of accuracy can be evaluated only after having performed the split and retrained the entire pipeline, making an exhaustive evaluation of all the plausible splitting points prohibitive in terms of time. Here we show that not only the architecture of the layers does matter, but the importance of the neurons contained therein too. A neuron is important if its gradient with respect to the correct class decision is high. It follows that a split should be applied right after a layer with a high density of important neurons, in order to preserve the information flowing until then. Upon this idea, we propose Interpretable Split (I-SPLIT): a procedure that identifies the most suitable splitting points by providing a reliable prediction on how well this split will perform in terms of classification accuracy, beforehand of its effective implementation. As a further major contribution of I-SPLIT, we show that the best choice for the splitting point on a multiclass categorization problem depends also on which specific classes the network has to deal with. Exhaustive experiments have been carried out on two networks, VGG16 and ResNet-50, and three datasets, Tiny-Imagenet-200, notMNIST, and Chest X-Ray Pneumonia. The source code is available at https://github.com/vips4/I-Split.
Real Time Detection Free Tracking of Multiple Objects Via Equilibrium Optimizer
May 24, 2022
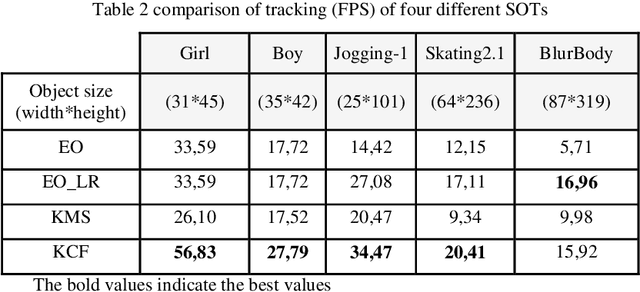
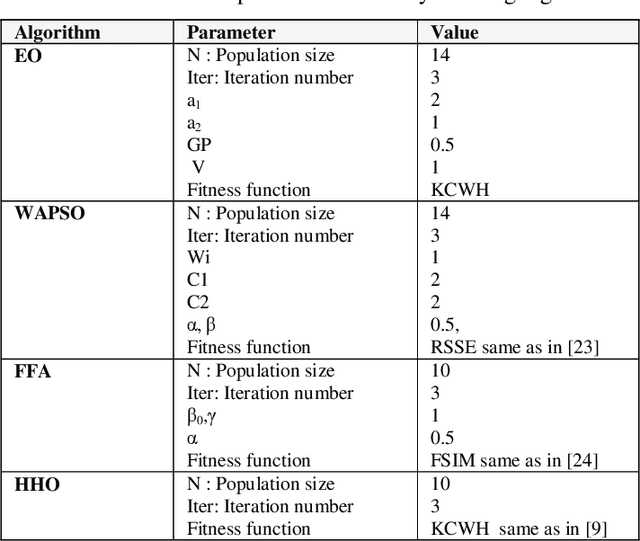
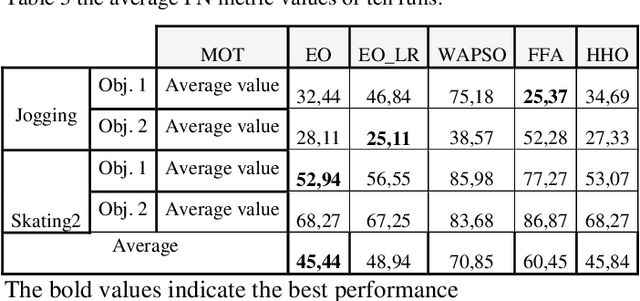
Multiple objects tracking (MOT) is a difficult task, as it usually requires special hardware and higher computation complexity. In this work, we present a new framework of MOT by using of equilibrium optimizer (EO) algorithm and reducing the resolution of the bounding boxes of the objects to solve such problems in the detection free framework. First, in the first frame the target objects are initialized and its size is computed, then its resolution is reduced if it is higher than a threshold, and then modeled by their kernel color histogram to establish a feature model. The Bhattacharya distances between the histogram of object models and other candidates are used as the fitness function to be optimized. Multiple agents are generated by EO, according to the number of the target objects to be tracked. EO algorithm is used because of its efficiency and lower computation cost compared to other algorithms in global optimization. Experimental results confirm that EO multi-object tracker achieves satisfying tracking results then other trackers.
Log-linear Error State Model Derivation without Approximation for INS
Aug 06, 2022Through assembling the navigation parameters as matrix Lie group state, the corresponding inertial navigation system (INS) kinematic model possesses a group-affine property. The Lie logarithm of the navigation state estimation error satisfies a log-linear autonomous differential equation. These log-linear models are still applicable even with arbitrarily large initial errors, which is very attractive for INS initial alignment. However, in existing works, the log-linear models are all derived based on first-order linearization approximation, which seemingly goes against their successful applications in INS initial alignment with large misalignments. In this work, it is shown that the log-linear models can also be derived without any approximation, the error dynamics for both left and right invariant error in continuous time are given in matrix Lie group SE_2 (3) for the first time. This work provides another evidence for the validity of the log-linear model in situations with arbitrarily large initial errors.