 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
From Displacements to Distributions: A Machine-Learning Enabled Framework for Quantifying Uncertainties in Parameters of Computational Models
Mar 04, 2024
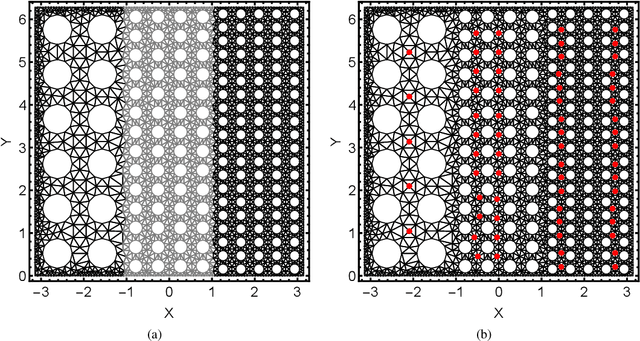

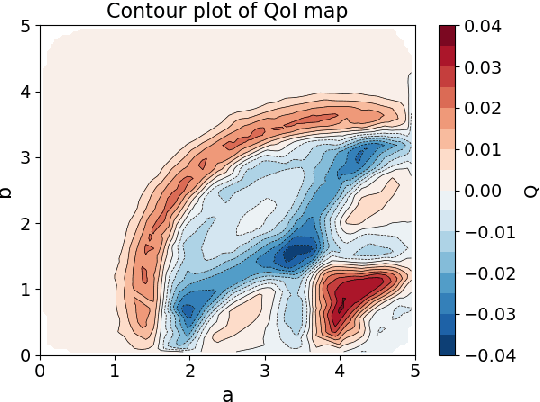

This work presents novel extensions for combining two frameworks for quantifying both aleatoric (i.e., irreducible) and epistemic (i.e., reducible) sources of uncertainties in the modeling of engineered systems. The data-consistent (DC) framework poses an inverse problem and solution for quantifying aleatoric uncertainties in terms of pullback and push-forward measures for a given Quantity of Interest (QoI) map. Unfortunately, a pre-specified QoI map is not always available a priori to the collection of data associated with system outputs. The data themselves are often polluted with measurement errors (i.e., epistemic uncertainties), which complicates the process of specifying a useful QoI. The Learning Uncertain Quantities (LUQ) framework defines a formal three-step machine-learning enabled process for transforming noisy datasets into samples of a learned QoI map to enable DC-based inversion. We develop a robust filtering step in LUQ that can learn the most useful quantitative information present in spatio-temporal datasets. The learned QoI map transforms simulated and observed datasets into distributions to perform DC-based inversion. We also develop a DC-based inversion scheme that iterates over time as new spatial datasets are obtained and utilizes quantitative diagnostics to identify both the quality and impact of inversion at each iteration. Reproducing Kernel Hilbert Space theory is leveraged to mathematically analyze the learned QoI map and develop a quantitative sufficiency test for evaluating the filtered data. An illustrative example is utilized throughout while the final two examples involve the manufacturing of shells of revolution to demonstrate various aspects of the presented frameworks.
Root Causing Prediction Anomalies Using Explainable AI
Mar 04, 2024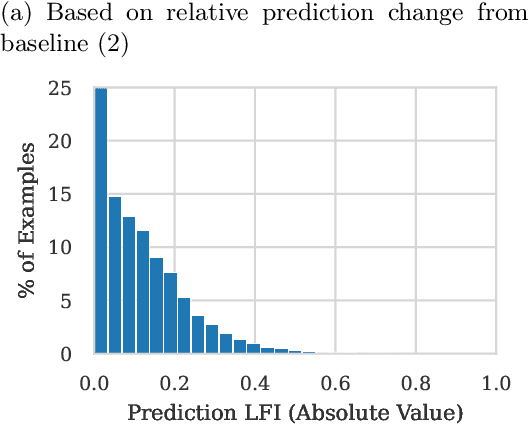
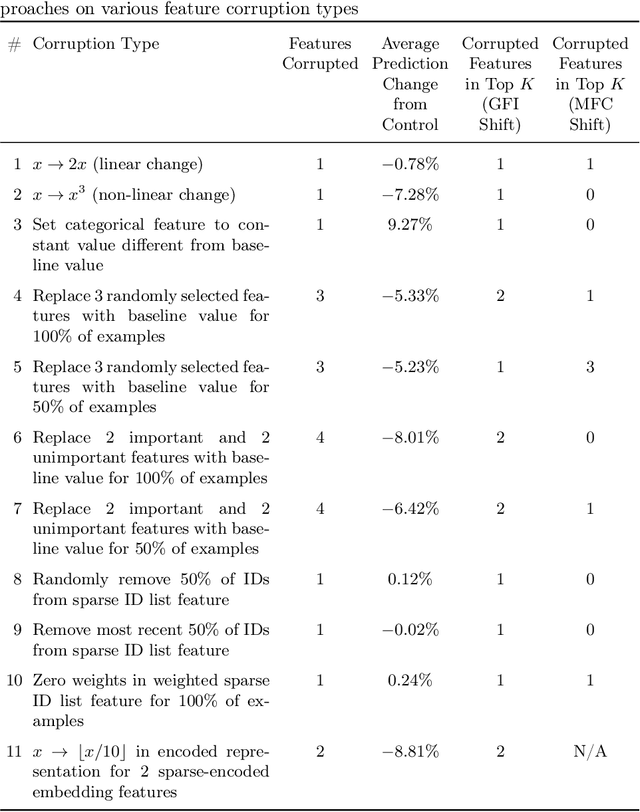
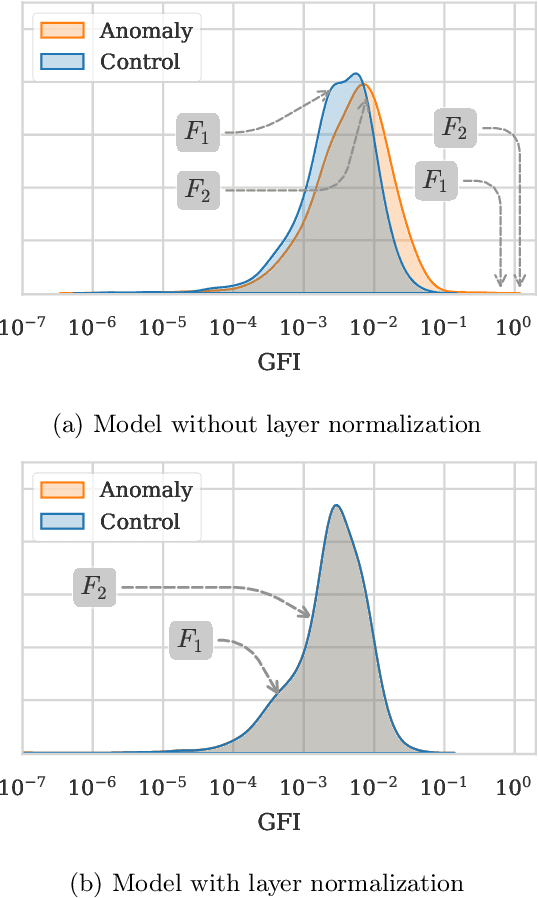
This paper presents a novel application of explainable AI (XAI) for root-causing performance degradation in machine learning models that learn continuously from user engagement data. In such systems a single feature corruption can cause cascading feature, label and concept drifts. We have successfully applied this technique to improve the reliability of models used in personalized advertising. Performance degradation in such systems manifest as prediction anomalies in the models. These models are typically trained continuously using features that are produced by hundreds of real time data processing pipelines or derived from other upstream models. A failure in any of these pipelines or an instability in any of the upstream models can cause feature corruption, causing the model's predicted output to deviate from the actual output and the training data to become corrupted. The causal relationship between the features and the predicted output is complex, and root-causing is challenging due to the scale and dynamism of the system. We demonstrate how temporal shifts in the global feature importance distribution can effectively isolate the cause of a prediction anomaly, with better recall than model-to-feature correlation methods. The technique appears to be effective even when approximating the local feature importance using a simple perturbation-based method, and aggregating over a few thousand examples. We have found this technique to be a model-agnostic, cheap and effective way to monitor complex data pipelines in production and have deployed a system for continuously analyzing the global feature importance distribution of continuously trained models.
Improving and Unifying Discrete&Continuous-time Discrete Denoising Diffusion
Feb 06, 2024Discrete diffusion models have seen a surge of attention with applications on naturally discrete data such as language and graphs. Although discrete-time discrete diffusion has been established for a while, only recently Campbell et al. (2022) introduced the first framework for continuous-time discrete diffusion. However, their training and sampling processes differ significantly from the discrete-time version, necessitating nontrivial approximations for tractability. In this paper, we first present a series of mathematical simplifications of the variational lower bound that enable more accurate and easy-to-optimize training for discrete diffusion. In addition, we derive a simple formulation for backward denoising that enables exact and accelerated sampling, and importantly, an elegant unification of discrete-time and continuous-time discrete diffusion. Thanks to simpler analytical formulations, both forward and now also backward probabilities can flexibly accommodate any noise distribution, including different noise distributions for multi-element objects. Experiments show that our proposed USD3 (for Unified Simplified Discrete Denoising Diffusion) outperform all SOTA baselines on established datasets. We open-source our unified code at https://github.com/LingxiaoShawn/USD3.
Automated Testing of Spatially-Dependent Environmental Hypotheses through Active Transfer Learning
Feb 28, 2024The efficient collection of samples is an important factor in outdoor information gathering applications on account of high sampling costs such as time, energy, and potential destruction to the environment. Utilization of available a-priori data can be a powerful tool for increasing efficiency. However, the relationships of this data with the quantity of interest are often not known ahead of time, limiting the ability to leverage this knowledge for improved planning efficiency. To this end, this work combines transfer learning and active learning through a Multi-Task Gaussian Process and an information-based objective function. Through this combination it can explore the space of hypothetical inter-quantity relationships and evaluate these hypotheses in real-time, allowing this new knowledge to be immediately exploited for future plans. The performance of the proposed method is evaluated against synthetic data and is shown to evaluate multiple hypotheses correctly. Its effectiveness is also demonstrated on real datasets. The technique is able to identify and leverage hypotheses which show a medium or strong correlation to reduce prediction error by a factor of 1.5--6 within the first 5 samples, and poor hypotheses are quickly identified and rejected, having no adverse effect on planning after around 3 samples.
Genie: Smart ROS-based Caching for Connected Autonomous Robots
Feb 29, 2024Despite the promising future of autonomous robots, several key issues currently remain that can lead to compromised performance and safety. One such issue is latency, where we find that even the latest embedded platforms from NVIDIA fail to execute intelligence tasks (e.g., object detection) of autonomous vehicles in a real-time fashion. One remedy to this problem is the promising paradigm of edge computing. Through collaboration with our industry partner, we identify key prohibitive limitations of the current edge mindset: (1) servers are not distributed enough and thus, are not close enough to vehicles, (2) current proposed edge solutions do not provide substantially better performance and extra information specific to autonomous vehicles to warrant their cost to the user, and (3) the state-of-the-art solutions are not compatible with popular frameworks used in autonomous systems, particularly the Robot Operating System (ROS). To remedy these issues, we provide Genie, an encapsulation technique that can enable transparent caching in ROS in a non-intrusive way (i.e., without modifying the source code), can build the cache in a distributed manner (in contrast to traditional central caching methods), and can construct a collective three-dimensional object map to provide substantially better latency (even on low-power edge servers) and higher quality data to all vehicles in a certain locality. We fully implement our design on state-of-the-art industry-adopted embedded and edge platforms, using the prominent autonomous driving software Autoware, and find that Genie can enhance the latency of Autoware Vision Detector by 82% on average, enable object reusability 31% of the time on average and as much as 67% for the incoming requests, and boost the confidence in its object map considerably over time.
Poisson-Gamma Dynamical Systems with Non-Stationary Transition Dynamics
Feb 26, 2024Bayesian methodologies for handling count-valued time series have gained prominence due to their ability to infer interpretable latent structures and to estimate uncertainties, and thus are especially suitable for dealing with noisy and incomplete count data. Among these Bayesian models, Poisson-Gamma Dynamical Systems (PGDSs) are proven to be effective in capturing the evolving dynamics underlying observed count sequences. However, the state-of-the-art PGDS still falls short in capturing the time-varying transition dynamics that are commonly observed in real-world count time series. To mitigate this limitation, a non-stationary PGDS is proposed to allow the underlying transition matrices to evolve over time, and the evolving transition matrices are modeled by sophisticatedly-designed Dirichlet Markov chains. Leveraging Dirichlet-Multinomial-Beta data augmentation techniques, a fully-conjugate and efficient Gibbs sampler is developed to perform posterior simulation. Experiments show that, in comparison with related models, the proposed non-stationary PGDS achieves improved predictive performance due to its capacity to learn non-stationary dependency structure captured by the time-evolving transition matrices.
Enhancing the "Immunity" of Mixture-of-Experts Networks for Adversarial Defense
Feb 29, 2024Recent studies have revealed the vulnerability of Deep Neural Networks (DNNs) to adversarial examples, which can easily fool DNNs into making incorrect predictions. To mitigate this deficiency, we propose a novel adversarial defense method called "Immunity" (Innovative MoE with MUtual information \& positioN stabilITY) based on a modified Mixture-of-Experts (MoE) architecture in this work. The key enhancements to the standard MoE are two-fold: 1) integrating of Random Switch Gates (RSGs) to obtain diverse network structures via random permutation of RSG parameters at evaluation time, despite of RSGs being determined after one-time training; 2) devising innovative Mutual Information (MI)-based and Position Stability-based loss functions by capitalizing on Grad-CAM's explanatory power to increase the diversity and the causality of expert networks. Notably, our MI-based loss operates directly on the heatmaps, thereby inducing subtler negative impacts on the classification performance when compared to other losses of the same type, theoretically. Extensive evaluation validates the efficacy of the proposed approach in improving adversarial robustness against a wide range of attacks.
Nonlinear Sheaf Diffusion in Graph Neural Networks
Mar 01, 2024
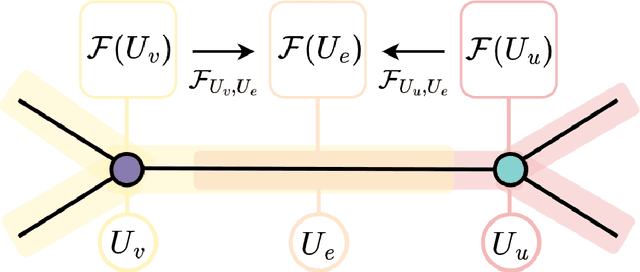
This work focuses on exploring the potential benefits of introducing a nonlinear Laplacian in Sheaf Neural Networks for graph-related tasks. The primary aim is to understand the impact of such nonlinearity on diffusion dynamics, signal propagation, and performance of neural network architectures in discrete-time settings. The study primarily emphasizes experimental analysis, using real-world and synthetic datasets to validate the practical effectiveness of different versions of the model. This approach shifts the focus from an initial theoretical exploration to demonstrating the practical utility of the proposed model.
Set the Clock: Temporal Alignment of Pretrained Language Models
Feb 26, 2024Language models (LMs) are trained on web text originating from many points in time and, in general, without any explicit temporal grounding. This work investigates the temporal chaos of pretrained LMs and explores various methods to align their internal knowledge to a target time, which we call "temporal alignment." To do this, we first automatically construct a dataset containing 20K time-sensitive questions and their answers for each year from 2000 to 2023. Based on this dataset, we empirically show that pretrained LMs (e.g., LLaMa2), despite having a recent pretraining cutoff (e.g., 2022), mostly answer questions using earlier knowledge (e.g., in 2019). We then develop several methods, from prompting to finetuning, to align LMs to use their most recent knowledge when answering questions, and investigate various factors in this alignment. Our experiments show that aligning LLaMa2 to the year 2022 can boost its performance by up to 62% relatively as measured by that year, even without mentioning time information explicitly, indicating the possibility of aligning models' internal sense of time after pretraining. Finally, we find that alignment to a historical time is also possible, with up to 2.8$\times$ the performance of the unaligned LM in 2010 if finetuning models to that year. These findings hint at the sophistication of LMs' internal knowledge organization and the necessity of tuning them properly.
SWTrack: Multiple Hypothesis Sliding Window 3D Multi-Object Tracking
Feb 27, 2024Modern robotic systems are required to operate in dense dynamic environments, requiring highly accurate real-time track identification and estimation. For 3D multi-object tracking, recent approaches process a single measurement frame recursively with greedy association and are prone to errors in ambiguous association decisions. Our method, Sliding Window Tracker (SWTrack), yields more accurate association and state estimation by batch processing many frames of sensor data while being capable of running online in real-time. The most probable track associations are identified by evaluating all possible track hypotheses across the temporal sliding window. A novel graph optimization approach is formulated to solve the multidimensional assignment problem with lifted graph edges introduced to account for missed detections and graph sparsity enforced to retain real-time efficiency. We evaluate our SWTrack implementation$^{2}$ on the NuScenes autonomous driving dataset to demonstrate improved tracking performance.