 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real Time Integration Centre of Mass (riCOM) Reconstruction for 4D-STEM
Dec 08, 2021
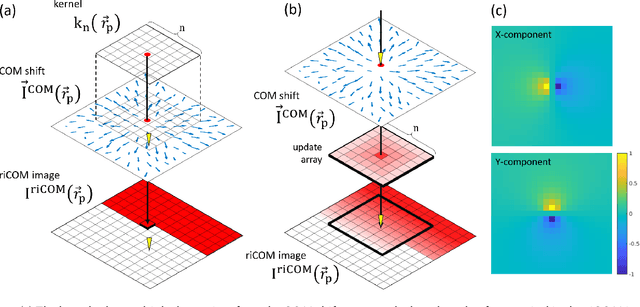
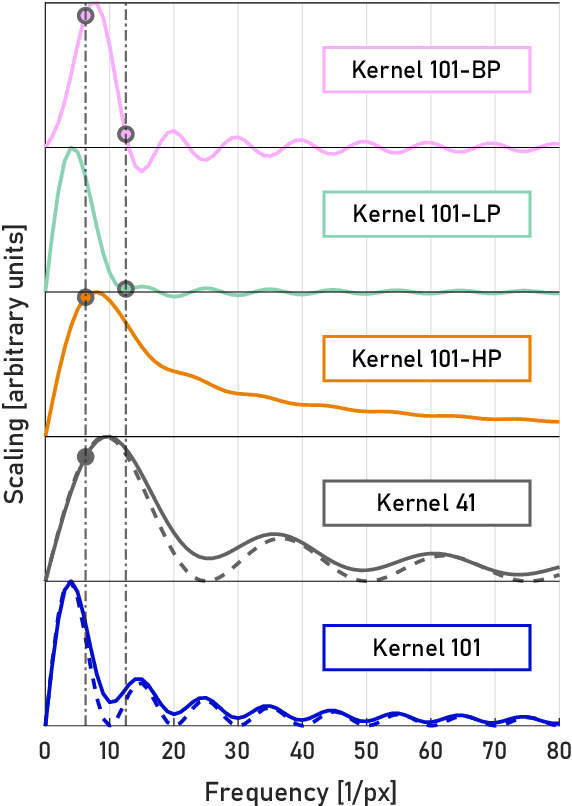
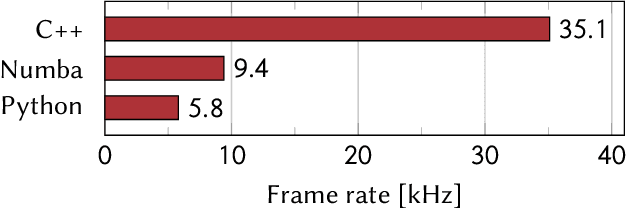
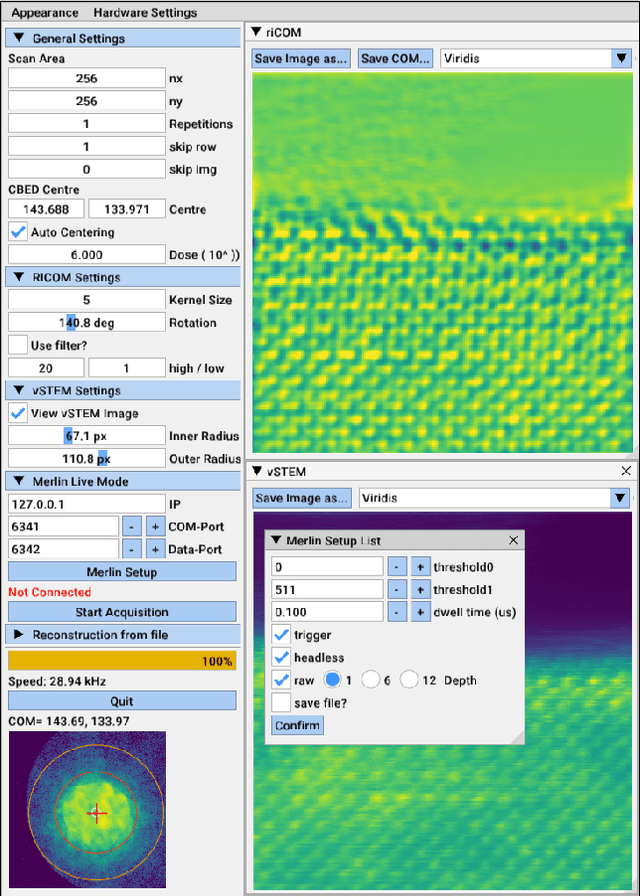
A real-time image reconstruction method for scanning transmission electron microscopy (STEM) is proposed. The method uses the concept of integrated centre of mass (iCOM) and creates a live-updated image based on diffraction patterns collected at each probe position during scanning. It is shown that the method has similar characteristics to the traditional iCOM approach. However, by reformulating the integration method, the reconstruction process can be divided into sub-units, with each unit requiring only information from a single probe position, such that the resulting image can be updated each time a new probe position is visited without storing any intermediate diffraction patterns. As a certain position in the image is only influenced by its surrounding pixels in the immediate vicinity, the image update provides interpretable images being build up while the scanning is being performed. The results show clearer features at higher spatial frequency, such as atomic column positions. It is also demonstrated that common post processing methods, such as a band pass filter, can be directly integrated in the real time processing flow. By comparing with other reconstruction methods, it is shown that the proposed method can produce high quality reconstructions with good noise robustness at extremely low memory and computational requirements. We further present an efficient, interactive open source implementation of the concept, compatible with frame-based, as well as event-based camera/file types. The proposed method provides the attractive feature of immediate feedback that microscope operators have become used to for e.g. conventional HAADF STEM imaging allowing for rapid decision making and fine tuning to obtain the best possible images for beam sensitive samples at the lowest possible dose.
Augraphy: A Data Augmentation Library for Document Images
Aug 30, 2022

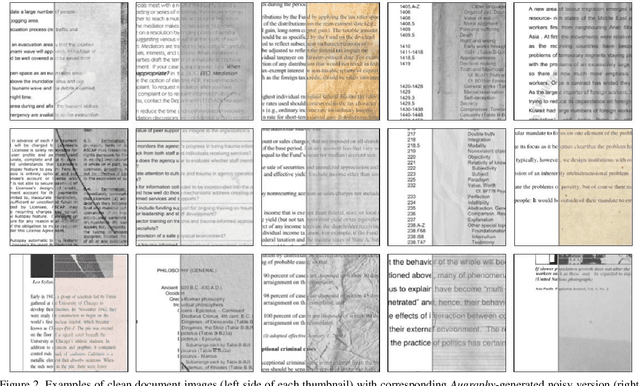
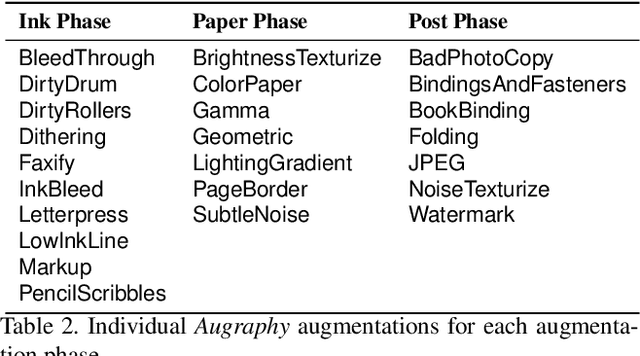
This paper introduces Augraphy, a Python package geared toward realistic data augmentation strategies for document images. Augraphy uses many different augmentation strategies to produce augmented versions of clean document images that appear as if they have been distorted from standard office operations, such as printing, scanning, and faxing through old or dirty machines, degradation of ink over time, and handwritten markings. Augraphy can be used both as a data augmentation tool for (1) producing diverse training data for tasks such as document de-noising, and (2) generating challenging test data for evaluating model robustness on document image modeling tasks. This paper provides an overview of Augraphy and presents three example robustness testing use-cases of Augraphy.
OLIVES Dataset: Ophthalmic Labels for Investigating Visual Eye Semantics
Sep 22, 2022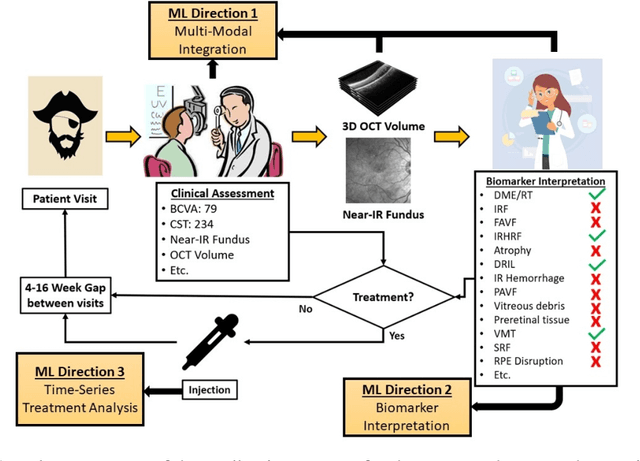
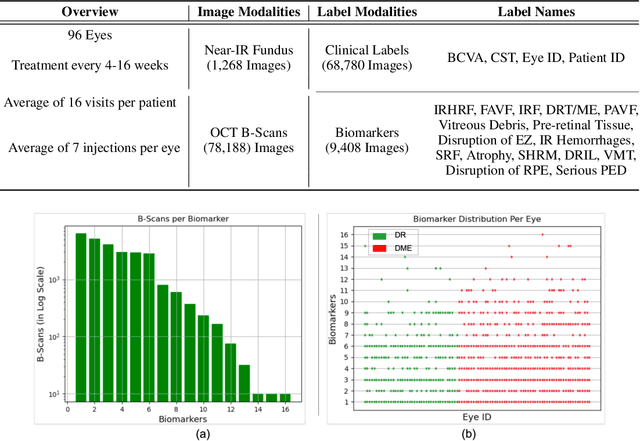
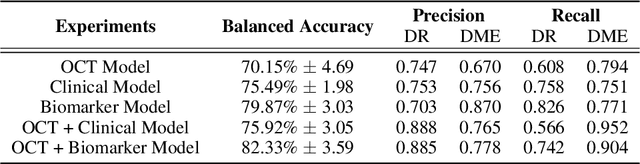
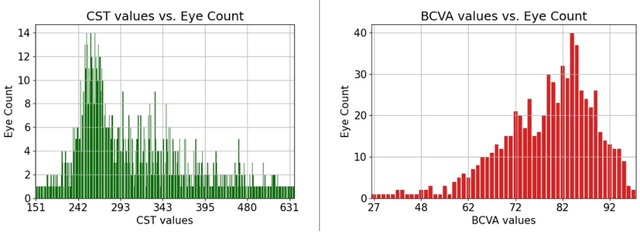
Clinical diagnosis of the eye is performed over multifarious data modalities including scalar clinical labels, vectorized biomarkers, two-dimensional fundus images, and three-dimensional Optical Coherence Tomography (OCT) scans. Clinical practitioners use all available data modalities for diagnosing and treating eye diseases like Diabetic Retinopathy (DR) or Diabetic Macular Edema (DME). Enabling usage of machine learning algorithms within the ophthalmic medical domain requires research into the relationships and interactions between all relevant data over a treatment period. Existing datasets are limited in that they neither provide data nor consider the explicit relationship modeling between the data modalities. In this paper, we introduce the Ophthalmic Labels for Investigating Visual Eye Semantics (OLIVES) dataset that addresses the above limitation. This is the first OCT and near-IR fundus dataset that includes clinical labels, biomarker labels, disease labels, and time-series patient treatment information from associated clinical trials. The dataset consists of 1268 near-IR fundus images each with at least 49 OCT scans, and 16 biomarkers, along with 4 clinical labels and a disease diagnosis of DR or DME. In total, there are 96 eyes' data averaged over a period of at least two years with each eye treated for an average of 66 weeks and 7 injections. We benchmark the utility of OLIVES dataset for ophthalmic data as well as provide benchmarks and concrete research directions for core and emerging machine learning paradigms within medical image analysis.
Automated Urban Planning aware Spatial Hierarchies and Human Instructions
Sep 26, 2022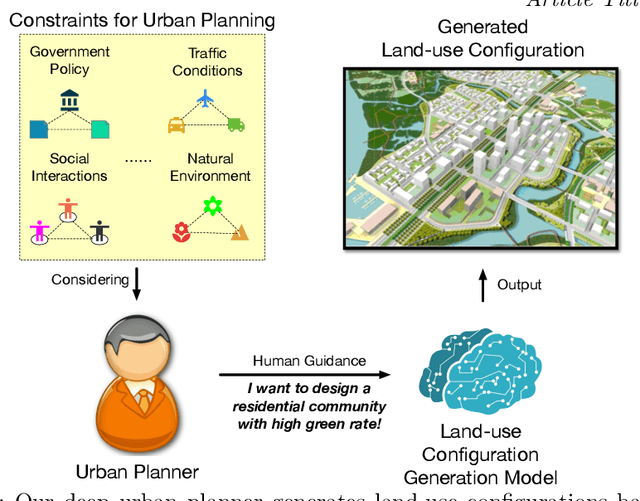
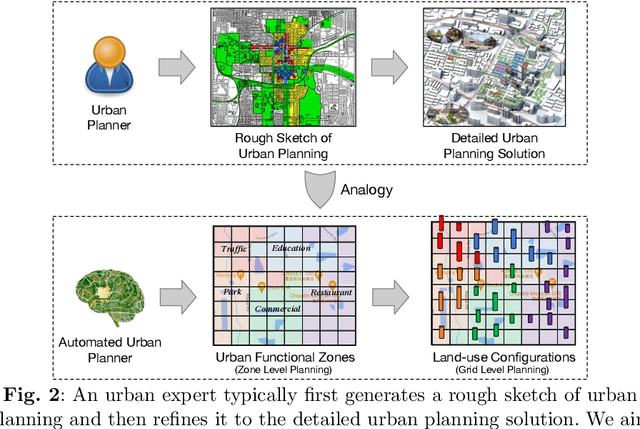
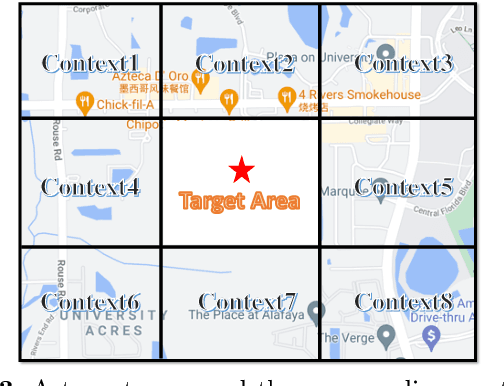
Traditional urban planning demands urban experts to spend considerable time and effort producing an optimal urban plan under many architectural constraints. The remarkable imaginative ability of deep generative learning provides hope for renovating urban planning. While automated urban planners have been examined, they are constrained because of the following: 1) neglecting human requirements in urban planning; 2) omitting spatial hierarchies in urban planning, and 3) lacking numerous urban plan data samples. To overcome these limitations, we propose a novel, deep, human-instructed urban planner. In the preliminary work, we formulate it into an encoder-decoder paradigm. The encoder is to learn the information distribution of surrounding contexts, human instructions, and land-use configuration. The decoder is to reconstruct the land-use configuration and the associated urban functional zones. The reconstruction procedure will capture the spatial hierarchies between functional zones and spatial grids. Meanwhile, we introduce a variational Gaussian mechanism to mitigate the data sparsity issue. Even though early work has led to good results, the performance of generation is still unstable because the way spatial hierarchies are captured may lead to unclear optimization directions. In this journal version, we propose a cascading deep generative framework based on generative adversarial networks (GANs) to solve this problem, inspired by the workflow of urban experts. In particular, the purpose of the first GAN is to build urban functional zones based on information from human instructions and surrounding contexts. The second GAN will produce the land-use configuration based on the functional zones that have been constructed. Additionally, we provide a conditioning augmentation module to augment data samples. Finally, we conduct extensive experiments to validate the efficacy of our work.
uChecker: Masked Pretrained Language Models as Unsupervised Chinese Spelling Checkers
Sep 15, 2022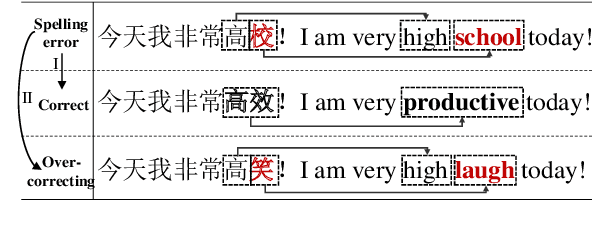


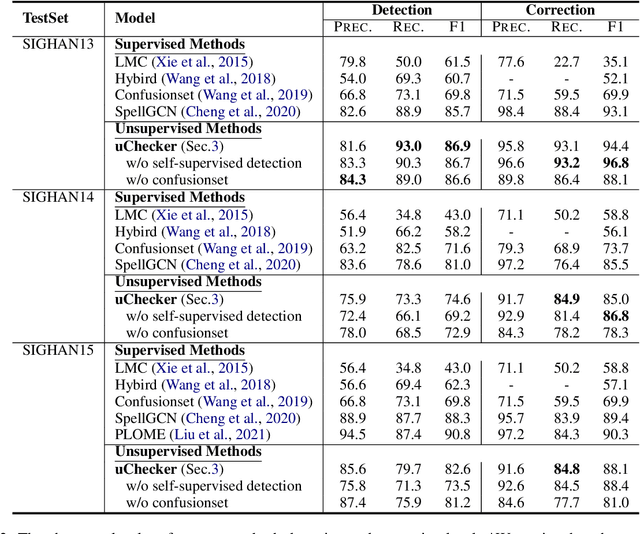
The task of Chinese Spelling Check (CSC) is aiming to detect and correct spelling errors that can be found in the text. While manually annotating a high-quality dataset is expensive and time-consuming, thus the scale of the training dataset is usually very small (e.g., SIGHAN15 only contains 2339 samples for training), therefore supervised-learning based models usually suffer the data sparsity limitation and over-fitting issue, especially in the era of big language models. In this paper, we are dedicated to investigating the \textbf{unsupervised} paradigm to address the CSC problem and we propose a framework named \textbf{uChecker} to conduct unsupervised spelling error detection and correction. Masked pretrained language models such as BERT are introduced as the backbone model considering their powerful language diagnosis capability. Benefiting from the various and flexible MASKing operations, we propose a Confusionset-guided masking strategy to fine-train the masked language model to further improve the performance of unsupervised detection and correction. Experimental results on standard datasets demonstrate the effectiveness of our proposed model uChecker in terms of character-level and sentence-level Accuracy, Precision, Recall, and F1-Measure on tasks of spelling error detection and correction respectively.
Habitat classification from satellite observations with sparse annotations
Sep 26, 2022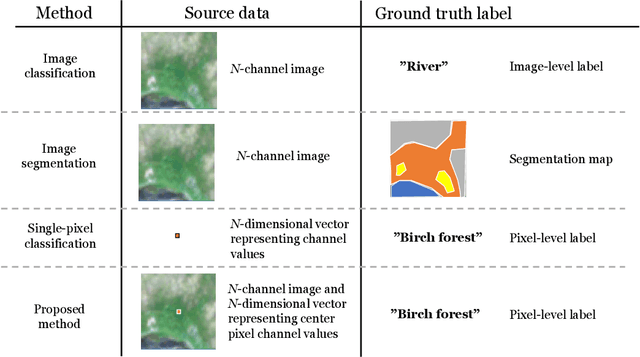

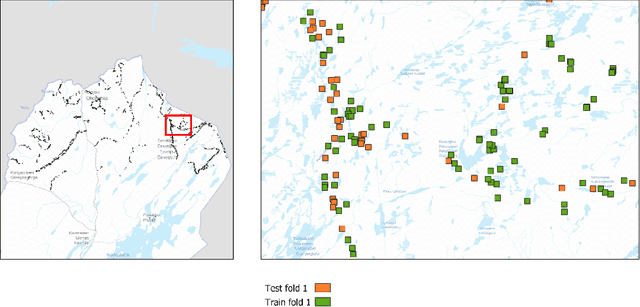
Remote sensing benefits habitat conservation by making monitoring of large areas easier compared to field surveying especially if the remote sensed data can be automatically analyzed. An important aspect of monitoring is classifying and mapping habitat types present in the monitored area. Automatic classification is a difficult task, as classes have fine-grained differences and their distributions are long-tailed and unbalanced. Usually training data used for automatic land cover classification relies on fully annotated segmentation maps, annotated from remote sensed imagery to a fairly high-level taxonomy, i.e., classes such as forest, farmland, or urban area. A challenge with automatic habitat classification is that reliable data annotation requires field-surveys. Therefore, full segmentation maps are expensive to produce, and training data is often sparse, point-like, and limited to areas accessible by foot. Methods for utilizing these limited data more efficiently are needed. We address these problems by proposing a method for habitat classification and mapping, and apply this method to classify the entire northern Finnish Lapland area into Natura2000 classes. The method is characterized by using finely-grained, sparse, single-pixel annotations collected from the field, combined with large amounts of unannotated data to produce segmentation maps. Supervised, unsupervised and semi-supervised methods are compared, and the benefits of transfer learning from a larger out-of-domain dataset are demonstrated. We propose a \ac{CNN} biased towards center pixel classification ensembled with a random forest classifier, that produces higher quality classifications than the models themselves alone. We show that cropping augmentations, test-time augmentation and semi-supervised learning can help classification even further.
Convergence Rates of Two-Time-Scale Gradient Descent-Ascent Dynamics for Solving Nonconvex Min-Max Problems
Dec 17, 2021
There are much recent interests in solving noncovnex min-max optimization problems due to its broad applications in many areas including machine learning, networked resource allocations, and distributed optimization. Perhaps, the most popular first-order method in solving min-max optimization is the so-called simultaneous (or single-loop) gradient descent-ascent algorithm due to its simplicity in implementation. However, theoretical guarantees on the convergence of this algorithm is very sparse since it can diverge even in a simple bilinear problem. In this paper, our focus is to characterize the finite-time performance (or convergence rates) of the continuous-time variant of simultaneous gradient descent-ascent algorithm. In particular, we derive the rates of convergence of this method under a number of different conditions on the underlying objective function, namely, two-sided Polyak-L ojasiewicz (PL), one-sided PL, nonconvex-strongly concave, and strongly convex-nonconcave conditions. Our convergence results improve the ones in prior works under the same conditions of objective functions. The key idea in our analysis is to use the classic singular perturbation theory and coupling Lyapunov functions to address the time-scale difference and interactions between the gradient descent and ascent dynamics. Our results on the behavior of continuous-time algorithm may be used to enhance the convergence properties of its discrete-time counterpart.
On-device Real-time Hand Gesture Recognition
Oct 29, 2021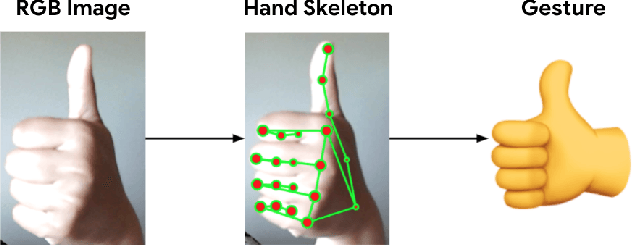
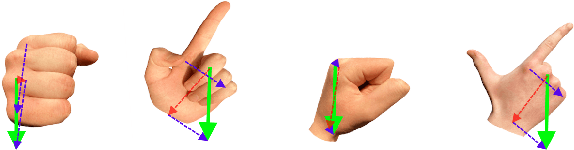

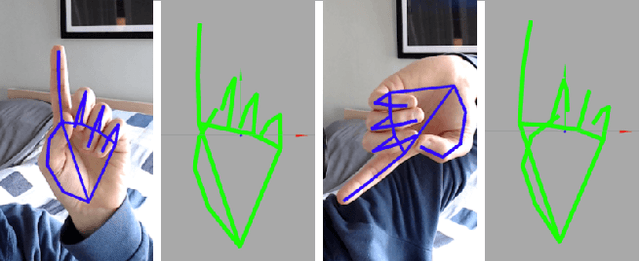
We present an on-device real-time hand gesture recognition (HGR) system, which detects a set of predefined static gestures from a single RGB camera. The system consists of two parts: a hand skeleton tracker and a gesture classifier. We use MediaPipe Hands as the basis of the hand skeleton tracker, improve the keypoint accuracy, and add the estimation of 3D keypoints in a world metric space. We create two different gesture classifiers, one based on heuristics and the other using neural networks (NN).
Programmable and Customized Intelligence for Traffic Steering in 5G Networks Using Open RAN Architectures
Sep 28, 2022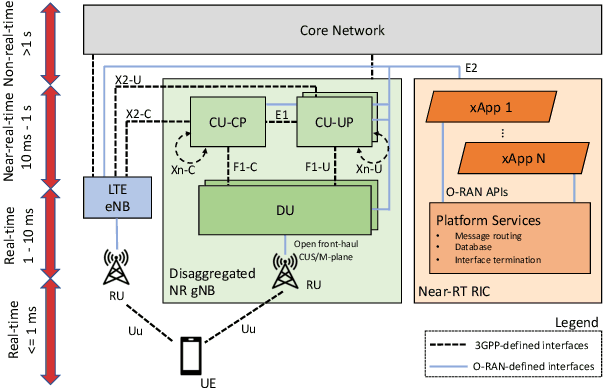

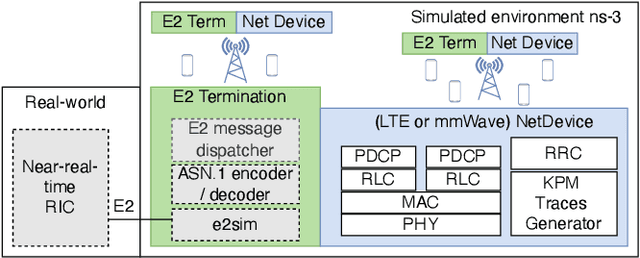
5G and beyond mobile networks will support heterogeneous use cases at an unprecedented scale, thus demanding automated control and optimization of network functionalities customized to the needs of individual users. Such fine-grained control of the Radio Access Network (RAN) is not possible with the current cellular architecture. To fill this gap, the Open RAN paradigm and its specification introduce an open architecture with abstractions that enable closed-loop control and provide data-driven, and intelligent optimization of the RAN at the user level. This is obtained through custom RAN control applications (i.e., xApps) deployed on near-real-time RAN Intelligent Controller (near-RT RIC) at the edge of the network. Despite these premises, as of today the research community lacks a sandbox to build data-driven xApps, and create large-scale datasets for effective AI training. In this paper, we address this by introducing ns-O-RAN, a software framework that integrates a real-world, production-grade near-RT RIC with a 3GPP-based simulated environment on ns-3, enabling the development of xApps and automated large-scale data collection and testing of Deep Reinforcement Learning-driven control policies for the optimization at the user-level. In addition, we propose the first user-specific O-RAN Traffic Steering (TS) intelligent handover framework. It uses Random Ensemble Mixture, combined with a state-of-the-art Convolutional Neural Network architecture, to optimally assign a serving base station to each user in the network. Our TS xApp, trained with more than 40 million data points collected by ns-O-RAN, runs on the near-RT RIC and controls its base stations. We evaluate the performance on a large-scale deployment, showing that the xApp-based handover improves throughput and spectral efficiency by an average of 50% over traditional handover heuristics, with less mobility overhead.
Learning Audio-Visual embedding for Wild Person Verification
Sep 09, 2022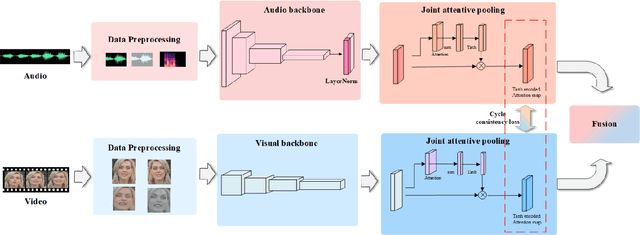
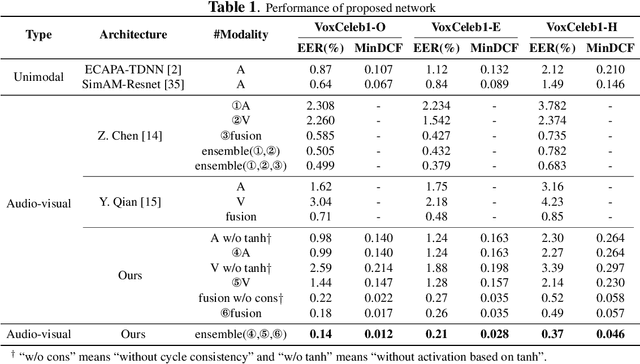
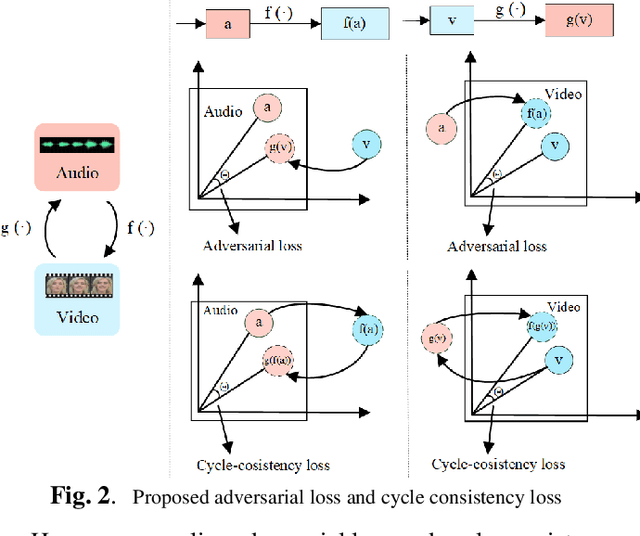
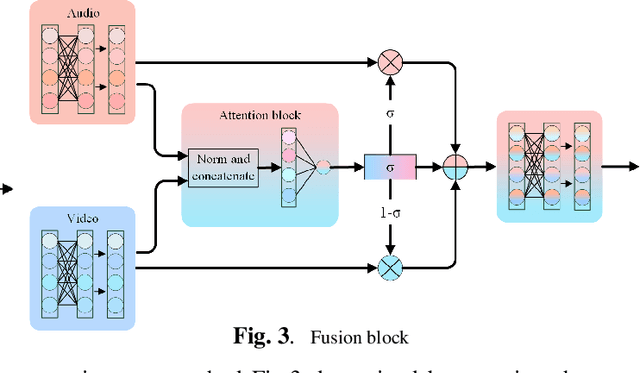
It has already been observed that audio-visual embedding can be extracted from these two modalities to gain robustness for person verification. However, the aggregator that used to generate a single utterance representation from each frame does not seem to be well explored. In this article, we proposed an audio-visual network that considers aggregator from a fusion perspective. We introduced improved attentive statistics pooling for the first time in face verification. Then we find that strong correlation exists between modalities during pooling, so joint attentive pooling is proposed which contains cycle consistency to learn the implicit inter-frame weight. Finally, fuse the modality with a gated attention mechanism. All the proposed models are trained on the VoxCeleb2 dev dataset and the best system obtains 0.18\%, 0.27\%, and 0.49\% EER on three official trail lists of VoxCeleb1 respectively, which is to our knowledge the best-published results for person verification. As an analysis, visualization maps are generated to explain how this system interact between modalities.