 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CSSAM: U-net Network for Application and Segmentation of Welding Engineering Drawings
Sep 28, 2022
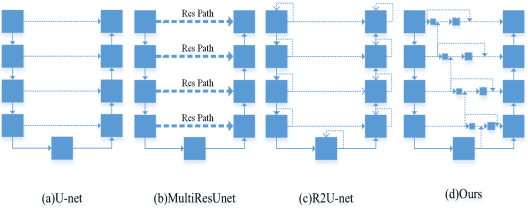
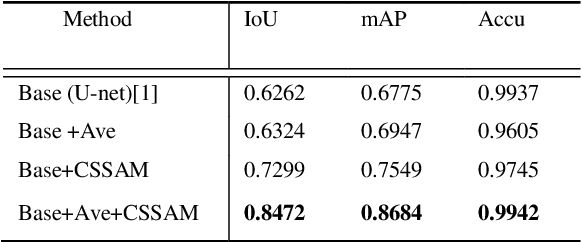
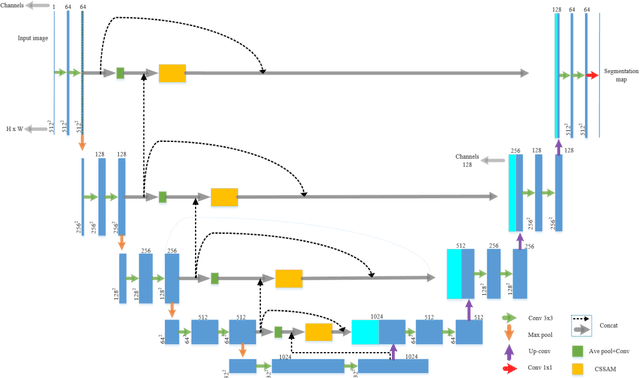

Heavy equipment manufacturing splits specific contours in drawings and cuts sheet metal to scale for welding. Currently, most of the segmentation and extraction of weld map contours is achieved manually. Its efficiency is greatly reduced. Therefore, we propose a U-net-based contour segmentation and extraction method for welding engineering drawings. The contours of the parts required for engineering drawings can be automatically divided and blanked, which significantly improves manufacturing efficiency. U-net includes an encoder-decoder, which implements end-to-end mapping through semantic differences and spatial location feature information between the encoder and decoder. While U-net excels at segmenting medical images, our extensive experiments on the Welding Structural Diagram dataset show that the classic U-Net architecture falls short in segmenting welding engineering drawings. Therefore, we design a novel Channel Spatial Sequence Attention Module (CSSAM) and improve on the classic U-net. At the same time, vertical max pooling and average horizontal pooling are proposed. Pass the pooling operation through two equal convolutions into the CSSAM module. The output and the features before pooling are fused by semantic clustering, which replaces the traditional jump structure and effectively narrows the semantic gap between the encoder and the decoder, thereby improving the segmentation performance of welding engineering drawings. We use vgg16 as the backbone network. Compared with the classic U-net, our network has good performance in engineering drawing dataset segmentation.
Active Self-Training for Weakly Supervised 3D Scene Semantic Segmentation
Sep 15, 2022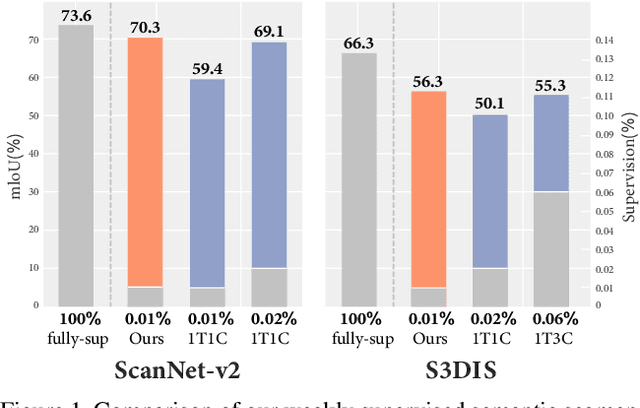
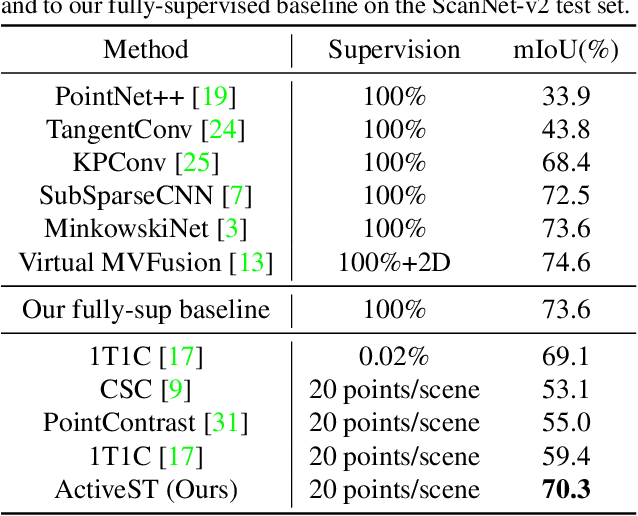
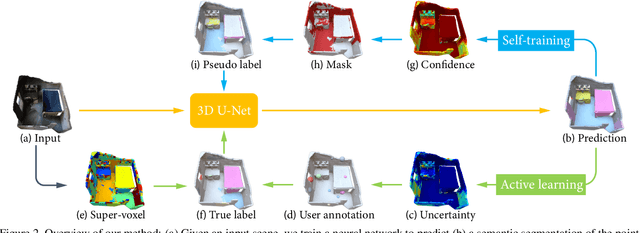
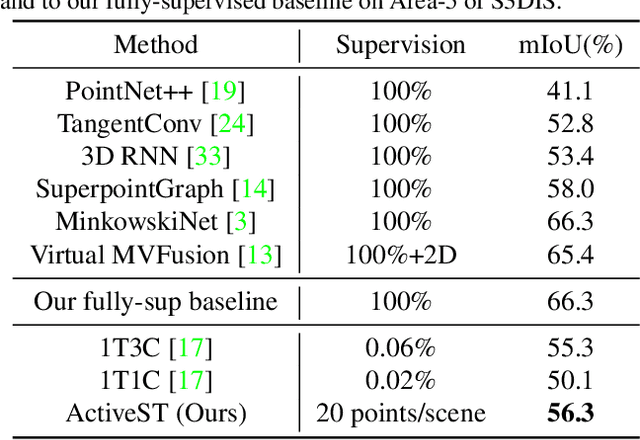
Since the preparation of labeled data for training semantic segmentation networks of point clouds is a time-consuming process, weakly supervised approaches have been introduced to learn from only a small fraction of data. These methods are typically based on learning with contrastive losses while automatically deriving per-point pseudo-labels from a sparse set of user-annotated labels. In this paper, our key observation is that the selection of what samples to annotate is as important as how these samples are used for training. Thus, we introduce a method for weakly supervised segmentation of 3D scenes that combines self-training with active learning. The active learning selects points for annotation that likely result in performance improvements to the trained model, while the self-training makes efficient use of the user-provided labels for learning the model. We demonstrate that our approach leads to an effective method that provides improvements in scene segmentation over previous works and baselines, while requiring only a small number of user annotations.
Grape Cold Hardiness Prediction via Multi-Task Learning
Sep 23, 2022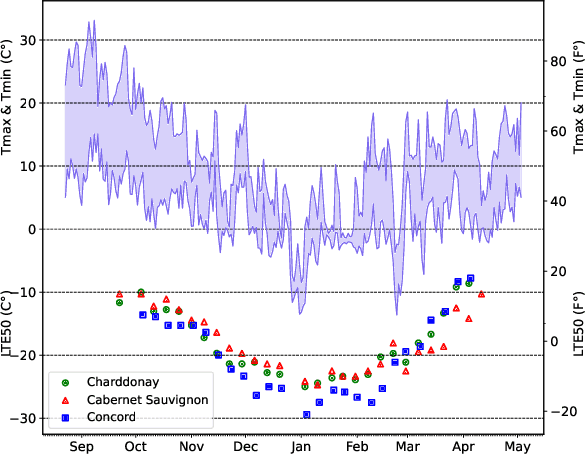
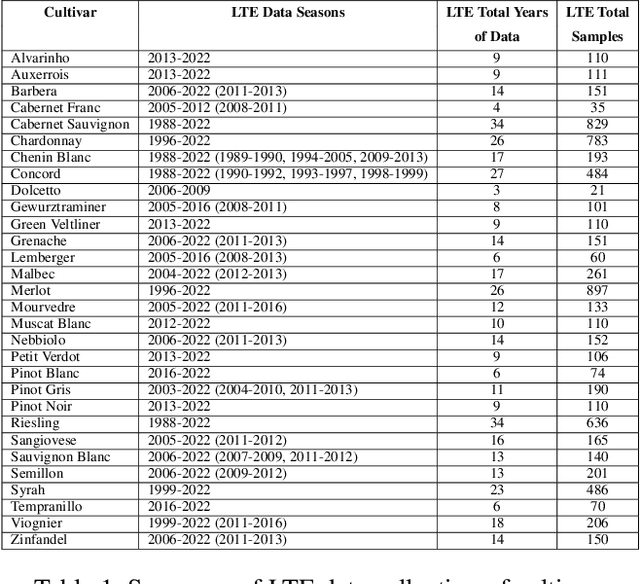
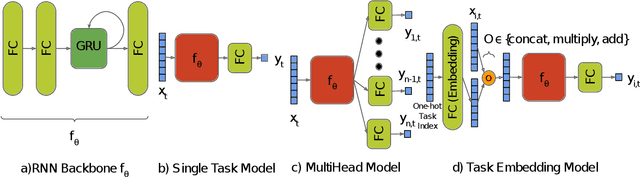
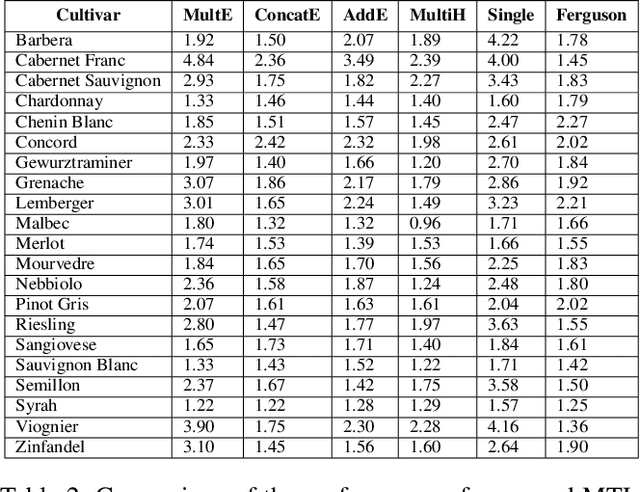
Cold temperatures during fall and spring have the potential to cause frost damage to grapevines and other fruit plants, which can significantly decrease harvest yields. To help prevent these losses, farmers deploy expensive frost mitigation measures, such as, sprinklers, heaters, and wind machines, when they judge that damage may occur. This judgment, however, is challenging because the cold hardiness of plants changes throughout the dormancy period and it is difficult to directly measure. This has led scientists to develop cold hardiness prediction models that can be tuned to different grape cultivars based on laborious field measurement data. In this paper, we study whether deep-learning models can improve cold hardiness prediction for grapes based on data that has been collected over a 30-year time period. A key challenge is that the amount of data per cultivar is highly variable, with some cultivars having only a small amount. For this purpose, we investigate the use of multi-task learning to leverage data across cultivars in order to improve prediction performance for individual cultivars. We evaluate a number of multi-task learning approaches and show that the highest performing approach is able to significantly improve over learning for single cultivars and outperforms the current state-of-the-art scientific model for most cultivars.
Performance Assessment of different Machine Learning Algorithm for Life-Time Prediction of Solder Joints based on Synthetic Data
Apr 13, 2022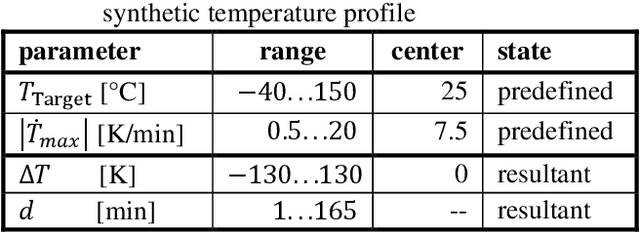
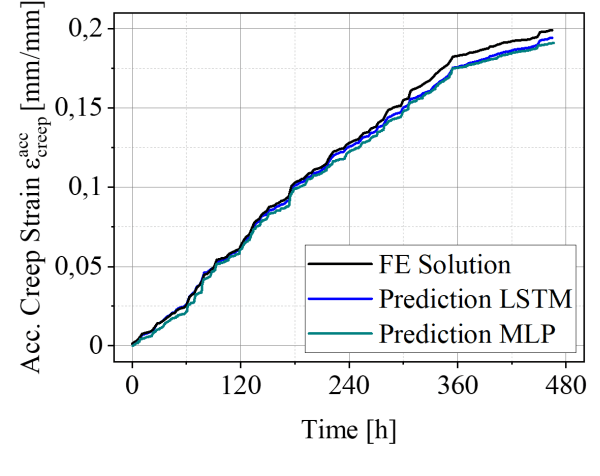
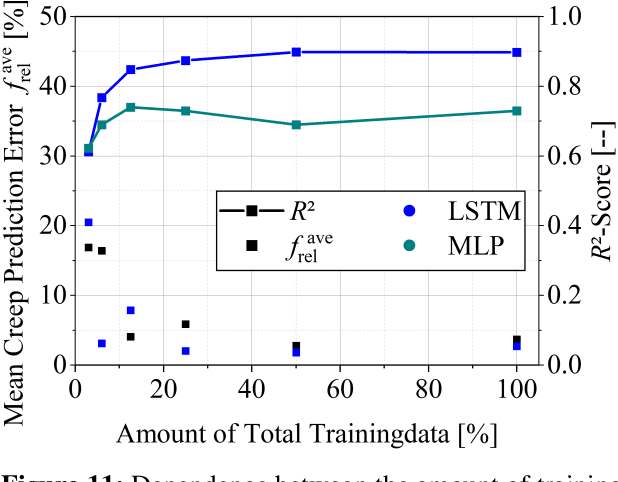

This paper proposes a computationally efficient methodology to predict the damage progression in solder contacts of electronic components using temperature-time curves. For this purpose, two machine learning algorithms, a Multilayer Perceptron and a Long Short-Term Memory network, are trained and compared with respect to their prediction accuracy and the required amount of training data. The training is performed using synthetic, normally distributed data that is realistic for automotive applications. A finite element model of a simple bipolar chip resistor in surface mount technology configuration is used to numerically compute the synthetic data. As a result, both machine learning algorithms show a relevant accuracy for the prediction of accumulated creep strains. With a training data length of 350 hours (12.5% of the available training data), both models show a constantly good fitting performance of $R^2$ of 0.72 for the Multilayer Perceptron and $R^2$ of 0.87 for the Long Short-Term Memory network. The prediction errors of the accumulated creep strains are less than 10% with an amount of 350 hours training data and decreases to less than 5 % when using further data. Therefore, both approaches are promising for the lifetime prediction directly on the electronic device.
Phase Difference based Doppler Disambiguation Method for TDM-MIMOFMCW Radars
Aug 05, 2022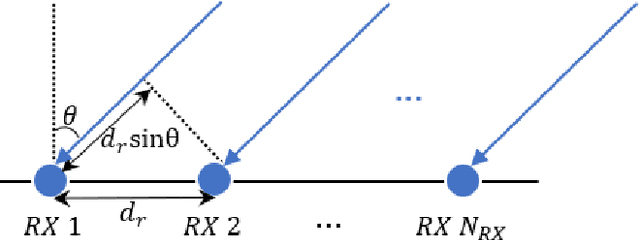
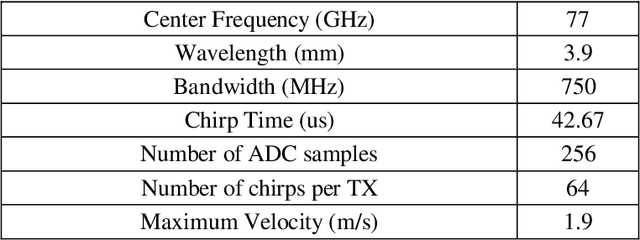
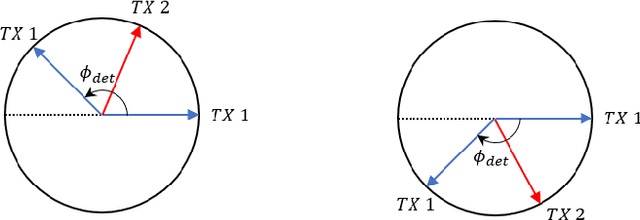
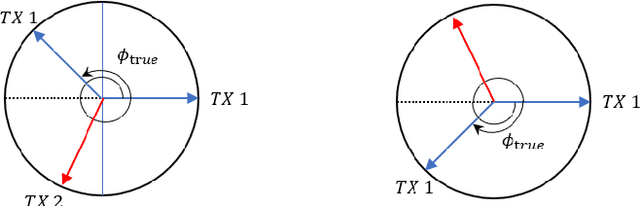
State-of-the-art automotive radar sensors use a Mutliple-Input Mutiple-Output (MIMO) approach to obtain a better angular resolution. Time-Division Multiplexing (TDM) scheme is commonly applied to realize the orthogonality in time at the transmitter. Apart from its simplicity in implementation, TDM scheme has the drawback of a reduced maximum unambiguous Doppler proportional to the number of transmitters. In this paper, a phase difference based Doppler disambiguation method is proposed to regain the maximum unambiguous Doppler which is equivalent to only one transmitter. This method works well when the number of transmitters is large. The proposed method is demonstrated with simulation and measurement data.
Simplifying Model-based RL: Learning Representations, Latent-space Models, and Policies with One Objective
Sep 18, 2022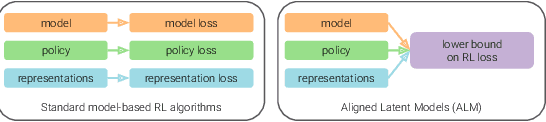
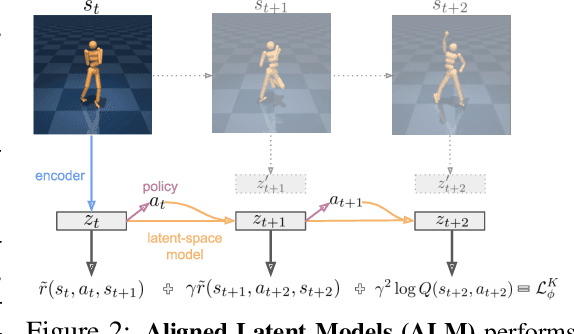
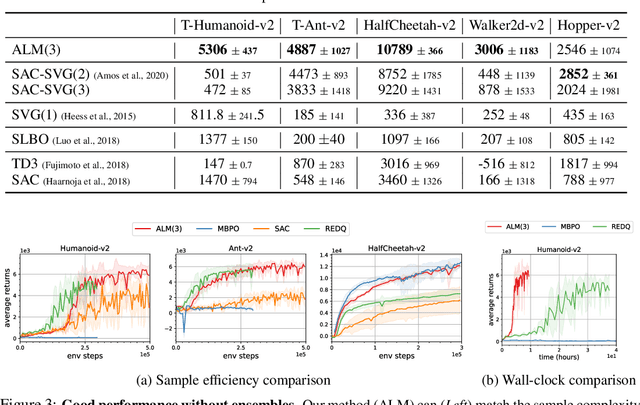
While reinforcement learning (RL) methods that learn an internal model of the environment have the potential to be more sample efficient than their model-free counterparts, learning to model raw observations from high dimensional sensors can be challenging. Prior work has addressed this challenge by learning low-dimensional representation of observations through auxiliary objectives, such as reconstruction or value prediction. However, the alignment between these auxiliary objectives and the RL objective is often unclear. In this work, we propose a single objective which jointly optimizes a latent-space model and policy to achieve high returns while remaining self-consistent. This objective is a lower bound on expected returns. Unlike prior bounds for model-based RL on policy exploration or model guarantees, our bound is directly on the overall RL objective. We demonstrate that the resulting algorithm matches or improves the sample-efficiency of the best prior model-based and model-free RL methods. While such sample efficient methods typically are computationally demanding, our method attains the performance of SAC in about 50\% less wall-clock time.
Uncertainty-Aware Time-to-Event Prediction using Deep Kernel Accelerated Failure Time Models
Jul 26, 2021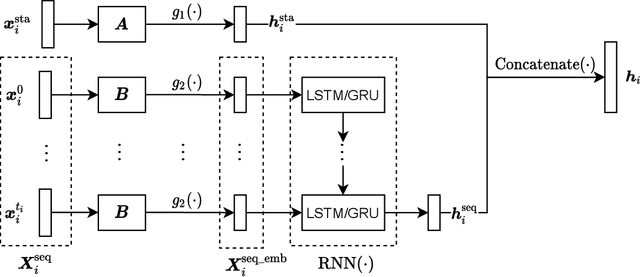
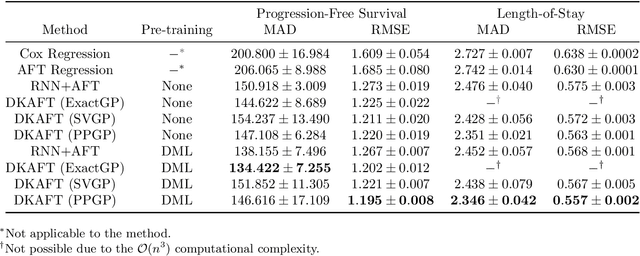
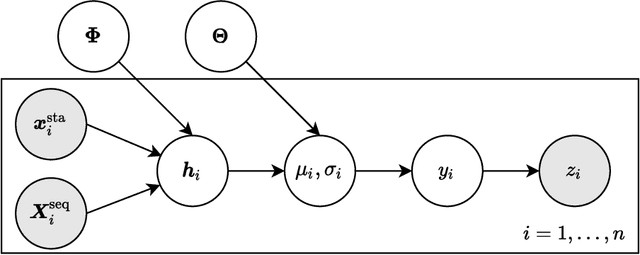

Recurrent neural network based solutions are increasingly being used in the analysis of longitudinal Electronic Health Record data. However, most works focus on prediction accuracy and neglect prediction uncertainty. We propose Deep Kernel Accelerated Failure Time models for the time-to-event prediction task, enabling uncertainty-awareness of the prediction by a pipeline of a recurrent neural network and a sparse Gaussian Process. Furthermore, a deep metric learning based pre-training step is adapted to enhance the proposed model. Our model shows better point estimate performance than recurrent neural network based baselines in experiments on two real-world datasets. More importantly, the predictive variance from our model can be used to quantify the uncertainty estimates of the time-to-event prediction: Our model delivers better performance when it is more confident in its prediction. Compared to related methods, such as Monte Carlo Dropout, our model offers better uncertainty estimates by leveraging an analytical solution and is more computationally efficient.
A More Stable Accelerated Gradient Method Inspired by Continuous-Time Perspective
Dec 09, 2021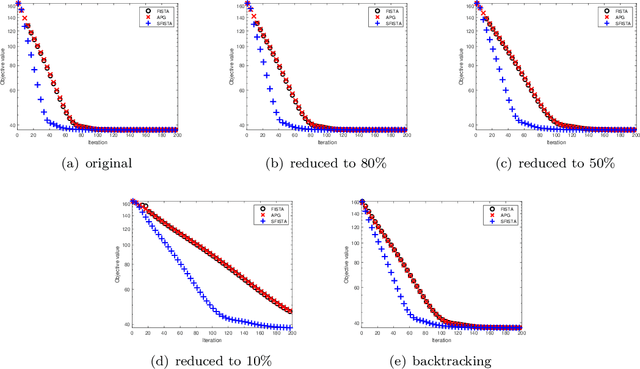
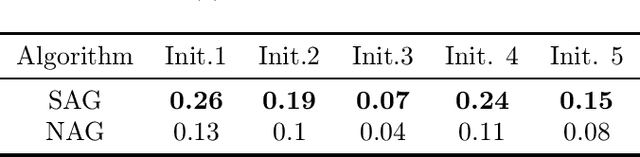
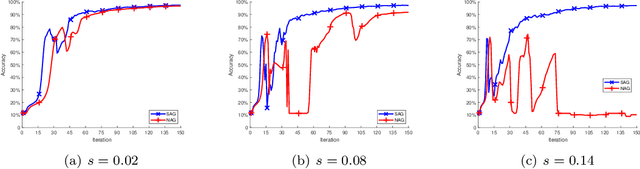
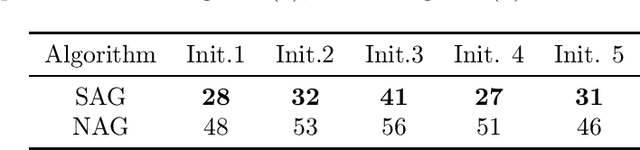
Nesterov's accelerated gradient method (NAG) is widely used in problems with machine learning background including deep learning, and is corresponding to a continuous-time differential equation. From this connection, the property of the differential equation and its numerical approximation can be investigated to improve the accelerated gradient method. In this work we present a new improvement of NAG in terms of stability inspired by numerical analysis. We give the precise order of NAG as a numerical approximation of its continuous-time limit and then present a new method with higher order. We show theoretically that our new method is more stable than NAG for large step size. Experiments of matrix completion and handwriting digit recognition demonstrate that the stability of our new method is better. Furthermore, better stability leads to higher computational speed in experiments.
A Taxonomy of Recurrent Learning Rules
Jul 23, 2022
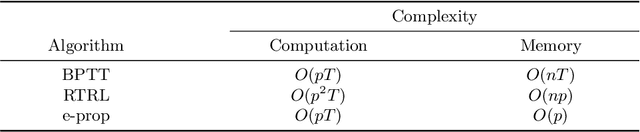
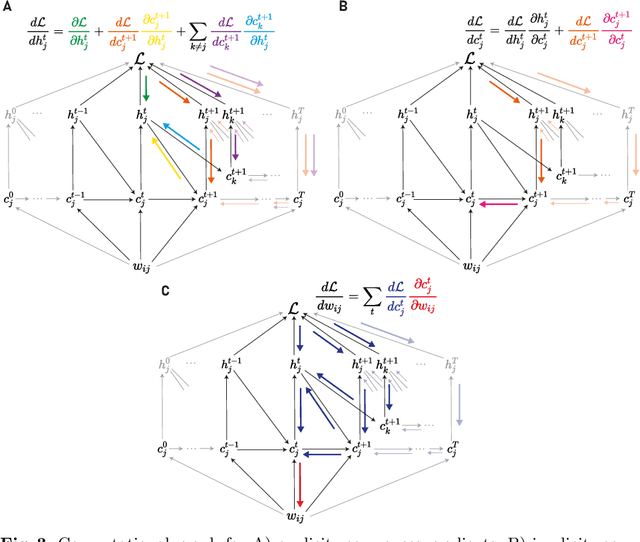
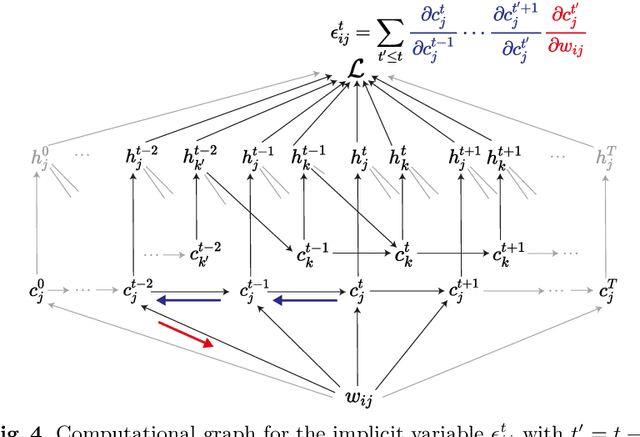
Backpropagation through time (BPTT) is the de facto standard for training recurrent neural networks (RNNs), but it is non-causal and non-local. Real-time recurrent learning is a causal alternative, but it is highly inefficient. Recently, e-prop was proposed as a causal, local, and efficient practical alternative to these algorithms, providing an approximation of the exact gradient by radically pruning the recurrent dependencies carried over time. Here, we derive RTRL from BPTT using a detailed notation bringing intuition and clarification to how they are connected. Furthermore, we frame e-prop within in the picture, formalising what it approximates. Finally, we derive a family of algorithms of which e-prop is a special case.
Investigation of a Machine learning methodology for the SKA pulsar search pipeline
Sep 09, 2022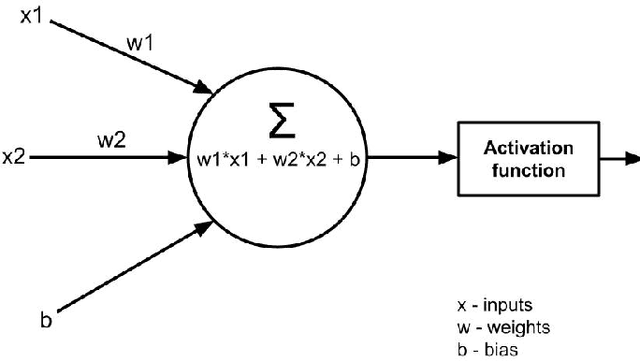
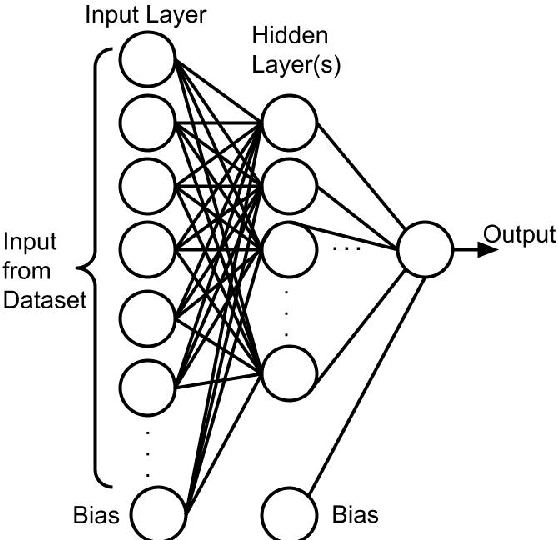
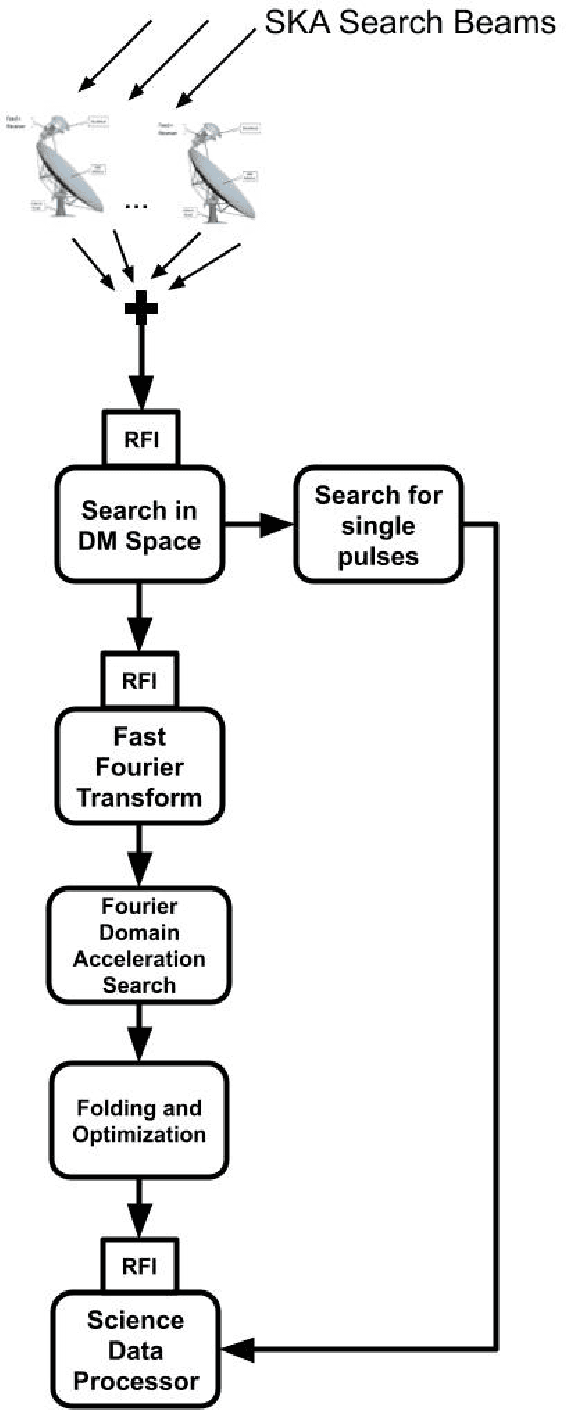
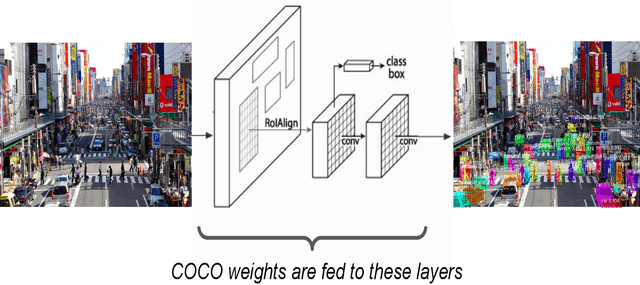
The SKA pulsar search pipeline will be used for real time detection of pulsars. Modern radio telescopes such as SKA will be generating petabytes of data in their full scale of operation. Hence experience-based and data-driven algorithms become indispensable for applications such as candidate detection. Here we describe our findings from testing a state of the art object detection algorithm called Mask R-CNN to detect candidate signatures in the SKA pulsar search pipeline. We have trained the Mask R-CNN model to detect candidate images. A custom annotation tool was developed to mark the regions of interest in large datasets efficiently. We have successfully demonstrated this algorithm by detecting candidate signatures on a simulation dataset. The paper presents details of this work with a highlight on the future prospects.