 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMR-LLM: Industrial Multi-Robot Task Planning and Program Generation using Large Language Models
Mar 03, 2026In modern industrial production, multiple robots often collaborate to complete complex manufacturing tasks. Large language models (LLMs), with their strong reasoning capabilities, have shown potential in coordinating robots for simple household and manipulation tasks. However, in industrial scenarios, stricter sequential constraints and more complex dependencies within tasks present new challenges for LLMs. To address this, we propose IMR-LLM, a novel LLM-driven Industrial Multi-Robot task planning and program generation framework. Specifically, we utilize LLMs to assist in constructing disjunctive graphs and employ deterministic solving methods to obtain a feasible and efficient high-level task plan. Based on this, we use a process tree to guide LLMs to generate executable low-level programs. Additionally, we create IMR-Bench, a challenging benchmark that encompasses multi-robot industrial tasks across three levels of complexity. Experimental results indicate that our method significantly surpasses existing methods across all evaluation metrics.
By-Example Synthesis of Vector Textures
Jan 23, 2025We propose a new method for synthesizing an arbitrarily sized novel vector texture given a single raster exemplar. Our method first segments the exemplar to extract the primary textons, and then clusters them based on visual similarity. We then compute a descriptor to capture each texton's neighborhood which contains the inter-category relationships that are used at synthesis time. Next, we use a simple procedure to both extract and place the secondary textons behind the primary polygons. Finally, our method constructs a gradient field for the background which is defined by a set of data points and colors. The color of the secondary polygons are also adjusted to better match the gradient field. To compare our work with other methods, we use a wide range of perceptual-based metrics.
Diverse Part Synthesis for 3D Shape Creation
Jan 17, 2024



Methods that use neural networks for synthesizing 3D shapes in the form of a part-based representation have been introduced over the last few years. These methods represent shapes as a graph or hierarchy of parts and enable a variety of applications such as shape sampling and reconstruction. However, current methods do not allow easily regenerating individual shape parts according to user preferences. In this paper, we investigate techniques that allow the user to generate multiple, diverse suggestions for individual parts. Specifically, we experiment with multimodal deep generative models that allow sampling diverse suggestions for shape parts and focus on models which have not been considered in previous work on shape synthesis. To provide a comparative study of these techniques, we introduce a method for synthesizing 3D shapes in a part-based representation and evaluate all the part suggestion techniques within this synthesis method. In our method, which is inspired by previous work, shapes are represented as a set of parts in the form of implicit functions which are then positioned in space to form the final shape. Synthesis in this representation is enabled by a neural network architecture based on an implicit decoder and a spatial transformer. We compare the various multimodal generative models by evaluating their performance in generating part suggestions. Our contribution is to show with qualitative and quantitative evaluations which of the new techniques for multimodal part generation perform the best and that a synthesis method based on the top-performing techniques allows the user to more finely control the parts that are generated in the 3D shapes while maintaining high shape fidelity when reconstructing shapes.
Active Self-Training for Weakly Supervised 3D Scene Semantic Segmentation
Sep 15, 2022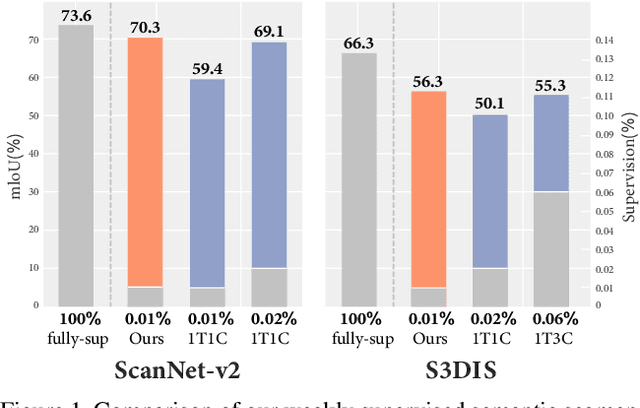
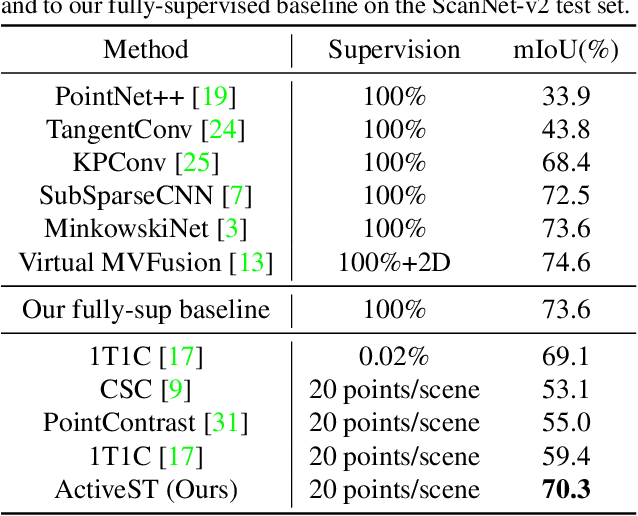
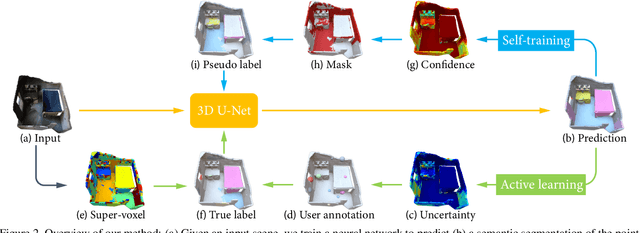
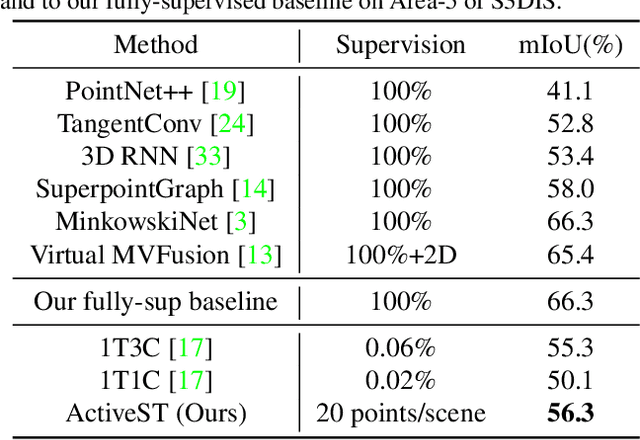
Since the preparation of labeled data for training semantic segmentation networks of point clouds is a time-consuming process, weakly supervised approaches have been introduced to learn from only a small fraction of data. These methods are typically based on learning with contrastive losses while automatically deriving per-point pseudo-labels from a sparse set of user-annotated labels. In this paper, our key observation is that the selection of what samples to annotate is as important as how these samples are used for training. Thus, we introduce a method for weakly supervised segmentation of 3D scenes that combines self-training with active learning. The active learning selects points for annotation that likely result in performance improvements to the trained model, while the self-training makes efficient use of the user-provided labels for learning the model. We demonstrate that our approach leads to an effective method that provides improvements in scene segmentation over previous works and baselines, while requiring only a small number of user annotations.
AutoPoly: Predicting a Polygonal Mesh Construction Sequence from a Silhouette Image
Mar 29, 2022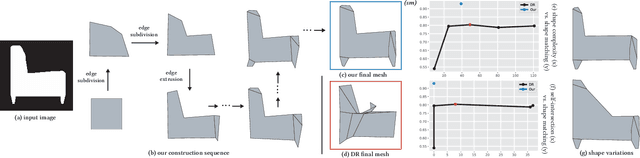
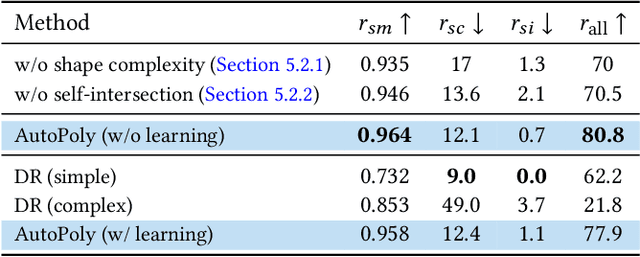
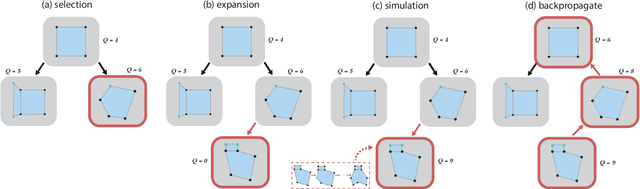
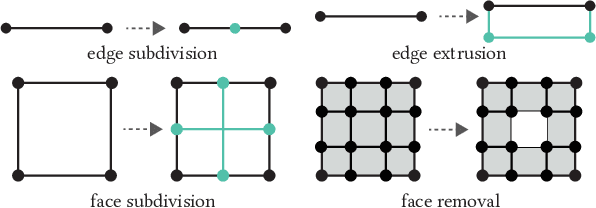
Polygonal modeling is a core task of content creation in Computer Graphics. The complexity of modeling, in terms of the number and the order of operations and time required to execute them makes it challenging to learn and execute. Our goal is to automatically derive a polygonal modeling sequence for a given target. Then, one can learn polygonal modeling by observing the resulting sequence and also expedite the modeling process by starting from the auto-generated result. As a starting point for building a system for 3D modeling in the future, we tackle the 2D shape modeling problem and present AutoPoly, a hybrid method that generates a polygonal mesh construction sequence from a silhouette image. The key idea of our method is the use of the Monte Carlo tree search (MCTS) algorithm and differentiable rendering to separately predict sequential topological actions and geometric actions. Our hybrid method can alter topology, whereas the recently proposed inverse shape estimation methods using differentiable rendering can only handle a fixed topology. Our novel reward function encourages MCTS to select topological actions that lead to a simpler shape without self-intersection. We further designed two deep learning-based methods to improve the expansion and simulation steps in the MCTS search process: an $n$-step "future action prediction" network (nFAP-Net) to generate candidates for potential topological actions, and a shape warping network (WarpNet) to predict polygonal shapes given the predicted rendered images and topological actions. We demonstrate the efficiency of our method on 2D polygonal shapes of multiple man-made object categories.
Shape-driven Coordinate Ordering for Star Glyph Sets via Reinforcement Learning
Mar 03, 2021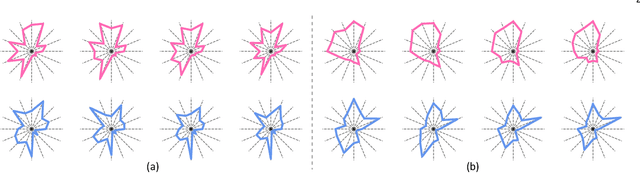
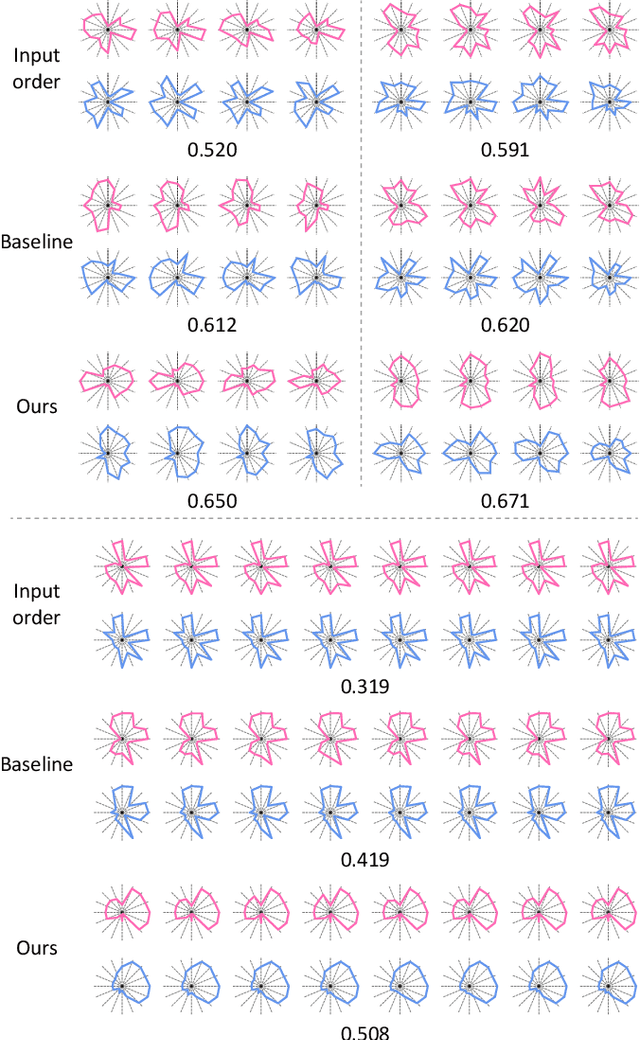
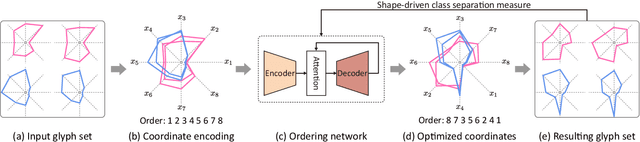
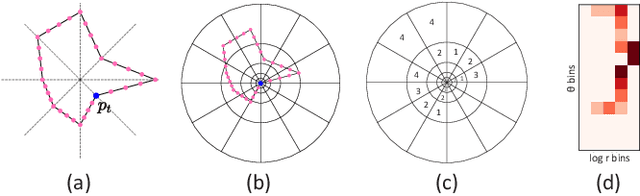
We present a neural optimization model trained with reinforcement learning to solve the coordinate ordering problem for sets of star glyphs. Given a set of star glyphs associated to multiple class labels, we propose to use shape context descriptors to measure the perceptual distance between pairs of glyphs, and use the derived silhouette coefficient to measure the perception of class separability within the entire set. To find the optimal coordinate order for the given set, we train a neural network using reinforcement learning to reward orderings with high silhouette coefficients. The network consists of an encoder and a decoder with an attention mechanism. The encoder employs a recurrent neural network (RNN) to encode input shape and class information, while the decoder together with the attention mechanism employs another RNN to output a sequence with the new coordinate order. In addition, we introduce a neural network to efficiently estimate the similarity between shape context descriptors, which allows to speed up the computation of silhouette coefficients and thus the training of the axis ordering network. Two user studies demonstrate that the orders provided by our method are preferred by users for perceiving class separation. We tested our model on different settings to show its robustness and generalization abilities and demonstrate that it allows to order input sets with unseen data size, data dimension, or number of classes. We also demonstrate that our model can be adapted to coordinate ordering of other types of plots such as RadViz by replacing the proposed shape-aware silhouette coefficient with the corresponding quality metric to guide network training.
Predictive and Generative Neural Networks for Object Functionality
Jun 28, 2020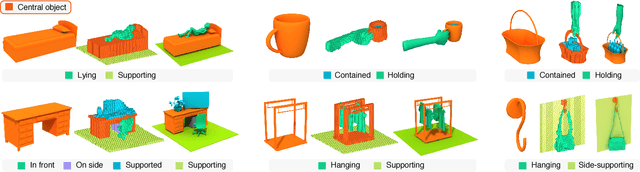

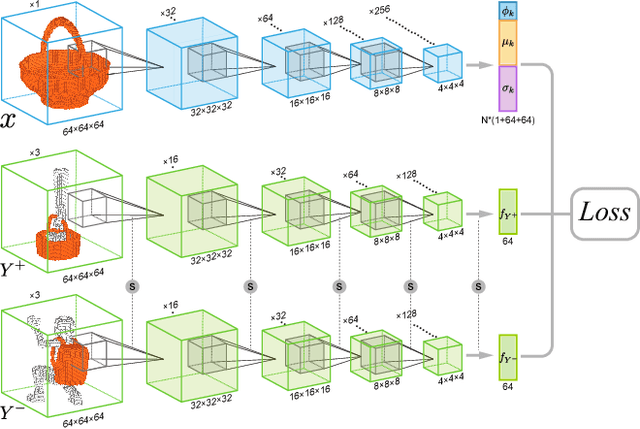
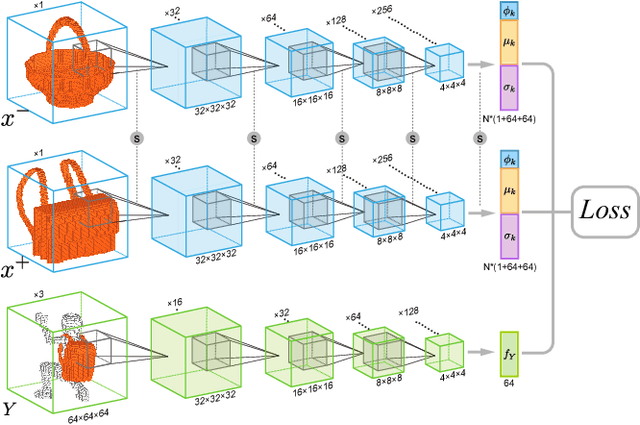
Humans can predict the functionality of an object even without any surroundings, since their knowledge and experience would allow them to "hallucinate" the interaction or usage scenarios involving the object. We develop predictive and generative deep convolutional neural networks to replicate this feat. Specifically, our work focuses on functionalities of man-made 3D objects characterized by human-object or object-object interactions. Our networks are trained on a database of scene contexts, called interaction contexts, each consisting of a central object and one or more surrounding objects, that represent object functionalities. Given a 3D object in isolation, our functional similarity network (fSIM-NET), a variation of the triplet network, is trained to predict the functionality of the object by inferring functionality-revealing interaction contexts. fSIM-NET is complemented by a generative network (iGEN-NET) and a segmentation network (iSEG-NET). iGEN-NET takes a single voxelized 3D object with a functionality label and synthesizes a voxelized surround, i.e., the interaction context which visually demonstrates the corresponding functionality. iSEG-NET further separates the interacting objects into different groups according to their interaction types.
* Accepted to SIGGRAPH 2018, project page at https://vcc.tech/research/2018/ICON4
RPM-Net: Recurrent Prediction of Motion and Parts from Point Cloud
Jun 26, 2020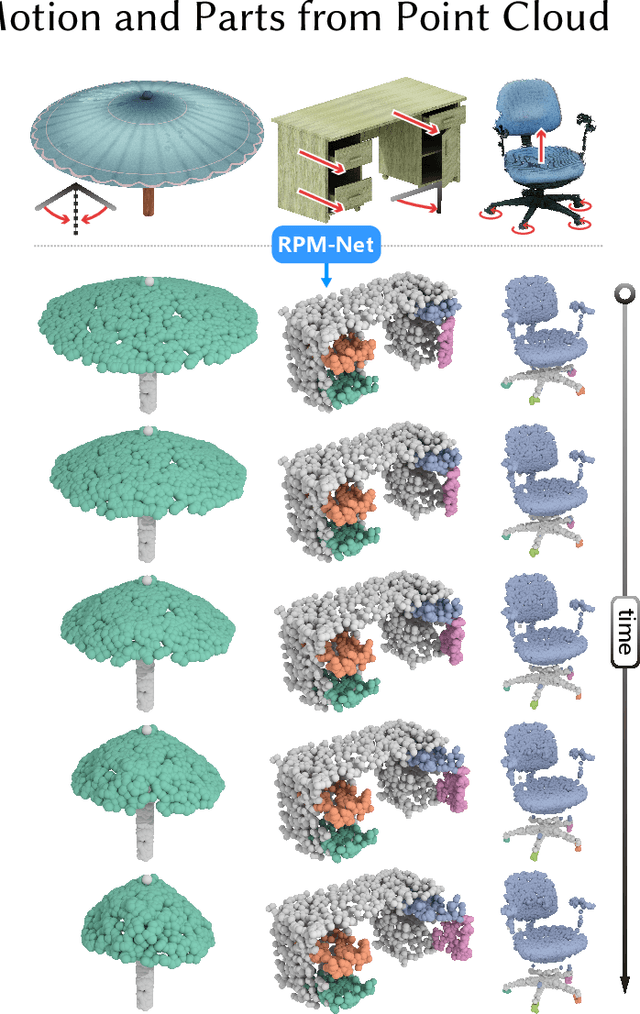
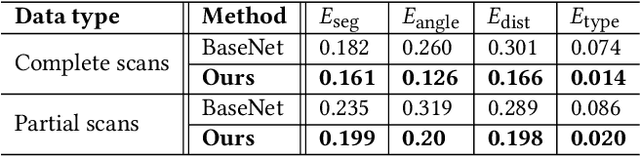
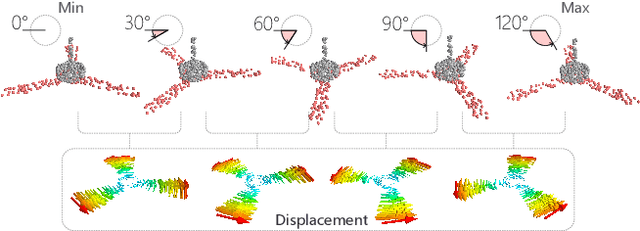
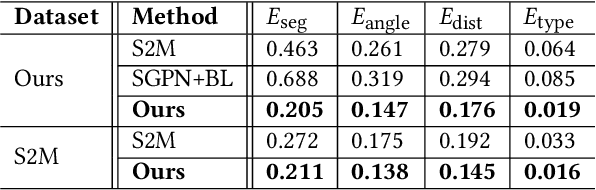
We introduce RPM-Net, a deep learning-based approach which simultaneously infers movable parts and hallucinates their motions from a single, un-segmented, and possibly partial, 3D point cloud shape. RPM-Net is a novel Recurrent Neural Network (RNN), composed of an encoder-decoder pair with interleaved Long Short-Term Memory (LSTM) components, which together predict a temporal sequence of pointwise displacements for the input point cloud. At the same time, the displacements allow the network to learn movable parts, resulting in a motion-based shape segmentation. Recursive applications of RPM-Net on the obtained parts can predict finer-level part motions, resulting in a hierarchical object segmentation. Furthermore, we develop a separate network to estimate part mobilities, e.g., per-part motion parameters, from the segmented motion sequence. Both networks learn deep predictive models from a training set that exemplifies a variety of mobilities for diverse objects. We show results of simultaneous motion and part predictions from synthetic and real scans of 3D objects exhibiting a variety of part mobilities, possibly involving multiple movable parts.
* Accepted to SIGGRAPH Asia 2019, project page at https://vcc.tech/research/2019/RPMNet
Graph2Plan: Learning Floorplan Generation from Layout Graphs
Apr 27, 2020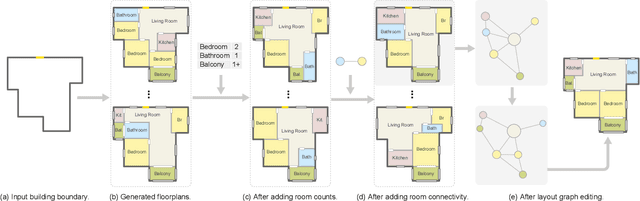
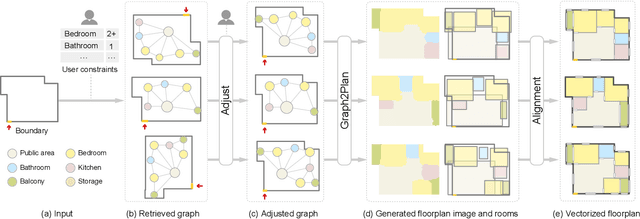
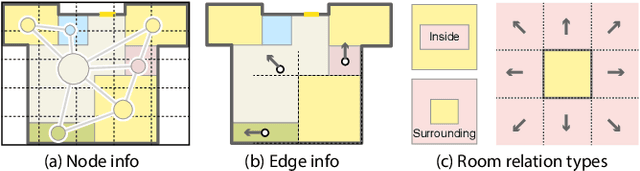
We introduce a learning framework for automated floorplan generation which combines generative modeling using deep neural networks and user-in-the-loop designs to enable human users to provide sparse design constraints. Such constraints are represented by a layout graph. The core component of our learning framework is a deep neural network, Graph2Plan, which converts a layout graph, along with a building boundary, into a floorplan that fulfills both the layout and boundary constraints. Given an input building boundary, we allow a user to specify room counts and other layout constraints, which are used to retrieve a set of floorplans, with their associated layout graphs, from a database. For each retrieved layout graph, along with the input boundary, Graph2Plan first generates a corresponding raster floorplan image, and then a refined set of boxes representing the rooms. Graph2Plan is trained on RPLAN, a large-scale dataset consisting of 80K annotated floorplans. The network is mainly based on convolutional processing over both the layout graph, via a graph neural network (GNN), and the input building boundary, as well as the raster floorplan images, via conventional image convolution.