 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ros2_tracing: Multipurpose Low-Overhead Framework for Real-Time Tracing of ROS 2
Jan 02, 2022
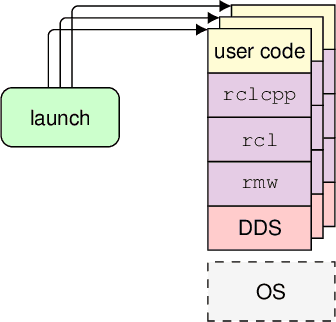
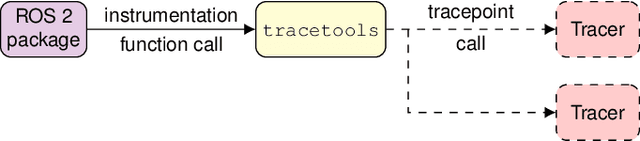
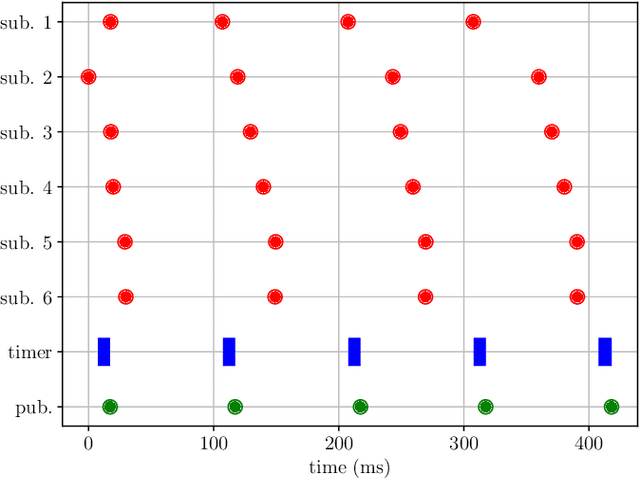
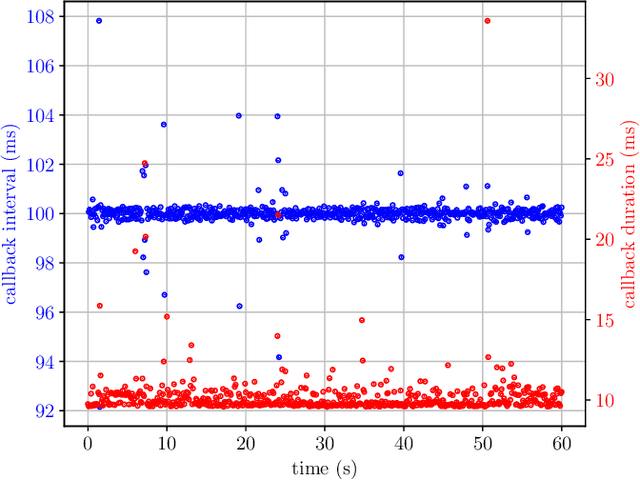
Testing and debugging have become major obstacles for robot software development, because of high system complexity and dynamic environments. Standard, middleware-based data recording does not provide sufficient information on internal computation and performance bottlenecks. Other existing methods also target very specific problems and thus cannot be used for multipurpose analysis. Moreover, they are not suitable for real-time applications. In this paper, we present ros2_tracing, a collection of flexible tracing tools and multipurpose instrumentation for ROS 2. It allows collecting runtime execution information on real-time distributed systems, using the low-overhead LTTng tracer. Tools also integrate tracing into the invaluable ROS 2 orchestration system and other usability tools. A message latency experiment shows that the end-to-end message latency overhead, when enabling all ROS 2 instrumentation, is below 0.0055 ms, which we believe is suitable for production real-time systems. ROS 2 execution information obtained using ros2_tracing can be combined with trace data from the operating system, enabling a wider range of precise analyses, that help understand an application execution, to find the cause of performance bottlenecks and other issues. The source code is available at: https://gitlab.com/ros-tracing/ros2_tracing.
Learning Video-independent Eye Contact Segmentation from In-the-Wild Videos
Oct 05, 2022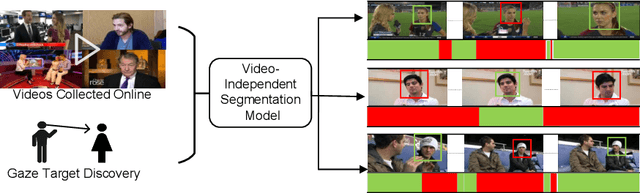

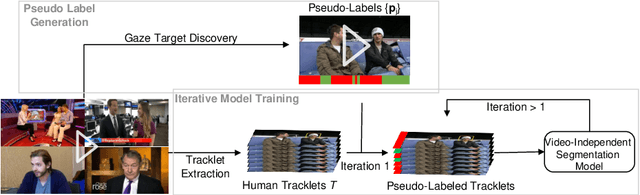
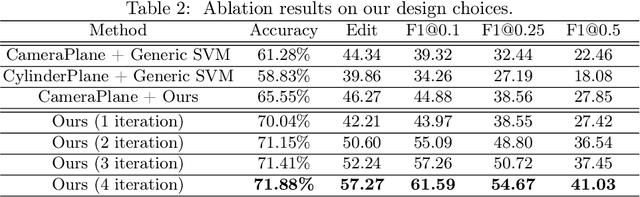
Human eye contact is a form of non-verbal communication and can have a great influence on social behavior. Since the location and size of the eye contact targets vary across different videos, learning a generic video-independent eye contact detector is still a challenging task. In this work, we address the task of one-way eye contact detection for videos in the wild. Our goal is to build a unified model that can identify when a person is looking at his gaze targets in an arbitrary input video. Considering that this requires time-series relative eye movement information, we propose to formulate the task as a temporal segmentation. Due to the scarcity of labeled training data, we further propose a gaze target discovery method to generate pseudo-labels for unlabeled videos, which allows us to train a generic eye contact segmentation model in an unsupervised way using in-the-wild videos. To evaluate our proposed approach, we manually annotated a test dataset consisting of 52 videos of human conversations. Experimental results show that our eye contact segmentation model outperforms the previous video-dependent eye contact detector and can achieve 71.88% framewise accuracy on our annotated test set. Our code and evaluation dataset are available at https://github.com/ut-vision/Video-Independent-ECS.
Rethinking Personalized Ranking at Pinterest: An End-to-End Approach
Sep 18, 2022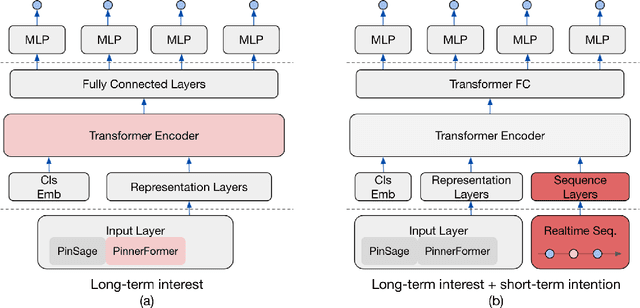
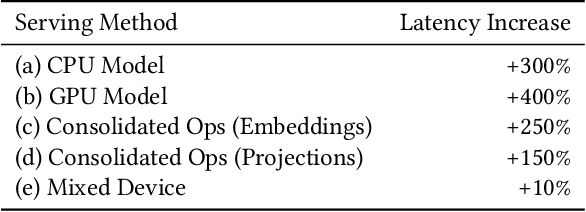
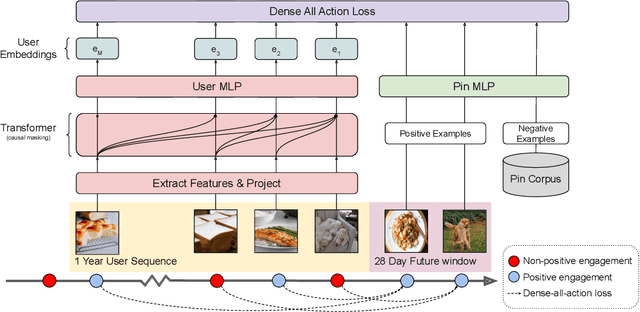

In this work, we present our journey to revolutionize the personalized recommendation engine through end-to-end learning from raw user actions. We encode user's long-term interest in Pinner- Former, a user embedding optimized for long-term future actions via a new dense all-action loss, and capture user's short-term intention by directly learning from the real-time action sequences. We conducted both offline and online experiments to validate the performance of the new model architecture, and also address the challenge of serving such a complex model using mixed CPU/GPU setup in production. The proposed system has been deployed in production at Pinterest and has delivered significant online gains across organic and Ads applications.
Drone Detection and Tracking in Real-Time by Fusion of Different Sensing Modalities
Jul 05, 2022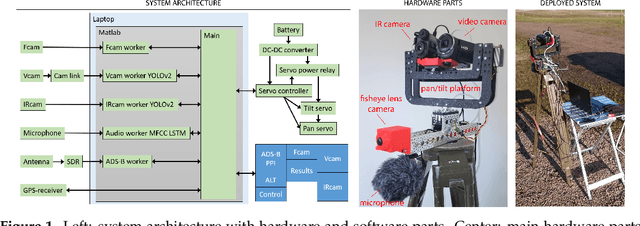



Automatic detection of flying drones is a key issue where its presence, specially if unauthorized, can create risky situations or compromise security. Here, we design and evaluate a multi-sensor drone detection system. In conjunction with common video cameras and microphone sensors, we explore the use of thermal infrared cameras, pointed out as a feasible and promising solution that is scarcely addressed in the related literature. Our solution integrates a fish-eye camera as well to monitor a wider part of the sky and steer the other cameras towards objects of interest. The sensing solutions are complemented with an ADS-B receiver, a GPS receiver, and a radar module, although the latter has been not included in our final deployment due to its limited detection range. The thermal camera is shown to be a feasible solution as good as the video camera, even if the camera employed here has a lower resolution. Two other novelties of our work are the creation of a new public dataset of multi-sensor annotated data that expand the number of classes in comparison to existing ones, as well as the study of the detector performance as a function of the sensor-to-target distance. Sensor fusion is also explored, showing that the system can be made more robust in this way, mitigating false detections of the individual sensors
Parallel Spatio-Temporal Attention-Based TCN for Multivariate Time Series Prediction
Mar 02, 2022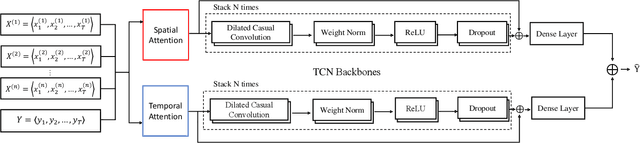
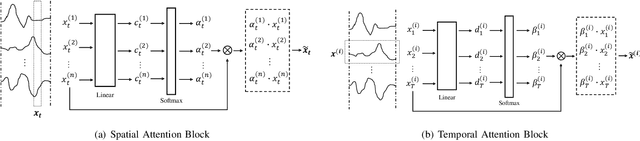

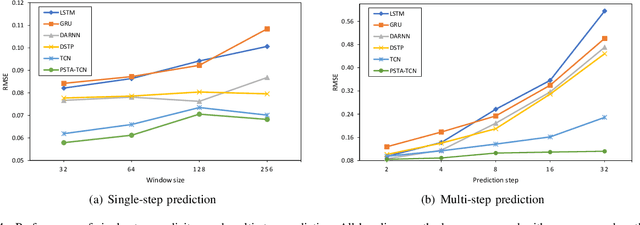
As industrial systems become more complex and monitoring sensors for everything from surveillance to our health become more ubiquitous, multivariate time series prediction is taking an important place in the smooth-running of our society. A recurrent neural network with attention to help extend the prediction windows is the current-state-of-the-art for this task. However, we argue that their vanishing gradients, short memories, and serial architecture make RNNs fundamentally unsuited to long-horizon forecasting with complex data. Temporal convolutional networks (TCNs) do not suffer from gradient problems and they support parallel calculations, making them a more appropriate choice. Additionally, they have longer memories than RNNs, albeit with some instability and efficiency problems. Hence, we propose a framework, called PSTA-TCN, that combines a parallel spatio-temporal attention mechanism to extract dynamic internal correlations with stacked TCN backbones to extract features from different window sizes. The framework makes full use parallel calculations to dramatically reduce training times, while substantially increasing accuracy with stable prediction windows up to 13 times longer than the status quo.
Adaptive Machine Learning for Cooperative Manipulators
Sep 06, 2022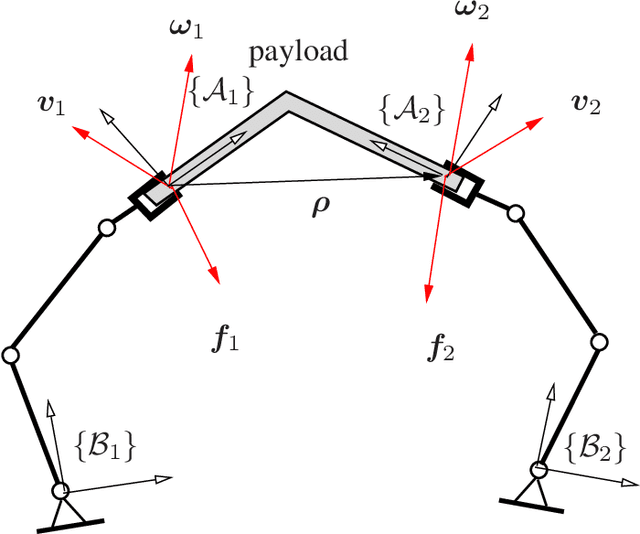
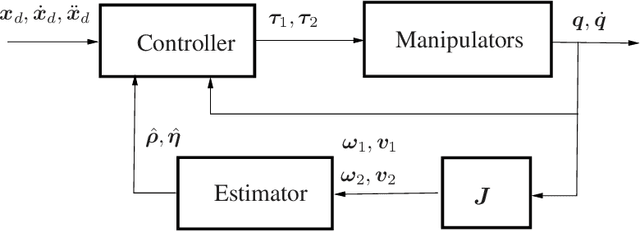
The problem of self-tuning control of cooperative manipulators forming a closed kinematic chain in the presence of an inaccurate kinematics model is addressed using adaptive machine learning. The kinematic parameters pertaining to the relative position/orientation uncertainties of the interconnected manipulators are updated online by two cascaded estimators in order to tune a cooperative controller for achieving accurate motion tracking with minimum-norm actuation force. This technique permits accurate calibration of the relative kinematics of the involved manipulators without needing high precision end-point sensing or force measurements, and hence it is economically justified. Investigating the stability of the entire real-time estimator/controller system reveals that the convergence and stability of the adaptive control process can be ensured if i) the direction of the angular velocity vector does not remain constant over time, and ii) the initial kinematic parameter error is upper bounded by a scaler function of some known parameters. The adaptive controller is proved to be singularity-free even though the control law involves inverting the approximation of a matrix computed at the estimated parameters. Experimental results demonstrate the sensitivity of the tracking performance of the conventional inverse dynamic control scheme to kinematic inaccuracies, while the tracking error is significantly reduced by the self-tuning cooperative controller.
Chandojnanam: A Sanskrit Meter Identification and Utilization System
Sep 29, 2022
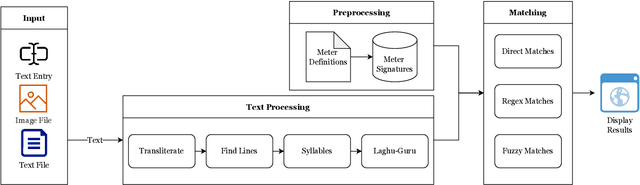
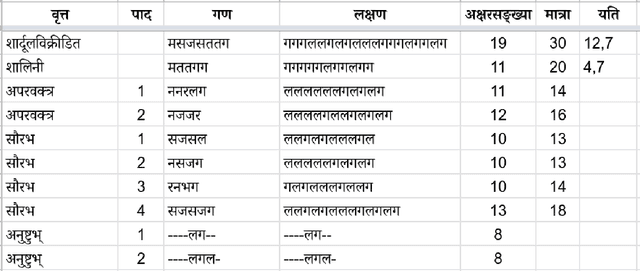

We present Chandoj\~n\=anam, a web-based Sanskrit meter (Chanda) identification and utilization system. In addition to the core functionality of identifying meters, it sports a friendly user interface to display the scansion, which is a graphical representation of the metrical pattern. The system supports identification of meters from uploaded images by using optical character recognition (OCR) engines in the backend. It is also able to process entire text files at a time. The text can be processed in two modes, either by treating it as a list of individual lines, or as a collection of verses. When a line or a verse does not correspond exactly to a known meter, Chandoj\~n\=anam is capable of finding fuzzy (i.e., approximate and close) matches based on sequence matching. This opens up the scope of a meter-based correction of erroneous digital corpora. The system is available for use at https://sanskrit.iitk.ac.in/jnanasangraha/chanda/, and the source code in the form of a Python library is made available at https://github.com/hrishikeshrt/chanda/.
Spatio-Temporal Wind Speed Forecasting using Graph Networks and Novel Transformer Architectures
Aug 29, 2022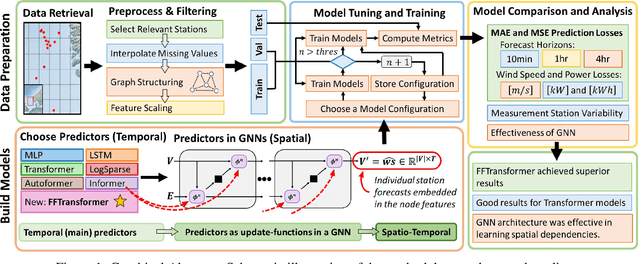
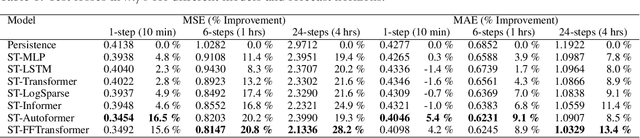
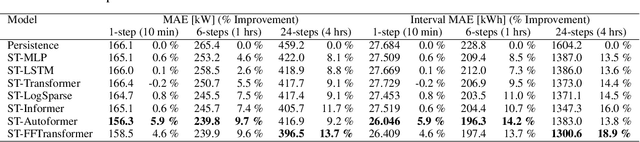
To improve the security and reliability of wind energy production, short-term forecasting has become of utmost importance. This study focuses on multi-step spatio-temporal wind speed forecasting for the Norwegian continental shelf. A graph neural network (GNN) architecture was used to extract spatial dependencies, with different update functions to learn temporal correlations. These update functions were implemented using different neural network architectures. One such architecture, the Transformer, has become increasingly popular for sequence modelling in recent years. Various alterations of the original architecture have been proposed to better facilitate time-series forecasting, of which this study focused on the Informer, LogSparse Transformer and Autoformer. This is the first time the LogSparse Transformer and Autoformer have been applied to wind forecasting and the first time any of these or the Informer have been formulated in a spatio-temporal setting for wind forecasting. By comparing against spatio-temporal Long Short-Term Memory (LSTM) and Multi-Layer Perceptron (MLP) models, the study showed that the models using the altered Transformer architectures as update functions in GNNs were able to outperform these. Furthermore, we propose the Fast Fourier Transformer (FFTransformer), which is a novel Transformer architecture based on signal decomposition and consists of two separate streams that analyse trend and periodic components separately. The FFTransformer and Autoformer were found to achieve superior results for the 10-minute and 1-hour ahead forecasts, with the FFTransformer significantly outperforming all other models for the 4-hour ahead forecasts. Finally, by varying the degree of connectivity for the graph representations, the study explicitly demonstrates how all models were able to leverage spatial dependencies to improve local short-term wind speed forecasting.
Repairing Bugs in Python Assignments Using Large Language Models
Sep 29, 2022

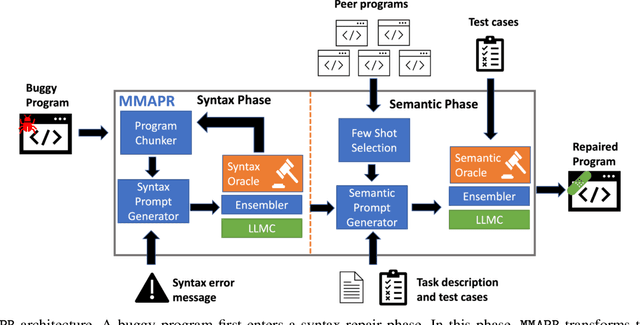

Students often make mistakes on their introductory programming assignments as part of their learning process. Unfortunately, providing custom repairs for these mistakes can require a substantial amount of time and effort from class instructors. Automated program repair (APR) techniques can be used to synthesize such fixes. Prior work has explored the use of symbolic and neural techniques for APR in the education domain. Both types of approaches require either substantial engineering efforts or large amounts of data and training. We propose to use a large language model trained on code, such as Codex, to build an APR system -- MMAPR -- for introductory Python programming assignments. Our system can fix both syntactic and semantic mistakes by combining multi-modal prompts, iterative querying, test-case-based selection of few-shots, and program chunking. We evaluate MMAPR on 286 real student programs and compare to a baseline built by combining a state-of-the-art Python syntax repair engine, BIFI, and state-of-the-art Python semantic repair engine for student assignments, Refactory. We find that MMAPR can fix more programs and produce smaller patches on average.
4D-StOP: Panoptic Segmentation of 4D LiDAR using Spatio-temporal Object Proposal Generation and Aggregation
Sep 29, 2022
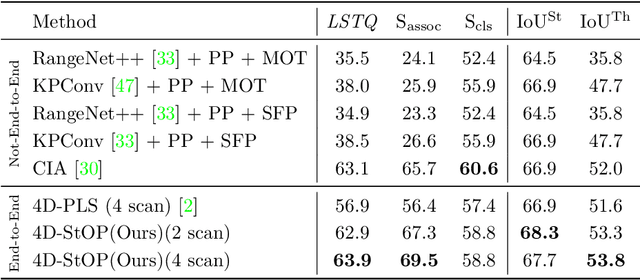
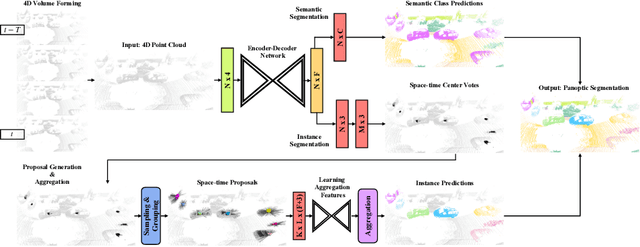
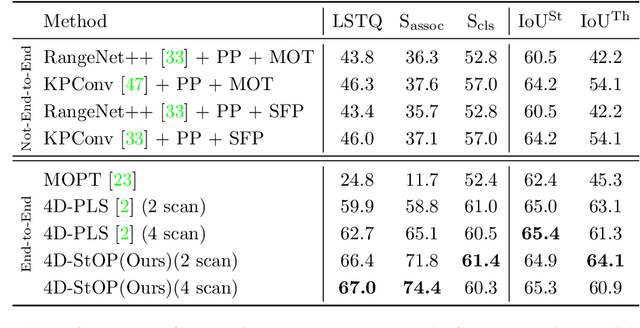
In this work, we present a new paradigm, called 4D-StOP, to tackle the task of 4D Panoptic LiDAR Segmentation. 4D-StOP first generates spatio-temporal proposals using voting-based center predictions, where each point in the 4D volume votes for a corresponding center. These tracklet proposals are further aggregated using learned geometric features. The tracklet aggregation method effectively generates a video-level 4D scene representation over the entire space-time volume. This is in contrast to existing end-to-end trainable state-of-the-art approaches which use spatio-temporal embeddings that are represented by Gaussian probability distributions. Our voting-based tracklet generation method followed by geometric feature-based aggregation generates significantly improved panoptic LiDAR segmentation quality when compared to modeling the entire 4D volume using Gaussian probability distributions. 4D-StOP achieves a new state-of-the-art when applied to the SemanticKITTI test dataset with a score of 63.9 LSTQ, which is a large (+7%) improvement compared to current best-performing end-to-end trainable methods. The code and pre-trained models are available at: https://github.com/LarsKreuzberg/4D-StOP.