 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy
Oct 11, 2021
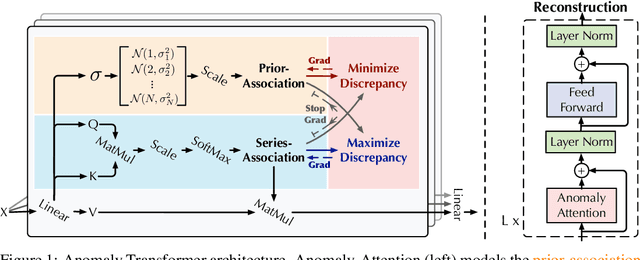
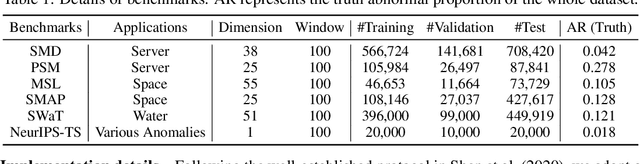
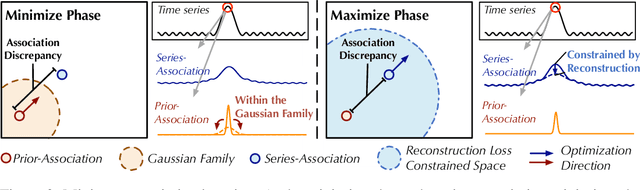
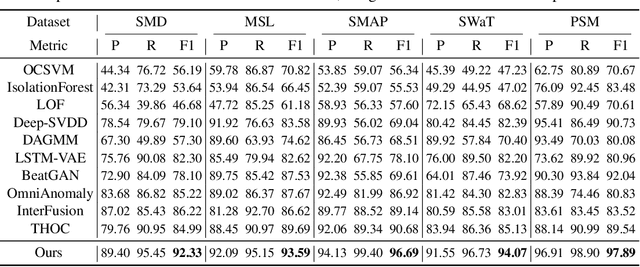
Unsupervisedly detecting anomaly points in time series is challenging, which requires the model to learn informative representations and derive a distinguishable criterion. Prior methods mainly detect anomalies based on the recurrent network representation of each time point. However, the point-wise representation is less informative for complex temporal patterns and can be dominated by normal patterns, making rare anomalies less distinguishable. We find that in each time series, each time point can also be described by its associations with all time points, presenting as a point-wise distribution that is more expressive for temporal modeling. We further observe that due to the rarity of anomalies, it is harder for anomalies to build strong associations with the whole series and their associations shall mainly concentrate on the adjacent time points. This observation implies an inherently distinguishable criterion between normal and abnormal points, which we highlight as the \emph{Association Discrepancy}. Technically we propose the \emph{Anomaly Transformer} with an \emph{Anomaly-Attention} mechanism to compute the association discrepancy. A minimax strategy is devised to amplify the normal-abnormal distinguishability of the association discrepancy. Anomaly Transformer achieves state-of-the-art performance on six unsupervised time series anomaly detection benchmarks for three applications: service monitoring, space \& earth exploration, and water treatment.
N-HiTS: Neural Hierarchical Interpolation for Time Series Forecasting
Feb 02, 2022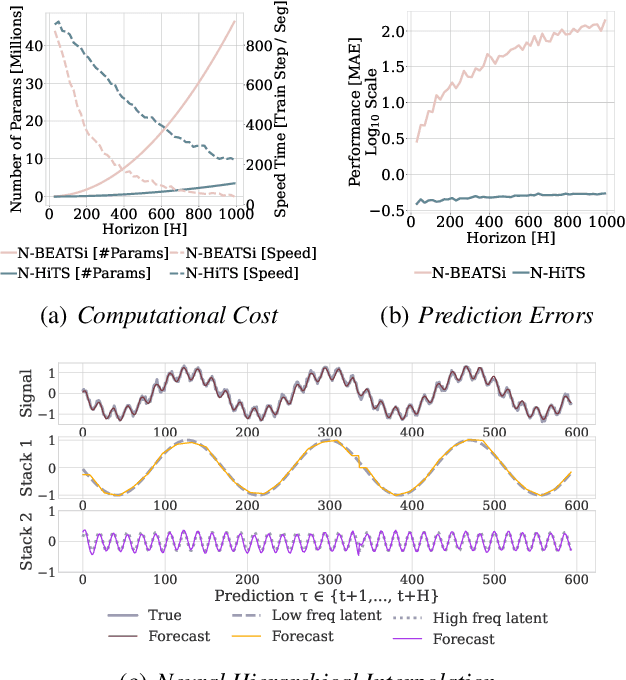
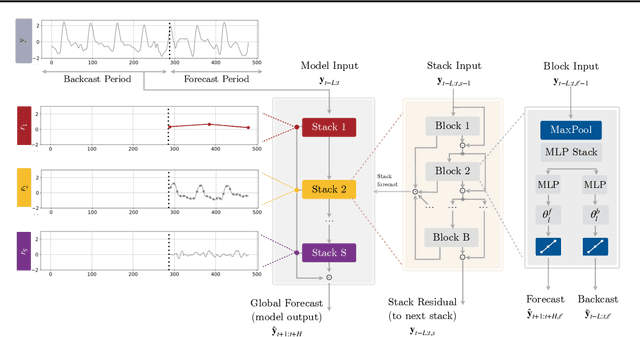
Recent progress in neural forecasting accelerated improvements in the performance of large-scale forecasting systems. Yet, long-horizon forecasting remains a very difficult task. Two common challenges afflicting long-horizon forecasting are the volatility of the predictions and their computational complexity. In this paper, we introduce N-HiTS, a model which addresses both challenges by incorporating novel hierarchical interpolation and multi-rate data sampling techniques. These techniques enable the proposed method to assemble its predictions sequentially, selectively emphasizing components with different frequencies and scales, while decomposing the input signal and synthesizing the forecast. We conduct an extensive empirical evaluation demonstrating the advantages of N-HiTS over the state-of-the-art long-horizon forecasting methods. On an array of multivariate forecasting tasks, the proposed method provides an average accuracy improvement of 25% over the latest Transformer architectures while reducing the computation time by an order of magnitude. Our code is available at https://github.com/cchallu/n-hits.
Visualization of Real-time Displacement Time History superimposed with Dynamic Experiments using Wireless Smart Sensors (WSS) and Augmented Reality (AR)
Oct 17, 2021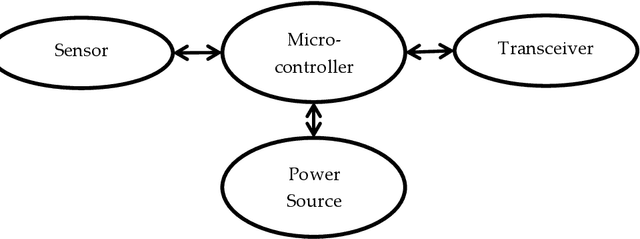
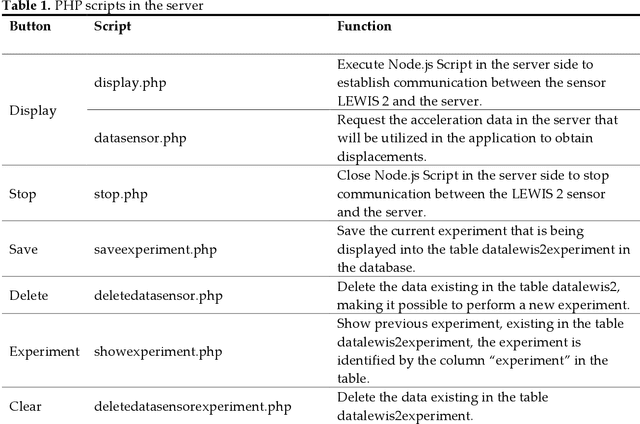

Wireless Smart Sensors (WSS) process field data and inform structural engineers and owners about the infrastructure health and safety. In bridge engineering, inspectors make decisions using objective data from each bridge. They decide about repairs and replacements and prioritize the maintenance of certain structure elements on the basis of changes in displacements under loads. However, access to displacement information in the field and in real-time remains a challenge. Displacement data provided by WSS in the field undergoes additional processing and is seen at a different location by an inspector and a sensor specialist. When the data is shared and streamed to the field inspector, there is a inter-dependence between inspectors, sensor specialists, and infrastructure owners, which limits the actionability of the data related to the bridge condition. If inspectors were able to see structural displacements in real-time at the locations of interest, they could conduct additional observations, which would create a new, information-based, decision-making reality in the field. This paper develops a new, human-centered interface that provides inspectors with real-time access to actionable structural data (real-time displacements under loads) during inspection and monitoring enhanced by Augmented Reality (AR). It summarizes the development and validation of the new human-infrastructure interface and evaluates its efficiency through laboratory experiments. The experiments demonstrate that the interface accurately estimates dynamic displacements in comparison with the laser. Using this new AR interface tool, inspectors can observe and compare displacement data, share it across space and time, and visualize displacements in time history.
Dual-Wideband Time-Varying Sub-Terahertz Massive MIMO Systems: A Compressed Training Framework
Jan 04, 2022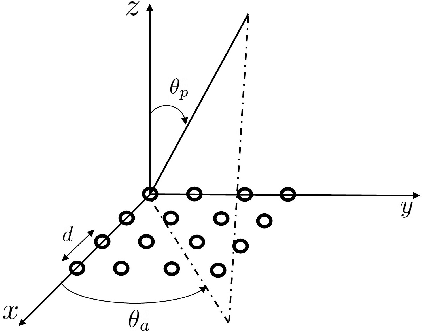
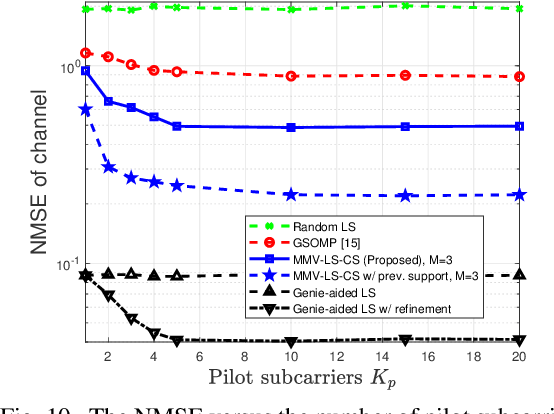
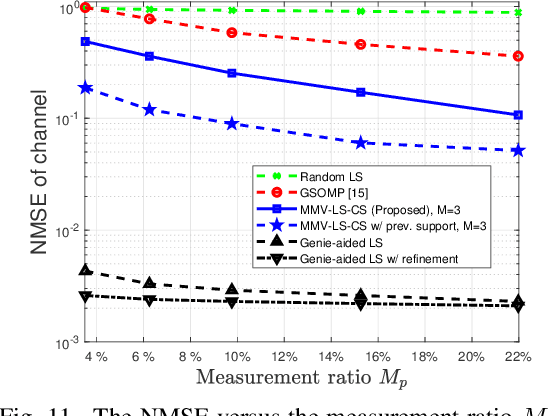
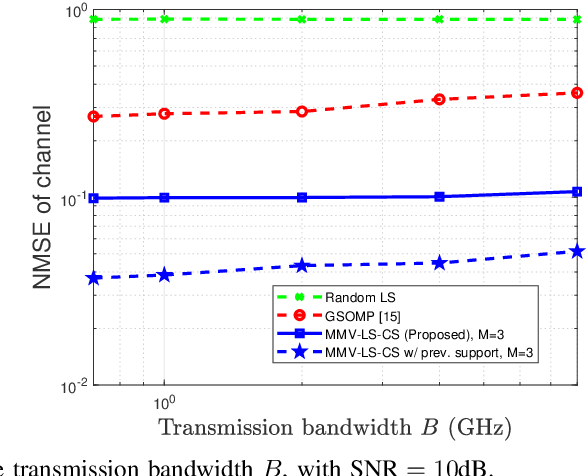
Designers of beyond-5G systems are planning to use new frequencies in the millimeter wave (mmWave) and sub-terahertz (sub-THz) bands to meet ever-increasing demand for wireless broadband access. Sub-THz communication, however, will come with many challenges of mmWave communication and new challenges associated with the wider bandwidths, larger numbers of antennas and harsher propagation characteristics. Notably the frequency- and spatial-wideband (dual-wideband) effects are significant at sub-THz. To address these challenges, this paper presents a compressed training framework to estimate the sub-THz time-varying MIMO-OFDM channels. A set of frequency-dependent array response matrices are constructed, enabling the channel recovery from multiple observations across subcarriers via multiple measurement vectors (MMV). Capitalizing on the temporal correlation, MMV least squares (MMV-LS) is designed to estimate the channel on the previous beam index support, followed by MMV compressed sensing (MMV-CS) on the residual signal to estimate the time-varying channel components. Furthermore, a channel refinement algorithm is proposed to estimate the path coefficients and time delays of the dominant paths. To reduce the computational complexity, a sequential search method using hierarchical codebooks is proposed for greedy beam selection. Numerical results show that MMV-LS-CS achieves a more accurate and robust channel estimation than state-of-the-art algorithms on time-varying dual-wideband MIMO-OFDM.
A distributed Gibbs Sampler with Hypergraph Structure for High-Dimensional Inverse Problems
Oct 05, 2022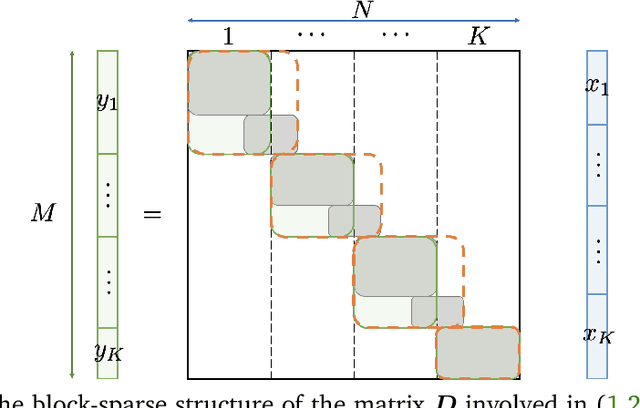
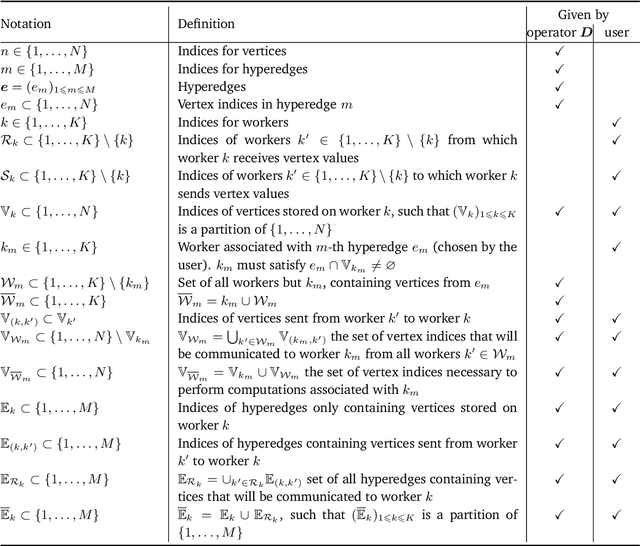
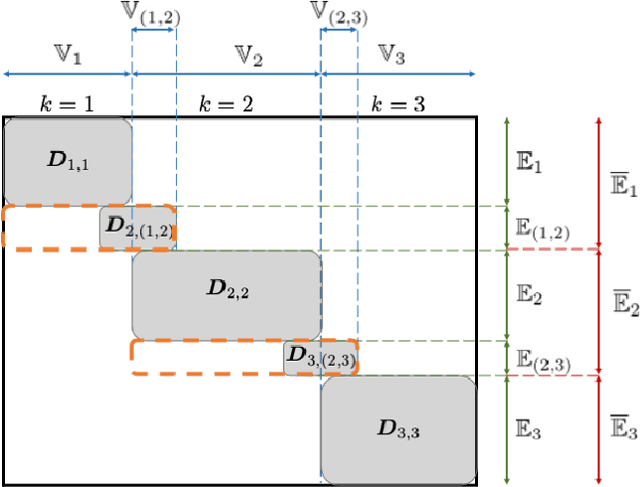

Sampling-based algorithms are classical approaches to perform Bayesian inference in inverse problems. They provide estimators with the associated credibility intervals to quantify the uncertainty on the estimators. Although these methods hardly scale to high dimensional problems, they have recently been paired with optimization techniques, such as proximal and splitting approaches, to address this issue. Such approaches pave the way to distributed samplers, splitting computations to make inference more scalable and faster. We introduce a distributed Gibbs sampler to efficiently solve such problems, considering posterior distributions with multiple smooth and non-smooth functions composed with linear operators. The proposed approach leverages a recent approximate augmentation technique reminiscent of primal-dual optimization methods. It is further combined with a block-coordinate approach to split the primal and dual variables into blocks, leading to a distributed block-coordinate Gibbs sampler. The resulting algorithm exploits the hypergraph structure of the involved linear operators to efficiently distribute the variables over multiple workers under controlled communication costs. It accommodates several distributed architectures, such as the Single Program Multiple Data and client-server architectures. Experiments on a large image deblurring problem show the performance of the proposed approach to produce high quality estimates with credibility intervals in a small amount of time.
Real-Time Style Modelling of Human Locomotion via Feature-Wise Transformations and Local Motion Phases
Jan 12, 2022



Controlling the manner in which a character moves in a real-time animation system is a challenging task with useful applications. Existing style transfer systems require access to a reference content motion clip, however, in real-time systems the future motion content is unknown and liable to change with user input. In this work we present a style modelling system that uses an animation synthesis network to model motion content based on local motion phases. An additional style modulation network uses feature-wise transformations to modulate style in real-time. To evaluate our method, we create and release a new style modelling dataset, 100STYLE, containing over 4 million frames of stylised locomotion data in 100 different styles that present a number of challenges for existing systems. To model these styles, we extend the local phase calculation with a contact-free formulation. In comparison to other methods for real-time style modelling, we show our system is more robust and efficient in its style representation while improving motion quality.
Energy-Efficiency Maximization for a WPT-D2D Pair in a MISO-NOMA Downlink Network
Oct 08, 2022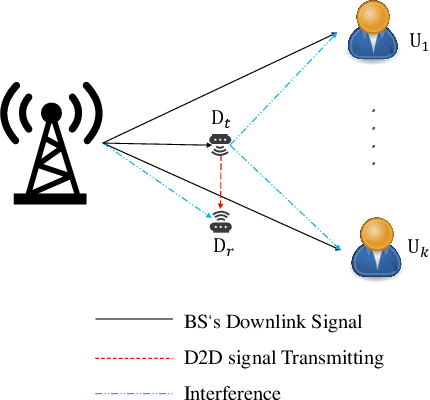
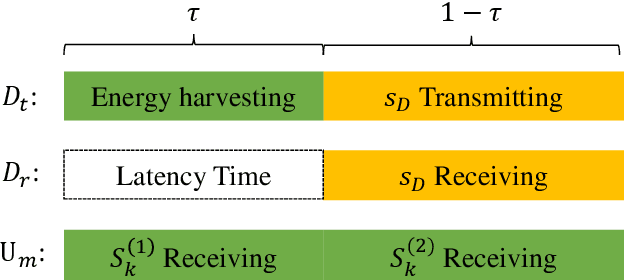
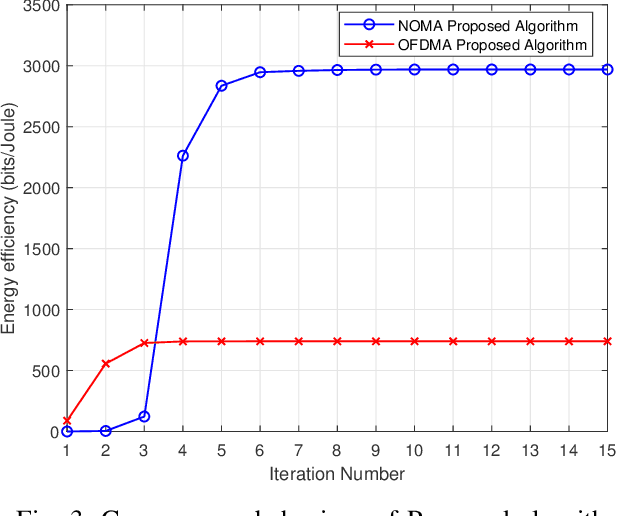
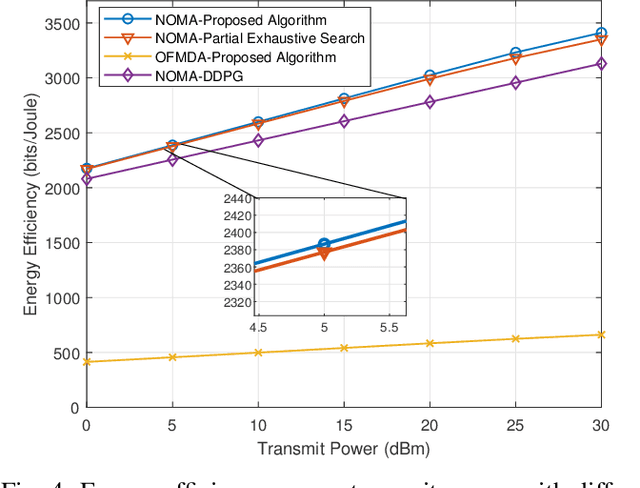
The combination of non-orthogonal multiple access (NOMA) and wireless power transfer (WPT) is a promising solution to enhance the energy efficiency of Device-to-Device (D2D) enabled wireless communication networks. In this paper, we focus on maximizing the energy efficiency of a WPT-D2D pair in a multiple-input single-output (MISO)-NOMA downlink network, by alternatively optimizing the beamforming vectors of the base station (BS) and the time switching coefficient of the WPT assisted D2D transmitter. The formulated energy efficiency maximization problem is non-convex due to the highly coupled variables. To efficiently address the non-convex problem, we first divide it into two subproblems. Afterwards, an alternating algorithm based on the Dinkelbach method and quadratic transform is proposed to solve the two subproblems iteratively. To verify the proposed alternating algorithm's accuracy, partial exhaustive search algorithm is proposed as a benchmark. We also utilize a deep reinforcement learning (DRL) method to solve the non-convex problem and compare it with the proposed algorithm. To demonstrate the respective superiority of the proposed algorithm and DRL-based method, simulations are performed for two scenarios of perfect and imperfect channel state information (CSI). Simulation results are provided to compare NOMA and orthogonal multiple access (OMA), which demonstrate the superior performance of energy efficiency of the NOMA scheme.
Improving Fine-Grain Segmentation via Interpretable Modifications: A Case Study in Fossil Segmentation
Oct 08, 2022
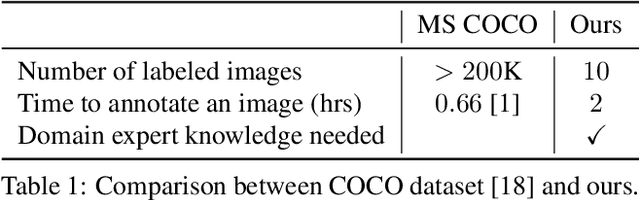
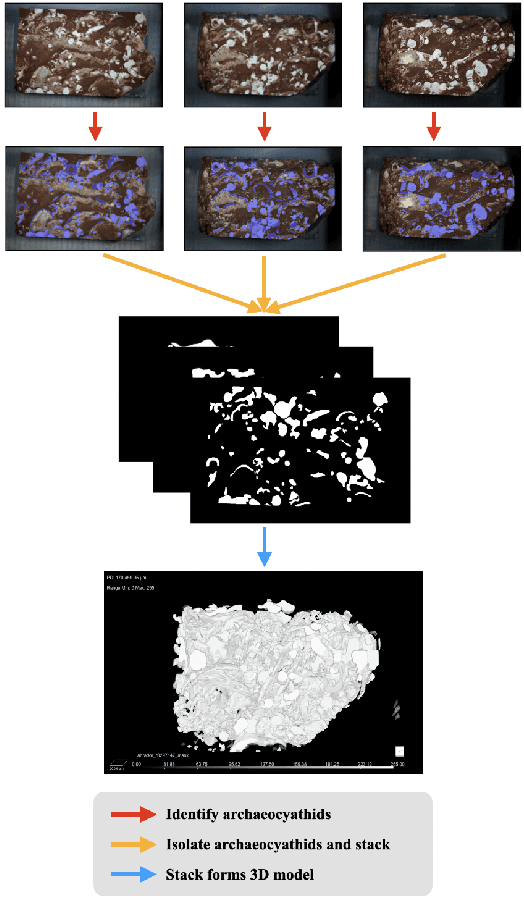
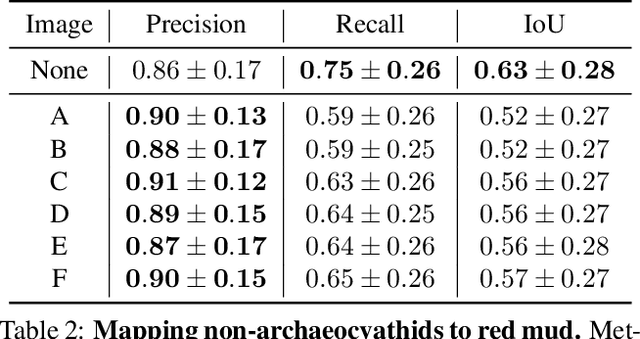
Most interpretability research focuses on datasets containing thousands of images of commonplace objects. However, many high-impact datasets, such as those in medicine and the geosciences, contain fine-grain objects that require domain-expert knowledge to recognize and are time-consuming to collect and annotate. As a result, these datasets contain few annotated images, and current machine vision models cannot train intensively on them. Thus, adapting interpretability techniques to maximize the amount of information that models can learn from small, fine-grain datasets is an important endeavor. Using a Mask R-CNN to segment ancient reef fossils in rock sample images, we present a general paradigm for identifying and mitigating model weaknesses. Specifically, we apply image perturbations to expose the Mask R-CNN's inability to distinguish between different classes of fossils and its inconsistency in segmenting fossils with different textures. To address these shortcomings, we extend an existing model-editing method for correcting systematic mistakes in image classification to image segmentation and introduce a novel application of the technique: encouraging a greater separation between positive and negative pixels for a given class. Through extensive experiments, we find that editing the model by perturbing all pixels for a given class in one image is most effective (compared to using multiple images and/or fewer pixels). Our paradigm may also generalize to other segmentation models trained on small, fine-grain datasets.
LW-ISP: A Lightweight Model with ISP and Deep Learning
Oct 08, 2022

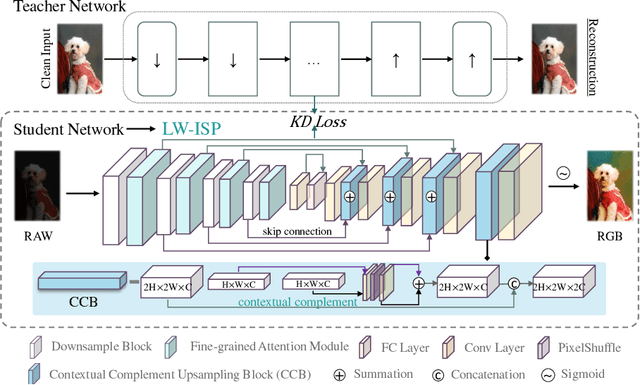

The deep learning (DL)-based methods of low-level tasks have many advantages over the traditional camera in terms of hardware prospects, error accumulation and imaging effects. Recently, the application of deep learning to replace the image signal processing (ISP) pipeline has appeared one after another; however, there is still a long way to go towards real landing. In this paper, we show the possibility of learning-based method to achieve real-time high-performance processing in the ISP pipeline. We propose LW-ISP, a novel architecture designed to implicitly learn the image mapping from RAW data to RGB image. Based on U-Net architecture, we propose the fine-grained attention module and a plug-and-play upsampling block suitable for low-level tasks. In particular, we design a heterogeneous distillation algorithm to distill the implicit features and reconstruction information of the clean image, so as to guide the learning of the student model. Our experiments demonstrate that LW-ISP has achieved a 0.38 dB improvement in PSNR compared to the previous best method, while the model parameters and calculation have been reduced by 23 times and 81 times. The inference efficiency has been accelerated by at least 15 times. Without bells and whistles, LW-ISP has achieved quite competitive results in ISP subtasks including image denoising and enhancement.
Contact-aware Human Motion Forecasting
Oct 08, 2022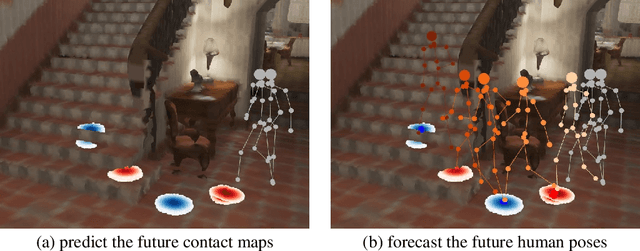
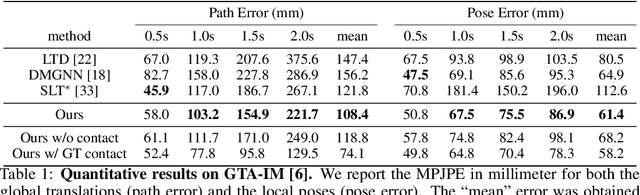
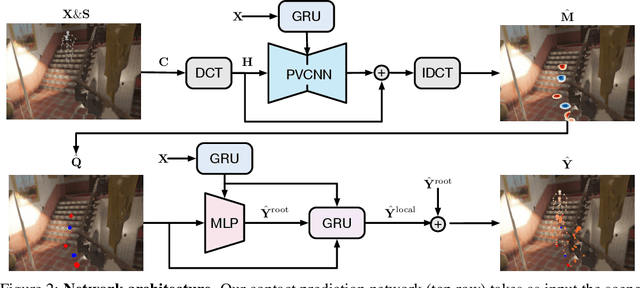
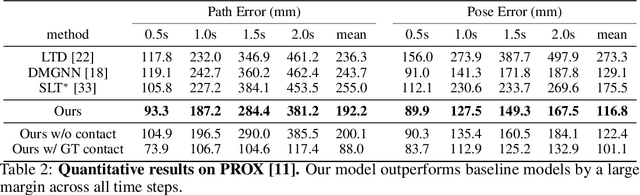
In this paper, we tackle the task of scene-aware 3D human motion forecasting, which consists of predicting future human poses given a 3D scene and a past human motion. A key challenge of this task is to ensure consistency between the human and the scene, accounting for human-scene interactions. Previous attempts to do so model such interactions only implicitly, and thus tend to produce artifacts such as "ghost motion" because of the lack of explicit constraints between the local poses and the global motion. Here, by contrast, we propose to explicitly model the human-scene contacts. To this end, we introduce distance-based contact maps that capture the contact relationships between every joint and every 3D scene point at each time instant. We then develop a two-stage pipeline that first predicts the future contact maps from the past ones and the scene point cloud, and then forecasts the future human poses by conditioning them on the predicted contact maps. During training, we explicitly encourage consistency between the global motion and the local poses via a prior defined using the contact maps and future poses. Our approach outperforms the state-of-the-art human motion forecasting and human synthesis methods on both synthetic and real datasets. Our code is available at https://github.com/wei-mao-2019/ContAwareMotionPred.