 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FastOcc: Accelerating 3D Occupancy Prediction by Fusing the 2D Bird's-Eye View and Perspective View
Mar 05, 2024
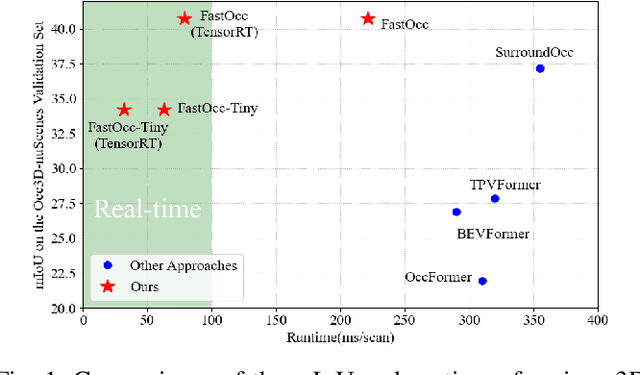
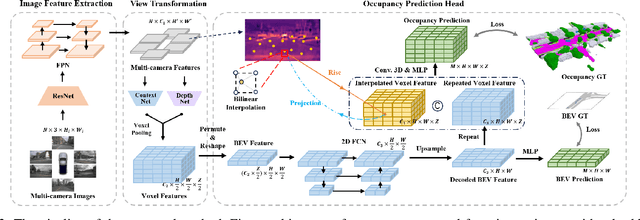
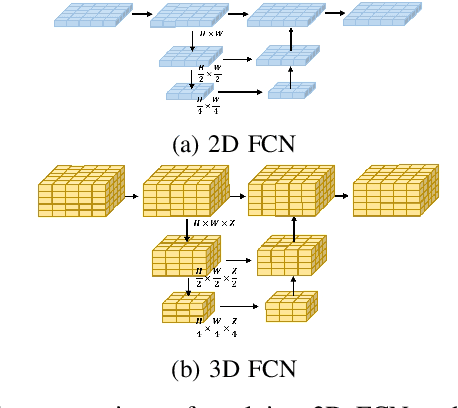
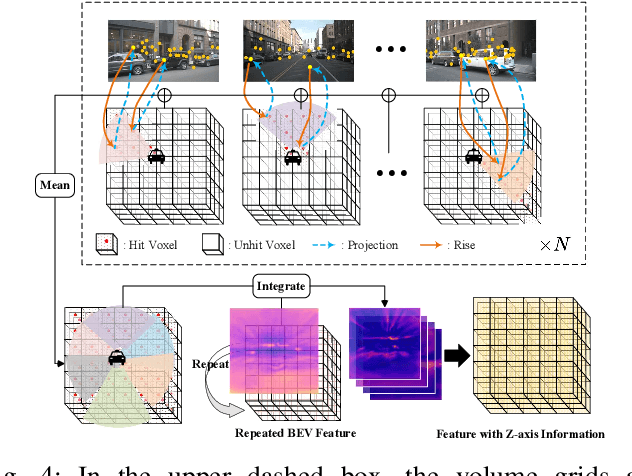
In autonomous driving, 3D occupancy prediction outputs voxel-wise status and semantic labels for more comprehensive understandings of 3D scenes compared with traditional perception tasks, such as 3D object detection and bird's-eye view (BEV) semantic segmentation. Recent researchers have extensively explored various aspects of this task, including view transformation techniques, ground-truth label generation, and elaborate network design, aiming to achieve superior performance. However, the inference speed, crucial for running on an autonomous vehicle, is neglected. To this end, a new method, dubbed FastOcc, is proposed. By carefully analyzing the network effect and latency from four parts, including the input image resolution, image backbone, view transformation, and occupancy prediction head, it is found that the occupancy prediction head holds considerable potential for accelerating the model while keeping its accuracy. Targeted at improving this component, the time-consuming 3D convolution network is replaced with a novel residual-like architecture, where features are mainly digested by a lightweight 2D BEV convolution network and compensated by integrating the 3D voxel features interpolated from the original image features. Experiments on the Occ3D-nuScenes benchmark demonstrate that our FastOcc achieves state-of-the-art results with a fast inference speed.
Matrix Completion with Convex Optimization and Column Subset Selection
Mar 05, 2024
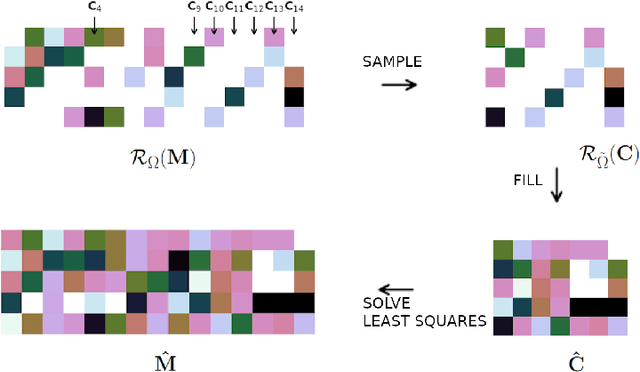
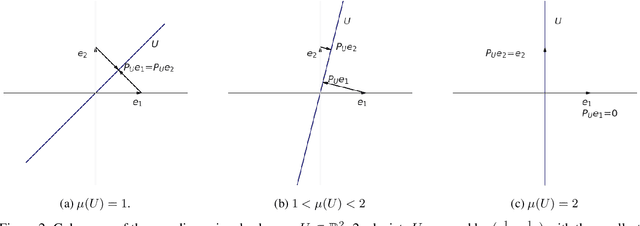
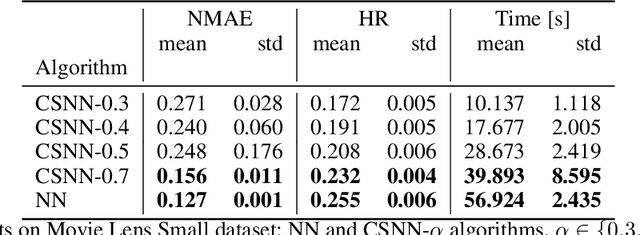
We introduce a two-step method for the matrix recovery problem. Our approach combines the theoretical foundations of the Column Subset Selection and Low-rank Matrix Completion problems. The proposed method, in each step, solves a convex optimization task. We present two algorithms that implement our Columns Selected Matrix Completion (CSMC) method, each dedicated to a different size problem. We performed a formal analysis of the presented method, in which we formulated the necessary assumptions and the probability of finding a correct solution. In the second part of the paper, we present the results of the experimental work. Numerical experiments verified the correctness and performance of the algorithms. To study the influence of the matrix size, rank, and the proportion of missing elements on the quality of the solution and the computation time, we performed experiments on synthetic data. The presented method was applied to two real-life problems problems: prediction of movie rates in a recommendation system and image inpainting. Our thorough analysis shows that CSMC provides solutions of comparable quality to matrix completion algorithms, which are based on convex optimization. However, CSMC offers notable savings in terms of runtime.
Attention Guidance Mechanism for Handwritten Mathematical Expression Recognition
Mar 05, 2024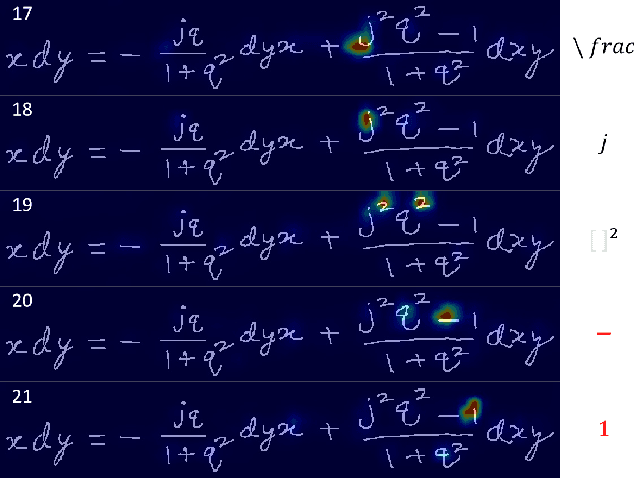
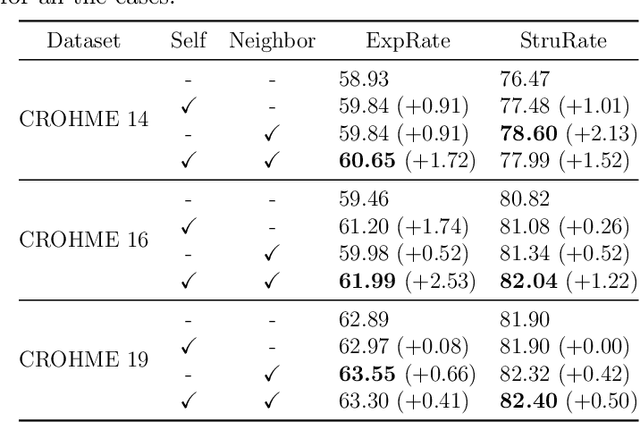
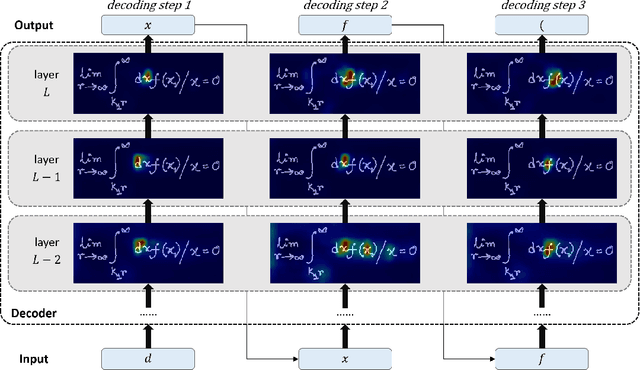
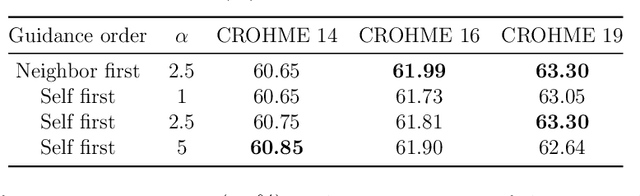
Handwritten mathematical expression recognition (HMER) is challenging in image-to-text tasks due to the complex layouts of mathematical expressions and suffers from problems including over-parsing and under-parsing. To solve these, previous HMER methods improve the attention mechanism by utilizing historical alignment information. However, this approach has limitations in addressing under-parsing since it cannot correct the erroneous attention on image areas that should be parsed at subsequent decoding steps. This faulty attention causes the attention module to incorporate future context into the current decoding step, thereby confusing the alignment process. To address this issue, we propose an attention guidance mechanism to explicitly suppress attention weights in irrelevant areas and enhance the appropriate ones, thereby inhibiting access to information outside the intended context. Depending on the type of attention guidance, we devise two complementary approaches to refine attention weights: self-guidance that coordinates attention of multiple heads and neighbor-guidance that integrates attention from adjacent time steps. Experiments show that our method outperforms existing state-of-the-art methods, achieving expression recognition rates of 60.75% / 61.81% / 63.30% on the CROHME 2014/ 2016/ 2019 datasets.
A Zero-Shot Reinforcement Learning Strategy for Autonomous Guidewire Navigation
Mar 05, 2024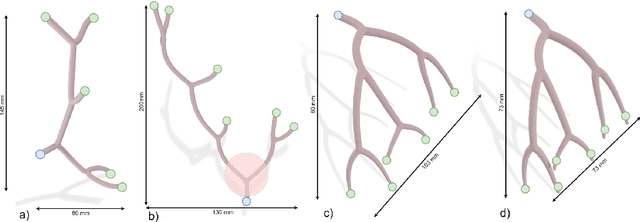
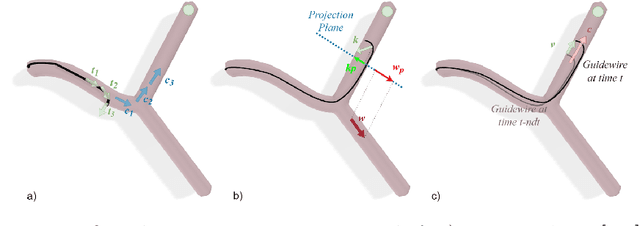
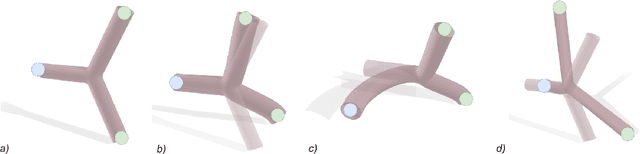
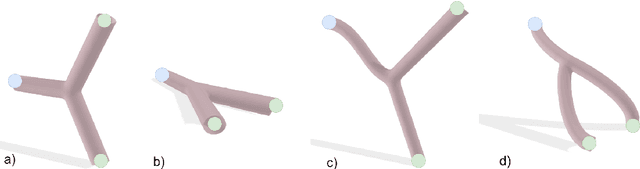
Purpose: The treatment of cardiovascular diseases requires complex and challenging navigation of a guidewire and catheter. This often leads to lengthy interventions during which the patient and clinician are exposed to X-ray radiation. Deep Reinforcement Learning approaches have shown promise in learning this task and may be the key to automating catheter navigation during robotized interventions. Yet, existing training methods show limited capabilities at generalizing to unseen vascular anatomies, requiring to be retrained each time the geometry changes. Methods: In this paper, we propose a zero-shot learning strategy for three-dimensional autonomous endovascular navigation. Using a very small training set of branching patterns, our reinforcement learning algorithm is able to learn a control that can then be applied to unseen vascular anatomies without retraining. Results: We demonstrate our method on 4 different vascular systems, with an average success rate of 95% at reaching random targets on these anatomies. Our strategy is also computationally efficient, allowing the training of our controller to be performed in only 2 hours. Conclusion: Our training method proved its ability to navigate unseen geometries with different characteristics, thanks to a nearly shape-invariant observation space.
Mixer is more than just a model
Mar 02, 2024Recently, MLP structures have regained popularity, with MLP-Mixer standing out as a prominent example. In the field of computer vision, MLP-Mixer is noted for its ability to extract data information from both channel and token perspectives, effectively acting as a fusion of channel and token information. Indeed, Mixer represents a paradigm for information extraction that amalgamates channel and token information. The essence of Mixer lies in its ability to blend information from diverse perspectives, epitomizing the true concept of "mixing" in the realm of neural network architectures. Beyond channel and token considerations, it is possible to create more tailored mixers from various perspectives to better suit specific task requirements. This study focuses on the domain of audio recognition, introducing a novel model named Audio Spectrogram Mixer with Roll-Time and Hermit FFT (ASM-RH) that incorporates insights from both time and frequency domains. Experimental results demonstrate that ASM-RH is particularly well-suited for audio data and yields promising outcomes across multiple classification tasks. The models and optimal weights files will be published.
Grid-based Fast and Structural Visual Odometry
Mar 02, 2024
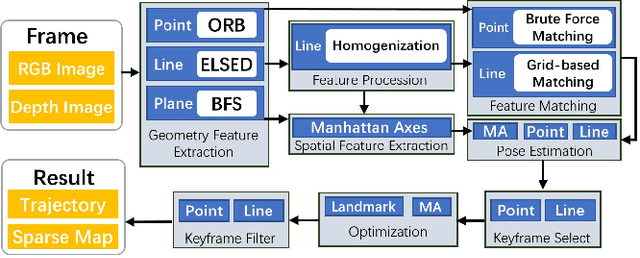
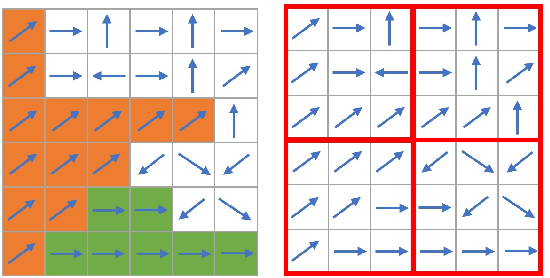
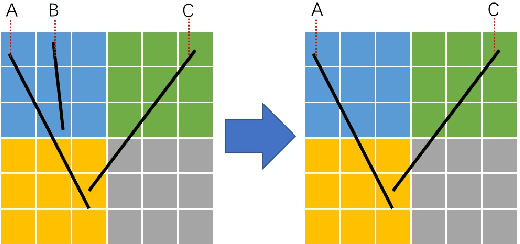
In the field of Simultaneous Localization and Mapping (SLAM), researchers have always pursued better performance in terms of accuracy and time cost. Traditional algorithms typically rely on fundamental geometric elements in images to establish connections between frames. However, these elements suffer from disadvantages such as uneven distribution and slow extraction. In addition, geometry elements like lines have not been fully utilized in the process of pose estimation. To address these challenges, we propose GFS-VO, a grid-based RGB-D visual odometry algorithm that maximizes the utilization of both point and line features. Our algorithm incorporates fast line extraction and a stable line homogenization scheme to improve feature processing. To fully leverage hidden elements in the scene, we introduce Manhattan Axes (MA) to provide constraints between local map and current frame. Additionally, we have designed an algorithm based on breadth-first search for extracting plane normal vectors. To evaluate the performance of GFS-VO, we conducted extensive experiments. The results demonstrate that our proposed algorithm exhibits significant improvements in both time cost and accuracy compared to existing approaches.
Performance Evaluation of Semi-supervised Learning Frameworks for Multi-Class Weed Detection
Mar 06, 2024
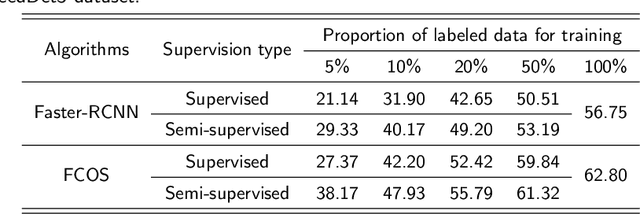

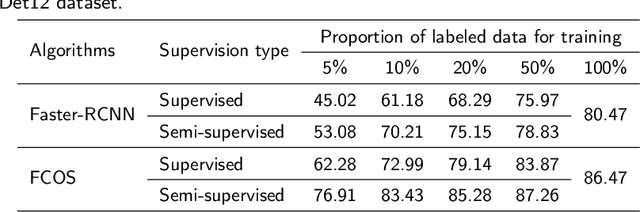
Effective weed control plays a crucial role in optimizing crop yield and enhancing agricultural product quality. However, the reliance on herbicide application not only poses a critical threat to the environment but also promotes the emergence of resistant weeds. Fortunately, recent advances in precision weed management enabled by ML and DL provide a sustainable alternative. Despite great progress, existing algorithms are mainly developed based on supervised learning approaches, which typically demand large-scale datasets with manual-labeled annotations, which is time-consuming and labor-intensive. As such, label-efficient learning methods, especially semi-supervised learning, have gained increased attention in the broader domain of computer vision and have demonstrated promising performance. These methods aim to utilize a small number of labeled data samples along with a great number of unlabeled samples to develop high-performing models comparable to the supervised learning counterpart trained on a large amount of labeled data samples. In this study, we assess the effectiveness of a semi-supervised learning framework for multi-class weed detection, employing two well-known object detection frameworks, namely FCOS and Faster-RCNN. Specifically, we evaluate a generalized student-teacher framework with an improved pseudo-label generation module to produce reliable pseudo-labels for the unlabeled data. To enhance generalization, an ensemble student network is employed to facilitate the training process. Experimental results show that the proposed approach is able to achieve approximately 76\% and 96\% detection accuracy as the supervised methods with only 10\% of labeled data in CottenWeedDet3 and CottonWeedDet12, respectively. We offer access to the source code, contributing a valuable resource for ongoing semi-supervised learning research in weed detection and beyond.
Embracing the black box: Heading towards foundation models for causal discovery from time series data
Feb 14, 2024Causal discovery from time series data encompasses many existing solutions, including those based on deep learning techniques. However, these methods typically do not endorse one of the most prevalent paradigms in deep learning: End-to-end learning. To address this gap, we explore what we call Causal Pretraining. A methodology that aims to learn a direct mapping from multivariate time series to the underlying causal graphs in a supervised manner. Our empirical findings suggest that causal discovery in a supervised manner is possible, assuming that the training and test time series samples share most of their dynamics. More importantly, we found evidence that the performance of Causal Pretraining can increase with data and model size, even if the additional data do not share the same dynamics. Further, we provide examples where causal discovery for real-world data with causally pretrained neural networks is possible within limits. We argue that this hints at the possibility of a foundation model for causal discovery.
Safe Active Learning for Time-Series Modeling with Gaussian Processes
Feb 09, 2024Learning time-series models is useful for many applications, such as simulation and forecasting. In this study, we consider the problem of actively learning time-series models while taking given safety constraints into account. For time-series modeling we employ a Gaussian process with a nonlinear exogenous input structure. The proposed approach generates data appropriate for time series model learning, i.e. input and output trajectories, by dynamically exploring the input space. The approach parametrizes the input trajectory as consecutive trajectory sections, which are determined stepwise given safety requirements and past observations. We analyze the proposed algorithm and evaluate it empirically on a technical application. The results show the effectiveness of our approach in a realistic technical use case.
ROME: Memorization Insights from Text, Probability and Hidden State in Large Language Models
Mar 04, 2024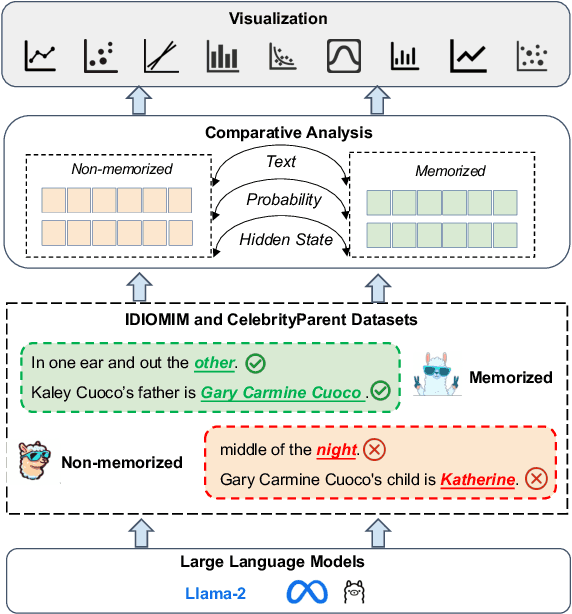


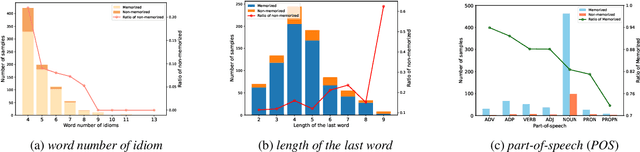
Probing the memorization of large language models holds significant importance. Previous works have established metrics for quantifying memorization, explored various influencing factors, such as data duplication, model size, and prompt length, and evaluated memorization by comparing model outputs with training corpora. However, the training corpora are of enormous scale and its pre-processing is time-consuming. To explore memorization without accessing training data, we propose a novel approach, named ROME, wherein memorization is explored by comparing disparities across memorized and non-memorized. Specifically, models firstly categorize the selected samples into memorized and non-memorized groups, and then comparing the demonstrations in the two groups from the insights of text, probability, and hidden state. Experimental findings show the disparities in factors including word length, part-of-speech, word frequency, mean and variance, just to name a few.