 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Ethical Risks of Analyzing Crisis Events on Social Media with Machine Learning
Oct 07, 2022
Social media platforms provide a continuous stream of real-time news regarding crisis events on a global scale. Several machine learning methods utilize the crowd-sourced data for the automated detection of crises and the characterization of their precursors and aftermaths. Early detection and localization of crisis-related events can help save lives and economies. Yet, the applied automation methods introduce ethical risks worthy of investigation - especially given their high-stakes societal context. This work identifies and critically examines ethical risk factors of social media analyses of crisis events focusing on machine learning methods. We aim to sensitize researchers and practitioners to the ethical pitfalls and promote fairer and more reliable designs.
Every word counts: A multilingual analysis of individual human alignment with model attention
Oct 05, 2022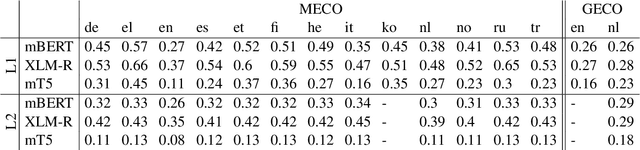
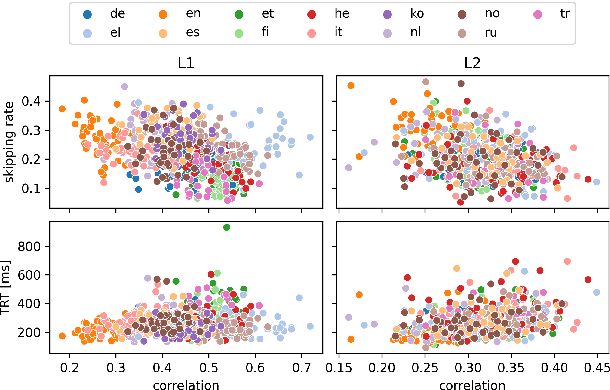
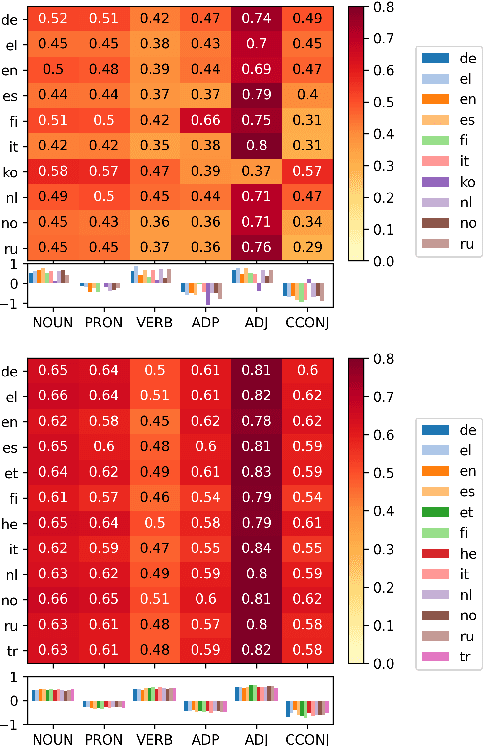
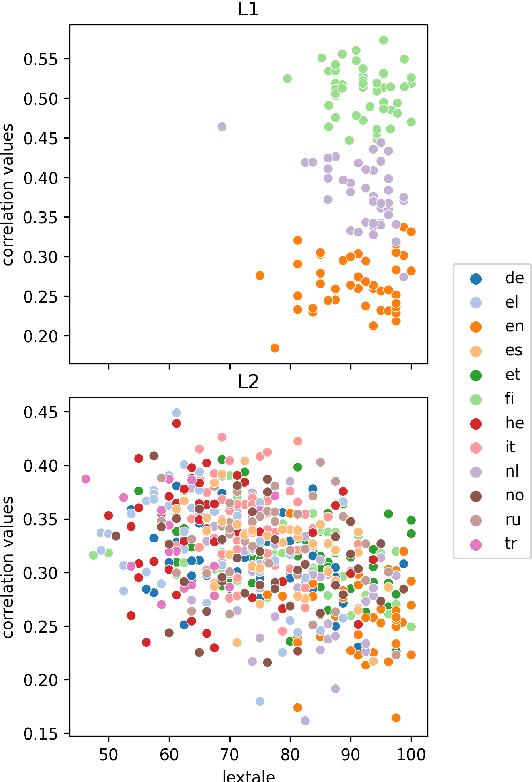
Human fixation patterns have been shown to correlate strongly with Transformer-based attention. Those correlation analyses are usually carried out without taking into account individual differences between participants and are mostly done on monolingual datasets making it difficult to generalise findings. In this paper, we analyse eye-tracking data from speakers of 13 different languages reading both in their native language (L1) and in English as language learners (L2). We find considerable differences between languages but also that individual reading behaviour such as skipping rate, total reading time and vocabulary knowledge (LexTALE) influence the alignment between humans and models to an extent that should be considered in future studies.
Neuromorphic implementation of ECG anomaly detection using delay chains
Sep 02, 2022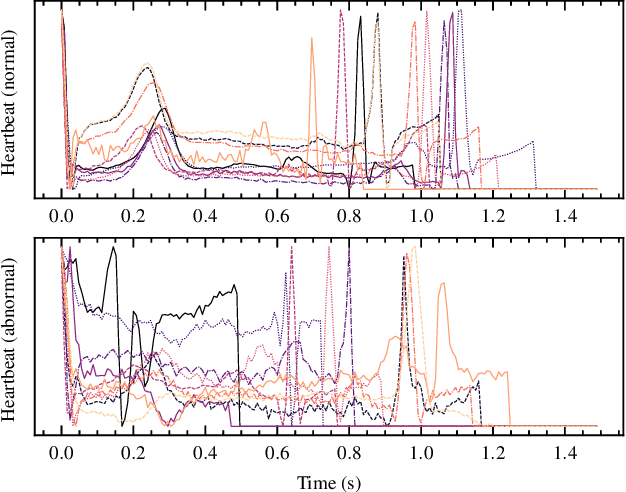
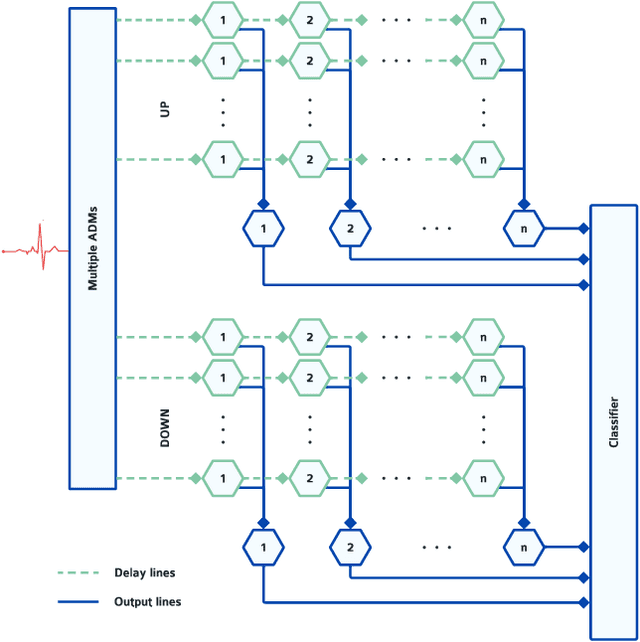
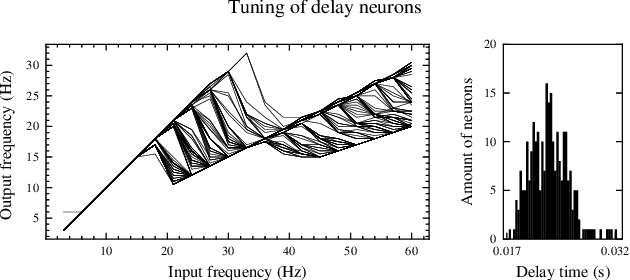
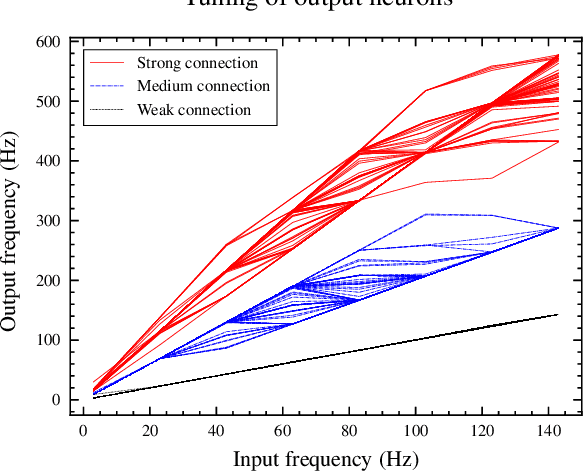
Real-time analysis and classification of bio-signals measured using wearable devices is computationally costly and requires dedicated low-power hardware. One promising approach is to use spiking neural networks implemented using in-memory computing architectures and neuromorphic electronic circuits. However, as these circuits process data in streaming mode without the possibility of storing it in external buffers, a major challenge lies in the processing of spatio-temporal signals that last longer than the time constants present in the network synapses and neurons. Here we propose to extend the memory capacity of a spiking neural network by using parallel delay chains. We show that it is possible to map temporal signals of multiple seconds into spiking activity distributed across multiple neurons which have time constants of few milliseconds. We validate this approach on an ECG anomaly detection task and present experimental results that demonstrate how temporal information is properly preserved in the network activity.
Learning to Price Supply Chain Contracts against a Learning Retailer
Nov 02, 2022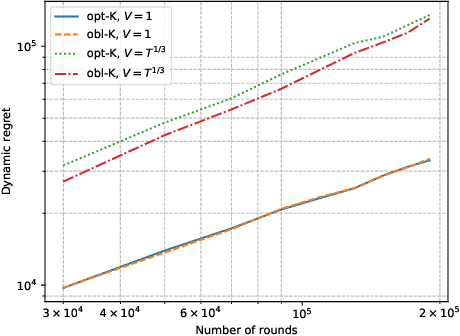
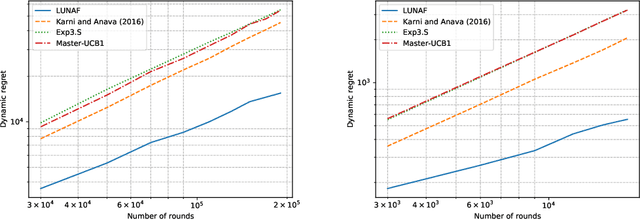
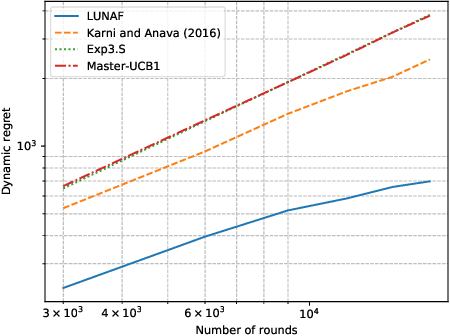
The rise of big data analytics has automated the decision-making of companies and increased supply chain agility. In this paper, we study the supply chain contract design problem faced by a data-driven supplier who needs to respond to the inventory decisions of the downstream retailer. Both the supplier and the retailer are uncertain about the market demand and need to learn about it sequentially. The goal for the supplier is to develop data-driven pricing policies with sublinear regret bounds under a wide range of possible retailer inventory policies for a fixed time horizon. To capture the dynamics induced by the retailer's learning policy, we first make a connection to non-stationary online learning by following the notion of variation budget. The variation budget quantifies the impact of the retailer's learning strategy on the supplier's decision-making. We then propose dynamic pricing policies for the supplier for both discrete and continuous demand. We also note that our proposed pricing policy only requires access to the support of the demand distribution, but critically, does not require the supplier to have any prior knowledge about the retailer's learning policy or the demand realizations. We examine several well-known data-driven policies for the retailer, including sample average approximation, distributionally robust optimization, and parametric approaches, and show that our pricing policies lead to sublinear regret bounds in all these cases. At the managerial level, we answer affirmatively that there is a pricing policy with a sublinear regret bound under a wide range of retailer's learning policies, even though she faces a learning retailer and an unknown demand distribution. Our work also provides a novel perspective in data-driven operations management where the principal has to learn to react to the learning policies employed by other agents in the system.
Supporting the Task-driven Skill Identification in Open Source Project Issue Tracking Systems
Nov 02, 2022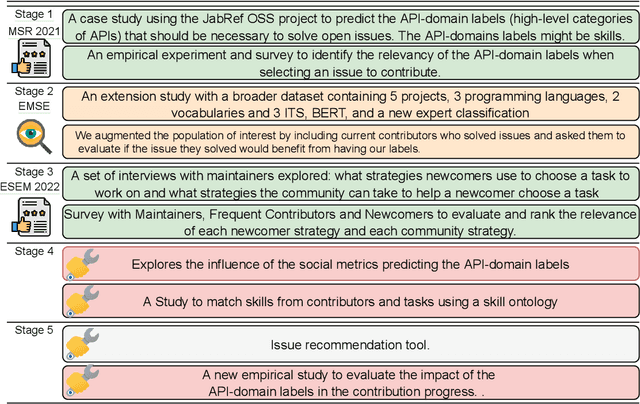
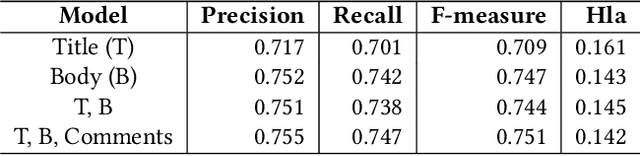
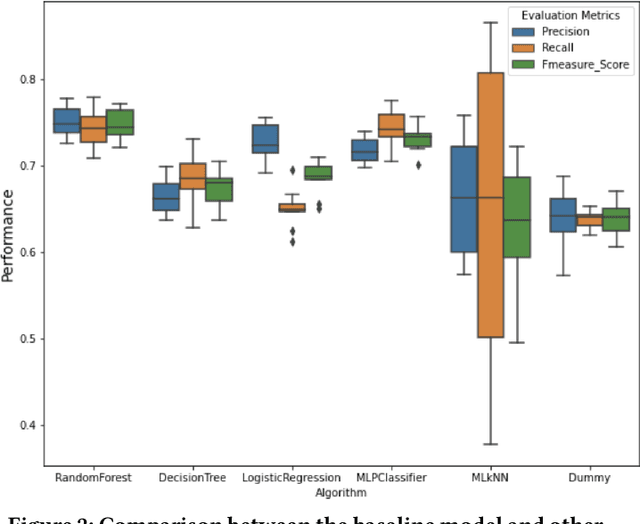
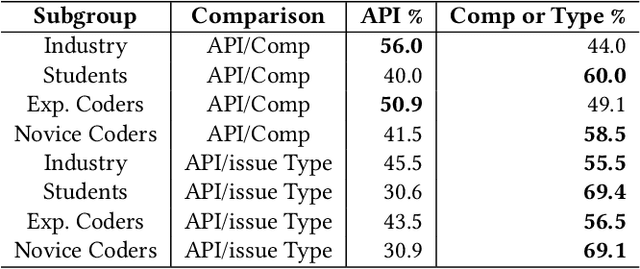
Selecting an appropriate task is challenging for contributors to Open Source Software (OSS), mainly for those who are contributing for the first time. Therefore, researchers and OSS projects have proposed various strategies to aid newcomers, including labeling tasks. We investigate the automatic labeling of open issues strategy to help the contributors to pick a task to contribute. We label the issues with API-domains--categories of APIs parsed from the source code used to solve the issues. We plan to add social network analysis metrics from the issues conversations as new predictors. By identifying the skills, we claim the contributor candidates should pick a task more suitable. We analyzed interview transcripts and the survey's open-ended questions to comprehend the strategies used to assist in onboarding contributors and used to pick up an issue. We applied quantitative studies to analyze the relevance of the labels in an experiment and compare the strategies' relative importance. We also mined issue data from OSS repositories to predict the API-domain labels with comparable precision, recall, and F-measure with the state-of-art. We plan to use a skill ontology to assist the matching process between contributors and tasks. By analyzing the confidence level of the matching instances in ontologies describing contributors' skills and tasks, we might recommend issues for contribution. So far, the results showed that organizing the issues--which includes assigning labels is seen as an essential strategy for diverse roles in OSS communities. The API-domain labels are relevant for experienced practitioners. The predictions have an average precision of 75.5%. Labeling the issues indicates the skills involved in an issue. The labels represent possible skills in the source code related to an issue. By investigating this research topic, we expect to assist the new contributors in finding a task.
Task-Oriented Over-the-Air Computation for Multi-Device Edge AI
Nov 02, 2022
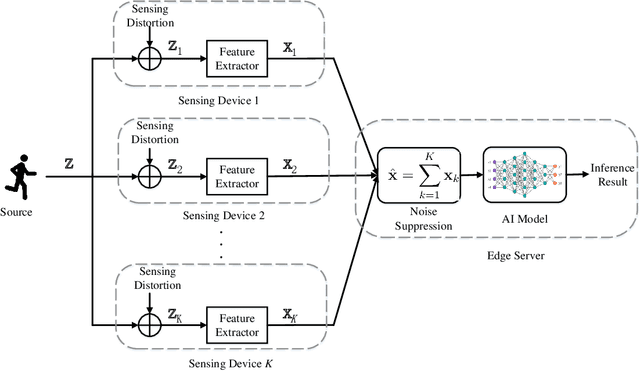
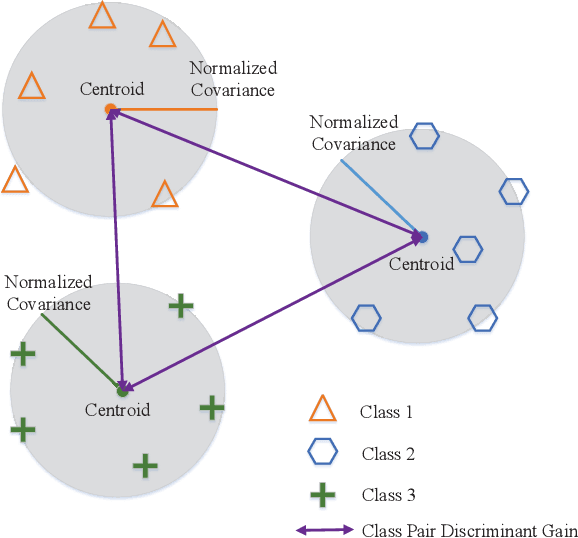
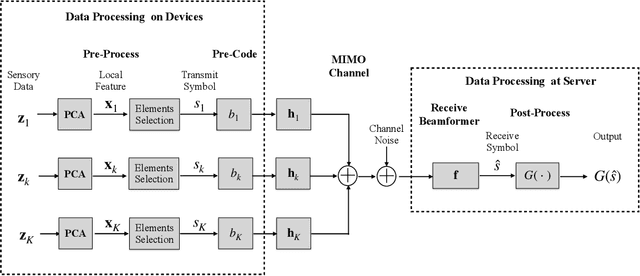
Departing from the classic paradigm of data-centric designs, the 6G networks for supporting edge AI features task-oriented techniques that focus on effective and efficient execution of AI task. Targeting end-to-end system performance, such techniques are sophisticated as they aim to seamlessly integrate sensing (data acquisition), communication (data transmission), and computation (data processing). Aligned with the paradigm shift, a task-oriented over-the-air computation (AirComp) scheme is proposed in this paper for multi-device split-inference system. In the considered system, local feature vectors, which are extracted from the real-time noisy sensory data on devices, are aggregated over-the-air by exploiting the waveform superposition in a multiuser channel. Then the aggregated features as received at a server are fed into an inference model with the result used for decision making or control of actuators. To design inference-oriented AirComp, the transmit precoders at edge devices and receive beamforming at edge server are jointly optimized to rein in the aggregation error and maximize the inference accuracy. The problem is made tractable by measuring the inference accuracy using a surrogate metric called discriminant gain, which measures the discernibility of two object classes in the application of object/event classification. It is discovered that the conventional AirComp beamforming design for minimizing the mean square error in generic AirComp with respect to the noiseless case may not lead to the optimal classification accuracy. The reason is due to the overlooking of the fact that feature dimensions have different sensitivity towards aggregation errors and are thus of different importance levels for classification. This issue is addressed in this work via a new task-oriented AirComp scheme designed by directly maximizing the derived discriminant gain.
A Simple Temporal Information Matching Mechanism for Entity Alignment Between Temporal Knowledge Graphs
Sep 20, 2022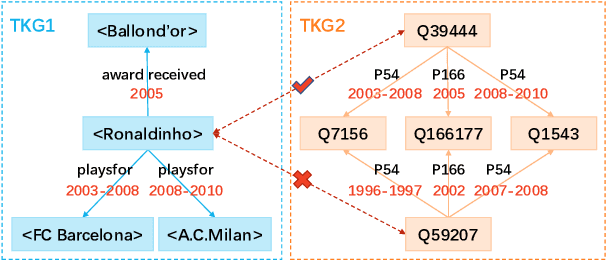

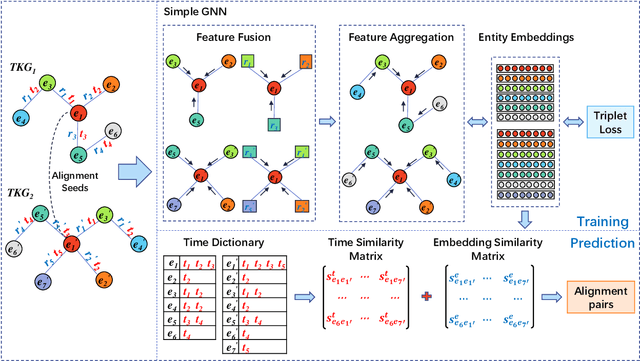
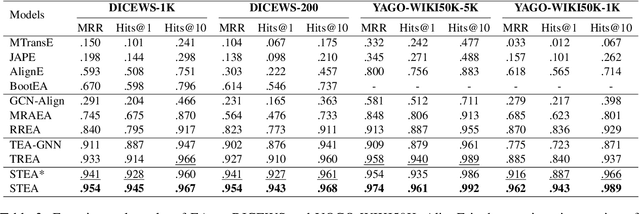
Entity alignment (EA) aims to find entities in different knowledge graphs (KGs) that refer to the same object in the real world. Recent studies incorporate temporal information to augment the representations of KGs. The existing methods for EA between temporal KGs (TKGs) utilize a time-aware attention mechanism to incorporate relational and temporal information into entity embeddings. The approaches outperform the previous methods by using temporal information. However, we believe that it is not necessary to learn the embeddings of temporal information in KGs since most TKGs have uniform temporal representations. Therefore, we propose a simple graph neural network (GNN) model combined with a temporal information matching mechanism, which achieves better performance with less time and fewer parameters. Furthermore, since alignment seeds are difficult to label in real-world applications, we also propose a method to generate unsupervised alignment seeds via the temporal information of TKG. Extensive experiments on public datasets indicate that our supervised method significantly outperforms the previous methods and the unsupervised one has competitive performance.
Real-time motion planning and decision-making for a group of differential drive robots under connectivity constraints using robust MPC and mixed-integer programming
May 31, 2022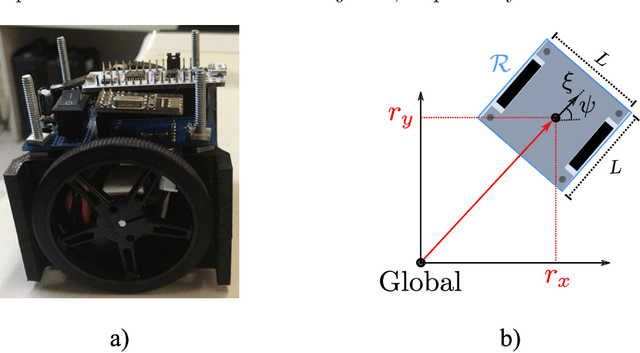

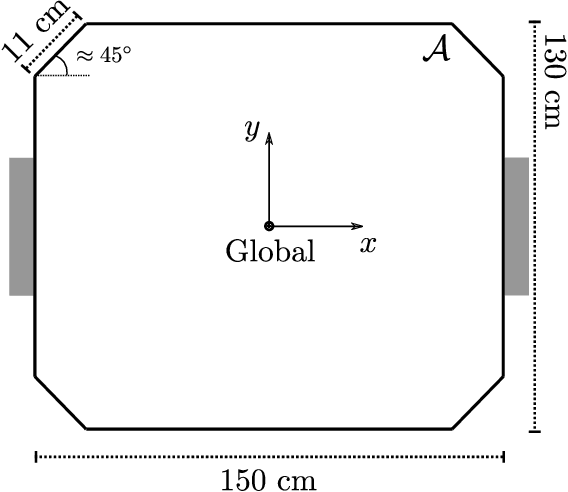
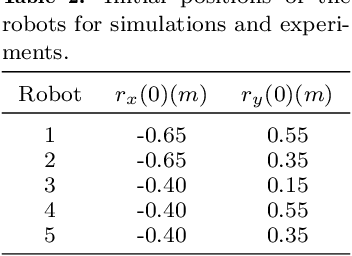
This work is concerned with the problem of planning trajectories and assigning tasks for a Multi-Agent System (MAS) comprised of differential drive robots. We propose a multirate hierarchical control structure that employs a planner based on robust Model Predictive Control (MPC) with mixed-integer programming (MIP) encoding. The planner computes trajectories and assigns tasks for each element of the group in real-time, while also guaranteeing the communication network of the MAS to be robustly connected at all times. Additionally, we provide a data-based methodology to estimate the disturbances sets required by the robust MPC formulation. The results are demonstrated with experiments in two obstacle-filled scenarios
Spectrum of non-Hermitian deep-Hebbian neural networks
Aug 24, 2022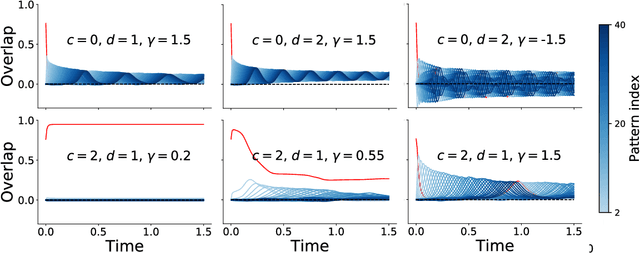
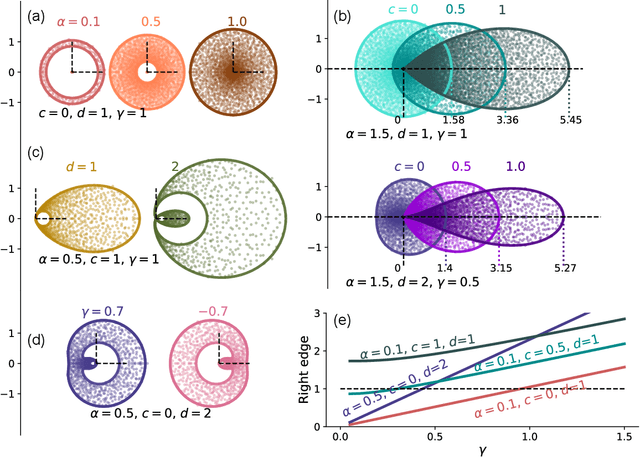
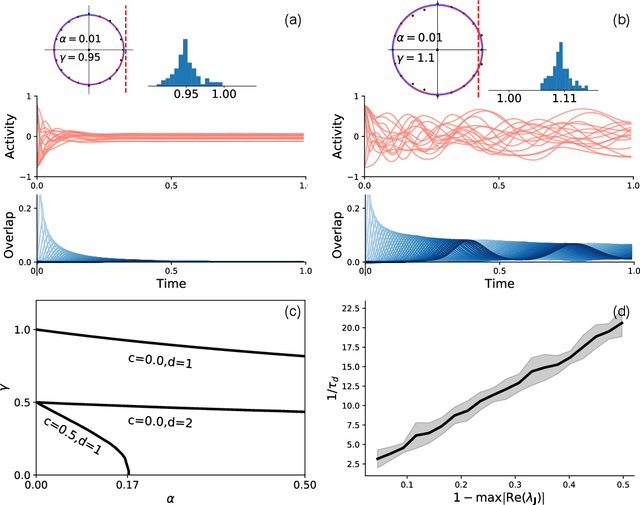
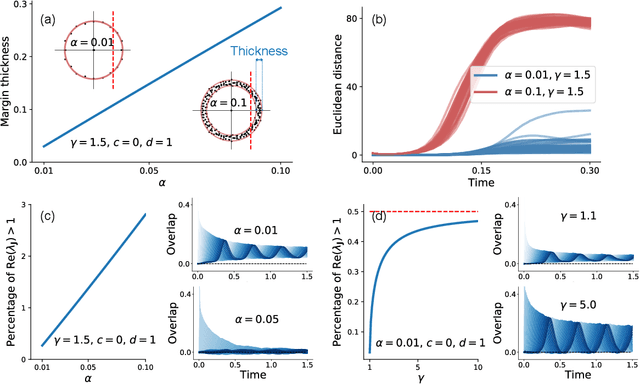
Neural networks with recurrent asymmetric couplings are important to understand how episodic memories are encoded in the brain. Here, we integrate the experimental observation of wide synaptic integration window into our model of sequence retrieval in the continuous time dynamics. The model with non-normal neuron-interactions is theoretically studied by deriving a random matrix theory of the Jacobian matrix in neural dynamics. The spectra bears several distinct features, such as breaking rotational symmetry about the origin, and the emergence of nested voids within the spectrum boundary. The spectral density is thus highly non-uniformly distributed in the complex plane. The random matrix theory also predicts a transition to chaos. In particular, the edge of chaos provides computational benefits for the sequential retrieval of memories. Our work provides a systematic study of time-lagged correlations with arbitrary time delays, and thus can inspire future studies of a broad class of memory models, and even big data analysis of biological time series.
DQLAP: Deep Q-Learning Recommender Algorithm with Update Policy for a Real Steam Turbine System
Oct 12, 2022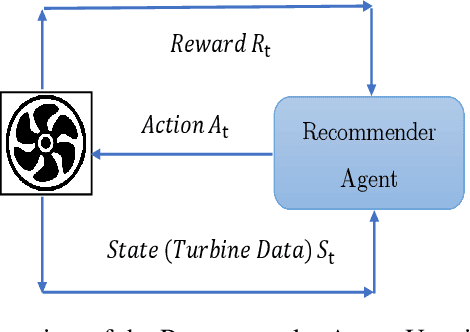
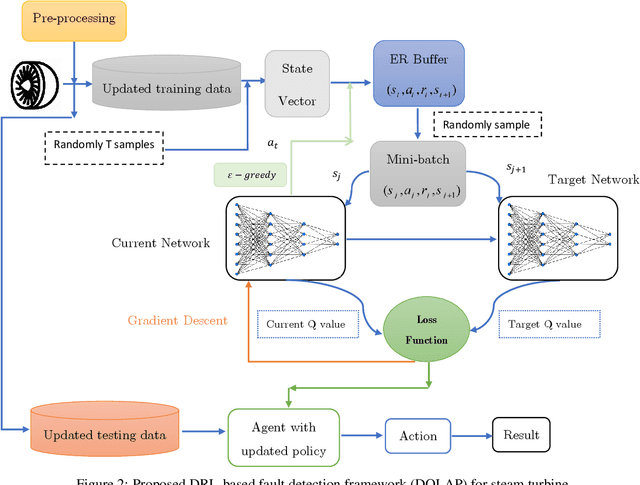
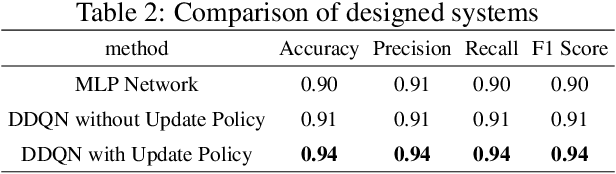
In modern industrial systems, diagnosing faults in time and using the best methods becomes more and more crucial. It is possible to fail a system or to waste resources if faults are not detected or are detected late. Machine learning and deep learning have proposed various methods for data-based fault diagnosis, and we are looking for the most reliable and practical ones. This paper aims to develop a framework based on deep learning and reinforcement learning for fault detection. We can increase accuracy, overcome data imbalance, and better predict future defects by updating the reinforcement learning policy when new data is received. By implementing this method, we will see an increase of $3\%$ in all evaluation metrics, an improvement in prediction speed, and $3\%$ - $4\%$ in all evaluation metrics compared to typical backpropagation multi-layer neural network prediction with similar parameters.