 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBye Bye Perspective API: Lessons for Measurement Infrastructure in NLP, CSS and LLM Evaluation
Apr 28, 2026The closure of Perspective API at the end of 2026 discards what has functioned as the de facto standard for automated toxicity measurement in NLP, CSS, and LLM evaluation research. We document the structural dependence that the communities built on this single proprietary tool and discuss how this dependence caused epistemic problems that have affected - and will likely continue to affect - collective research efforts. Perspective's model was periodically updated without versioning or disclosure, its annotation structure reflected a single corporate operationalisation of a contested concept, and its scores were used simultaneously as an evaluation target and an evaluation standard. Its closure leaves behind non-updatable benchmarks, irreproducible results, and ultimately a field at risk of perpetuating these issues by turning to closed-source LLMs. We use Perspective's announced termination as an opportunity to call for an independent, valid, adaptable, and reproducible toxicity and hate speech measurement infrastructure, with the technical and governance requirements outlined in this paper.
Social Bias in Popular Question-Answering Benchmarks
May 21, 2025Question-answering (QA) and reading comprehension (RC) benchmarks are essential for assessing the capabilities of large language models (LLMs) in retrieving and reproducing knowledge. However, we demonstrate that popular QA and RC benchmarks are biased and do not cover questions about different demographics or regions in a representative way, potentially due to a lack of diversity of those involved in their creation. We perform a qualitative content analysis of 30 benchmark papers and a quantitative analysis of 20 respective benchmark datasets to learn (1) who is involved in the benchmark creation, (2) how social bias is addressed or prevented, and (3) whether the demographics of the creators and annotators correspond to particular biases in the content. Most analyzed benchmark papers provided insufficient information regarding the stakeholders involved in benchmark creation, particularly the annotators. Notably, just one of the benchmark papers explicitly reported measures taken to address social representation issues. Moreover, the data analysis revealed gender, religion, and geographic biases across a wide range of encyclopedic, commonsense, and scholarly benchmarks. More transparent and bias-aware QA and RC benchmark creation practices are needed to facilitate better scrutiny and incentivize the development of fairer LLMs.
The Ethical Risks of Analyzing Crisis Events on Social Media with Machine Learning
Oct 07, 2022Social media platforms provide a continuous stream of real-time news regarding crisis events on a global scale. Several machine learning methods utilize the crowd-sourced data for the automated detection of crises and the characterization of their precursors and aftermaths. Early detection and localization of crisis-related events can help save lives and economies. Yet, the applied automation methods introduce ethical risks worthy of investigation - especially given their high-stakes societal context. This work identifies and critically examines ethical risk factors of social media analyses of crisis events focusing on machine learning methods. We aim to sensitize researchers and practitioners to the ethical pitfalls and promote fairer and more reliable designs.
The Lifecycle of "Facts": A Survey of Social Bias in Knowledge Graphs
Oct 07, 2022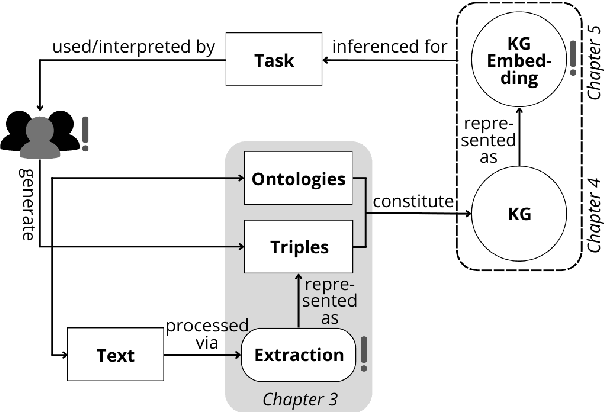
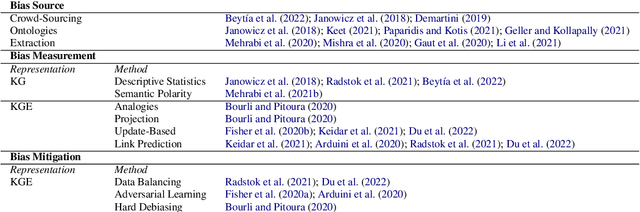
Knowledge graphs are increasingly used in a plethora of downstream tasks or in the augmentation of statistical models to improve factuality. However, social biases are engraved in these representations and propagate downstream. We conducted a critical analysis of literature concerning biases at different steps of a knowledge graph lifecycle. We investigated factors introducing bias, as well as the biases that are rendered by knowledge graphs and their embedded versions afterward. Limitations of existing measurement and mitigation strategies are discussed and paths forward are proposed.