 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Applying Physics-Informed Enhanced Super-Resolution Generative Adversarial Networks to Finite-Rate-Chemistry Flows and Predicting Lean Premixed Gas Turbine Combustors
Oct 28, 2022
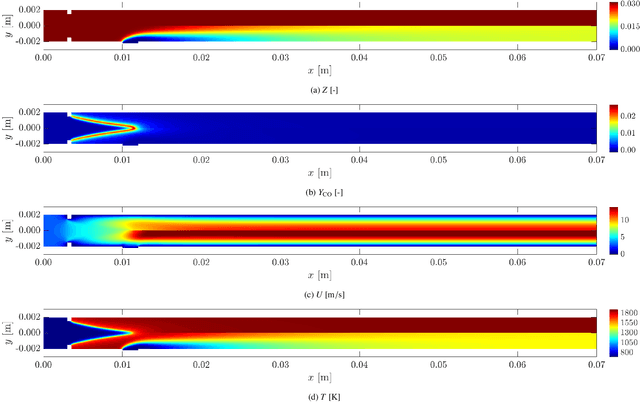

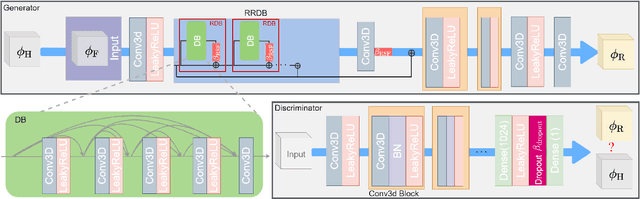
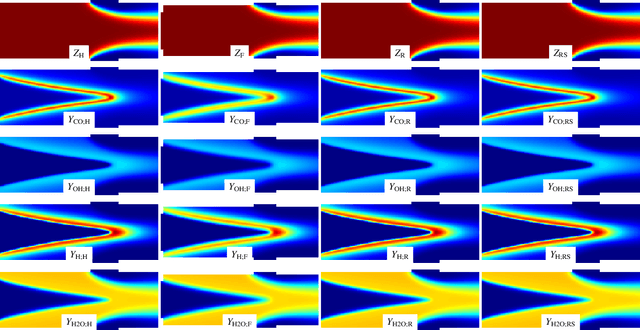
The accurate prediction of small scales in underresolved flows is still one of the main challenges in predictive simulations of complex configurations. Over the last few years, data-driven modeling has become popular in many fields as large, often extensively labeled datasets are now available and training of large neural networks has become possible on graphics processing units (GPUs) that speed up the learning process tremendously. In fact, the successful application of deep neural networks in fluid dynamics, such as for underresolved reactive flows, is still challenging. This work advances the recently introduced PIESRGAN to reactive finite-rate-chemistry flows. However, since combustion chemistry typically acts on the smallest scales, the original approach needs to be extended. Therefore, the modeling approach of PIESRGAN is modified to accurately account for the challenges in the context of laminar finite-rate-chemistry flows. The modified PIESRGAN-based model gives good agreement in a priori and a posteriori tests in a laminar lean premixed combustion setup. Furthermore, a reduced PIESRGAN-based model is presented that solves only the major species on a reconstructed field and employs PIERSGAN lookup for the remaining species, utilizing staggering in time. The advantages of the discriminator-supported training are shown, and the usability of the new model demonstrated in the context of a model gas turbine combustor.
Debiasing Masks: A New Framework for Shortcut Mitigation in NLU
Oct 28, 2022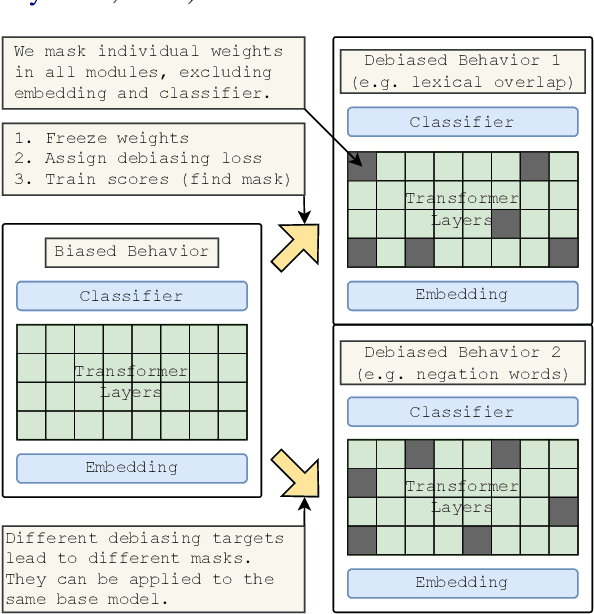
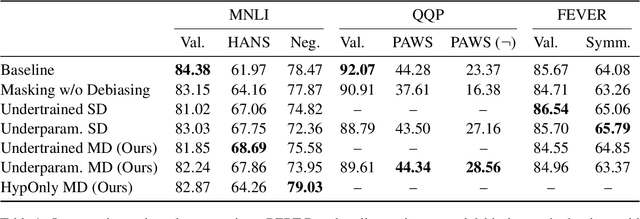
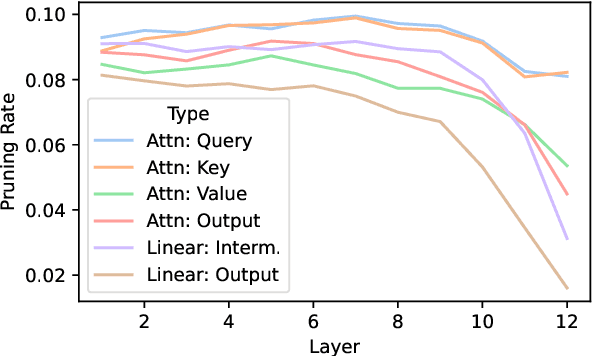
Debiasing language models from unwanted behaviors in Natural Language Understanding tasks is a topic with rapidly increasing interest in the NLP community. Spurious statistical correlations in the data allow models to perform shortcuts and avoid uncovering more advanced and desirable linguistic features. A multitude of effective debiasing approaches has been proposed, but flexibility remains a major issue. For the most part, models must be retrained to find a new set of weights with debiased behavior. We propose a new debiasing method in which we identify debiased pruning masks that can be applied to a finetuned model. This enables the selective and conditional application of debiasing behaviors. We assume that bias is caused by a certain subset of weights in the network; our method is, in essence, a mask search to identify and remove biased weights. Our masks show equivalent or superior performance to the standard counterparts, while offering important benefits. Pruning masks can be stored with high efficiency in memory, and it becomes possible to switch among several debiasing behaviors (or revert back to the original biased model) at inference time. Finally, it opens the doors to further research on how biases are acquired by studying the generated masks. For example, we observed that the early layers and attention heads were pruned more aggressively, possibly hinting towards the location in which biases may be encoded.
A Novel Sparse Bayesian Learning and Its Application to Fault Diagnosis for Multistation Assembly Systems
Oct 28, 2022
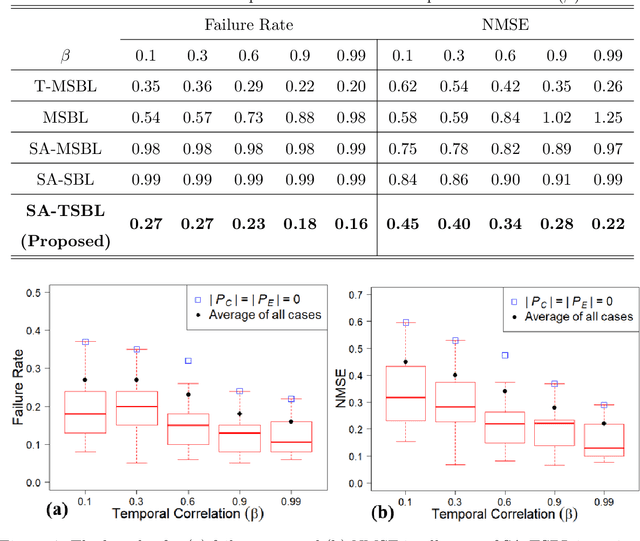
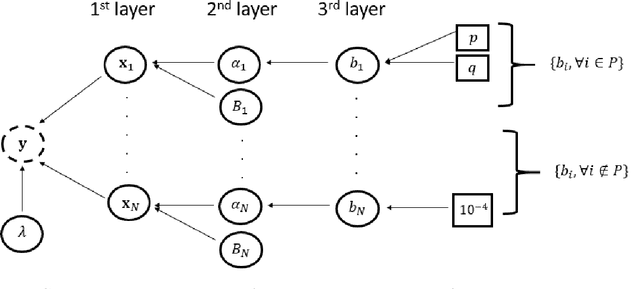
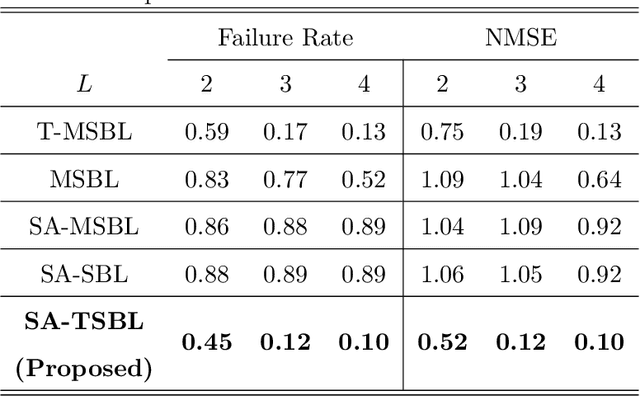
This paper addresses the problem of fault diagnosis in multistation assembly systems. Fault diagnosis is to identify process faults that cause the excessive dimensional variation of the product using dimensional measurements. For such problems, the challenge is solving an underdetermined system caused by a common phenomenon in practice; namely, the number of measurements is less than that of the process errors. To address this challenge, this paper attempts to solve the following two problems: (1) how to utilize the temporal correlation in the time series data of each process error and (2) how to apply prior knowledge regarding which process errors are more likely to be process faults. A novel sparse Bayesian learning method is proposed to achieve the above objectives. The method consists of three hierarchical layers. The first layer has parameterized prior distribution that exploits the temporal correlation of each process error. Furthermore, the second and third layers achieve the prior distribution representing the prior knowledge of process faults. Then, these prior distributions are updated with the likelihood function of the measurement samples from the process, resulting in the accurate posterior distribution of process faults from an underdetermined system. Since posterior distributions of process faults are intractable, this paper derives approximate posterior distributions via Variational Bayes inference. Numerical and simulation case studies using an actual autobody assembly process are performed to demonstrate the effectiveness of the proposed method.
ODNet: A Convolutional Neural Network for Asteroid Occultation Detection
Oct 28, 2022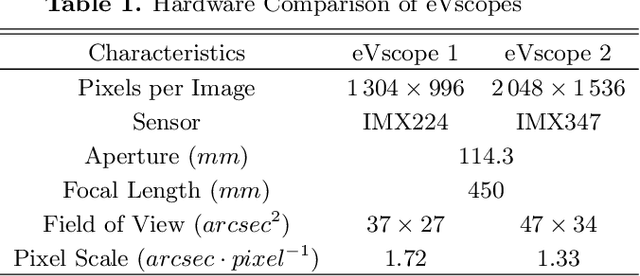

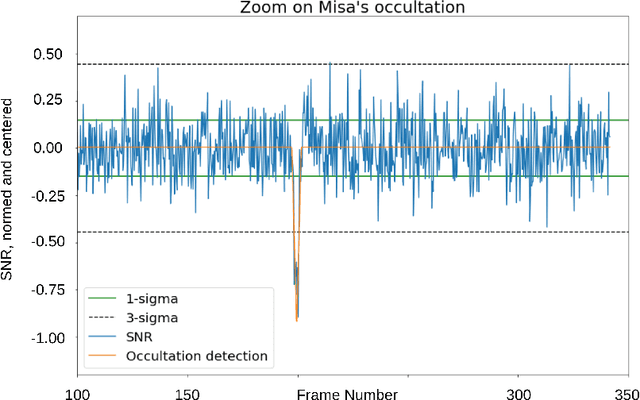

We propose to design and build an algorithm that will use a Convolutional Neural Network (CNN) and observations from the Unistellar network to reliably detect asteroid occultations. The Unistellar Network, made of more than 10,000 digital telescopes owned by citizen scientists, and is regularly used to record asteroid occultations. In order to process the increasing amount of observational produced by this network, we need a quick and reliable way to analyze occultations. In an effort to solve this problem, we trained a CNN with artificial images of stars with twenty different types of photometric signals. Inputs to the network consists of two stacks of snippet images of stars, one around the star that is supposed to be occulted and a reference star used for comparison. We need the reference star to distinguish between a true occultation and artefacts introduced by poor atmospheric condition. Our Occultation Detection Neural Network (ODNet), can analyze three sequence of stars per second with 91\% of precision and 87\% of recall. The algorithm is sufficiently fast and robust so we can envision incorporating onboard the eVscopes to deliver real-time results. We conclude that citizen science represents an important opportunity for the future studies and discoveries in the occultations, and that application of artificial intelligence will permit us to to take better advantage of the ever-growing quantity of data to categorize asteroids.
Federated Learning based Energy Demand Prediction with Clustered Aggregation
Oct 28, 2022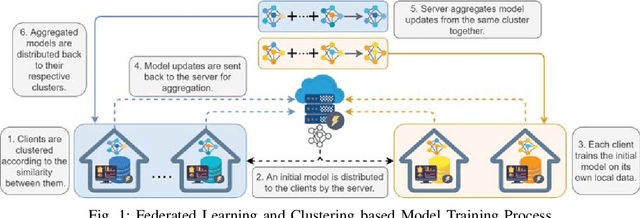
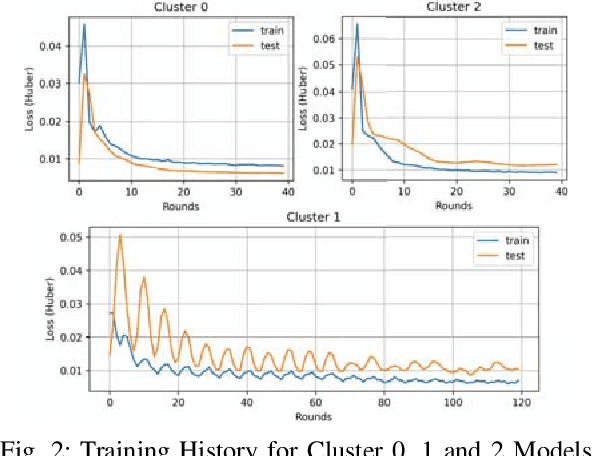
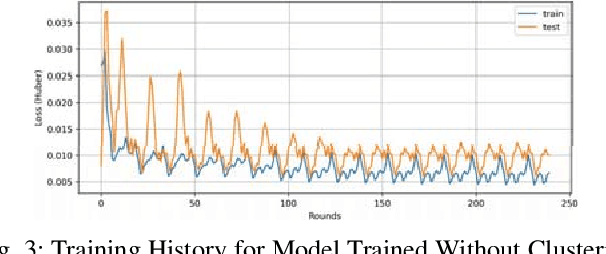
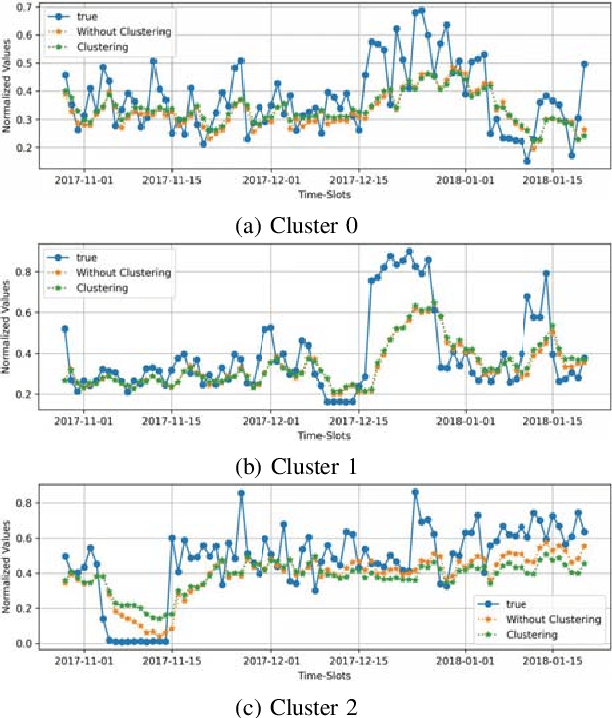
To reduce negative environmental impacts, power stations and energy grids need to optimize the resources required for power production. Thus, predicting the energy consumption of clients is becoming an important part of every energy management system. Energy usage information collected by the clients' smart homes can be used to train a deep neural network to predict the future energy demand. Collecting data from a large number of distributed clients for centralized model training is expensive in terms of communication resources. To take advantage of distributed data in edge systems, centralized training can be replaced by federated learning where each client only needs to upload model updates produced by training on its local data. These model updates are aggregated into a single global model by the server. But since different clients can have different attributes, model updates can have diverse weights and as a result, it can take a long time for the aggregated global model to converge. To speed up the convergence process, we can apply clustering to group clients based on their properties and aggregate model updates from the same cluster together to produce a cluster specific global model. In this paper, we propose a recurrent neural network based energy demand predictor, trained with federated learning on clustered clients to take advantage of distributed data and speed up the convergence process.
Beyond Not-Forgetting: Continual Learning with Backward Knowledge Transfer
Nov 01, 2022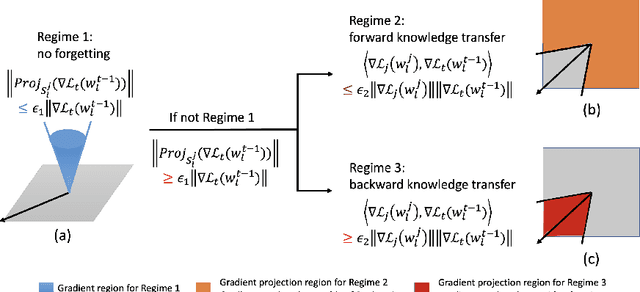
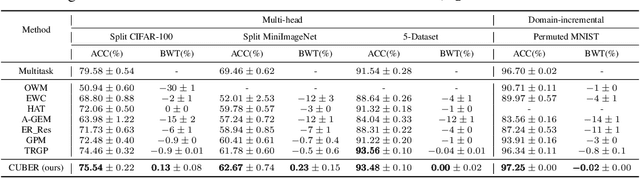


By learning a sequence of tasks continually, an agent in continual learning (CL) can improve the learning performance of both a new task and `old' tasks by leveraging the forward knowledge transfer and the backward knowledge transfer, respectively. However, most existing CL methods focus on addressing catastrophic forgetting in neural networks by minimizing the modification of the learnt model for old tasks. This inevitably limits the backward knowledge transfer from the new task to the old tasks, because judicious model updates could possibly improve the learning performance of the old tasks as well. To tackle this problem, we first theoretically analyze the conditions under which updating the learnt model of old tasks could be beneficial for CL and also lead to backward knowledge transfer, based on the gradient projection onto the input subspaces of old tasks. Building on the theoretical analysis, we next develop a ContinUal learning method with Backward knowlEdge tRansfer (CUBER), for a fixed capacity neural network without data replay. In particular, CUBER first characterizes the task correlation to identify the positively correlated old tasks in a layer-wise manner, and then selectively modifies the learnt model of the old tasks when learning the new task. Experimental studies show that CUBER can even achieve positive backward knowledge transfer on several existing CL benchmarks for the first time without data replay, where the related baselines still suffer from catastrophic forgetting (negative backward knowledge transfer). The superior performance of CUBER on the backward knowledge transfer also leads to higher accuracy accordingly.
CCS Explorer: Relevance Prediction, Extractive Summarization, and Named Entity Recognition from Clinical Cohort Studies
Nov 01, 2022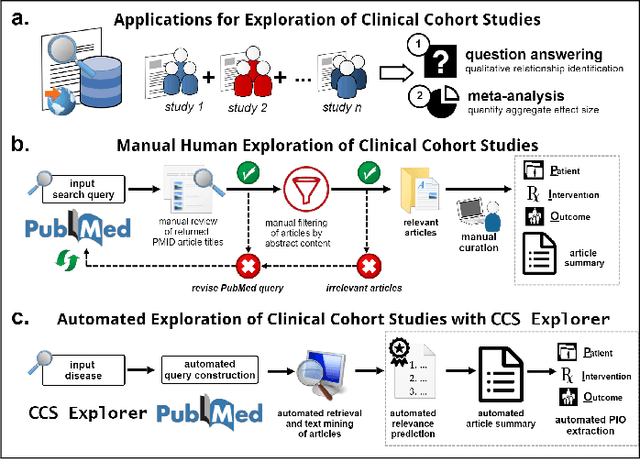
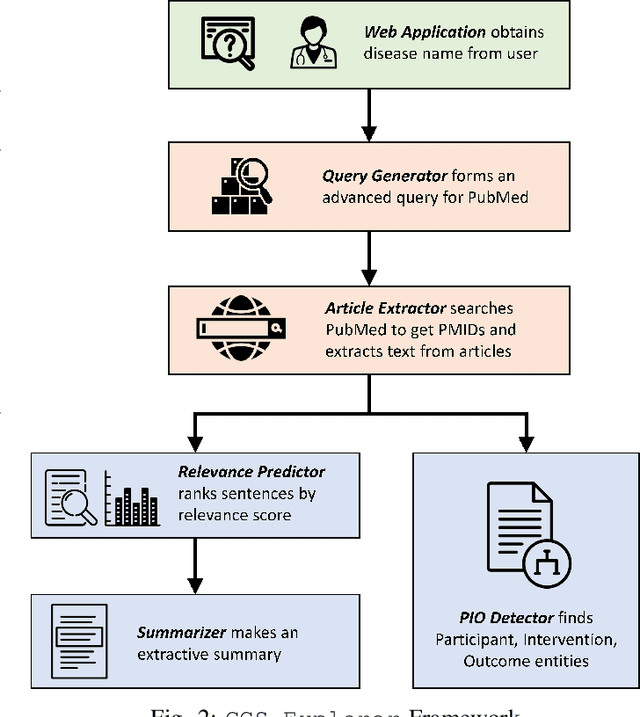
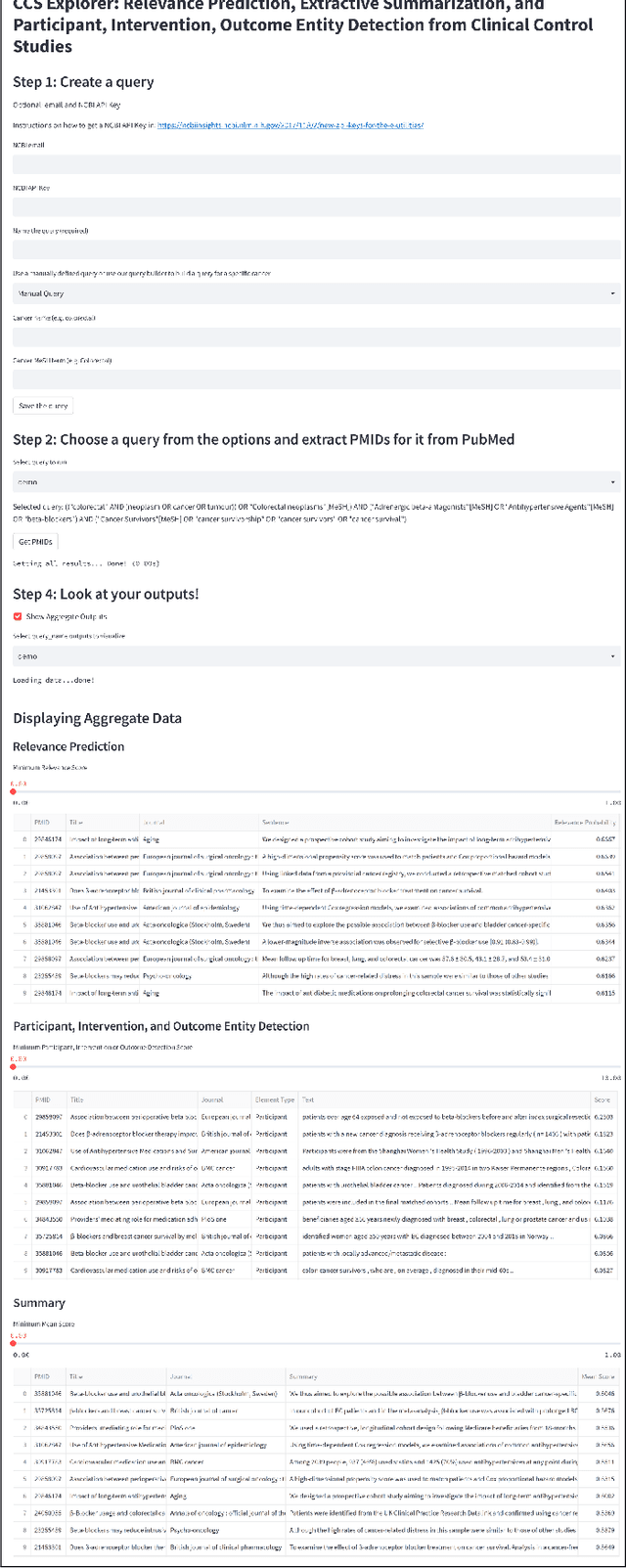
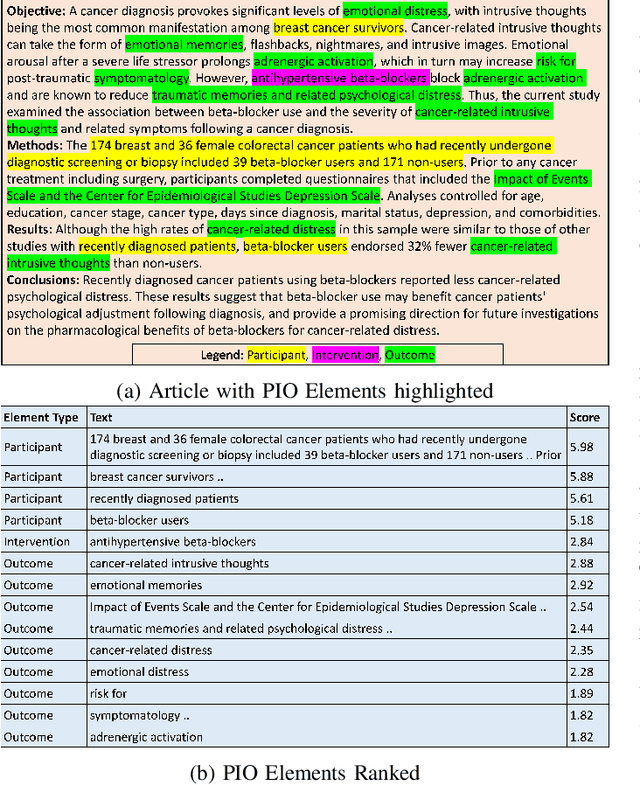
Clinical Cohort Studies (CCS) are a great source of documented clinical research. Ideally, a clinical expert will interpret these articles for exploratory analysis ranging from drug discovery for evaluating the efficacy of existing drugs in tackling emerging diseases to the first test of newly developed drugs. However, more than 100 CCS articles are published on PubMed every day. As a result, it can take days for a doctor to find articles and extract relevant information. Can we find a way to quickly sift through the long list of these articles faster and document the crucial takeaways from each of these articles? In this work, we propose CCS Explorer, an end-to-end system for relevance prediction of sentences, extractive summarization, and patient, outcome, and intervention entity detection from CCS. CCS Explorer is packaged in a web-based graphical user interface where the user can provide any disease name. CCS Explorer then extracts and aggregates all relevant information from articles on PubMed based on the results of an automatically generated query produced on the back-end. CCS Explorer fine-tunes pre-trained language models based on transformers with additional layers for each of these tasks. We evaluate the models using two publicly available datasets. CCS Explorer obtains a recall of 80.2%, AUC-ROC of 0.843, and an accuracy of 88.3% on sentence relevance prediction using BioBERT and achieves an average Micro F1-Score of 77.8% on Patient, Intervention, Outcome detection (PIO) using PubMedBERT. Thus, CCS Explorer can reliably extract relevant information to summarize articles, saving time by ~ 660$\times$.
Self-Supervised Real-time Video Stabilization
Nov 10, 2021
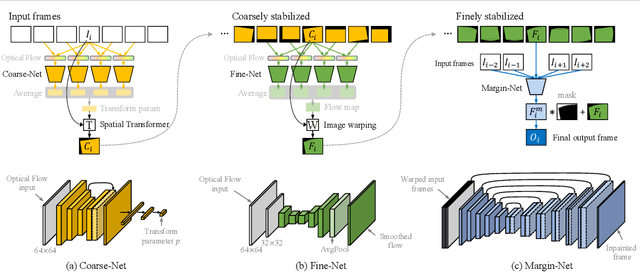

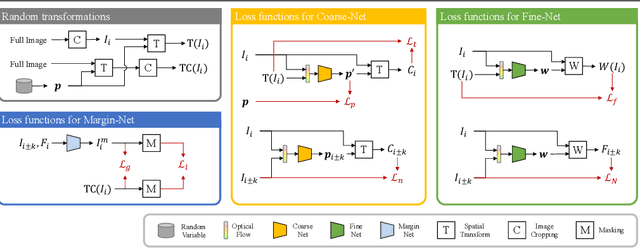
Videos are a popular media form, where online video streaming has recently gathered much popularity. In this work, we propose a novel method of real-time video stabilization - transforming a shaky video to a stabilized video as if it were stabilized via gimbals in real-time. Our framework is trainable in a self-supervised manner, which does not require data captured with special hardware setups (i.e., two cameras on a stereo rig or additional motion sensors). Our framework consists of a transformation estimator between given frames for global stability adjustments, followed by scene parallax reduction module via spatially smoothed optical flow for further stability. Then, a margin inpainting module fills in the missing margin regions created during stabilization to reduce the amount of post-cropping. These sequential steps reduce distortion and margin cropping to a minimum while enhancing stability. Hence, our approach outperforms state-of-the-art real-time video stabilization methods as well as offline methods that require camera trajectory optimization. Our method procedure takes approximately 24.3 ms yielding 41 fps regardless of resolution (e.g., 480p or 1080p).
Time flies by: Analyzing the Impact of Face Ageing on the Recognition Performance with Synthetic Data
Aug 17, 2022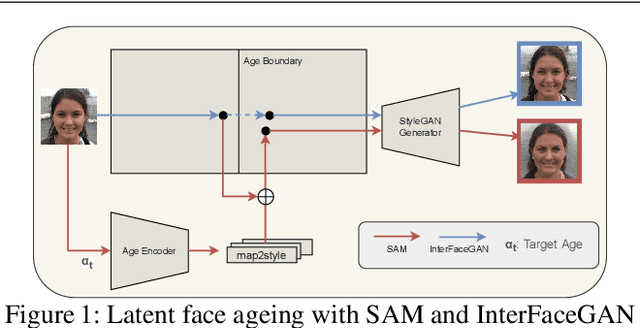
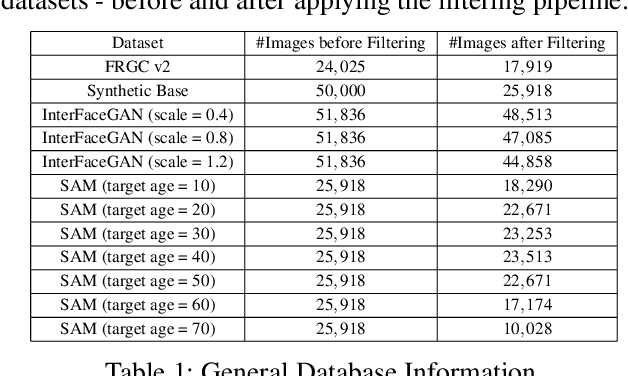
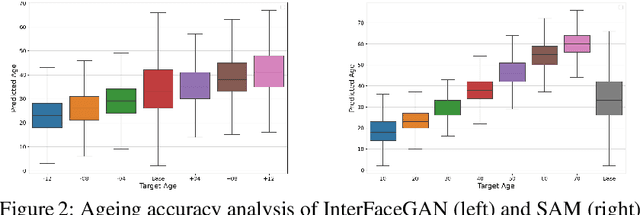
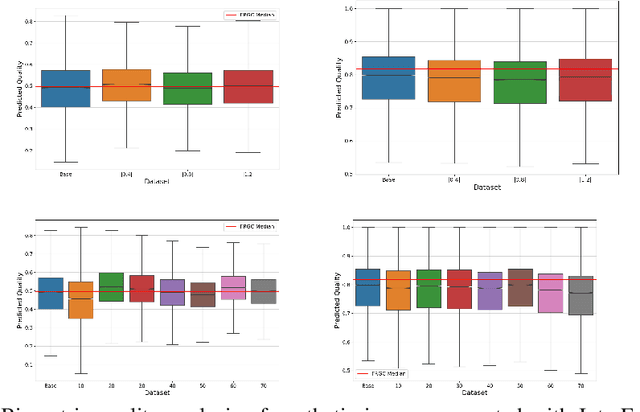
The vast progress in synthetic image synthesis enables the generation of facial images in high resolution and photorealism. In biometric applications, the main motivation for using synthetic data is to solve the shortage of publicly-available biometric data while reducing privacy risks when processing such sensitive information. These advantages are exploited in this work by simulating human face ageing with recent face age modification algorithms to generate mated samples, thereby studying the impact of ageing on the performance of an open-source biometric recognition system. Further, a real dataset is used to evaluate the effects of short-term ageing, comparing the biometric performance to the synthetic domain. The main findings indicate that short-term ageing in the range of 1-5 years has only minor effects on the general recognition performance. However, the correct verification of mated faces with long-term age differences beyond 20 years poses still a significant challenge and requires further investigation.
A Robust and Explainable Data-Driven Anomaly Detection Approach For Power Electronics
Sep 23, 2022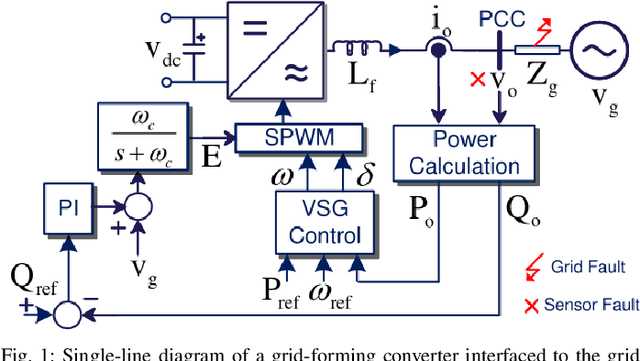
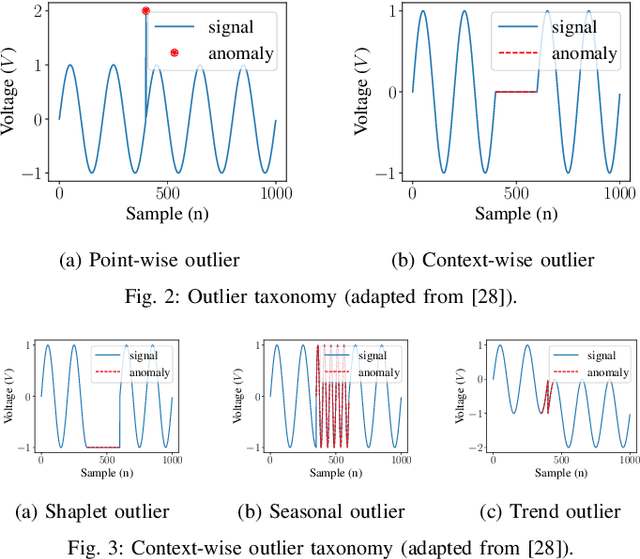
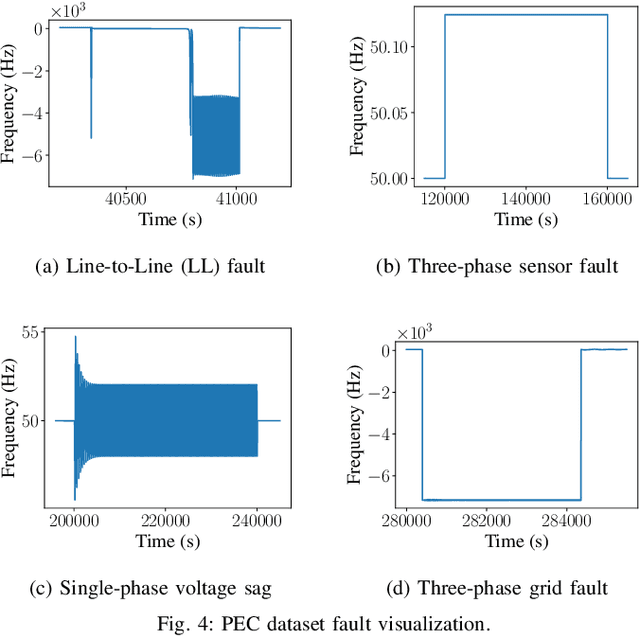
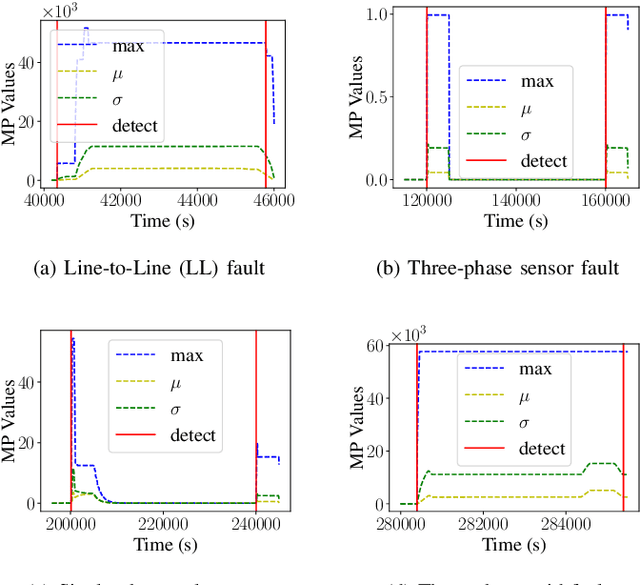
Timely and accurate detection of anomalies in power electronics is becoming increasingly critical for maintaining complex production systems. Robust and explainable strategies help decrease system downtime and preempt or mitigate infrastructure cyberattacks. This work begins by explaining the types of uncertainty present in current datasets and machine learning algorithm outputs. Three techniques for combating these uncertainties are then introduced and analyzed. We further present two anomaly detection and classification approaches, namely the Matrix Profile algorithm and anomaly transformer, which are applied in the context of a power electronic converter dataset. Specifically, the Matrix Profile algorithm is shown to be well suited as a generalizable approach for detecting real-time anomalies in streaming time-series data. The STUMPY python library implementation of the iterative Matrix Profile is used for the creation of the detector. A series of custom filters is created and added to the detector to tune its sensitivity, recall, and detection accuracy. Our numerical results show that, with simple parameter tuning, the detector provides high accuracy and performance in a variety of fault scenarios.