 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Two-Stage Deep Representation Learning-Based Speech Enhancement Method Using Variational Autoencoder and Adversarial Training
Nov 16, 2022
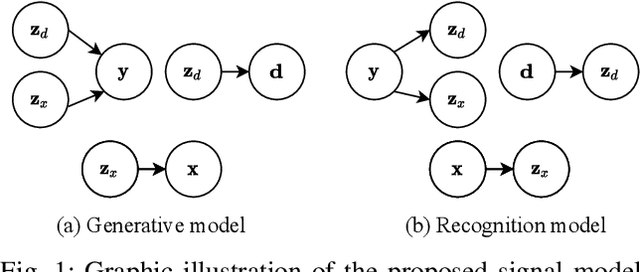
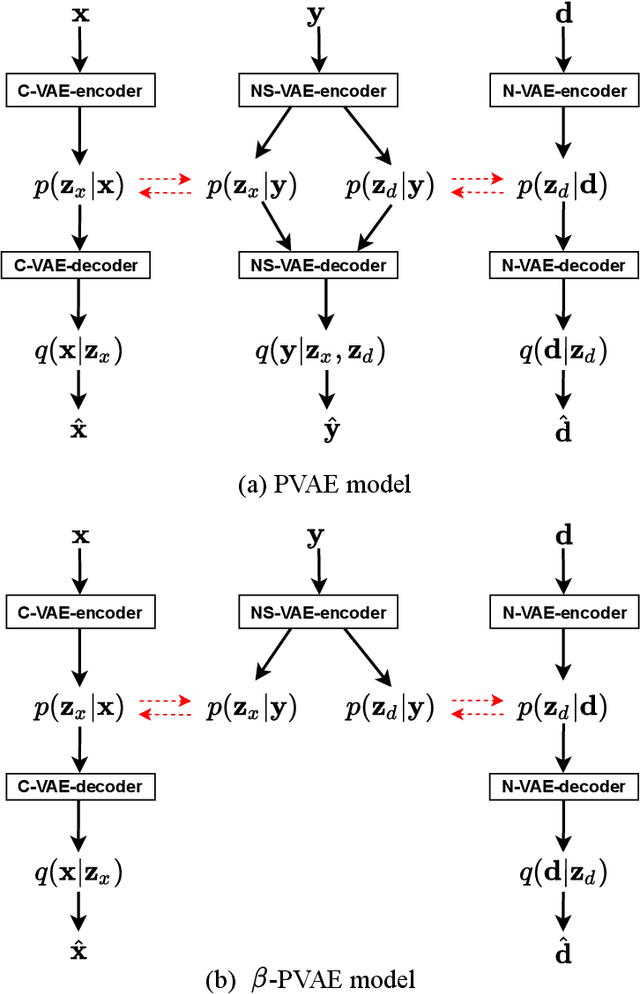
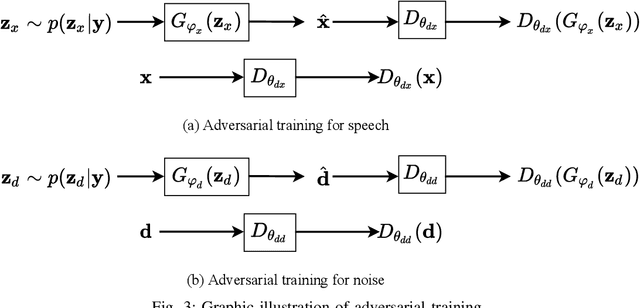
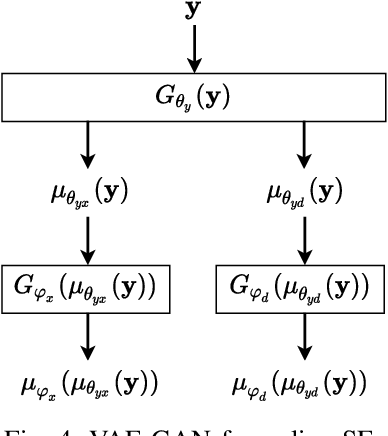
This paper focuses on leveraging deep representation learning (DRL) for speech enhancement (SE). In general, the performance of the deep neural network (DNN) is heavily dependent on the learning of data representation. However, the DRL's importance is often ignored in many DNN-based SE algorithms. To obtain a higher quality enhanced speech, we propose a two-stage DRL-based SE method through adversarial training. In the first stage, we disentangle different latent variables because disentangled representations can help DNN generate a better enhanced speech. Specifically, we use the $\beta$-variational autoencoder (VAE) algorithm to obtain the speech and noise posterior estimations and related representations from the observed signal. However, since the posteriors and representations are intractable and we can only apply a conditional assumption to estimate them, it is difficult to ensure that these estimations are always pretty accurate, which may potentially degrade the final accuracy of the signal estimation. To further improve the quality of enhanced speech, in the second stage, we introduce adversarial training to reduce the effect of the inaccurate posterior towards signal reconstruction and improve the signal estimation accuracy, making our algorithm more robust for the potentially inaccurate posterior estimations. As a result, better SE performance can be achieved. The experimental results indicate that the proposed strategy can help similar DNN-based SE algorithms achieve higher short-time objective intelligibility (STOI), perceptual evaluation of speech quality (PESQ), and scale-invariant signal-to-distortion ratio (SI-SDR) scores. Moreover, the proposed algorithm can also outperform recent competitive SE algorithms.
The availability, outage, and capacity of spatially correlated, Australasian free-space optical networks
Nov 16, 2022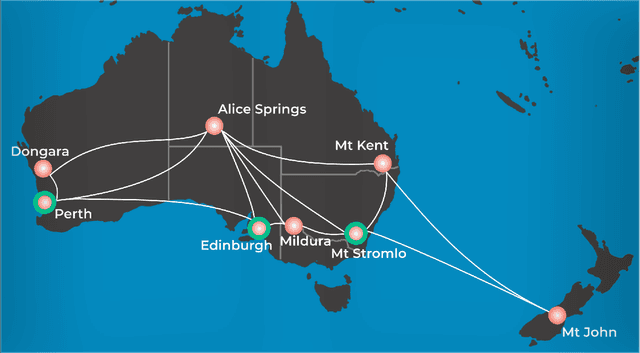
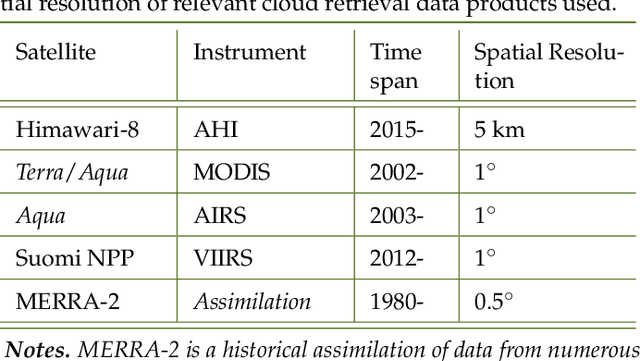
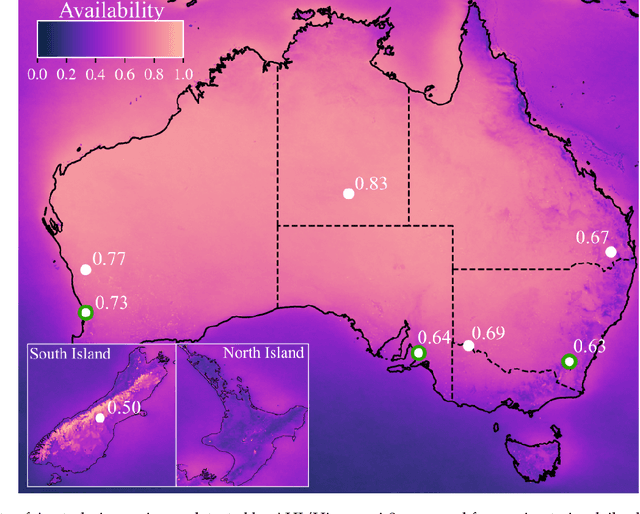
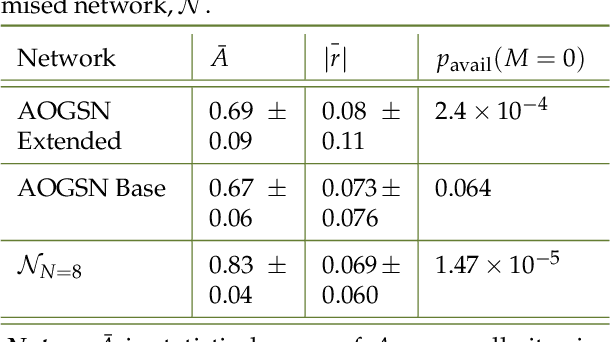
Network capacity and reliability for free space optical communication (FSOC) is strongly driven by ground station availability, dominated by local cloud cover causing an outage, and how availability relations between stations produce network diversity. We combine remote sensing data and novel methods to provide a generalised framework for assessing and optimising optical ground station networks. This work is guided by an example network of eight Australian and New Zealand optical communication ground stations which would span approximately $60^\circ$ in longitude and $20^\circ$ in latitude. Utilising time-dependent cloud cover data from five satellites, we present a detailed analysis determining the availability and diversity of the network, finding the Australasian region is well-suited for an optical network with a 69% average site availability and low spatial cloud cover correlations. Employing methods from computational neuroscience, we provide a Monte Carlo method for sampling the joint probability distribution of site availabilities for an arbitrarily sized and point-wise correlated network of ground stations. Furthermore, we develop a general heuristic for site selection under availability and correlation optimisations, and combine this with orbital propagation simulations to compare the data capacity between optimised networks and the example network. We show that the example network may be capable of providing tens of terabits per day to a LEO satellite, and up to 99.97% reliability to GEO satellites. We therefore use the Australasian region to demonstrate novel, generalised tools for assessing and optimising FSOC ground station networks, and additionally, the suitability of the region for hosting such a network.
Squeeze flow of micro-droplets: convolutional neural network with trainable and tunable refinement
Nov 16, 2022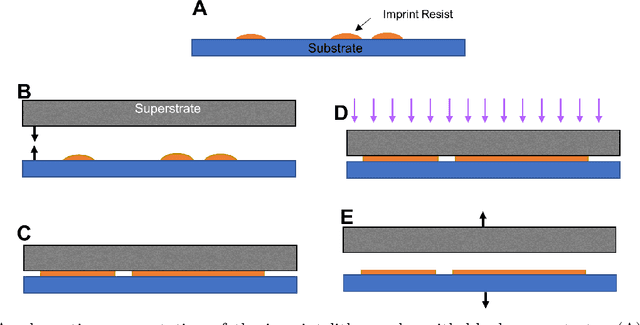
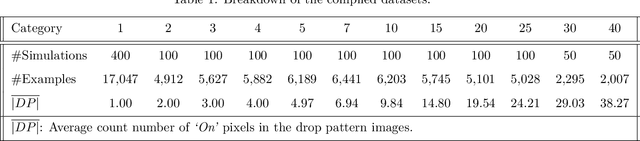
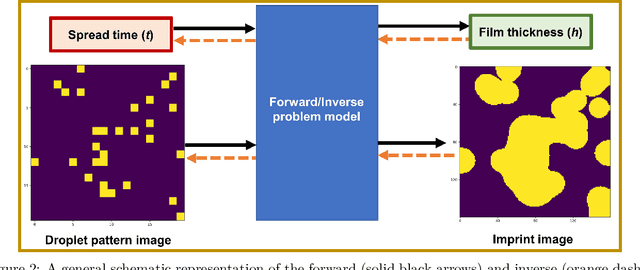
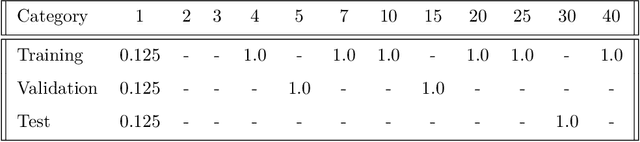
We propose a platform based on neural networks to solve the image-to-image translation problem in the context of squeeze flow of micro-droplets. In the first part of this paper, we present the governing partial differential equations to lay out the underlying physics of the problem. We also discuss our developed Python package, sqflow, which can potentially serve as free, flexible, and scalable standardized benchmarks in the fields of machine learning and computer vision. In the second part of this paper, we introduce a residual convolutional neural network to solve the corresponding inverse problem: to translate a high-resolution (HR) imprint image with a specific liquid film thickness to a low-resolution (LR) droplet pattern image capable of producing the given imprint image for an appropriate spread time of droplets. We propose a neural network architecture that learns to systematically tune the refinement level of its residual convolutional blocks by using the function approximators that are trained to map a given input parameter (film thickness) to an appropriate refinement level indicator. We use multiple stacks of convolutional layers the output of which is translated according to the refinement level indicators provided by the directly-connected function approximators. Together with a non-linear activation function, such a translation mechanism enables the HR imprint image to be refined sequentially in multiple steps until the target LR droplet pattern image is revealed. The proposed platform can be potentially applied to data compression and data encryption. The developed package and datasets are publicly available on GitHub at https://github.com/sqflow/sqflow.
Differentially Private Optimization on Large Model at Small Cost
Sep 30, 2022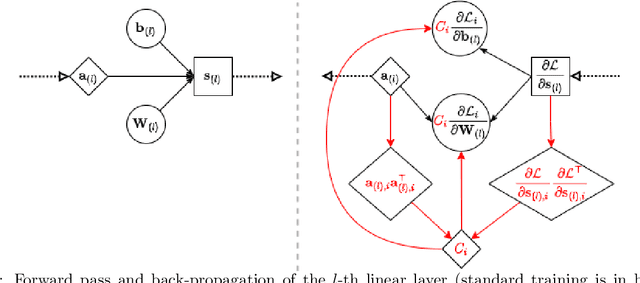

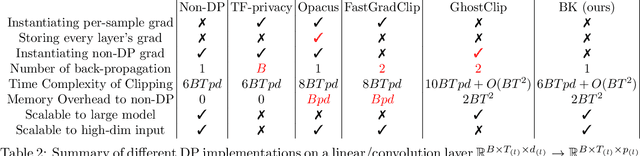

Differentially private (DP) optimization is the standard paradigm to learn large neural networks that are accurate and privacy-preserving. The computational cost for DP deep learning, however, is notoriously heavy due to the per-sample gradient clipping. Existing DP implementations are $2-1000\times$ more costly in time and space complexity than the standard (non-private) training. In this work, we develop a novel Book-Keeping (BK) technique that implements existing DP optimizers (thus achieving the same accuracy), with a substantial improvement on the computational cost. Specifically, BK enables DP training on large models and high dimensional data to be roughly as efficient as the standard training, whereas previous DP algorithms can be inefficient or incapable of training due to memory error. The computational advantage of BK is supported by the complexity analysis as well as extensive experiments on vision and language tasks. Our implementation achieves state-of-the-art (SOTA) accuracy with very small extra cost: on GPT2 and at the same memory cost, BK has 1.0$\times$ the time complexity of the standard training (0.75$\times$ training speed in practice), and 0.6$\times$ the time complexity of the most efficient DP implementation (1.24$\times$ training speed in practice). We will open-source the codebase for the BK algorithm.
ATRAPOS: Evaluating Metapath Query Workloads in Real Time
Jan 11, 2022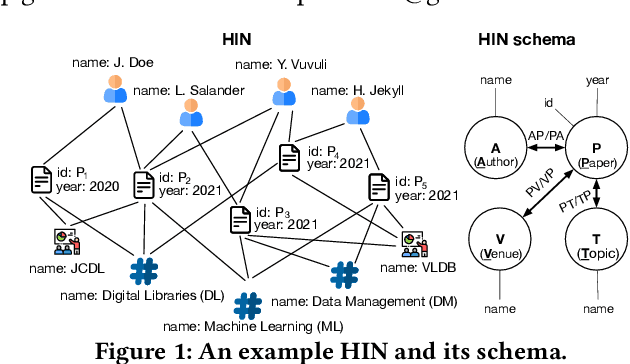

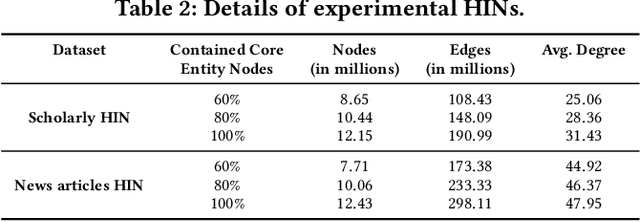
Heterogeneous information networks (HINs) represent different types of entities and relationships between them. Exploring, analysing, and extracting knowledge from such networks relies on metapath queries that identify pairs of entities connected by relationships of diverse semantics. While the real-time evaluation of metapath query workloads on large, web-scale HINs is highly demanding in computational cost, current approaches do not exploit interrelationships among the queries. In this paper, we present ATRAPOS, a new approach for the real-time evaluation of metapath query workloads that leverages a combination of efficient sparse matrix multiplication and intermediate result caching. ATRAPOS selects intermediate results to cache and reuse by detecting frequent sub-metapaths among workload queries in real time, using a tailor-made data structure, the Overlap Tree, and an associated caching policy. Our experimental study on real data shows that ATRAPOS accelerates exploratory data analysis and mining on HINs, outperforming off-the-shelf caching approaches and state-of-the-art research prototypes in all examined scenarios.
Many processors, little time: MCMC for partitions via optimal transport couplings
Feb 23, 2022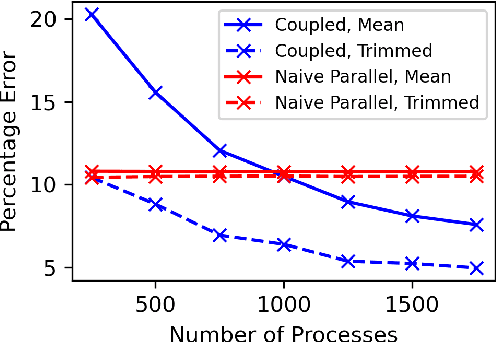
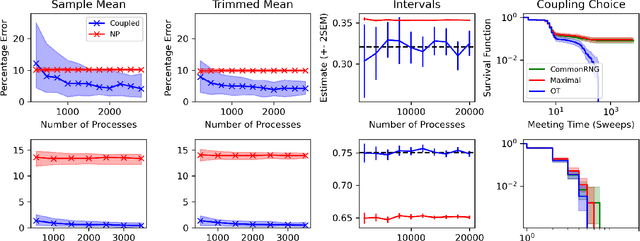
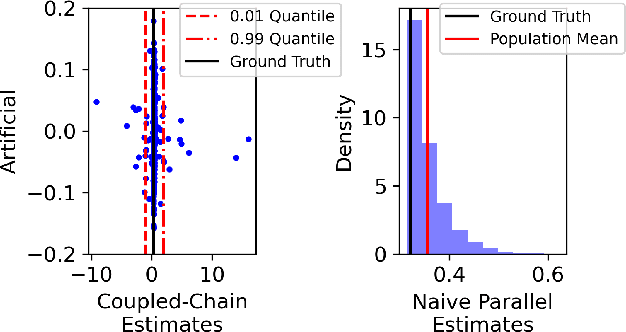
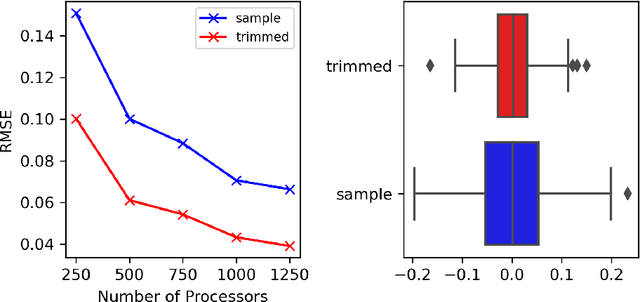
Markov chain Monte Carlo (MCMC) methods are often used in clustering since they guarantee asymptotically exact expectations in the infinite-time limit. In finite time, though, slow mixing often leads to poor performance. Modern computing environments offer massive parallelism, but naive implementations of parallel MCMC can exhibit substantial bias. In MCMC samplers of continuous random variables, Markov chain couplings can overcome bias. But these approaches depend crucially on paired chains meetings after a small number of transitions. We show that straightforward applications of existing coupling ideas to discrete clustering variables fail to meet quickly. This failure arises from the "label-switching problem": semantically equivalent cluster relabelings impede fast meeting of coupled chains. We instead consider chains as exploring the space of partitions rather than partitions' (arbitrary) labelings. Using a metric on the partition space, we formulate a practical algorithm using optimal transport couplings. Our theory confirms our method is accurate and efficient. In experiments ranging from clustering of genes or seeds to graph colorings, we show the benefits of our coupling in the highly parallel, time-limited regime.
SFCW GPR tree roots detection enhancement by time frequency analysis in tropical areas
Apr 06, 2022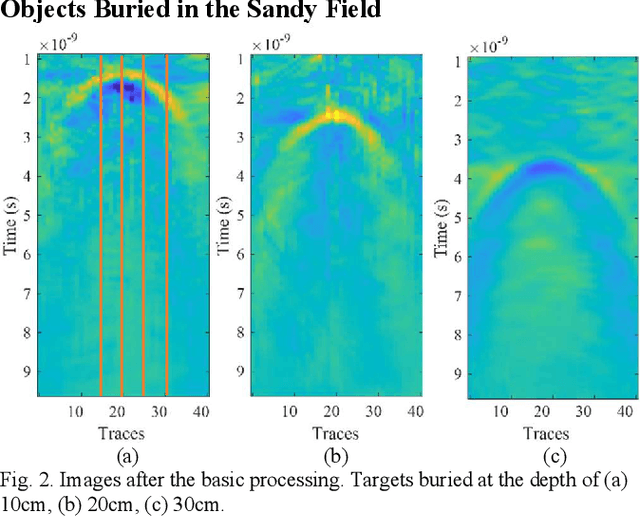
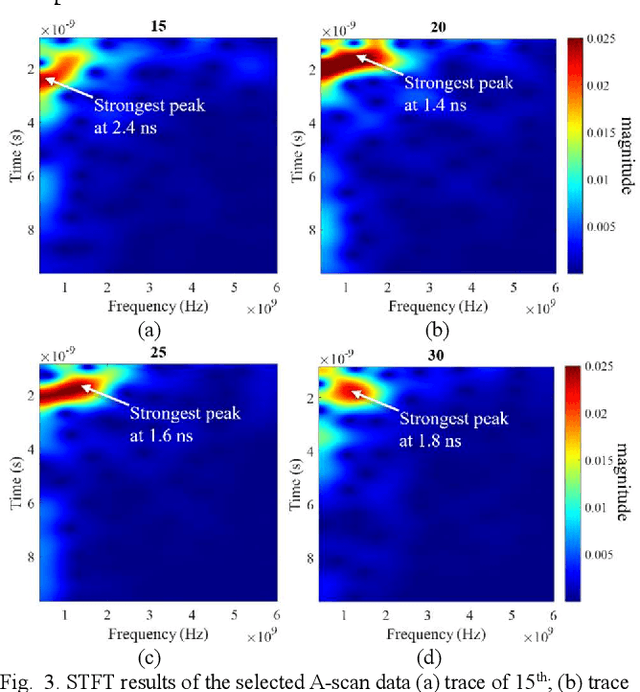
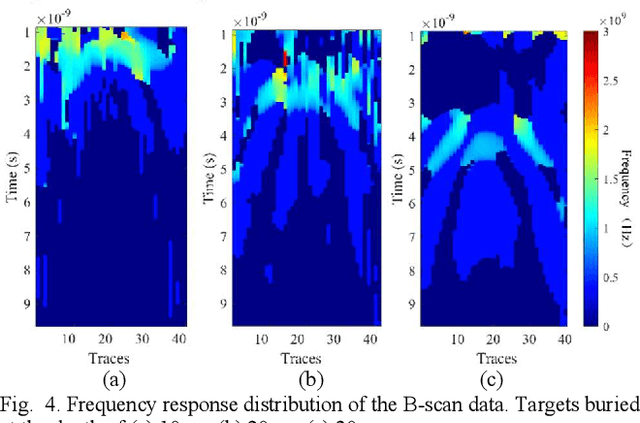
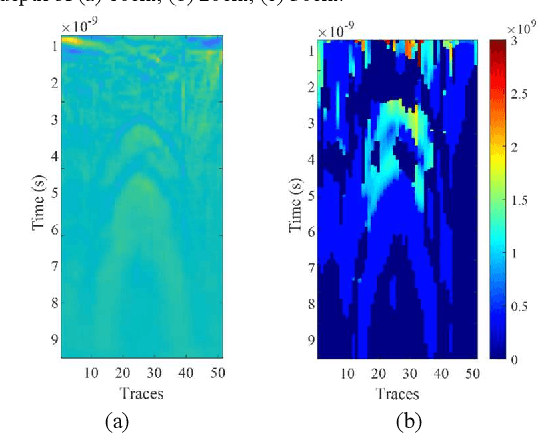
Accurate monitoring of tree roots using ground penetrating radar (GPR) is very useful in assessing the trees health. In high moisture tropical areas such as Singapore, tree fall due to root rot can cause loss of lives and properties. The tropical complex soil characteristics due to the high moisture content tends to affect penetration depth of the signal. This limits the depth range of the GPR. Typically, a wide band signal is used to increase the penetration depth and to improve the resolution of the GPR. However, this broad band frequency tends to be noisy and selective frequency filtering is required for noise reduction. Therefore, in this paper, we adapt the stepped frequency continuous wave (SFCW) GPR and propose the use of a Joint time frequency analysis (JTFA) method called short time Fourier transform (STFT), to reduce noise and enhance tree root detection. The proposed methodology is illustrated and tested with controlled experiments and real tree roots testing. The results show promising prospects of the method for tree roots detection in tropical areas.
Learning Fast and Slow for Online Time Series Forecasting
Feb 23, 2022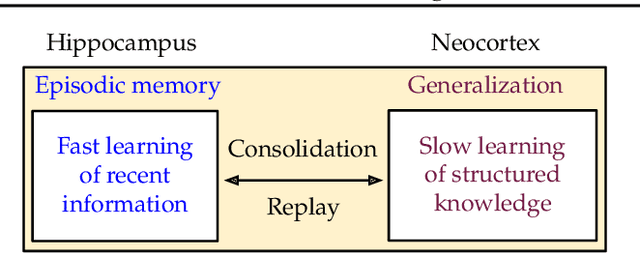
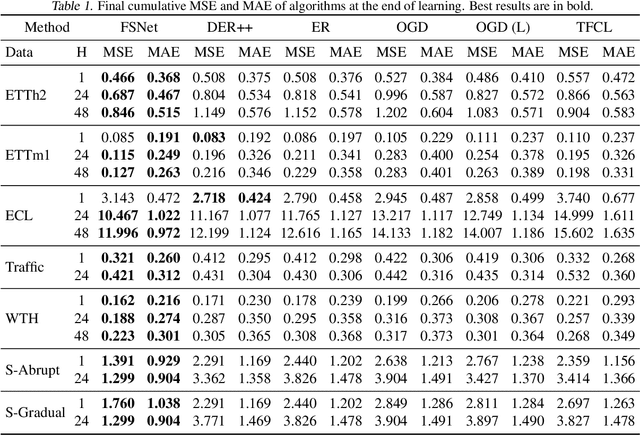
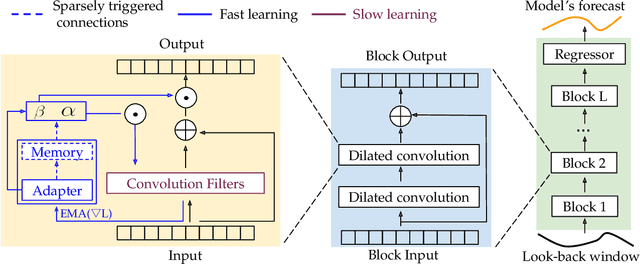
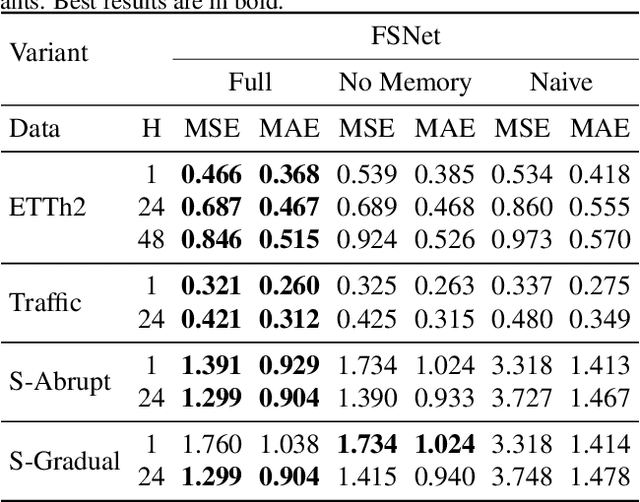
The fast adaptation capability of deep neural networks in non-stationary environments is critical for online time series forecasting. Successful solutions require handling changes to new and recurring patterns. However, training deep neural forecaster on the fly is notoriously challenging because of their limited ability to adapt to non-stationary environments and the catastrophic forgetting of old knowledge. In this work, inspired by the Complementary Learning Systems (CLS) theory, we propose Fast and Slow learning Networks (FSNet), a holistic framework for online time-series forecasting to simultaneously deal with abrupt changing and repeating patterns. Particularly, FSNet improves the slowly-learned backbone by dynamically balancing fast adaptation to recent changes and retrieving similar old knowledge. FSNet achieves this mechanism via an interaction between two complementary components of an adapter to monitor each layer's contribution to the lost, and an associative memory to support remembering, updating, and recalling repeating events. Extensive experiments on real and synthetic datasets validate FSNet's efficacy and robustness to both new and recurring patterns. Our code will be made publicly available.
S-Rocket: Selective Random Convolution Kernels for Time Series Classification
Mar 07, 2022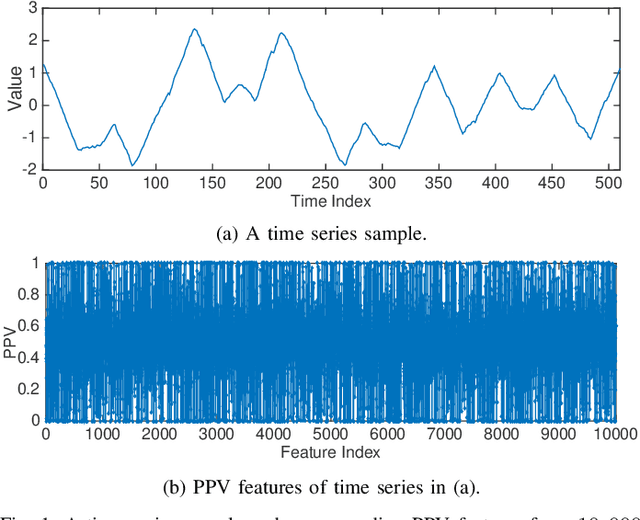
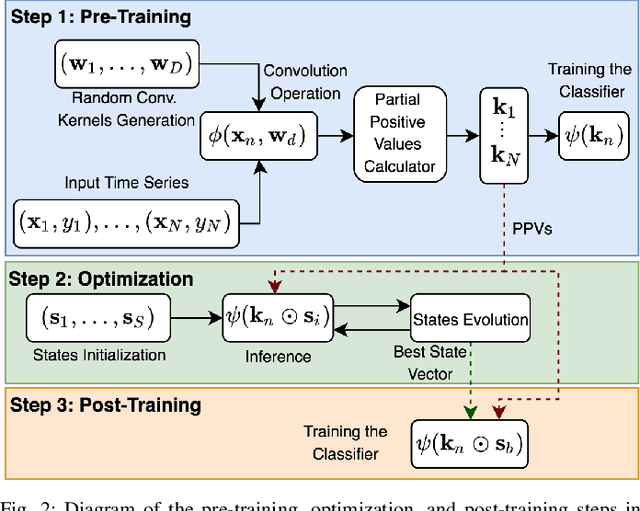
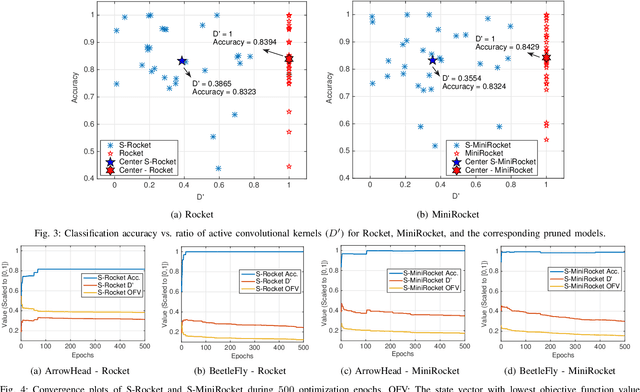
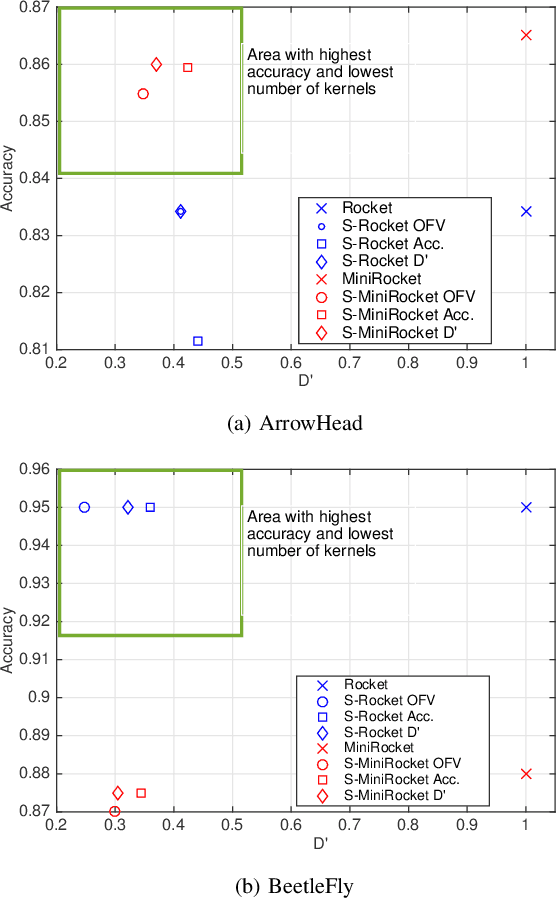
Random convolution kernel transform (Rocket) is a fast, efficient, and novel approach for time series feature extraction, using a large number of randomly initialized convolution kernels, and classification of the represented features with a linear classifier, without training the kernels. Since these kernels are generated randomly, a portion of these kernels may not positively contribute in performance of the model. Hence, selection of the most important kernels and pruning the redundant and less important ones is necessary to reduce computational complexity and accelerate inference of Rocket. Selection of these kernels is a combinatorial optimization problem. In this paper, the kernels selection process is modeled as an optimization problem and a population-based approach is proposed for selecting the most important kernels. This approach is evaluated on the standard time series datasets and the results show that on average it can achieve a similar performance to the original models by pruning more than 60% of kernels. In some cases, it can achieve a similar performance using only 1% of the kernels.
Self-distillation with Online Diffusion on Batch Manifolds Improves Deep Metric Learning
Nov 14, 2022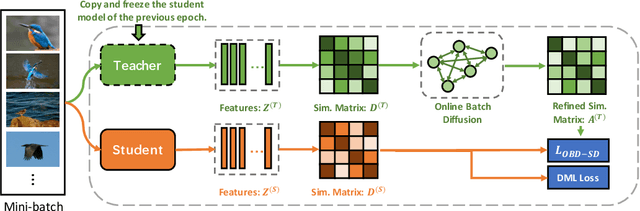

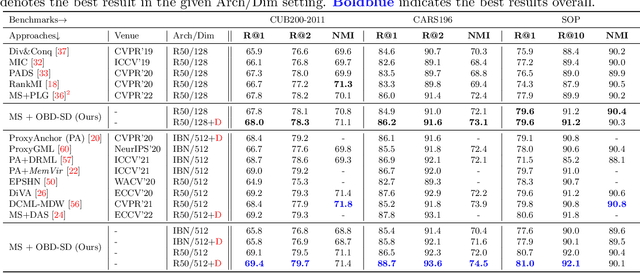
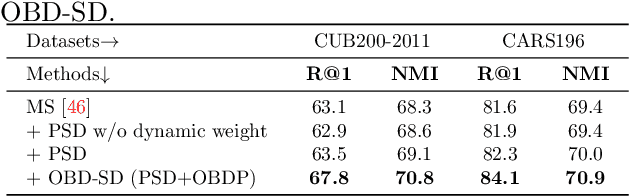
Recent deep metric learning (DML) methods typically leverage solely class labels to keep positive samples far away from negative ones. However, this type of method normally ignores the crucial knowledge hidden in the data (e.g., intra-class information variation), which is harmful to the generalization of the trained model. To alleviate this problem, in this paper we propose Online Batch Diffusion-based Self-Distillation (OBD-SD) for DML. Specifically, we first propose a simple but effective Progressive Self-Distillation (PSD), which distills the knowledge progressively from the model itself during training. The soft distance targets achieved by PSD can present richer relational information among samples, which is beneficial for the diversity of embedding representations. Then, we extend PSD with an Online Batch Diffusion Process (OBDP), which is to capture the local geometric structure of manifolds in each batch, so that it can reveal the intrinsic relationships among samples in the batch and produce better soft distance targets. Note that our OBDP is able to restore the insufficient manifold relationships obtained by the original PSD and achieve significant performance improvement. Our OBD-SD is a flexible framework that can be integrated into state-of-the-art (SOTA) DML methods. Extensive experiments on various benchmarks, namely CUB200, CARS196, and Stanford Online Products, demonstrate that our OBD-SD consistently improves the performance of the existing DML methods on multiple datasets with negligible additional training time, achieving very competitive results. Code: \url{https://github.com/ZelongZeng/OBD-SD_Pytorch}