 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On The Computational Complexity of Self-Attention
Sep 11, 2022

Transformer architectures have led to remarkable progress in many state-of-art applications. However, despite their successes, modern transformers rely on the self-attention mechanism, whose time- and space-complexity is quadratic in the length of the input. Several approaches have been proposed to speed up self-attention mechanisms to achieve sub-quadratic running time; however, the large majority of these works are not accompanied by rigorous error guarantees. In this work, we establish lower bounds on the computational complexity of self-attention in a number of scenarios. We prove that the time complexity of self-attention is necessarily quadratic in the input length, unless the Strong Exponential Time Hypothesis (SETH) is false. This argument holds even if the attention computation is performed only approximately, and for a variety of attention mechanisms. As a complement to our lower bounds, we show that it is indeed possible to approximate dot-product self-attention using finite Taylor series in linear-time, at the cost of having an exponential dependence on the polynomial order.
Deep Dynamic Effective Connectivity Estimation from Multivariate Time Series
Feb 16, 2022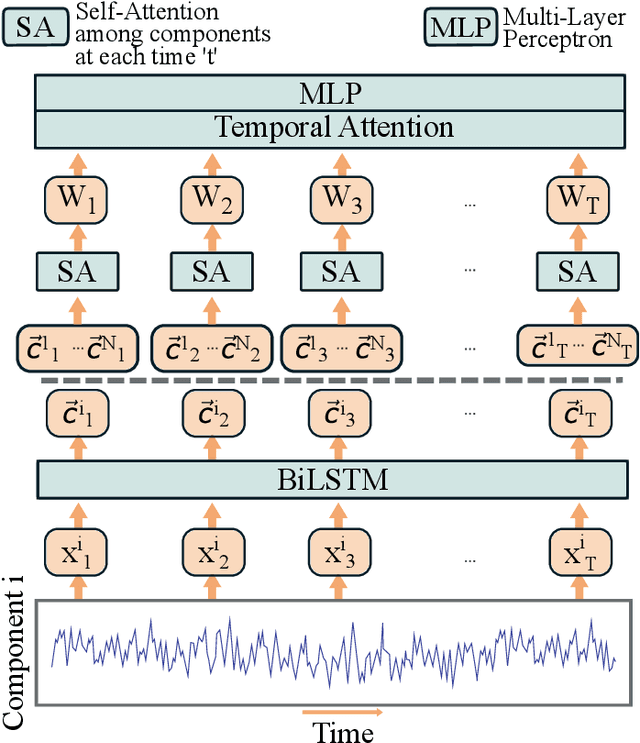
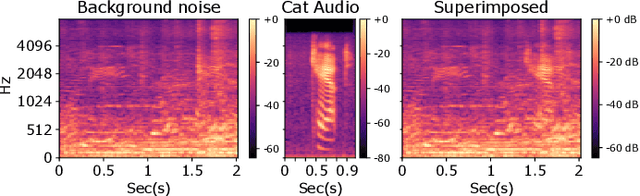
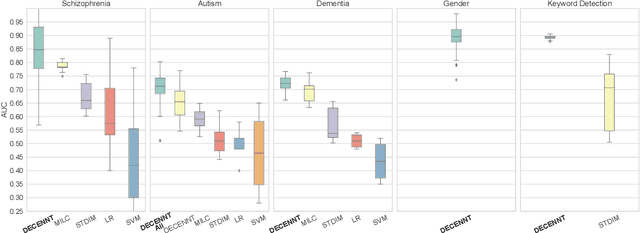
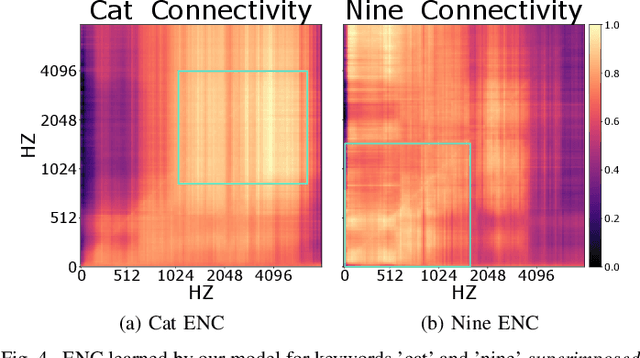
Recently, methods that represent data as a graph, such as graph neural networks (GNNs) have been successfully used to learn data representations and structures to solve classification and link prediction problems. The applications of such methods are vast and diverse, but most of the current work relies on the assumption of a static graph. This assumption does not hold for many highly dynamic systems, where the underlying connectivity structure is non-stationary and is mostly unobserved. Using a static model in these situations may result in sub-optimal performance. In contrast, modeling changes in graph structure with time can provide information about the system whose applications go beyond classification. Most work of this type does not learn effective connectivity and focuses on cross-correlation between nodes to generate undirected graphs. An undirected graph is unable to capture direction of an interaction which is vital in many fields, including neuroscience. To bridge this gap, we developed dynamic effective connectivity estimation via neural network training (DECENNT), a novel model to learn an interpretable directed and dynamic graph induced by the downstream classification/prediction task. DECENNT outperforms state-of-the-art (SOTA) methods on five different tasks and infers interpretable task-specific dynamic graphs. The dynamic graphs inferred from functional neuroimaging data align well with the existing literature and provide additional information. Additionally, the temporal attention module of DECENNT identifies time-intervals crucial for predictive downstream task from multivariate time series data.
FingerFlex: Inferring Finger Trajectories from ECoG signals
Oct 23, 2022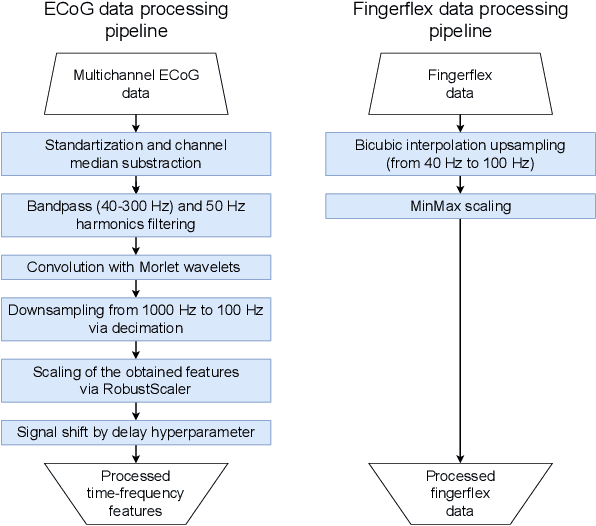

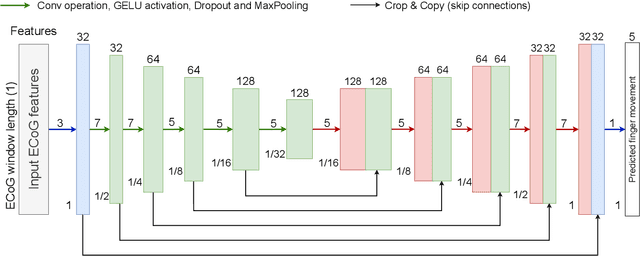
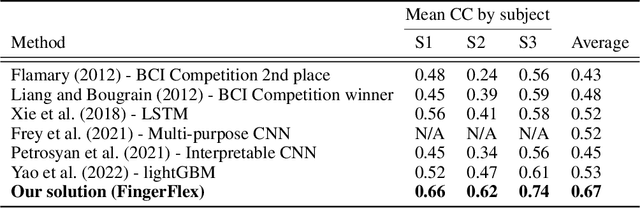
Motor brain-computer interface (BCI) development relies critically on neural time series decoding algorithms. Recent advances in deep learning architectures allow for automatic feature selection to approximate higher-order dependencies in data. This article presents the FingerFlex model - a convolutional encoder-decoder architecture adapted for finger movement regression on electrocorticographic (ECoG) brain data. State-of-the-art performance was achieved on a publicly available BCI competition IV dataset 4 with a correlation coefficient between true and predicted trajectories up to 0.74. The presented method provides the opportunity for developing fully-functional high-precision cortical motor brain-computer interfaces.
Clarinet: A Music Retrieval System
Oct 23, 2022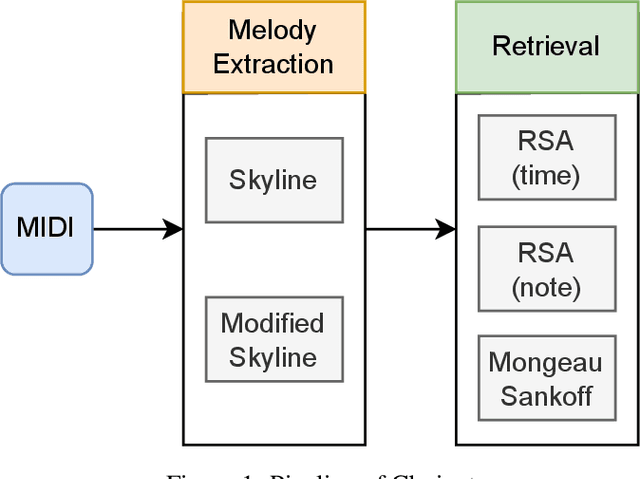
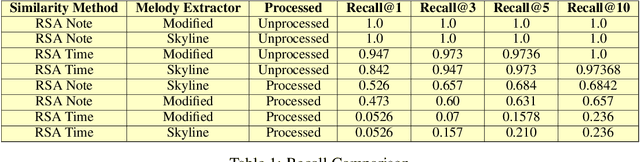

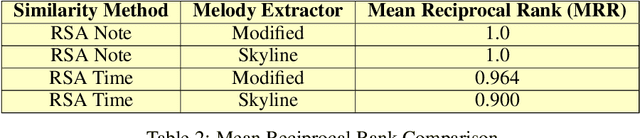
A MIDI based approach for music recognition is proposed and implemented in this paper. Our Clarinet music retrieval system is designed to search piano MIDI files with high recall and speed. We design a novel melody extraction algorithm that improves recall results by more than 10%. We also implement 3 algorithms for retrieval-two self designed (RSA Note and RSA Time), and a modified version of the Mongeau Sankoff Algorithm. Algorithms to achieve tempo and scale invariance are also discussed in this paper. The paper also contains detailed experimentation and benchmarks with four different metrics. Clarinet achieves recall scores of more than 94%.
Real-time Virtual-Try-On from a Single Example Image through Deep Inverse Graphics and Learned Differentiable Renderers
May 12, 2022

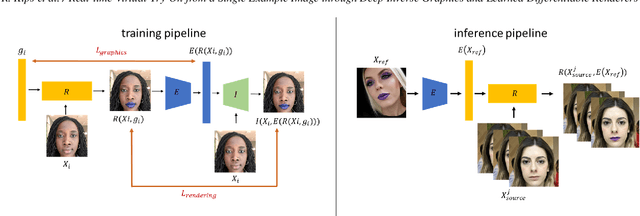

Augmented reality applications have rapidly spread across online platforms, allowing consumers to virtually try-on a variety of products, such as makeup, hair dying, or shoes. However, parametrizing a renderer to synthesize realistic images of a given product remains a challenging task that requires expert knowledge. While recent work has introduced neural rendering methods for virtual try-on from example images, current approaches are based on large generative models that cannot be used in real-time on mobile devices. This calls for a hybrid method that combines the advantages of computer graphics and neural rendering approaches. In this paper we propose a novel framework based on deep learning to build a real-time inverse graphics encoder that learns to map a single example image into the parameter space of a given augmented reality rendering engine. Our method leverages self-supervised learning and does not require labeled training data which makes it extendable to many virtual try-on applications. Furthermore, most augmented reality renderers are not differentiable in practice due to algorithmic choices or implementation constraints to reach real-time on portable devices. To relax the need for a graphics-based differentiable renderer in inverse graphics problems, we introduce a trainable imitator module. Our imitator is a generative network that learns to accurately reproduce the behavior of a given non-differentiable renderer. We propose a novel rendering sensitivity loss to train the imitator, which ensures that the network learns an accurate and continuous representation for each rendering parameter. Our framework enables novel applications where consumers can virtually try-on a novel unknown product from an inspirational reference image on social media. It can also be used by graphics artists to automatically create realistic rendering from a reference product image.
Optimal Admission Control for Multiclass Queues with Time-Varying Arrival Rates via State Abstraction
Mar 14, 2022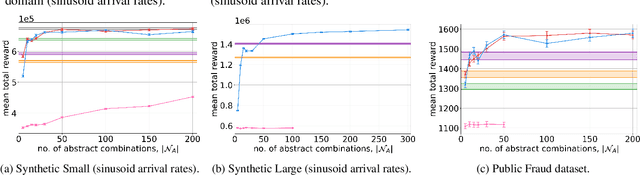
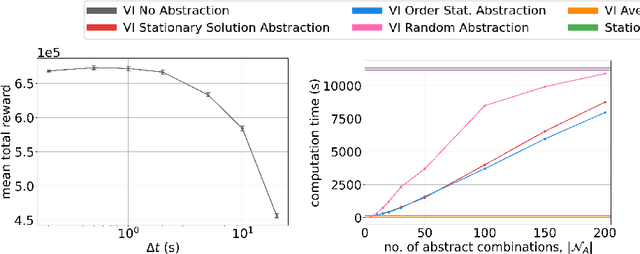
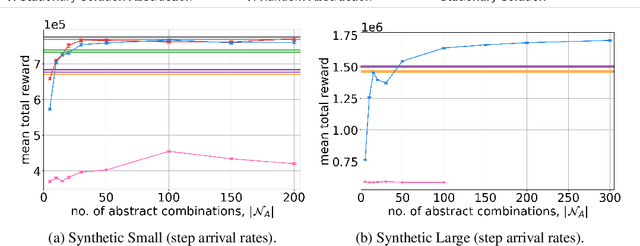
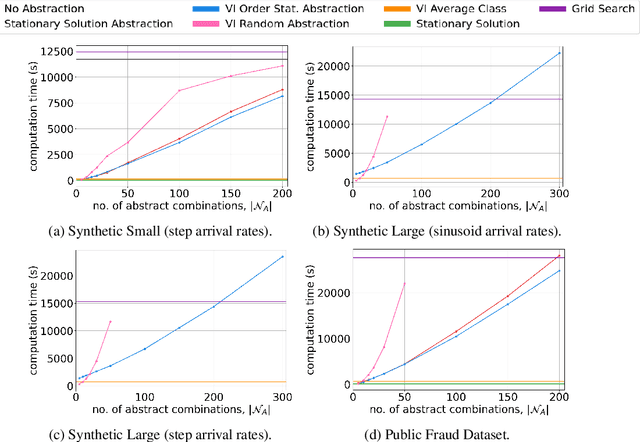
We consider a novel queuing problem where the decision-maker must choose to accept or reject randomly arriving tasks into a no buffer queue which are processed by $N$ identical servers. Each task has a price, which is a positive real number, and a class. Each class of task has a different price distribution and service rate, and arrives according to an inhomogenous Poisson process. The objective is to decide which tasks to accept so that the total price of tasks processed is maximised over a finite horizon. We formulate the problem as a discrete time Markov Decision Process (MDP) with a hybrid state space. We show that the optimal value function has a specific structure, which enables us to solve the hybrid MDP exactly. Moreover, we prove that as the time step is reduced, the discrete time solution approaches the optimal solution to the original continuous time problem. To improve the scalability of our approach to a greater number of task classes, we present an approximation based on state abstraction. We validate our approach on synthetic data, as well as a real financial fraud data set, which is the motivating application for this work.
Time Masking for Temporal Language Models
Oct 22, 2021

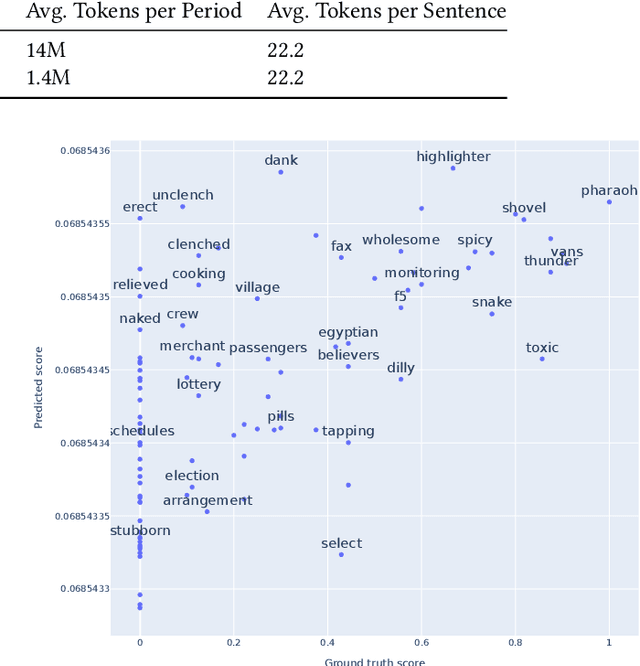
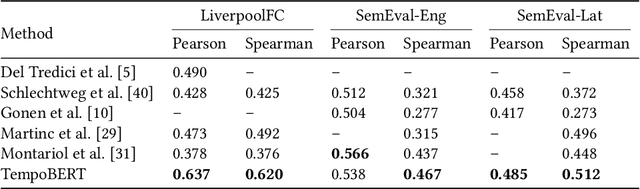
Our world is constantly evolving, and so is the content on the web. Consequently, our languages, often said to mirror the world, are dynamic in nature. However, most current contextual language models are static and cannot adapt to changes over time. In this work, we propose a temporal contextual language model called TempoBERT, which uses time as an additional context of texts. Our technique is based on modifying texts with temporal information and performing time masking - specific masking for the supplementary time information. We leverage our approach for the tasks of semantic change detection and sentence time prediction, experimenting on diverse datasets in terms of time, size, genre, and language. Our extensive evaluation shows that both tasks benefit from exploiting time masking.
Probabilistic reconciliation of forecasts via importance sampling
Oct 05, 2022
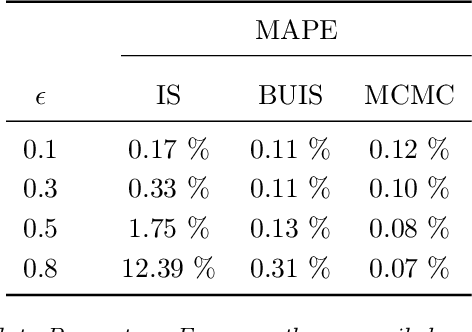
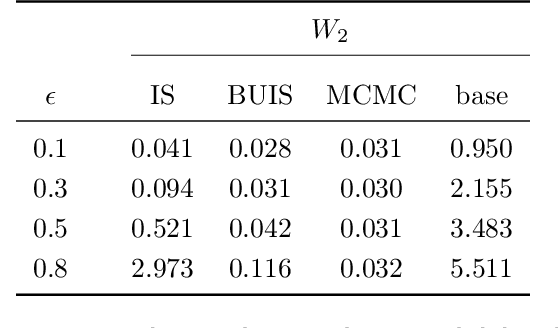
Hierarchical time series are common in several applied fields. Forecasts are required to be coherent, that is, to satisfy the constraints given by the hierarchy. The most popular technique to enforce coherence is called reconciliation, which adjusts the base forecasts computed for each time series. However, recent works on probabilistic reconciliation present several limitations. In this paper, we propose a new approach based on conditioning to reconcile any type of forecast distribution. We then introduce a new algorithm, called Bottom-Up Importance Sampling, to efficiently sample from the reconciled distribution. It can be used for any base forecast distribution: discrete, continuous, or even in the form of samples. The method was tested on several temporal hierarchies showing that our reconciliation effectively improves the quality of probabilistic forecasts. Moreover, our algorithm is up to 3 orders of magnitude faster than vanilla MCMC methods.
Counterfactual Data Augmentation via Perspective Transition for Open-Domain Dialogues
Oct 30, 2022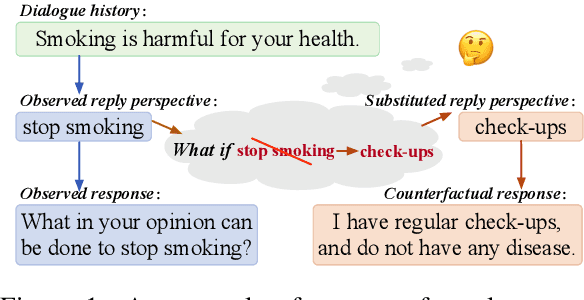
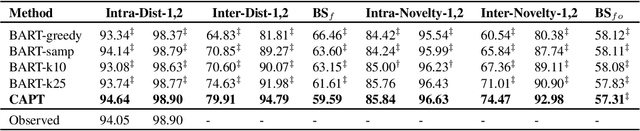
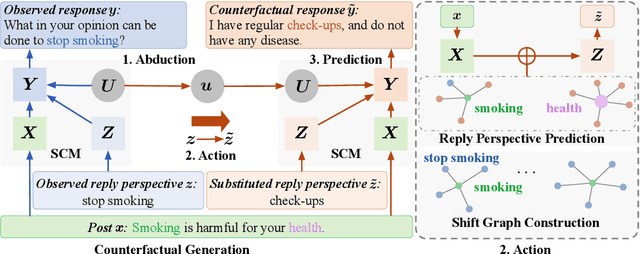
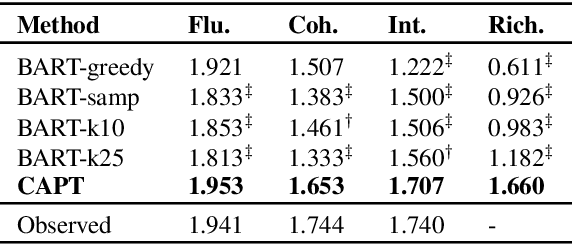
The construction of open-domain dialogue systems requires high-quality dialogue datasets. The dialogue data admits a wide variety of responses for a given dialogue history, especially responses with different semantics. However, collecting high-quality such a dataset in most scenarios is labor-intensive and time-consuming. In this paper, we propose a data augmentation method to automatically augment high-quality responses with different semantics by counterfactual inference. Specifically, given an observed dialogue, our counterfactual generation model first infers semantically different responses by replacing the observed reply perspective with substituted ones. Furthermore, our data selection method filters out detrimental augmented responses. Experimental results show that our data augmentation method can augment high-quality responses with different semantics for a given dialogue history, and can outperform competitive baselines on multiple downstream tasks.
One Gradient Frank-Wolfe for Decentralized Online Convex and Submodular Optimization
Oct 30, 2022
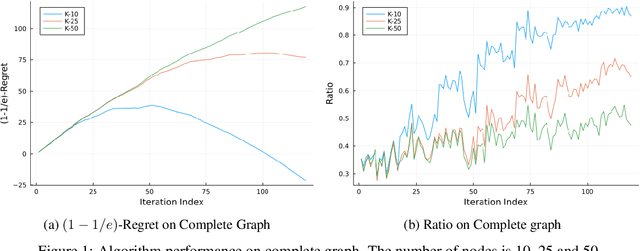
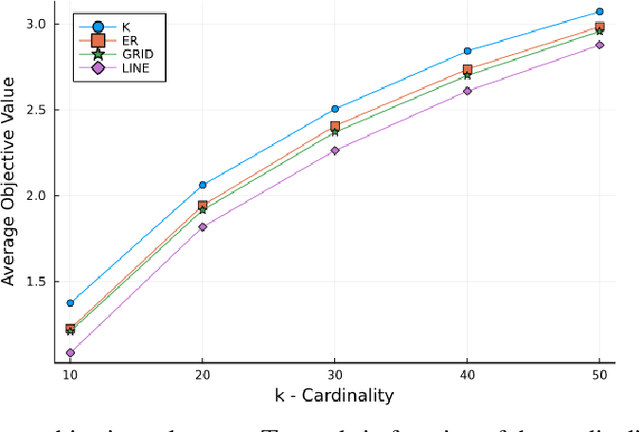
Decentralized learning has been studied intensively in recent years motivated by its wide applications in the context of federated learning. The majority of previous research focuses on the offline setting in which the objective function is static. However, the offline setting becomes unrealistic in numerous machine learning applications that witness the change of massive data. In this paper, we propose \emph{decentralized online} algorithm for convex and continuous DR-submodular optimization, two classes of functions that are present in a variety of machine learning problems. Our algorithms achieve performance guarantees comparable to those in the centralized offline setting. Moreover, on average, each participant performs only a \emph{single} gradient computation per time step. Subsequently, we extend our algorithms to the bandit setting. Finally, we illustrate the competitive performance of our algorithms in real-world experiments.