 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
One-Shot Messaging at Any Load Through Random Sub-Channeling in OFDM
Sep 22, 2022
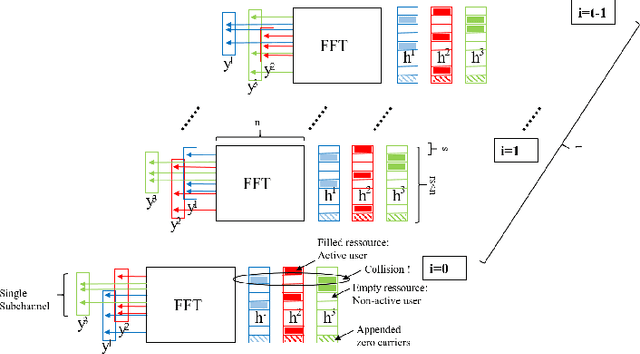
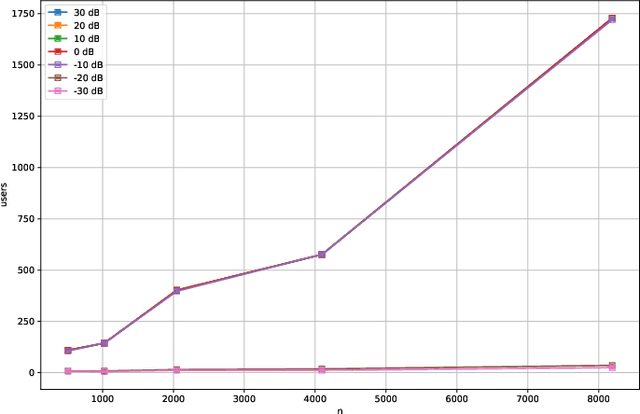
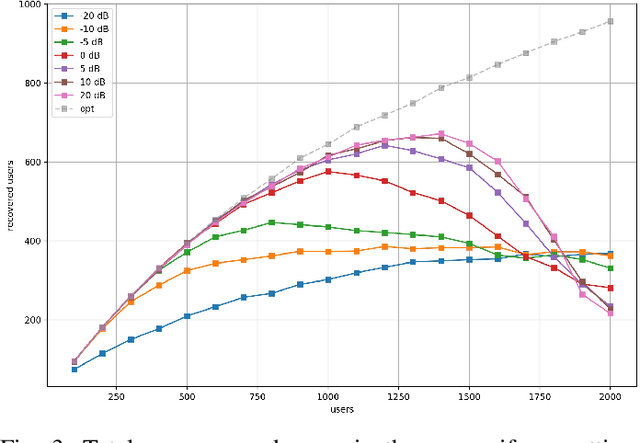
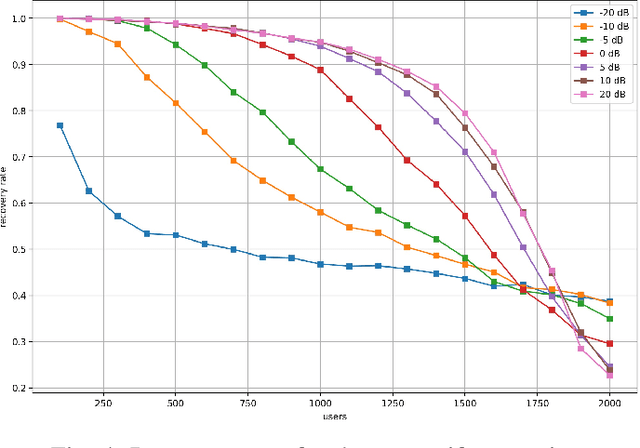
Compressive Sensing has well boosted massive random access protocols over the last decade. In this paper we apply an orthogonal FFT basis as it is used in OFDM, but subdivide its image into so-called sub-channels and let each sub-channel take only a fraction of the load. In a random fashion the subdivision is consecutively applied over a suitable number of time-slots. Within the time-slots the users will not change their sub-channel assignment and send in parallel the data. Activity detection is carried out jointly across time-slots in each of the sub-channels. For such system design we derive three rather fundamental results: i) First, we prove that the subdivision can be driven to the extent that the activity in each sub-channel is sparse by design. An effect that we call sparsity capture effect. ii) Second, we prove that effectively the system can sustain any overload situation relative to the FFT dimension, i.e. detection failure of active and non-active users can be kept below any desired threshold regardless of the number of users. The only price to pay is delay, i.e. the number of time-slots over which cross-detection is performed. We achieve this by jointly exploring the effect of measure concentration in time and frequency and careful system parameter scaling. iii) Third, we prove that parallel to activity detection active users can carry one symbol per pilot resource and time-slot so it supports so-called one-shot messaging. The key to proving these results are new concentration results for sequences of randomly sub-sampled FFTs detecting the sparse vectors "en bloc". Eventually, we show by simulations that the system is scalable resulting in a coarsely 30-fold capacity increase compared to standard OFDM.
Robustness Analysis of Deep Learning Models for Population Synthesis
Nov 23, 2022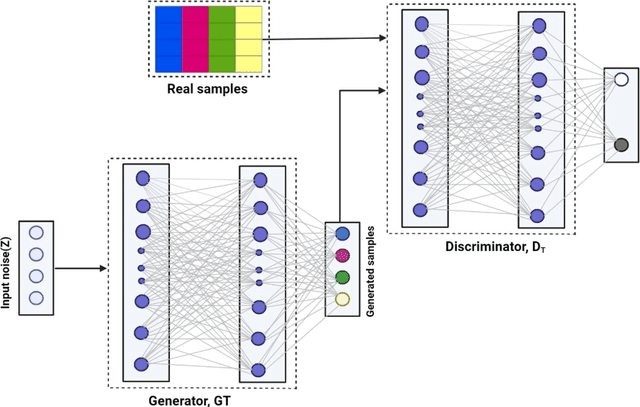

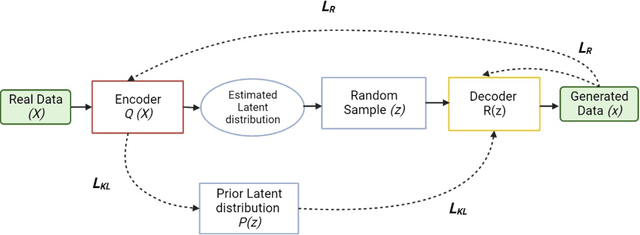
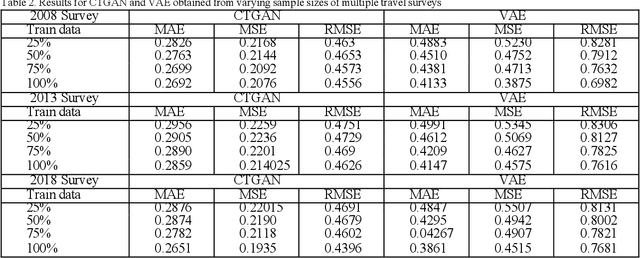
Deep generative models have become useful for synthetic data generation, particularly population synthesis. The models implicitly learn the probability distribution of a dataset and can draw samples from a distribution. Several models have been proposed, but their performance is only tested on a single cross-sectional sample. The implementation of population synthesis on single datasets is seen as a drawback that needs further studies to explore the robustness of the models on multiple datasets. While comparing with the real data can increase trust and interpretability of the models, techniques to evaluate deep generative models' robustness for population synthesis remain underexplored. In this study, we present bootstrap confidence interval for the deep generative models, an approach that computes efficient confidence intervals for mean errors predictions to evaluate the robustness of the models to multiple datasets. Specifically, we adopt the tabular-based Composite Travel Generative Adversarial Network (CTGAN) and Variational Autoencoder (VAE), to estimate the distribution of the population, by generating agents that have tabular data using several samples over time from the same study area. The models are implemented on multiple travel diaries of Montreal Origin- Destination Survey of 2008, 2013, and 2018 and compare the predictive performance under varying sample sizes from multiple surveys. Results show that the predictive errors of CTGAN have narrower confidence intervals indicating its robustness to multiple datasets of the varying sample sizes when compared to VAE. Again, the evaluation of model robustness against varying sample size shows a minimal decrease in model performance with decrease in sample size. This study directly supports agent-based modelling by enabling finer synthetic generation of populations in a reliable environment.
Can Ensemble of Classifiers Provide Better Recognition Results in Packaging Activity?
Nov 05, 2022Skeleton-based Motion Capture (MoCap) systems have been widely used in the game and film industry for mimicking complex human actions for a long time. MoCap data has also proved its effectiveness in human activity recognition tasks. However, it is a quite challenging task for smaller datasets. The lack of such data for industrial activities further adds to the difficulties. In this work, we have proposed an ensemble-based machine learning methodology that is targeted to work better on MoCap datasets. The experiments have been performed on the MoCap data given in the Bento Packaging Activity Recognition Challenge 2021. Bento is a Japanese word that resembles lunch-box. Upon processing the raw MoCap data at first, we have achieved an astonishing accuracy of 98% on 10-fold Cross-Validation and 82% on Leave-One-Out-Cross-Validation by using the proposed ensemble model.
Modeling Multi-Dimensional Datasets via a Fast Scale-Free Network Model
Nov 05, 2022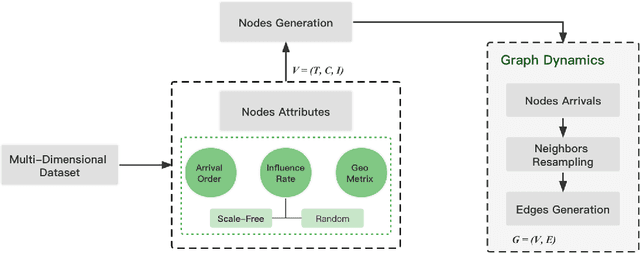

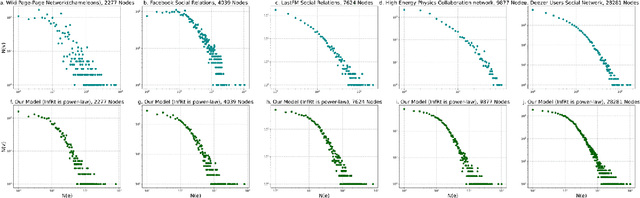
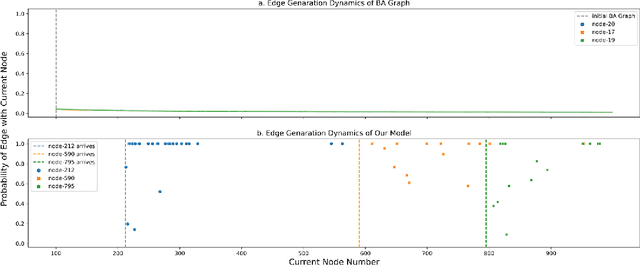
Compared with network datasets, multi-dimensional data are much more common nowadays. If we can model multi-dimensional datasets into networks with accurate network properties, while, in the meantime, preserving the original dataset features, we can not only explore the dataset dynamic but also acquire abundant synthetic network data. This paper proposed a fast scale-free network model for large-scale multi-dimensional data not limited to the network domain. The proposed network model is dynamic and able to generate scale-free graphs within linear time regardless of the scale or field of the modeled dataset. We further argued that in a dynamic network where edge-generation probability represents influence, as the network evolves, that influence also decays. We demonstrated how this influence decay phenomenon is reflected in our model and provided a case study using the Global Terrorism Database.
Boundary Corrected Multi-scale Fusion Network for Real-time Semantic Segmentation
Mar 01, 2022

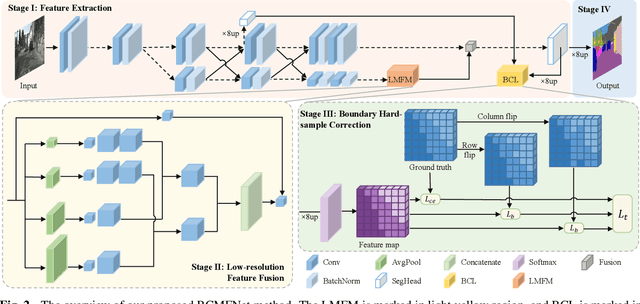
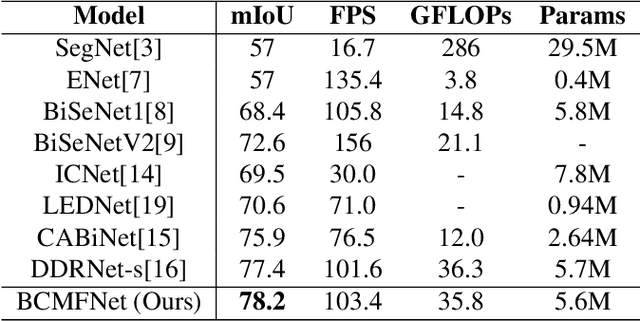
Image semantic segmentation aims at the pixel-level classification of images, which has requirements for both accuracy and speed in practical application. Existing semantic segmentation methods mainly rely on the high-resolution input to achieve high accuracy and do not meet the requirements of inference time. Although some methods focus on high-speed scene parsing with lightweight architectures, they can not fully mine semantic features under low computation with relatively low performance. To realize the real-time and high-precision segmentation, we propose a new method named Boundary Corrected Multi-scale Fusion Network, which uses the designed Low-resolution Multi-scale Fusion Module to extract semantic information. Moreover, to deal with boundary errors caused by low-resolution feature map fusion, we further design an additional Boundary Corrected Loss to constrain overly smooth features. Extensive experiments show that our method achieves a state-of-the-art balance of accuracy and speed for the real-time semantic segmentation.
Synthetic Data Supervised Salient Object Detection
Oct 25, 2022
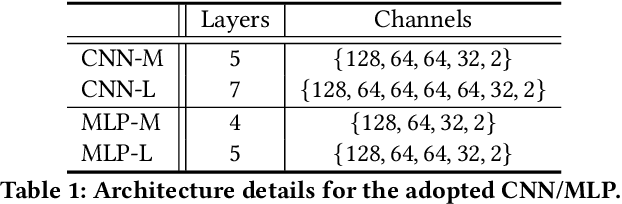
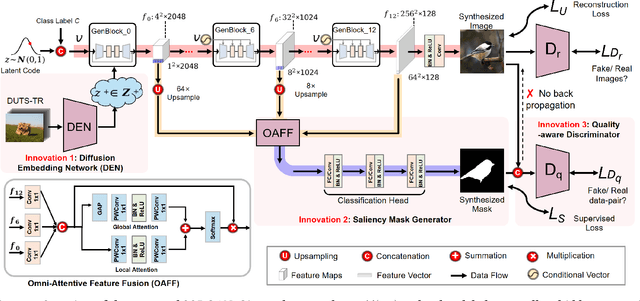
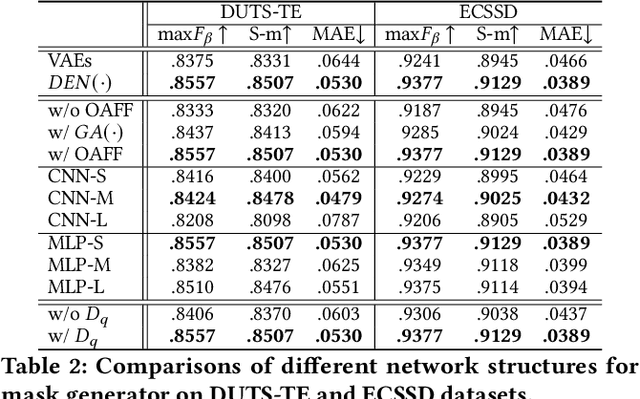
Although deep salient object detection (SOD) has achieved remarkable progress, deep SOD models are extremely data-hungry, requiring large-scale pixel-wise annotations to deliver such promising results. In this paper, we propose a novel yet effective method for SOD, coined SODGAN, which can generate infinite high-quality image-mask pairs requiring only a few labeled data, and these synthesized pairs can replace the human-labeled DUTS-TR to train any off-the-shelf SOD model. Its contribution is three-fold. 1) Our proposed diffusion embedding network can address the manifold mismatch and is tractable for the latent code generation, better matching with the ImageNet latent space. 2) For the first time, our proposed few-shot saliency mask generator can synthesize infinite accurate image synchronized saliency masks with a few labeled data. 3) Our proposed quality-aware discriminator can select highquality synthesized image-mask pairs from noisy synthetic data pool, improving the quality of synthetic data. For the first time, our SODGAN tackles SOD with synthetic data directly generated from the generative model, which opens up a new research paradigm for SOD. Extensive experimental results show that the saliency model trained on synthetic data can achieve $98.4\%$ F-measure of the saliency model trained on the DUTS-TR. Moreover, our approach achieves a new SOTA performance in semi/weakly-supervised methods, and even outperforms several fully-supervised SOTA methods. Code is available at https://github.com/wuzhenyubuaa/SODGAN
* 9 pages, 8 figures
Conversational Pattern Mining using Motif Detection
Nov 13, 2022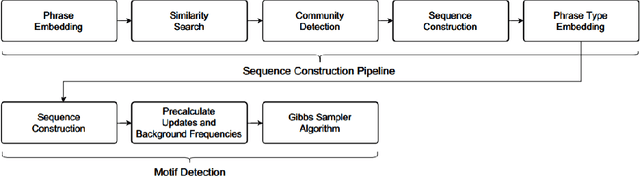
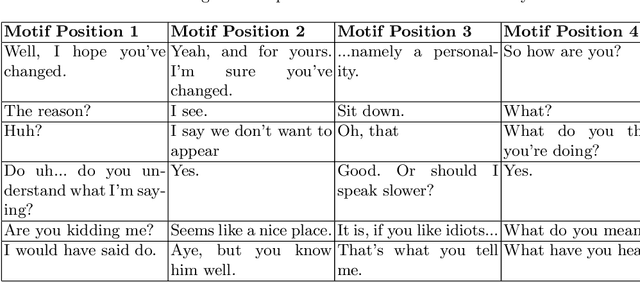
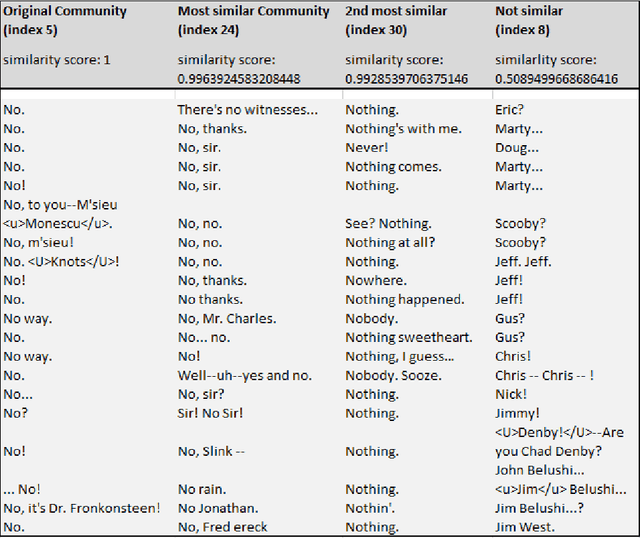
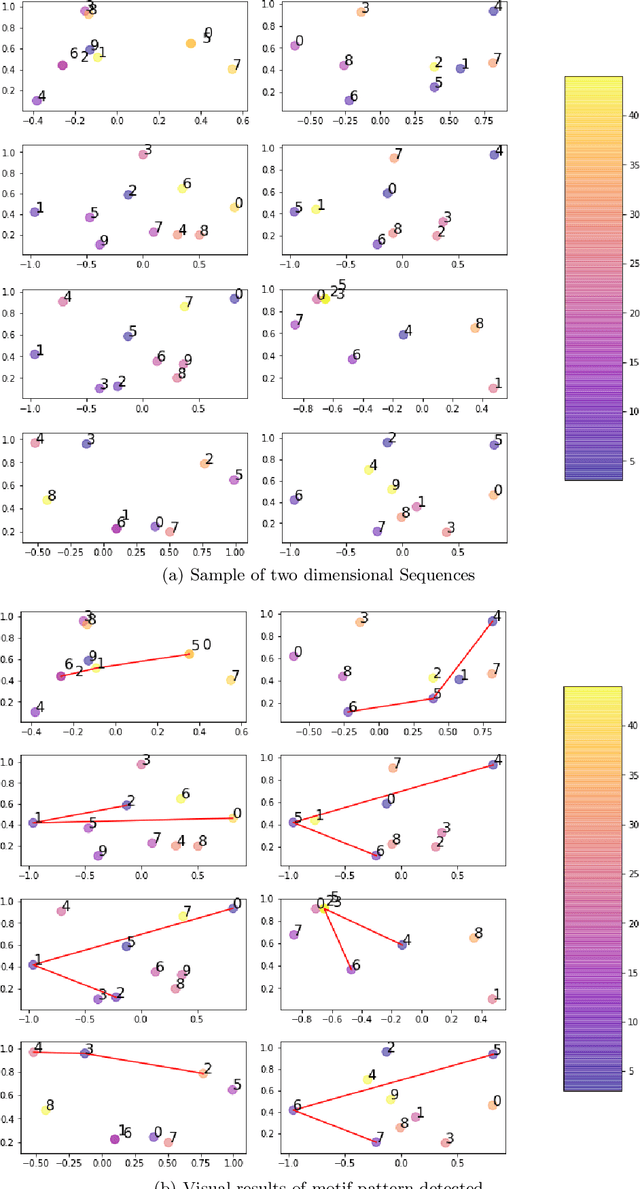
The subject of conversational mining has become of great interest recently due to the explosion of social and other online media. Supplementing this explosion of text is the advancement in pre-trained language models which have helped us to leverage these sources of information. An interesting domain to analyse is conversations in terms of complexity and value. Complexity arises due to the fact that a conversation can be asynchronous and can involve multiple parties. It is also computationally intensive to process. We use unsupervised methods in our work in order to develop a conversational pattern mining technique which does not require time consuming, knowledge demanding and resource intensive labelling exercises. The task of identifying repeating patterns in sequences is well researched in the Bioinformatics field. In our work, we adapt this to the field of Natural Language Processing and make several extensions to a motif detection algorithm. In order to demonstrate the application of the algorithm on a dynamic, real world data set; we extract motifs from an open-source film script data source. We run an exploratory investigation into the types of motifs we are able to mine.
Layerwise Sparsifying Training and Sequential Learning Strategy for Neural Architecture Adaptation
Nov 13, 2022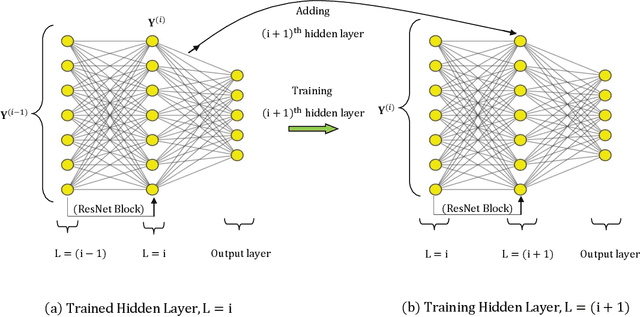
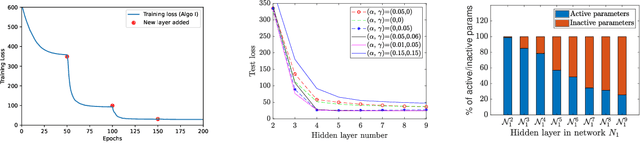


This work presents a two-stage framework for progressively developing neural architectures to adapt/ generalize well on a given training data set. In the first stage, a manifold-regularized layerwise sparsifying training approach is adopted where a new layer is added each time and trained independently by freezing parameters in the previous layers. In order to constrain the functions that should be learned by each layer, we employ a sparsity regularization term, manifold regularization term and a physics-informed term. We derive the necessary conditions for trainability of a newly added layer and analyze the role of manifold regularization. In the second stage of the Algorithm, a sequential learning process is adopted where a sequence of small networks is employed to extract information from the residual produced in stage I and thereby making robust and more accurate predictions. Numerical investigations with fully connected network on prototype regression problem, and classification problem demonstrate that the proposed approach can outperform adhoc baseline networks. Further, application to physics-informed neural network problems suggests that the method could be employed for creating interpretable hidden layers in a deep network while outperforming equivalent baseline networks.
Stochastic strategies for patrolling a terrain with a synchronized multi-robot system
Sep 14, 2022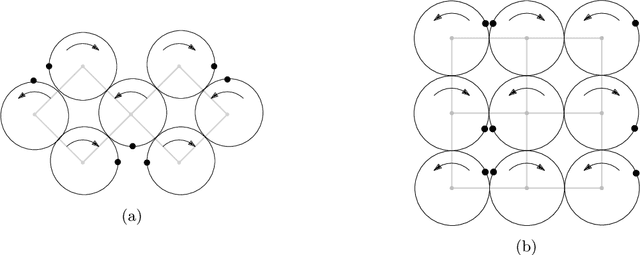
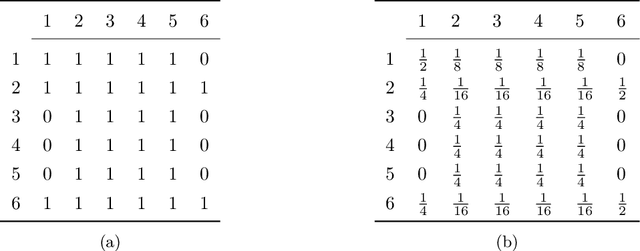
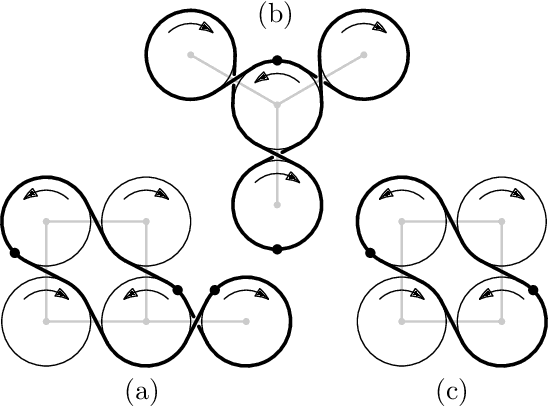
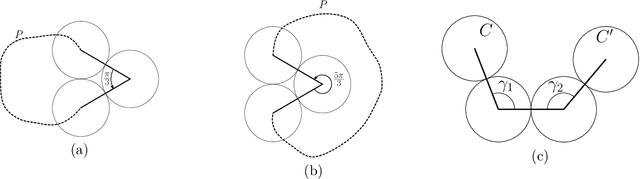
A group of cooperative aerial robots can be deployed to efficiently patrol a terrain, in which each robot flies around an assigned area and shares information with the neighbors periodically in order to protect or supervise it. To ensure robustness, previous works on these synchronized systems propose sending a robot to the neighboring area in case it detects a failure. In order to deal with unpredictability and to improve on the efficiency in the deterministic patrolling scheme, this paper proposes random strategies to cover the areas distributed among the agents. First, a theoretical study of the stochastic process is addressed in this paper for two metrics: the \emph{idle time}, the expected time between two consecutive observations of any point of the terrain and the \emph{isolation time}, the expected time that a robot is without communication with any other robot. After that, the random strategies are experimentally compared with the deterministic strategy adding another metric: the \emph{broadcast time}, the expected time elapsed from the moment a robot emits a message until it is received by all the other robots of the team. The simulations show that theoretical results are in good agreement with the simulations and the random strategies outperform the behavior obtained with the deterministic protocol proposed in the literature.
Mixed Reality Interface for Digital Twin of Plant Factory
Oct 29, 2022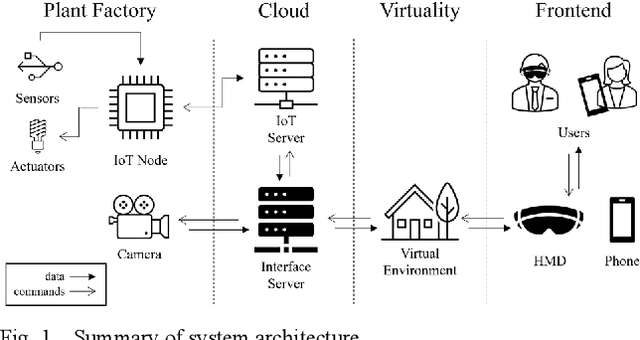



An easier and intuitive interface architecture is necessary for digital twin of plant factory. I suggest an immersive and interactive mixed reality interface for digital twin models of smart farming, for remote work rather than simulation of components. The environment is constructed with UI display and a streaming background scene, which is a real time scene taken from camera device located in the plant factory, processed with deformable neural radiance fields. User can monitor and control the remote plant factory facilities with HMD or 2D display based mixed reality environment. This paper also introduces detailed concept and describes the system architecture to implement suggested mixed reality interface.