 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time Series Generation with Masked Autoencoder
Jan 14, 2022
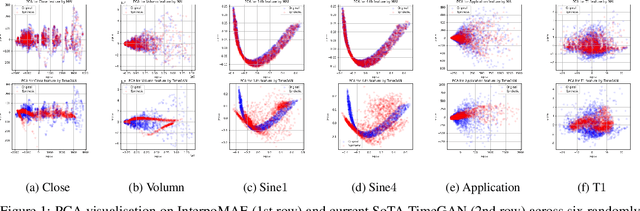
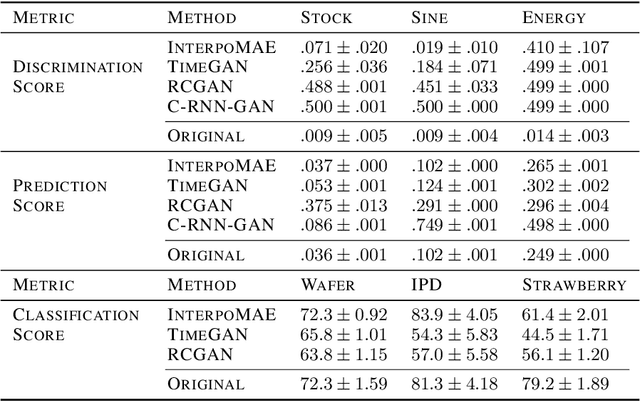
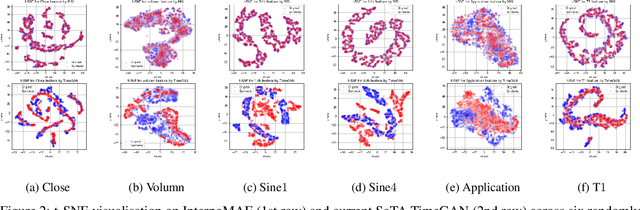
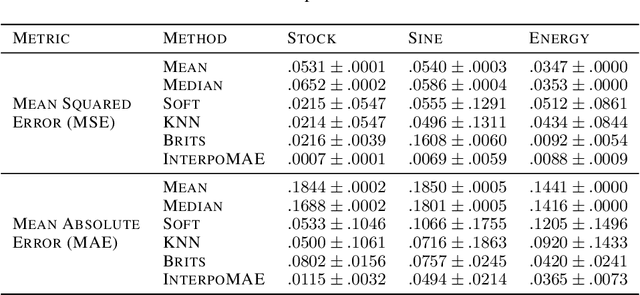
This paper shows that masked autoencoders with interpolators (InterpoMAE) are scalable self-supervised generators for time series. InterpoMAE masks random patches from the input time series and restore the missing patches in the latent space by an interpolator. The core design is that InterpoMAE uses an interpolator rather than mask tokens to restore the latent representations for missing patches in the latent space. This design enables more efficient and effective capture of temporal dynamics with bidirectional information. InterpoMAE allows for explicit control on the diversity of synthetic data by changing the size and number of masked patches. Our approach consistently and significantly outperforms state-of-the-art (SoTA) benchmarks of unsupervised learning in time series generation on several real datasets. Synthetic data produced show promising scaling behavior in various downstream tasks such as data augmentation, imputation and denoise.
ECM-OPCC: Efficient Context Model for Octree-based Point Cloud Compression
Nov 22, 2022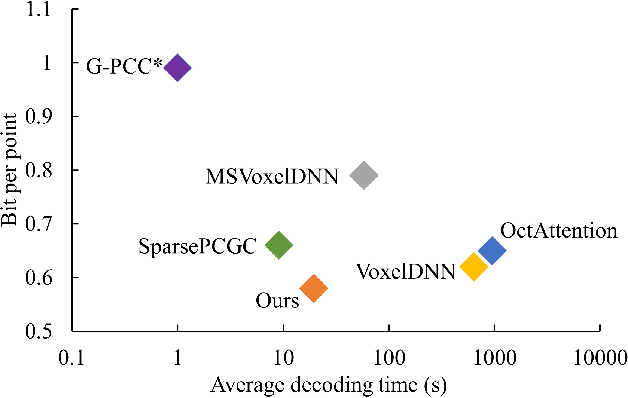
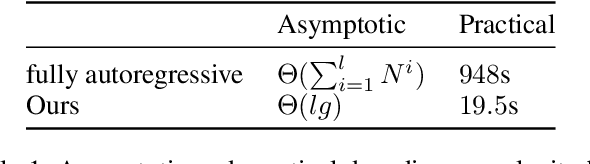
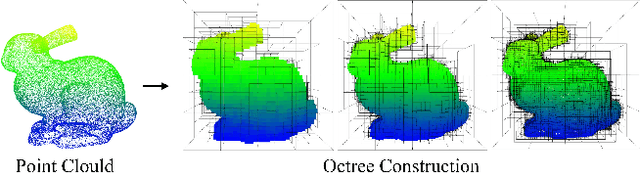
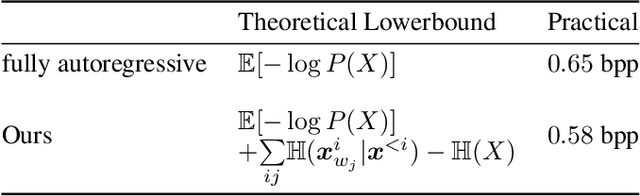
Recently, deep learning methods have shown promising results in point cloud compression. For octree-based point cloud compression, previous works show that the information of ancestor nodes and sibling nodes are equally important for predicting current node. However, those works either adopt insufficient context or bring intolerable decoding complexity (e.g. >600s). To address this problem, we propose a sufficient yet efficient context model and design an efficient deep learning codec for point clouds. Specifically, we first propose a window-constrained multi-group coding strategy to exploit the autoregressive context while maintaining decoding efficiency. Then, we propose a dual transformer architecture to utilize the dependency of current node on its ancestors and siblings. We also propose a random-masking pre-train method to enhance our model. Experimental results show that our approach achieves state-of-the-art performance for both lossy and lossless point cloud compression. Moreover, our multi-group coding strategy saves 98% decoding time compared with previous octree-based compression method.
SMAUG: Sparse Masked Autoencoder for Efficient Video-Language Pre-training
Nov 22, 2022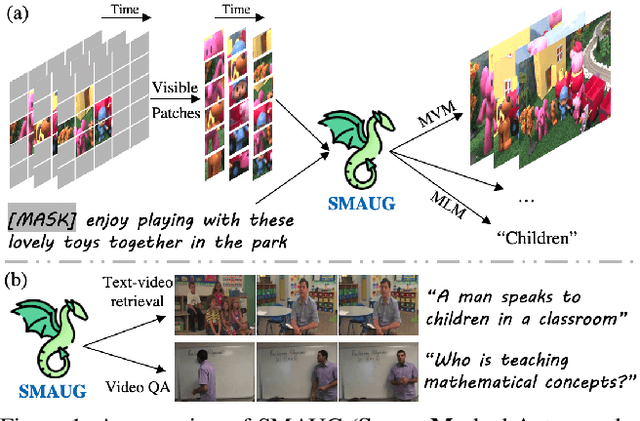
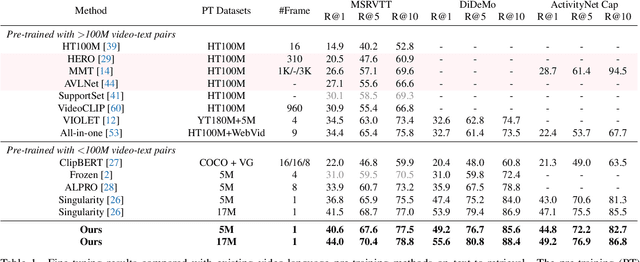
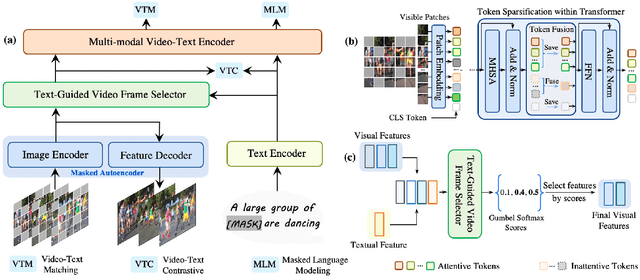
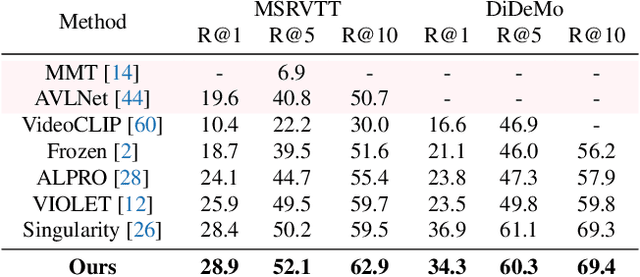
Video-language pre-training is crucial for learning powerful multi-modal representation. However, it typically requires a massive amount of computation. In this paper, we develop SMAUG, an efficient pre-training framework for video-language models. The foundation component in SMAUG is masked autoencoders. Different from prior works which only mask textual inputs, our masking strategy considers both visual and textual modalities, providing a better cross-modal alignment and saving more pre-training costs. On top of that, we introduce a space-time token sparsification module, which leverages context information to further select only "important" spatial regions and temporal frames for pre-training. Coupling all these designs allows our method to enjoy both competitive performances on text-to-video retrieval and video question answering tasks, and much less pre-training costs by 1.9X or more. For example, our SMAUG only needs about 50 NVIDIA A6000 GPU hours for pre-training to attain competitive performances on these two video-language tasks across six popular benchmarks.
Learnable Spectral Wavelets on Dynamic Graphs to Capture Global Interactions
Nov 22, 2022
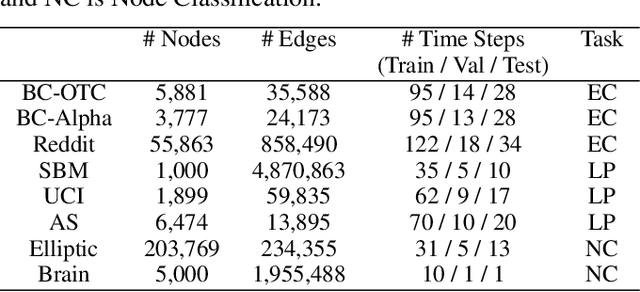
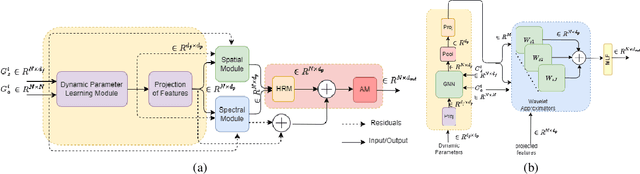
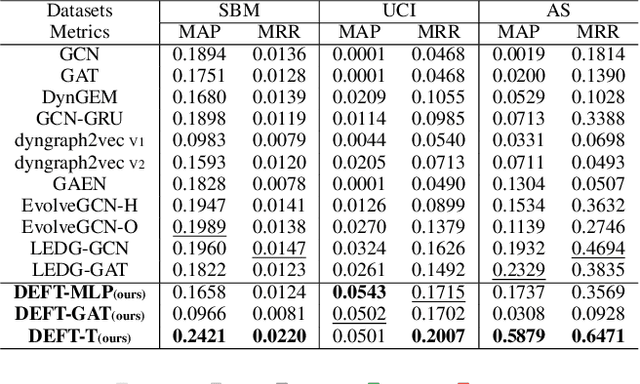
Learning on evolving(dynamic) graphs has caught the attention of researchers as static methods exhibit limited performance in this setting. The existing methods for dynamic graphs learn spatial features by local neighborhood aggregation, which essentially only captures the low pass signals and local interactions. In this work, we go beyond current approaches to incorporate global features for effectively learning representations of a dynamically evolving graph. We propose to do so by capturing the spectrum of the dynamic graph. Since static methods to learn the graph spectrum would not consider the history of the evolution of the spectrum as the graph evolves with time, we propose a novel approach to learn the graph wavelets to capture this evolving spectra. Further, we propose a framework that integrates the dynamically captured spectra in the form of these learnable wavelets into spatial features for incorporating local and global interactions. Experiments on eight standard datasets show that our method significantly outperforms related methods on various tasks for dynamic graphs.
PESE: Event Structure Extraction using Pointer Network based Encoder-Decoder Architecture
Nov 22, 2022
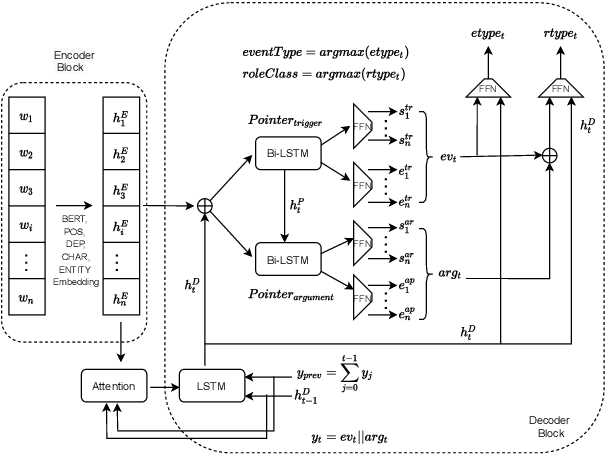
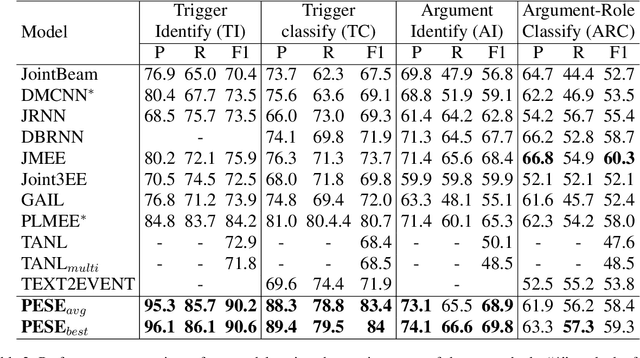
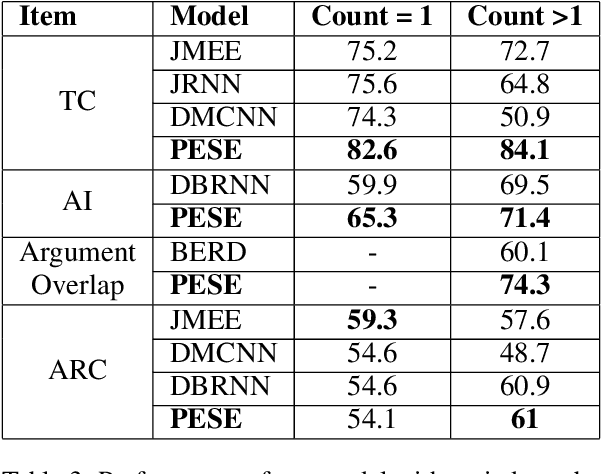
The task of event extraction (EE) aims to find the events and event-related argument information from the text and represent them in a structured format. Most previous works try to solve the problem by separately identifying multiple substructures and aggregating them to get the complete event structure. The problem with the methods is that it fails to identify all the interdependencies among the event participants (event-triggers, arguments, and roles). In this paper, we represent each event record in a unique tuple format that contains trigger phrase, trigger type, argument phrase, and corresponding role information. Our proposed pointer network-based encoder-decoder model generates an event tuple in each time step by exploiting the interactions among event participants and presenting a truly end-to-end solution to the EE task. We evaluate our model on the ACE2005 dataset, and experimental results demonstrate the effectiveness of our model by achieving competitive performance compared to the state-of-the-art methods.
Online Detection Of Supply Chain Network Disruptions Using Sequential Change-Point Detection for Hawkes Processes
Nov 22, 2022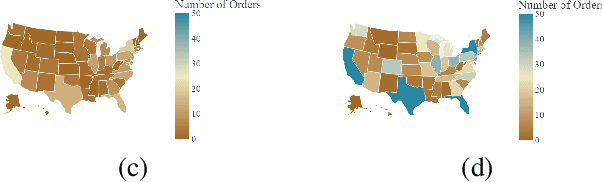
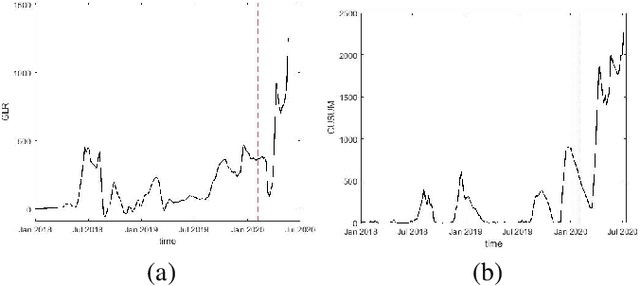
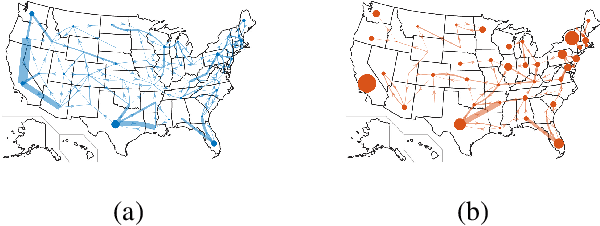

In this paper, we attempt to detect an inflection or change-point resulting from the Covid-19 pandemic on supply chain data received from a large furniture company. To accomplish this, we utilize a modified CUSUM (Cumulative Sum) procedure on the company's spatial-temporal order data as well as a GLR (Generalized Likelihood Ratio) based method. We model the order data using the Hawkes Process Network, a multi-dimensional self and mutually exciting point process, by discretizing the spatial data and treating each order as an event that has a corresponding node and time. We apply the methodologies on the company's most ordered item on a national scale and perform a deep dive into a single state. Because the item was ordered infrequently in the state compared to the nation, this approach allows us to show efficacy upon different degrees of data sparsity. Furthermore, it showcases use potential across differing levels of spatial detail.
Polynomial-Time Algorithms for Counting and Sampling Markov Equivalent DAGs with Applications
May 11, 2022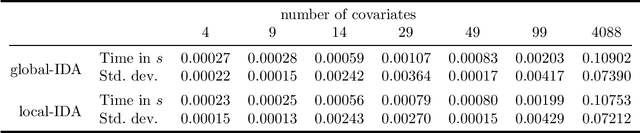
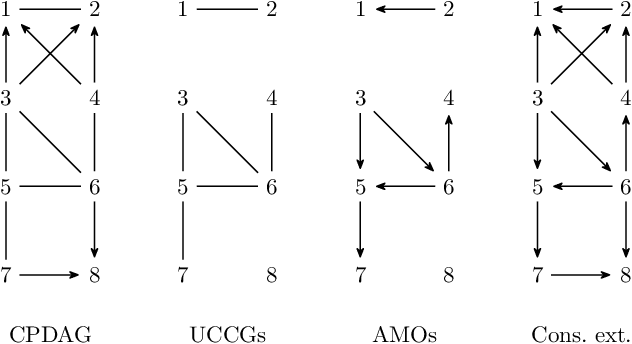
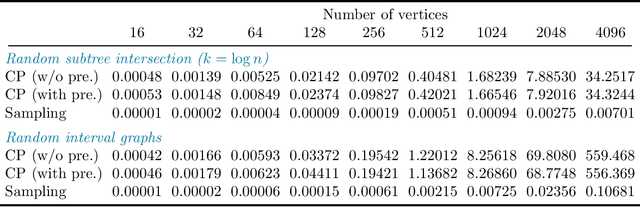
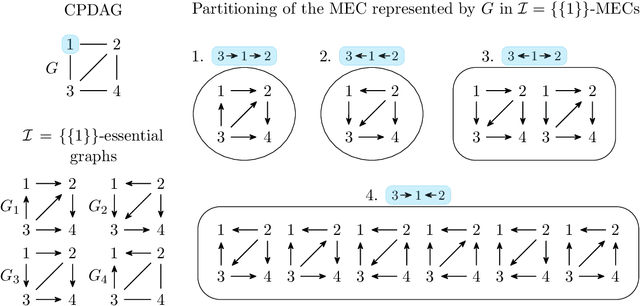
Counting and sampling directed acyclic graphs from a Markov equivalence class are fundamental tasks in graphical causal analysis. In this paper we show that these tasks can be performed in polynomial time, solving a long-standing open problem in this area. Our algorithms are effective and easily implementable. As we show in experiments, these breakthroughs make thought-to-be-infeasible strategies in active learning of causal structures and causal effect identification with regard to a Markov equivalence class practically applicable.
Arbitrarily Accurate Classification Applied to Specific Emitter Identification
Nov 16, 2022This article introduces a method of evaluating subsamples until any prescribed level of classification accuracy is attained, thus obtaining arbitrary accuracy. A logarithmic reduction in error rate is obtained with a linear increase in sample count. The technique is applied to specific emitter identification on a published dataset of physically recorded over-the-air signals from 16 ostensibly identical high-performance radios. The technique uses a multi-channel deep learning convolutional neural network acting on the bispectra of I/Q signal subsamples each consisting of 56 parts per million (ppm) of the original signal duration. High levels of accuracy are obtained with minimal computation time: in this application, each addition of eight samples decreases error by one order of magnitude.
XTENTH-CAR: A Proportionally Scaled Experimental Vehicle Platform for Connected Autonomy and All-Terrain Research
Dec 03, 2022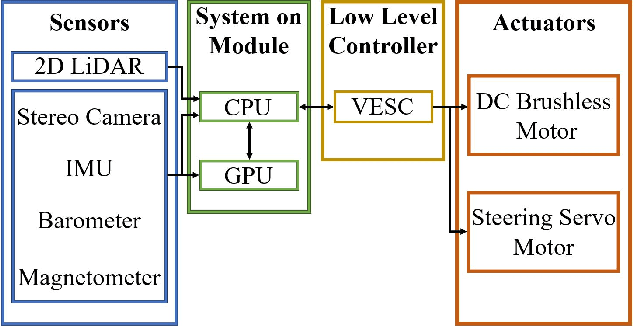


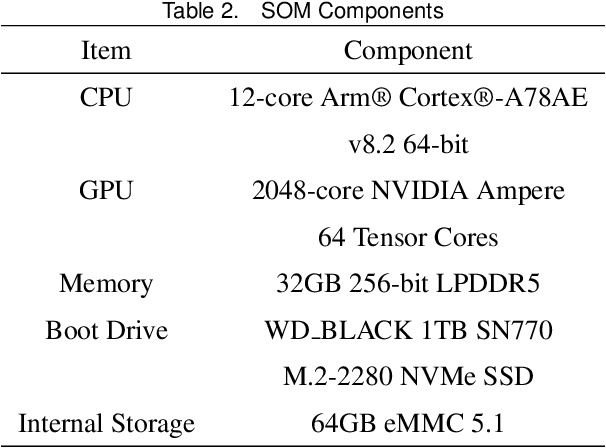
Connected Autonomous Vehicles (CAVs) are key components of the Intelligent Transportation System (ITS), and all-terrain Autonomous Ground Vehicles (AGVs) are indispensable tools for a wide range of applications such as disaster response, automated mining, agriculture, military operations, search and rescue missions, and planetary exploration. Experimental validation is a requisite for CAV and AGV research, but requires a large, safe experimental environment when using full-size vehicles which is time-consuming and expensive. To address these challenges, we developed XTENTH-CAR (eXperimental one-TENTH scaled vehicle platform for Connected autonomy and All-terrain Research), an open-source, cost-effective proportionally one-tenth scaled experimental vehicle platform governed by the same physics as a full-size on-road vehicle. XTENTH-CAR is equipped with the best-in-class NVIDIA Jetson AGX Orin System on Module (SOM), stereo camera, 2D LiDAR and open-source Electronic Speed Controller (ESC) with drivers written in the new Robot Operating System (ROS 2) to facilitate experimental CAV and AGV perception, motion planning and control research, that incorporate state-of-the-art computationally expensive algorithms such as Deep Reinforcement Learning (DRL). XTENTH-CAR is designed for compact experimental environments, and aims to increase the accessibility of experimental CAV and AGV research with low upfront costs, and complete Autonomous Vehicle (AV) hardware and software architectures similar to the full-sized X-CAR experimental vehicle platform, enabling efficient cross-platform development between small-scale and full-scale vehicles.
Improving Time Sensitivity for Question Answering over Temporal Knowledge Graphs
Mar 01, 2022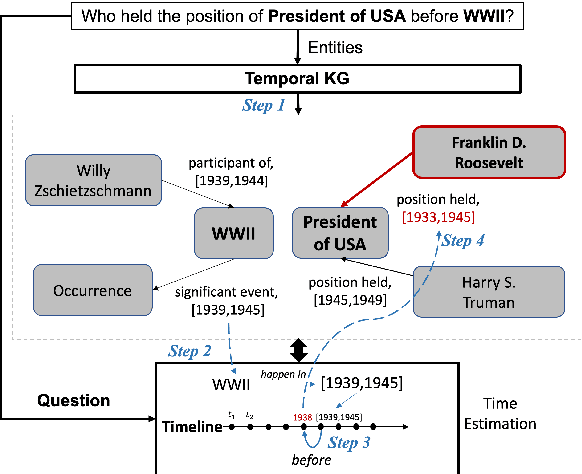
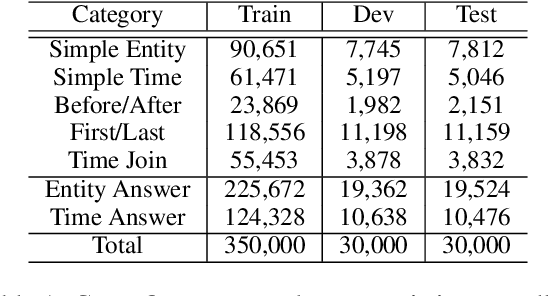
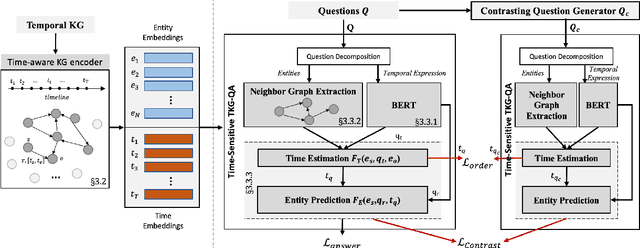
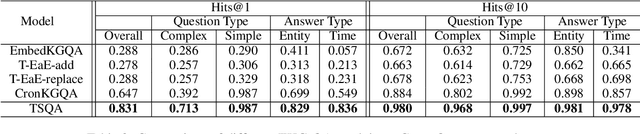
Question answering over temporal knowledge graphs (KGs) efficiently uses facts contained in a temporal KG, which records entity relations and when they occur in time, to answer natural language questions (e.g., "Who was the president of the US before Obama?"). These questions often involve three time-related challenges that previous work fail to adequately address: 1) questions often do not specify exact timestamps of interest (e.g., "Obama" instead of 2000); 2) subtle lexical differences in time relations (e.g., "before" vs "after"); 3) off-the-shelf temporal KG embeddings that previous work builds on ignore the temporal order of timestamps, which is crucial for answering temporal-order related questions. In this paper, we propose a time-sensitive question answering (TSQA) framework to tackle these problems. TSQA features a timestamp estimation module to infer the unwritten timestamp from the question. We also employ a time-sensitive KG encoder to inject ordering information into the temporal KG embeddings that TSQA is based on. With the help of techniques to reduce the search space for potential answers, TSQA significantly outperforms the previous state of the art on a new benchmark for question answering over temporal KGs, especially achieving a 32% (absolute) error reduction on complex questions that require multiple steps of reasoning over facts in the temporal KG.
* 10 pages, 2 figures