 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Joint Direction-of-Arrival and Time-of-Arrival Estimation with Ultra-wideband Elliptical Arrays
Jul 26, 2022
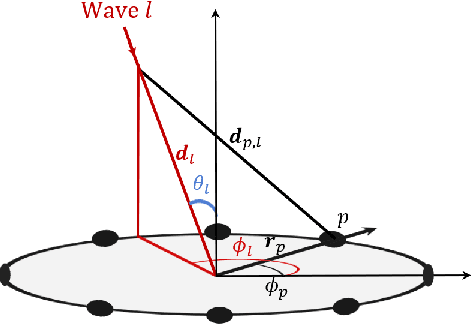
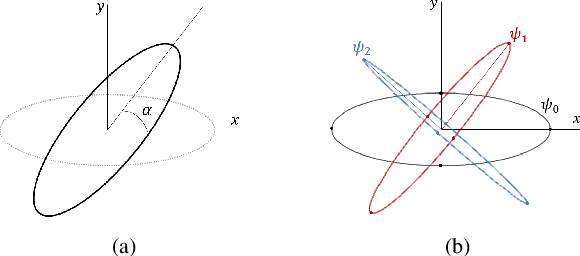
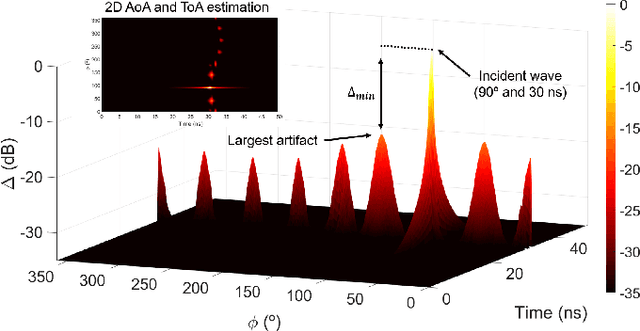
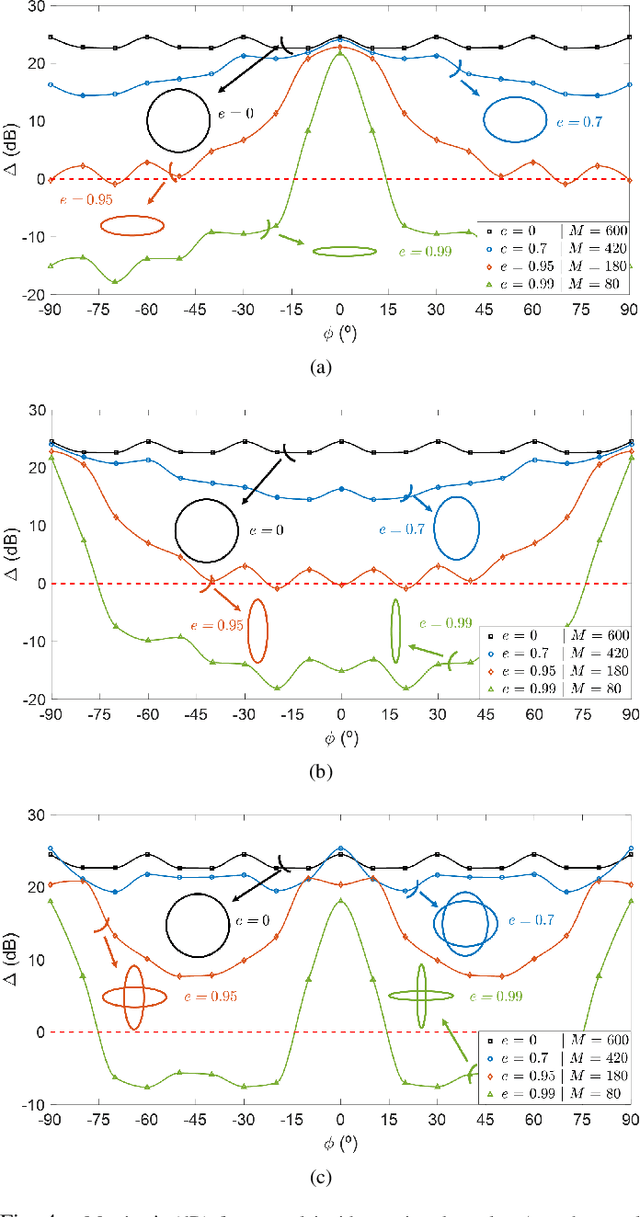
This paper presents a general technique for the joint Direction-of-Arrival (DoA) and Time-of-Arrival (ToA) estimation in multipath environments. The proposed ultra-wideband technique is based on phase-mode expansions and the use of nearly frequency-invariant elliptical arrays. New possibilities open with the present approach, as not only elliptical, but also circular and linear arrays can be considered with the same implementation. Systematic selection/rejection of signals-of-interest/signals-not-of-interest in smart wireless environments is possible, unlike with previous approaches based on circular arrays. Concentric elliptical arrays of many sizes and eccentricities can be jointly considered, with the subsequent improvement that entails in DoA and ToA detection. This leads to the realization of pseudo-random array patterns; namely, quasi-arbitrary geometries created from the superposition of multiple elliptical arrays. Some simulation and experimental tests (measurements in an anechoic chamber) are carried out for several frequency bands to check the correct performance of the method. The method is proven to give accurate estimations in all tested scenarios, and to be robust against noise, channel nonidealities, position uncertainty in sensor placement and interferences.
Transforming RIS-Assisted Passive Beamforming from Tedious to Simple: A Relaxation Algorithm for Rician Channel
Nov 22, 2022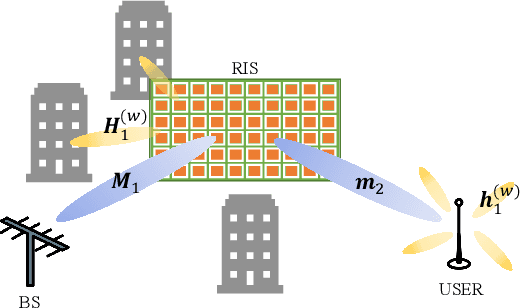
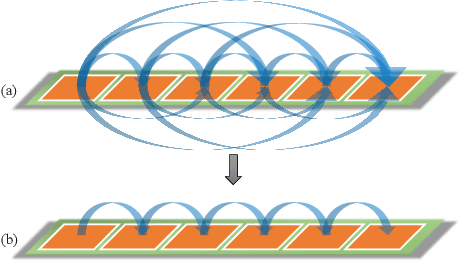
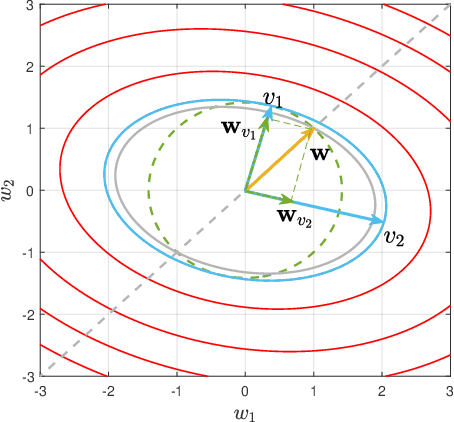
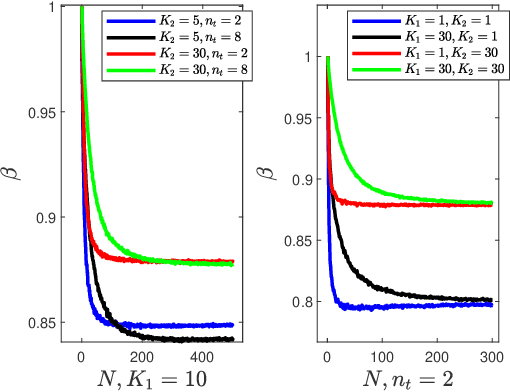
This paper investigates the problem of maximizing the signal-to-noise ratio (SNR) in reconfigurable intelligent surface (RIS)-assisted MISO communication systems. The problem will be reformulated as a complex quadratic form problem with unit circle constraints. We proved that the SNR maximizing problem has a closed-form global optimal solution when it is a rank-one problem, whereas the former researchers regarded it as an optimization problem. Moreover, We propose a relaxation algorithm (RA) that relaxes the constraints to that of Rayleigh's quotient problem and then projects the solution back, where the SNR obtained by RA achieves much the same SNR as the upper bound but with significantly low time consumption. Then we asymptotically analyze its performance when the transmitter antennas n_t and the number of units of RIS N grow large together, with N/n_t -> c. Finally, our numerical simulations show that RA achieves over 98% of the performance of the upper bound and takes below 1% time consumption of manifold optimization (MO) and 0.1% of semidefinite relaxation (SDR).
Temporal patterns in insulin needs for Type 1 diabetes
Nov 17, 2022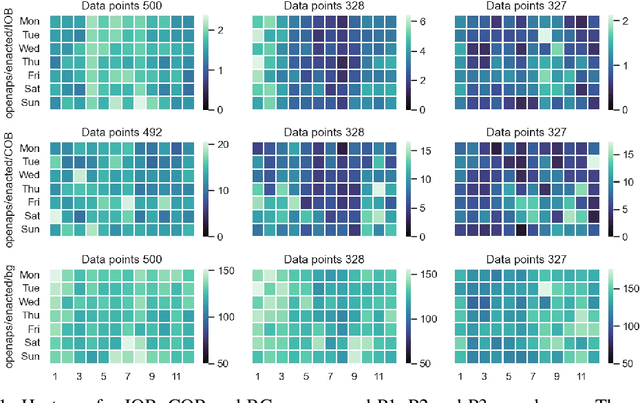
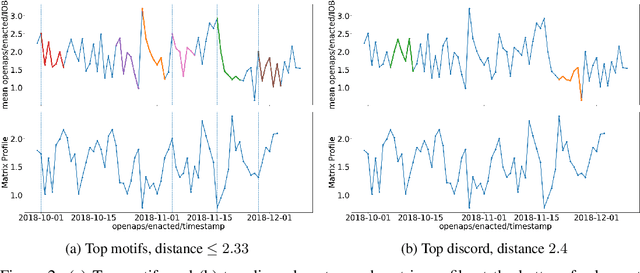
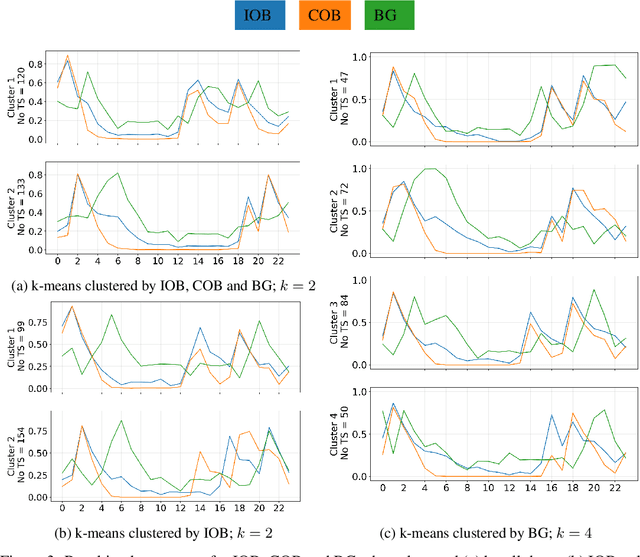
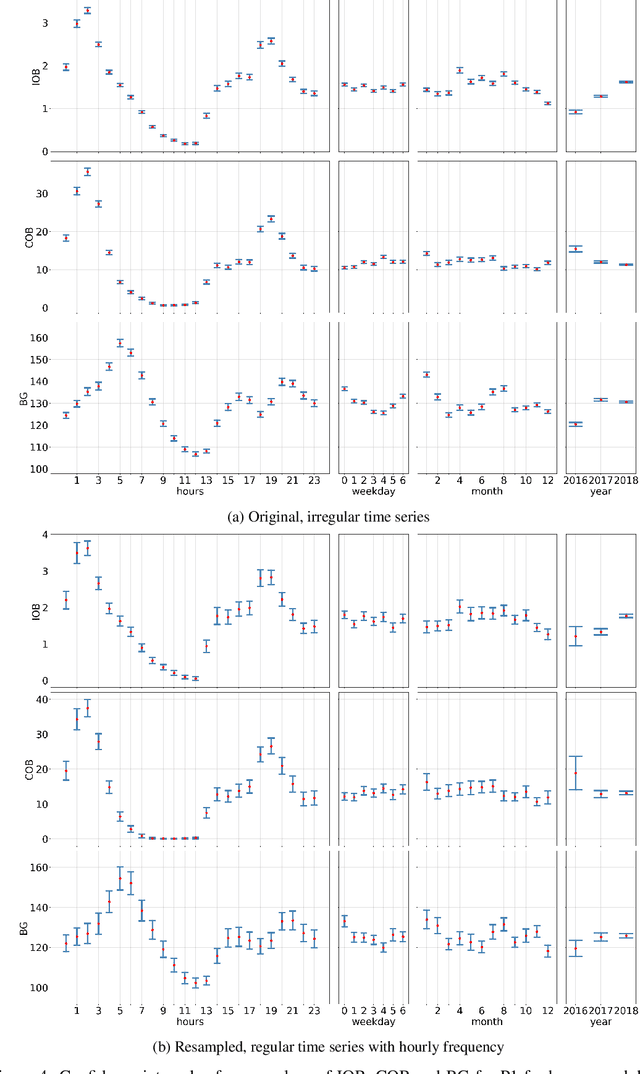
Type 1 Diabetes (T1D) is a chronic condition where the body produces little or no insulin, a hormone required for the cells to use blood glucose (BG) for energy and to regulate BG levels in the body. Finding the right insulin dose and time remains a complex, challenging and as yet unsolved control task. In this study, we use the OpenAPS Data Commons dataset, which is an extensive dataset collected in real-life conditions, to discover temporal patterns in insulin need driven by well-known factors such as carbohydrates as well as potentially novel factors. We utilised various time series techniques to spot such patterns using matrix profile and multi-variate clustering. The better we understand T1D and the factors impacting insulin needs, the more we can contribute to building data-driven technology for T1D treatments.
Automatic Recognition and Classification of Future Work Sentences from Academic Articles in a Specific Domain
Dec 28, 2022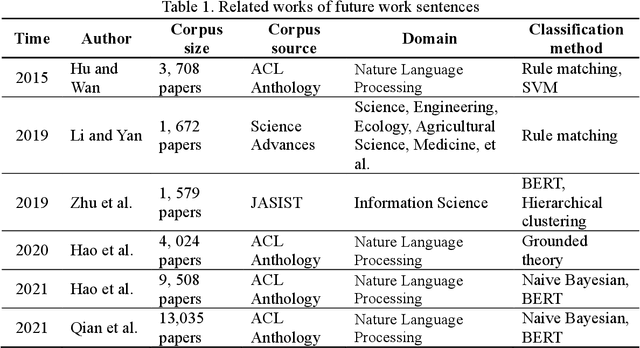
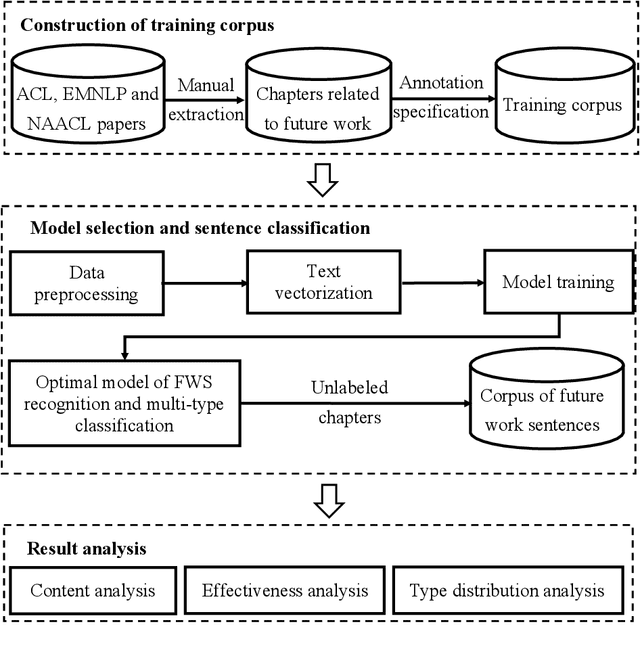


Future work sentences (FWS) are the particular sentences in academic papers that contain the author's description of their proposed follow-up research direction. This paper presents methods to automatically extract FWS from academic papers and classify them according to the different future directions embodied in the paper's content. FWS recognition methods will enable subsequent researchers to locate future work sentences more accurately and quickly and reduce the time and cost of acquiring the corpus. The current work on automatic identification of future work sentences is relatively small, and the existing research cannot accurately identify FWS from academic papers, and thus cannot conduct data mining on a large scale. Furthermore, there are many aspects to the content of future work, and the subdivision of the content is conducive to the analysis of specific development directions. In this paper, Nature Language Processing (NLP) is used as a case study, and FWS are extracted from academic papers and classified into different types. We manually build an annotated corpus with six different types of FWS. Then, automatic recognition and classification of FWS are implemented using machine learning models, and the performance of these models is compared based on the evaluation metrics. The results show that the Bernoulli Bayesian model has the best performance in the automatic recognition task, with the Macro F1 reaching 90.73%, and the SCIBERT model has the best performance in the automatic classification task, with the weighted average F1 reaching 72.63%. Finally, we extract keywords from FWS and gain a deep understanding of the key content described in FWS, and we also demonstrate that content determination in FWS will be reflected in the subsequent research work by measuring the similarity between future work sentences and the abstracts.
Recurrent Neural Networks and Universal Approximation of Bayesian Filters
Nov 01, 2022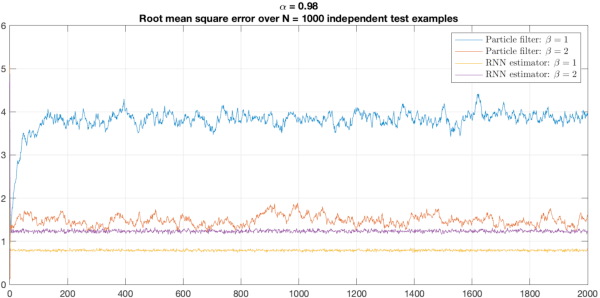
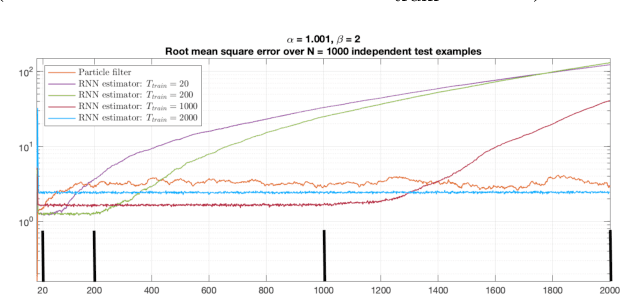
We consider the Bayesian optimal filtering problem: i.e. estimating some conditional statistics of a latent time-series signal from an observation sequence. Classical approaches often rely on the use of assumed or estimated transition and observation models. Instead, we formulate a generic recurrent neural network framework and seek to learn directly a recursive mapping from observational inputs to the desired estimator statistics. The main focus of this article is the approximation capabilities of this framework. We provide approximation error bounds for filtering in general non-compact domains. We also consider strong time-uniform approximation error bounds that guarantee good long-time performance. We discuss and illustrate a number of practical concerns and implications of these results.
Graph Learning from Multivariate Dependent Time Series via a Multi-Attribute Formulation
Apr 29, 2022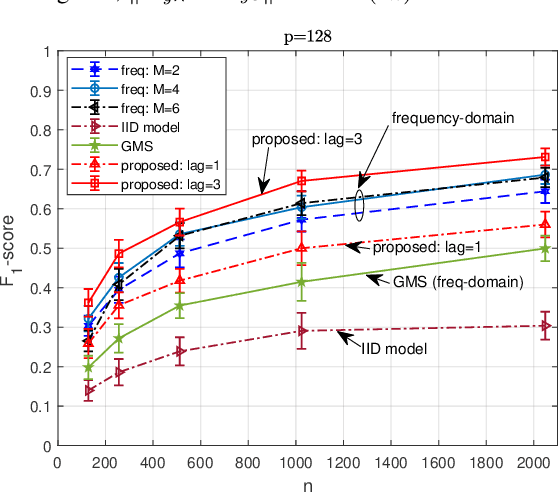
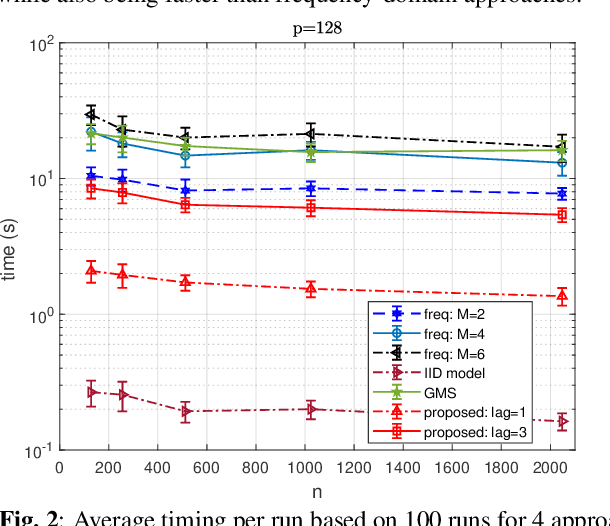
We consider the problem of inferring the conditional independence graph (CIG) of a high-dimensional stationary multivariate Gaussian time series. In a time series graph, each component of the vector series is represented by distinct node, and associations between components are represented by edges between the corresponding nodes. We formulate the problem as one of multi-attribute graph estimation for random vectors where a vector is associated with each node of the graph. At each node, the associated random vector consists of a time series component and its delayed copies. We present an alternating direction method of multipliers (ADMM) solution to minimize a sparse-group lasso penalized negative pseudo log-likelihood objective function to estimate the precision matrix of the random vector associated with the entire multi-attribute graph. The time series CIG is then inferred from the estimated precision matrix. A theoretical analysis is provided. Numerical results illustrate the proposed approach which outperforms existing frequency-domain approaches in correctly detecting the graph edges.
3D-TOGO: Towards Text-Guided Cross-Category 3D Object Generation
Dec 02, 2022
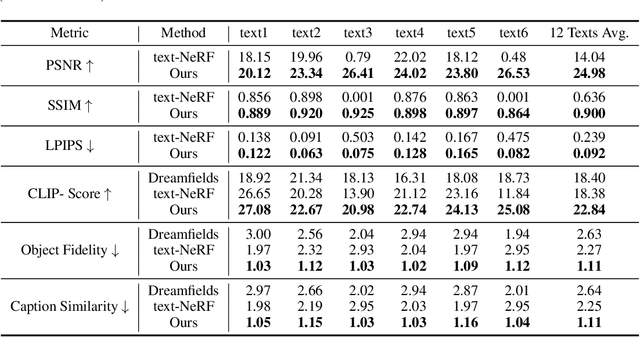
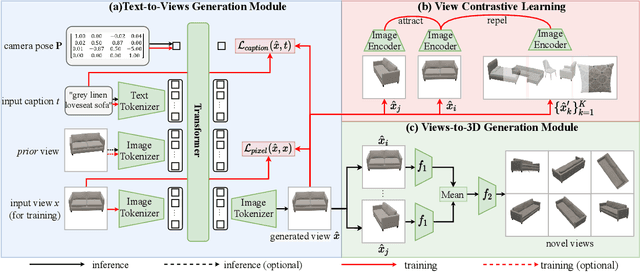
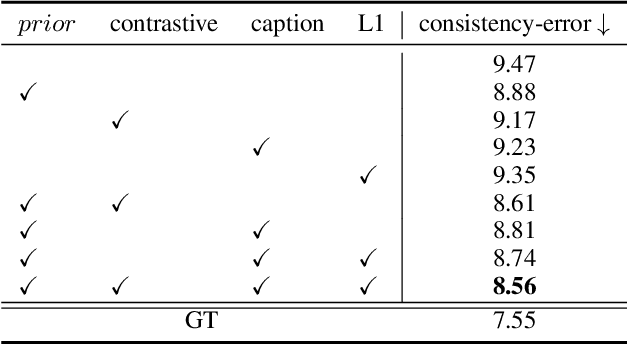
Text-guided 3D object generation aims to generate 3D objects described by user-defined captions, which paves a flexible way to visualize what we imagined. Although some works have been devoted to solving this challenging task, these works either utilize some explicit 3D representations (e.g., mesh), which lack texture and require post-processing for rendering photo-realistic views; or require individual time-consuming optimization for every single case. Here, we make the first attempt to achieve generic text-guided cross-category 3D object generation via a new 3D-TOGO model, which integrates a text-to-views generation module and a views-to-3D generation module. The text-to-views generation module is designed to generate different views of the target 3D object given an input caption. prior-guidance, caption-guidance and view contrastive learning are proposed for achieving better view-consistency and caption similarity. Meanwhile, a pixelNeRF model is adopted for the views-to-3D generation module to obtain the implicit 3D neural representation from the previously-generated views. Our 3D-TOGO model generates 3D objects in the form of the neural radiance field with good texture and requires no time-cost optimization for every single caption. Besides, 3D-TOGO can control the category, color and shape of generated 3D objects with the input caption. Extensive experiments on the largest 3D object dataset (i.e., ABO) are conducted to verify that 3D-TOGO can better generate high-quality 3D objects according to the input captions across 98 different categories, in terms of PSNR, SSIM, LPIPS and CLIP-score, compared with text-NeRF and Dreamfields.
Space, Time, and Interaction: A Taxonomy of Corner Cases in Trajectory Datasets for Automated Driving
Oct 17, 2022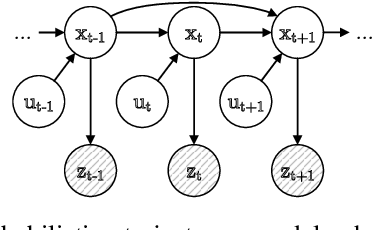
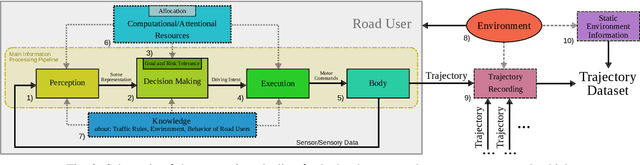
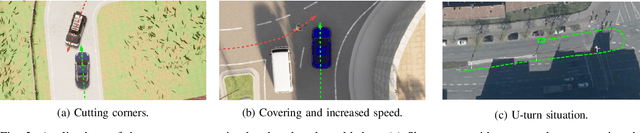
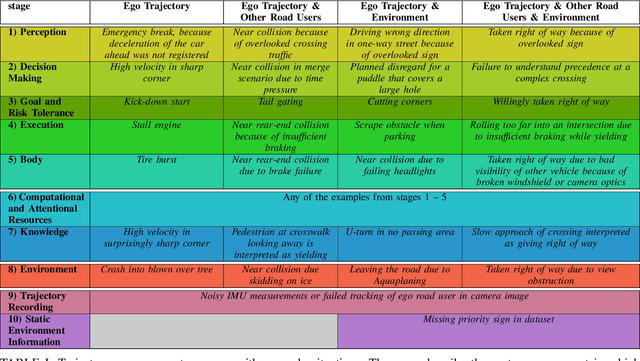
Trajectory data analysis is an essential component for highly automated driving. Complex models developed with these data predict other road users' movement and behavior patterns. Based on these predictions - and additional contextual information such as the course of the road, (traffic) rules, and interaction with other road users - the highly automated vehicle (HAV) must be able to reliably and safely perform the task assigned to it, e.g., moving from point A to B. Ideally, the HAV moves safely through its environment, just as we would expect a human driver to do. However, if unusual trajectories occur, so-called trajectory corner cases, a human driver can usually cope well, but an HAV can quickly get into trouble. In the definition of trajectory corner cases, which we provide in this work, we will consider the relevance of unusual trajectories with respect to the task at hand. Based on this, we will also present a taxonomy of different trajectory corner cases. The categorization of corner cases into the taxonomy will be shown with examples and is done by cause and required data sources. To illustrate the complexity between the machine learning (ML) model and the corner case cause, we present a general processing chain underlying the taxonomy.
Improving trajectory localization accuracy via direction-of-arrival derivative estimation
Dec 10, 2022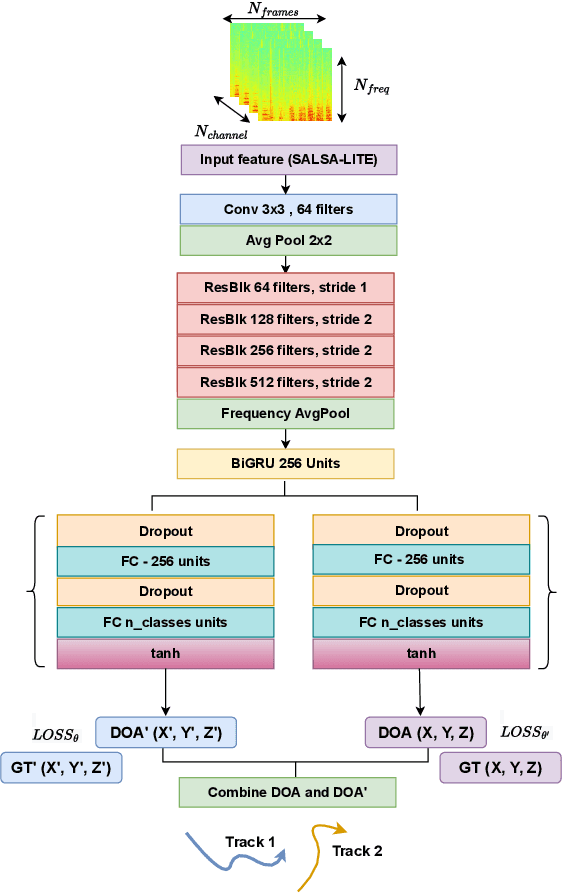
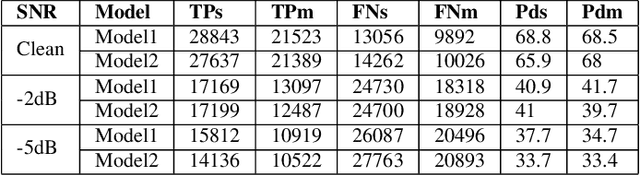
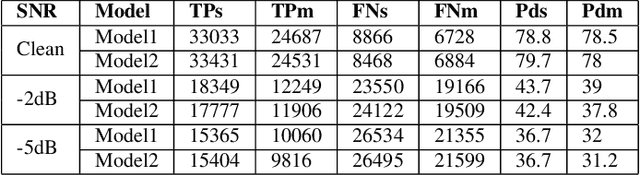
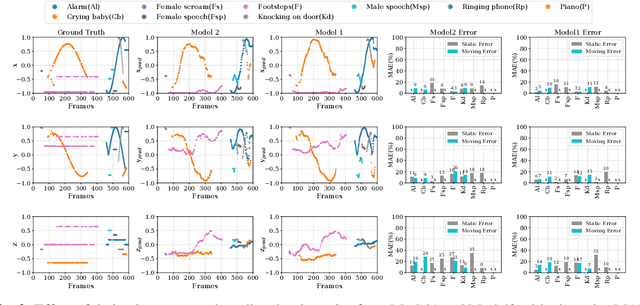
Sound source localization is crucial in acoustic sensing and monitoring-related applications. In this paper, we do a comprehensive analysis of improvement in sound source localization by combining the direction of arrivals (DOAs) with their derivatives which quantify the changes in the positions of sources over time. This study uses the SALSA-Lite feature with a convolutional recurrent neural network (CRNN) model for predicting DOAs and their first-order derivatives. An update rule is introduced to combine the predicted DOAs with the estimated derivatives to obtain the final DOAs. The experimental validation is done using TAU-NIGENS Spatial Sound Events (TNSSE) 2021 dataset. We compare the performance of the networks predicting DOAs with derivative vs. the one predicting only the DOAs at low SNR levels. The results show that combining the derivatives with the DOAs improves the localization accuracy of moving sources.
Delay Embedded Echo-State Network: A Predictor for Partially Observed Systems
Nov 11, 2022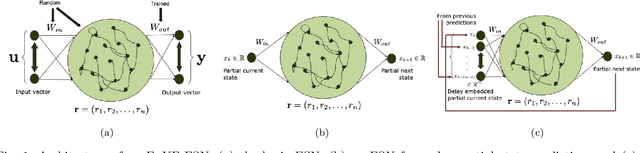

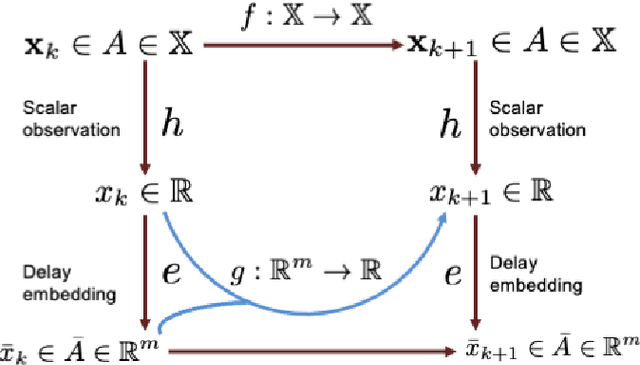
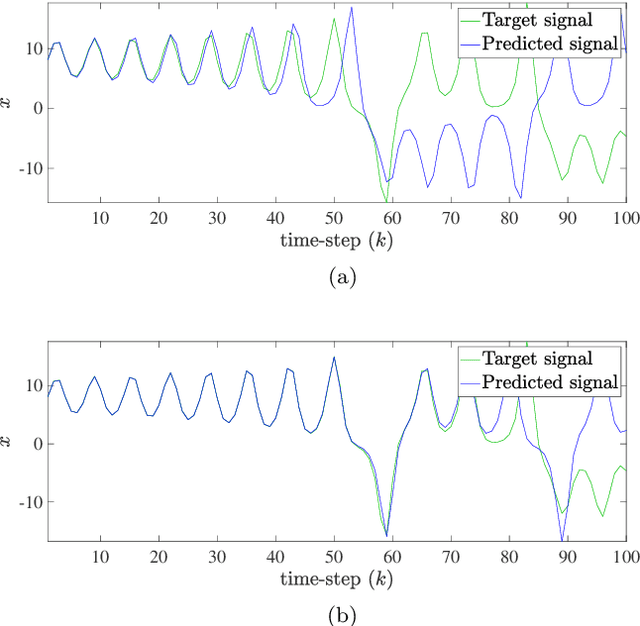
This paper considers the problem of data-driven prediction of partially observed systems using a recurrent neural network. While neural network based dynamic predictors perform well with full-state training data, prediction with partial observation during training phase poses a significant challenge. Here a predictor for partial observations is developed using an echo-state network (ESN) and time delay embedding of the partially observed state. The proposed method is theoretically justified with Taken's embedding theorem and strong observability of a nonlinear system. The efficacy of the proposed method is demonstrated on three systems: two synthetic datasets from chaotic dynamical systems and a set of real-time traffic data.