 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sound Localization by Self-Supervised Time Delay Estimation
Apr 26, 2022
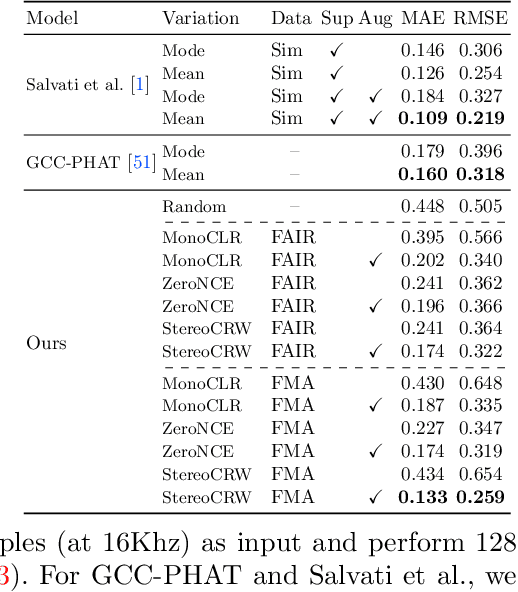
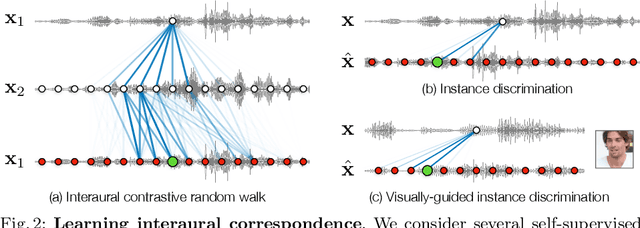
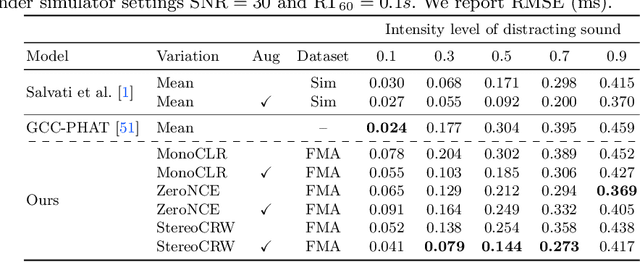

Sounds reach one microphone in a stereo pair sooner than the other, resulting in an interaural time delay that conveys their directions. Estimating a sound's time delay requires finding correspondences between the signals recorded by each microphone. We propose to learn these correspondences through self-supervision, drawing on recent techniques from visual tracking. We adapt the contrastive random walk of Jabri et al. to learn a cycle-consistent representation from unlabeled stereo sounds, resulting in a model that performs on par with supervised methods on "in the wild" internet recordings. We also propose a multimodal contrastive learning model that solves a visually-guided localization task: estimating the time delay for a particular person in a multi-speaker mixture, given a visual representation of their face. Project site: https://ificl.github.io/stereocrw/
Revisiting Realistic Test-Time Training: Sequential Inference and Adaptation by Anchored Clustering
Jun 06, 2022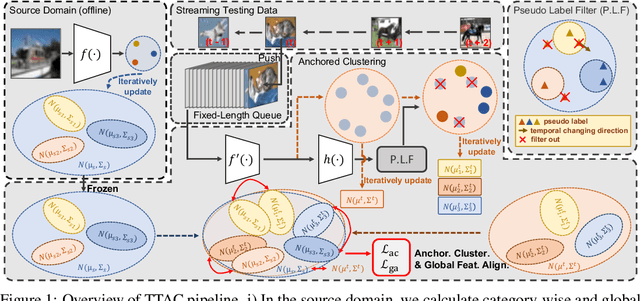
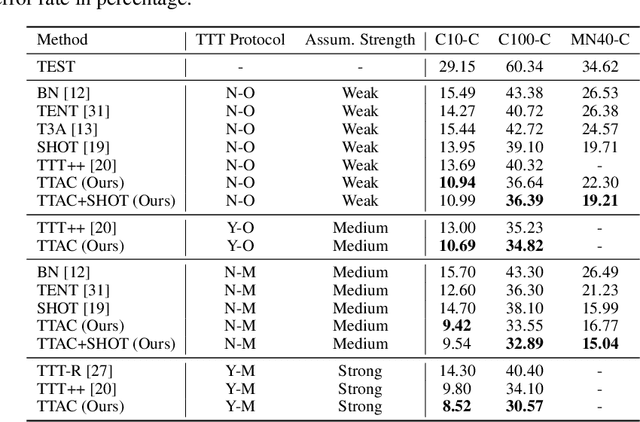
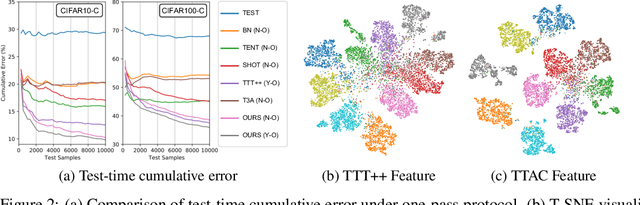
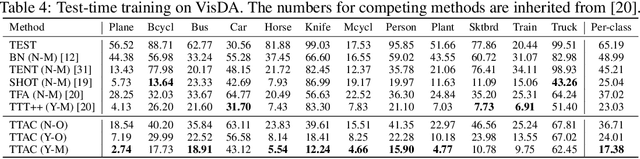
Deploying models on target domain data subject to distribution shift requires adaptation. Test-time training (TTT) emerges as a solution to this adaptation under a realistic scenario where access to full source domain data is not available and instant inference on target domain is required. Despite many efforts into TTT, there is a confusion over the experimental settings, thus leading to unfair comparisons. In this work, we first revisit TTT assumptions and categorize TTT protocols by two key factors. Among the multiple protocols, we adopt a realistic sequential test-time training (sTTT) protocol, under which we further develop a test-time anchored clustering (TTAC) approach to enable stronger test-time feature learning. TTAC discovers clusters in both source and target domain and match the target clusters to the source ones to improve generalization. Pseudo label filtering and iterative updating are developed to improve the effectiveness and efficiency of anchored clustering. We demonstrate that under all TTT protocols TTAC consistently outperforms the state-of-the-art methods on five TTT datasets. We hope this work will provide a fair benchmarking of TTT methods and future research should be compared within respective protocols. A demo code is available at https://github.com/Gorilla-Lab-SCUT/TTAC.
Power Control for 6G Industrial Wireless Subnetworks: A Graph Neural Network Approach
Dec 30, 2022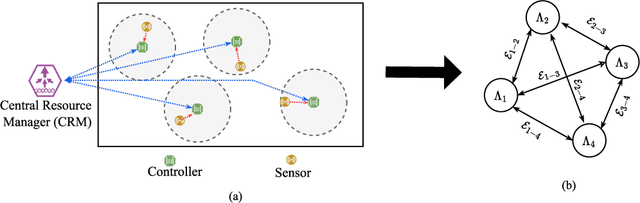
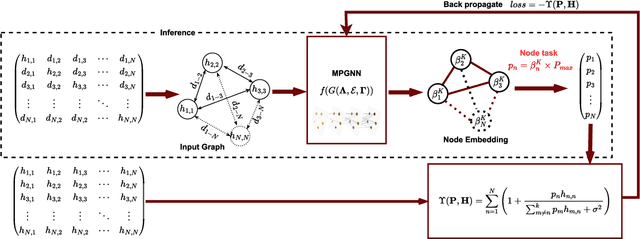
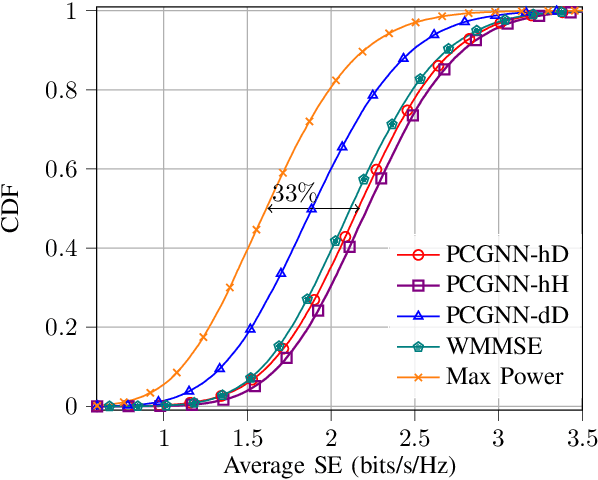
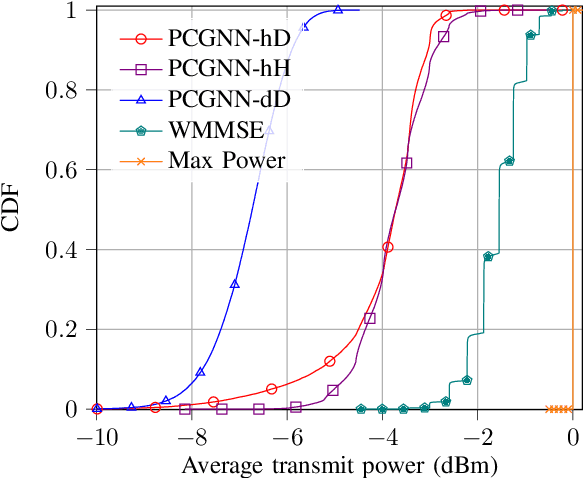
6th Generation (6G) industrial wireless subnetworks are expected to replace wired connectivity for control operation in robots and production modules. Interference management techniques such as centralized power control can improve spectral efficiency in dense deployments of such subnetworks. However, existing solutions for centralized power control may require full channel state information (CSI) of all the desired and interfering links, which may be cumbersome and time-consuming to obtain in dense deployments. This paper presents a novel solution for centralized power control for industrial subnetworks based on Graph Neural Networks (GNNs). The proposed method only requires the subnetwork positioning information, usually known at the central controller, and the knowledge of the desired link channel gain during the execution phase. Simulation results show that our solution achieves similar spectral efficiency as the benchmark schemes requiring full CSI in runtime operations. Also, robustness to changes in the deployment density and environment characteristics with respect to the training phase is verified.
A Machine Learning Case Study for AI-empowered echocardiography of Intensive Care Unit Patients in low- and middle-income countries
Dec 30, 2022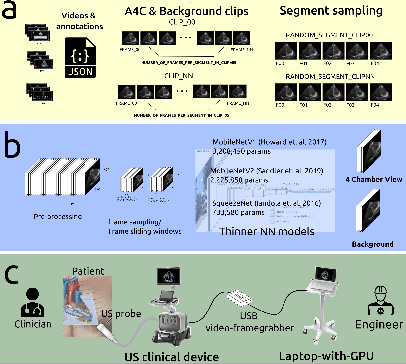
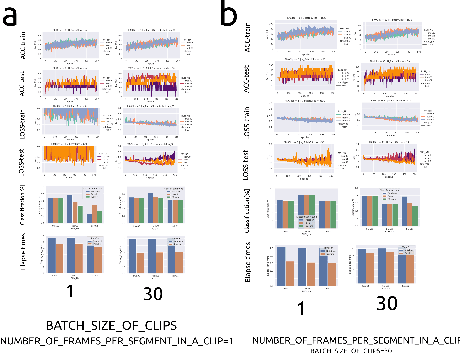
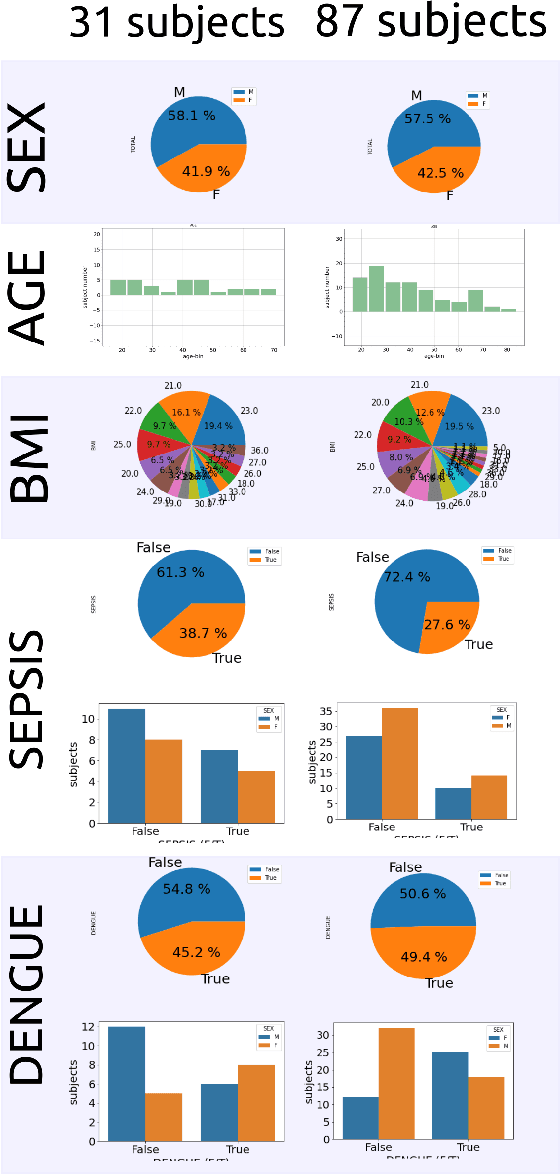
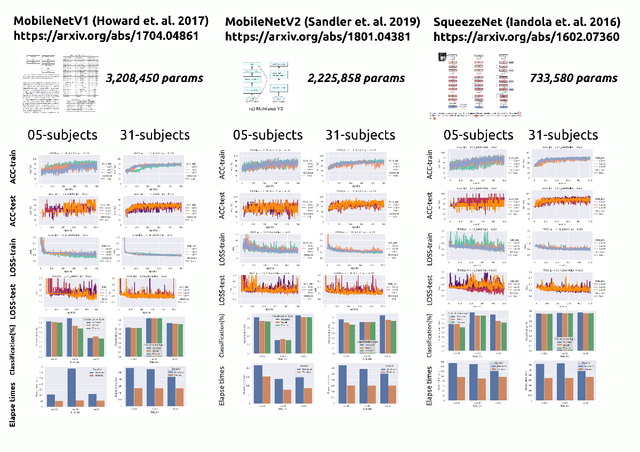
We present a Machine Learning (ML) study case to illustrate the challenges of clinical translation for a real-time AI-empowered echocardiography system with data of ICU patients in LMICs. Such ML case study includes data preparation, curation and labelling from 2D Ultrasound videos of 31 ICU patients in LMICs and model selection, validation and deployment of three thinner neural networks to classify apical four-chamber view. Results of the ML heuristics showed the promising implementation, validation and application of thinner networks to classify 4CV with limited datasets. We conclude this work mentioning the need for (a) datasets to improve diversity of demographics, diseases, and (b) the need of further investigations of thinner models to be run and implemented in low-cost hardware to be clinically translated in the ICU in LMICs. The code and other resources to reproduce this work are available at https://github.com/vital-ultrasound/ai-assisted-echocardiography-for-low-resource-countries.
MountNet: Learning an Inertial Sensor Mounting Angle with Deep Neural Networks
Dec 10, 2022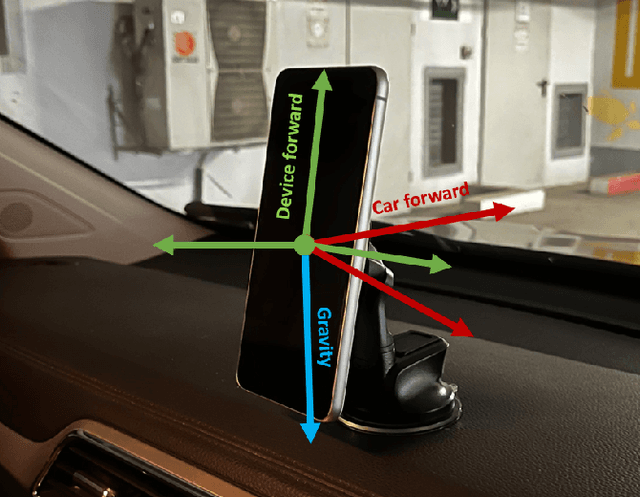
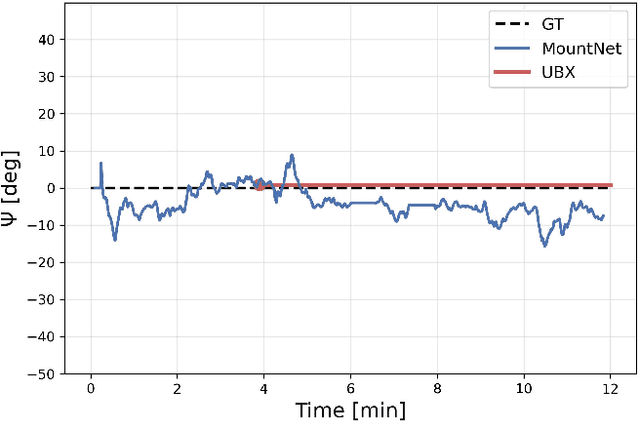
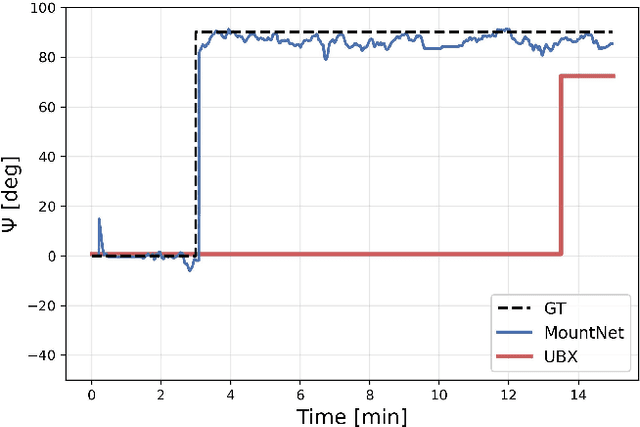
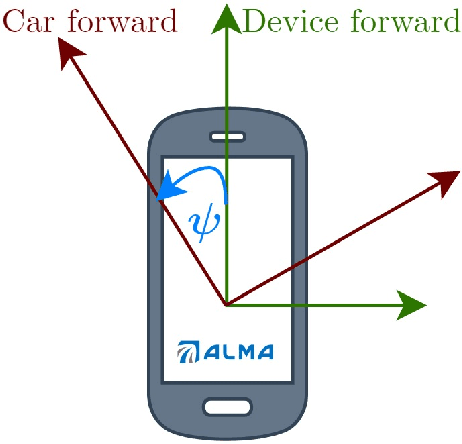
Finding the mounting angle of a smartphone inside a car is crucial for navigation, motion detection, activity recognition, and other applications. It is a challenging task in several aspects: (i) the mounting angle at the drive start is unknown and may differ significantly between users; (ii) the user, or bad fixture, may change the mounting angle while driving; (iii) a rapid and computationally efficient real-time solution is required for most applications. To tackle these problems, a data-driven approach using deep neural networks (DNNs) is presented to learn the yaw mounting angle of a smartphone equipped with an inertial measurement unit (IMU) and strapped to a car. The proposed model, MountNet, uses only IMU readings as input and, in contrast to existing solutions, does not require inputs from global navigation satellite systems (GNSS). IMU data is collected for training and validation with the sensor mounted at a known yaw mounting angle and a range of ground truth labels is generated by applying a prescribed rotation to the measurements. Although the training data did not include recordings with real sensor rotations, tests on data with real and synthetic rotations show similar results. An algorithm is formulated for real-time deployment to detect and smooth transitions in device mounting angle estimated by MountNet. MountNet is shown to find the mounting angle rapidly which is critical in real-time applications. Our method converges in less than 30 seconds of driving to a mean error of 4 degrees allowing a fast calibration phase for other algorithms and applications. When the device is rotated in the middle of a drive, large changes converge in 5 seconds and small changes converge in less than 30 seconds.
Multi-Variate Time Series Forecasting on Variable Subsets
Jun 25, 2022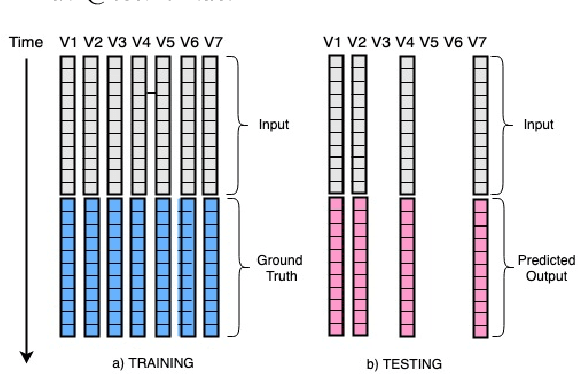
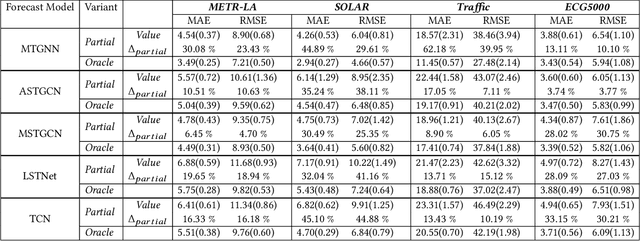
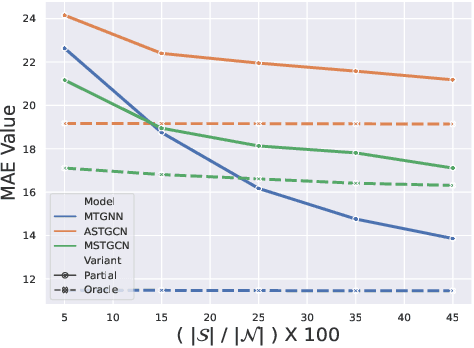

We formulate a new inference task in the domain of multivariate time series forecasting (MTSF), called Variable Subset Forecast (VSF), where only a small subset of the variables is available during inference. Variables are absent during inference because of long-term data loss (eg. sensor failures) or high -> low-resource domain shift between train / test. To the best of our knowledge, robustness of MTSF models in presence of such failures, has not been studied in the literature. Through extensive evaluation, we first show that the performance of state of the art methods degrade significantly in the VSF setting. We propose a non-parametric, wrapper technique that can be applied on top any existing forecast models. Through systematic experiments across 4 datasets and 5 forecast models, we show that our technique is able to recover close to 95\% performance of the models even when only 15\% of the original variables are present.
Automated Optical Inspection of FAST's Reflector Surface using Drones and Computer Vision
Dec 18, 2022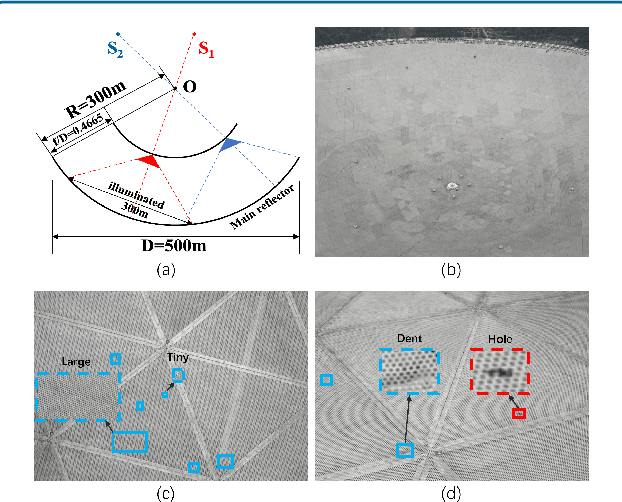
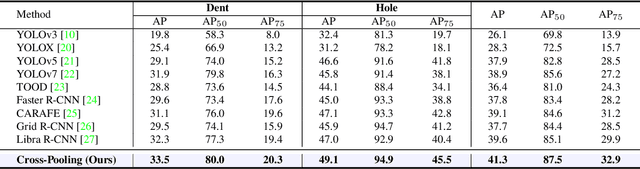
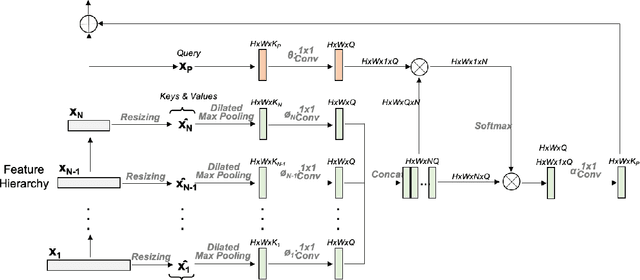
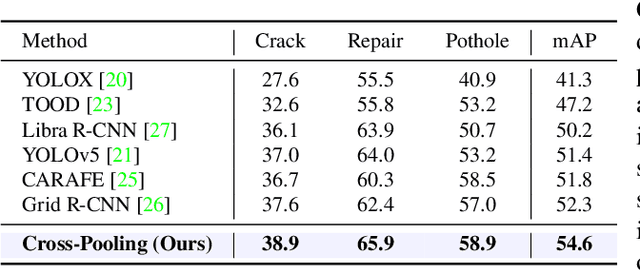
The Five-hundred-meter Aperture Spherical radio Telescope (FAST) is the world's largest single-dish radio telescope. Its large reflecting surface achieves unprecedented sensitivity but is prone to damage, such as dents and holes, caused by naturally-occurring falling objects. Hence, the timely and accurate detection of surface defects is crucial for FAST's stable operation. Conventional manual inspection involves human inspectors climbing up and examining the large surface visually, a time-consuming and potentially unreliable process. To accelerate the inspection process and increase its accuracy, this work makes the first step towards automating the inspection of FAST by integrating deep-learning techniques with drone technology. First, a drone flies over the surface along a predetermined route. Since surface defects significantly vary in scale and show high inter-class similarity, directly applying existing deep detectors to detect defects on the drone imagery is highly prone to missing and misidentifying defects. As a remedy, we introduce cross-fusion, a dedicated plug-in operation for deep detectors that enables the adaptive fusion of multi-level features in a point-wise selective fashion, depending on local defect patterns. Consequently, strong semantics and fine-grained details are dynamically fused at different positions to support the accurate detection of defects of various scales and types. Our AI-powered drone-based automated inspection is time-efficient, reliable, and has good accessibility, which guarantees the long-term and stable operation of FAST.
GPU-accelerated Guided Source Separation for Meeting Transcription
Dec 10, 2022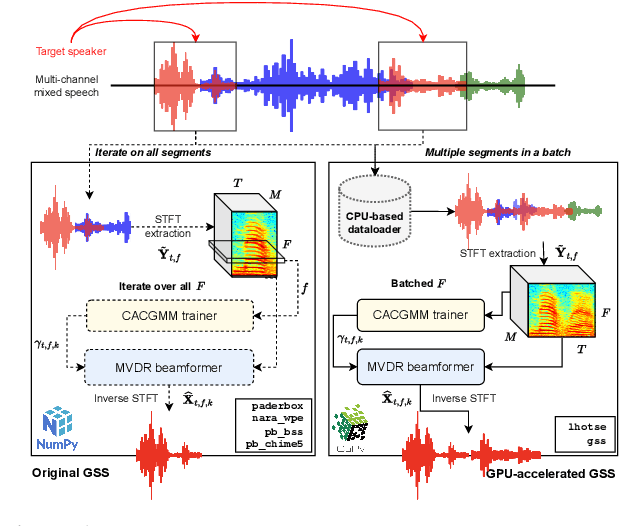
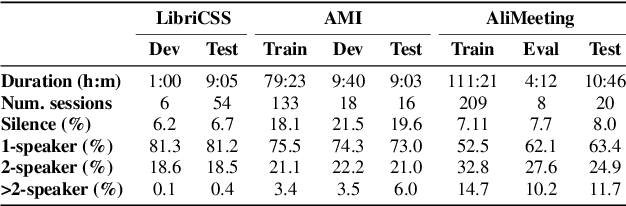
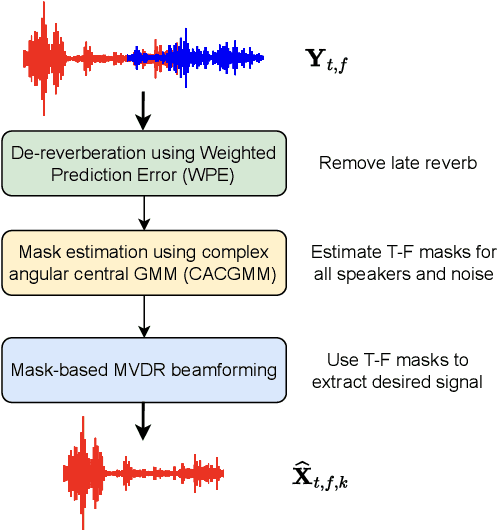
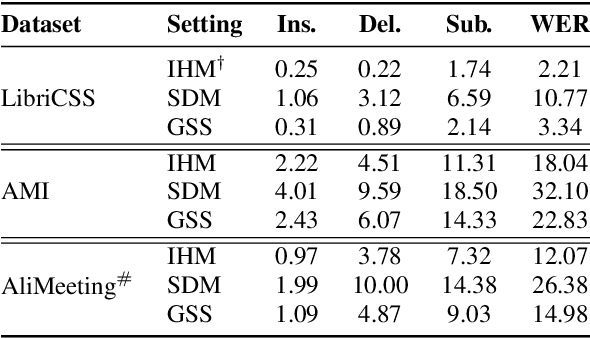
Guided source separation (GSS) is a type of target-speaker extraction method that relies on pre-computed speaker activities and blind source separation to perform front-end enhancement of overlapped speech signals. It was first proposed during the CHiME-5 challenge and provided significant improvements over the delay-and-sum beamforming baseline. Despite its strengths, however, the method has seen limited adoption for meeting transcription benchmarks primarily due to its high computation time. In this paper, we describe our improved implementation of GSS that leverages the power of modern GPU-based pipelines, including batched processing of frequencies and segments, to provide 300x speed-up over CPU-based inference. The improved inference time allows us to perform detailed ablation studies over several parameters of the GSS algorithm -- such as context duration, number of channels, and noise class, to name a few. We provide end-to-end reproducible pipelines for speaker-attributed transcription of popular meeting benchmarks: LibriCSS, AMI, and AliMeeting. Our code and recipes are publicly available: https://github.com/desh2608/gss.
DADAO: Decoupled Accelerated Decentralized Asynchronous Optimization for Time-Varying Gossips
Jul 26, 2022
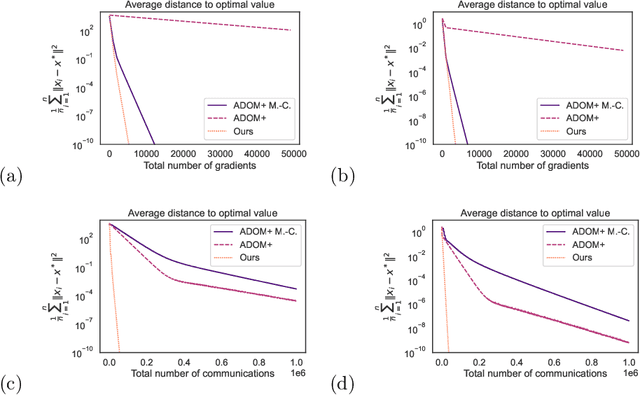

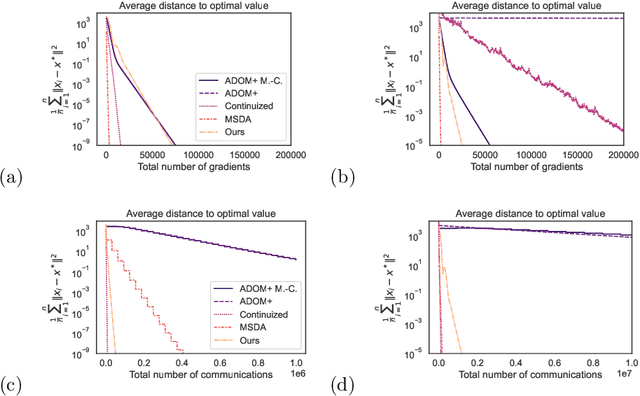
DADAO is a novel decentralized asynchronous stochastic algorithm to minimize a sum of $L$-smooth and $\mu$-strongly convex functions distributed over a time-varying connectivity network of size $n$. We model the local gradient updates and gossip communication procedures with separate independent Poisson Point Processes, decoupling the computation and communication steps in addition to making the whole approach completely asynchronous. Our method employs primal gradients and do not use a multi-consensus inner loop nor other ad-hoc mechanisms as Error Feedback, Gradient Tracking or a Proximal operator. By relating spatial quantities of our graphs $\chi^*_1,\chi_2^*$ to a necessary minimal communication rate between nodes of the network, we show that our algorithm requires $\mathcal{O}(n\sqrt{\frac{L}{\mu}}\log \epsilon)$ local gradients and only $\mathcal{O}(n\sqrt{\chi_1^*\chi_2^*}\sqrt{\frac{L}{\mu}}\log \epsilon)$ communications to reach a precision $\epsilon$. If SGD with uniform noise $\sigma^2$ is used, we reach a precision $\epsilon$ with same speed, up to a bias term in $\mathcal{O}(\frac{\sigma^2}{\sqrt{\mu L}})$. This improves upon the bounds obtained with current state-of-the-art approaches, our simulations validating the strength of our relatively unconstrained method. Our source-code is released on a public repository.
Personalized Student Attribute Inference
Dec 26, 2022Accurately predicting their future performance can ensure students successful graduation, and help them save both time and money. However, achieving such predictions faces two challenges, mainly due to the diversity of students' background and the necessity of continuously tracking their evolving progress. The goal of this work is to create a system able to automatically detect students in difficulty, for instance predicting if they are likely to fail a course. We compare a naive approach widely used in the literature, which uses attributes available in the data set (like the grades), with a personalized approach we called Personalized Student Attribute Inference (PSAI). With our model, we create personalized attributes to capture the specific background of each student. Both approaches are compared using machine learning algorithms like decision trees, support vector machine or neural networks.