 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Self-Supervised Video Forensics by Audio-Visual Anomaly Detection
Jan 04, 2023
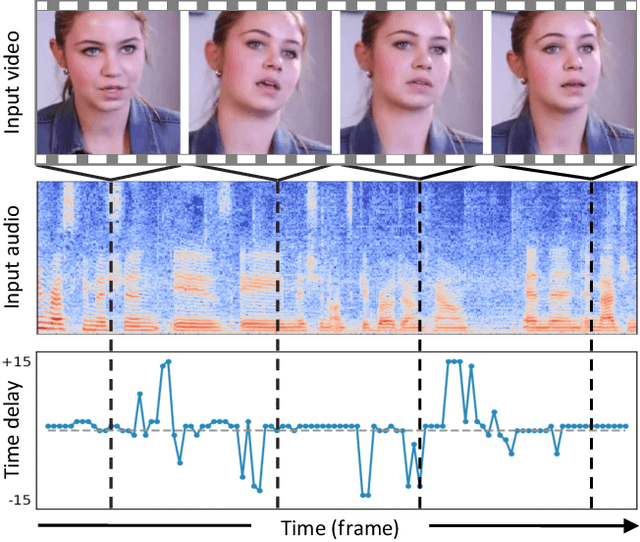
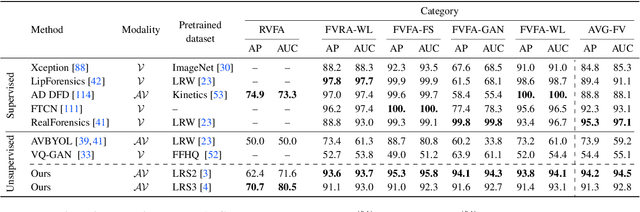
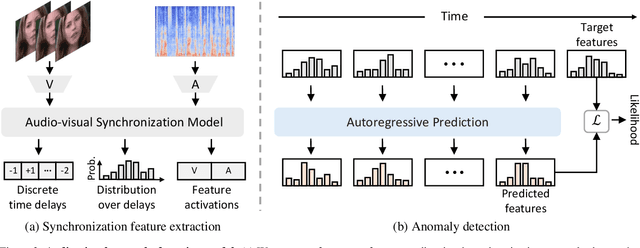
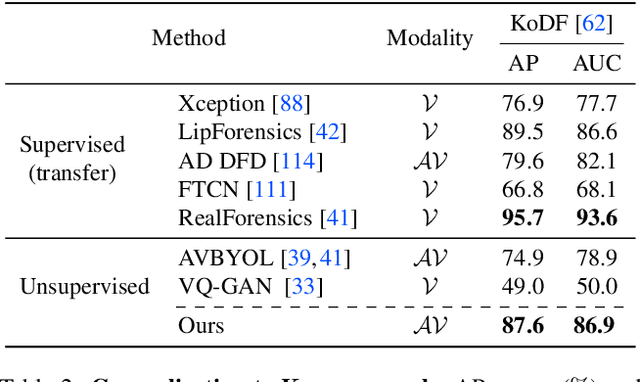
Manipulated videos often contain subtle inconsistencies between their visual and audio signals. We propose a video forensics method, based on anomaly detection, that can identify these inconsistencies, and that can be trained solely using real, unlabeled data. We train an autoregressive model to generate sequences of audio-visual features, using feature sets that capture the temporal synchronization between video frames and sound. At test time, we then flag videos that the model assigns low probability. Despite being trained entirely on real videos, our model obtains strong performance on the task of detecting manipulated speech videos. Project site: https://cfeng16.github.io/audio-visual-forensics
Neural Assets: Volumetric Object Capture and Rendering for Interactive Environments
Dec 12, 2022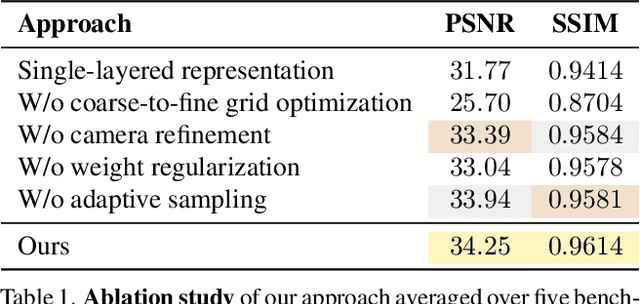
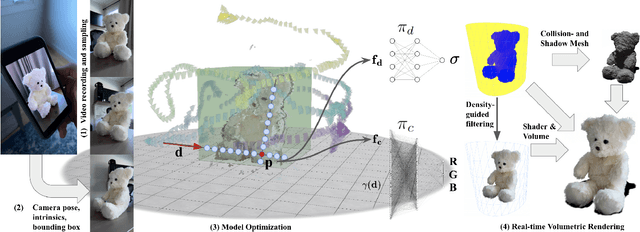
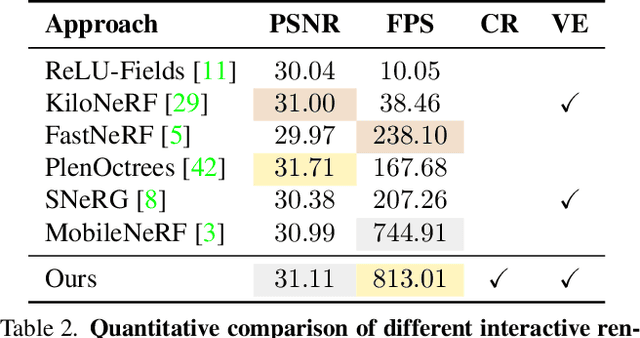
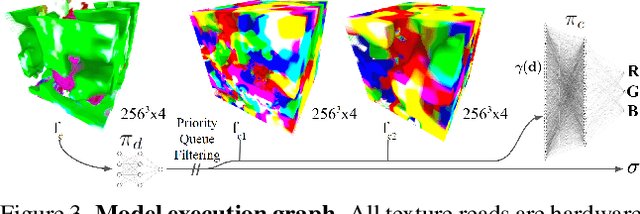
Creating realistic virtual assets is a time-consuming process: it usually involves an artist designing the object, then spending a lot of effort on tweaking its appearance. Intricate details and certain effects, such as subsurface scattering, elude representation using real-time BRDFs, making it impossible to fully capture the appearance of certain objects. Inspired by the recent progress of neural rendering, we propose an approach for capturing real-world objects in everyday environments faithfully and fast. We use a novel neural representation to reconstruct volumetric effects, such as translucent object parts, and preserve photorealistic object appearance. To support real-time rendering without compromising rendering quality, our model uses a grid of features and a small MLP decoder that is transpiled into efficient shader code with interactive framerates. This leads to a seamless integration of the proposed neural assets with existing mesh environments and objects. Thanks to the use of standard shader code rendering is portable across many existing hardware and software systems.
Boundary Guided Semantic Learning for Real-time COVID-19 Lung Infection Segmentation System
Sep 07, 2022
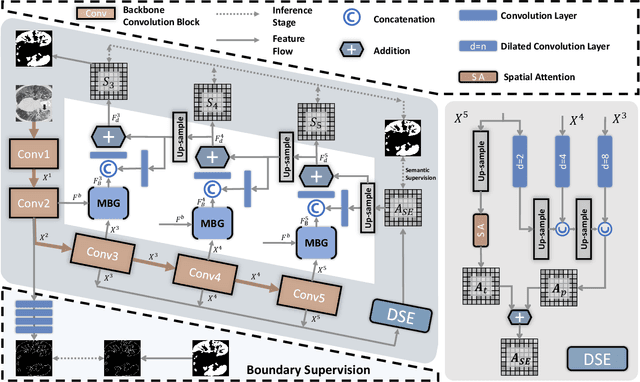
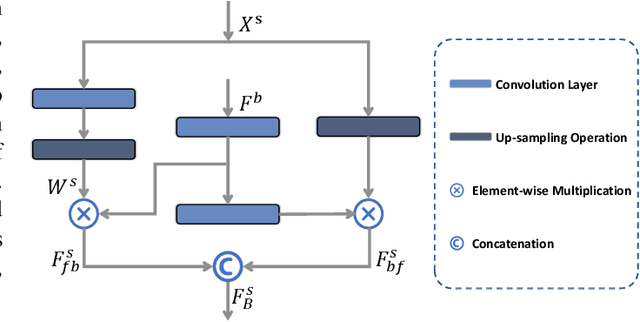
The coronavirus disease 2019 (COVID-19) continues to have a negative impact on healthcare systems around the world, though the vaccines have been developed and national vaccination coverage rate is steadily increasing. At the current stage, automatically segmenting the lung infection area from CT images is essential for the diagnosis and treatment of COVID-19. Thanks to the development of deep learning technology, some deep learning solutions for lung infection segmentation have been proposed. However, due to the scattered distribution, complex background interference and blurred boundaries, the accuracy and completeness of the existing models are still unsatisfactory. To this end, we propose a boundary guided semantic learning network (BSNet) in this paper. On the one hand, the dual-branch semantic enhancement module that combines the top-level semantic preservation and progressive semantic integration is designed to model the complementary relationship between different high-level features, thereby promoting the generation of more complete segmentation results. On the other hand, the mirror-symmetric boundary guidance module is proposed to accurately detect the boundaries of the lesion regions in a mirror-symmetric way. Experiments on the publicly available dataset demonstrate that our BSNet outperforms the existing state-of-the-art competitors and achieves a real-time inference speed of 44 FPS.
Narrowband Interference Detection via Deep Learning
Jan 23, 2023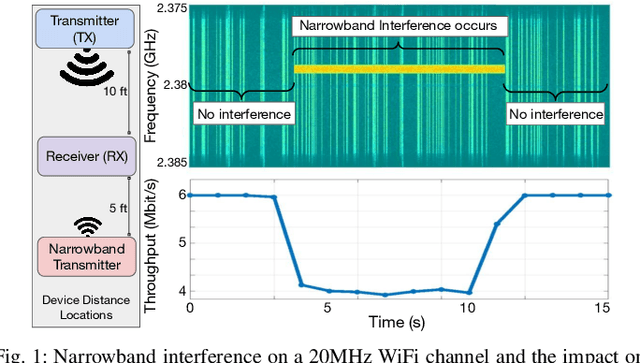
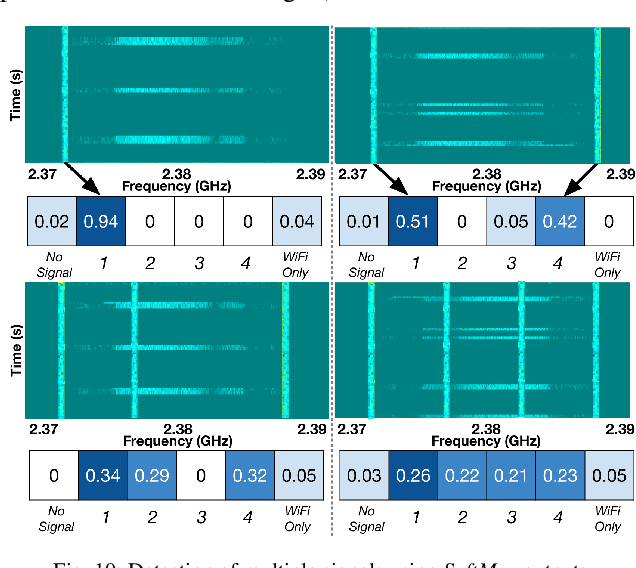
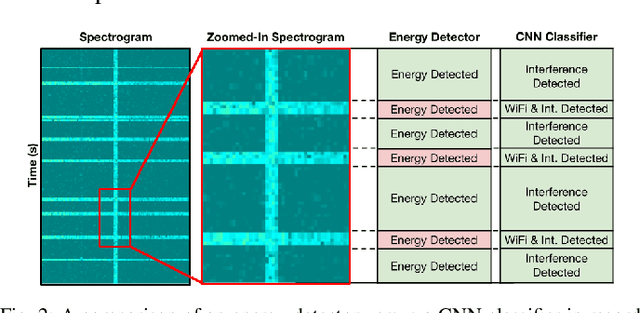
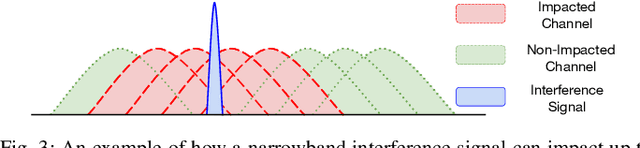
Due to the increased usage of spectrum caused by the exponential growth of wireless devices, detecting and avoiding interference has become an increasingly relevant problem to ensure uninterrupted wireless communications. In this paper, we focus our interest on detecting narrowband interference caused by signals that despite occupying a small portion of the spectrum only can cause significant harm to wireless systems, for example, in the case of interference with pilots and other signals that are used to equalize the effect of the channel or attain synchronization. Due to the small sizes of these signals, detection can be difficult due to their low energy footprint, while greatly impacting (or denying completely in some cases) network communications. We present a novel narrowband interference detection solution that utilizes convolutional neural networks (CNNs) to detect and locate these signals with high accuracy. To demonstrate the effectiveness of our solution, we have built a prototype that has been tested and validated on a real-world over-the-air large-scale wireless testbed. Our experimental results show that our solution is capable of detecting narrowband jamming attacks with an accuracy of up to 99%. Moreover, it is also able to detect multiple attacks affecting several frequencies at the same time even in the case of previously unseen attack patterns. Not only can our solution achieve a detection accuracy between 92% and 99%, but it does so by only adding an inference latency of 0.093ms.
Tracking the industrial growth of modern China with high-resolution panchromatic imagery: A sequential convolutional approach
Jan 23, 2023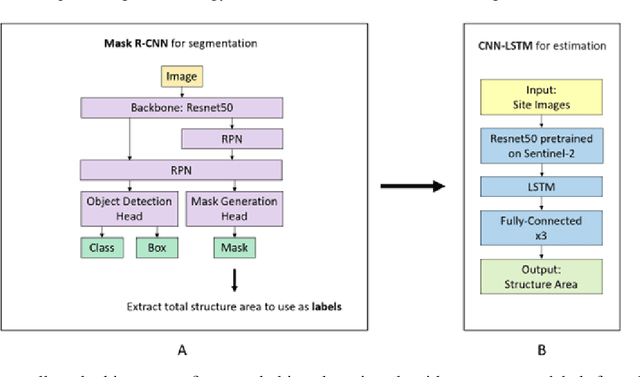
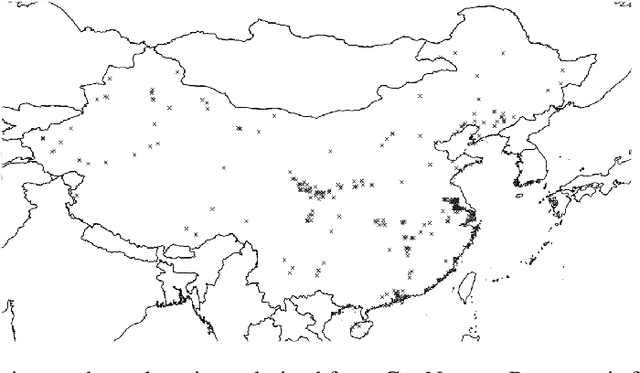

Due to insufficient or difficult to obtain data on development in inaccessible regions, remote sensing data is an important tool for interested stakeholders to collect information on economic growth. To date, no studies have utilized deep learning to estimate industrial growth at the level of individual sites. In this study, we harness high-resolution panchromatic imagery to estimate development over time at 419 industrial sites in the People's Republic of China using a multi-tier computer vision framework. We present two methods for approximating development: (1) structural area coverage estimated through a Mask R-CNN segmentation algorithm, and (2) imputing development directly with visible & infrared radiance from the Visible Infrared Imaging Radiometer Suite (VIIRS). Labels generated from these methods are comparatively evaluated and tested. On a dataset of 2,078 50 cm resolution images spanning 19 years, the results indicate that two dimensions of industrial development can be estimated using high-resolution daytime imagery, including (a) the total square meters of industrial development (average error of 0.021 $\textrm{km}^2$), and (b) the radiance of lights (average error of 9.8 $\mathrm{\frac{nW}{cm^{2}sr}}$). Trend analysis of the techniques reveal estimates from a Mask R-CNN-labeled CNN-LSTM track ground truth measurements most closely. The Mask R-CNN estimates positive growth at every site from the oldest image to the most recent, with an average change of 4,084 $\textrm{m}^2$.
Image quality prediction using synthetic and natural codebooks: comparative results
Dec 21, 2022
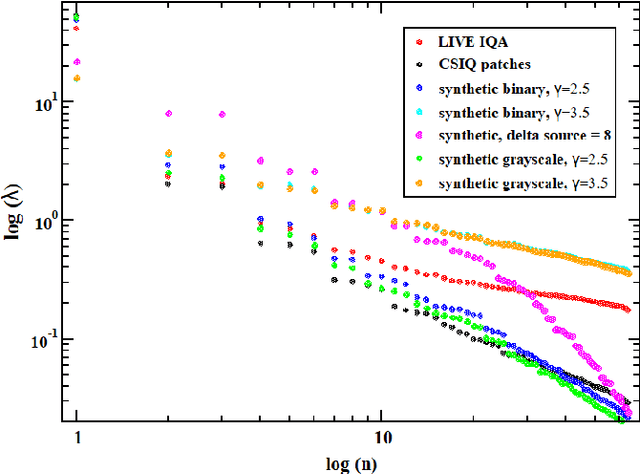
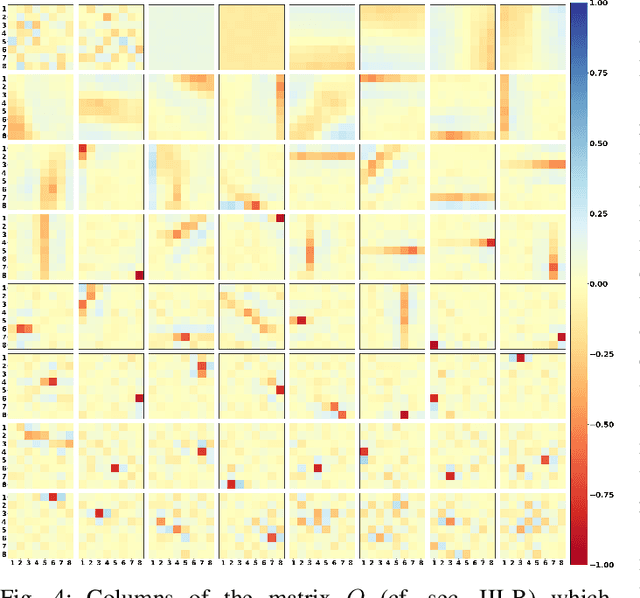
We investigate a model for image/video quality assessment based on building a set of codevectors representing in a sense some basic properties of images, similar to well-known CORNIA model. We analyze the codebook building method and propose some modifications for it. Also the algorithm is investigated from the point of inference time reduction. Both natural and synthetic images are used for building codebooks and some analysis of synthetic images used for codebooks is provided. It is demonstrated the results on quality assessment may be improves with the use if synthetic images for codebook construction. We also demonstrate regimes of the algorithm in which real time execution on CPU is possible for sufficiently high correlations with mean opinion score (MOS). Various pooling strategies are considered as well as the problem of metric sensitivity to bitrate.
Data Distillation: A Survey
Jan 11, 2023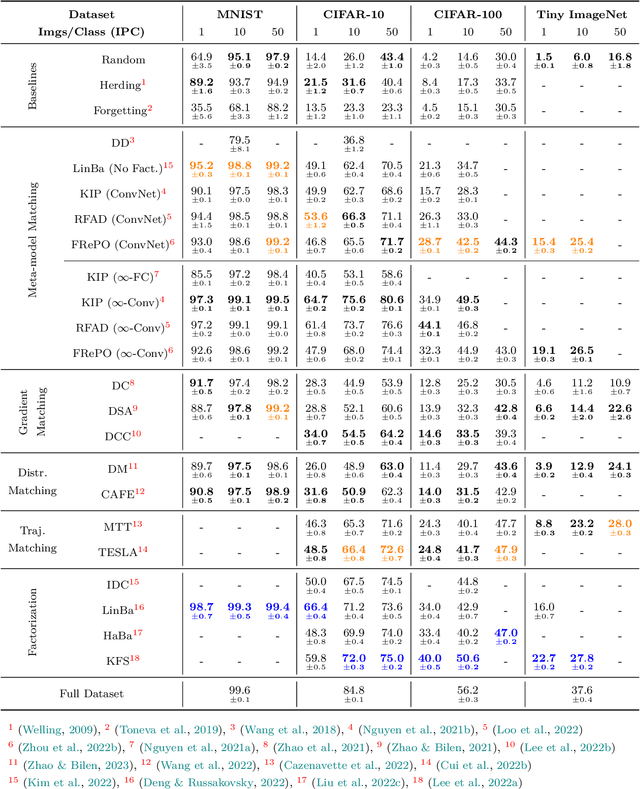
The popularity of deep learning has led to the curation of a vast number of massive and multifarious datasets. Despite having close-to-human performance on individual tasks, training parameter-hungry models on large datasets poses multi-faceted problems such as (a) high model-training time; (b) slow research iteration; and (c) poor eco-sustainability. As an alternative, data distillation approaches aim to synthesize terse data summaries, which can serve as effective drop-in replacements of the original dataset for scenarios like model training, inference, architecture search, etc. In this survey, we present a formal framework for data distillation, along with providing a detailed taxonomy of existing approaches. Additionally, we cover data distillation approaches for different data modalities, namely images, graphs, and user-item interactions (recommender systems), while also identifying current challenges and future research directions.
Deep Learning Based Object Tracking in Walking Droplet and Granular Intruder Experiments
Jan 27, 2023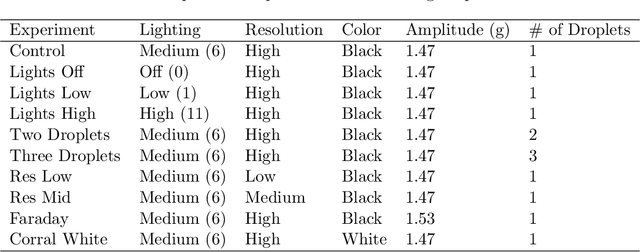
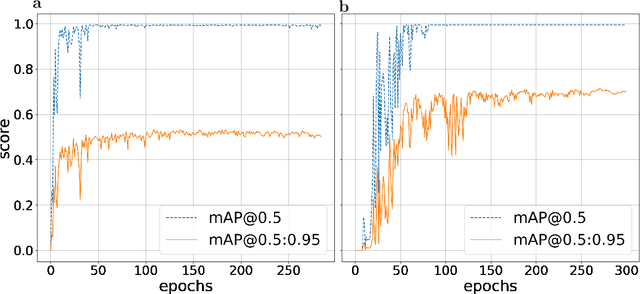


We present a deep-learning based tracking objects of interest in walking droplet and granular intruder experiments. In a typical walking droplet experiment, a liquid droplet, known as \textit{walker}, propels itself laterally on the free surface of a vibrating bath of the same liquid. This motion is the result of the interaction between the droplets and the surface waves generated by the droplet itself after each successive bounce. A walker can exhibit a highly irregular trajectory over the course of its motion, including rapid acceleration and complex interactions with the other walkers present in the same bath. In analogy with the hydrodynamic experiments, the granular matter experiments consist of a vibrating bath of very small solid particles and a larger solid \textit{intruder}. Like the fluid droplets, the intruder interacts with and travels the domain due to the waves of the bath but tends to move much slower and much less smoothly than the droplets. When multiple intruders are introduced, they also exhibit complex interactions with each other. We leverage the state-of-art object detection model YOLO and the Hungarian Algorithm to accurately extract the trajectory of a walker or intruder in real-time. Our proposed methodology is capable of tracking individual walker(s) or intruder(s) in digital images acquired from a broad spectrum of experimental settings and does not suffer from any identity-switch issues. Thus, the deep learning approach developed in this work could be used to automatize the efficient, fast and accurate extraction of observables of interests in walking droplet and granular flow experiments. Such extraction capabilities are critically enabling for downstream tasks such as building data-driven dynamical models for the coarse-grained dynamics and interactions of the objects of interest.
Fine-tuning Neural-Operator architectures for training and generalization
Jan 27, 2023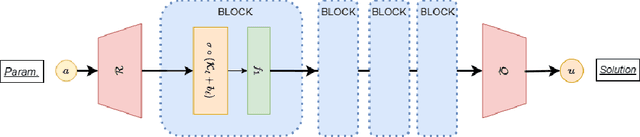

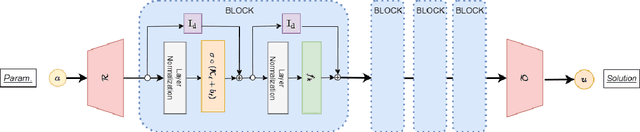
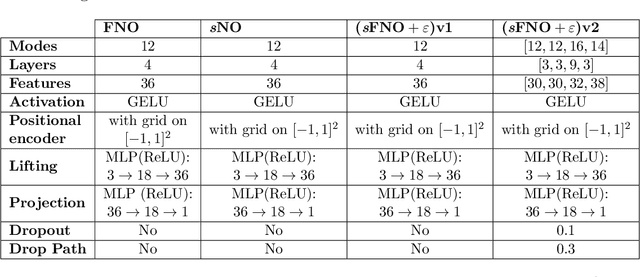
In this work, we present an analysis of the generalization of Neural Operators (NOs) and derived architectures. We proposed a family of networks, which we name (${\textit{s}}{\text{NO}}+\varepsilon$), where we modify the layout of NOs towards an architecture resembling a Transformer; mainly, we substitute the Attention module with the Integral Operator part of NOs. The resulting network preserves universality, has a better generalization to unseen data, and similar number of parameters as NOs. On the one hand, we study numerically the generalization by gradually transforming NOs into ${\textit{s}}{\text{NO}}+\varepsilon$ and verifying a reduction of the test loss considering a time-harmonic wave dataset with different frequencies. We perform the following changes in NOs: (a) we split the Integral Operator (non-local) and the (local) feed-forward network (MLP) into different layers, generating a {\it sequential} structure which we call sequential Neural Operator (${\textit{s}}{\text{NO}}$), (b) we add the skip connection, and layer normalization in ${\textit{s}}{\text{NO}}$, and (c) we incorporate dropout and stochastic depth that allows us to generate deep networks. In each case, we observe a decrease in the test loss in a wide variety of initialization, indicating that our changes outperform the NO. On the other hand, building on infinite-dimensional Statistics, and in particular the Dudley Theorem, we provide bounds of the Rademacher complexity of NOs and ${\textit{s}}{\text{NO}}$, and we find the following relationship: the upper bound of the Rademacher complexity of the ${\textit{s}}{\text{NO}}$ is a lower-bound of the NOs, thereby, the generalization error bound of ${\textit{s}}{\text{NO}}$ is smaller than NO, which further strengthens our numerical results.
A Faster $k$-means++ Algorithm
Nov 28, 2022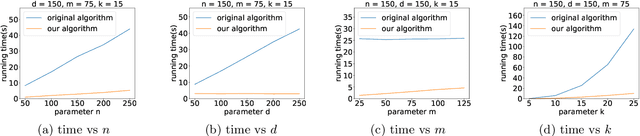
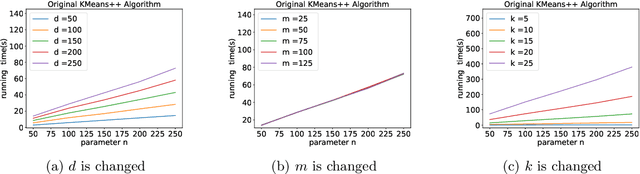
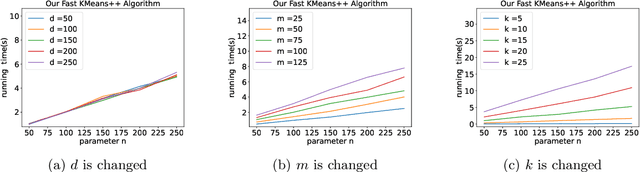
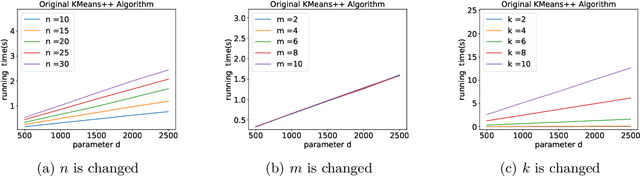
K-means++ is an important algorithm to choose initial cluster centers for the k-means clustering algorithm. In this work, we present a new algorithm that can solve the $k$-means++ problem with near optimal running time. Given $n$ data points in $\mathbb{R}^d$, the current state-of-the-art algorithm runs in $\widetilde{O}(k )$ iterations, and each iteration takes $\widetilde{O}(nd k)$ time. The overall running time is thus $\widetilde{O}(n d k^2)$. We propose a new algorithm \textsc{FastKmeans++} that only takes in $\widetilde{O}(nd + nk^2)$ time, in total.