 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Design and Control of Delta: Deformable Multilinked Multirotor with Rolling Locomotion Ability in Terrestrial Domain
Mar 11, 2024

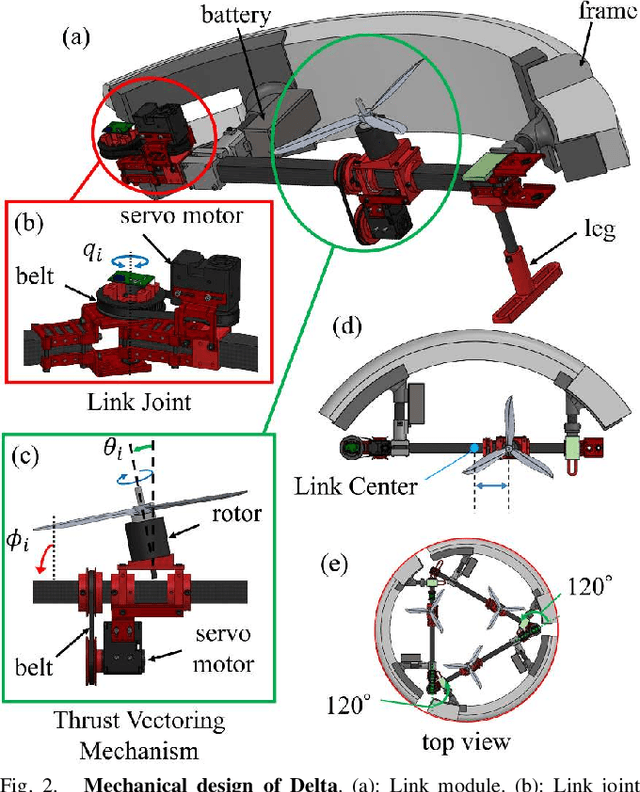
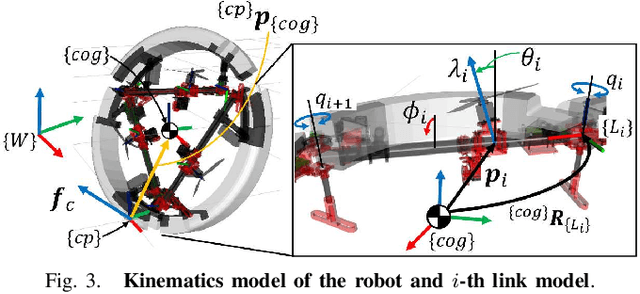
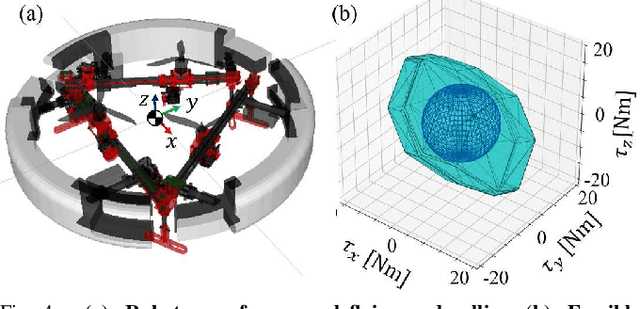
In recent years, multiple types of locomotion methods for robots have been developed and enabled to adapt to multiple domains. In particular, aerial robots are useful for exploration in several situations, taking advantage of its three-dimensional mobility. Moreover, some aerial robots have achieved manipulation tasks in the air. However, energy consumption for flight is large and thus locomotion ability on the ground is also necessary for aerial robots to do tasks for long time. Therefore, in this work, we aim to develop deformable multirotor robot capable of rolling movement with its entire body and achieve motions on the ground and in the air. In this paper, we first describe the design methodology of a deformable multilinked air-ground hybrid multirotor. We also introduce its mechanical design and rotor configuration based on control stability. Then, thrust control method for locomotion in air and ground domains is described. Finally, we show the implemented prototype of the proposed robot and evaluate through experiments in air and terrestrial domains. To the best of our knowledge, this is the first time to achieve the rolling locomotion by multilink structured mutltrotor.
Emergency Response Inference Mapping (ERIMap): A Bayesian Network-based Method for Dynamic Observation Processing in Spatially Distributed Emergencies
Mar 11, 2024

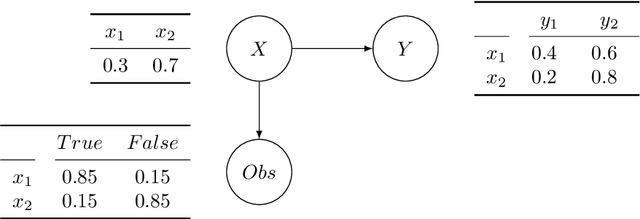

In emergencies, high stake decisions often have to be made under time pressure and strain. In order to support such decisions, information from various sources needs to be collected and processed rapidly. The information available tends to be temporally and spatially variable, uncertain, and sometimes conflicting, leading to potential biases in decisions. Currently, there is a lack of systematic approaches for information processing and situation assessment which meet the particular demands of emergency situations. To address this gap, we present a Bayesian network-based method called ERIMap that is tailored to the complex information-scape during emergencies. The method enables the systematic and rapid processing of heterogeneous and potentially uncertain observations and draws inferences about key variables of an emergency. It thereby reduces complexity and cognitive load for decision makers. The output of the ERIMap method is a dynamically evolving and spatially resolved map of beliefs about key variables of an emergency that is updated each time a new observation becomes available. The method is illustrated in a case study in which an emergency response is triggered by an accident causing a gas leakage on a chemical plant site.
Reconstructing Blood Flow in Data-Poor Regimes: A Vasculature Network Kernel for Gaussian Process Regression
Mar 14, 2024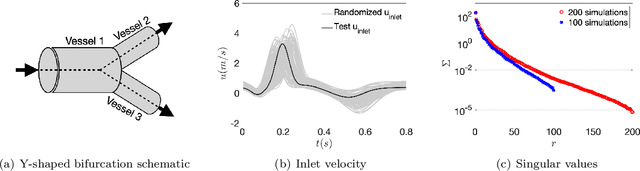
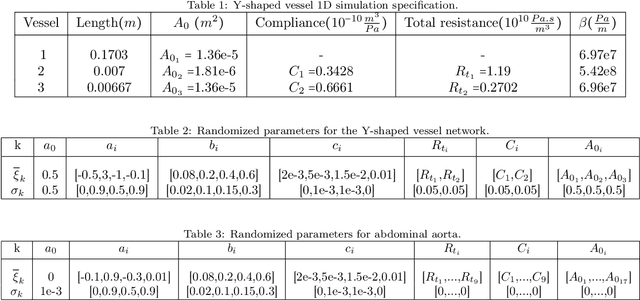
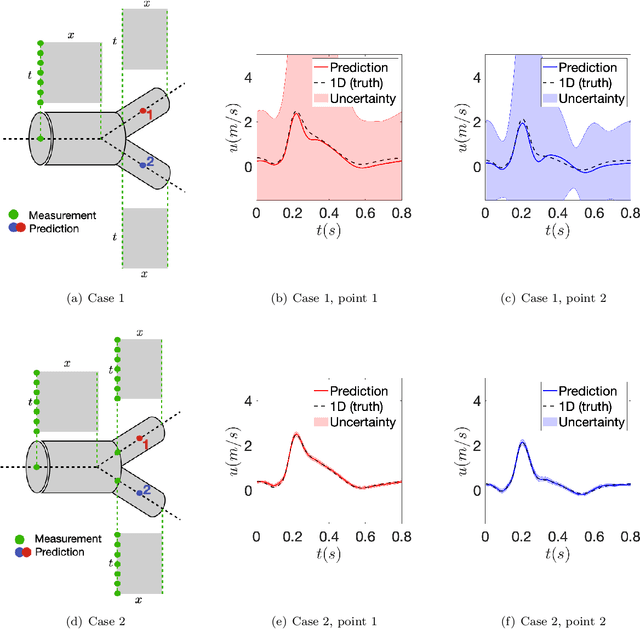
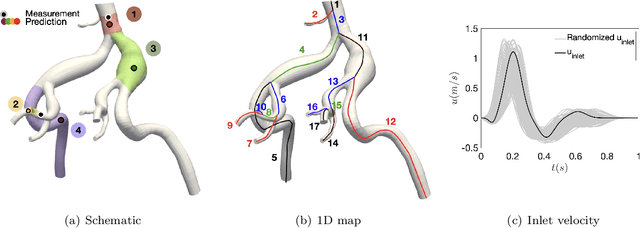
Blood flow reconstruction in the vasculature is important for many clinical applications. However, in clinical settings, the available data are often quite limited. For instance, Transcranial Doppler ultrasound (TCD) is a noninvasive clinical tool that is commonly used in the clinical settings to measure blood velocity waveform at several locations on brain's vasculature. This amount of data is grossly insufficient for training machine learning surrogate models, such as deep neural networks or Gaussian process regression. In this work, we propose a Gaussian process regression approach based on physics-informed kernels, enabling near-real-time reconstruction of blood flow in data-poor regimes. We introduce a novel methodology to reconstruct the kernel within the vascular network, which is a non-Euclidean space. The proposed kernel encodes both spatiotemporal and vessel-to-vessel correlations, thus enabling blood flow reconstruction in vessels that lack direct measurements. We demonstrate that any prediction made with the proposed kernel satisfies the conservation of mass principle. The kernel is constructed by running stochastic one-dimensional blood flow simulations, where the stochasticity captures the epistemic uncertainties, such as lack of knowledge about boundary conditions and uncertainties in vasculature geometries. We demonstrate the performance of the model on three test cases, namely, a simple Y-shaped bifurcation, abdominal aorta, and the Circle of Willis in the brain.
VIRUS-NeRF -- Vision, InfraRed and UltraSonic based Neural Radiance Fields
Mar 14, 2024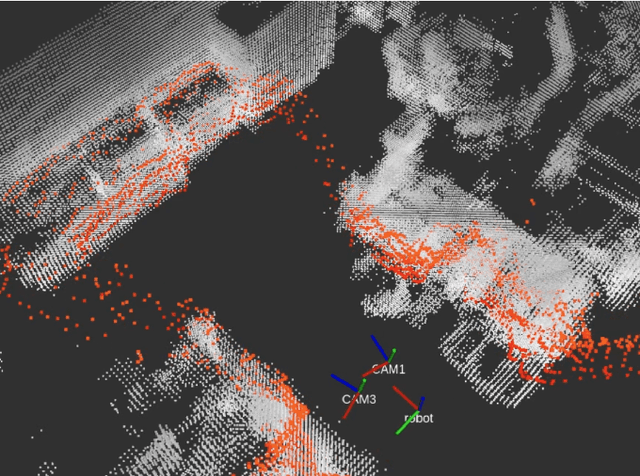

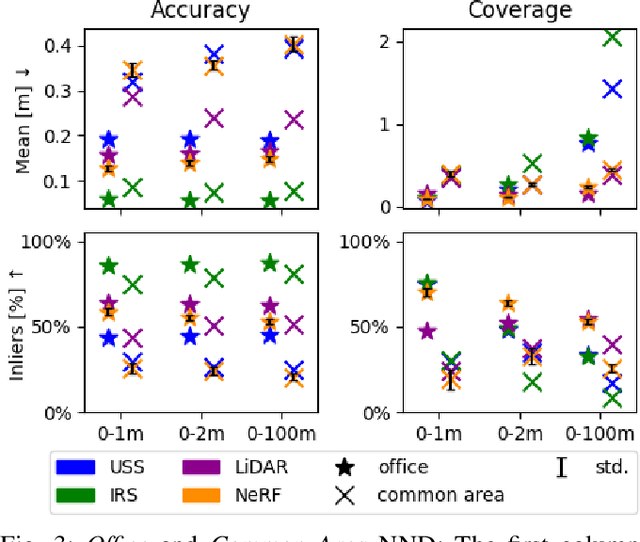
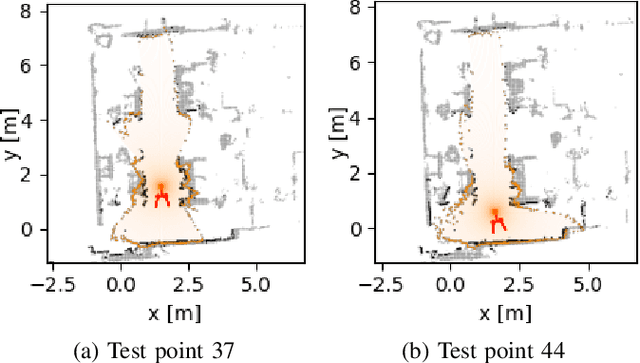
Autonomous mobile robots are an increasingly integral part of modern factory and warehouse operations. Obstacle detection, avoidance and path planning are critical safety-relevant tasks, which are often solved using expensive LiDAR sensors and depth cameras. We propose to use cost-effective low-resolution ranging sensors, such as ultrasonic and infrared time-of-flight sensors by developing VIRUS-NeRF - Vision, InfraRed, and UltraSonic based Neural Radiance Fields. Building upon Instant Neural Graphics Primitives with a Multiresolution Hash Encoding (Instant-NGP), VIRUS-NeRF incorporates depth measurements from ultrasonic and infrared sensors and utilizes them to update the occupancy grid used for ray marching. Experimental evaluation in 2D demonstrates that VIRUS-NeRF achieves comparable mapping performance to LiDAR point clouds regarding coverage. Notably, in small environments, its accuracy aligns with that of LiDAR measurements, while in larger ones, it is bounded by the utilized ultrasonic sensors. An in-depth ablation study reveals that adding ultrasonic and infrared sensors is highly effective when dealing with sparse data and low view variation. Further, the proposed occupancy grid of VIRUS-NeRF improves the mapping capabilities and increases the training speed by 46% compared to Instant-NGP. Overall, VIRUS-NeRF presents a promising approach for cost-effective local mapping in mobile robotics, with potential applications in safety and navigation tasks. The code can be found at https://github.com/ethz-asl/virus nerf.
SAM-Lightening: A Lightweight Segment Anything Model with Dilated Flash Attention to Achieve 30 times Acceleration
Mar 14, 2024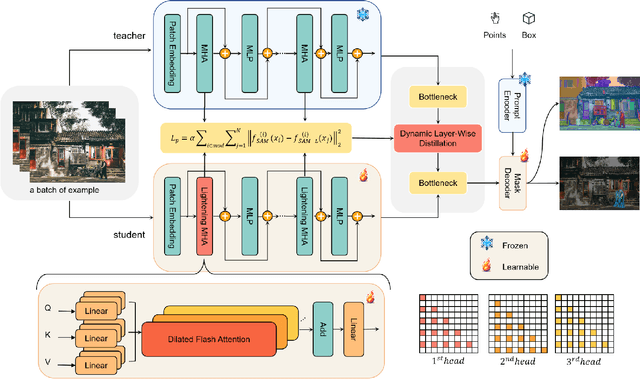
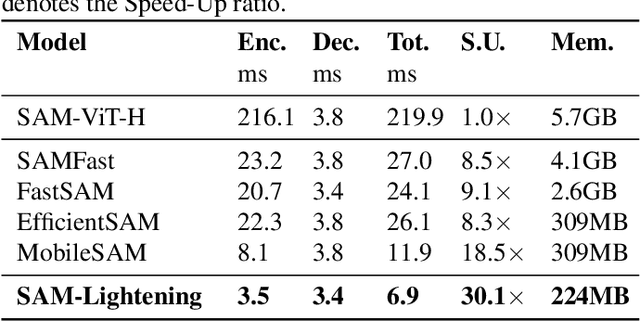

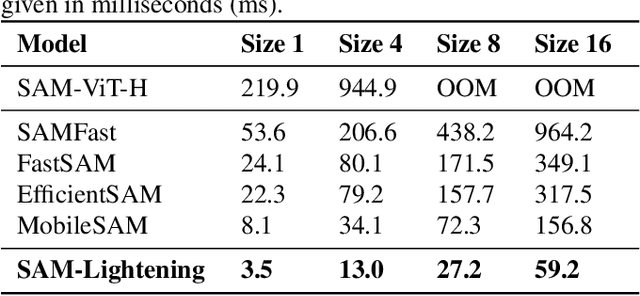
Segment Anything Model (SAM) has garnered significant attention in segmentation tasks due to their zero-shot generalization ability. However, a broader application of SAMs to real-world practice has been restricted by their low inference speed and high computational memory demands, which mainly stem from the attention mechanism. Existing work concentrated on optimizing the encoder, yet has not adequately addressed the inefficiency of the attention mechanism itself, even when distilled to a smaller model, which thus leaves space for further improvement. In response, we introduce SAM-Lightening, a variant of SAM, that features a re-engineered attention mechanism, termed Dilated Flash Attention. It not only facilitates higher parallelism, enhancing processing efficiency but also retains compatibility with the existing FlashAttention. Correspondingly, we propose a progressive distillation to enable an efficient knowledge transfer from the vanilla SAM without costly training from scratch. Experiments on COCO and LVIS reveal that SAM-Lightening significantly outperforms the state-of-the-art methods in both run-time efficiency and segmentation accuracy. Specifically, it can achieve an inference speed of 7 milliseconds (ms) per image, for images of size 1024*1024 pixels, which is 30.1 times faster than the vanilla SAM and 2.1 times than the state-of-the-art. Moreover, it takes only 244MB memory, which is 3.5\% of the vanilla SAM. The code and weights are available at https://anonymous.4open.science/r/SAM-LIGHTENING-BC25/.
Visual Decoding and Reconstruction via EEG Embeddings with Guided Diffusion
Mar 14, 2024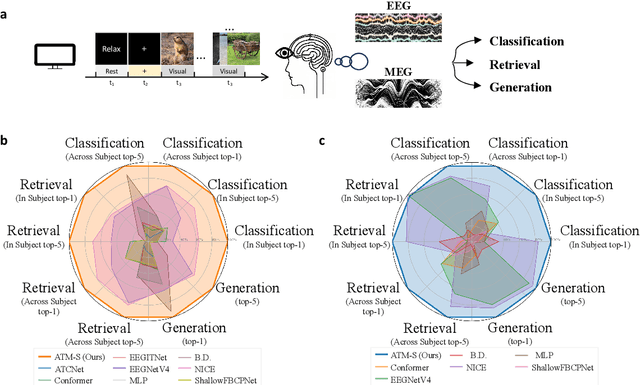
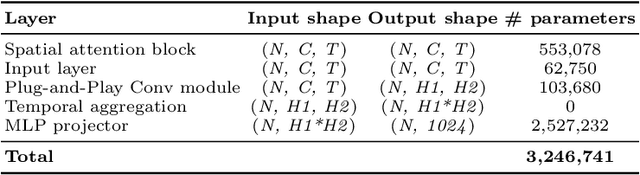
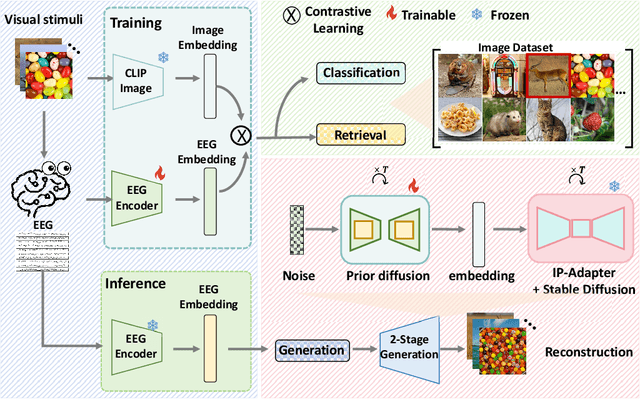

How to decode human vision through neural signals has attracted a long-standing interest in neuroscience and machine learning. Modern contrastive learning and generative models improved the performance of fMRI-based visual decoding and reconstruction. However, the high cost and low temporal resolution of fMRI limit their applications in brain-computer interfaces (BCIs), prompting a high need for EEG-based visual reconstruction. In this study, we present an EEG-based visual reconstruction framework. It consists of a plug-and-play EEG encoder called the Adaptive Thinking Mapper (ATM), which is aligned with image embeddings, and a two-stage EEG guidance image generator that first transforms EEG features into image priors and then reconstructs the visual stimuli with a pre-trained image generator. Our approach allows EEG embeddings to achieve superior performance in image classification and retrieval tasks. Our two-stage image generation strategy vividly reconstructs images seen by humans. Furthermore, we analyzed the impact of signals from different time windows and brain regions on decoding and reconstruction. The versatility of our framework is demonstrated in the magnetoencephalogram (MEG) data modality. We report that EEG-based visual decoding achieves SOTA performance, highlighting the portability, low cost, and high temporal resolution of EEG, enabling a wide range of BCI applications. The code of ATM is available at https://github.com/dongyangli-del/EEG_Image_decode.
Leveraging Constraint Programming in a Deep Learning Approach for Dynamically Solving the Flexible Job-Shop Scheduling Problem
Mar 14, 2024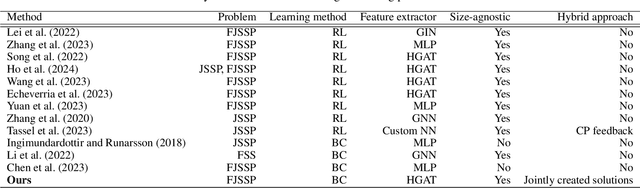
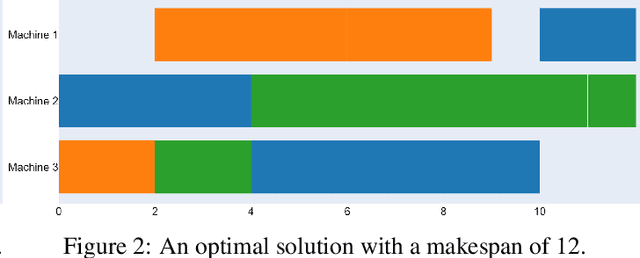
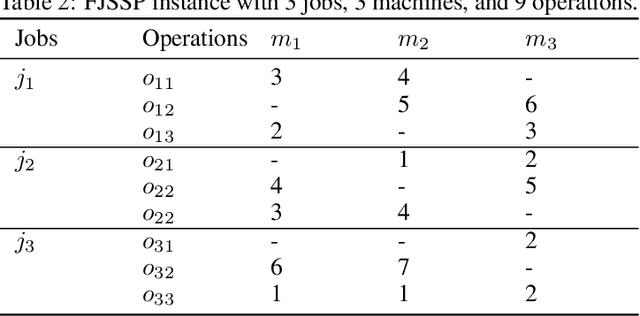
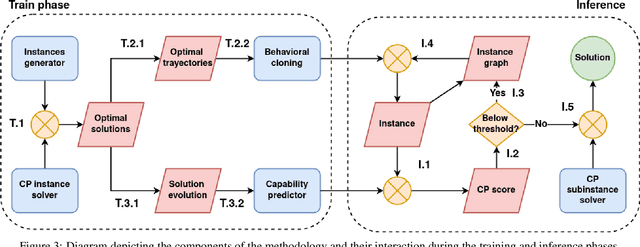
Recent advancements in the flexible job-shop scheduling problem (FJSSP) are primarily based on deep reinforcement learning (DRL) due to its ability to generate high-quality, real-time solutions. However, DRL approaches often fail to fully harness the strengths of existing techniques such as exact methods or constraint programming (CP), which can excel at finding optimal or near-optimal solutions for smaller instances. This paper aims to integrate CP within a deep learning (DL) based methodology, leveraging the benefits of both. In this paper, we introduce a method that involves training a DL model using optimal solutions generated by CP, ensuring the model learns from high-quality data, thereby eliminating the need for the extensive exploration typical in DRL and enhancing overall performance. Further, we integrate CP into our DL framework to jointly construct solutions, utilizing DL for the initial complex stages and transitioning to CP for optimal resolution as the problem is simplified. Our hybrid approach has been extensively tested on three public FJSSP benchmarks, demonstrating superior performance over five state-of-the-art DRL approaches and a widely-used CP solver. Additionally, with the objective of exploring the application to other combinatorial optimization problems, promising preliminary results are presented on applying our hybrid approach to the traveling salesman problem, combining an exact method with a well-known DRL method.
Real-Time FPGA Demonstrator of ANN-Based Equalization for Optical Communications
Feb 23, 2024In this work, we present a high-throughput field programmable gate array (FPGA) demonstrator of an artificial neural network (ANN)-based equalizer. The equalization is performed and illustrated in real-time for a 30 GBd, two-level pulse amplitude modulation (PAM2) optical communication system.
Nonlinear Manifold Learning Determines Microgel Size from Raman Spectroscopy
Mar 13, 2024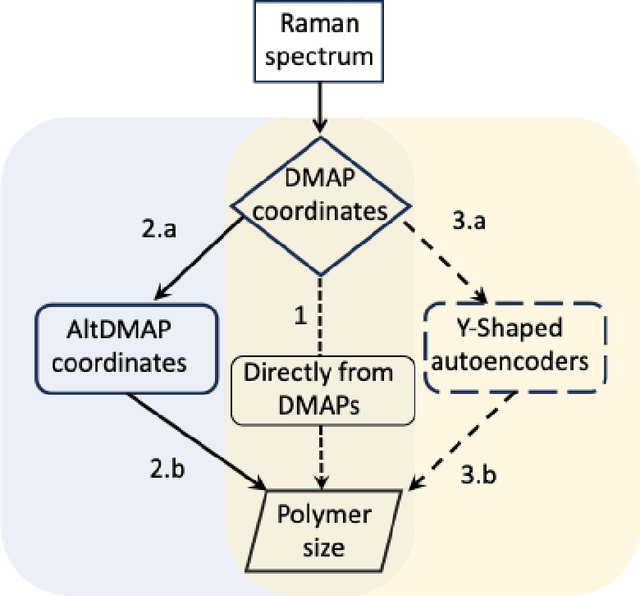
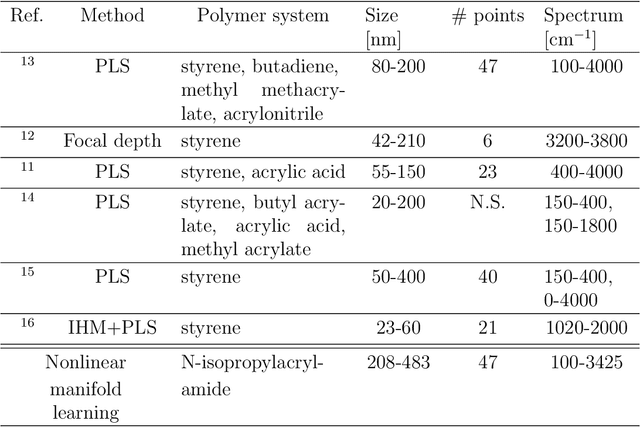
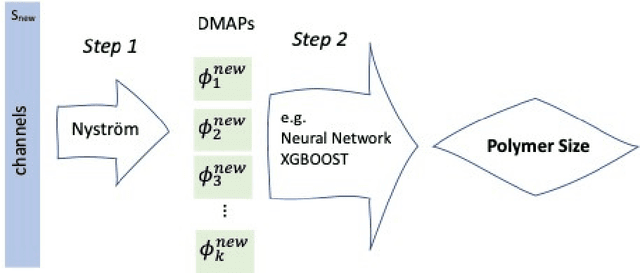
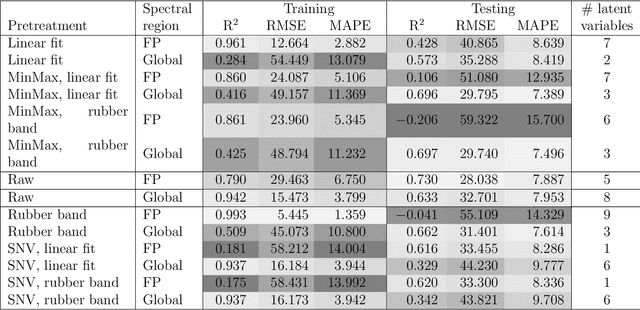
Polymer particle size constitutes a crucial characteristic of product quality in polymerization. Raman spectroscopy is an established and reliable process analytical technology for in-line concentration monitoring. Recent approaches and some theoretical considerations show a correlation between Raman signals and particle sizes but do not determine polymer size from Raman spectroscopic measurements accurately and reliably. With this in mind, we propose three alternative machine learning workflows to perform this task, all involving diffusion maps, a nonlinear manifold learning technique for dimensionality reduction: (i) directly from diffusion maps, (ii) alternating diffusion maps, and (iii) conformal autoencoder neural networks. We apply the workflows to a data set of Raman spectra with associated size measured via dynamic light scattering of 47 microgel (cross-linked polymer) samples in a diameter range of 208nm to 483 nm. The conformal autoencoders substantially outperform state-of-the-art methods and results for the first time in a promising prediction of polymer size from Raman spectra.
Unsupervised Learning of Hybrid Latent Dynamics: A Learn-to-Identify Framework
Mar 13, 2024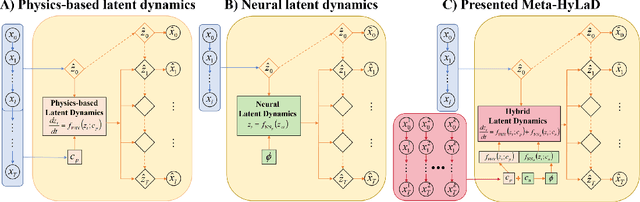
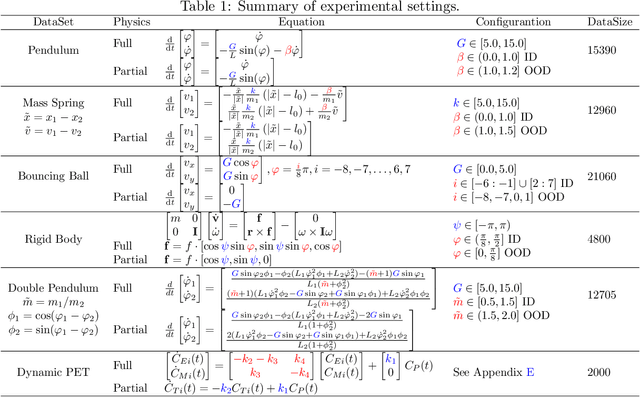
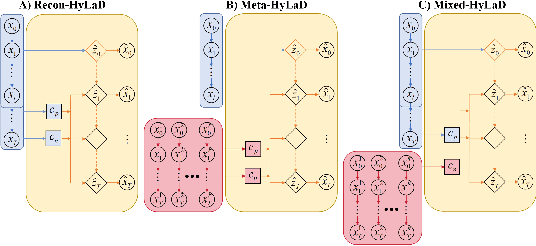

Modern applications increasingly require unsupervised learning of latent dynamics from high-dimensional time-series. This presents a significant challenge of identifiability: many abstract latent representations may reconstruct observations, yet do they guarantee an adequate identification of the governing dynamics? This paper investigates this challenge from two angles: the use of physics inductive bias specific to the data being modeled, and a learn-to-identify strategy that separates forecasting objectives from the data used for the identification. We combine these two strategies in a novel framework for unsupervised meta-learning of hybrid latent dynamics (Meta-HyLaD) with: 1) a latent dynamic function that hybridize known mathematical expressions of prior physics with neural functions describing its unknown errors, and 2) a meta-learning formulation to learn to separately identify both components of the hybrid dynamics. Through extensive experiments on five physics and one biomedical systems, we provide strong evidence for the benefits of Meta-HyLaD to integrate rich prior knowledge while identifying their gap to observed data.