 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enhancing Deep Traffic Forecasting Models with Dynamic Regression
Jan 17, 2023
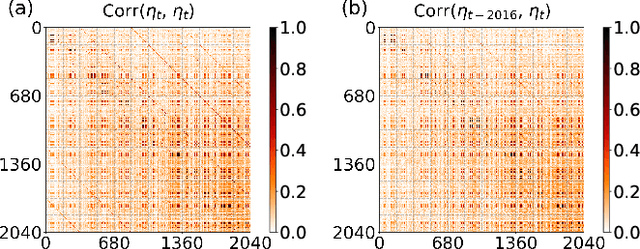
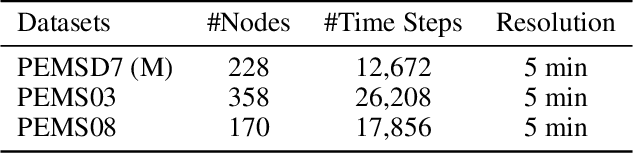
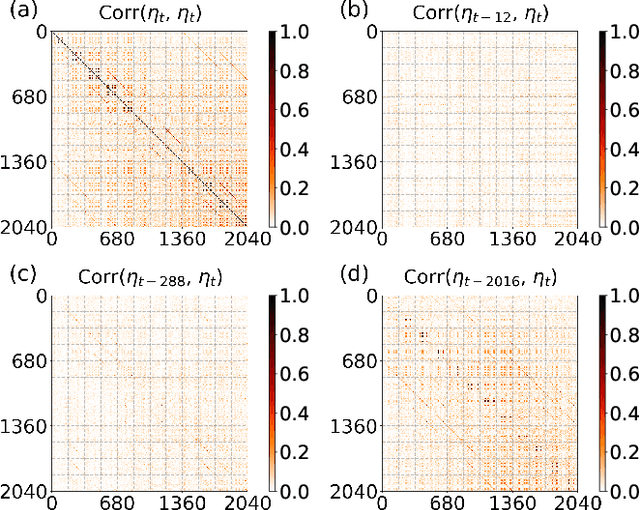
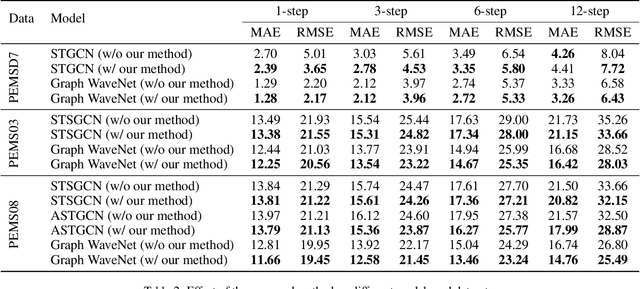
A common assumption in deep learning-based multivariate and multistep traffic time series forecasting models is that residuals are independent, isotropic, and uncorrelated in space and time. While this assumption provides a straightforward loss function (such as MAE/MSE), it is inevitable that residual processes will exhibit strong autocorrelation and structured spatiotemporal correlation. In this paper, we propose a complementary dynamic regression (DR) framework to enhance existing deep multistep traffic forecasting frameworks through structured specifications and learning for the residual process. Specifically, we assume the residuals of the base model (i.e., a well-developed traffic forecasting model) are governed by a matrix-variate seasonal autoregressive (AR) model, which can be seamlessly integrated into the training process by redesigning the overall loss function. Parameters in the DR framework can be jointly learned with the base model. We evaluate the effectiveness of the proposed framework in enhancing several state-of-the-art deep traffic forecasting models on both speed and flow datasets. Our experiment results show that the DR framework not only improves existing traffic forecasting models but also offers interpretable regression coefficients and spatiotemporal covariance matrices.
Calculating lexicase selection probabilities is NP-Hard
Jan 17, 2023Calculating the probability of an individual solution being selected under lexicase selection is an important problem in attempts to develop a deeper theoretical understanding of lexicase selection, a state-of-the art parent selection algorithm in evolutionary computation. Discovering a fast solution to this problem would also have implications for efforts to develop practical improvements to lexicase selection. Here, I prove that this problem, which I name lex-prob, is NP-Hard. I achieve this proof by reducing SAT, a well-known NP-Complete problem, to lex-prob in polynomial time. This reduction involves an intermediate step in which a popular variant of lexicase selection, epsilon-lexicase selection, is reduced to standard lexicase selection. This proof has important practical implications for anyone needing a fast way of calculating the probabilities of individual solutions being selected under lexicase selection. Doing so in polynomial time would be incredibly challenging, if not all-together impossible. Thus, finding approximation algorithms or practical optimizations for speeding up the brute-force solution is likely more worthwhile. This result also has deeper theoretical implications about the relationship between epsilon-lexicase selection and lexicase selection and the relationship between lex-prob and other NP-Hard problems.
A Continuous Time Framework for Discrete Denoising Models
May 30, 2022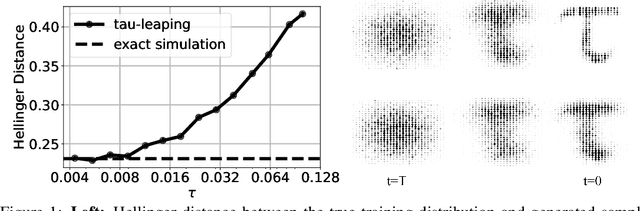
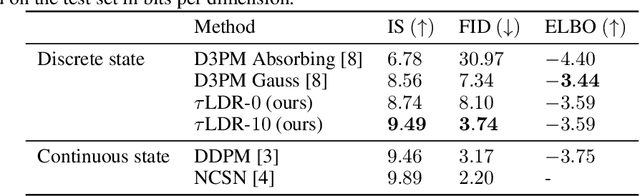


We provide the first complete continuous time framework for denoising diffusion models of discrete data. This is achieved by formulating the forward noising process and corresponding reverse time generative process as Continuous Time Markov Chains (CTMCs). The model can be efficiently trained using a continuous time version of the ELBO. We simulate the high dimensional CTMC using techniques developed in chemical physics and exploit our continuous time framework to derive high performance samplers that we show can outperform discrete time methods for discrete data. The continuous time treatment also enables us to derive a novel theoretical result bounding the error between the generated sample distribution and the true data distribution.
A data science and machine learning approach to continuous analysis of Shakespeare's plays
Jan 15, 2023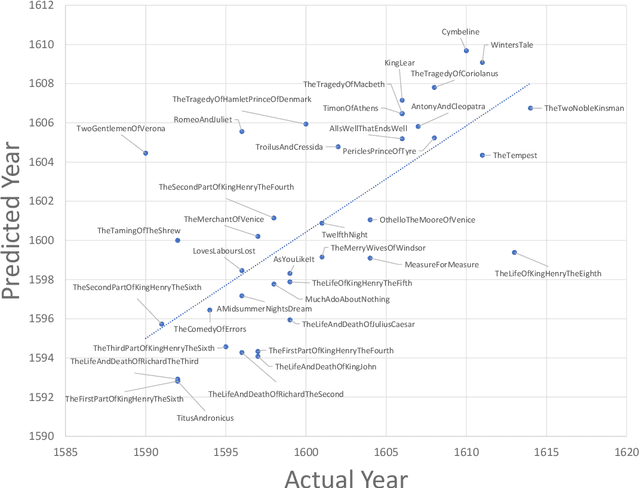
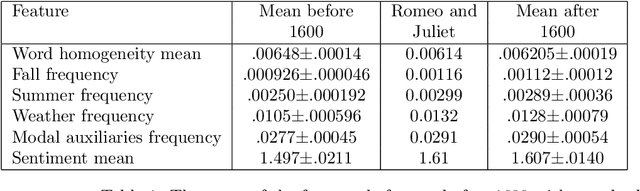
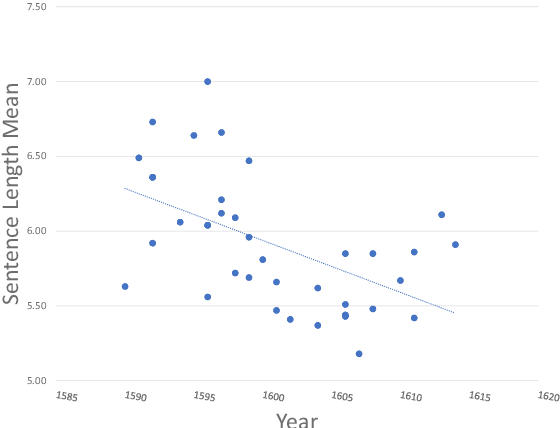
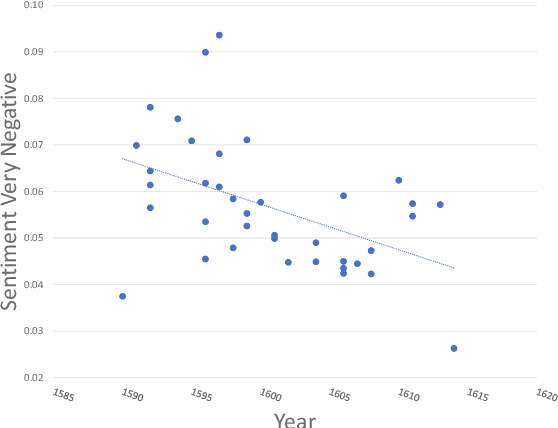
The availability of quantitative methods that can analyze text has provided new ways of examining literature in a manner that was not available in the pre-information era. Here we apply comprehensive machine learning analysis to the work of William Shakespeare. The analysis shows clear change in style of writing over time, with the most significant changes in the sentence length, frequency of adjectives and adverbs, and the sentiments expressed in the text. Applying machine learning to make a stylometric prediction of the year of the play shows a Pearson correlation of 0.71 between the actual and predicted year, indicating that Shakespeare's writing style as reflected by the quantitative measurements changed over time. Additionally, it shows that the stylometrics of some of the plays is more similar to plays written either before or after the year they were written. For instance, Romeo and Juliet is dated 1596, but is more similar in stylometrics to plays written by Shakespeare after 1600. The source code for the analysis is available for free download.
BoW3D: Bag of Words for Real-time Loop Closing in 3D LiDAR SLAM
Aug 15, 2022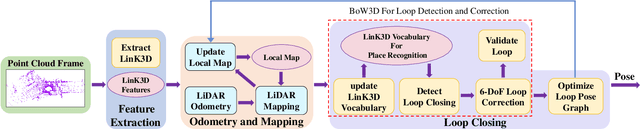
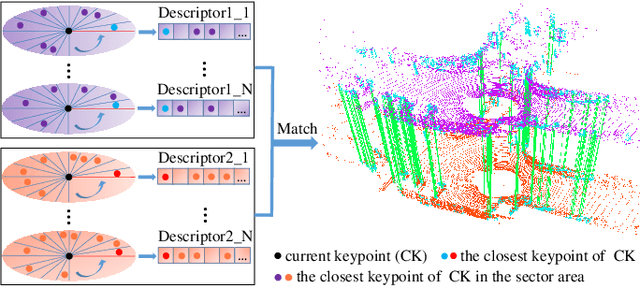
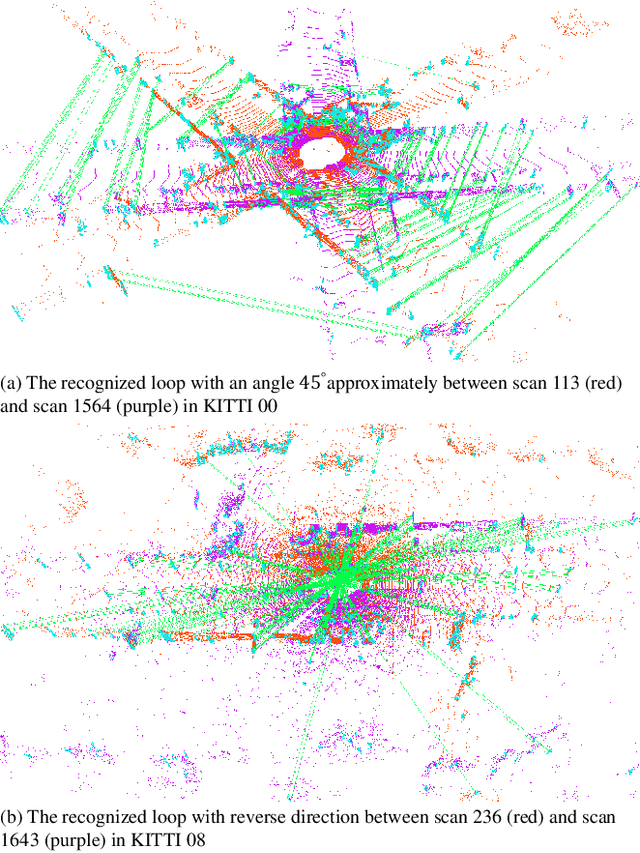
Loop closing is a fundamental part of simultaneous localization and mapping (SLAM) for autonomous mobile systems. In the field of visual SLAM, bag of words (BoW) has achieved great success in loop closure. The BoW features for loop searching can also be used in the subsequent 6-DoF loop correction. However, for 3D LiDAR SLAM, the state-of-the-art methods may fail to effectively recognize the loop in real time, and usually cannot correct the full 6-DoF loop pose. To address this limitation, we present a novel Bag of Words for real-time loop closing in 3D LiDAR SLAM, called BoW3D. The novelty of our method lies in that it not only efficiently recognize the revisited loop places, but also correct the full 6-DoF loop pose in real time. BoW3D builds the bag of words based on the 3D feature LinK3D, which is efficient, pose-invariant and can be used for accurate point-to-point matching. We furthermore embed our proposed method into 3D LiDAR odometry system to evaluate loop closing performance. We test our method on public dataset, and compare it against other state-of-the-art algorithms. BoW3D shows better performance in terms of F1 max and extended precision scores in most scenarios with superior real-time performance. It is noticeable that BoW3D takes an average of 50 ms to recognize and correct the loops in KITTI 00 (includes 4K+ 64-ray LiDAR scans), when executed on a notebook with an Intel Core i7 @2.2 GHz processor.
From Zero-Shot to Few-Shot Learning: A Step of Embedding-Aware Generative Models
Feb 09, 2023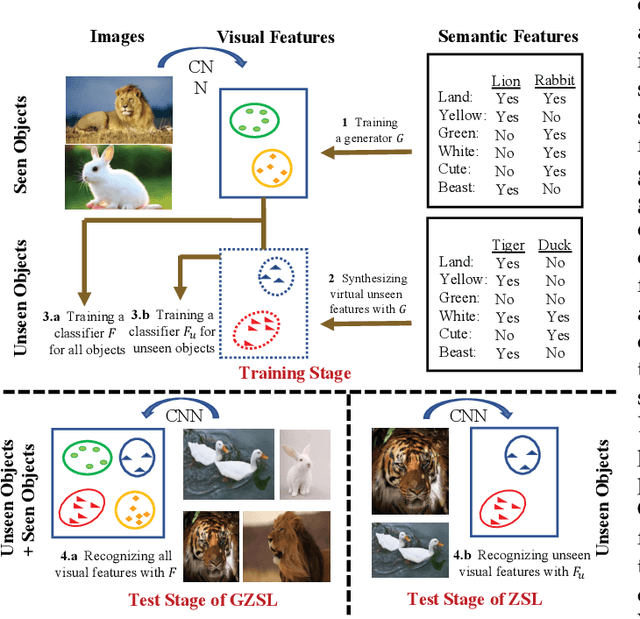
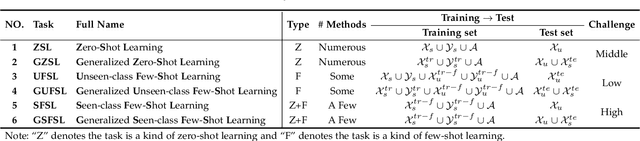
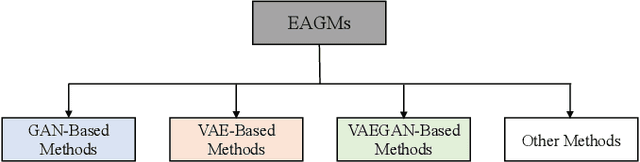

Embedding-aware generative model (EAGM) addresses the data insufficiency problem for zero-shot learning (ZSL) by constructing a generator between semantic and visual embedding spaces. Thanks to the predefined benchmark and protocols, the number of proposed EAGMs for ZSL is increasing rapidly. We argue that it is time to take a step back and reconsider the embedding-aware generative paradigm. The purpose of this paper is three-fold. First, given the fact that the current embedding features in benchmark datasets are somehow out-of-date, we improve the performance of EAGMs for ZSL remarkably with embarrassedly simple modifications on the embedding features. This is an important contribution, since the results reveal that the embedding of EAGMs deserves more attention. Second, we compare and analyze a significant number of EAGMs in depth. Based on five benchmark datasets, we update the state-of-the-art results for ZSL and give a strong baseline for few-shot learning (FSL), including the classic unseen-class few-shot learning (UFSL) and the more challenging seen-class few-shot learning (SFSL). Finally, a comprehensive generative model repository, namely, generative any-shot learning (GASL) repository, is provided, which contains the models, features, parameters, and settings of EAGMs for ZSL and FSL. Any results in this paper can be readily reproduced with only one command line based on GASL.
Improved Batching Strategy For Irregular Time-Series ODE
Jul 12, 2022
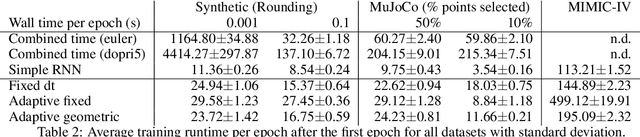
Irregular time series data are prevalent in the real world and are challenging to model with a simple recurrent neural network (RNN). Hence, a model that combines the use of ordinary differential equations (ODE) and RNN was proposed (ODE-RNN) to model irregular time series with higher accuracy, but it suffers from high computational costs. In this paper, we propose an improvement in the runtime on ODE-RNNs by using a different efficient batching strategy. Our experiments show that the new models reduce the runtime of ODE-RNN significantly ranging from 2 times up to 49 times depending on the irregularity of the data while maintaining comparable accuracy. Hence, our model can scale favorably for modeling larger irregular data sets.
Consistency is Key: Disentangling Label Variation in Natural Language Processing with Intra-Annotator Agreement
Jan 25, 2023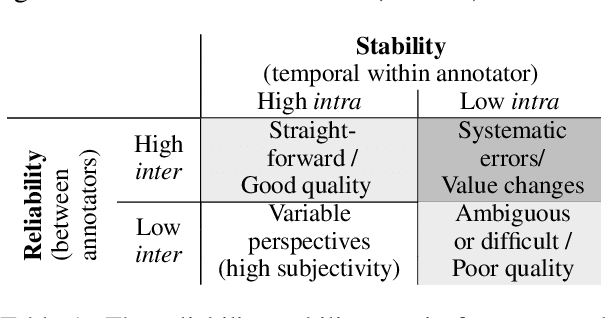

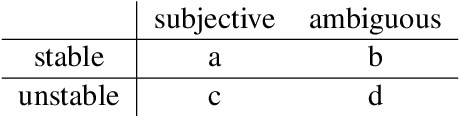
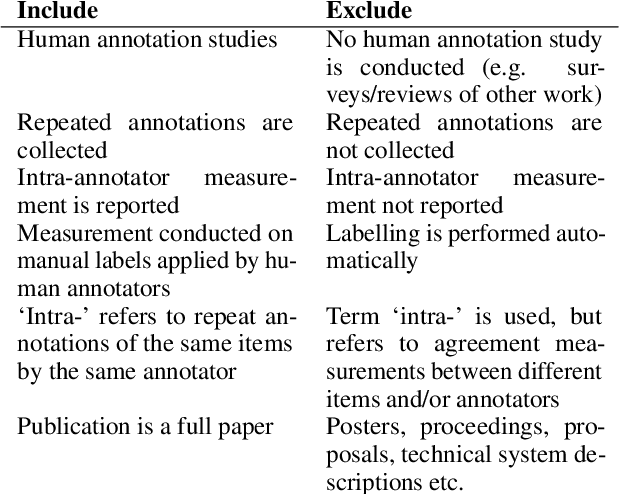
We commonly use agreement measures to assess the utility of judgements made by human annotators in Natural Language Processing (NLP) tasks. While inter-annotator agreement is frequently used as an indication of label reliability by measuring consistency between annotators, we argue for the additional use of intra-annotator agreement to measure label stability over time. However, in a systematic review, we find that the latter is rarely reported in this field. Calculating these measures can act as important quality control and provide insights into why annotators disagree. We propose exploratory annotation experiments to investigate the relationships between these measures and perceptions of subjectivity and ambiguity in text items.
Open Problem: Properly learning decision trees in polynomial time?
Jun 29, 2022
The authors recently gave an $n^{O(\log\log n)}$ time membership query algorithm for properly learning decision trees under the uniform distribution (Blanc et al., 2021). The previous fastest algorithm for this problem ran in $n^{O(\log n)}$ time, a consequence of Ehrenfeucht and Haussler (1989)'s classic algorithm for the distribution-free setting. In this article we highlight the natural open problem of obtaining a polynomial-time algorithm, discuss possible avenues towards obtaining it, and state intermediate milestones that we believe are of independent interest.
Towards cumulative race time regression in sports: I3D ConvNet transfer learning in ultra-distance running events
Aug 23, 2022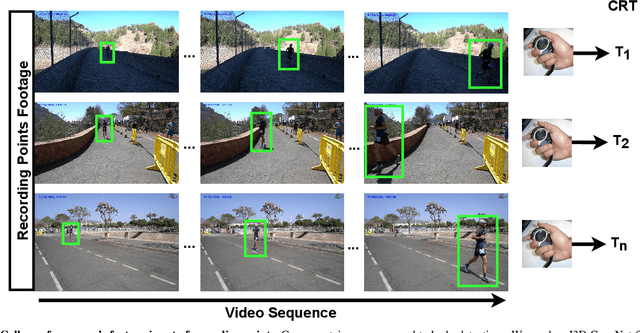


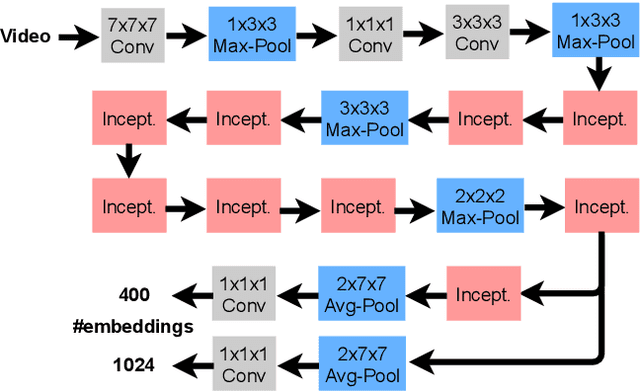
Predicting an athlete's performance based on short footage is highly challenging. Performance prediction requires high domain knowledge and enough evidence to infer an appropriate quality assessment. Sports pundits can often infer this kind of information in real-time. In this paper, we propose regressing an ultra-distance runner cumulative race time (CRT), i.e., the time the runner has been in action since the race start, by using only a few seconds of footage as input. We modified the I3D ConvNet backbone slightly and trained a newly added regressor for that purpose. We use appropriate pre-processing of the visual input to enable transfer learning from a specific runner. We show that the resulting neural network can provide a remarkable performance for short input footage: 18 minutes and a half mean absolute error in estimating the CRT for runners who have been in action from 8 to 20 hours. Our methodology has several favorable properties: it does not require a human expert to provide any insight, it can be used at any moment during the race by just observing a runner, and it can inform the race staff about a runner at any given time.