 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automatic Intrinsic Reward Shaping for Exploration in Deep Reinforcement Learning
Jan 26, 2023
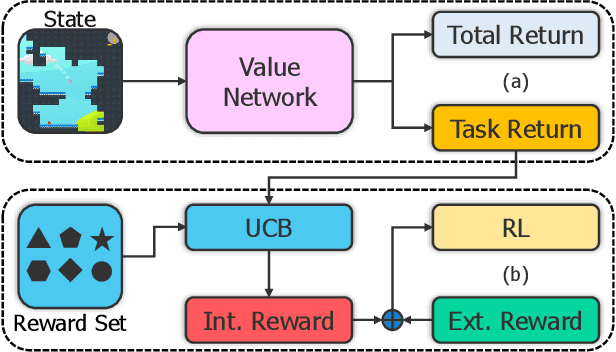

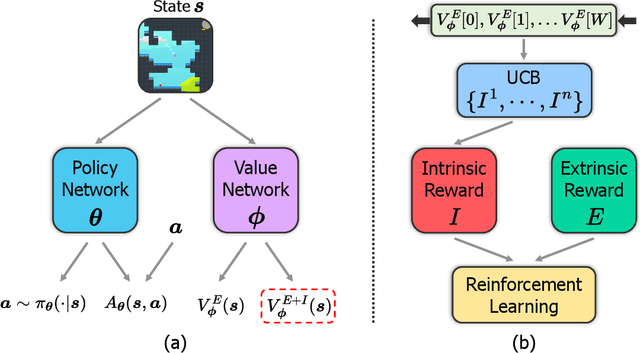
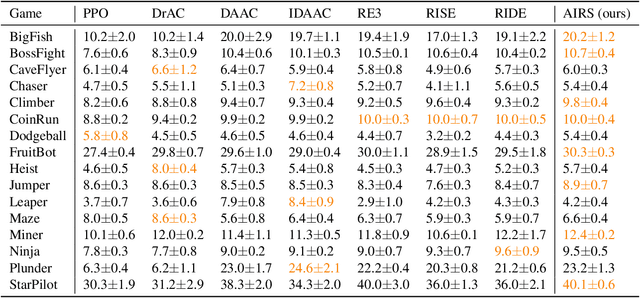
We present AIRS: Automatic Intrinsic Reward Shaping that intelligently and adaptively provides high-quality intrinsic rewards to enhance exploration in reinforcement learning (RL). More specifically, AIRS selects shaping function from a predefined set based on the estimated task return in real-time, providing reliable exploration incentives and alleviating the biased objective problem. Moreover, we develop an intrinsic reward toolkit to provide efficient and reliable implementations of diverse intrinsic reward approaches. We test AIRS on various tasks of Procgen games and DeepMind Control Suite. Extensive simulation demonstrates that AIRS can outperform the benchmarking schemes and achieve superior performance with simple architecture.
Concrete Safety for ML Problems: System Safety for ML Development and Assessment
Feb 06, 2023
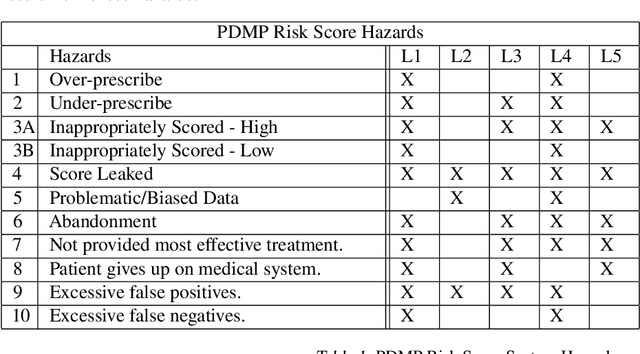
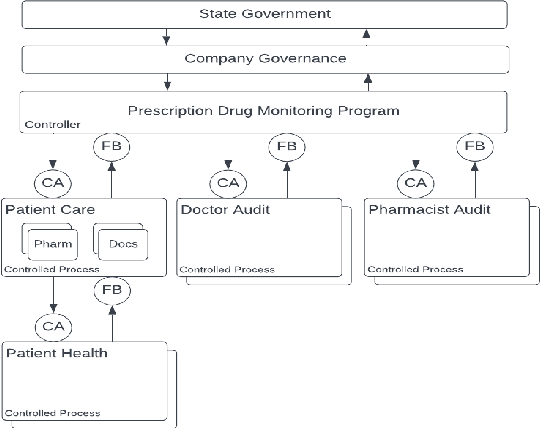
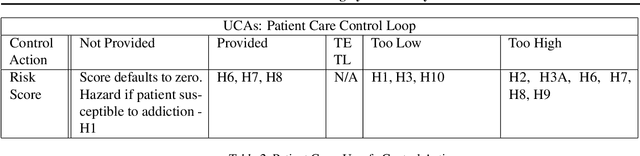
Many stakeholders struggle to make reliances on ML-driven systems due to the risk of harm these systems may cause. Concerns of trustworthiness, unintended social harms, and unacceptable social and ethical violations undermine the promise of ML advancements. Moreover, such risks in complex ML-driven systems present a special challenge as they are often difficult to foresee, arising over periods of time, across populations, and at scale. These risks often arise not from poor ML development decisions or low performance directly but rather emerge through the interactions amongst ML development choices, the context of model use, environmental factors, and the effects of a model on its target. Systems safety engineering is an established discipline with a proven track record of identifying and managing risks even in high-complexity sociotechnical systems. In this work, we apply a state-of-the-art systems safety approach to concrete applications of ML with notable social and ethical risks to demonstrate a systematic means for meeting the assurance requirements needed to argue for safe and trustworthy ML in sociotechnical systems.
On Exact Sampling in the Two-Variable Fragment of First-Order Logic
Feb 06, 2023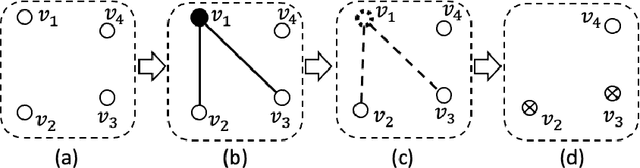
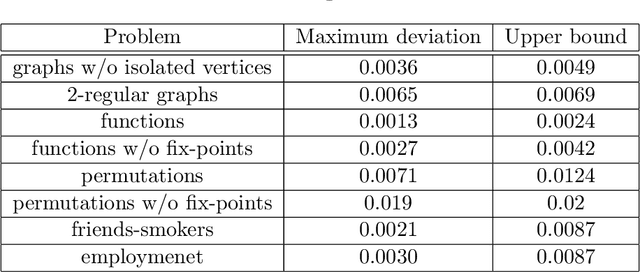
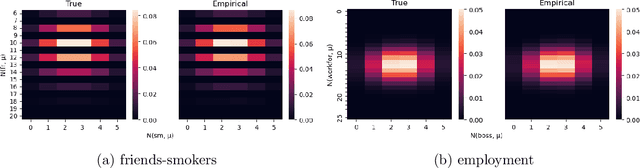
In this paper, we study the sampling problem for first-order logic proposed recently by Wang et al. -- how to efficiently sample a model of a given first-order sentence on a finite domain? We extend their result for the universally-quantified subfragment of two-variable logic $\mathbf{FO}^2$ ($\mathbf{UFO}^2$) to the entire fragment of $\mathbf{FO}^2$. Specifically, we prove the domain-liftability under sampling of $\mathbf{FO}^2$, meaning that there exists a sampling algorithm for $\mathbf{FO}^2$ that runs in time polynomial in the domain size. We then further show that this result continues to hold even in the presence of counting constraints, such as $\forall x\exists_{=k} y: \varphi(x,y)$ and $\exists_{=k} x\forall y: \varphi(x,y)$, for some quantifier-free formula $\varphi(x,y)$. Our proposed method is constructive, and the resulting sampling algorithms have potential applications in various areas, including the uniform generation of combinatorial structures and sampling in statistical-relational models such as Markov logic networks and probabilistic logic programs.
From CAD models to soft point cloud labels: An automatic annotation pipeline for cheaply supervised 3D semantic segmentation
Feb 06, 2023
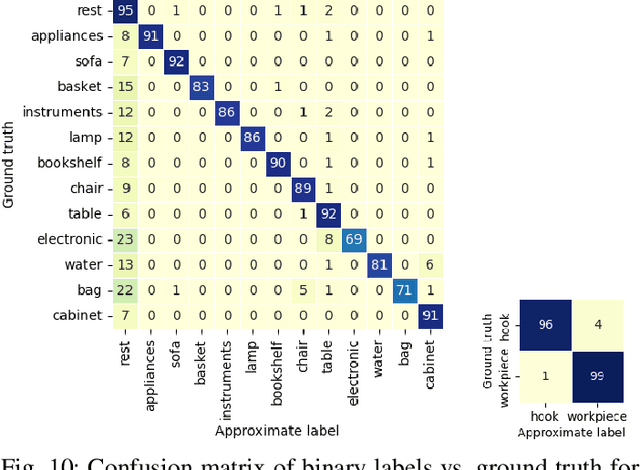
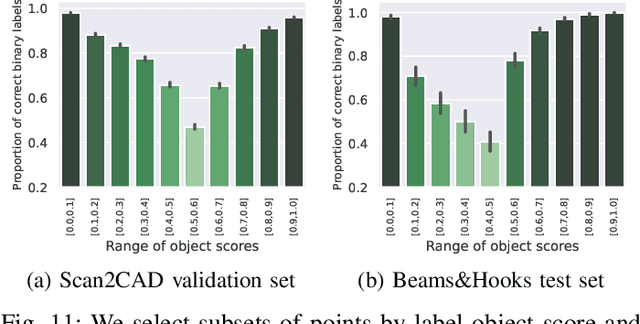
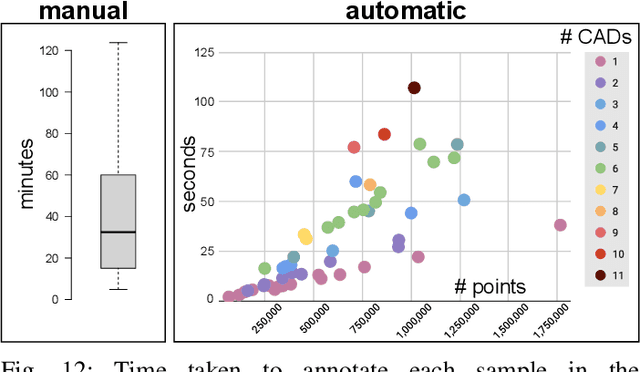
We propose a fully automatic annotation scheme which takes a raw 3D point cloud with a set of fitted CAD models as input, and outputs convincing point-wise labels which can be used as cheap training data for point cloud segmentation. Compared to manual annotations, we show that our automatic labels are accurate while drastically reducing the annotation time, and eliminating the need for manual intervention or dataset-specific parameters. Our labeling pipeline outputs semantic classes and soft point-wise object scores which can either be binarized into standard one-hot-encoded labels, thresholded into weak labels with ambiguous points left unlabeled, or used directly as soft labels during training. We evaluate the label quality and segmentation performance of PointNet++ on a dataset of real industrial point clouds and Scan2CAD, a public dataset of indoor scenes. Our results indicate that reducing supervision in areas which are more difficult to label automatically is beneficial, compared to the conventional approach of naively assigning a hard "best guess" label to every point.
Cooperative Task-Oriented Communication for Multi-Modal Data with Transmission Control
Feb 06, 2023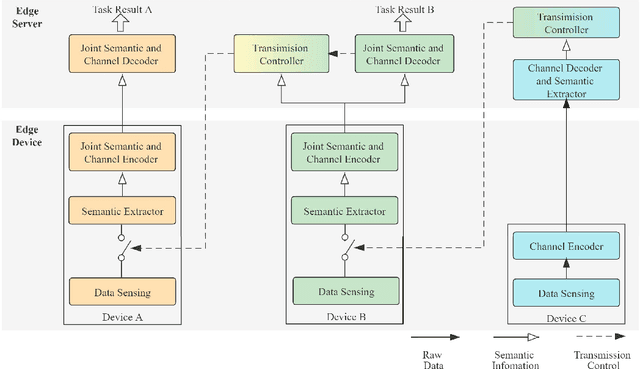
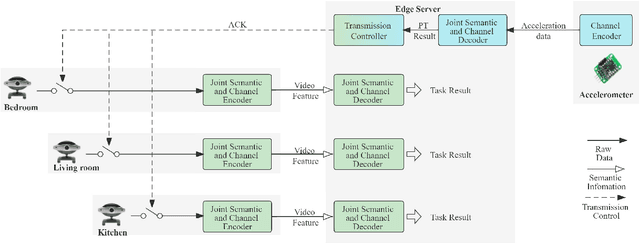


Real-time intelligence applications in Internet of Things (IoT) environment depend on timely data communication. However, it is challenging to transmit and analyse massive data of various modalities. Recently proposed task-oriented communication methods based on deep learning have showed its superiority in communication efficiency. In this paper, we propose a cooperative task-oriented communication method for the transmission of multi-modal data from multiple end devices to a central server. In particular, we use the transmission result of data of one modality, which is with lower rate, to control the transmission of other modalities with higher rate in order to reduce the amount of transmitted date. We take the human activity recognition (HAR) task in a smart home environment and design the semantic-oriented transceivers for the transmission of monitoring videos of different rooms and acceleration data of the monitored human. The numerical results demonstrate that by using the transmission control based on the obtained results of the received acceleration data, the transmission is reduced to 2% of that without transmission control while preserving the performance on the HAR task.
Accelerated Dynamic Magnetic Resonance Imaging from Spatial-Subspace Reconstructions (SPARS)
Feb 06, 2023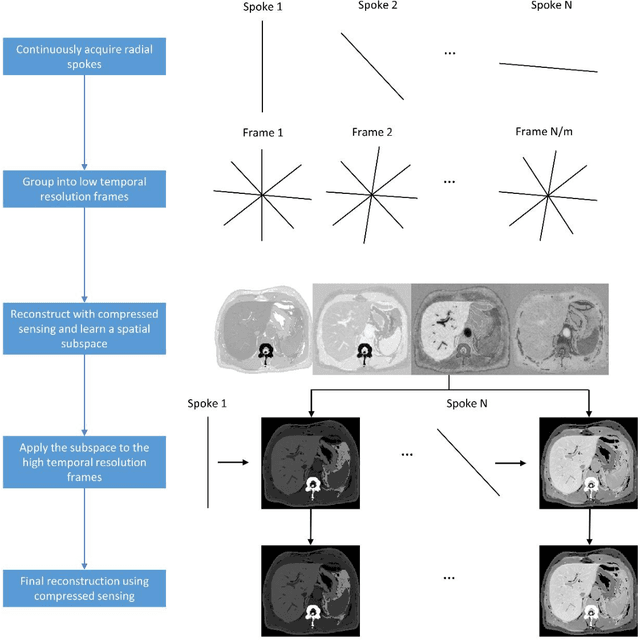
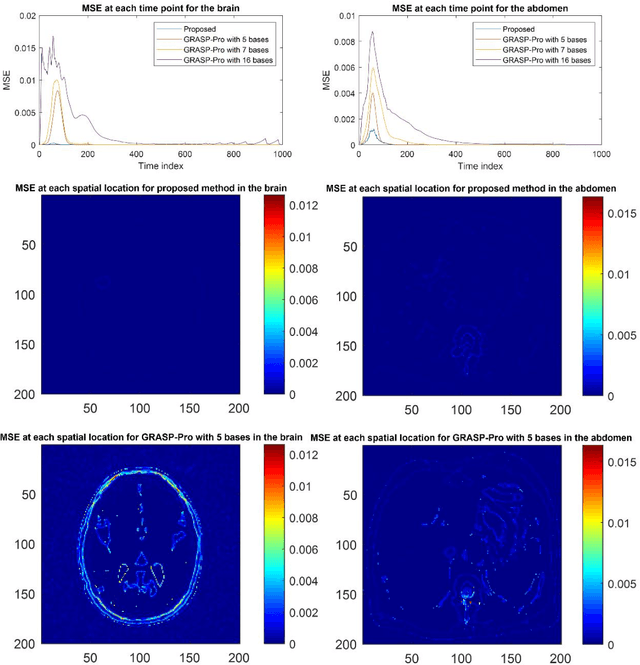
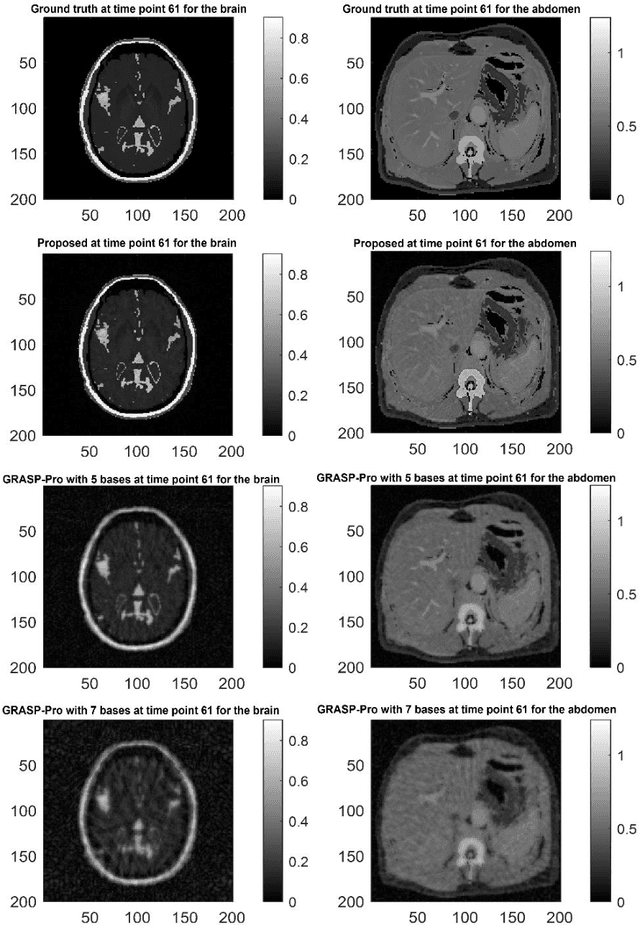
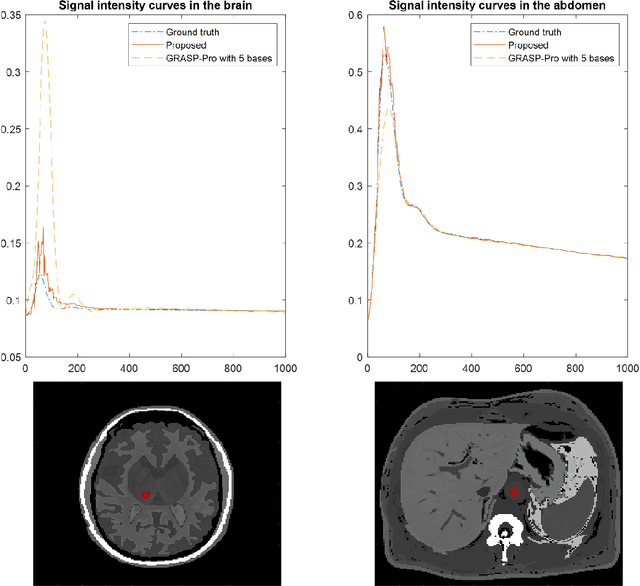
Dynamic contrast-enhanced (DCE) magnetic resonance imaging (MRI) ideally requires a high spatial and high temporal resolution, but hardware limitations prevent acquisitions from simultaneously achieving both. Existing image reconstruction techniques can artificially create spatial resolution at a given temporal resolution by estimating data that is not acquired, but, ultimately, spatial details are sacrificed at very high acceleration rates. The purpose of this paper is to introduce the concept of spatial subspace reconstructions (SPARS) and demonstrate its ability to reconstruct high spatial resolution dynamic images from as few as one acquired radial spoke per dynamic frame. Briefly, a low-temporal-high-spatial resolution organization of the acquired raw data is used to estimate a spatial subspace in which the high-temporal-high-spatial ground truth data resides. This subspace is then used to estimate entire images from single k-space spokes. In both simulated and human in-vivo data, the proposed SPARS reconstruction method outperformed standard GRASP and GRASP-Pro reconstruction, providing a shorter reconstruction time and yielding higher accuracy from both a spatial and temporal perspective.
Real-time Gesture Animation Generation from Speech for Virtual Human Interaction
Aug 05, 2022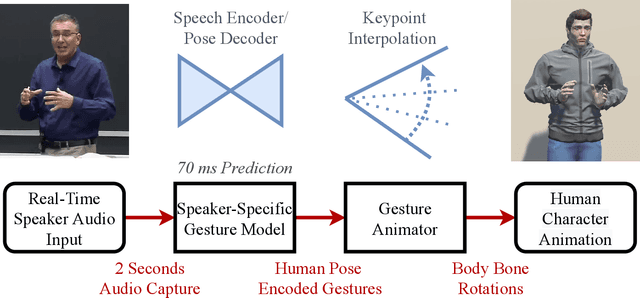
We propose a real-time system for synthesizing gestures directly from speech. Our data-driven approach is based on Generative Adversarial Neural Networks to model the speech-gesture relationship. We utilize the large amount of speaker video data available online to train our 3D gesture model. Our model generates speaker-specific gestures by taking consecutive audio input chunks of two seconds in length. We animate the predicted gestures on a virtual avatar. We achieve a delay below three seconds between the time of audio input and gesture animation. Code and videos are available at https://github.com/mrebol/Gestures-From-Speech
* CHI EA '21: Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems. arXiv admin note: text overlap with arXiv:2107.00712
Generative AI-empowered Effective Physical-Virtual Synchronization in the Vehicular Metaverse
Jan 19, 2023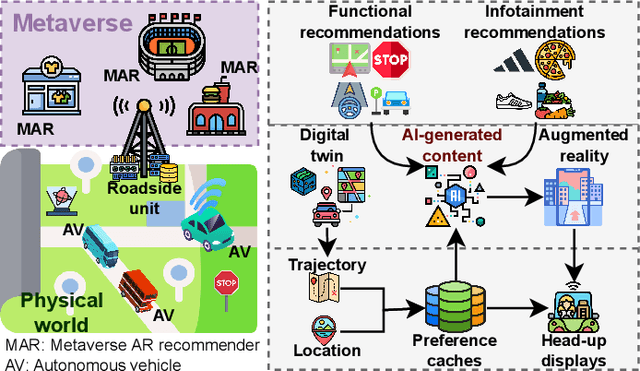
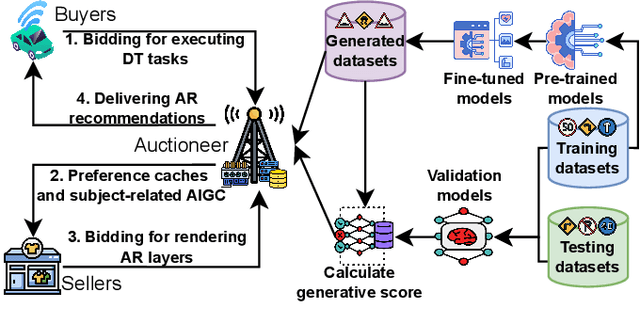

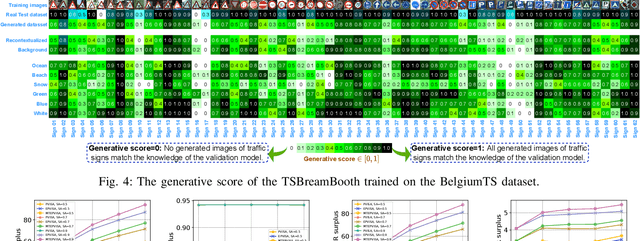
Metaverse seamlessly blends the physical world and virtual space via ubiquitous communication and computing infrastructure. In transportation systems, the vehicular Metaverse can provide a fully-immersive and hyperreal traveling experience (e.g., via augmented reality head-up displays, AR-HUDs) to drivers and users in autonomous vehicles (AVs) via roadside units (RSUs). However, provisioning real-time and immersive services necessitates effective physical-virtual synchronization between physical and virtual entities, i.e., AVs and Metaverse AR recommenders (MARs). In this paper, we propose a generative AI-empowered physical-virtual synchronization framework for the vehicular Metaverse. In physical-to-virtual synchronization, digital twin (DT) tasks generated by AVs are offloaded for execution in RSU with future route generation. In virtual-to-physical synchronization, MARs customize diverse and personal AR recommendations via generative AI models based on user preferences. Furthermore, we propose a multi-task enhanced auction-based mechanism to match and price AVs and MARs for RSUs to provision real-time and effective services. Finally, property analysis and experimental results demonstrate that the proposed mechanism is strategy-proof and adverse-selection free while increasing social surplus by 50%.
Leveraging Vision-Language Models for Granular Market Change Prediction
Jan 17, 2023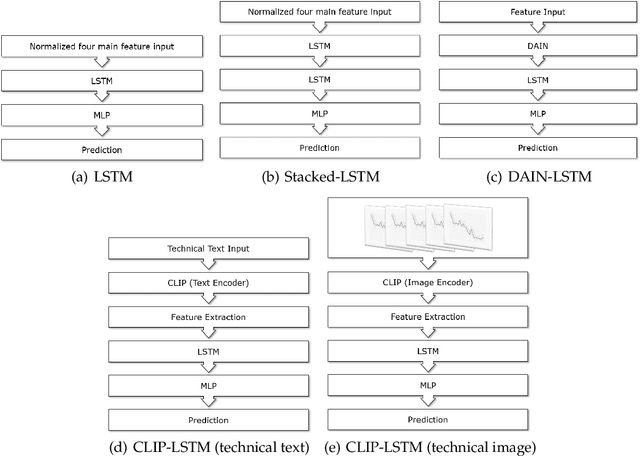

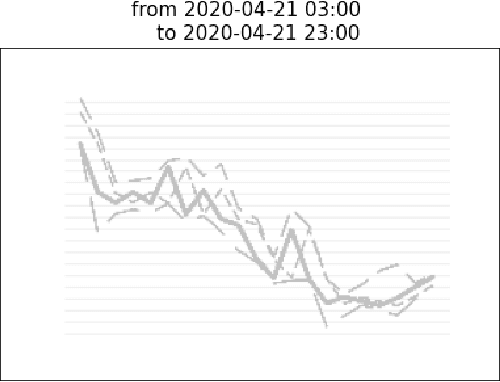
Predicting future direction of stock markets using the historical data has been a fundamental component in financial forecasting. This historical data contains the information of a stock in each specific time span, such as the opening, closing, lowest, and highest price. Leveraging this data, the future direction of the market is commonly predicted using various time-series models such as Long-Short Term Memory networks. This work proposes modeling and predicting market movements with a fundamentally new approach, namely by utilizing image and byte-based number representation of the stock data processed with the recently introduced Vision-Language models. We conduct a large set of experiments on the hourly stock data of the German share index and evaluate various architectures on stock price prediction using historical stock data. We conduct a comprehensive evaluation of the results with various metrics to accurately depict the actual performance of various approaches. Our evaluation results show that our novel approach based on representation of stock data as text (bytes) and image significantly outperforms strong deep learning-based baselines.
Explain What You See: Open-Ended Segmentation and Recognition of Occluded 3D Objects
Jan 17, 2023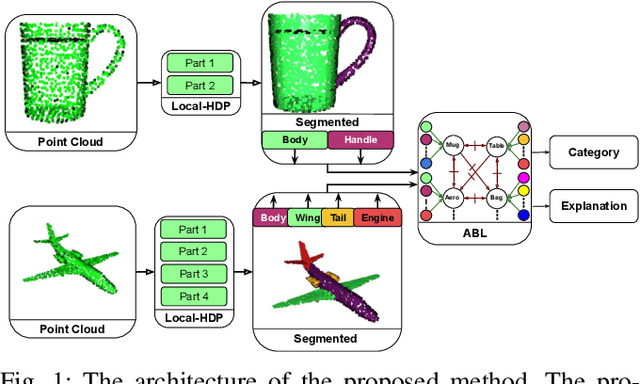
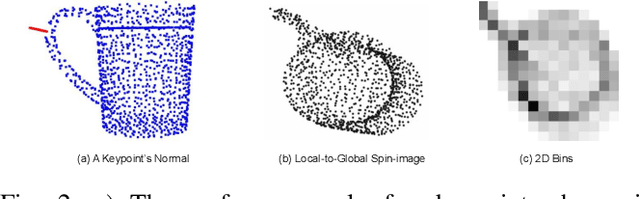
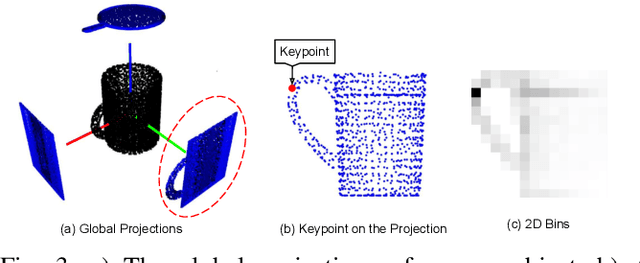

Local-HDP (for Local Hierarchical Dirichlet Process) is a hierarchical Bayesian method that has recently been used for open-ended 3D object category recognition. This method has been proven to be efficient in real-time robotic applications. However, the method is not robust to a high degree of occlusion. We address this limitation in two steps. First, we propose a novel semantic 3D object-parts segmentation method that has the flexibility of Local-HDP. This method is shown to be suitable for open-ended scenarios where the number of 3D objects or object parts is not fixed and can grow over time. We show that the proposed method has a higher percentage of mean intersection over union, using a smaller number of learning instances. Second, we integrate this technique with a recently introduced argumentation-based online incremental learning method, thereby enabling the model to handle a high degree of occlusion. We show that the resulting model produces an explicit set of explanations for the 3D object category recognition task.