 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Resource-Constrained Station-Keeping for Helium Balloons using Reinforcement Learning
Mar 02, 2023
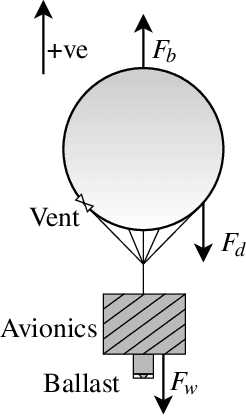
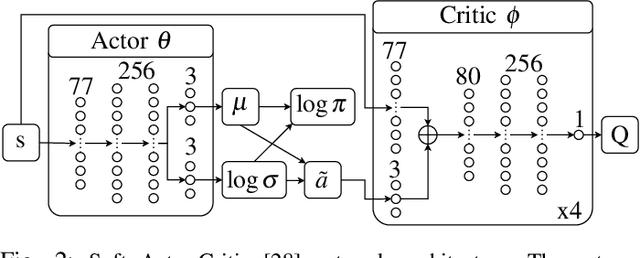
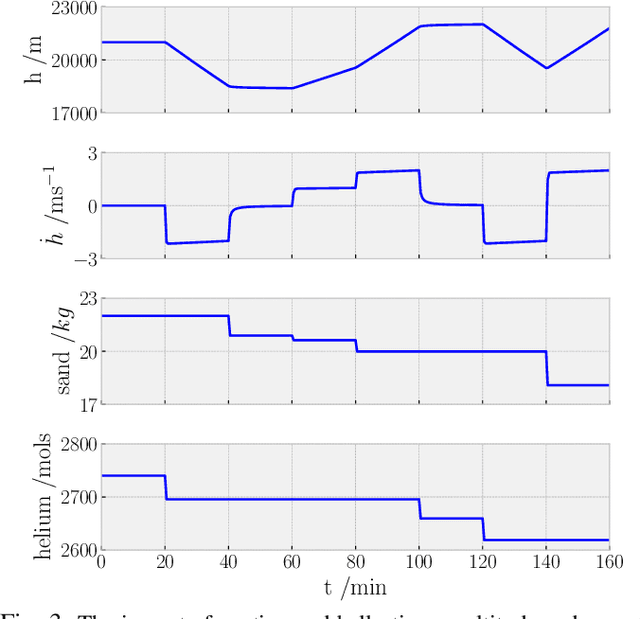
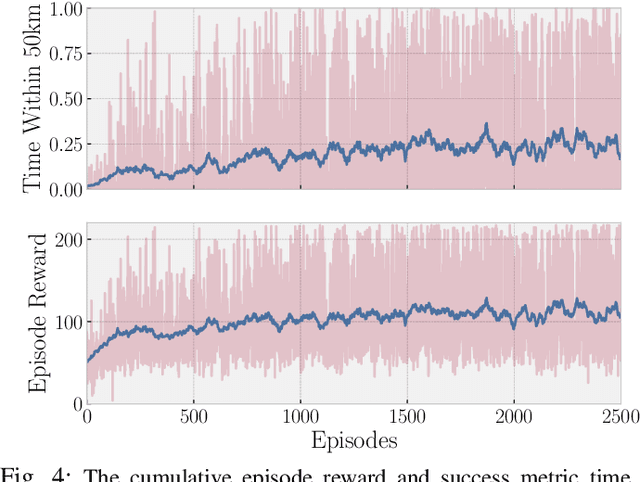
High altitude balloons have proved useful for ecological aerial surveys, atmospheric monitoring, and communication relays. However, due to weight and power constraints, there is a need to investigate alternate modes of propulsion to navigate in the stratosphere. Very recently, reinforcement learning has been proposed as a control scheme to maintain the balloon in the region of a fixed location, facilitated through diverse opposing wind-fields at different altitudes. Although air-pump based station keeping has been explored, there is no research on the control problem for venting and ballasting actuated balloons, which is commonly used as a low-cost alternative. We show how reinforcement learning can be used for this type of balloon. Specifically, we use the soft actor-critic algorithm, which on average is able to station-keep within 50\;km for 25\% of the flight, consistent with state-of-the-art. Furthermore, we show that the proposed controller effectively minimises the consumption of resources, thereby supporting long duration flights. We frame the controller as a continuous control reinforcement learning problem, which allows for a more diverse range of trajectories, as opposed to current state-of-the-art work, which uses discrete action spaces. Furthermore, through continuous control, we can make use of larger ascent rates which are not possible using air-pumps. The desired ascent-rate is decoupled into desired altitude and time-factor to provide a more transparent policy, compared to low-level control commands used in previous works. Finally, by applying the equations of motion, we establish appropriate thresholds for venting and ballasting to prevent the agent from exploiting the environment. More specifically, we ensure actions are physically feasible by enforcing constraints on venting and ballasting.
BenchDirect: A Directed Language Model for Compiler Benchmarks
Mar 02, 2023The exponential increase of hardware-software complexity has made it impossible for compiler engineers to find the right optimization heuristics manually. Predictive models have been shown to find near optimal heuristics with little human effort but they are limited by a severe lack of diverse benchmarks to train on. Generative AI has been used by researchers to synthesize benchmarks into existing datasets. However, the synthetic programs are short, exceedingly simple and lacking diversity in their features. We develop BenchPress, the first ML compiler benchmark generator that can be directed within source code feature representations. BenchPress synthesizes executable functions by infilling code that conditions on the program's left and right context. BenchPress uses active learning to introduce new benchmarks with unseen features into the dataset of Grewe's et al. CPU vs GPU heuristic, improving its acquired performance by 50%. BenchPress targets features that has been impossible for other synthesizers to reach. In 3 feature spaces, we outperform human-written code from GitHub, CLgen, CLSmith and the SRCIROR mutator in targeting the features of Rodinia benchmarks. BenchPress steers generation with beam search over a feature-agnostic language model. We improve this with BenchDirect which utilizes a directed LM that infills programs by jointly observing source code context and the compiler features that are targeted. BenchDirect achieves up to 36% better accuracy in targeting the features of Rodinia benchmarks, it is 1.8x more likely to give an exact match and it speeds up execution time by up to 72% compared to BenchPress. Both our models produce code that is difficult to distinguish from human-written code. We conduct a Turing test which shows our models' synthetic benchmarks are labelled as 'human-written' as often as human-written code from GitHub.
Wideband Time Frequency Coding
May 31, 2022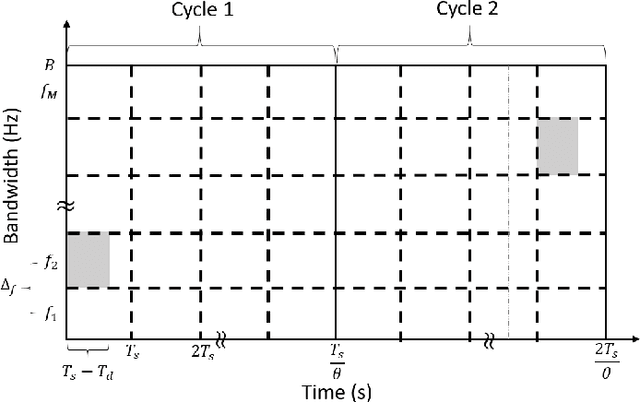
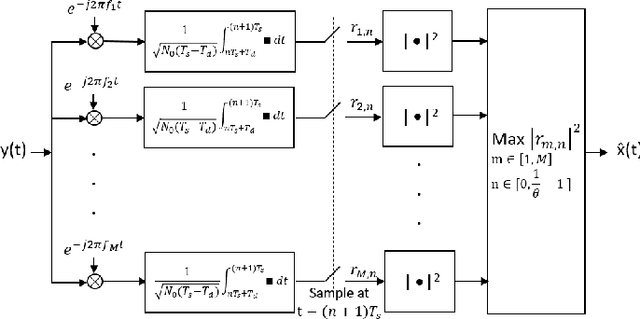
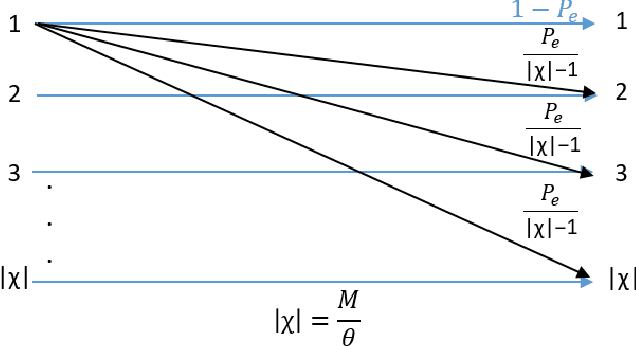
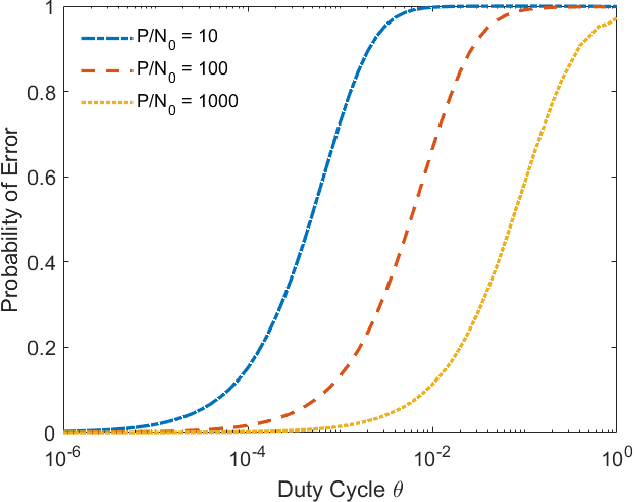
In the wideband regime, the performance of many of the popular modulation schemes such as code division multiple access and orthogonal frequency division multiplexing falls quickly without channel state information. Obtaining the amount of channel information required for these techniques to work is costly and difficult, which suggests the need for schemes which can perform well without channel state information. In this work, we present one such scheme, called wideband time frequency coding, which achieves rates on the order of the additive white Gaussian noise capacity without requiring any channel state information. Wideband time frequency coding combines impulsive frequency shift keying with pulse position modulation, which allows for information to be encoded in both the transmitted frequency and the transmission time period. On the detection side, we propose a non-coherent decoder based on a square-law detector, akin to the optimal decoder for frequency shift keying based signals. The impacts of various parameters on the symbol error probability and capacity of wideband time frequency coding are investigated, and the results show that it is robust to shadowing and highly fading channels. When compared to other modulation schemes such as code division multiple access, orthogonal frequency division multiplexing, pulse position modulation, and impulsive frequency shift keying without channel state information, wideband time frequency coding achieves higher rates in the wideband regime, and performs comparably in smaller bandwidths.
Immersive Virtual Colonoscopy Viewer for Colorectal Diagnosis
Feb 06, 2023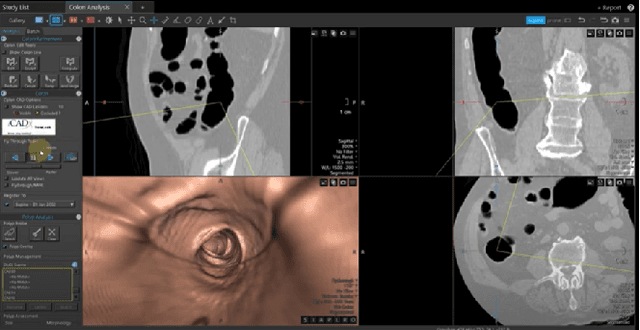
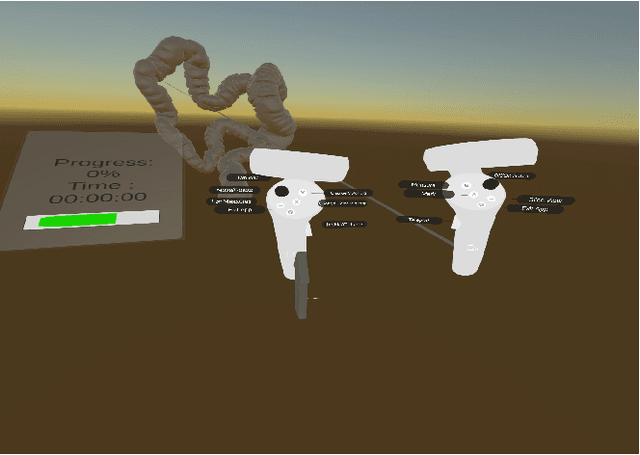
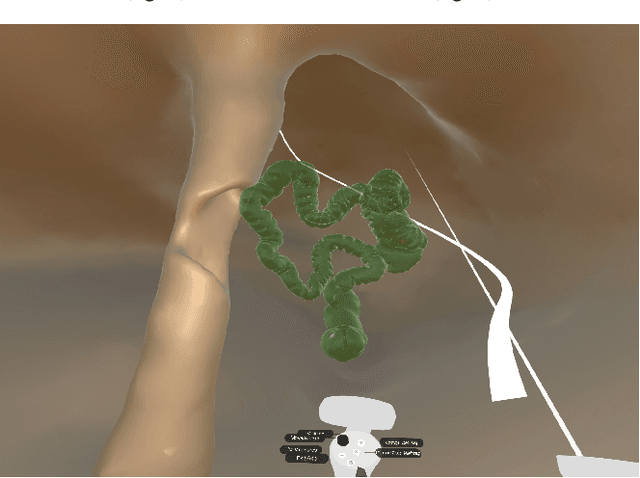
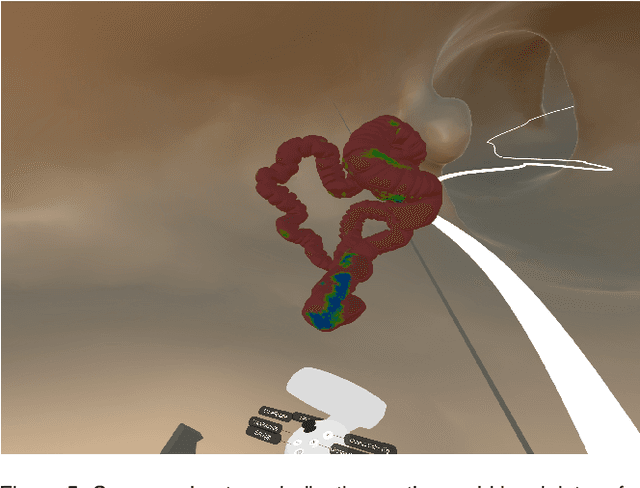
Desktop-based virtual colonoscopy has been proven to be an asset in the identification of colon anomalies. The process is accurate, although time-consuming. The use of immersive interfaces for virtual colonoscopy is incipient and not yet understood. In this work, we present a new design exploring elements of the VR paradigm to make the immersive analysis more efficient while still effective. We also plan the conduction of experiments with experts to assess the multi-factor influences of coverage, duration, and diagnostic accuracy.
An Information-Theoretic Analysis of Nonstationary Bandit Learning
Feb 09, 2023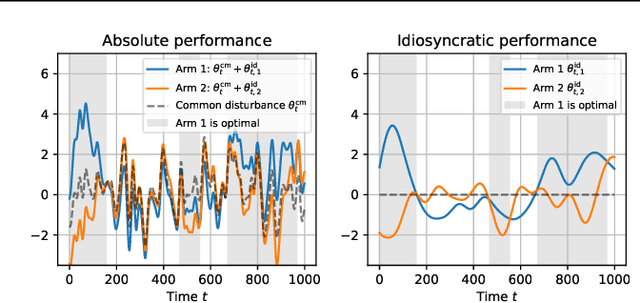
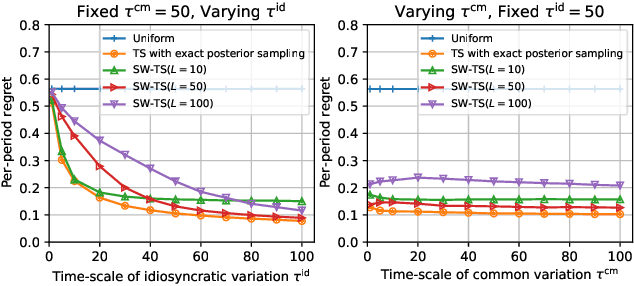
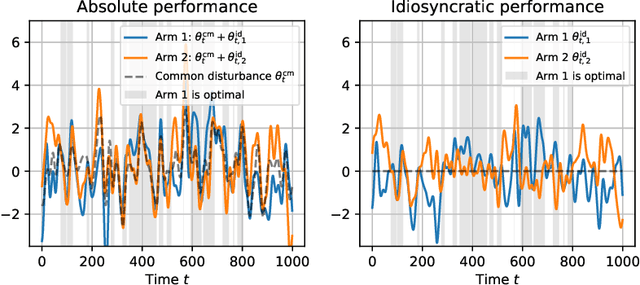
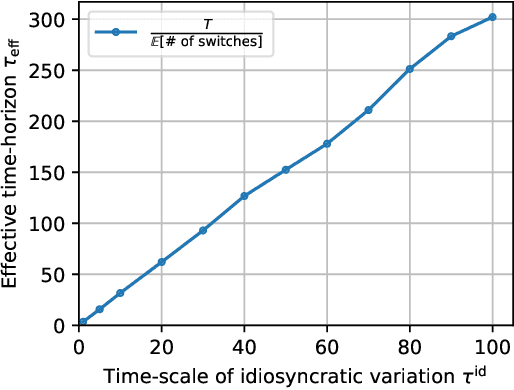
In nonstationary bandit learning problems, the decision-maker must continually gather information and adapt their action selection as the latent state of the environment evolves. In each time period, some latent optimal action maximizes expected reward under the environment state. We view the optimal action sequence as a stochastic process, and take an information-theoretic approach to analyze attainable performance. We bound limiting per-period regret in terms of the entropy rate of the optimal action process. The bound applies to a wide array of problems studied in the literature and reflects the problem's information structure through its information-ratio.
Social4Rec: Distilling User Preference from Social Graph for Video Recommendation in Tencent
Feb 23, 2023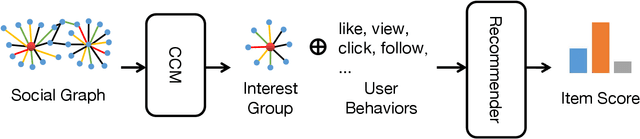
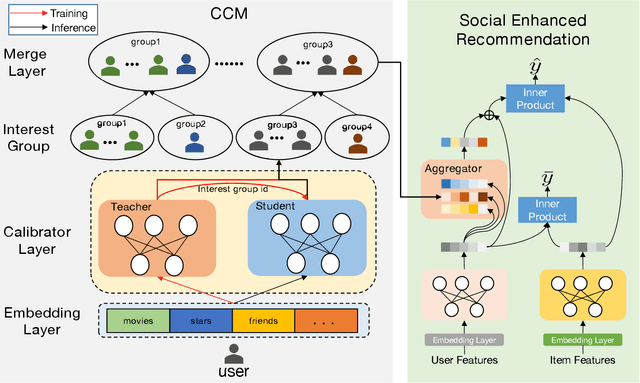

Despite recommender systems play a key role in network content platforms, mining the user's interests is still a significant challenge. Existing works predict the user interest by utilizing user behaviors, i.e., clicks, views, etc., but current solutions are ineffective when users perform unsettled activities. The latter ones involve new users, which have few activities of any kind, and sparse users who have low-frequency behaviors. We uniformly describe both these user-types as "cold users", which are very common but often neglected in network content platforms. To address this issue, we enhance the representation of the user interest by combining his social interest, e.g., friendship, following bloggers, interest groups, etc., with the activity behaviors. Thus, in this work, we present a novel algorithm entitled SocialNet, which adopts a two-stage method to progressively extract the coarse-grained and fine-grained social interest. Our technique then concatenates SocialNet's output with the original user representation to get the final user representation that combines behavior interests and social interests. Offline experiments on Tencent video's recommender system demonstrate the superiority over the baseline behavior-based model. The online experiment also shows a significant performance improvement in clicks and view time in the real-world recommendation system. The source code is available at https://github.com/Social4Rec/SocialNet.
MFBE: Leveraging Multi-Field Information of FAQs for Efficient Dense Retrieval
Feb 23, 2023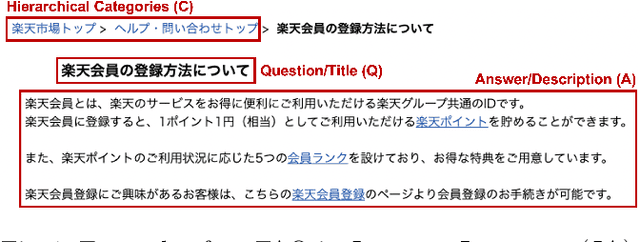
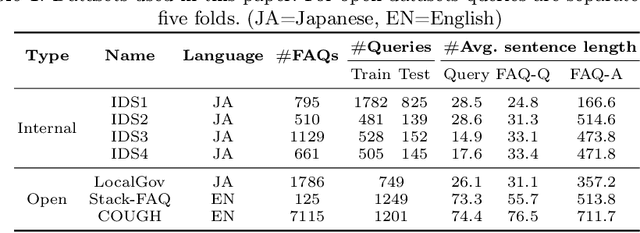
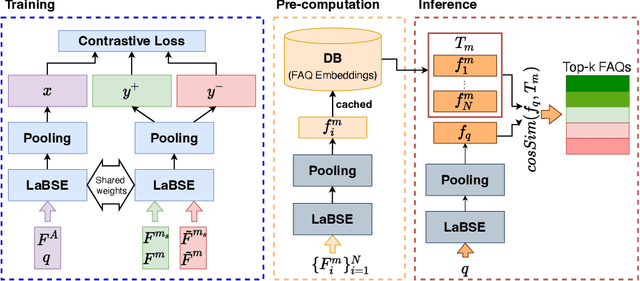
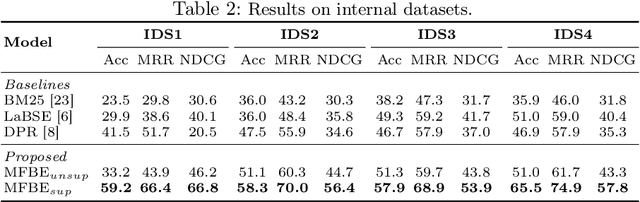
In the domain of question-answering in NLP, the retrieval of Frequently Asked Questions (FAQ) is an important sub-area which is well researched and has been worked upon for many languages. Here, in response to a user query, a retrieval system typically returns the relevant FAQs from a knowledge-base. The efficacy of such a system depends on its ability to establish semantic match between the query and the FAQs in real-time. The task becomes challenging due to the inherent lexical gap between queries and FAQs, lack of sufficient context in FAQ titles, scarcity of labeled data and high retrieval latency. In this work, we propose a bi-encoder-based query-FAQ matching model that leverages multiple combinations of FAQ fields (like, question, answer, and category) both during model training and inference. Our proposed Multi-Field Bi-Encoder (MFBE) model benefits from the additional context resulting from multiple FAQ fields and performs well even with minimal labeled data. We empirically support this claim through experiments on proprietary as well as open-source public datasets in both unsupervised and supervised settings. Our model achieves around 27% and 20% better top-1 accuracy for the FAQ retrieval task on internal and open datasets, respectively over the best performing baseline.
Effects of Archive Size on Computation Time and Solution Quality for Multi-Objective Optimization
Sep 07, 2022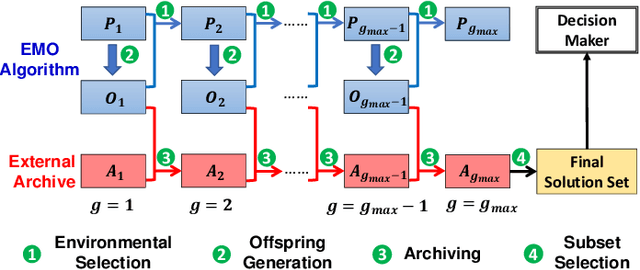
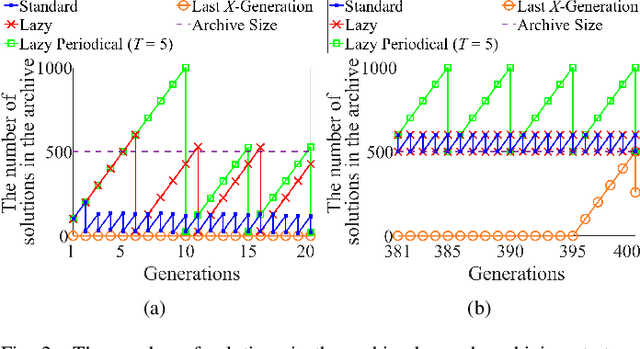
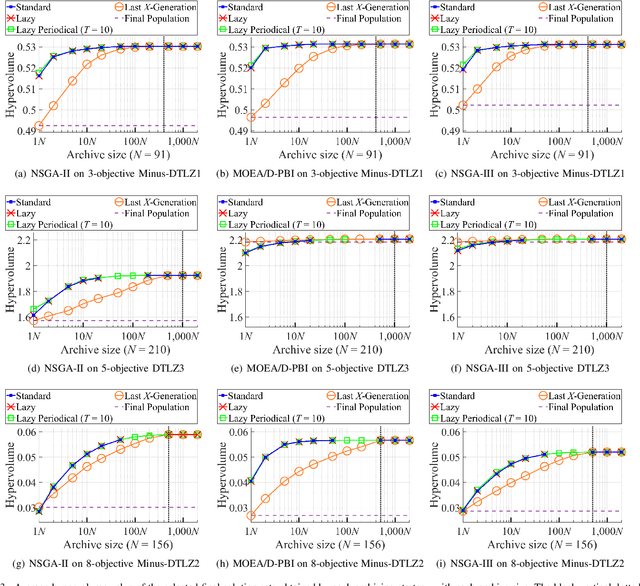
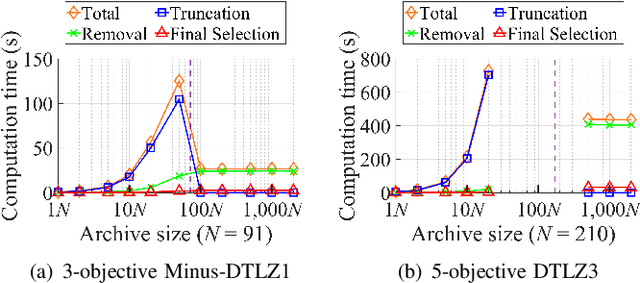
An unbounded external archive has been used to store all nondominated solutions found by an evolutionary multi-objective optimization algorithm in some studies. It has been shown that a selected solution subset from the stored solutions is often better than the final population. However, the use of the unbounded archive is not always realistic. When the number of examined solutions is huge, we must pre-specify the archive size. In this study, we examine the effects of the archive size on three aspects: (i) the quality of the selected final solution set, (ii) the total computation time for the archive maintenance and the final solution set selection, and (iii) the required memory size. Unsurprisingly, the increase of the archive size improves the final solution set quality. Interestingly, the total computation time of a medium-size archive is much larger than that of a small-size archive and a huge-size archive (e.g., an unbounded archive). To decrease the computation time, we examine two ideas: periodical archive update and archiving only in later generations. Compared with updating the archive at every generation, the first idea can obtain almost the same final solution set quality using a much shorter computation time at the cost of a slight increase of the memory size. The second idea drastically decreases the computation time at the cost of a slight deterioration of the final solution set quality. Based on our experimental results, some suggestions are given about how to appropriately choose an archiving strategy and an archive size.
Interpretable Time Series Clustering Using Local Explanations
Aug 01, 2022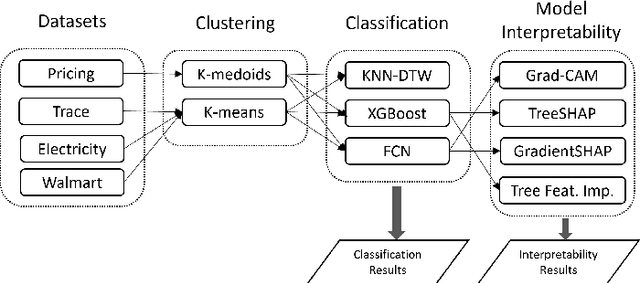
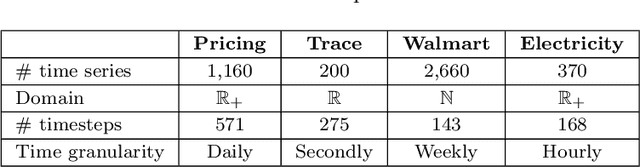
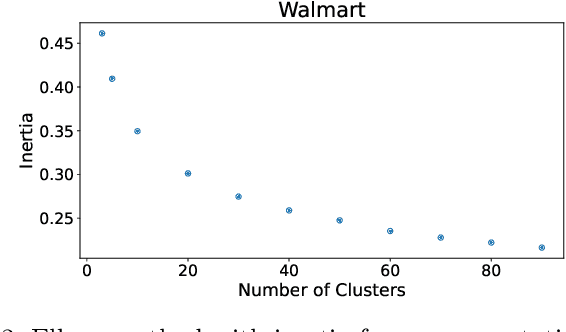
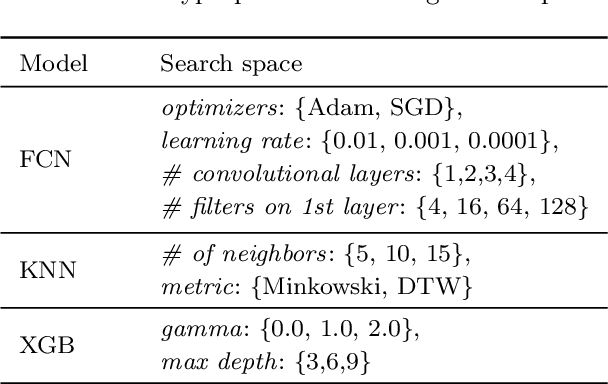
This study focuses on exploring the use of local interpretability methods for explaining time series clustering models. Many of the state-of-the-art clustering models are not directly explainable. To provide explanations for these clustering algorithms, we train classification models to estimate the cluster labels. Then, we use interpretability methods to explain the decisions of the classification models. The explanations are used to obtain insights into the clustering models. We perform a detailed numerical study to test the proposed approach on multiple datasets, clustering models, and classification models. The analysis of the results shows that the proposed approach can be used to explain time series clustering models, specifically when the underlying classification model is accurate. Lastly, we provide a detailed analysis of the results, discussing how our approach can be used in a real-life scenario.
Deep Class-Incremental Learning: A Survey
Feb 07, 2023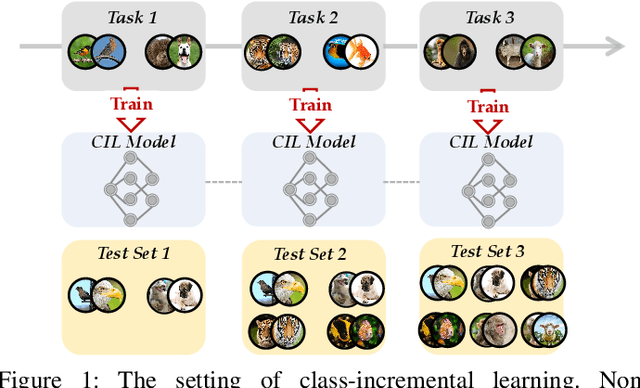
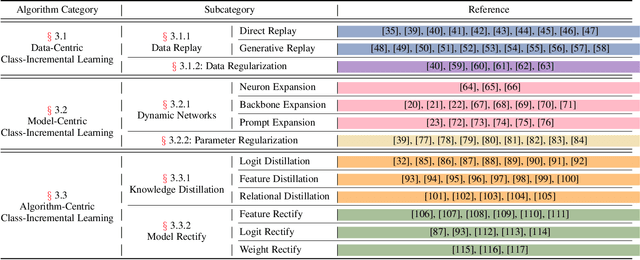
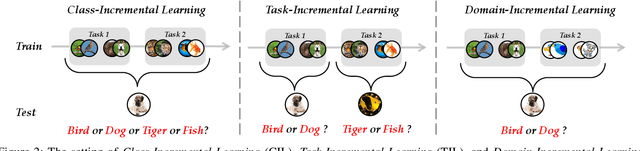
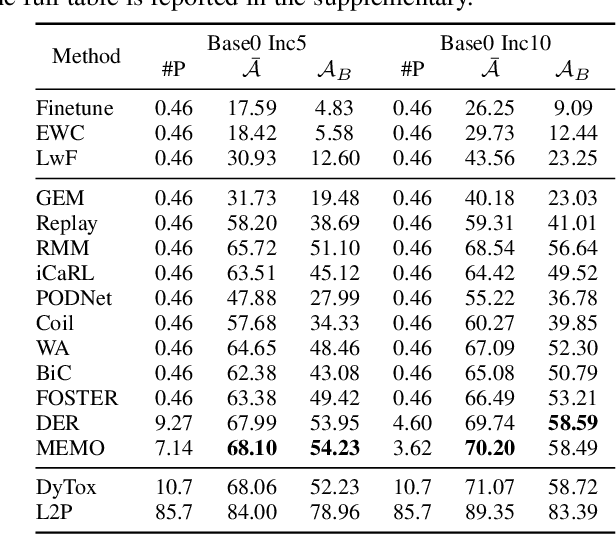
Deep models, e.g., CNNs and Vision Transformers, have achieved impressive achievements in many vision tasks in the closed world. However, novel classes emerge from time to time in our ever-changing world, requiring a learning system to acquire new knowledge continually. For example, a robot needs to understand new instructions, and an opinion monitoring system should analyze emerging topics every day. Class-Incremental Learning (CIL) enables the learner to incorporate the knowledge of new classes incrementally and build a universal classifier among all seen classes. Correspondingly, when directly training the model with new class instances, a fatal problem occurs -- the model tends to catastrophically forget the characteristics of former ones, and its performance drastically degrades. There have been numerous efforts to tackle catastrophic forgetting in the machine learning community. In this paper, we survey comprehensively recent advances in deep class-incremental learning and summarize these methods from three aspects, i.e., data-centric, model-centric, and algorithm-centric. We also provide a rigorous and unified evaluation of 16 methods in benchmark image classification tasks to find out the characteristics of different algorithms empirically. Furthermore, we notice that the current comparison protocol ignores the influence of memory budget in model storage, which may result in unfair comparison and biased results. Hence, we advocate fair comparison by aligning the memory budget in evaluation, as well as several memory-agnostic performance measures. The source code to reproduce these evaluations is available at https://github.com/zhoudw-zdw/CIL_Survey/